

Python数据类型
- 1. 数据类型
- 2 整型:int
- 3 浮点型:float
- 4. 字符串:str
- 4.1 str内置方法
- 4.1.1 类型转换,任意类型都可以转成字符串类型
- 4.1.2 索引取值
- 4.1.3 切片(前开后合,顾头不顾尾)
- 4.1.4 步长操作
- 4.1.5 索引支持负数
- 4.1.6 统计字符串内部字符的长度
- 4.1.7 移除字符串首尾指定的字符(strip())
- 4.1.8 按照指定的字符切割字符串(split())
- 4.1.9 转换字母大小写
- 4.1.10 判断字符串是否以指定的字符开头
- 4.1.11 判断字符串是否以指定的字符结尾
- 4.1.12字符串格式化输出
format() - 4.1.13 字符串的拼接
- 4.1.14 替换字符串中指定的字符
- 4.1.15 判断字符串中是否是纯数字
- 4.1.16 开头首字母大写和所有单词首字母大写
- 4.1.17 小写变大写,大写变小写
- 4.1.18 查看指定字符的索引值
- 4.1.19 统计某个字符出现的次数
- 4.1.20 其他(居中,左右对齐,只包含字母和既可包含数字也可包含字母)
- 4.1 str内置方法
- 5. 列表:list
- 6. 字典:dict
- 7. 布尔值:bool
- 8. 元组:tuple
- 9. 集合:set
- 10. 用户交互
- 11. 格式化输出
- 12. 运算符
- 13. 逻辑运算符:与或非
- 16. 可变类型和不可变类型
- 17. 深拷贝和浅拷贝

1. 数据类型
1.1 什么是数据类型
数据类型是一个值的集合和定义在此集合上一组操作(通常是增删改查或者操作读写的方法)的总称。
数据类型又分:
- 原子类型:比如编程语言的int,double,char,byte,boolean。
- 复合类型:又称结构类型,通过原子类型封装的更复杂的类型,比如面向对象语言里面的类
python 中常用数据类型包括: int、float,str、list、dict、bool、tuple、set
2 整型:int
整型:没有小数部分的数据,即整数。在计算机中使用int表示。
示例:
>>> num = 9
>>> type(num)
<class 'int'>
2.1 int()函数
int()函数主要是类型转换。int()在做类型转换的时候 只能转换纯数字
>>> num = '123'
>>> type(num)
<class 'str'>
>>> num = int(num)
>>> type(num)
<class 'int'>
int()还可以做进制数转换
>>> bin(10) #把十进制10转成二进制
'0b1010'
>>> oct(10) #把十进制10转成八进制
'0o12'
>>> hex(10) #把十进制10转成十六进制
'0xa'
#利用int()把二进制,八进制,十六进制转换十进制
>>> int('0b1010', 2) #把二进制转换十进制
10
>>> int('0o12', 8) #把八进制转换十进制
10
>>> int('0xa', 16) #把十六进制转换十进制
10
3 浮点型:float
浮点型:简单来说就是表示带有小数的数据,即小数。
示例:
>>> salary = 30000.5
>>> type(salary)
<class 'float'>
3.1 float()函数
float()做类型转换。
>>> fnum = '123.456'
>>> type(fnum)
<class 'str'>
>>> fnum = float(fnum)
>>> type(fnum)
<class 'float'>
>>> num = 123
>>> type(num)
<class 'int'>
>>> num = float(num)
>>> type(num)
<class 'float'>
>>> num
123.0
4. 字符串:str
字符串:是由零个或多个字符组成的有限序列.
定义字符串:
- 单引号:
'允许包含有 "双" 引号' - 双引号:
"允许包含有 '单' 引号"。 - 三重引号:
'''三重单引号''',"""三重双引号"""
使用三重引号的字符串可以跨越多行 —— 其中所有的空白字符都将包含在该字符串字面值中.
示例:
1. 单引号
name = 'Hans'
2. 双引号
name = "Hans"
3. 三重引号
name = '''Hans'''
name = """Hans"""
>>> name = 'Hans'
>>> type(name)
<class 'str'>
>>> info = "My name is 'Hans'"
>>> print(info)
My name is 'Hans'
>>> type(info)
<class 'str'>
>>> pythonzen = """
... Beautiful is better than ugly.
... Explicit is better than implicit.
... Simple is better than complex.
... """
>>> print(pythonzen)
Beautiful is better than ugly.
Explicit is better than implicit.
Simple is better than complex.
字符串可以使用 + 和* 运算符,
+为拼接
>>> h = "Hello"
>>> name = "'Hans"
>>> h + name
'HelloHans'
//不过不推荐使用这种方式拼接,比较消耗内存资源,可以使用join()
* n 为连接不换行打印n次
>>> name * 5
'HansHansHansHansHans'
4.1 str内置方法
4.1.1 类型转换,任意类型都可以转成字符串类型
>>> num = 123
>>> type(num)
<class 'int'>
>>> num = str(num) #int类型转字符串
>>> type(num)
<class 'str'>
>>> fnum = 123.45
>>> type(fnum)
<class 'float'>
>>> fnum = str(fnum) #float类型转字符串
>>> type(fnum)
<class 'str'>
>>> list1 = [1, 2, 3, 4]
>>> list1 = str(list1) #list类型转字符串
>>> type(list1)
<class 'str'>
>>> list1
'[1, 2, 3, 4]'
>>> tuple1 = (1, 2, 3, 4)
>>> tuple1 = str(tuple1) #tuple类型转字符串
>>> type(tuple1)
<class 'str'>
>>> dict1 = {'name':'Hans', 'age': 18}
>>> dict1 = str(dict1) #dict类型转字符串
>>> type(dict1)
<class 'str'>
>>> set1 = {1, 2, 3, 4}
>>> set1 = str(set1) #set类型转字符串
>>> type(set1)
<class 'str'>
4.1.2 索引取值
>>> res = "Hello World!"
