
Python 面向对象程序设计
Python 面向对象程序设计

1 面向过程编程
面向过程——Procedure Oriented,是一种以过程为中心的编程思想,它首先分析出解决问题所需要的步骤,然后用函数把这些步骤一步一步实现,在使用时依次调用,是一种基础的顺序的思维方式。面向过程开发方式是对计算机底层结构的一层抽象,它将程序分为数据和操纵数据的操作两部分,其核心问题是数据结构和算法的开发和优化。
最典型的就是流水线,上一道工序完成后,后面的流程才能进行。
-
面过程编程的特点:
功能模块化,代码流程化
-
优点:
性能高,适合资源紧张、实时性强的场合
-
缺点:
不易复用和不易扩展
2 面向对象编程
面向对象编程——Object Oriented Programming,简称OOP,是一种程序设计思想。OOP把对象作为程序的基本单元,一个对象包含了数据和操作数据的函数。
面向对象的程序设计把计算机程序视为一组对象的集合,而每个对象都可以接收其他对象发过来的消息,并处理这些消息,计算机程序的执行就是一系列消息在各个对象之间传递。
在Python中,所有数据类型都可以视为对象,当然也可以自定义对象。自定义的对象数据类型就是面向对象中的类(Class)的概念。
3. 面向过程和面向对象的优缺点
| 面向对象 | 面向过程 | |
|---|---|---|
| 特性 | 抽象、继承、封装、多态 | 功能模块化,代码流程化 |
| 优点 | 易维护、易复用、易扩展、低耦合 | 性能高,适合资源紧张、实时性强的场合 |
| 缺点 | 性能比面向过程低 | 没有面向对象易维护、易复用、易扩展 |
4. 由浅入深了解面向对象之---封装
4.1 学生选课为例
"""
1, 要定义学生的信息: 姓名,性别,年龄,学校,所选课程
"""
# 学生的特征:
student_name = 'Hans'
student_gender = 'M'
student_age = 20
shool = '社会大学'
student_course = []
# 学生的功能:选课
def course_selection_system(name, gender, age, shool, course):
student_course.append(course)
print("学生:%s 性别:%s 年龄:%s 在%s 期间所选课程:%s" % (name, gender, age, shool, student_course))
# 执行结果:
course_selection_system(student_name, student_gender, student_age, shool, "如何接受社会的毒打")
学生:Hans 性别:M 年龄:20 在社会大学 期间所选课程:['如何接受社会的毒打']
"""
2, 把学生的信息定义成一个字典
"""
student1 = {
'student_name': 'Hans',
'student_gender': 'M',
'student_age': 20,
'shool':'社会大学',
'student_course':[]
}
def course_selection_system(student, course):
student1['student_course'].append(course)
print("学生:%s 性别:%s 年龄:%s 在%s 期间所选课程:%s" % (student['student_name'], student['student_gender'], \
student['student_age'], student['shool'], student['student_course']))
#执行结果:
course_selection_system(student1, "如何接受社会的毒打")
学生:Hans 性别:M 年龄:20 在社会大学 期间所选课程:['如何接受社会的毒打']
"""
3, 把选课的函数放到字典里, 某个学生要选课成功,里面要包括他的特征和技能,
这样一个学生他的特征和功能都有了
"""
def course_selection_system(student, course):
student1['student_course'].append(course)
print("学生:%s 性别:%s 年龄:%s 在%s 期间所选课程:%s" % (student['student_name'], student['student_gender'], \
student['student_age'], student['shool'], student['student_course']))
student1 = {
'student_name': 'Hans',
'student_gender': 'M',
'student_age': 20,
'shool':'社会大学',
'student_course':[],
'course_select':course_selection_system
}
student2 = {
'student_name': 'Jack',
'student_gender': 'M',
'student_age': 20,
'shool':'社会大学',
'student_course':[],
'course_select':course_selection_system
}
student1['course_select'](student1, "五块钱如何花一星期")
student2['course_select'](student2, "如何接受社会的毒打")
#执行结果:
学生:Hans 性别:M 年龄:20 在社会大学 期间所选课程:['五块钱如何花一星期']
学生:Jack 性别:M 年龄:20 在社会大学 期间所选课程:['如何接受社会的毒打'
# 这是一两个学生,如果是十个,百个或更多都要手写一遍???
# 这时就需要面向对象了。
"""
对象是什么
1. 程序中:
函数:盛放数据的容器
对象:盛放数据和函数的容器
2. 现实生活中:
一切皆对象
对象:特征与技能的结合体
"""
4.2 类和对象
"""
对象: 特征与技能的结合体
类:一系列对象相似的特征与相似的技能的结合体
站在不同的分类,划分的分类不一定一样
在程序中先有类再有对象。现实中先有对象,再有类
"""
# 把上面的程序 相同的部分拿出来,
student1 = {
'student_name': 'Hans',
'student_gender': 'M',
'student_age': 20,
'shool':'社会大学',
'student_course':[],
'course_select':course_selection_system
}
student2 = {
'student_name': 'Jack',
'student_gender': 'M',
'student_age': 20,
'shool':'社会大学',
'student_course':[],
'course_select':course_selection_system
}
"""
这个程序中有哪些是相同的:
学校(shool)和选课功能(course_selection_system)
可以把这两个功能提取出来
"""
student_public = {
'shool':'社会大学',
'course_select':course_selection_system
}
# 这个提取出来的公共的功能就是类,但在python中写有专业的写法:
class 类名():
pass
# class为关键字
# 类名一般首字母大写
# 代码:
class student_public():
shool = '社会大学'
def course_selection_system(student, course):
student1['student_course'].append(course)
print("学生:%s 性别:%s 年龄:%s 在%s 期间所选课程:%s" % (student['student_name'], student['student_gender'], \
student['student_age'], student['shool'], student['student_course']))
# 类在定义的时候会执行,这是与函数不同的地方(函数在定义时不会执行,只有在调用时执行)
# 查看类的名称空间:
print(student_public.__dict__)
{'__module__': '__main__', 'shool': '社会大学', 'course_selection_system': <function student_public.course_selection_system at 0x000002ADBB6AA5F0>, '__dict__': <attribute '__dict__' of 'student_public' objects>, '__weakref__': <attribute '__weakref__' of 'student_public' objects>, '__doc__': None}
# 类的底层为字典
"""
类在定义时做了哪些:
1. 类在定义时会立即执行
2. 产生一个类的名称空间,然后把类体里执行的数据都放到名称空间里(__dict__返回的字典里)
3. 把类的名称空间绑定给__dict__
变量放到类里面叫属性
函数放到类里面叫方法
"""
# 调用类
stu = student_public()
# 调用类从而产生对象。
# 调用类从而产生对象的过程,叫类的初始化
#查看对象的名称空间
print(stu.__dict__)
# 执行结果:
{} # 一个空字典
# 现在用Python的语法把类定义出来了。
# 但是学生自己独有的特征还没有(自己的名字,自己的年龄等等),刚才看到了为空
# 给对象添加自己独有的特征
stu.__dict__['name'] = 'Hans'
stu.__dict__['gender'] = 'M'
stu.__dict__['age'] = 20
stu.__dict__['course'] = ['五块钱如何花一星期','如何接受社会毒打']
print(stu.__dict__)
# 执行结果:
{'name': 'Hans', 'gender': 'M', 'age': 20, 'course': ['五块钱如何花一星期', '如何接受社会毒打']}
# 对象的名称空间为一个空字典,现在添加了一些key,所以也可以对它进行取值
print(stu.__dict__['name'])
Hans
#在Python中一般不使用这种方法赋值和取值,Python中的方法
# 添加
stu.name = 'Hans'
stu.gender = 'M'
stu.age = 20
stu.course = ['五块钱如何花一星期','如何接受社会毒打']
# 取值
print(stu.__dict__)
print(stu.name)
# 执行结果:
{'name': 'Hans', 'gender': 'M', 'age': 20, 'course': ['五块钱如何花一星期', '如何接受社会毒打']}
Hans
# 这种方法只能在对象种使用
# 上面的方法依然是很个学生对象都要写一遍,所以这个方法也可以做成函数形式。
# 1. 定义一个类
class student_public():
shool = '社会大学'
def course_selection_system(student, course):
student['student_course'].append(course)
print("学生:%s 性别:%s 年龄:%s 在%s 期间所选课程:%s" % (student['student_name'], student['student_gender'], \
student['student_age'], student['shool'], student['student_course']))
#
# 实例化对象
stu1 = student_public()
# 定义函数
def init(name,gender,age,course):
stu1.name = name
stu1.gender = gender
stu1.age = age
stu1.course = course
init('hans', 'M',20,['五块钱如何花一星期','如何接受社会毒打'])
print(stu1.__dict__)
# 执行结果:
{'name': 'hans', 'gender': 'M', 'age': 20, 'course': ['五块钱如何花一星期', '如何接受社会毒打']}
# init()函数中stu1为固定值,如果初始化一个学生,这个函数就不满足了,所以stu1的位置也要传参获得
def init(student,name,gender,age,course):
student.name = name
student.gender = gender
student.age = age
student.course = course
stu1 = student_public()
stu2 = student_public()
