

Python递归、三元表达式、生成式(列表,字典)、匿名函数
目录
1. 递归函数

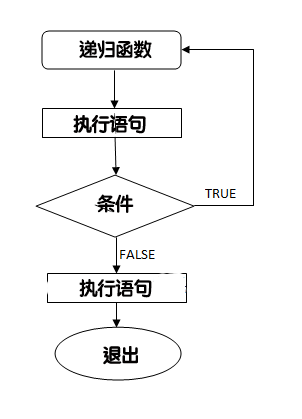
1.1 什么是递归?
生活中用到的递归:
从前有座山,山里有座庙,庙里有个老和尚,正在给小和尚讲故事呢!讲的什么呢? 讲的是:"从前有座山,山里有座庙,庙里有个老和尚,正在给小和尚讲故事呢!讲的什么呢? 讲的是:'从前有座山,山里有座庙,庙里有个老和尚,正在给小和尚讲故事呢!讲的什么呢?
递归就是函数在运行过程中,直接或者间接的调用了自身。
递归的核心:
- 递推
一层层往下推导答案(每次递归之后复制度相较于上一次一定要有所下降) - 回溯
依据最后的结论往后推导出最初需要的答案
重点: 递归一定要有结束条件!!!
如果没有结果条件会一直递归下去,python解释器中默认递归次数是1000次
>>> import sys
>>> sys.getrecursionlimit()
1000
1.2 递归示例
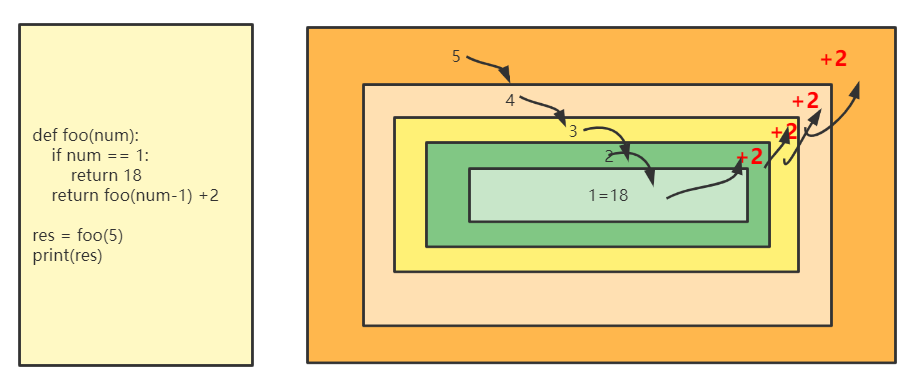
示例1:求第5个人的的年龄,已知第1个人的年龄为18,第2个人比第1个人大两岁,第3个人比第2个人大两岁,依次类推
# 代码:
def foo(num):
if num == 1:
return 18
return foo(num-1) +2
res = foo(5)
print(res)
执行结果:
26
示例2: 只打印列表中的数字
l = [1,[2,[3,[4,[5,[6,[7,[8,[9,[10,[11,[12,[13,[14,]]]]]]]]]]]]]]
def boo(l):
for i in l:
if type(i) == int:
print(i, end=' ')
else:
boo(i)
boo(l)
print()
执行结果:
1 2 3 4 5 6 7 8 9 10 11 12 13 14
示例3: 阶乘
# 代码:
def func1(num):
if num == 1:
return 1
return func1(num -1) * num
res = func1(5)
print(res)
# 执行结果:
120
2. 三元表达式
判断两个数的大小,返回大的数:
之前的代码:
# 代码
def foo(a, b):
if a > b:
return a
else:
return b
print(foo(5, 6))
# 执行结果:
6
使用三元表达式:
def foo2(a,b):
return a if a >b else b
print(foo2(5,6))
# 执行结果:
6
# 判断用户输入的是y或n
user_input=input("Please input y/n:").strip()
Please input y/n:y
if user_input == 'y':
print("OK")
else:
print("NO")
OK
# 使用三元表达式:
>>> user_input=input("Please input y/n:").strip()
Please input y/n:y
>>> "OK" if user_input=='y' else "NO"
'OK'
值 if 条件 else 值条件成立采用if前面的值,不成立采用else后面的值。
三元表达式还可以嵌套:
>>> res = True if 5 > 4 else (False if 1 < 2 else True)
>>> print(res)
True
# 如果 前面的if 5 > 4为真则直接返回,否则再去计算 else后面的(False if 1 < 2 else True)
>>> res = True if 5 < 4 else (False if 1 < 2 else True)
>>> print(res)
False
但是,三元表达式尽量不要嵌套使用
注意: 当功能需求仅仅是二选一的情况下,那么推荐使用三元表达式
3. 列表生成式
列表生成式:功能是提供一种方便的列表创建方法.