>>> res[0] # 索引取值下标从0开始
'H'
4.1.3 切片(前开后合,顾头不顾尾)
>>> res[2:4] #切出来下标为2到下标为4中间的数据,其中包括下标为2的,但不包括下标为4的
'll'
4.1.4 步长操作
>>> res[1:8:2]
'el o'
4.1.5 索引支持负数
>>> res[-1] #最后一位
'!'
>>> res
'Hello World!'
>>> res[-5:-1] #取-5到-1的元素,从左向右,并且不包括-1
'orld'
4.1.6 统计字符串内部字符的长度
>>> res
'Hello World!'
>>> len(res)
12
4.1.7 移除字符串首尾指定的字符(strip())
>>> name = " hans "
>>> name
' hans '
>>> len(name)
12
>>> name = name.strip() # 默认取掉首尾的空格
>>> name
'hans'
>>> len(name)
4
#去掉左边的空格
>>> name = " hans "
>>> name
' hans '
>>> name.lstrip()
'hans '
#去掉右边的空格
>>> name
' hans '
>>> name.rstrip()
' hans'
#strip()默认去除空格,可以设置去除别的符号
>>> name = '###Hans####'
>>> name
'###Hans####'
>>> name.strip('#')
'Hans'
示例,去除用户输入时在关键字左右的空格:
>>> name = input("Your Name:")
Your Name: Hans
>>> name
' Hans '
>>> name = name.strip()
>>> name
'Hans
或者:
>>> name = input("Your Name:").strip() #在用户输入时直接去掉空格
Your Name: hans
>>> name
'hans'
4.1.8 按照指定的字符切割字符串(split())
>>> str1 = "hans 18 study"
>>> str1.split() #默认以空格分隔
['hans', '18', 'study']
>>> str1 = "hans|18|study"
>>> str1
'hans|18|study'
>>> str1.split("|") #以‘|’分隔
['hans', '18', 'study']
>>> str1
'hans|18|study'
>>> str1.split("|", maxsplit=1) #只分隔一次,默认从左向右分隔
['hans', '18|study']
>>>
>>> str1.rsplit("|", maxsplit=1) #从右向左分隔,只分隔一次,
['hans|18', 'study']
#maxsplit为最大分隔的次数
4.1.9 转换字母大小写
name = 'hans' //全部转成大写字母
name.upper()
'HANS'
name="HANS"//全部转成小写字母
name.lower()
'hans'
"""
实际案例:图片验证码忽略大小写
思路:全部转大写或者小写再比对
"""
>>> code = "ACed08"
>>> inputCode = input("code:").strip()
code:ACED08
>>> if code.lower() == inputCode.lower():
... print("验证码正确")
...
验证码正确
1. 判断是否全为大写
>>> name
'HANS'
>>> name.isupper()
True
>>> name="Hans"
>>> name.isupper()
False
2. 判断是否全为小写
>>> name='hans'
>>> name.islower()
True
4.1.10 判断字符串是否以指定的字符开头
>>> str1 = "My name is 'Hans'"
>>> str1.startswith("my")
False
>>> str1.startswith("MY")
False
>>> str1.startswith("My")
True
>>> str1.startswith("M")
True
>>> str1.startswith("My ")
True
>>> str1.startswith("My name")
True
4.1.11 判断字符串是否以指定的字符结尾
>>> str1 = "My name is Hans"
>>> str1.endswith("hans")
False
>>> str1.endswith("Hans")
True
>>> str1.endswith("ans")
True
>>> str1.endswith("s")
True
4.1.12字符串格式化输出format()
第一种方法 相当于占位符
>>> str1 = "My name is {}, age is {}"
>>> str1.format("Hans", 18)
'My name is Hans, age is 18'
第二种方法 大括号内写索引值可以打破顺序 并且可以反复使用相同位置的数据
>>> str1 = "My name is {0}, age is {1}"
>>> str1.format("Hans", 18)
'My name is Hans, age is 18'
>>> str1 = "My name is {0}, age is {1}, Hi {0}"
>>> str1.format("Hans", 18)
'My name is Hans, age is 18, Hi Hans'
第三种方法 大括号内写变量名
>>> str1 = "My name is {name}, age is {age}, Hi {name}"
>>> str1.format(name = "Hans", age = 18)
'My name is Hans, age is 18, Hi Hans'
4.1.13 字符串的拼接
方法一: 使用加号(+)
>>> print("Hello" + "world")
Helloworld
方法二: 使用join
>>> l1 = ["apple", 'banana', 'pear', 'charry']
>>> "|".join(l1)
'apple|banana|pear|charry'
>>> "#".join(l1)
'apple#banana#pear#charry'
>>> " ".join(l1)
'apple banana pear charry'
join()只适用于字符串。不能和别的类型拼接
>>> l1 = [1, 2, 3, "a"]
>>> '|'.join(l1)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: sequence item 0: expected str instance, int found
>>> l1 = [1, 2, 3, 4]
>>> ("|").join(l1)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: sequence item 0: expected str instance, int found
注意:join()只适用于字符串。不能用的别的类型上,而且也不能和别的类型拼接(在python不同数据类型之间无法直接操作)
4.1.14 替换字符串中指定的字符
>>> str2 = ("My name is Hans, Hans is my name")
>>> str2
'My name is Hans, Hans is my name'
>>> str2.replace("Hans", "Joy")
'My name is Joy, Joy is my name'
#默认替换字符串中所有匹配到的
#还可以替换指定个数
>>> str2.replace("Hans", "Joy",1)
'My name is Joy, Hans is my name'
>>> str2 = ("My name is Hans, Hans is my name, Hi Hans")
>>> str2.replace("Hans", "Joy",2)
'My name is Joy, Joy is my name, Hi Hans'
4.1.15 判断字符串中是否是纯数字
>>> name = "Hans"
>>> name.isdigit()
False
>>> name = "Hans123"
>>> name.isdigit()
False
>>> name = "123"
>>> name.isdigit()
True
#如果你只想让用户输入的是数字,可以利用这个来限制。
age = input("Please input your age:\n").strip()
if age.isdigit():
age = int(age)
else:
print("Please input digital.")
