3、使用keepalived高可用LVS实例演示
回顾:
keepalived: vrrp协议的实现;
虚拟路由器:
MASTER,BACKUP
VI:Virtual Instance
keepalived.conf
GLOBAL
VRRP
LVS
keepalived(2)
# man keepalived.conf
VRRP instance(s)和VRRP synchronization group(s)都有邮件通知选项
在虚拟实例VI中的主机状态发生改变生发送通知:
# notify scripts, alert as above //自行写一个脚本
notify_master <STRING>|<QUOTED-STRING> //只有被操作的当前节点转换为MASTER时,就发送这里指明的通知信息(即<STRING>|<QUOTED-STRING>)
notify_master "/etc/keepalived/notify.sh master"
//最后的master是参数,当给脚本传递master参数时,定义的脚本就会发送当前主机转换为master状态
notify_backup <STRING>|<QUOTED-STRING> //同上,当前节点转换为BACKUP时...,<STRING>表示字符串,<QUOTED-STRING>表示引号引起来的字串
notify_fault <STRING>|<QUOTED-STRING> //当前节点转换为fault...
notify <STRING>|<QUOTED-STRING> //只要状态转换,就通知...
smtp_alert
定义通知脚本
# cd /etc/keepalived
# vim notify.sh
1 #!/bin/bash 2 3 # Author: MageEdu <linuxedu@foxmail.com> 4 # description: An example of notify script 5 6 vip=172.16.100.88 7 contact='root@localhost' //邮件联系人即发给谁 8 9 notify() { 10 mailsubject="`hostname` to be $1: $vip floating" //邮件标题,$1接收传递的第一个参数,如果传递的参数时master,则当前主机转换为master,则上面定义的vip发生流动float。
mailbody="`date '+%F %H:%M:%S'`: vrrp transition, `hostname` changed to be $1" //邮件主题,hostname` changed to be $1 定义当前主机转换的状态 12 echo $mailbody | mail -s "$mailsubject" $contact 13 } 14 15 case "$1" in 16 master) 17 notify master 18 exit 0 19 ;; 20 21 backup) 22 notify backup 23 exit 0 24 ;; 25 26 fault) 27 notify fault 28 exit 0 29 ;; 30 31 *) 32 echo 'Usage: `basename $0` {master|backup|fault}' 33 exit 1 34 ;; 35 esac
# bash notify.sh master //执行这个脚本,并传递参数,如果显示无法找到mail命令,则安装mail
# yum install mailx
Heirloom Mail version 12.5 7/5/10. Type ? for help.
"/var/spool/mail/root": 2 messages 1 new 2 unread
U 1 root Sat Dec 8 21:40 19/699 "node1 to be master: 192.168.184.141 floating"
>N 2 root Sat Dec 8 22:39 18/689 "node1 to be master: 192.168.184.141 floating"
& q
Held 2 messages in /var/spool/mail/root
下面结合1和2博客里面的配置进行实例演示
在vrrp_instance中定义分别接收不同参数的方式调用警告邮件的脚本/etc/keepalived/notify.sh,来发出告警信息
# scp -p notify.sh node2:/etc/keepalived/ //把脚本复制到node2上,注意这里是免密交互
# vim keepalived.conf //在141实例1的末尾添加,同样在142节点的配置文件中做修改
1 vrrp_instance VI_1 { 2 ...... 3 virtual_ipaddress { 4 192.168.184.150/24 5 } 6 7 track_script { 8 chk_down 9 } 10 notify_master "/etc/keepalived/notify.sh master" 11 notify_backup "/etc/keepalived/notify.sh backup" 12 notify_fault "/etc/keepalived/notify.sh fault" 13 }
# systemctl restart keepalived; ssh node2 'systemctl restart keepalived'
You have new mail in /var/spool/mail/root //此时直接提示有邮件信息
# touch down //在node1上创建down文件,前面已经配置,此文件可使node1节点的优先级减2变为backup
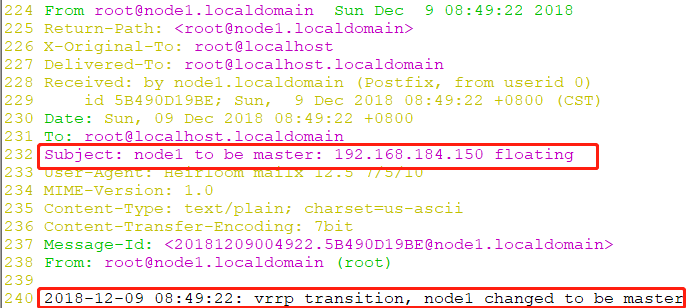
# vim /var/spool/mail/root //进入此文件,可以看到node1节点成为backup。

