

字符编码和python文件操作
字符编码和文件操作
1. 字符编码

1.1 什么是字符编码
计算机中储存的信息都是用二进制数表示的;而我们在屏幕上看到的英文、汉字等字符是二进制数转换之后的结果。通俗的说,按照何种规则将字符存储在计算机中,如'a'用什么表示,称为"编码";反之,将存储在计算机中的二进制数解析显示出来,称为”解码”。
1.2 字符编码的发展史
1.2.1 ASCII码
现代计算机起源于美国,所以当时美国就发明了一套只适用于它们的编码方式,即ASCII码。
ASCII编码:将ASCII字符集转换为计算机可以接受的数字系统的数的规则。ASCII 设计时只有128个字符,为了表示更多的欧洲常用字符对ASCII进行了扩展,ASCII扩展字符集使用8位(bits)表示一个字符,共256字符。
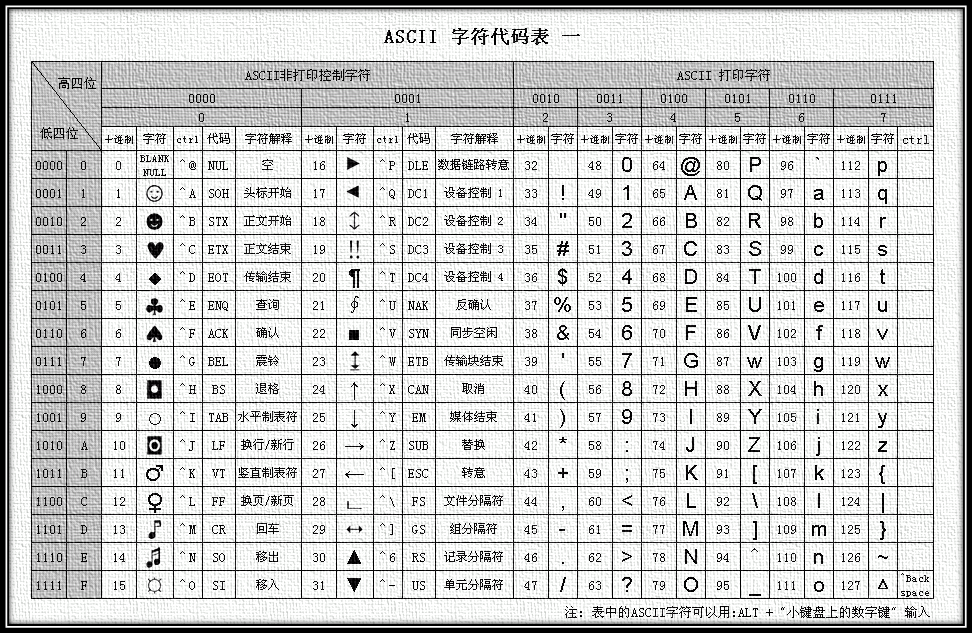
ASCII的最大缺点是只能显示26个基本拉丁字母、阿拉伯数字和英式标点符号,因此只能用于显示现代美国英语,对其他国家的语言无法支持。
1.2.2 各国编码
计算机出现后很长一段时间只用应用于美国及西方一些发达国家,ASCII能够很好满足用户的需求。但是计算机进入我国之后,为了显示中文,必须设计一套编码规则用于将汉字转换为计算机可以接受的数字系统的数。
国内专家把那些127号之后的奇异符号们(即EASCII)取消掉,规定:一个小于127的字符的意义与原来相同,但两个大于127的字符连在一起时,就表示一个汉字。这样我们就可以组合出大约7000多个简体汉字了(实际上只有6763个汉字)。在这些编码里,还把数学符号、罗马希腊的 字母、日文的假名们都编进去了,连在ASCII里本来就有的数字、标点、字母都统统重新编了两个字节长的编码,这就是常说的"全角"字符,而原来在127号以下的那些就叫"半角"字符了。这就是就是GB2312。
GB2312的出现,基本满足了汉字的计算机处理需要,它所收录的汉字已经覆盖中国大陆99.75%的使用频率。对于人名、古汉语等方面出现的罕用字,GB2312不能处理,这导致了后来GBK及GB 18030汉字字符集的出现。
GB 18030,全称:国家标准GB 18030-2005《信息技术 中文编码字符集》,是中华人民共和国现时最新的内码字集,是GB 18030-2000《信息技术 信息交换用汉字编码字符集 基本集的扩充》的修订版。与GB 2312-1980完全兼容,与GBK基本兼容,支持GB 13000及Unicode的全部统一汉字,共收录汉字70244个。
现行版本为国家质量监督检验总局和中国国家标准化管理委员会于2005年11月8日发布,2006年5月1日实施。此规格为在中国境内所有软件产品支持的强制规格。
当计算机传到世界各个国家时,为了适合当地语言和字符,设计和实现类似GB232/GBK的一套编码,各个国家各搞一套,在本地使用没有问题,一旦出现在网络中,由于不兼容,互相访问就出现了乱码现象。为了解决这个问题就出现了Unicode
1.2.3 Unicode
Unicode(统一码、万国码、单一码、标准万国码)是业界的一种标准。Unicode编码系统为表达任意语言的任意字符而设计。它使用4字节的数字来表达每个字母、符号,或者表意文字(ideograph)。每个数字代表唯一的至少在某种语言中使用的符号。
它可以使电脑得以体现世界上数十种文字的系统。Unicode 是基于通用字符集(Universal Character Set)的标准来发展,并且同时也以书本的形式对外发表,目前为止Unicode 就已经包含了超过十万个字符,Unicode 组织(The Unicode Consortium)是由一个非营利性的机构所运作,并主导 Unicode 的后续发展,其目标在于:将既有的字符编码方案以Unicode 编码方案来加以取代,特别是既有的方案在多语环境下,皆仅有有限的空间以及不兼容的问题。
Unicode字符编码方案:UTF-32、UTF-16、UTF-8
-
UTF-32