4.1.16 开头首字母大写和所有单词首字母大写
>>> str1 = "my name is Hans"
>>> str1.capitalize() #开头首字母大写
'My name is hans'
>>> str1.title() #所有单词首字母大写
'My Name Is Hans'
4.1.17 小写变大写,大写变小写
>>> str2
'My name is Hans, Hans is my name, Hi Hans'
>>> str2.swapcase() #小写变大写,大写变小写
'mY NAME IS hANS, hANS IS MY NAME, hI hANS'
4.1.18 查看指定字符的索引值
>>> str2
'My name is Hans, Hans is my name, Hi Hans'
>>> str2.find("H")
11
>>> print(str2.find('A')) #找不到返回-1
-1
#index()也可以找索引,但它找不到会报错。
>>> str2.index("H")
11
>>> str2.index("A")
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
ValueError: substring not found
4.1.19 统计某个字符出现的次数
>>> str2
'My name is Hans, Hans is my name, Hi Hans'
>>> str2.count("n")
5
>>> str2.count("Hans")
3
4.1.20 其他(居中,左右对齐,只包含字母和既可包含数字也可包含字母)
#1. center()居中
>>> name = 'Hans'
>>> name.center(14,'-') #
'-----Hans-----'
#2.左对齐
>>> name.ljust(9,'-')
'Hans-----'
#3.右对齐
>>> name.rjust(9,'-')
'-----Hans'
#4.只包含字母
>>> name.isalpha()
True
>>> name = "hans12"
>>> name.isalpha() #只能包含字母
False
#5.既可以包含数字也可以包含字母
>>> name.isalnum()
True
5. 列表:list
列表:列表是可变序列,通常用于存放相同类型元素的集合。
列表可以包含不同类型的元素,但一般情况下,各个元素的类型相同
创建列表:用方括号标注,逗号分隔的一组值,元素可以是任意数据类型
- 使用一对方括号来表示空列表:
[] - 使用方括号,其中的项以逗号分隔:
[a],[a, b, c]
示例:
>>> list1 = [1, 2, 3, 4, 5, 6, 7, 8, 9]
>>> type(list1)
<class 'list'>
利用下标(索引)可以随意取出列表中的值,下标的值从0开始。
//例如要把5取出来,由于下标从0开始,5所在的下标为4,所以:
>>> list1[4]
5
//定义一个列表,取出"second"
>>> list2 = [1, 2, 3,['A','B','C',["fist", "second"]]]
>>> list2[3][3][1]
'second'
列表类型是一个容器,它里面可以存放任意数量、任意类型的数据
5.1 list内置方法
5.1.1 类型转换
#列表list()只可以把可迭代的数据类型换成列表。如:字符串,元组,字典,集合。
# int和float类型不可以转成列表
>>> list(123)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: 'int' object is not iterable
>>> list(12.3)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: 'float' object is not iterable
#这两个类型都不是可迭代对象
#字符串转列表
>>> name
'hans12'
>>> list(name)
['h', 'a', 'n', 's', '1', '2']
#元组转列表
>>> list((1, 2, 3, 4))
[1, 2, 3, 4]
#字典转列表
>>> list({"name":"Hans","age":18})
['name', 'age']
#集合转列表
>>> list({'A', 'B', 'C', 'D', 'E'})
['B', 'E', 'C', 'D', 'A']
5.1.2 列表修改元素值,追加元素,插入元素和扩展元素
>>> l1 = ['apple', 'banana', 'pear', 'charry']
>>> l1[0] = "watermelon" #修改元素下标为0的值
>>> l1
['watermelon', 'banana', 'pear', 'charry']
#在列表尾部追加值
>>> l1.append('pineapple')
>>> l1
['watermelon', 'banana', 'pear', 'charry', 'pineapple']
>>> l1.append(["green", "yellow", "pink"])#添加一个列表
>>> l1
['watermelon', 'banana', 'pear', 'charry', 'pineapple', ['green', 'yellow', 'pink']]
# 插入元素
>>> l1
['watermelon', 'banana', 'pear', 'charry', 'pineapple', ['green', 'yellow', 'pink']]
>>> l1.insert(0,"orange") #在索引值为0的地方插入
>>> l1
['orange', 'watermelon', 'banana', 'pear', 'charry', 'pineapple', ['green', 'yellow', 'pink']]
#扩展元素(把两个列表合并成一个)
>>> l1
['orange', 'watermelon', 'banana', 'pear', 'charry', 'pineapple']
>>> l1.extend(['green', 'yellow', 'pink'])
>>> l1
['orange', 'watermelon', 'banana', 'pear', 'charry', 'pineapple', 'green', 'yellow', 'pink']
#其实extend()相当于for和append操作的组合
>>> firut = ['orange', 'watermelon', 'banana']
>>> color = ["green", "yellow", "pink"]
>>> for i in color:
firut.append(i)
>>> firut
['orange', 'watermelon', 'banana', 'green', 'yellow', 'pink']
5.1.3 列表删除数据
# 方法一: del
>>> firut = ['orange', 'watermelon', 'banana', 'green', 'yellow', 'pink']
>>> del firut[5]
>>> firut
['orange', 'watermelon', 'banana', 'green', 'yellow']
# 方法二: remove() 删除指定的元素值
>>> firut.remove('orange')
>>> firut
['watermelon', 'banana', 'green', 'yellow']
# 方法三: pop() 通过索引值把需要删除的元素弹出,括号内如果不写参数则默认弹出列表尾部元素
>>> firut = ['watermelon', 'banana', 'green', 'yellow']
>>> firut.pop() #默认最后一个
'yellow'
>>> firut
['watermelon', 'banana', 'green']