init(stu1,'hans', 'M',20,['五块钱如何花一星期','如何接受社会毒打'])
init(stu2,'jack', 'M',18,['五块钱如何花一星期','如何接受社会毒打'])
print(stu1.__dict__)
print(stu2.__dict__)
# 执行结果:
{'name': 'hans', 'gender': 'M', 'age': 20, 'course': ['五块钱如何花一星期', '如何接受社会毒打']}
{'name': 'jack', 'gender': 'M', 'age': 18, 'course': ['五块钱如何花一星期', '如何接受社会毒打']}
# 这样比较相对比较完美了,但是每次都要手动调用init()这个方法,有没有什么方法可以自动执行init()
# 可以把它写入到类里面,不过要变形
class student_public():
def __init__(student, name, gender, age, course):
student.name = name
student.gender = gender
student.age = age
student.course = course
shool = '社会大学'
def course_selection_system(student, course):
student['student_course'].append(course)
print("学生:%s 性别:%s 年龄:%s 在%s 期间所选课程:%s" % (student['student_name'], student['student_gender'], \
student['student_age'], student['shool'], student['student_course']))
print(student_public.__dict__)
stu1 = student_public()
# 执行结果:
TypeError: student_public.__init__() missing 4 required positional arguments: 'name', 'gender', 'age', and 'course'
# 提示要四个参数,现在给它传四个参数:
stu1 = student_public('hans', 'M',20,['五块钱如何花一星期','如何接受社会毒打'])
print(stu1.__dict__)
# 现在执行不会报错
{'name': 'hans', 'gender': 'M', 'age': 20, 'course': ['五块钱如何花一星期', '如何接受社会毒打']}
# __init__()上面写了五个参数,但是对象在调用的时候只让写四个,因为使用对象调用它会把自己当成第一个参数传递给函数。
# 在类中的方法,类和对象都可以调用,但是类在调用的时候,里面写了几个参数就要传几个参数,但是使用对象时它把自己当成第一个参数传过去,所以推荐使用对象调用
# Python中,因为方法中第一个参数为自己,所以把这个写成self
class student_public():
def __init__(self, name, gender, age, course):
self.name = name
self.gender = gender
self.age = age
self.course = course
shool = '社会大学'
def course_selection_system(self, course):
self['student_course'].append(course)
print("学生:%s 性别:%s 年龄:%s 在%s 期间所选课程:%s" % (self['student_name'], self['student_gender'], \
self['student_age'], self['shool'], self['student_course']))
# 执行:
stu1 = student_public('hans', 'M', 20, '五块钱如何花一星期') # 实例化对象
print(stu1.__dict__)
{'name': 'hans', 'gender': 'M', 'age': 20, 'course': '五块钱如何花一星期'}
# 判断一个
print(isinstance(stu1, student_public))
True
"""
调用类:
1. 调用类(stu1 = student_public())会得到一个空对象,把这个空对象传给student_public.__dict__
2. 调用student_public.__dict__(空对象,'hans', 'M',20,'五块钱如何花一星期')
3. 得到一个初始化结果
4. 在__init__里不能使用return 返回值,如果真要使用也只能返回None
"""
4.3 属性的查找顺序
类属性(在类中定义的):
# 1, 查看类属性
class student_public():
def __init__(student, name, gender, age, course):
student.name = name
student.gender = gender
student.age = age
student.course = course
shool = '社会大学'
stu1 = student_public('hans', 'M',20,'五块钱如何花一星期')
print(stu1.shool)
# 2, 增加一个类属性
stu1.country = 'CN'
print(stu1.__dict__)
{'name': 'hans', 'gender': 'M', 'age': 20, 'course': '五块钱如何花一星期', 'country': 'CN'}
# 3, 修改类属性
stu1.shool = '清华大学'
print(stu1.shool)
清华大学
# 4, 修改类属性
del stu1.shool
对象属性
class student_public():
def __init__(student, name, gender, age, course):
student.name = name
student.gender = gender
student.age = age
student.course = course
shool = '社会大学'
stu1 = student_public('hans', 'M',20,'五块钱如何花一星期')
# 1, 查看
print(stu1.name)
print(stu1.gender)
print(stu1.age)
hans
M
20
# 2, 修改
stu1.age = 18
print(stu1.age)
18
# 3,增加
stu1.result = '优'
print(stu1.__dict__)
{'name': 'hans', 'gender': 'M', 'age': 18, 'course': '五块钱如何花一星期', 'country': 'CN', 'result': '优'}
# 4, 删除
del stu1.result
print(stu1.__dict__)
{'name': 'hans', 'gender': 'M', 'age': 18, 'course': '五块钱如何花一星期', 'country': 'CN'}
属性查找顺序
1. 先在对象中查找,如果对象中没有则去类中查找
class student_public():
def __init__(self, name, gender, age, course):
self.name = name
self.gender = gender
self.age = age
self.course = course
shool = '社会大学'
print(stu1.shool) # 这个shool为类中定义的
社会大学
print(stu1.__dict__['shool']) # 这个会报错,因为在对象stu1中根本没有shool这个属性,shool这个是类的属性,直接这么取是拿不到的,因为指定从对象stu1中的名称空间中取,对象stu1中的名称空间中根本没有。
#所以使用点(.)的方式,如果对象中的名称空间中没有,它会去类的名称空间中找。
class student_public():
def __init__(self, name, gender, age, course):
self.name = name
self.gender = gender
self.age = age
self.shool = "清华大学"
self.course = course
shool = '社会大学'
print(stu1.shool) # 这个shool为对象中定义的
清华大学
5. 面向对象绑定方法
5.1 小案例:计算一共产生了多少个对象
class Count():
count = 0
def __init__(self, name):
self.name = name
Count.count +=1 # 统计次数
s1 = Count('Hello')
s2 = Count('World')
print(Count.count)
# 执行结果:
2
# 类属性修改,所有对象都改。
# 还有一种写法:
class Count():
count = 0
def __init__(self, name):
self.name = name
self.__class__.count +=1 # 统计次数 和Count.count +=1 一样
s1 = Count('Hello')
s2 = Count('World')
print(Count.count)
5.2 绑定方法
绑定方法有两种:
-
绑定给对象
class Students(): def __init__(self,name, age, gender): self.name = name self.age = age self.gender = gender def printInfo(self): print("%s %s %s" % (self.name, self.age, self.gender)) stu = Students("Hans", 18, 'M') stu.printInfo() # 把printInfo方法绑定给对象stu -
绑定给类
IP = '192.168.1.123' PORT = 3306 class Mysql(): def __init__(self, ip, port): self.ip = ip self.port = port mysql = Mysql(IP, PORT) print(mysql.ip,mysql.port) # 执行结果: 192.168.1.123 3306 # 如果有多个需要写多次。能不能把Mysql(IP, PORT)这个只写一次 # 可以把这个放到一个函数里 IP = '192.168.1.123' PORT = 3306 class Mysql(): def __init__(self, ip, port): self.ip = ip self.port = port def tell(self): mysql = Mysql(IP, PORT) return mysql obj = Mysql(IP, PORT) obj1 = obj.tell() print(obj1.ip,obj1.port) # 写到函数里后,又有一个问题,mysql = Mysql(IP, PORT)现在是写的MySQL的,如果换别的数据库如redis,pg等是不是就不那么灵活了。 class Database(): def __init__(self, ip, port): self.ip = ip self.port = port @classmethod def tell(cls): obj = cls(IP, PORT) return obj mysql = Database.tell() print(mysql.ip, mysql.port) # 换个IP和端口 IP = '192.168.1.111' PORT = 6379 redis = Database.tell() print(redis.ip, redis.port) # 执行结果: 192.168.1.123 3306 192.168.1.111 6379 # @classmethod 这个装饰器绑定给了类,以后类来调用,会自动把类名当成第一个参数传过来(cls) # 这时调用的时候,使用类名调用 # 如果即用到绑定对象,又用到绑定类,推荐使用绑定对象,因为在对象中可以使用__class__拿到类
5.3 静态方法(非绑定方法)
import random
class Students():
def __init__(self,name,age):
self.name = name
self.age = age
def randnum(self):
print(random.randint(1, 10))
info = Students("Hans", 18)
info.randnum()
info.randnum()