使用4字节的数字来表达每个字母、符号,或者表意文字(ideograph),每个数字代表唯一的至少在某种语言中使用的符号的编码方案。对每个字符都使用4字节。就空间而言,是非常没有效率的。即固定占用4个字节。
-
UTF-16
UTF-16编码最明显的优点是它在空间效率上比UTF-32高两倍,因为每个字符只需要2个字节来存储,而不是UTF-32中的4个字节。虽然它UTF-16在空间上效率高,超过两个字节也会扩容四个字节存储。但它每个字符都占两个字节,在存单个字节的时候也会浪费一些空间。
-
UTF-8
UTF-8(8-bit Unicode Transformation Format)是一种针对Unicode的可变长度字符编码(定长码),也是一种前缀码。它可以用来表示Unicode标准中的任何字符,且其编码中的第一个字节仍与ASCII兼容,这使得原来处理ASCII字符的软件无须或只须做少部份修改,即可继续使用。因此,它逐渐成为电子邮件、网页及其他存储或传送文字的应用中,优先采用的编码。互联网工程工作小组(IETF)要求所有互联网协议都必须支持UTF-8编码。
UTF-8使用一至四个字节为每个字符编码(兼容ASCII编码):
ASCII字符只需一个字节编码
带有附加符号的拉丁文、希腊文、西里尔字母、亚美尼亚语、希伯来文、阿拉伯文、叙利亚文及它拿字母则需要二个字节编码
其他基本多文种平面(BMP)中的字符(这包含了大部分常用字)使用三个字节编码
其他极少使用的Unicode辅助平面的字符使用四字节编码。
在处理经常会用到的ASCII字符方面非常有效。在处理扩展的拉丁字符集方面也不比UTF-16差。对于中文字符来说,比UTF-32要好。
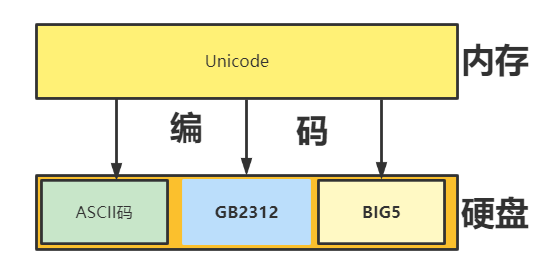
现在默认使用的编码是utf8
注意软件是存放于硬盘的,而运行软件是要将软件加载到内存的,面对硬盘中存放的各种传统编码的软件,想让我们的计算机能够将它们全都正常运行而不出现乱码,内存中必须有一种兼容万国的编码,并且该编码需要与其他编码有相对应的映射/转换关系。
1.3 字符编码练习
如何解决文件乱码问题:文件当初以什么格式编码的 打开的时候就以什么格式解码。
python解释器中python2版本的编码方式默认为ACSII码,python3版本的编码方式默认为UTF8
python2版本中使用UTF-8
[root@hans ~]#cat py2.py
str1 = "你好"
print(str1)
[root@hans ~]# python --version
Python 2.7.5
[root@hans ~]# python py2.py
File "py2.py", line 1
SyntaxError: Non-ASCII character '\xe4' in file py2.py on line 1, but no encoding declared; see http://www.python.org/peps/pep-0263.html for details
# 使用python2版本执行的时候就会报错。
解决方法:
[root@hans ~]#cat py2.py
#coding:utf8 #在开头写入本行,告诉解释器以下编码使用utf8
str1 = u"你好" #定义字符串前面要加一个小u,告诉解释器这是一个unicode.
print(str1)
1.4 编码和解码
什么是编码(encode)?
将我们能够读懂的字符按照对应的编码类型转换成计算机能够识别的0和1。
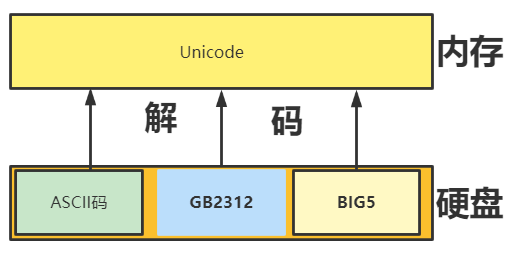
什么是解码(decode)?
将0和1根据对应的解码类型转换成我们能够读懂的字符
示例:
#编码
str1 = "好好学习 天天向上"
enstr = str1.encode('utf8') #将字符串按utf8编码
print(enstr)
打印结果:
b'\xe5\xa5\xbd\xe5\xa5\xbd\xe5\xad\xa6\xe4\xb9\xa0 \xe5\xa4\xa9\xe5\xa4\xa9\xe5\x90\x91\xe4\xb8\x8a'