>>> firut.pop(0) #删除索引值为0的值
'watermelon'
>>> firut
['banana', 'green']
# 清空列表
firut.clear()
5.1.4 排序sort()
>>> list1 = [33, 44, 88, 77, 66, 2, 3, 1, 9, 10]
>>> list1.sort() #默认升序
>>> list1
[1, 2, 3, 9, 10, 33, 44, 66, 77, 88]
>>> list1.sort(reverse=True) #降序
>>> list1
[88, 77, 66, 44, 33, 10, 9, 3, 2, 1]
5.1.5 反转reverse()
>>> list1=[88, 77, 66, 44, 33, 10, 9, 3, 2, 1]
>>> list1.reverse() #顺序颠倒
>>> list1
[1, 2, 3, 9, 10, 33, 44, 66, 77, 88]
5.1.6 其他
>>> list1
[1, 2, 3, 9, 10, 33, 44, 66, 77, 88]
>>> list1[:] #打印出全部
[1, 2, 3, 9, 10, 33, 44, 66, 77, 88]
>>> list1[::-1] #前面没写表示全部打印,-1为步长,倒排
[88, 77, 66, 44, 33, 10, 9, 3, 2, 1]
>>> list1[:5] #从下标0开始到5(前开后合,打印到下标为4的值)
[1, 2, 3, 9, 10]
>>> list1[1:] #从下标1的元素到最后
[2, 3, 9, 10, 33, 44, 66, 77, 88]
# 列表比较:
>>> list1
[1, 2, 3, 9, 10, 33, 44, 66, 77, 88]
>>> list2 = [7, 8, 9]
>>> list2 > list1
True
# 列表比较运算采用相同索引元素比较 只要有一个比出了结果就直接得出结论
6. 字典:dict
字典:用于存放具有映射关系的数据。
字典相当于保存了两组数据,其中一组数据是关键数据,被称为 key;另一组数据可通过 key 来访问,被称为 value。
字典可以通过将以逗号分隔的 键: 值 对列表包含于花括号之内来创建,value可以是任意数据类型
字典可用多种方式来创建:
- 使用花括号内以逗号分隔
键: 值对的方式:{'jack': 4098, 'sjoerd': 4127}or{4098: 'jack', 4127: 'sjoerd'} - 使用字典推导式:
{},{x: x ** 2 for x in range(10)} - 使用类型构造器:
dict(),dict([('foo', 100), ('bar', 200)]),dict(foo=100, bar=200)
>>> person = {"name" : "Hans", "age" : 18, "gender" : "M", "phone" : "1234567890"}
>>> type(person)
<class 'dict'>
>>> person
{'name': 'Hans', 'age': 18, 'gender': 'M', 'phone': '1234567890'}
//字典取值使用键来取,即用key来取value.
>>> person['name']
'Hans'
>>> person['phone']
'1234567890'
练习:
定义一个字典{'name': 'Hans', 'age': 18, 'addr': ['中国', '上海', ['青浦区', 999, 602]]},取出里数字999.
>>> person_info = {
... "name" : "Hans",
... "age" : 18,
... "addr" : ["中国","上海", ["青浦区", 999, 602]]
... }
>>> person_info['addr'][2][1]
999
6.1 dict内置方法
6.1.1 按Key取值
>>> dict1 = {"name":"Hans", "age":18, "hobby":"study"}
>>> dict1["name"]
'Hans'
>>> dict1["passwd"] # 如果k不存在,这种取值方法会报错
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
KeyError: 'passwd'
# 推荐使用get方法取值,即是取不到值也不会报错,它返回一个'None'
>>> print(dict1.get("passwd"))
None
>>> dict1.get('name', '哈哈哈') # 如果Key存在返回key对应的value.
'Hans'
>>> dict1.get('password', '哈哈哈')# 如果Key存在返回key对应的value.否则返回自定义信息
'哈哈哈'
>>> dict1
{'name': 'Hans', 'age': 18, 'hobby': 'study'}
6.1.2 按Key修改值
>>> dict1['age']
18
>>> dict1['age'] = 28 # key存在则修改值
>>> dict1
{'name': 'Hans', 'age': 28, 'hobby': 'study'}
>>> dict1['password'] = 123 # Key不存在则新增k:v
>>> dict1
{'name': 'Hans', 'age': 28, 'hobby': 'study', 'password': 123}
6.1.3 统计字典内部键值对的个数
>>> dict1
{'name': 'Hans', 'age': 28, 'hobby': 'study', 'password': 123}
>>> len(dict1)
4
6.1.4 成员运算
>>> dict1
{'name': 'Hans', 'age': 28, 'hobby': 'study', 'password': 123}
>>> 'Hans' in dict1
False
>>> 'name' in dict1
True
# 字典做成员运算时只会判断Key里有没有那个值
6.1.5 删除元素
# 方法1:del
>>> dict1
{'name': 'Hans', 'age': 28, 'hobby': 'study', 'password': 123}
>>> del dict1["password"]
>>> dict1
{'name': 'Hans', 'age': 28, 'hobby': 'study'}
# 方法2:pop()指定K,返回V
>>> dict1
{'name': 'Hans', 'age': 28, 'hobby': 'study'}
>>> dict1.pop("age")
28
>>> dict1
{'name': 'Hans', 'hobby': 'study'}
# 方法3 popitem()弹出键值对(元组的方式)
>>> dict1
{'name': 'Hans', 'hobby': 'study'}
>>> dict1.popitem() # 前在的是Key后面的是value
('hobby', 'study')
>>> dict1
{'name': 'Hans'}
#清空字典
dict1.clear()
6.1.6 取出所有的Key
# 取出所有的Key
>>> dict1.keys() #python3版本会生成一个迭代器
dict_keys(['name', 'age', 'hobby'])
>>> dict1.keys() # python2版本直接生成一个列表
['hobby', 'age', 'name']
6.1.7 取出所有的vlaue
# 取出所有的Vaule
>>> dict1.values() # python3版本会生成一个迭代器
dict_values(['Hans', 18, 'study'])
>>> dict1.values() # python2版本直接生成一个列表
['study', 18, 'Hans']