示例1: 给一个列表里面的每一个元素都加个ex_前缀。
# 给列表每个元素都个ex_前缀,组成一个新列表:
list1 = ['apple', 'orange', 'purple']
new_list = ['ex_apple', 'ex_orange', 'ex_purple']
# 目前代码实现
# 代码:
list1 = ['apple', 'orange', 'purple']
new_list=[]
def foo(list1):
for name in list1:
new_list.append("ex_%s" % name)
foo(list1)
print(new_list)
# 执行结果:
['ex_apple', 'ex_orange', 'ex_purple']
# 使用列表生成式
>>> res = ["ex_%s" % name for name in list1]
>>> res
['ex_apple', 'ex_orange', 'ex_purple']
列表生成式里面还可以使用if
# 除了orange外其他元素加`ex_`前缀并加入列表。
>>> res = ["ex_%s" % name for name in list1 if name != 'orange']
>>> res
['ex_apple', 'ex_purple']
# 但 if 后面不能再加else了。
4. 字典生成式
快速生成一个字典。
如果快速把列表 list1 = ['apple', 'orange', 'purple'] 生成一个字典
>>> {i:j for i, j in enumerate(list1)}
{0: 'apple', 1: 'orange', 2: 'purple'}
# enumerate() 为枚举
# 对于一个可迭代的(iterable)/可遍历的对象(如列表、字符串),enumerate将其组成一个索引序列,利用它可以同时获得索引和值。默认从0开始,但可以修改。
>>> {i:j for i, j in enumerate(list1,start=1)}
{1: 'apple', 2: 'orange', 3: 'purple'}
还可以快速生成一个集合:
把 list1 = ['apple', 'orange', 'purple'] 生成一个集合
>>> {i for i in list1}
{'purple', 'apple', 'orange'}
5. 匿名函数lambda
5.1 匿名函数定义和格式
匿名函数:没有名字的函数.
格式:
lambda 形参:返回值
def foo(n):
return n**2
#就相当于:
lambda n:n**2
# 在调用的时候
>>> print(foo(3))
9
# 而匿名函数:
>>> print((lambda n:n**2)(3))
9
匿名函数一般不会单独使用 都是配合其他函数一起使用
5.2 和匿名函数结合使用的内置方法
匿名函数一般不会单独使用 都是配合其他函数一起使用
map() 映射
把列表中 list_num = [1, 2, 3, 4, 5]的元素都乘以2。
正常会把每个元素都遍历一遍,然后乘以2,最后打印。
还可以使用map()内置方法,它的参数可以是一个函数
def foo(x):
return x*2
print(list(map(foo, list_num)))
[2, 4, 6, 8, 10]
# 还可以把foo替换为一个匿名函数
>>> print(list(map(lambda x:x*2, list_num)))
[2, 4, 6, 8, 10]
面试题:一行代码打印出来9以内偶数的平方和
>>> sum(map(lambda x:x**2, [x for x in range(1,10) if x % 2 == 0]))
120
zip() 拉链
把多个容器中的元素,一一对应组成一上元素
>>> l1 = [1, 2, 3, 4, 5] # 元素个数相等
>>> l2 = ['apple', 'watermelon', 'pear', 'cherry', 'strawberry']
>>> list(zip(l1, l2))
[(1, 'apple'), (2, 'watermelon'), (3, 'pear'), (4, 'cherry'), (5, 'strawberry')]
# 如果两个列表中元素个数不相等,则以少的元素为准
>>> l1 = [1, 2, 3, 4, 5, 6] # 元素个数不相等
>>> l2 = ['apple', 'watermelon', 'pear', 'cherry', 'strawberry']
# 不但能组合两个,还可以更多个,但还是以最少元素为准
>>> l1 = [1, 2, 3, 4, 5, 6]
>>> l2 = ['apple', 'watermelon', 'pear', 'cherry', 'strawberry']
>>> l3=('a','b','c','d')
>>> list(zip(l1, l2,l3))
[(1, 'apple', 'a'), (2, 'watermelon', 'b'), (3, 'pear', 'c'), (4, 'cherry', 'd')]
max() 求最大值和min() 求最小值
>>> l1 = [100, 2, 999, 3, 89, 30]
>>> max(l1) # 求最大值
999
>>> min(l1) # 求最小值
2
>>> dict_list = {'Amy':9999,
'Bill': 1999,
'jack':100}
# 打印出数字最大的用户
# 如果直接使用
>>> max(dict_list)
'jack'
# 发现结果不对,因为dict_list是字典,它只会取key,key为字符串,它会按它的ASCII码做比较
max用法:
max(iterable, *[, default=obj, key=func]) -> value
