网络及其计算知识要点
1.了解TCP/IP协议体系结构及每层协议的功能。
答:TCP/IP 协议体系结构有四层,分别为应用层、运输层、网际层 IP 和链路层。应用层有各种应用层协议如 DNS、HTTP、SMTP 等;运输层为 TCP 或 UDP;网际层 IP;链路层并没有具体内容。
2.传输介质
答:传输介质有双绞线、同轴电缆、光缆和无线电波。
了解频分复用、时分复用(统计时分复用)、波分复用和码分复用信道复用技术。
答:频分复用是各个用户能使用不同频率位置的信号同时进行通信;时分复用是将时间划分成等长的时分复用 TDM 帧,每个用户在一个 TDM 帧内使用一份时隙进行通信;统计时分复用则是用统计学的方法动态分配好 TDM 帧的资源,而不是像之前那样固定地将时隙分配给某个用户;波分复用就是光的频分复用,将概念转移到光纤上,用波长而不是频率来表示不同的光载波;码分复用则需要用到码片序列,在叠加的信号中区分不同基站发送的信号。
3.掌握位填充、字节填充
答:在数据链路层的点对点协议 PPP 中,PPP 帧的定界符是标志字段 F,十六进制为 0x7E,二进制为 01111110。在数据部分就要进行处理,以免误判为结束标志。如果是异步传输(逐个字符地传送)就要用到字节填充;如果是同步传输(比特流传送)就要用到零比特填充。字节填充有两条规则:7E => 7D 5E 和 7D => 7D 5D;零比特填充则是出现连续 5 个 1,就要立即填入一个 0。
掌握循环冗余校验原理(CRC)
答:循环冗余检验 CRC 是一种检错方法,冗余码 FCS 是添加在数据后面的冗余码。
假设冗余码为 n 位,发送方和接收方需要事先商定一个长度为 ( n + 1 ) 位的除数 P。
发送端:先把数据划分成组,待传送的一组数据 M,长度为 k,先在 M 后添加 n 个 0 得到 ( k + n ) 位的数据再列竖式除以除数 P,具体除法是做异或运算,得到 n 位的冗余码,加在原始数据后面则一共发送 ( k + n ) 位。
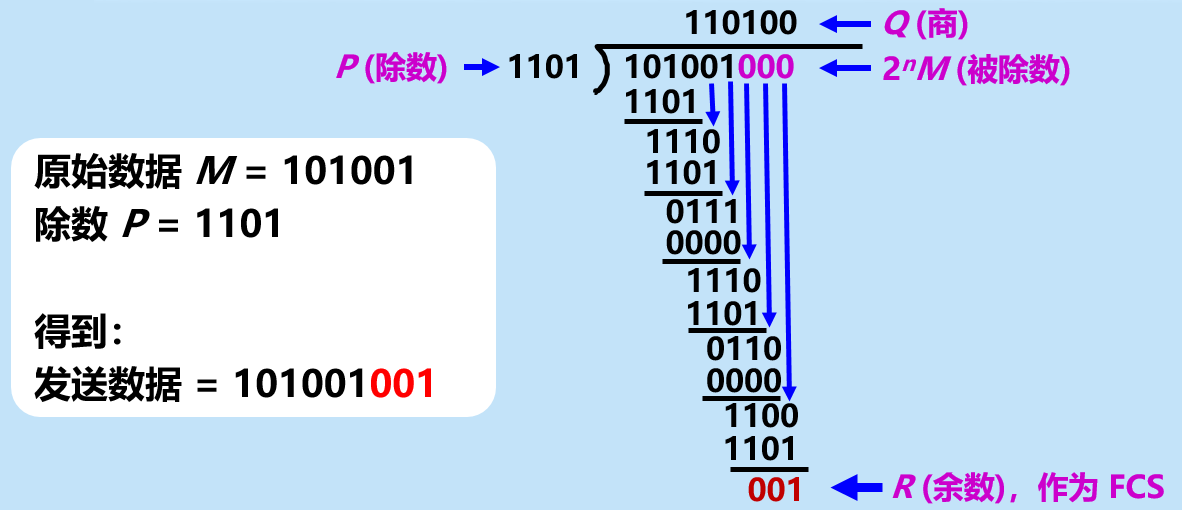
接收端:对接收到的完整数据(原始数据加上冗余码)对除数 P 做除法运算,得到的余数肯定是 0,否则传输就出现错误。
理解以太网介质控制原理(CSMA/CD协议)
答:多点接入(总线型网络)、载波监听(边发送边监听)、碰撞检测。当发生碰撞就要退避一个随机时间,r 倍争用期。因为以太网最短帧长为 64 字节,即 512 比特,对于 10 Mbit/s 以太网,发送 512 比特的时间需要 51.2 μs,也就是争用期。