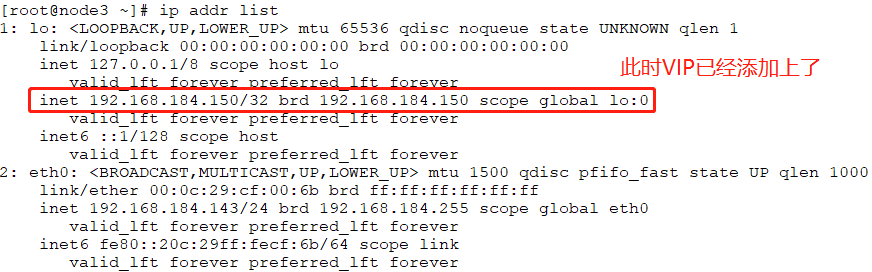
# ip addr list //这里查看node1的VIP,已经漂移到node2上。
# rm -rf down //删除town文件,注意操作路径都是在/etc/keepalived
# ip addr list //再次查看VIP,此时已经在node1上了
# vim /var/spool/mail/root //进入邮件进行查看,可以看出node1上的VIP称为master
# mail //同时也可以直接使用mail命令进行查看
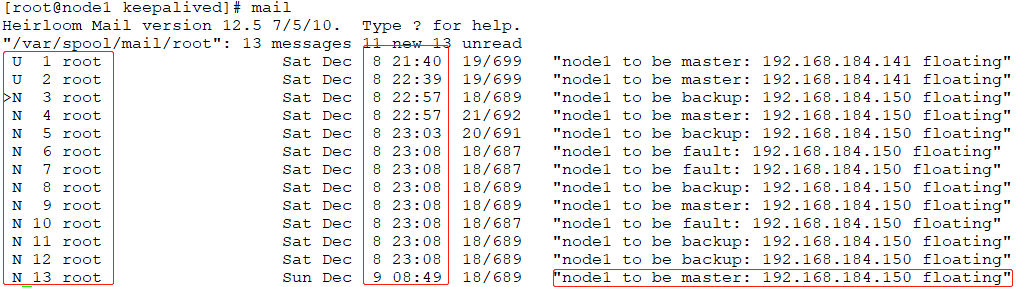
同时在node2节点上也很会有mail通知,查看方式一样,但提前时必须安装mail,#yum install mailx
如何实现为keepalived提供ipvs规则(如何在高可用服务vrrp所提供的资源流转之外,真正实现负载均衡)
# man keepalived.conf
LVS CONFIGURATION
contains subblocks of Virtual server group(s) and Virtual server(s)
The subblocks contain arguments for ipvsadm(8). Knowledge of ipvsadm(8) will be helpful here.
Virtual server(s)
A virtual_server can be a declaration of one of //三种方法
vip vport (IPADDR PORT pair) //ip+端口,这里及支持tcp协议有支持UDP协议,支持哪种协议要用protocol进行定义
fwmark <INT> //防火墙标记
(virtual server) group <STRING> //意义不大
如何设定LVS集群 #setup service virtual_server IP port | virtual_server fwmark int | virtual_server group string { # delay timer for service polling delay_loop <INT> //service polling的延时计时器,keepalived不仅可以实现LVS规则的自动生成,还可以对各real server做健康状态检测, //delay_loop表示每隔多久向各real server发一次健康状态探查命令,还可以指明多少次 # LVS scheduler lb_algo rr|wrr|lc|wlc|lblc|sh|dh //负载均衡所支持的调度算法
# Enable hashed entry hashed # Enable flag-1 for scheduler (-b flag-1 in ipvsadm) # Enable One-Packet-Scheduling for UDP (-O in ipvsadm) //每一个报文单独进行调度,DUP协议是无连接的,UDP协议每发一个报文都是一个新请求,是否对UDP报文的每一个请求都单独调度, ops //否则可以使ipvs实现追踪效果 # LVS forwarding method lb_kind NAT|DR|TUN //lvs的类型 # LVS persistence engine name persistence_engine <STRING> # LVS persistence timeout in seconds, default 6 minutes persistence_timeout [<INT>] //持久时长 # LVS granularity mask (-M in ipvsadm) persistence_granularity <NETMASK> # L4 protocol protocol TCP|UDP|SCTP //设定支持的协议 # If VS IP address is not set, # suspend healthchecker's activity ha_suspend lvs_sched # synonym for lb_algo lvs_method # synonym for lb_kind
# VirtualHost string for HTTP_GET or SSL_GET //如果高可用的是web服务器的话,web服务器有可能支持虚拟主机
# eg virtualhost www.firewall.loc
virtualhost <STRING> //定义对哪个虚拟主机基于HTTP_GET或SSL_GET方式做健康状态检测
# RS to add when all realservers are down
sorry_server <IPADDR> <PORT> //提示错误信息
# applies inhibit_on_failure behaviour to the
# preceding sorry_server directive
sorry_server_inhibit
# HTTP and SSL healthcheckers
real_server <IPADDR> <PORT> { # relative weight to use, default: 1 weight <INT> # Set weight to 0 when healthchecker detects failure inhibit_on_failure # Script to execute when healthchecker # considers service as up. notify_up <STRING>|<QUOTED-STRING> [username [groupname]] # Script to execute when healthchecker # considers service as down. notify_down <STRING>|<QUOTED-STRING> [username [groupname]] uthreshold <INTEGER> # maximum number of connections to server lthreshold <INTEGER> # minimum number of connections to server # pick one healthchecker # HTTP_GET|SSL_GET|TCP_CHECK|SMTP_CHECK|DNS_CHECK|MISC_CHECK # HTTP and SSL healthcheckers HTTP_GET|SSL_GET { # An url to test # can have multiple entries here url { #eg path / , or path /mrtg2/ path <STRING> # healthcheck needs status_code # or status_code and digest # Digest computed with genhash # eg digest 9b3a0c85a887a256d6939da88aabd8cd digest <STRING> # status code returned in the HTTP header # eg status_code 200. Default is any 2xx value status_code <INT> } # number of get retries nb_get_retry <INT> //访问失败后重试几次 # delay before retry // delay_before_retry <INT> //每一次超时重试之前需要等多长时间 # ======== generic connection options # Optional IP address to connect to. # The default is the realserver IP connect_ip <IP ADDRESS> //指明对哪个主机做健康状态检测 # Optional port to connect to # The default is the realserver port connect_port <PORT> //指明端口 # Optional interface to use to # originate the connection bindto <IP ADDRESS> //指在本机的哪个接口发出健康状态检测,应该是DIP所在的网卡 # Optional source port to # originate the connection from bind_port <PORT> //自己的port # Optional connection timeout in seconds. # The default is 5 seconds connect_timeout <INTEGER> # Optional fwmark to mark all outgoing # checker packets with fwmark <INTEGER> # Optional random delay to start the initial check # for maximum N seconds. # Useful to scatter multiple simultaneous # checks to the same RS. Enabled by default, with # the maximum at delay_loop. Specify 0 to disable warmup <INT> } #HTTP_GET|SSL_GET
TCP检测机制 # TCP healthchecker TCP_CHECK { # ======== generic connection options # Optional IP address to connect to. # The default is the realserver IP connect_ip <IP ADDRESS> # Optional port to connect to # The default is the realserver port connect_port <PORT> # Optional interface to use to # originate the connection bindto <IP ADDRESS> # Optional source port to # originate the connection from bind_port <PORT> # Optional connection timeout in seconds. # The default is 5 seconds connect_timeout <INTEGER> # Optional fwmark to mark all outgoing # checker packets with fwmark <INTEGER> # Optional random delay to start the initial check # for maximum N seconds. # Useful to scatter multiple simultaneous # checks to the same RS. Enabled by default, with # the maximum at delay_loop. Specify 0 to disable warmup <INT> # Retry count to make additional checks if check # of an alive server fails. Default: 1 retry <INT> # Delay in seconds before retrying. Default: 1 delay_before_retry <INT> } #TCP_CHECK
实例演示
基于DR模型,director和各real server在同一个交换机上。两台director做高可用,VIP在同一时刻只能在两台director的其中一台上。为了实现错误提时页面,需要在两台keepalived即director上都需要安装http服务,启动web服务。由于ipvs上定义了ipvs集群,所以客户端的请求都会调度到后端的real server上,一旦后端的real server都宕机,两台director可以为客户端的请求转移到自己127.0.0.1的80端口上,提供错误页面的服务。
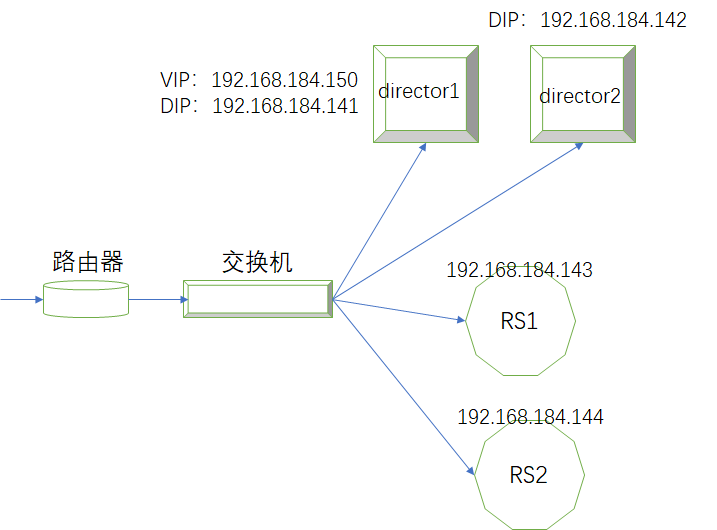
1、准备工作:彼此可以解析主机名(这里设置四台主机都可以解析,其实两台director可以解析就可以)、同时时间
# vim /etc/hosts //四台主机同时修改
192.168.184.141 node1
192.168.184.142 node2
192.168.184.143 node3
192.168.184.144 node4
# ssh-keygen //生成密码,实现免密交互
# ssh-copy-id -i /root/.ssh/id_rsa.pub root@192.168.184.142 //分发到142、143、144三台主机
# yum install ntp -y
# ntpd -u cn.pool.ntp.org 或者 #ntpdate -u cn.pool.ntp.org
# date; ssh node2 'date'; ssh node3 'date'; ssh node4 'date' //同时查看四台主机时间是否同步
Mon Dec 10 20:31:48 CST 2018
Mon Dec 10 20:31:48 CST 2018
Mon Dec 10 20:31:49 CST 2018
Mon Dec 10 20:31:49 CST 2018
2、准备两台real server,分别是192.168.184.143和192.168.184.144
# rpm -q httpd //查看两台RS是否安装httpd服务
# yum install httpd //安装
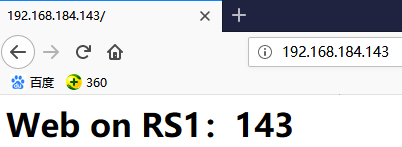
# echo "<h1>Web on RS1:143</h1>" > /var/www/html/index.html //在143主机上创建主页
# echo "<h1>Web on RS2:144</h1>" > /var/www/html/index.html //同上,在RS2