#解码:
destr = enstr.decode("utf8")
print(destr)
#打印结果:
好好学习 天天向上
#完整脚本:
[root@hans_tencent_centos82 ~]# cat deencode.py
str1 = "好好学习 天天向上"
enstr = str1.encode('utf8')
print(enstr)
destr = enstr.decode("utf8")
print(destr)
#执行结果:
[root@hans_tencent_centos82 ~]# python3 deencode.py
b'\xe5\xa5\xbd\xe5\xa5\xbd\xe5\xad\xa6\xe4\xb9\xa0 \xe5\xa4\xa9\xe5\xa4\xa9\xe5\x90\x91\xe4\xb8\x8a'
好好学习 天天向上
2. 文件操作
使用python操作文件主要有三步:
- 打开文件
- 操作文件
- 关闭文件
使用python操作文件方法一:
2.1 open()使用方法:
open(file, mode='r', buffering=-1, encoding=None, errors=None, newline=None, closefd=True, opener=None)
参数说明:
- file: 必需,文件路径(相对或者绝对路径)。
- mode: 可选,文件打开模式
- buffering: 设置缓冲
- encoding: 一般使用utf8
- errors: 报错级别
- newline: 区分换行符
- closefd: 传入的file参数类型
- opener: 设置自定义开启器,开启器的返回值必须是一个打开的文件描述符。
mode 参数有:
| 模式 | 描述 |
|---|---|
| r | 以只读方式打开文件。文件的指针将会放在文件的开头。这是默认模式。 |
| w | 打开一个文件只用于写入。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。 |
| a | 打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。也就是说,新的内容将会被写入到已有内容之后。如果该文件不存在,创建新文件进行写入 |
示例:
# a.txt文件内容
There's a fire starting in my heart
Reaching a fever pitch and it's bringing me out the dark
Finally I can see you crystal clear
Go ahead and sell me out and I'll lay your ship bare
See how I leave with every piece of you
Don't underestimate the things that I will do
There's a fire starting in my heart
# 脚本:mod:r 只读模式
[root@hans_tencent_centos82 tmp]# cat test.py
#!/usr/bin/env python3
file1 = 'a.txt'
res = open(file1, 'r', encoding='utf8')
print(res.read())
res.close()
#在计算机中有些符号加字母有特殊意义如\a或\n,如果直接写到脚本里可能会引起歧义,可以使用r取消
file1 = r'D:\pycharm\codestudy\n.txt'
r就是你写的什么就原样处理。
# 执行脚本
[root@hans_tencent_centos82 tmp]# python3 test.py
There's a fire starting in my heart