6.1.8 取出全部的值(即取出key又取出value)
>>> dict1.items() # python3版本会生成一个迭代器
dict_items([('name', 'Hans'), ('age', 18), ('hobby', 'study')])
>>> dict1.items() # python2版本直接生成一个列表
[('hobby', 'study'), ('age', 18), ('name', 'Hans')]
# 元组内有两个元素 第一个是key第二个是value
#利用这个方法可以一次性取出全部key和value,也可以用for遍历:
>>> for k, v in dict1.items():
print("key is %s, value is %s" % (k, v))
key is name, value is Hans
key is age, value is 18
key is hobby, value is study
6.1.9 更新字典
>>> dict1 = {"name":"Hans", "age":18, "hobby":"study"}
>>> dict1.update({"age" : 20, "password" : 123})
>>> dict1
{'name': 'Hans', 'age': 20, 'hobby': 'study', 'password': 123}
6.1.10 初始化字典
>>> dict.fromkeys({"K1", "K2", "K3"})
{'K3': None, 'K1': None, 'K2': None}
>>> dict.fromkeys(["K1", "K2", "K3"])
{'K1': None, 'K2': None, 'K3': None}
>>> dict.fromkeys(("K1", "K2", "K3"))
{'K1': None, 'K2': None, 'K3': None}
# 常见问题
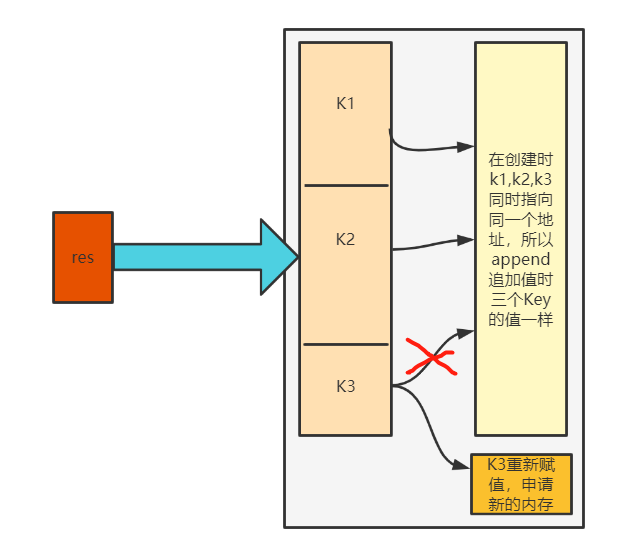
>>> res = dict.fromkeys(("K1", "K2", "K3"),[])
>>> res
{'K1': [], 'K2': [], 'K3': []}
>>> res['K1'].append(123)
>>> res #就会发现K1,K2,K3的值一样
{'K1': [123], 'K2': [123], 'K3': [123]}
# 这是因为在创建的时候它们使用的同一块内存地址,如果想让值不一样,要单独赋值:
>>> res['K3'] = [456, 789] # K3单独赋值相当于不
>>> res
{'K1': [123], 'K2': [123], 'K3': [456, 789]}
6.1.11 默认值setdefault()
>>> dict1
{'name': 'Hans', 'age': 20, 'hobby': 'study'}
>>> dict1.setdefault('age',18) #当KEY存在时,setdefalut不修改KEY的值,而是返回该该KEY的值
20
>>> dict1.setdefault('password',123) #当KEY不存在时,setdefalut会新增该键值对,并且返回新增KEY的值
123
>>> dict1
{'name': 'Hans', 'age': 20, 'hobby': 'study', 'password': 123}
>>>
7. 布尔值:bool
布尔:用于判断事物的对错 是否可行等。
布尔只有两个值:True和False.True表示真,False表示假
>>> type(True)
<class 'bool'>
>>> type(False)
<class 'bool'>
实际上bool类型是int类型的一个子类
>>> bool.__bases__
(<class 'int'>,)
>>> True + 1
2
>>> False + 1
1
>>> bool(0)
False
>>> bool(1)
True
所以,True代表1,False代表0。
在python中所有的数据类型都可以转成布尔值。
布尔值为False的有:
-
整数值0、浮点数值0.0等、空字符串都为假
"" -
None为假
-
空数据对象都是假,比如
[]、{}、()等
其他情况一律为True。
针对布尔值的变量名一般采用is开头
is_ok
is_delete
8. 元组:tuple
Python的元组与列表类似,不同之处在于元组的元素不能修改,元组是不可变序列。
元组使用小括号,列表使用方括号。
创建元组: 用小括号中添加元素,并使用逗号隔开。
可以用多种方式构建元组:
- 使用一对圆括号来表示空元组:
() - 使用一个后缀的逗号来表示单元组:
a,或(a,) - 使用以逗号分隔的多个项:
a, b, cor(a, b, c) - 使用内置的
tuple():tuple()或tuple(iterable)
示例:
>>> tuple1 = (1, 2, 3, 4, 5, 6, 7, 8, 9)
>>> type(tuple1)
<class 'tuple'>
>>> tuple1='a',
>>> tuple1
('a',)
请注意决定生成元组的其实是逗号而不是圆括号。 圆括号只是可选的
元组取值和列表一样,也是用下标(索引),并且下标的值也是从0开始。
例如依然取5这个值,它的下标为4
>>> tuple1[4]
5
//元组和列表最大区别为列表可以修改,元组不可以修改,如:
//修改列表:
>>> list1
[1, 2, 3, 4, 5, 6, 7, 8, 9]
>>>
>>> list1[0]
1
>>> list1[0] = "A"
>>> list1[0]
'A'
>>> list1
['A', 2, 3, 4, 5, 6, 7, 8, 9]
//修改元组:
>>> tuple1
(1, 2, 3, 4, 5, 6, 7, 8, 9)
>>> tuple1[0]
1
>>> tuple1[0]="AA"
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: 'tuple' object does not support item assignment //报错,元组不支持修改
8.1 tuple内置方法
8.1.1 tuple类型转换
# 类型转换:
>>> tuple(11) # 整型不能转换成元组
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: 'int' object is not iterable
>>> tuple(12.3) # 浮点型不能转换成元组
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: 'float' object is not iterable
# 可迭代对象都可转换成元组
>>> tuple("Hello") # 字符串转元组
('H', 'e', 'l', 'l', 'o')
>>> tuple([1, 2, 3, 4, 5]) # 列表转元组
(1, 2, 3, 4, 5)
>>> tuple({"name":"Hans", "age":18}) # 字典转元组
('age', 'name')
>>> tuple({"first", "second", "third"}) # 集合转元组
('second', 'third', 'first')
# 注意:
# 在设置一个元素的元组时经犯的错误
>>> tuple1 = (123)
>>> type(tuple1)
<type 'int'>
>>> tuple1 = (123.4)
>>> type(tuple1)
<type 'float'>
>>> tuple1 = ("Hello")
>>> type(tuple1)
<type 'str'>
# 如果里面有一个元素,直接写的话创建出来的不是元组。
# 创建一个元素的元组:
>>> tuple1 = ("world",)
>>> type(tuple1)
<type 'tuple'>