# 执行结果:
1
4
# 在 def randnum(self) 中根本没有用到self,是不是可以不传?
# 现在在类中如果不传就会报错(TypeError: Students.randnum() takes 0 positional arguments but 1 was given),所以可以使用 @staticmethod
import random
class Students():
def __init__(self,name,age):
self.name = name
self.age = age
@staticmethod
def randnum():
print(random.randint(1, 10))
info = Students("Hans", 18)
info.randnum()
info.randnum()
# 执行结果:
4
9
6. 隐藏属性
为什么要隐藏属性?
有些时间有些数据,只想让内部看到,不想让外部看到。
如何隐藏属性
class Students():
shool = '社会大学'
def __init__(self,name,age):
self.name = name
self.age = age
stu1 = Students("Hans", 18)
print(stu1.shool)
#shool是可以拿到的,如何把shool属性隐藏掉
class Students():
__shool = '社会大学' # 只需要在属性前面加两个下划线(__),只在前面加
def __init__(self,name,age):
self.name = name
self.age = age
stu1 = Students("Hans", 18)
print(stu1.shool)
# 执行结果:
AttributeError: 'Students' object has no attribute 'shool'
print(stu1.__shool)
# 执行结果:
AttributeError: 'Students' object has no attribute '__shool'
# 就会发现shool这个不管用什么方法都访问不到了。
# 可以看一下它变成了什么?
print(Students.__dict__)
{'__module__': '__main__', '_Students__shool': '社会大学', '__init__': <function Students.__init__ at 0x000001E5EC31A0E0>, '__dict__': <attribute '__dict__' of 'Students' objects>, '__weakref__': <attribute '__weakref__' of 'Students' objects>, '__doc__': None}
# 可以看到shool前面加了双下划线(__)后就变成: _Students__shool(_类名__属性名)
# 现在在外面拿不到了,在内部是否可以拿到?
class Students():
__shool = '社会大学'
def __init__(self,name,age):
self.name = name
self.age = age
def get_shool(self):
return self.__shool
stu1 = Students("Hans", 18)
print(stu1.get_shool())
# 执行结果:
社会大学
# 可以看到在内部可以拿到
# 其实如果外部要拿也能拿到:
stu1 = Students("Hans", 18)
print(stu1._Students__shool) # 因为在类的名称空间为_Students__shool,所以直接取这个就可以拿到
print(Students._Students__shool)
# 不但可以隐藏类中的属性也可以隐藏方法和对象中的属性,写法都一样,使用双下划线
# 对象属性:
self.__name
#类中的方法:
def __get_shool(self):
#
# 在外部有方法拿到隐藏的属性,是不是也可以修改? 正常的方法是改不了,可以在类中定义一个专门修改的函数
class Students():
__shool = '社会大学'
def __init__(self,name,age):
self.name = name
self.age = age
def get_shool(self):
return self.__shool
def set_shool(self):
self.__shool = "清华大学"
stu1 = Students("Hans", 18)
stu1.set_shool()
print(stu1.get_shool())
# 执行结果:
清华大学
# 更好的方法是给set_shool传值
class Students():
__shool = '社会大学'
def __init__(self,name,age):
self.name = name
self.age = age
def get_shool(self):
return self.__shool
def set_shool(self,shoolname):
self.__shool = shoolname
stu1 = Students("Hans", 18)
stu1.set_shool("北京大学")
print(stu1.get_shool())
# 执行结果:
北京大学
# 还可以对修改的内容进行判断,现在要修改的是学校名字,按目前写的传什么值都可以,但有些类型不合适用在这个地方比如int类型,所以可以判断一下。
class Students():
__shool = '社会大学'
def __init__(self,name,age):
self.name = name
self.age = age
def get_shool(self):
return self.__shool
def set_shool(self,shoolname):
# if type(shoolname) is not str: return
if not isinstance(shoolname, str): return
self.__shool = shoolname
stu1 = Students("Hans", 18)
stu1.set_shool(123) # 123 不是字符串,直接return返回,所以shool的值还是原来的
print(stu1.get_shool())
# 执行结果:
社会大学
"""
隐藏属性发生了什么?