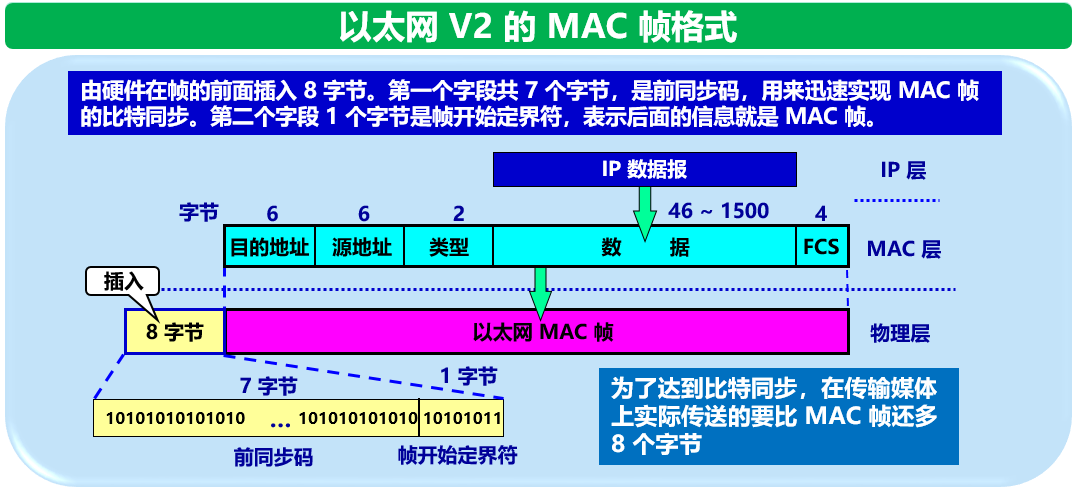
掌握以太网的帧结构(数据链路层帧结构)
答:数据部分的长度为 46 到 1500 字节之间(最短帧长 64 - 6 - 6 - 2 - 4 = 46 字节)。则有效的 MAC 帧长度为 64 到 1518 字节之间。
掌握网桥的工作原理
答:以太网是局域网,通过一台集线器将多台主机进行连接,组成一个碰撞域。如果用一台集线器将多个碰撞域进行连接,就组成了一个扩展的以太网,即一个更大的碰撞域。但是扩展以太网如果简单地用集线器将不同的碰撞域进行互连,就会因为短板效应,大家都只能工作在最低的速率。
扩展以太网人们最初使用的就是网桥,网桥的功能是转发和过滤。当网桥收到一个数据帧时,并不是向所有端口转发此帧,而是根据此帧的目的 MAC 地址和网桥中的地址表进行转发,或者把它丢弃(即过滤)。
4.掌握分类IP地址
答:在互联网发展早期使用的是分类的 IP 地址,总共有 A、B、C、D、E 五类地址,其中 A、B、C 类是单播地址,D 类是多播地址,E 类是保留地址。
IP 网络数据传输的三种方式为单播、广播和组播(多播以前被译为组播)。单播是主机间一对一的通信模式,在发送者与每一个接收者之间建立点对点连接,网络中的交换机和路由器对数据只进行转发不进行复制,如果需要给多个接收者传输相同的数据,则需要复制并发送多份相同的数据包,容易导致骨干网络出现拥塞;广播是指在 IP 子网内广播数据包,所有在子网内部的主机都将收到该数据包,不管你是否需要;组播在发送者和每一个接收者之间建立点对多连接,网络中的交换机和路由器有选择地复制并传输数据,组播源只发送一次信息,它提高了数据传送效率,减少了骨干网络出现拥塞的可能性。
五类 IP 地址都是 32 位的 IP 地址,A 类地址的网络号有 8 位,则主机号有 24 位;B 类地址的网络号有 16 位,则主机号有 16 位;C 类地址的网络号有 24 位,则主机号有 8 位。如何区分是哪类 IP 地址,每类 IP 地址网络号前面都有固定的位数,A 类为 0,B 类为 10,C 类为 110,D 类为 1110,E 类为 1111。