Reaching a fever pitch and it's bringing me out the dark
Finally I can see you crystal clear
Go ahead and sell me out and I'll lay your ship bare
See how I leave with every piece of you
Don't underestimate the things that I will do
There's a fire starting in my heart
# 如果文件不存在,则会报错:
[root@hans_tencent_centos82 tmp]# python3 test.py
Traceback (most recent call last):
File "test.py", line 5, in <module>
res = open(file1, 'r', encoding='utf8')
FileNotFoundError: [Errno 2] No such file or directory: 'b.txt'
# 脚本: mod:w 只写模式
# 如果文件存在:
[root@hans_tencent_centos82 tmp]# cat test.py
#!/usr/bin/env python3
file1 = 'a.txt'
res = open(file1, 'w', encoding='utf8')
res.write("Hello world!\n")
res.close()
[root@hans_tencent_centos82 tmp]# python3 test.py
[root@hans_tencent_centos82 tmp]# cat a.txt
Hello world!
# 发现a.txt文件之前的内容不在了,只有最后写入的一行。
# 文件存在则先清空文件内容,再执行写入操作。
# 如果文件不存在:
[root@hans_tencent_centos82 tmp]# ls -lrt b.txt # 文件不存在
ls: cannot access 'b.txt': No such file or directory
[root@hans_tencent_centos82 tmp]# cat test.py
#!/usr/bin/env python3
file1 = 'b.txt'
res = open(file1, 'w', encoding='utf8')
res.write("Hi!\n")
res.close()
[root@hans_tencent_centos82 tmp]# python3 test.py
[root@hans_tencent_centos82 tmp]# cat b.txt
Hi!
# 如果文件不存在会自动创建
使用open()函数处理文件的时候有时会遗忘关闭文件,可以使用with替代。
2.2 上下文管理with()
上下文管理器 是一个对象,它定义了在执行 with 语句时要建立的运行时上下文。 上下文管理器处理进入和退出所需运行时上下文以执行代码块。 通常使用 with 语句,但是也可以通过直接调用它们的方法来使用。
上下文管理器的典型用法包括保存和恢复各种全局状态,锁定和解锁资源,关闭打开的文件等等。
示例:
# 读:
file1 = 'a.txt'
with open(file1,'r',encoding='utf8') as f:
print(f.read())
结果:
Hello world!
# 写:
file1 = 'a.txt'
with open(file1,'w',encoding='utf8') as f:
f.write('Hi\n')
#结果:
Hi
#依然会把之前的清空然后重建。
2.3 追加模式
上面演示的内容,只读的不能写,能写的不能保留之前的内容,如果要写的时候保留之前的内容,可以使用a模式。
示例:
# 当前a.txt文件内容:
Hello world!