1, 在类定义阶段发生了变化,如__shool变成了_Students__shool,也只有在定义阶段发生变化,其他地方都不会发生变化
2, 隐藏对外不对内
"""

7. property装饰器
property是python的一种装饰器,是用来修饰方法的。
上面的例子我们把一些不想对外公开的属性隐蔽起来,而只是提供方法给用户操作(查看get_shool和设置set_shool),在方法里面,我们可以检查参数的合理性等。
class Students():
__shool = '社会大学'
def __init__(self,name,age):
self.__name = name
self.age = age
def get_name(self):
return self.__name
def set_name(self):
self.__name="ABC"
stu = Students("Hans", 18)
print(stu.get_name())
stu.set_name()
print(stu.get_name())
# 执行结果:
Hans
ABC
# 我们要得到name必须要调用get_name方法,但正常我们取一个属性直接使用.加属性名就可以(stu.name),
# 但现在还要调用一个方法,如何实现即要隐藏属性又要使用.属性获得值,就可以使用@property
class Students():
__shool = '社会大学'
def __init__(self,name,age):
self.__name = name
self.age = age
@property
def name(self): # 为了更像stu.name这种方法,把方法名直接改为name
return self.__name
stu = Students("Hans", 18)
print(stu.name)
# 执行结果:
Hans
# @property 装饰器会将 name() 方法转化为一个具有相同名称的只读属性的 "getter"
# 在修改的时候也要像查询一样,直接使得.属性的方式
class Students():
__shool = '社会大学'
def __init__(self,name,age):
self.__name = name
self.age = age
@property
def name(self):
return self.__name
@name.setter
def name(self,name):
if not isinstance(name, str):
print("必须为字符串")
return
self.__name= name
stu = Students("Hans", 18)
print(stu.name) # Hans
stu.name = 123 # 必须为字符串,执行到了isinstance
print(stu.name) # Hans
# 修改为一个合法类型:
stu = Students("Hans", 18)
print(stu.name) # Hans
stu.name = "XYZ"
print(stu.name) # XYZ
# 可以看到已经修改
# 要使用这种方法,在定义时:
"""
@property
def name(self): 1
return self.__name
@name.setter 2
def name(self,xxx) 3
这三个地方的名字一定要一致。
"""
# 删除一个属性
class Students():
__shool = '社会大学'
def __init__(self,name,age):
self.__name = name
self.age = age
@property
def name(self):
return self.__name
@name.setter
def name(self,name):
if not isinstance(name, str):
print("必须为字符串")
return
self.__name= name
@name.deleter
def name(self):
del self.__name
print("正在删除%s" % self.__name)
stu = Students("Hans", 18)
del stu.name
print(stu.name)
# 执行结果:
正在删除Hans
# 还有一种写法,现在已经不常用了,即定义一个托管属性
class Students():
__shool = '社会大学'
def __init__(self,name,age):
self.__name = name
self.age = age
def get_name(self):
return self.__name
def set_name(self,name):
if not isinstance(name, str):
print("必须为字符串")
return
self.__name= name
def del_name(self):
print("正在删除%s" % self.__name)
# 定义一个托管属性
name = property(get_name, set_name, del_name)
stu = Students("Hans", 18)
print(stu.name) # 调用get_name 方法
stu.name = "XYZ" # 调用set_name 方法
print(stu.name)
del stu.name # 调用del_name 方法
# 执行结果:
Hans
XYZ
正在删除XYZ
property就是把方法伪装成属性
property详细请看官网:
8. 由浅入深了解面向对象之---继承
8.1 什么是继承
继承就是新建类的一种方式,新建的类我们称为子类或者叫派生类,被继承的类我们称为父类或者基类
子类可以使用父类中的属性和方法
8.2 为什么要继承
- 类解决了对象与对象之间的代码冗余问题
- 继承解决的是类与类之间的代码冗余问题
子类 继承自 父类,可以直接 享受 父类中已经封装好的方法,不需要再次开发
8.3 类的继承
由于Python有两个主要版本即2.x和3.x版本,所以类又分为经典类和新式类。
-
Python2.x中使用的是经典类。
-
Python3.x中使用的是新式类。
在Python2中要使用新式类写法:
class 类名(object)
经典类和新式类的区别就在于是否继承了object,新式类中默认都继承了object,而经典类则没有继承object。
# 继承语法:
class sub(父类名):
pass
# 学生选课,老师打分
#学生类
class Students():
shool = '社会大学'
def __init__(self, name, age, gender, course):
self.name = name
self.age = age
self.gender = gender
self.course = course
def select_course(self, course):
self.course = course
print("在%s,%s选课成功,课程为:<<%s>>" % (self.shool, self.name, course))
#教师类
class Teachers():
shool = '社会大学'
def __init__(self, name, age, gender, level):
self.name = name
self.age = age
self.gender = gender
self.level = level
def score(self, stu_obj, score):
stu_obj.score = score # 给学生打分
print('教师%s就<<%s>>课程给%s打了%s分' % (self.name, stu_obj.course, stu_obj.name, score))
#学生类实例化
stu1 = Students('Hans', 18, 'M', "如何讨富婆欢心")
stu1.select_course(stu1.course)
# 教师类实例化
teach1 = Teachers("Jack", 40, 'M', '中级')
teach1.score(stu1, 70)
# 执行结果:
在社会大学,Hans选课成功,课程为:<<如何讨富婆欢心>>
教师Jack就<<如何讨富婆欢心>>课程给Hans打了70分
# 就上面的问题,有些内容是冗余的,把这些冗余的可以写一个公共的类,然后学生类和教师类去继承
# 把相同的部分都提取出来,放到这个公共类里,这个类就是Students和Teachers的父类
class Person():
shool = '社会大学'
def __init__(self, name, age, gender):
self.name = name
self.age = age
self.gender = gender
class Students(Person):
def __init__(self, name, age, gender, course):
self.course = course
Person.__init__(self, name, age, gender)
def select_course(self, course):
self.course = course
print("在%s,%s选课成功,课程为:<<%s>>" % (self.shool, self.name, course))
class Teachers(Person):
def __init__(self, name, age, gender, level):
self.level = level
Person.__init__(self, name, age, gender)
def score(self, stu_obj, score):
stu_obj.score = score # 给学生打分
print('教师%s就<<%s>>课程给%s打了%s分' % (self.name, stu_obj.course, stu_obj.name, score))
stu1 = Students('Hans', 18, 'M', "如何讨富婆欢心")
stu1.select_course(stu1.course)
teach1 = Teachers("Jack", 40, 'M', '中级')
teach1.score(stu1, 70)
注意: 继承查找中找到一个就结束
8.3.1 单继承属性查找
# 上面的例子中Students中是没有shool这个属性的,这个已经放到父类Person中了,但在执行的时候并没有报错
class Students(Person):
def __init__(self, name, age, gender, course):
self.course = course
Person.__init__(self, name, age, gender)
def select_course(self, course):
self.course = course
print("在%s,%s选课成功,课程为:<<%s>>" % (self.shool, self.name, course))
# self.shool,self.name都在Person类中
#
# 类有继承,在查找属性时如果自己的名称空间中没有找到,则去继承的父类中查找
# 练习1:
class Foo():
def f1(self):
print("from Foo.f1")
def f2(self):
print("from Foo.f2")
self.f1()
class Bar(Foo):
def f1(self):
print("from Bar.f1")
test = Bar()
test.f2() #打印结果
###结果:###
from Foo.f2
from Bar.f1
"""
分析:
test为Bar实例化出来的,Bar中并没有f2(),所以会去它继承的Foo中去找,Foo中有f2,f2中执行self.f1(),Bar实例化时会给Bar传个空对象即test,在类中为self,所以self.f1()为test.f1().
"""
# 练习2:
class Foo():
def __f1(self): # _Foo__f1()
print("from Foo.f1")
def f2(self):
print("from Foo.f2")
self.__f1() # _Foo__f1()
class Bar(Foo):
def __f1(self): # _Foo__f1()
print("from Bar.f1")
test = Bar()
test.f2()
###结果:###
from Foo.f2
from Foo.f1
"""
分析:
test为Bar实例化出来的,Bar中并没有f2(),所以会去它继承的Foo中去找,Foo中有f2,f2执行self.__f1(),__f1()为隐藏方法,__f1()其实是: _类名__f1(), 因为是在Foo类中所以它是:_Foo__f1()
所以执行结果为from Foo.f1
"""
8.3.2 多重继承属性查找
有些语言是不支持多重继承的,但是Python是支持多继承的,子类 可以拥有 多个父类,并且具有 所有父类 的 属性 和 方法。
语法:
class 子类名(父类名1, 父类名2...)