所以每类 IP 地址可供使用的网络号都有所减少,比如 A 类地址可供使用的网络号只有 7 位,并且网络号为 00000000(全零)的 IP 地址表示本网络,网络号为 01111111 的 IP 地址保留作为本地软件回环测试,这对于 A 类地址很特殊,所以 A 类地址可供使用的网络号为 27 - 2 = 126 个,而 B 类地址可供使用的网络号就有 216 个。可供使用的主机号则所有地址都要减 2,全 0 的主机号表示“本主机”所连接到的单个网络地址,即网关地址;全 1 的主机号表示该网络上的所有主机,即广播地址。
掌握地址解析协议ARP原理
答:每一台主机都设有一个 ARP 高速缓存(ARP cache),在主机的 ARP 高速缓存表中存放一个从 IP 地址到 MAC 地址的映射表,这些都是该主机目前知道的一些 MAC 地址,并且这个映射表还经常动态更新。主机发送 ARP 请求,局域网广播,局域网中的路由器转发 ARP 请求,ARP 响应,映射表更新。
掌握子网掩码及无类编址CIDR(地址分配和子网划分)
答:地址掩码又称子网掩码,例如点分十进制的 IP 地址是 128.14.35.7/20 (CIDR 编址采用斜线记法),二进制为 10000000 00001110 00100011 00000111 / 20,则子网掩码是 11111111 11111111 11110000 00000000,做按位 AND 运算,则网络地址为 100000000 00001110 00100000 00000000。
子网划分是通过借用 IP 地址主机号的若干位来充当子网地址,从而将原网络划分为若干子网。院校得到分配的一个 CIDR 地址块后再进行子网划分。
掌握网络IP地址配置
答:根据每个网络的主机数量来分配地址块。
理解IP数据报结构
答:IP 数据报首部固定部分有 20 字节,可选字段最多有 40 字节,所以 IP 数据报首部为 20 到 60 字节。最常用的以太网规定的最大传送单元 MTU 是 1500 字节,否则就要进行分片。首部检验和只检验数据报的首部,每个 16 位序列进行反复的反码求和运算。
掌握路由表知识(给出特定网络拓扑能写出某路由器路由表)
答:前缀匹配、下一跳。
掌握路由器如何处理IP数据报(给出路由表和若干IP数据报,能够计算路由器如何转发)
答:IP 地址由网络前缀和主机号组成,路由器根据最长前缀匹配来转发给下一跳。
掌握路由选择协议RIP原理及应用、了解路由选择协议OSPF原理