#添加内容:
If you miss the train I'm on
You will know that I am gone
You can hear the whistle blow a hundred miles
A hundred miles, a hundred miles
# 脚本:
[root@hans_tencent_centos82 tmp]# cat test.py
#!/usr/bin/env python3
file1 = 'a.txt'
with open(file1,'a',encoding='utf8') as f:
f.write("If you miss the train I'm on\n")
f.write("You will know that I am gone\n")
f.write("You can hear the whistle blow a hundred miles\n")
f.write("A hundred miles, a hundred miles\n")
# 执行结果:
[root@hans_tencent_centos82 tmp]# cat a.txt
Hello world!
If you miss the train I'm on
You will know that I am gone
You can hear the whistle blow a hundred miles
A hundred miles, a hundred miles
# 文件不存在:
[root@hans_tencent_centos82 tmp]# ls -lrt b.txt
ls: cannot access 'b.txt': No such file or directory
#脚本:
with open(r'b.txt', 'a', encoding='utf8') as f:
f.write("If you miss the train I'm on\n")
f.write("You will know that I am gone\n")
f.write("You can hear the whistle blow a hundred miles\n")
f.write("A hundred miles, a hundred miles\n")
# 执行结果:
[root@hans_tencent_centos82 tmp]# ls -lrt b.txt
-rw-r--r-- 1 root root 137 Nov 11 15:03 b.txt
[root@hans_tencent_centos82 tmp]# cat b.txt
If you miss the train I'm on
You will know that I am gone
You can hear the whistle blow a hundred miles
A hundred miles, a hundred miles
推荐使用with语法.
如果在有些操作中,只是补充语法结构,而不任何操作可以使用:
pass或...
2.4 文件操作之读系列
-
read()
# 代码: with open(r'b.txt', 'r', encoding='utf8') as f: print(f.read()) # 执行结果: If you miss the train I'm on You will know that I am gone You can hear the whistle blow a hundred miles A hundred miles, a hundred miles # read() 一次性读取文件内所有的内容 -
readline()
# 代码: with open(r'b.txt', 'r', encoding='utf8') as f: print(f.readline()) #执行结果: If you miss the train I'm on # 只打印出来一行 # readline() 每次只读文件一行内容 -
readines()
# 代码 with open(r'b.txt', 'r', encoding='utf8') as f: print(f.readlines()) # 执行结果: ["If you miss the train I'm on\n", 'You will know that I am gone\n', 'You can hear the whistle blow a hundred miles\n', 'A hundred miles, a hundred miles\n'] # readines() 读取文件所有的内容,所以内容组成一个列表 每个元素是文件的每行内容。 -
readable()
# 代码 with open(r'b.txt', 'r', encoding='utf8') as f: print(f.readable()) # 执行结果: True # readable() 判断当前文件是否具备读的能力 -
读文件方法的选择
上面有三种读文件的方法(
read(),readline(),readlines()),具体用哪个?# 使用read()读文件,它会把文件内容全部读出来,该方法在读取大文件的时候,可能会造成内存溢出的情况,解决这个问题的策略就是逐行读取文件内容 with open(r'b.txt', 'r', encoding='utf8') as f: for line in f: # 逐行读文件,推荐使用 print(line) # readlines() 该方法也会把文件内容全部读出来 # readline() 该方法每次可以只能读一行注意:以后涉及到多行文件内容的情况一般都是采用
for循环读取
2.5 文件操作之写系列
-