pass
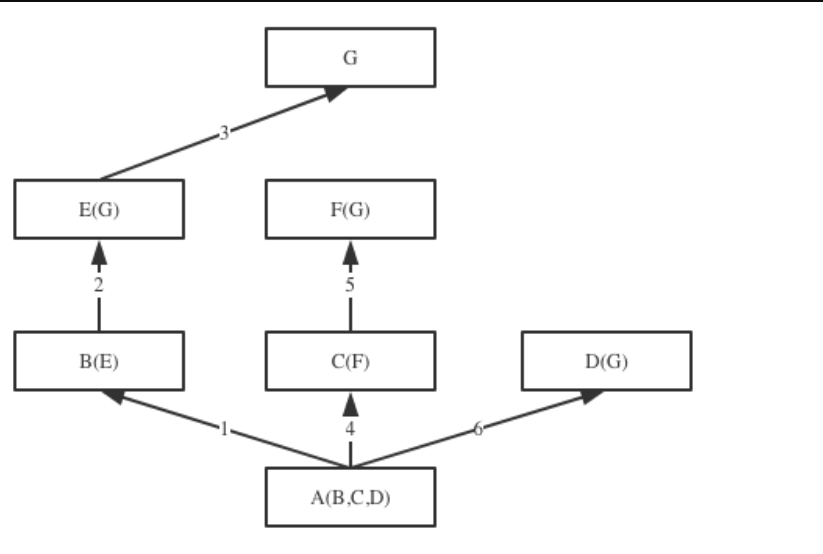
在多重继承上,如果继承关系为菱形结构(菱形问题或钻石问题),即子类的父类最后继承了同一个类,那么属性的查找方式有两种:
- 经典类:按照深度优先查询
class A():
def test(self):
print('from A')
class B(A):
pass
class C(A):
def test(self):
print('from C')
pass
class D(B):
pass
class E(C):
pass
class F(D, E):
pass
f1 = F()
f1.test()
####执行结果:####
from A
"""
经典类:
F(D,E)--->D(B)--->B(A)--->A
|--->E(C)--->C(A)
在经典类中按 深度优先查询,F中没有test方法,去D中找,D中也没有,去B中找,B中没有去A中找,如果A中也没有,则去E中找,E中没有去C中找,如果C中还没有,则报方法没找到。
但在此例是发现A中有,它就结束查找了。虽然C中也定义了test方法,但是在经典类中,因为A中找到了,所以它不走E那条线路。
"""
# 上面的代码在python2中执行。
-
新式类:按照广度优先查询
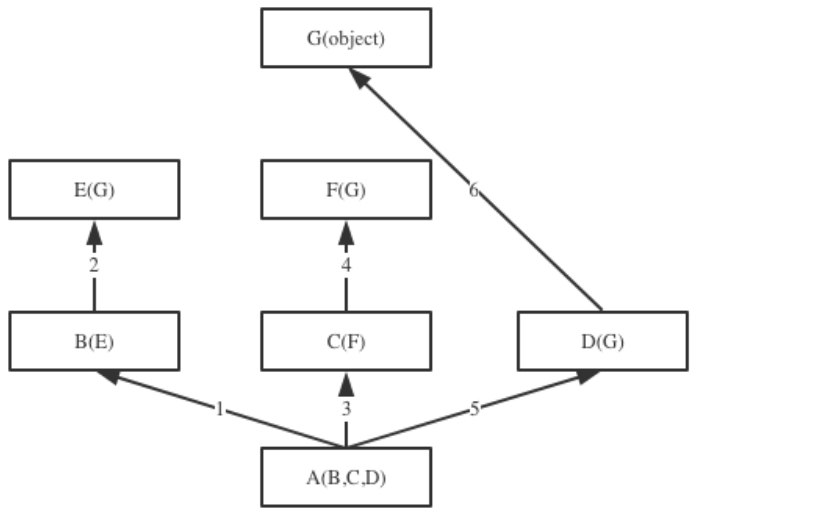
class A(): # class A(object) # 在python3中写不写object都一样,默认都为新式类 def test(self): print('from A') class B(A): pass class C(A): def test(self): print('from C') pass class D(B): pass class E(C): pass class F(D, E): pass f1 = F() f1.test() ####执行结果:#### from C """ 新式类: F(D,E)--->D(B)--->B(A) |--->E(C)--->C(A)--->A 在新式类中按 广度优先查询,F中没有test方法,去D中找,D中没有,去B中找,B中没有它会去E中找,E中没有去C中找,C中没有去A中找。 在此例中由于是新式类,广度优先,C中定义了test方法,所以执行C中的test查找就结束了,虽然A中也定义了,但不会执行到它,如果把C中的test去掉,它就会执行A中的 """
8.4 Mixins机制
8.4.1 什么是Mixin
Mixin本意是混入,程序中用来将不同功能(functionality)组合起来,从而为 类提供多种特性。而虽然继承(inheritance)也可以实现多种功能,但继承一般 有从属关系,即子类通常是父类更加具体的类。而 mixin 则更多的是功能上的 组合,因而相当于是接口(带实现的接口)。
8.4.2 Python中Mixins机制
Python提供了Mixins机制,简单来说Mixins机制指的是子类混合(mixin)不同类的功能。
1. 分主类和辅类
2. 命名方式一般以 Mixin, able, ible 为后缀
3. 辅类位置一般在主类的左边
示例:
"""
定义一个动物的类,里面包含动物的一些特征,如:talk、run、eat这是每个动物都具备的。狗,猫,鸟都是动物,但是鸟可以飞。如果把这个飞的功能加到动物这个类中就不合适了,因为狗和猫不会飞。
但是如果给每一个会飞的动物都定义一个飞的功能又会造成代码冗余。
所以可以只定义一个飞行的类,只让会飞的动物继承。
"""
class Animals():
def __init__(self,name):
self.name = name
def talk(self):
print("%s can talk" % self.name)
def run(self):
print("%s can run" % self.name)
def eat(self):
print("%s can eat" % self.name)
class Dog(Animals):
pass
d = Dog("Dog")
d.talk()
d.run()
d.eat()
# 执行结果:
Dog can talk
Dog can run
Dog can eat
# 如果再定义一个鸟的类,鸟属于动物,但是它有飞行的功能,所以要加一个飞行的类
class Animals():
def __init__(self,name):
self.name = name
def talk(self):
print("%s can talk" % self.name)
def run(self):
print("%s can run" % self.name)
def eat(self):
print("%s can eat" % self.name)
class Dog(Animals):
pass
class FlyMixin():
def __init__(self,name):
self.name = name
def fly(self):
print("%s can fly" % self.name)
class Birde(FlyMixin,Animals):
pass
d = Dog("Dog")
d.talk()
d.run()
d.eat()
b = Birde('birde')
b.talk()
b.run()
b.eat()
b.fly()
# 执行结果:
Dog can talk
Dog can run
Dog can eat
birde can talk
birde can run
birde can eat
birde can fly
Mixin类必须是某一个功能,而且仅能是一种功能,如果有多种功能要写多个。它不能依赖子类,子类即使没有继承Mixin类也能正常工作,只是少了某一项功能。
9 super和MRO
9.1 super()
class Person():
shool = '社会大学'
def __init__(self, name, age, gender):
self.name = name
self.age = age
self.gender = gender
class Students(Person):
def __init__(self, name, age, gender, course):
self.course = course
Person.__init__(self, name, age, gender)
def select_course(self, course):
self.course = course
print("在%s,%s选课成功,课程为:<<%s>>" % (self.shool, self.name, course))
在上面的代码中子类要调用父类中的方法或属性时,就必须使用类名称直接调用,但这样会有两个问题,如果父类改名了,子类中的代码也要改。由于python是支持多继承的语言,即一个类可以同时继承多个类。在多继承的情况下,会存在重复调用的问题,这两个问题可以使用super()函数解决
super() 函数是用于调用父类(超类)的一个方法。
super() 是用来解决多重继承问题的,直接用类名调用父类方法在使用单继承的时候没问题,但是如果使用多继承,会涉及到查找顺序(MRO)、重复调用(钻石继承)等种种问题。
super() 方法的语法:
super(type[, object-or-type])
参数
- type -- 类。
- object-or-type -- 类,一般是 self
Python3.x 和 Python2.x 的一个区别是: Python 3 可以使用直接使用 super().xxx 代替 super(Class, self).xxx :
可以把上面的代码改一下:
class Person():
shool = '社会大学'
def __init__(self, name, age, gender):
self.name = name
self.age = age
self.gender = gender
class Students(Person):
def __init__(self, name, age, gender, course):
self.course = course
super().__init__(name, age, gender)
def select_course(self, course):
self.course = course
print("在%s,%s选课成功,课程为:<<%s>>" % (self.shool, self.name, course))
stu1 = Students("hans",18, 'M',"如何五块钱花一礼拜")
stu1.select_course(stu1.course)
###执行结果:
在社会大学,hans选课成功,课程为:<<如何五块钱花一礼拜>>
"""
super().__init__(name, age, gender)和Person.__init__(self, name, age, gender) 功能一样。
"""
单继承super
class A:
def __init__(self):
self.n = 2
def add(self, m):
print('self is {0} @A.add'.format(self))
self.n += m
class B(A):
def __init__(self):
self.n = 3
def add(self, m):
print('self is {0} @B.add'.format(self))
super().add(m)
self.n += 3
b = B()
b.add(2)
print(b.n) # b.n 的值是多少?