答:目的网络、距离、下一跳路由器。距离 16 表示不可达。采用 UDP 进行传送。仅和相邻路由器交换路由信息,收到相邻路由器 R4 发来的路由更新信息,首先将发来的路由表的下一跳路由器全改为 R4,并且所有距离 +1,与原表进行比较,若目的网络和下一跳路由器都相同则直接用新表信息,若目的网络相同而下一跳路由器不同则看距离是否缩短来考虑是否更新,原表没有而新表有则直接插入该路由表信息。
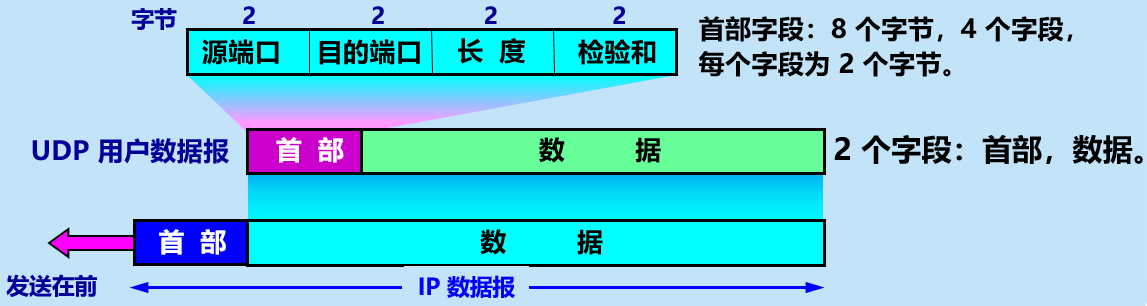
5.UDP协议:掌握协议数据结构
答:UDP 不需要建立连接,不保证可靠交付,是面向报文的,即应用层交给 UDP 多长的报文,UDP 就照样发送,也不会合并或拆分报文的边界。它只是将应用层发下来的报文添加一个 UDP 首部(只有 8 个字节)即交给下面的 IP 层。
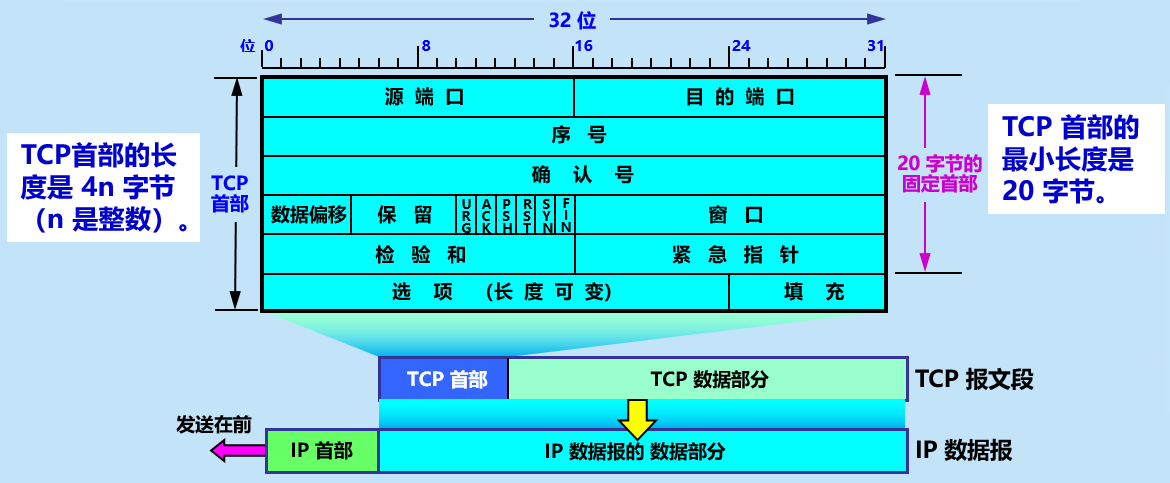
TCP协议:理解协议数据结构、
答:TCP 是面向连接的,提供可靠交付的服务,提供全双工通信,即通信双方都能发送和接收数据。TCP 有 20 字节的固定首部。详细见下图:
掌握TCP可靠传输的原理、
答:有停止等待协议和连续 ARQ 协议。停止等待协议就是接收方要对数据进行确认,发送方如果没有及时收到确认信息就会进行超时重传。连续 ARQ 协议是因为如果等分组发完后才进行确认,然后再发下一个分组的话,信道利用率太低了,于是采用滑动窗口的方式动态地对收到的信息进行确认。
了解TCP如何确定超时重传时间、
答:根据报文段的往返时间 RTT,即一个报文段从发出到收到相应的确认信息的时间之差。但这个时间并不是固定的,所以时刻需要自适应进行调整:
新的 RTTS = ( 1 - α ) * 旧的 RTTS + α * 新的 RTT 样本,( 0 ≤ α < 1)
用这种方法得出的加权平均往返时间 RTTS 就比测量出的 RTT 值更加平滑。α 的推荐值是 1 / 8 ,即 0.125。
而超时重传时间 RTO = RTTS + 4 * RTTD,RTTD 是 RTT 的偏差的加权平均值。同样需要自适应:
新的 RTTD = ( 1 - β ) * 旧的 RTTD + β * | RTTS - 新的 RTT 样本 |
β 的推荐值是 1 / 4,即 0.25。
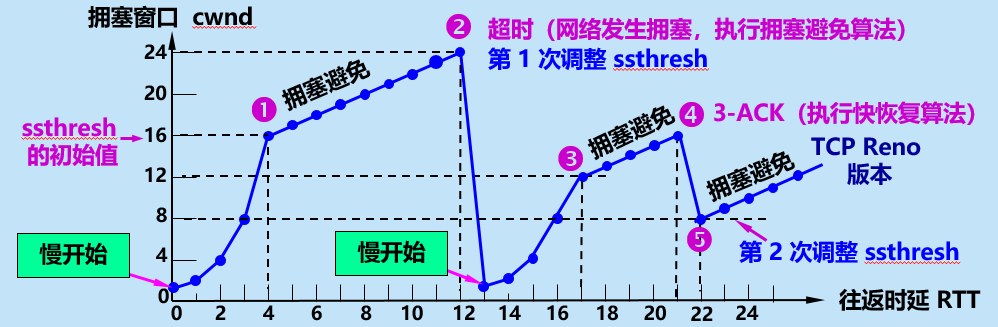
掌握TCP的拥塞控制原理、
答:TCP 进行拥塞控制的算法有四种,即慢开始、拥塞避免、快重传和快恢复。
慢开始:由小到大逐渐增大拥塞窗口 cwnd 数值。为了试探一下网络的拥塞情况。