write()
# 代码 with open(r'b.txt', 'w', encoding='utf8') as f: f.write("Hello World!\n") # 执行结果: [tmp]# cat b.txt Hello World! # 写入int类型 with open(r'b.txt', 'w', encoding='utf8') as f: f.write(123) # 报错信息: Traceback (most recent call last): File "e.py", line 4, in <module> f.write(123) TypeError: write() argument must be str, not int # write() 往文件内写入文本内容,只能写字符串类型。 -
writelines()
# 代码: with open(r'b.txt', 'w', encoding='utf8') as f: f.writelines(["apple", "cherry", "pipeapple"]) f.writelines("hahah\n") f.writelines(["apple\n", "cherry\n", "pipeapple\n"]) # 执行结果: applecherrypipeapple hahah apple cherry pipeapple # 可以将列表中多个字符串元素全部写入,默认情况把列表中的元素都放一行,中间不分隔。 -
writable()
# 代码: with open(r'b.txt', 'w', encoding='utf8') as f: print(f.writable()) # 执行结果: True # 判断当前文件是否具备写的能力 -
flush()
with open(r'b.txt', 'w', encoding='utf8') as f: f.writelines("hahah\n") f.writelines(["apple\n", "cherry\n", "pipeapple\n"]) f.flush() 直接将内存内文件数据写到硬盘,相当于写文件时手动点保存
2.6 文件操作模式
-
文件模式:
t文件模式为操作文件的默认模式,在写
mod类型时,r,w,a模式其实是rt,wt,at,在这种模下所有操作都是以字符串为基本单位在该模式下必须要指定
encoding参数该模式下只能操作文本文件
-
二进制模式:
b在该模式下可以操作任意类型的文件
该模式所有操作都是以
bytes类型为基本单位该模式下不需要指定
encoding参数使用二进制模式时要指定:
rb、wb、ab
read()括号内可以放数字# e.txt Hello world # 代码: # t 模式打开 with open(r'e.txt', 'r') as f: # t 模式打开 print(f.read(5)) # 结果 Hello # b 模式打开 with open(r'e.txt', 'rb') as f: print(f.read(4)) # 结果 Hell- 在t模式下表示字符个数
- 在b模式下表示字节个数
英文字符统一使用一个
bytes来表示
中文字符统一使用三个bytes来表示二进制模式练习:
# 简单复制任意类型文件 #脚本: sourceFile = input("please input source file:").strip() descFile = input("please input destination file:").strip() print("from %s copy to %s" % (sourceFile, descFile)) with open(sourceFile, 'rb') as sf: with open(descFile, 'wb') as df: for sline in sf: df.write(sline) print("copy success") # 执行结果: please input source file>>>:/root/99 please input destination file>>>:/tmp/99 from /root/99 copy to /tmp/99 copy success # 查看结果: ls -lrt /root/99 /tmp/99 -rwxr-xr-x 1 root root 17480 Nov 5 20:24 /root/99 -rw-r--r-- 1 root root 17480 Nov 11 17:00 /tmp/99
2.7 文件内移动光标seek()
seek()用法:
seek(offset,whence)
offset表示位移量
始终是以字节为最小单位
正数从左往右移动
负数从右往左移动
whence表示模式
0:以文件开头为参考系(支持t b两种模式)
1:只支持b模式 以当前位置为参考系
2:只支持b模式 以文件末尾为参考系
# 测试文件:c.txt
寥落古行宫
宫花寂寞红
白头宫女在
闲坐说玄宗
# 示例:0模式,以文件开头为参考
# 代码
with open(r'c.txt', 'r', encoding='utf8') as f:
print(f.read()) # 直接把文件内容读完,这时光标在尾部
f.seek(3,0) # 0模式,表示光标到文件开头,然后向右移3个字节
print(f.read()) # 光标从开头开始右移3个字节,所以开头的第一个字不会打印(一个汉字一般占三个字节)
# 结果:
寥落古行宫
宫花寂寞红
白头宫女在
闲坐说玄宗
落古行宫
宫花寂寞红
白头宫女在
闲坐说玄宗
# 示例: 1模式,以当前位置为参考
# 代码
with open(r'c.txt', 'rb') as f: # 1只能用在b模式下,所以打开文件用rb.