3、设置RS的arp_announce和arp_ignore,注意两台RS都要设置
# vim set.sh //两台RS都需要设置
1 #!/bin/bash 2 # 3 4 vip=192.168.184.150 5 case $1 in 6 start) 7 echo 1 > /proc/sys/net/ipv4/conf/all/arp_ignore 8 echo 1 > /proc/sys/net/ipv4/conf/eth0/arp_ignore 9 echo 2 > /proc/sys/net/ipv4/conf/all/arp_announce 10 echo 2 > /proc/sys/net/ipv4/conf/eth0/arp_announce 11 ifconfig lo:0 $vip netmask 255.255.255.255 broadcast $vip up 12 route add -host $vip dev lo:0 13 ;; 14 stop) 15 ifconfig lo:0 down 16 echo 0 > /proc/sys/net/ipv4/conf/all/arp_ignore 17 echo 0 > /proc/sys/net/ipv4/conf/eth0/arp_ignore 18 echo 0 > /proc/sys/net/ipv4/conf/all/arp_announce 19 echo 0 > /proc/sys/net/ipv4/conf/eth0/arp_announce 20 esac
# bash -x set.sh start
# ip addr list
# cat /proc/sys/net/ipv4/conf/all/arp_ignore //结果为1
# cat /proc/sys/net/ipv4/conf/all/arp_announce //结果为2
以上两台RS配置完成,下面配置两台director(手动生成vip和生成ipvs规则)
# yum install ipvsadm -y
# ip addr add 192.168.184.150/32 dev eth0 //手动添加VIP,在141上
# ip addr list