拥塞避免:防止拥塞窗口 cwnd 增长过大引起网络拥塞,还需要设置一个慢开始门限 ssthresh。
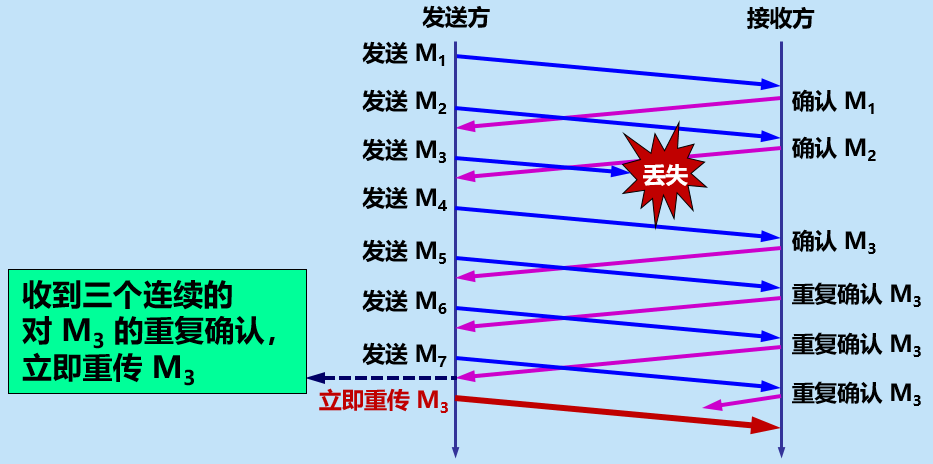
快重传:当报文丢失,接收方在收到后序报文时也要对丢失报文之前的一个报文进行重复确认,当发送方一连收到 3 个重复确认,就会知道现在并未出现网络拥塞,而是接收方少收到一个报文段,因而立即进行重传。
快恢复:发送方知道只是丢失了个别报文段,不是网络拥塞,于是不启动慢开始,而是执行快恢复算法。使 ssthresh = cwnd / 2。
了解TCP的连接建立和释放。
答:详细可参考我上篇博客三报文握手与四报文握手。
6.掌握域名解析过程
答:域名解析是需要获得域名相对应的 IP 地址。以下内容摘自我的上篇博客《计网知识的总结》
主机向本地域名服务器的查询一般都采用递归查询(recursive query)。即如果本地域名服务器不知道待查询域名的 IP 地址,那么本地域名服务器就以 DNS 客户的身份,向其他根域名服务器继续发出查询请求报文(替该主机继续查询),递归返回查询结果。
本地域名服务器向根域名服务器的查询通常采用迭代查询(iterative query)。即当根域名服务器收到本地域名服务器发来的迭代查询请求报文时,要么给出所要查询的 IP 地址,要么将自己知道的顶级域名服务器的 IP 地址告诉本地域名服务器,让它再向顶级域名服务器查询;顶级域名服务器在收到本地域名服务器的查询请求后,要么给出所要查询的 IP 地址,要么告诉本地域名服务器下一步应当向哪一个权限域名服务器进行查询,本地域名服务器就这样进行迭代查询。最后,知道了所要解析的域名的 IP 地址,然后把这个结果返回给发起查询的主机。当然,本地域名服务器也可以采用递归查询,这取决于最初的查询请求报文设置要求使用哪一种查询方式。
其中,根域名服务器是最高层次的域名服务器,所有的根域名服务器都知道所有的顶级域名服务器的域名和 IP 地址。根域名服务器是最重要的域名服务器,因为不管是哪一个本地域名服务器,要对互联网上任何一个域名进行解析,只要自己无法解析,就首先求助于根域名服务器。且根域名服务器采取任播(anycast)技术,即一组不同地点但使用相同的 IP 地址的主机,当 DNS 客户向某个根域名服务器的 IP 地址发出查询报文时,互联网上的路由器就能找到离这个 DNS 客户最近的一个根域名服务器。这样不仅加快了 DNS 的查询过程,也更合理地利用了互联网的资源。负责范围:根域名服务器 > 顶级域名服务器 > 权限域名服务器 > 本地域名服务器。