###执行结果:
self is <__main__.B object at 0x0000017D71A6BE20> @B.add
self is <__main__.B object at 0x0000017D71A6BE20> @A.add
8
"""
分析:
super().add(m) 确实调用了父类 A 的 add 方法。
super().add(m) 调用父类方法 def add(self, m) 时, 此时父类中 self 并不是父类的实例而是子类(b)的实例, 所以 super().add(m) 之后 self.n 的结果是 5 而不是 4 。
"""
多继承super
class A:
def __init__(self):
self.n = 2
def add(self, m):
print('self is {0} @A.add'.format(self))
self.n += m
class B(A):
def __init__(self):
self.n = 3
def add(self, m):
print('self is {0} @B.add'.format(self))
super().add(m)
self.n += 3
class C(A):
def __init__(self):
self.n = 4
def add(self, m):
print('self is {0} @C.add'.format(self))
super().add(m)
self.n += 4
class D(B, C):
def __init__(self):
self.n = 5
def add(self, m):
print('self is {0} @D.add'.format(self))
super().add(m)
self.n += 5
d = D()
d.add(2)
print(d.n)
###执行结果:
self is <__main__.D object at 0x0000026D17E7BD90> @D.add
self is <__main__.D object at 0x0000026D17E7BD90> @B.add
self is <__main__.D object at 0x0000026D17E7BD90> @C.add
self is <__main__.D object at 0x0000026D17E7BD90> @A.add
19
当我们调用 super() 的时候,实际上是实例化了一个 super 类。
在大多数情况下, super 包含了两个非常重要的信息: 一个 MRO(Method Resolution Order) 列表以及 MRO 中的一个类
调用过程图如下:
D.mro() == [D, B, C, A, object]
d = D()
d.n == 5
d.add(2)
class D(B, C): class B(A): class C(A): class A:
def add(self, m): def add(self, m): def add(self, m): def add(self, m):
super().add(m) 1.---> super().add(m) 2.---> super().add(m) 3.---> self.n += m
self.n += 5 <------6. self.n += 3 <----5. self.n += 4 <----4. <--|
(14+5=19) (11+3=14) (7+4=11) (5+2=7)

9.2 MRO
MRO 就是类的方法解析顺序表, 其实也就是继承父类方法时的顺序表。
定义的每一个类,Python会通过C3线性化算法计算出一个方法解析顺序(MRO)列表。 这个MRO列表就是一个简单的所有基类的线性顺序表。例如:
print(D.__mro__) 和print(D.mro())
(<class '__main__.D'>, <class '__main__.B'>, <class '__main__.C'>, <class '__main__.A'>, <class 'object'>)
Python会在MRO列表上从左到右开始查找基类,直到找到第一个匹配这个属性的类为止。
它会合并所有父类的MRO列表并遵循如下三条准则:
- 子类会先于父类被检查
- 多个父类会根据它们在列表中的顺序被检查
- 如果对下一个类存在两个合法的选择,选择第一个父类
# mro练习1:
class A:
def spam(self):
print('A.spam')
super().spam()
class B:
def spam(self):
print('B.spam')
class C(A, B):
pass
c = C()
c.spam() # 猜想打印结果
#执行结果:
A.spam
B.spam
# 打印mro表
print(C.mro())
[<class '__main__.C'>, <class '__main__.A'>, <class '__main__.B'>, <class 'object'>]
"""
可以看到在类A中使用 super().spam() 实际上调用的是跟类A毫无关系的类B中的 spam() 方法。 这个用类C的MRO列表就可以完全解释清楚了,它会依次执行A.test B.test
"""
# mro练习2:
class B:
def test(self):
print('B---->test')
def aaa(self):
print('B---->aaa')
class A:
def test(self):
print('A---->test')
super().aaa()
class C(A, B):
def aaa(self):
print('C----->aaa')
c = C()
c.test() # 猜想打印结果
#执行结果:
A---->test
B---->aaa
# 打印mro表
print(C.mro())
[<class '__main__.C'>, <class '__main__.A'>, <class '__main__.B'>, <class 'object'>]
由于 super() 可能会调用不是你想要的方法,所以应该遵循一些通用原则。
- 首先,确保在继承体系中所有相同名字的方法拥有可兼容的参数签名(比如相同的参数个数和参数名称)。 这样可以确保
super()调用一个非直接父类方法时不会出错。 - 其次,最好确保最顶层的类提供了这个方法的实现,这样的话在MRO上面的查找链肯定可以找到某个确定的方法。
10. 由浅入深了解面向对象之---多态
类的多态一定要满足两个条件:
- 继承:多态一定是发生在子类和父类之间;
- 重写:子类重写了父类的方法。
class Animal():
def run(self):
print('Animal is running...')
class Dog(Animal):
pass
class Cat(Animal):
pass
dog = Dog()
dog.run()
cat = Cat()
cat.run()
# 执行结果:
Animal is running...
Animal is running...
"""
Animal是Dog和Cat的父类,Dog和Cat是Animal的子类。
可以看到Dog和Cat类中什么都没做,但它们就有了run方法。这就是继承最大的好处:子类获得了父类的全部功能。
"""
# Dog和Cat运行都显示:Animal is running...,但我们想Dog的显示为Dog is running...,Cat的显示为cat is running...
# 代码:
class Animal():
def run(self):
print('Animal is running...')
class Dog(Animal):
def run(self):
print("Dog is running...")
class Cat(Animal):
def run(self):
print("Cat is running...")
dog = Dog()
dog.run()
cat = Cat()
cat.run()
# 执行结果:
Dog is running...
Cat is running...