# ping 192.168.184.150 //在director2即142主机上测试新添加的VIP是否生效
在两台director上添加规则
# ipvsadm -A -t 192.168.184.150:80 -s rr
# ipvsadm -a -t 192.168.184.150:80 -r 192.168.184.143 -g -w 1
# ipvsadm -a -t 192.168.184.150:80 -r 192.168.184.144 -g -w 2
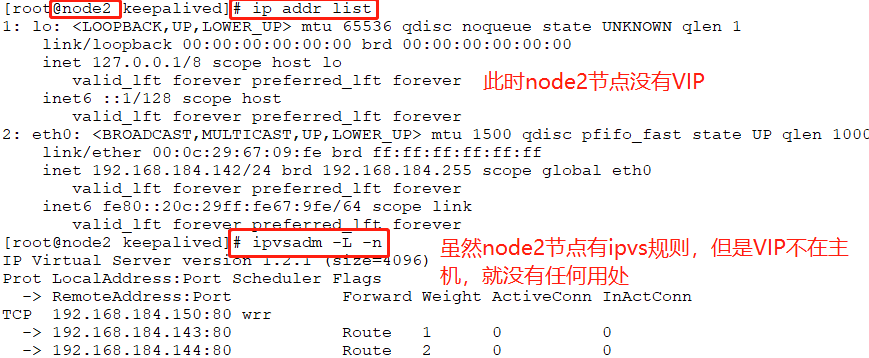
# ipvsadm -L -n