了解DNS、FTP、TELNET、HTTP、SMTP、DHCP、SNMP的作用。
答:各协议的作用如下:
53 域名系统 DNS(Domain Name System):将域名解析为 IP 地址。
21 文件传送协议 FTP(File Transfer Protocol):曾是互联网上使用得最广泛的文件传送协议,使用 TCP 可靠的运输服务。而 69 简单文件传送协议 TFTP(Trivial File Transfer Protocol)使用 UDP 数据报。他们都使用客户/服务器模式。
23 远程终端协议 TELNET :TCP 连接,客户/服务器模式,计算机进行远程控制。
80 超文本传送协议 HTTP(HyperText Transfer Protocol):TCP 连接,规定了万维网服务器与浏览器之间信息传递规范,是早期 Web 成功的有功之臣,因为它使开发和部署非常地直截了当。
25 简单邮件传送协议 SMTP(Simple Mail Transfer Protocol):仅限传送 7 位的 ASCII 码。邮件读取协议 POP3 和 IMAP。POP3 读取了邮件则直接删除,而 IMAP 则更加人性化。SMTP 有不少缺点,于是有了通用互联网邮件扩充 MIME。
36 动态主机配置协议 DHCP(Dynamic Host Configuration Protocol):即插即用联网,能动态给主机分配 IP 地址,而不需要人工进行协议配置。
161 简单网络管理协议 SNMP:网管,包括对硬件、软件和人力的使用、综合与协调,以便对网络资源进行监视、测试、配置、 分析、评价和控制,这样就能以合理的价格满足网络的一些需求,如实时运行性能、服务质量等。
了解套接字编程原理并具备初步的网络应用程序构思设计能力。
答:客户/服务器模式,套接字 Socket =(IP 地址:端口号)。
7. 了解对称和非对称秘钥密码体制,理解通过对称和非对称加密实现数据的机密性、数字签名、不可否认、数据完整性、鉴别(端点鉴别和报文鉴别)概念和作用,达到针对特定的网络通信模型能准确理解其作用并能简要说明理由。
答:对称密钥密码体制的加密密钥和解密密钥是相同的,通信双方使用的就是对称密钥,密钥需要保密,有 DES、3DES、AES;非对称密钥密码体制又称公钥密码体制,即加密密钥和解密密钥是不同的,加密密钥叫公钥 PK 是公开的,解密密钥叫私钥 SK 需要保密,加密算法 E 和解密算法 D 都是公开的,有 RSA。