# 创建元组时,哪怕一个元素也要加上逗号。还可以这样写:
>>> tuple2 = "Hi",
>>> type(tuple2)
<type 'tuple'>
8.1.2 索引取值、切片
>>> tuple3 = ('apple', 'pear', 'watermelon', 'pineapple', 'purple')
>>> tuple3[0]
'apple'
>>> tuple3[-1]
'purple'
# 切片
>>> tuple3[1:3]
('pear', 'watermelon')
>>> tuple3[:]
('apple', 'pear', 'watermelon', 'pineapple', 'purple')
>>> tuple3[::-1]
('purple', 'pineapple', 'watermelon', 'pear', 'apple')
# 步长
>>> tuple3[::2]
('apple', 'watermelon', 'purple')
>>> tuple3[1:5:2]
('pear', 'pineapple')
8.1.3 统计元组的元素个数
>>> len(tuple3)
5
8.1.4 统计元组内某个元素的个数
>>> tuple4 = (1, 2, 3, 4, 1, 1, 2, 3, 4, 5)
>>> tuple4.count(1)
3
>>> tuple4.count(5)
1
8.1.5 遍历元组
>>> for i in tuple4:
print(i)
9. 集合:set
集合也是容器,其内元素都是无序、唯一、不可变的。它常用来做成员测试、移除重复数据、数据计算(比如交集、并集、差集)。集合元素为不可变类型,而且元素不能重复。
可以使用大括号 { } 或者 set() 函数创建集合,元素与元素之间逗号隔开,创建一个空集合必须用 set() 而不是 { },因为 { } 是用来创建一个空字典。
示例:
>>> x = {1, 2, 3, 4}
>>> type(x)
<class 'set'>
>>> y = {1, 1, 2, 2, 3, 3, 4, 4}
>>> y //去重功能
{1, 2, 3, 4}
>>> print(y)
{1, 2, 3, 4}
集合的三个特点:
- 每个元素必须是不可变类型
- 集合内没有重复的元素
- 集合内元素无序
由于集合是通过hash值来存储的,没有位置索引。所以没法对集合进行单元素的检索,只能对集合进行修改操作,或迭代、遍历。
9.1 set集合内置方法
9.1.1 set类型转换
# 可迭代对象都可转换成集合
>>> set("hello") # 字符串转集合
set(['h', 'e', 'l', 'o'])
>>> set([1, 2, 3, 4, 5]) # 列表转集合
set([1, 2, 3, 4, 5])
>>> set({"name":"Hans","age":18}) # 字典转集合
set(['age', 'name'])
>>> set(('apple', 'pear', 'watermelon', 'pineapple', 'purple')) # 元组转集合
set(['purple', 'watermelon', 'pear', 'apple', 'pineapple'])
9.1.2 set增加和移除元素
>>> set1 = {1, 2, 3, 4, 1, 1, 2, 3, 4, 5}
>>> set1 # 默认去重
set([1, 2, 3, 4, 5])
# 向集合增加元素
>>> s1 = {1, 2, 3, 4}
>>> s1.add(5)
>>> s1
{1, 2, 3, 4, 5}
# 如果元素已存在,则不进行任何操作
# pop() 删除一个元素
>>> s2 = {'apple', 'pear', 'watermelon', 'pineapple', 'purple'}
>>> s2
{'purple', 'pineapple', 'pear', 'watermelon', 'apple'}
>>> s2.pop() #默认第一个
'purple'
>>> s2
{'pineapple', 'pear', 'watermelon', 'apple'}
>>>
# remove() 删除指定元素
>>> s2.remove('pear')
>>> s2
{'pineapple', 'watermelon', 'apple'}
# 清空集合
>>> s1
{1, 2, 3, 4, 5}
>>> s1.clear()
>>> s1
set()
9.1.3 集合关系运算
# 一个元素是否在集合当中
>>> s2
{'pineapple', 'watermelon', 'apple'}
>>> 'apple' in s2
True
>>> 'cherry' in s2
False
# 交集(两个集合共同的元素)
>>> fruit1 = {'apple', 'pear', 'peach', 'grape'}
>>> fruit2 = {'apple', 'pear', 'lemon', 'cherry'}
>>> fruit1.intersection(fruit2)
{'pear', 'apple'}
>>> fruit1 & fruit2
{'pear', 'apple'}
# 并集(合并两个集合)
>>> fruit1 | fruit2
{'cherry', 'grape', 'peach', 'pear', 'lemon', 'apple'}
>>> fruit1.union(fruit2)
{'cherry', 'grape', 'peach', 'pear', 'lemon', 'apple'}
# 差集 (元素包含在集合 x ,但不在集合 y)
>>> fruit1 - fruit2
{'grape', 'peach'}
>>> fruit1.difference(fruit2)
{'grape', 'peach'}
# 对称差集 (两个集合中不重复的元素)
>>> fruit1 ^ fruit2
{'cherry', 'grape', 'peach', 'lemon'}
>>> fruit1.symmetric_difference(fruit2)
{'cherry', 'grape', 'peach', 'lemon'}
# 子集(一个集合是否包含另一个集合)
# x.issuperset(y) # y所有元素都存在于集合x中,则返回True
# issubset() # 如果集合中的所有项目都存在于指定集合中,则返回True
>>> s1 = {1, 2, 3, 4}
>>> s2 = {2, 3}
>>> s1 > s2
True
>>> s1.issuperset(s2) #s2所有项目都存在于集合 S1 中
True
>>> s1 < s2
False
>>> s2.issubset(s1) #如果集合中的所有项目都存在于指定集合中
True
>>> s1
{1, 2, 3, 4}
>>> s3
{1, 2, 3, 4}
>>> s1 > s3
False
>>> s1 <= s3
True
>>> s1 < s3
False
>>> s1 <= s3
True
10. 用户交互
10.1 什么是用户交互
用户通过人机交互界面与系统交流,并进行操作,简单的区分为“输入”(Input)与“输出”(Output)两种。输入指的是由人来进行机械或设备的操作,输出指的是由机械或设备发出来的通知。
input() 函数接受一个标准输入数据,返回为 string 类型.使用input()可以进行用户交互
示例:
>>> num = input("please input a num:")
please input a num:123
>>> type(num)
<class 'str'>
>>> str1 = input("please input a string:")
please input a string:Hello
>>> type(str1)
<class 'str'>
//不管输入的是什么,python 里input()接受后都是字符串类型。
11. 格式化输出
格式化输出即按照一定的格式输出。
>>> print("Hi, %s." % name)
Hi, Hans.