"""
当子类和父类都存在相同的run()方法时,我们说,子类的run()覆盖了父类的run(),在代码运行的时候,总是会调用子类的run().这种从父类中继承了方法,自己又重新写这个方法,这种就是多态
"""
多态性的好处在于增强了程序的灵活性和可扩展性,比如通过继承Animal类创建了一个新的类,实例化得到的对象都可以使用它的run方法
多态性的本质在于不同的类中定义有相同的方法名,这样我们就可以不考虑类而统一用一种方式去使用对象,可以通过在父类引入抽象类的概念来硬性限制子类必须有某些方法名。
import abc
class Animal(metaclass=abc.ABCMeta):
@abc.abstractmethod
def run(self):
print('Animal is running...')
class Dog(Animal): # 但凡继承Animal的子类都必须遵循Animal规定,里面必须有一个run方法
pass
class Cat(Animal):
pass
dog = Dog()
dog.run()
cat = Cat()
cat.run()
#执行结果:
TypeError: Can't instantiate abstract class Dog with abstract method run
# metaclass=abc.ABCMeta 指定metaclass属性将类设置为抽象类
# 使用abc里面的方法来限制,子类中必须定义有一个名为run的方法。
import abc
class Animal(metaclass=abc.ABCMeta):
@abc.abstractmethod
def run(self):
print('Animal is running...')
class Dog(Animal):
def run(self):
print("Dog is running...")
class Cat(Animal):
def run(self):
print("Cat is running...")
dog = Dog()
dog.run()
cat = Cat()
cat.run()
# 执行结果:
Dog is running...
Cat is running...
抽象类只能被继承,它本身只是用来约束子类的,不能被实例化。
可以使用rasie来限制子类中必须要遵守父类中的规定
class Animal():
def run(self):
raise Exception("必须实现run方法")
class Dog(Animal):
pass
class Cat(Animal):
pass
dog = Dog()
cat = Cat()
dog.run()
cat.run()
# 执行结果:
Exception: 必须实现run方法
多态带来的特性:在不用考虑对象数据类型的情况下,直接调用对应的函数
10.1 鸭子类型(duck typing)
其实我们完全可以不依赖于继承,只需要制造出外观和行为相同对象,同样可以实现不考虑对象类型而使用对象,这正是Python的鸭子类型(duck typing):“如果看起来像、叫声像而且走起路来像鸭子,那么它就是鸭子”。比起继承的方式,鸭子类型在某种程度上实现了程序的松耦合度.
# 在Linux中一切皆文件。
# 一般来说一个文件,可读(read)可写(write)就是一个文件
# 所以一个东西它可读可写就可以把它当成一个文件
class Disk():
def read(self):
pass
def write(self):
pass
class socket():
def read(self):
pass
def write(self):
pass
# 上面两个都可读可写,那么它们俩就是文件
# 能跑的,能说话的就是动物
class Dog():
def run(self):
print("Dog is running...")
def talk(self):
print("Dog is talking...")
class Cat():
def run(self):
print("Cat is running...")
def talk(self):
print("Dog is talking...")
class Animal(animal):
return animal.run animal.talk
dog = Dog()
cat = Cat()
dog_run, dog_talk = Animal(dog)
cat_run, cat_talk = Animal(cat)
dog_run()
dog_talk()
cat_run()
cat_talk()
11. 面向对象其他知识拾遗
11.1 组合
上面讲了面向类与对象的继承,其实 类与类之间还有另一种关系,这就是组合。
组合就是一个类中使用到另一个类,从而把几个类拼到一起。组合的功能也是为了减少重复代码。
类的组合: 在一个类中以另一个类的对象作为数据属性,称为类的组合
以上面选课系统为例,定义了父类和初始化了学生类和教师类,如果给学生和老师类都加一上:课程名,课程周期,课程价格。最好的方法是把这些新增的内容重新定义为一个课程类。
class Person():
shool = '社会大学'
def __init__(self, name, age, gender):
self.name = name
self.age = age
self.gender = gender
class Students(Person):
def __init__(self, name, age, gender, course):
self.course = course
#Person.__init__(self, name, age, gender)
super().__init__(name, age, gender)
def select_course(self, course):
self.course = course
print("在%s,%s选课成功,课程为:<<%s>>" % (self.shool, self.name, course))
class Teachers(Person):
def __init__(self, name, age, gender, level):
self.level = level
Person.__init__(self, name, age, gender)
def score(self, stu_obj, score):
stu_obj.score = score # 给学生打分
print('教师%s就<<%s>>课程给%s打了%s分' % (self.name, stu_obj.course, stu_obj.name, score))
# 新增一个课程类:
class course():
def __init__(self,name, period, price):
self.name = name
self.period = period
self.price = price
golang = course("golang", "3个月", 3800)
java = course("java", "6个月", 28000)
stu1 = Students("Hans",20,'M',golang)
tea1 = Teachers("Jack", 45, 'M', "中级")
stu1.select_course(stu1.course.name)
tea1.score(stu1, 70)
# 执行结果:
在社会大学,Hans选课成功,课程为:<<golang>>
教师Jack就<<golang>>课程给Hans打了70分
11.2 面向对象内置方法(魔法函数)
所谓魔法函数(Magic Methods),是Python的一种高级语法,允许你在类中自定义函数(函数名格式一般为__xx__),并绑定到类的特殊方法中。
- Python中以双下划线(
__xx__)开始和结束的函数(不可自己定义)为魔法函数。 - 调用类实例化的对象的方法时自动调用魔法函数。
- 在自己定义的类中,可以实现之前的内置函数
1.__init__
语法:
def __init__(self,[arg1,arg2]):
其实它就是 Python 的构造方法,__init__() 方法可以包含多个参数,但必须包含一个名为self 的参数,且必须作为第一个参数,这个self表示对象本身,即谁调用,就表示谁,在类实例化一个对象时,隐式调用了 __init__() 构造方法,而且对类实例化时self这个参数不需要手动传递,只需要传arg1,arg2.而且__init__方法中不能用返回值,就是有也只能返回None
class A():
def __init__(self,a, b):
self.a = a
self.b = b
print("hello")
t1 = A(1, 2) # self 谁调用,就表示谁,现在把A这个类实例化为一个对象t1,这个self就为这个t1.
# 执行:
hello # 对A这个类一实例化,就执行了__init__()
2. __str__
当使用print输出对象的时候,只要自己定义了__str__(self)方法,那么就会打印从在这个方法中return的数据
class Hello():
def __init__(self,name):
self.name = name
def __str__(self):
return "Hello, %s" % self.name
hi = Hello("Hans")
print(hi) # 打印对象
# 执行结果:
Hello, Hans
注意: 使用__str__时return只返回字符串,不能是其他类型,None也不行。
3. __del__
__del__() 方法,功能正好和 __init__() 相反,其用来销毁实例化对象。如果之前创建的类实例化对象后续不再使用,最好在适当位置手动将其销毁,释放其占用的内存空间(整个过程称为垃圾回收(简称GC),虽然Python是自动的垃圾回收机制),无论是手动销毁,还是 Python 自动帮我们销毁,都会调用 __del__() 方法.