# ipvsadm -C //清空规则
# ip addr del 192.168.184.150/32 dev eth0 //删除VIP
# ip addr list //查看网络信息,如果有路由则需要删除路由
从以上测试可以知道两台director是没有问题的,主要是测试是否可以对后端两台RS做负载均衡
下面为了使两台director拥有sorry服务,做一下配置:
# yum install httpd //安装httpd服务
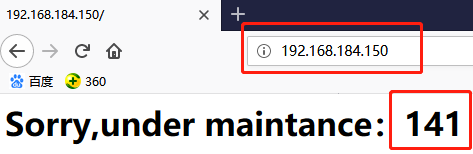
# echo "<h1>Sorry,under maintance:141</h1>" > /var/www/html/index.html
# echo "<h1>Sorry,under maintance:142</h1>" > /var/www/html/index.html //创建web页面
下面为两台director配置和使用keepalived
# yum install keepalived
# cd /etc/keepalived
# cp keepalived.conf keepalived.conf.bak
# vim keepalived.conf //注意这里用不到ipvsadm
! Configuration File for keepalived global_defs { notification_email { root@localhost //修改 } notification_email_from kaadmin@localhost //修改 smtp_server 127.0.0.1 //这里必须修改 smtp_connect_timeout 30 ... }
vrrp_script chk_mt {
script "/etc/keepalived/down.sh"
interval 1
weight -2
} vrrp_instance VI_1 { state MASTER interface eth0 virtual_router_id 51 priority 100 advert_int 1 authentication { auth_type PASS auth_pass 1111 } virtual_ipaddress { 192.168.184.150/32 //此处修改 }
track_script { //定义调用脚本
chk_mt
}
notify_master "/etc/keepalived/notify.sh master" //邮件通知
notify_backup "/etc/keepalived/notify.sh backup"
notify_fault "/etc/keepalived/notify.sh fault" }
virtual_server 192.168.200.150 80 { //根据协议+端口定义virtual_server
delay_loop 6 //检查失败时要检查几遍
lb_algo wrr
lb_kind DR //负载均衡的类型,修改
nat_mask 255.255.0.0 //这里采用规范
#persistence_timeout 50 //这里去掉,不做持久链接
protocol TCP
real_server 192.168.201.143 80 { //健康状态检测
weight 1
HTTP_GET { //这里是HTTP协议
url {
path /
status_code 200 //这里只对状态进行判断
}
#url { //可以对多个url进行检查,这里只检查一个
# path /mrtg/
# digest 9b3a0c85a887a256d6939da88aabd8cd
#}
connect_timeout 3
nb_get_retry 3
delay_before_retry 3
}
}
}
virtual_server 192.168.184.150 80 { //定义另一个real server
delay_loop 6
lb_algo wrr
lb_kind DR
net_mask 255.255.0.0
protocol TCP
real_server 192.168.184.144 80 {
weight 2
HTTP_GET {
url {
path /
status_code 200
}
connect_timeout 3
nb_get_retry 3
delay_before_retry 3
}
}
}
# vim /etc/keepalived.conf //在director2上只需作如下修改
1 vrrp_instance VI_1 { 2 state BACKUP //这里为备份 3 interface eth0 4 virtual_router_id 51 5 priority 99 //修改优先级 6 advert_int 1 7 authentication { 8 auth_type PASS 9 auth_pass 1111 10 }
....
# vim notify.sh //编写邮件通知脚本
1 #!/bin/bash 2 # 3 4 vip=172.168.184.150 5 contact='root@localhost' 6 7 notify() { 8 mailsubject="`hostname` to be $1: $vip floating" 9 mailbody="`date '+%F %H:%M:%S'`: vrrp transition, `hostname` changed to be $1" 10 echo $mailbody | mail -s "$mailsubject" $contact 11 } 12 13 case "$1" in 14 master) 15 notify master 16 exit 0 17 ;; 18 19 backup) 20 notify backup 21 exit 0 22 ;; 23 fault) 24 notify fault 25 exit 0 26 ;; 27 28 *) 29 echo 'Usage: `basename $0` {master|backup|fault}' exit 1 30 esac
# vim down.sh
# chmod +x down.sh
1 #!/bin/bash 2 # 3 4 [[ -f /etc/keepalived/down ]] && exit 1 || exit 0
以上配置就是两条director的配置
# systemctl start keepalived; ssh node2 'systemctl start keepalived'