max(arg1, arg2, *args, *[, key=func]) -> value
# 可以把字典中的value取出来,然后用max()返回最大值
>>> max(dict_list, key=lambda key:dict_list[key])
'Amy'
# 同理也可以取最小值
>>> min(dict_list, key=lambda x:dict_list[x])
'jack'
# 取出列表元素中值最大的元素
>>> list_num = [['a',5], ['b', 10], ['c', 6]]
>>> max(list_num, key=lambda x:x[1])
['b', 10]
filter() 过滤
filter(function or None, iterable) --> filter object
# 取出列表元素中大于20的元素
>>> list_num = [10, 18, 25, 20, 22]
>>> list(filter(lambda x:x>20, list_num))
[25, 22]
# 取出字典中value大于2000的key
>>> dict_list={'Amy': 9999, 'Bill': 1999, 'jack': 100}
>>> list(filter(lambda x:dict_list[x] > 2000, dict_list))
['Amy']
reduce() 归总
# 对参数序列中元素进行累积
# 函数将一个数据集合(链表,元组等)中的所有数据进行下列操作:用传给 reduce 中的函数 function(有两个参数)先对集合中的第 1、2 个元素进行操作,得到的结果再与第三个数据用 function 函数运算,最后得到一个结果。
# 使用的方法:
reduce(function, sequence[, initial]) -> value
For example, reduce(lambda x, y: x+y, [1, 2, 3, 4, 5]) calculates
((((1+2)+3)+4)+5)
# 在python2中可以直接使用reduce
# 在python3中reduce放到functools模块中了,使用的话要先从functools中导入
# python2:
>>> reduce(lambda x,y:x+y, [1, 2, 3, 4, 5])
15
>>> reduce(lambda x,y:x*y, [1, 2, 3, 4, 5])
120
# python3
>>> from functools import reduce
>>> list_num = [10, 18, 25, 20, 22]
>>> reduce(lambda x,y:x+y, list_num)
95
>>> reduce(lambda x,y:x*y, list_num)
1980000
# 还可以额外添加元素值
>>> reduce(lambda x,y:x+y, [1, 2, 3, 4, 5], 10)
25
# 10不在原来序列内,为额外添加的
sorted() 排序
# 排序并返回一个新列表
>>> list_num = [10, 18, 25, 20, 22]
>>> sorted(list_num) # 不改变原列表
[10, 18, 20, 22, 25]
# 把下面的字典按value的数值从小到大排序
>>> dict_list = {'Amy': 99, 'Bill': 200, 'jack': 100, 'az':300}
>>> sorted(dict_list,key=lambda x:dict_list[x])
['Amy', 'jack', 'Bill', 'az']
注意:
在python3中map、filter、zip返回的是一个迭代器。
在python2中:
map 返回列表
zip 返回元组列表
filter 返回 列表,元组或字符串
6. 二分法
算法就是解决问题的高效方法。
示例:从一个列表中查找一个数是否存在
# 普通方法,在全部遍历,然后判断是否有要找到的值
>>> list_num = [12, 34, 54, 78, 101, 132, 136, 248, 567, 901, 1000]
>>> count=0
>>> for n in list_num:
count+=1
if n == 132:
print("找了%d次,终于找到了" % count)
break
找了6次,终于找到了
# 使用二分法(把元素一分为二)
list_num = [12, 34, 54, 78, 101, 132, 136, 248, 567, 901, 1000]
find_num = 901 # 要找的数
def two(list_num):
num = len(list_num) // 2 # 把元素一分为二
if find_num >list_num[num]: # 如果要找的数,大于中间的数则向右边找
right_list=list_num[num+1:]
print(right_list)
two(right_list)
elif find_num < list_num[num]: # 如果要找的数,小于中间的数则向左边找
left_list=list_num[:num]
print(left_list)
two(left_list)
elif find_num == list_num[num]: # 如果正好等于则直接找到了。
print("Good,Find")
else: # 否则就是没找到
print("Not found")
two(list_num)
# 执行结果:
[136, 248, 567, 901, 1000]
[901, 1000]
[901]
Good,Find
注意 使用二分法,数据必须有序。
如果要查找的元素在开头 那么还没有依次遍历查找的效率高

 浙公网安备 33010602011771号
浙公网安备 33010602011771号