__init__()为构造函数,而__del__()为析构函数。
__del__()在类里定义,如果不定义,Python 会在后台提供默认析构函数。
__del__调用有两种:
-
使用
__del__显式的调用析构函数删除对象:del 对象名class Foo(): def __init__(self,name): self.name = name def __del__(self): print("del self") hi = Foo("Hans") del hi # 显式的调用 # 执行结果: del self -
当对象在某个作用域中调用完毕时,也会自动执行
__del__class Foo(): def __init__(self,name): self.name = name def __del__(self): print("del self") hi = Foo("Hans") # 执行结果: del self # 程序执行后自动触发
4. __enter__和__exit
__exit__和__enter__函数是与with语句的组合应用的,用于上下文管理。
出现with语句,对象的__enter__被触发,负责返回一个值,该返回值将赋值给as子句后面的变量,通常返回对象自己,即self。当with后面的代码块全部被执行完之后,将调用前面返回对象的__exit__()方法。
def __exit__(self, exc_type, exc_val, exc_tb):中,exc_type, exc_val, exc_tb三个参数分别代表异常类型,异常值和追溯信息。没有异常的情况下,exc_type, exc_val, exc_tb值都为None。with语句中代码块出现异常,则with后的代码都无法执行。
class Bar():
def __enter__(self):
print("开始enter")
return self
def __exit__(self, exc_type, exc_val, exc_tb):
print("执行exit")
print(exc_type)
print(exc_val)
print(exc_tb)
with Bar() as f:
pass
# 执行结果:
开始enter
执行exit
None
None
None
# 正常结束
class Bar():
def __enter__(self):
print("开始enter")
return self
def __exit__(self, exc_type, exc_val, exc_tb):
print("执行exit")
def test(self):
# raise "myself define Error"
print("Hello")
# return True
with Bar() as f:
f.test()
print("with is end")
# 执行结果
开始enter
Hello
with is end
执行exit
# 模拟with语句中出现异常
class Bar():
def __enter__(self):
print("开始enter")
return self
def __exit__(self, exc_type, exc_val, exc_tb):
print("执行exit")
def test(self):
# raise "myself define Error"
num = 1/0
return num
# return True
with Bar() as f:
f.test()
print("with is end")
# 执行结果:
开始enter
执行exit
Traceback (most recent call last):
f.test()
num = 1/0
ZeroDivisionError: division by zero
# with语句中代码块出现异常,则with后的代码都无法执行。
5. __call__()
该方法的功能类似于在类中重载 () 运算符,使得类实例对象可以像调用普通函数那样,以“对象名()”的形式使用。
即:__call__使实例能够像函数一样被调用。
# 正常实例化
class Foo():
def __init__(self):
print("Hello")
hi = Foo()
hi()
# 执行结果:
Hello
Traceback (most recent call last):
hi()
TypeError: 'Foo' object is not callable
# 正常情况下一个对象是没办法像函数一样被调用
# 但加上__call__就可以
class Foo():
def __init__(self):
print("Hello")
def __call__(self, *args, **kwargs):
print("__call__")
hi = Foo()
hi() # 把对象像函数一样调用
# 执行结果:
Hello
__call__
6. __new__()
该方法是一种负责创建类实例的静态方法,它无需使用 staticmethod 装饰器修饰,且该方法会优先 __init__() 初始化方法被调用。
因为是给类创建实例,所以至少传一个参数:cls,代表要实例化的类。它是实例中最先调用的方法。
>>> class New_init():
... def __init__(self, name):
... self.name = name
... print("__init__")
... def __new__(cls, *args, **kwargs):
... print("__new__")
... return object.__new__(cls)
...
>>>
>>> t = New_init("test")
__new__
__init__
__new__方法先调用
__init__和__new__的关系:
__init__第一个参数是self,表示需要初始化的实例,由解释器自动传入,而这个实例就是__new__返回的实例。
更多魔法方法请看:
[Python 魔术方法指南][https://pycoders-weekly-chinese.readthedocs.io/en/latest/issue6/a-guide-to-pythons-magic-methods.html]
[Python官网__数据模型][https://docs.python.org/zh-cn/3/reference/datamodel.html]
11.3 反射
反射:主要是指程序可以访问、检测和修改它本身状态或行为的一种能力。
在Python中面向对象中反射就是通过字符串映射object对象的方法或者属性。
反射的方法和使用:
-
getattr:获取object对象中与字符串同名的方法或者函数
接收两个参数,前面的是一个类或者模块,后面的是一个字符串
class Foo(): def talk(self): print("Hello") def run(self): print("is running") hi = Foo() print(getattr(hi, "runn",None)) #执行结果: None # 如果所传的字符串在对象中不存在,同时没有传None的话,就会报错 print(getattr(hi, "safasf") #执行结果: AttributeError: 'Foo' object has no attribute 'safasf' # 如果传的字符串存在: print(getattr(hi, "talk")) # 执行结果: <bound method Foo.talk of <__main__.Foo object at 0x000001D76FD6BDF0>> # 如果传的字符串存在则执行: getattr(hi, "talk")() # 执行结果: Hello # 或: new_talk = getattr(hi, "talk") new_talk() # 执行结果: Hello -
hasattr: 判断objec是否有所传字符串这个方法或者属性
接收两个参数,前面的是一个类或者模块,后面的是一个字符串
class Foo(): def talk(self): print("Hello") def run(self): print("is running") hi = Foo() print(hasattr(hi, 'asadfasdf')) # 传一个不存在的返回False # 执行结果: False # 传一个存在的,返回True print(hasattr(hi, 'talk')) True -
setattr: 为object对象设置一个以所传字符串为名的value方法或者属性
接收三个参数,前面的是一个类或者模块,后面的是一个字符串
class Foo(): def talk(self): print("Hello") def run(self): print("is running") hi = Foo() print(hi.__dict__) # {} setattr(hi, 'eat', "正吃东西") # 给hi对象设置一个eat的属性 print(hi.__dict__) # {'eat': '正吃东西'} print(hi.eat) #正吃东西 # 执行结果: {} {'eat': '正吃东西'} 正吃东西 # 设置一个eat的方法 class Foo(): def talk(self): print("Hello") def run(self): print("is running") def eat(): print("is eating") hi = Foo() setattr(hi, 'eat', eat) print(hi.__dict__) hi.eat() # 执行结果: {'eat': <function eat at 0x000001E6F3723F40>} is eating # 或者: class Foo(): def __init__(self,name): self.name = name def talk(self): print("Hello %s" % self.name) def run(self): print("%s is running" % self.name) def eat(self): print("%s is eating" % self.name) hi = Foo("Hans") hi.talk() print(hi.__dict__) # 先查看hi对象的名称空间内容 {'name': 'Hans'} setattr(hi, 'eat', eat) #给hi设置一个eat方法 print(hi.__dict__) # 设置后查看hi对象的名称空间内容:{'name': 'Hans', 'eat': <function eat at 0x0000027A79503F40>} hi.eat(hi) # 执行eat方法:Hans is eating, 这个hi必须要传给eat(hi),否则会报错:eat() missing 1 required positional argument: 'self' # 执行结果: Hello Hans {'name': 'Hans'} {'name': 'Hans', 'eat': <function eat at 0x0000027A79503F40>} Hans is eating -
delattr: 删除object对象中的所传字符串方法或者属性
接收两个参数,前面的是一个类或者模块,后面的是一个字符串
class Foo(): def __init__(self,name): self.name = name def talk(self): print("Hello %s" % self.name) def run(self): print("%s is running" % self.name) def eat(self): print("%s is eating" % self.name) hi = Foo("Hans") print("执行delattr前:") hi.eat() delattr(hi, 'eat') print("执行delattr后:") hi.eat() # 执行结果: 执行delattr前: Hans is eating Traceback (most recent call last): delattr(hi, 'eat') AttributeError: eat # 因为使用delattr删除了eat方法,所以再使用对象hi.eat()调用的时候就会报错
反射的实际应用
如果我们需要调用对方给的接口,我们需要通过不同的请求方式,调用不同的函数。使用对方接口是还需要判断一下这个接口里有没有我们需要的方法,就可以使用反射判断
class requst_method():
def post(self):
print("这是个post方法")
def get(self):
print("这是个get方法")
requst = requst_method()
method = input("请输入你要调用的方法>>>:").strip()
if hasattr(requst, method):
func = getattr(requst, method)
func()
else:
print("你要调用的方法不存在")
#执行结果:
请输入你要调用的方法>>>:get
这是个get方法
请输入你要调用的方法>>>:post
这是个post方法
请输入你要调用的方法>>>:sklafj
你要调用的方法不存在
没有人能够让你放弃梦想,你自己试试,就会放弃了。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号