# yum install mailx -y //安装邮件服务



此时模拟让一个后端的real server下线,比如是143下线
# systemctl stop httpd

# systemctl start httpd


上面实验可以看出使用keepalived实现了后端real server的健康状态检测;
下面启用安装在两台director上的sorry页面服务
# vim keepalived.conf
1 ... 2 virtual_server 192.168.184.150 80 { 3 delay_loop 6 4 lb_algo wrr 5 lb_kind DR 6 net_mask 255.255.0.0 7 protocol TCP 8 sorry_server 127.0.0.1 80 //添加 9 10 real_server 192.168.184.143 80 { 11 weight 1 12 ...
这里先不重启两台director,而是先把director1宕机,测试director2能不能工作
# touch down //在director1即141上创建town文件,此时VIP就漂移到director2上了

此时VIP在director2节点上,使用140节点做客户端看是否director2是否能够正常工作,对两条real server143和144做负载均衡


以上测试证明director1宕机时,director2把VIP夺过去开始对后端的real server进行负载均衡
下面把后端的两台real server全部宕机,然后在director2即142上实现sorry服务
# systemctl stop httpd //两条real sever的httpd服务器全部停掉
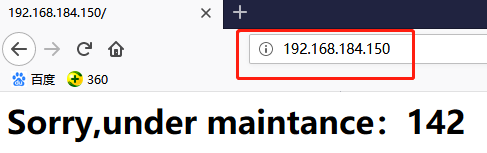
此时在浏览器中访问VIP就可以实现sorry服务了
# rm -rf down //在141即director1上删除down文件
# ip addr list //此时141已经把VIP从142上夺过来了
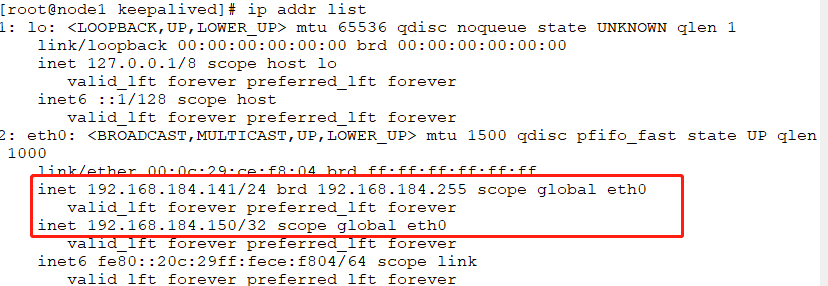
再次刷新页面,可以发现是141即director1提供的sorry服务

HA Services:
nginx
100: -25
96: -20 79 --> 99 --> 79
博客作业:
keepalived 高可用 ipvs
nginx
active/active