其中加密运算 E 和解密运算 D 并不一定是用于加密或解密,只是一种对报文的运算。比如数字签名,就需要让信息发送方用私钥先对报文进行 D 运算,再将密文发送出去,接收方通过公钥和 E 运算还原出报文,就能核实报文的身份,可以看出,数字签名的通信方式并非为了保密,而是为了进行签名和核实签名。因为除了信息发送方,没人拥有私钥可以产生这个密文,否则接收方解密出来的报文将不可读。这也导致发送方不可否认这是自己发出的信息。
数据完整性与密码散列函数有关,MD5 是代表算法,改变一个字符,得到的报文摘要则完全不同,不可通过报文摘要逆向变换为原始报文。数据完整性需要保证接收者接收到的数据与发送者发出的数据完全一样。
鉴别的内容有二,一是鉴别发信人,而不是冒充者,这就是实体鉴别,或端点鉴别;二是鉴别报文的完整性,即报文不能被人篡改过。
用报文鉴别码实现报文鉴别:如果将报文使用散列函数,如将 MD5 计算后的报文摘要直接拼接在报文后面,发送给接收方,可以实现报文的完整性鉴别,但容易被伪造者做手脚。可以约定一个只有通信双方知道的对称密钥,发送方将密钥拼接到报文后进行散列函数计算,得到的结果叫做报文鉴别码 MAC,将其拼接到原始报文后面,再发送给接收方;接收方收到扩展的报文后,将报文鉴别码 MAC 与报文分开,用同样的密钥拼接在报文后进行散列函数计算,将计算结果与报文鉴别码 MAC 进行比较,若相同,则既能保证实体鉴别,又能保证报文的完整性。不仅是不可伪造的,也是不可否认的。
报文鉴别是对每一个收到的报文都要鉴别报文的发送者,而实体鉴别是在通信期间只需验证一次。
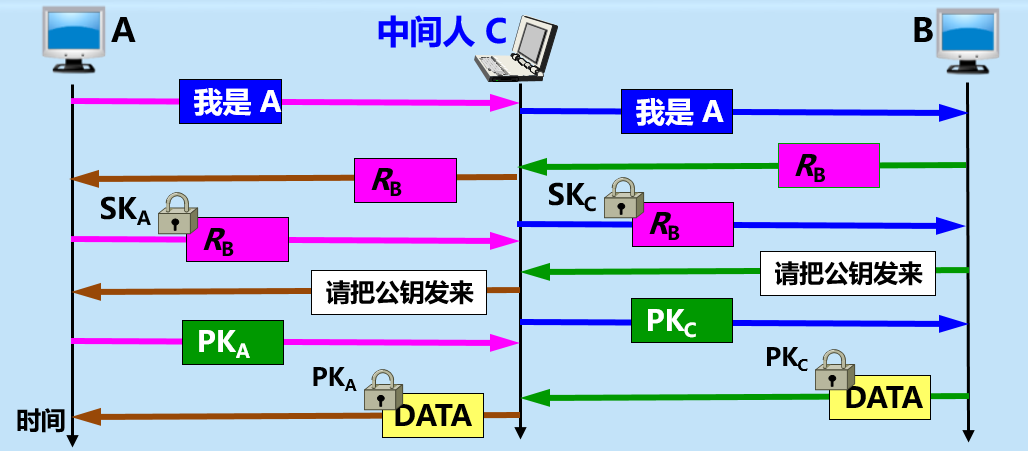
实体鉴别有个高明的欺骗手段“中间人攻击”。



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· Linux系列:如何用 C#调用 C方法造成内存泄露
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 单元测试从入门到精通
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 上周热点回顾(3.3-3.9)
· winform 绘制太阳,地球,月球 运作规律