>>> print("Hello, %s. Welcome to %s" %("Hans", "BJ"))
Hello, Hans. Welcome to BJ
其中%s为占位符。
| 格式化字符 | 含义 |
|---|---|
| %s | 字符串,在python中可接受任意类型数据 |
| %d | 有符号十进制整数,%06d 表示输出的整数显示位数,不足的地方使用 0 补全 |
| %f | 浮点数,%.2f 表示小数点后只显示两位 |
| %% | 输出 % |
print()常用参数:
- sep -- 用来间隔多个对象,默认值是一个空格。
- end -- 用来设定以什么结尾。默认值是换行符 \n,我们可以换成其他字符串。
示例:
#sep
>>> print("www","pymysql","com")
www pymysql com
>>> print("www","pymysql","com", sep='.')
www.pymysql.com
#end. end默认是换行符,所以每次打印一次就会换行
>>> print("www.pymysql.com")
www.pymysql.com
>>>
>>> print("www.pymysql.com",end='') #把默认换行换成空了,所以不自动换行了。
www.pymysql.com>>>
>>> print("www.pymysql.com",end='#') ##把默认换行换成井号'#''
www.pymysql.com#>>>
>>>
练习:
1. 接受用户输入,打印指定格式
>>> name = input("Your name:")
Your name:Hans
>>> age = input("Your age:")
Your age:18
>>> print("My name is %s, my age is %s" %(name, age))
My name is Hans, my age is 18
2.用户输入姓名,年龄,性别,工作,爱好,然后安格式打印
cat person.py
name = input("name:")
age = input("age:")
gender = input("gender:")
job = input("job:")
hobby = input("hobby:")
print(
"""
%s\tinfo to %s\t%s
Name : %s
Age : %s
Sex : %s
Job : %s
Hobby : %s
%s\tend\t%s
""" % ('_'* 10, name, '_'* 10,name, age, gender, job, hobby,'_'* 10,'_'* 10,)
)
python person.py
name:Hans
age:18
gender:male
job:student
hobby:study
__________ info to hans __________
Name : Hans
Age : 18
Sex : male
Job : student
Hobby : study
__________ end __________
12. 运算符
12.1 算术运算符
| 运算符 | 描述 | 实例 |
|---|---|---|
| + | 加,两个数相加 | 1 + 1 |
| - | 减,两个数相减 | 2 - 1 |
| * | 乘 - 两个数相乘 | 10 * 2 |
| / | 除,x除以y | 4 / 2 |
| % | 取模 - 返回除法的余数 | 10 % 3 = 1 |
| ** | 幂 - 返回x的y次幂 | 10 ** 2 |
| // | 取整除 - 返回商的整数部分(向下取整) | 9//2=4 |
示例:
>>> 1 + 1
2
>>> 2 - 1
1
>>> 2 * 4
8
>>> 4 / 2
2.0
>>> 10 % 3
1
>>> 9 // 2
4
12.2 关系运算符
| 运算符 | 描述 | 实例 |
|---|---|---|
| == | 等于,比较对象是否相等 | (a == b) 返回 False。 |
| != | 不等于 ,比较两个对象是否不相等 | (a != b) 返回 true. |
| > | 大于 | (a > b) 返回 False。 |
| < | 小于 | (a < b) 返回 true。 |
| >= | 大于等于 | (a >= b) 返回 False。 |
| <= | 小于等于 | (a <= b) 返回 true。 |
示例:
>>> "a" == "b"
False
>>> "a" != "b"
True
>>> 3 > 4
False
>>> 3 < 4
True
>>> 3 >= 4
False
>>> 3 <= 4
True
12.3 赋值运算符
=赋值。
a = 20
12.4 增量赋值运算符
| 运算符 | 描述 | 实例 |
|---|---|---|
| += | 加法赋值运算符 | c += a 等效于 c = c + a |
| -= | 减法赋值运算符 | c -= a 等效于 c = c - a |
| *= | 乘法赋值运算符 | c *= a 等效于 c = c * a |
| /= | 除法赋值运算符 | c /= a 等效于 c = c / a |
| %= | 取模赋值运算符 | c %= a 等效于 c = c % a |
| **= | 幂赋值运算符 | c **= a 等效于 c = c ** a |
| //= | 取整除赋值运算符 | c //= a 等效于 c = c // a |
示例:
>>> a = 2
>>> a += 1
>>> a
3
>>> a -= 1
>>> a
2
>>> a *= 2
>>> a
4
>>> a /= 2
>>> a
2.0
>>> a = 10
>>> a %= 3
>>> a
1
>>> a = 2
>>> a **= 3
>>> a
8
>>> a = 9
>>> a //= 2
>>> a
4
13.5 链式赋值
链式赋值: 同时对几个变量进行赋值
示例:
a = 3
b = 3
c = 3
可以写成
a = b = c = 3
>>> a = b = c = 3
>>> a
3
>>> b
3
>>> c
3
13.6 交叉赋值
即交换两个变量的数值.
