

JS中unicode和utf-8的转换
JS中unicode和utf-8的转换
最近公司找了几个py写后端项目,后端接口中返回 '\xe6\x88\x91\xe4\xbb\xac' 类似的编码,我看着就很好奇,于是将此段编码过的字符输入chrome的控制台,结果如下:
> '\xe6\x88\x91\xe4\xbb\xac'
< "æ们"
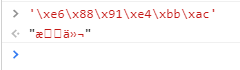
很明显,由于解释错误出现了乱码问题。。。
在网上一番搜索发现,这就是utf-8编码,本着好奇,就想知道unicode和utf-8之间是如何转换的。。。至于utf-8和unicode的区别,我只强调一点 UTF-8是 Unicode 的实现方式之一 ,具体的话大家网上自行查找,这里提供我参考的文章 字符编码笔记:ASCII,Unicode 和 UTF-8,下面我总结下在js中这两种编码之间如何转换
unicode转utf-8
我们知道在js中,encodeURI和encodeURIComponent函数将URI转为utf-8编码:
> encodeURIComponent('深圳华强')
< "%E6%B7%B1%E5%9C%B3%E5%8D%8E%E5%BC%BA"
在网上验证下没问题:

/**
*
* @param str {String}
* @return {Array{Number}}
*/
function encodeUTF8 (str = '深圳华强') {
let str1 = encodeURIComponent(str) // "%E6%B7%B1%E5%9C%B3%E5%8D%8E%E5%BC%BA"
let ret = []
for (let i = 0; i < str1.length / 3; i++) {
ret.push(str1.slice(i * 3, (i + 1) * 3).slice(1))
}
// ret = ["E6", "B7", "B1", "E5", "9C", "B3", "E5", "8D", "8E", "E5", "BC", "BA"]
return ret.map(el => parseInt(el, 16)) // [230, 183, 177, 229, 156, 179, 229, 141, 142, 229, 188, 186]
}
utf-8转unicode
/**
*
* @param arr {Array{Number}}
* @return {string}
*/
function decodeUTF8 (arr = [230, 183, 177, 229, 156, 179, 229, 141, 142, 229, 188, 186]) {
let str = arr.reduce((prev, cur) => prev +=`%${cur.toString(16)}`, '')
return decodeURIComponent(str) // '深圳华强'
}
测试
> encodeUTF8()
< [230, 183, 177, 229, 156, 179, 229, 141, 142, 229, 188, 186]
> decodeUTF8()
< "深圳华强"
最后回到我们开头的问题, '\xe6\x88\x91\xe4\xbb\xac' 到底代表什么意思?
我尝试很很多种方法,发现只要js识别到 '\xe6\x88\x91\xe4\xbb\xac' 马上就进行解码了,根本没有机会操作。。。最后我发现将其中\要先转义处理:'\xe6\x88\x91\xe4\xbb\xac',然后就好处理了,如果这个东西要前端要展示的话,只能暂时求助后端同学提前对反斜杠进行转移处理了。。。
let reg = /\\x/g
console.log('\\xe6\\x88\\x91\\xe4\\xbb\\xac') // \xe6\x88\x91\xe4\xbb\xac
console.log('\\xe6\\x88\\x91\\xe4\\xbb\\xac'.replace(reg, '%')) // %e6%88%91%e4%bb%ac
console.log(decodeURIComponent('\\xe6\\x88\\x91\\xe4\\xbb\\xac'.replace(reg, '%'))) // 我们
续更(2020.7.21)
对于昨天结尾遗留的问题,我找到了不完美的解决方案:ECMAScript 6 入门 String.raw()
ES6 还为原生的 String 对象,提供了一个raw()方法。该方法返回一个斜杠都被转义(即斜杠前面再加一个斜杠)的字符串,往往用于模板字符串的处理方法
String.raw`Hi\n${2+3}!`
// 实际返回 "Hi\\n5!",显示的是转义后的结果 "Hi\n5!"
String.raw`Hi\u000A!`;
// 实际返回 "Hi\\u000A!",显示的是转义后的结果 "Hi\u000A!"
解决方案跟昨天后端童鞋解决方案一样,通过 String.raw 对反斜杠\进行转义,如下:
let reg = /\\x/g
let str = String.raw`\xe6\x88\x91\xe4\xbb\xac`
// 实际返回 "\\xe6\\x88\\x91\\xe4\\xbb\\xac",显示的是转义后的记过 "\xe6\x88\x91\xe4\xbb\xac"
// 后续的操作就跟上边一样了,String.raw缺陷就是没办法传入变量...
let str = '\xe6\x88\x91\xe4\xbb\xac'
String.raw`${str }`
// 返回 "æ们" 相当于还是解析str了,导致String.raw失效了
参考资料:
UTF-8编码规则(转)
rfc3629
查看字符编码(UTF-8)在线工具
字符编码的前世今生
两次encodeURI和URLDecode的原理分析
JavaScript进行UTF-8编码与解码


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· Linux系列:如何用 C#调用 C方法造成内存泄露
· AI与.NET技术实操系列(二):开始使用ML.NET
· 【自荐】一款简洁、开源的在线白板工具 Drawnix
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY
· 无需6万激活码!GitHub神秘组织3小时极速复刻Manus,手把手教你使用OpenManus搭建本
· C#/.NET/.NET Core优秀项目和框架2025年2月简报