print(f.read().decode('utf8'))
f.seek(3,1) # 从当前位置向右位三个字节
print(f.read().decode('utf8'))
# 结果:
寥落古行宫
宫花寂寞红
白头宫女在
闲坐说玄宗
#发现打印完后f.seek(3,1)移动后为空,因为1为当前位置,f.read()光标已经在文件末尾,再向右边移三个字节是没有内容的。所以打印为空。
#把3改为-3让它向左移动。
f.seek(-3,1) #执行报错:
print(f.read().decode('utf8'))
UnicodeDecodeError: 'utf-8' codec can't decode byte 0xae in position 0: invalid start byte
# 但是改为-4就可以打印:
with open(r'c.txt', 'rb') as f:
print(f.read().decode('utf8'))
f.seek(-4,1) # 从当前位置向左位4个字节
print(f.read().decode('utf8'))
# 打印结果:
寥落古行宫
宫花寂寞红
白头宫女在
闲坐说玄宗
宗
#一直说汉字占三个字节,为什么-3的时候报错,因为在最后都有结束符,所以它占一个字节。
# 可以使用tell()函数来打印当前所在的位置:
ith open(r'c.txt', 'rb') as f:
print(f.read().decode('utf8'))
print(f.tell())
#执行结果:
寥落古行宫
宫花寂寞红
白头宫女在
闲坐说玄宗
64
# 3 * 5 * 4 + 4 = 64; 一个汉字3个字节,一行5个汉字,一共4行再加4个结束符。
# 如果只打印最后两个字 则设置为f.seek(-7,1)
with open(r'c.txt', 'rb') as f:
print(f.read().decode('utf8'))
f.seek(-7,1)
print(f.read().decode('utf8'))
# 执行结果:
寥落古行宫
宫花寂寞红
白头宫女在
闲坐说玄宗
玄宗
# 示例: 2模式,以文件末尾为参考
# 代码:
with open(r'c.txt', 'rb') as f: # 2只能用在b模式下,所以打开文件用rb.
f.seek(-7,2) # 2模式直接到文件末尾,然后向左移7个字节
print(f.read().decode('utf8'))
# 执行结果:
玄宗
2.8 当前在文件内的位置tell()
使用tell()可以看到当前在文件内的位置
# 代码:
with open(r'c.txt', 'rb') as f:
print(f.tell()) # 打开文件后直接打印当前做在的位置, 0
f.seek(9,0) # 以开头为参考向右移动9个字节,即跳过了寥落古三个字。
print(f.tell()) # 打印现在所在的位置, 9
print(f.read().decode('utf8')) # 打印第9个字节后面的全部内容
print(f.tell()) # 打印现在所在的位置, 64,即文件的尾部
# 结果:
0
9
行宫
宫花寂寞红
白头宫女在
闲坐说玄宗
64
2.9 文件内容修改
文件内容修改有两个方法:
-
覆盖
# 原文件d.txt If you miss the train I'm on You will know that I am gone You can hear the whistle blow a hundred miles A hundred miles, a hundred miles # 要把hundred替换为HUNDRED # 代码: with open(r'd.txt', 'r', encoding='utf8') as f1: data = f1.read() with open(r'd.txt', 'w', encoding='utf8') as f2: f2.write(data.replace('hundred', 'HUNDRED')) # 执行结果: If you miss the train I'm on You will know that I am gone You can hear the whistle blow a HUNDRED miles A HUNDRED miles, a HUNDRED miles -
新建
# 把上面修改为大写的HUNDRED再修改为小写hundred # 代码: import os with open(r'd.txt', 'r', encoding='utf8') as f1, open(r'd.txt.bak', 'w', encoding='utf8') as f2: for line in f1: f2.write(line.replace('HUNDRED', 'hundred')) os.remove("d.txt") os.rename("d.txt.bak", "d.txt") # 执行结果: If you miss the train I'm on You will know that I am gone You can hear the whistle blow a hundred miles A hundred miles, a hundred miles

 浙公网安备 33010602011771号
浙公网安备 33010602011771号