x = 10
y = 20
如何把x 和y 的值交换即:x = 20, y = 10
方法1:利用第三个变量
>>> x = 10
>>> y = 20
>>> m = x
>>> x = y
>>> y = m
>>> x
20
>>> y
10
方法2:交叉赋值
>>> x = 10
>>> y = 20
>>> x, y = y, x
>>> x
20
>>> y
10
13.7 解压赋值
任何的序列 (或者是可迭代对象) 可以通过一个简单的赋值语句解压并赋值给多个变量。唯一的前提就是变量的数量必须跟序列元素的数量是一样的。
>>> number_list = [1, 2, 3, 4]
>>> num1, num2, num3, num4 = number_list
>>> num1
1
>>> num2
2
>>> num3
3
>>> num4
4
//少一个不行
>>> n1, n2, n3 = number_list
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
ValueError: too many values to unpack (expected 3)
//多一个也不行
>>> n1, n2, n3, n4, n5 = number_list
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
ValueError: not enough values to unpack (expected 5, got 4)
// 如果只想要第一个和最后一个,如何突破上面的限制:
//可以使用星号(*)
>>> number_list = [1, 2, 3, 4]
>>> n1, *a, n2 = number_list
>>> n1
1
>>> n2
4
>>> a //把中间的都赋值给a
[2, 3]
//如果中间的数据不想要:
>>> nu1, *_, nu2 = number_list
>>> nu1
1
>>> n2
4
//可以接受多余的元素 组织成列表赋值给后面的变量名
//下划线单独作为变量名 通常表达的意思指向的值没有啥用
13. 逻辑运算符:与或非
| 运算符 | 逻辑表达式 | 描述 | 实例 |
|---|---|---|---|
| and | x and y | 布尔"与",两边都为真结果为真,如果是两个非零的数相与,则返回第二个数的值 | 1 and 3返回3, 0and 3返回0 |
| or | x or y | 布尔"或" 一个为真结果为真。如果 x 是非 0,它返回 x 的计算值,否则它返回 y 的计算值 | 2 or 0 返回2,0 or 1返回1 |
| not | not x | 布尔"非" 取反。如果 x 为 True,返回 False 。如果 x 为 False,它返回 True。 | not False返回True,not True返回False |
示例:
1. and
>>> 1 and 2
2
>>> 0 and 2
0
>>> 3 and 1
1
>>> -1 and -2
-2
2. or
>>> 1 or 3
1
>>> 2 or 3
2
>>> 2 or 0
2
>>> 0 or 0
0
>>> 0 or 1
1
3. not
>>> not True
False
>>> not False
True
逻辑运算符也是有优先级的:
not > and > or
不过编写程序时应该人为的规定好优先级,使用圆括号().
16. 可变类型和不可变类型
16.1 什么是可变类型
可变类型:当该数据类型对应的变量的值发生了变化时,如果它对应的内存地址不发生改变,那么这个数据类型就是 可变数据类型。
>>> firut = ['banana', 'green']
>>> id(firut)
140037521660552
>>> firut.append('watermelon')
>>> firut
['banana', 'green', 'watermelon'] #firut的值改变后,但它的内存地址不变。
>>> id(firut)
140037521660552
16.2 什么是不可变类型
不可变数据类型:当该数据类型对应的变量的值发生了变化时,如果它对应的内存地址也发生了改变,那么这个数据类型就是 不可变数据类型。
即:不变数据类型的对象一旦发生改变,就会在内存中开辟一个新的空间用于存储新的对象,原来的变量名就会指向一个新的地址。
>>> a = 2
>>> a
>>> 2
>>> id(a)
140037556831488
>>> a += 1
>>> a #值变了,内存地址也变了。
3
>>> id(a)
140037556831520
总结:
python内置类型中不可变类型有str, int, float, boolean, tuple;可变类型有list, dict, set。
17. 深拷贝和浅拷贝
深浅copy其实就是完全复制一份,和部分复制一份的意思
>>> l1 = [1,2,3,['A','B']]
>>> l2 = l1
>>> l1[0] = 10
>>> l1
[10, 2, 3, ['A', 'B']]
>>> l2
[10, 2, 3, ['A', 'B']]
>>> l1[3][0]='a'
>>> l1
[10, 2, 3, ['a', 'B']]
>>> l2
[10, 2, 3, ['a', 'B']]
l1与l2指向的是同一个内存地址,所以它们是完全一样的
>>> id(l1)
1689349666112
>>> id(l2)
1689349666112
17.1 浅拷贝
>>> l1 = [1,'a',(1,2,3),[4,5]]
>>> l2 = l1.copy()
>>> id(l1)
1689350032384
>>> id(l2)
1689350039680
>>> id(l1[0])
1689347948784
>>> id(l2[0])
1689347948784
>>> id(l2[-1])
1689350031936
>>> id(l1[-1])
1689350031936
# 发现除了列表的地址不一样,但是里面的元素地址是一样的。
对于浅copy来说,只是在内存中重新创建了开辟了一个空间存放一个新列表,但是新列表中的元素与原列表中的元素是公用的。
17.2 深拷贝
import copy
>>> l1 = [1,'a',(1,2,3),[4,5]]
>>> l2 = copy.deepcopy(l1)
>>> id(l1)
140491146130944
>>> id(l2)
140491145362496
>>> id(l1[0])
94214083067200
>>> id(l2[0])
94214083067200
>>> id(l1[-1])
140491146131136
>>> id(l2[-1])
140491145427072
对于深copy来说,列表是在内存中重新创建的,列表中可变的数据类型是重新创建的,列表中的不可变的数据类型用原来的
练习:
l1 = [1,2,3,['A']]
l2 = l1[::]
l1[-1].append(666)
print(l2)
# 结果:
[1, 2, 3, ['A', 666]]
分析:
>>> id(l1)
139768380761728
>>> id(l2)
139768380862720
>>> id(l1[0])
94845298675008
>>> id(l2[0])
94845298675008
>>> id(l1[-1])
139768380761920
>>> id(l2[-1])
139768380761920
l2 = l1[::] 相当于是浅拷贝

 浙公网安备 33010602011771号
浙公网安备 33010602011771号