
解决数据库插入之后的乱码问题 【转】
从网站上获取的信息要保存在本地数据库中,但是保存的过程中数据库的信息都变成了乱码,怎么解决呢?客官听我娓娓道来。
首先,保证以下四项的编码都是utf-8:
1. 代码
2. 数据库连接
3. 表的字符集格式
4. 插入的数据格式
每步的操作如下:
1. 保证代码的格式是utf-8,在代码最前面加上这句话
# -*- coding:utf8 -*-
#首先用于确定编码,加上这句
2. 保证数据库连接格式是utf-8,这么写
conn=MySQLdb.connect(host='localhost',user='root',passwd='****',db='kfxx',port=3306,charset='utf8')
cur=conn.cursor()
3. 保证表的字符集格式是utf-8,在建表的时候就能设置
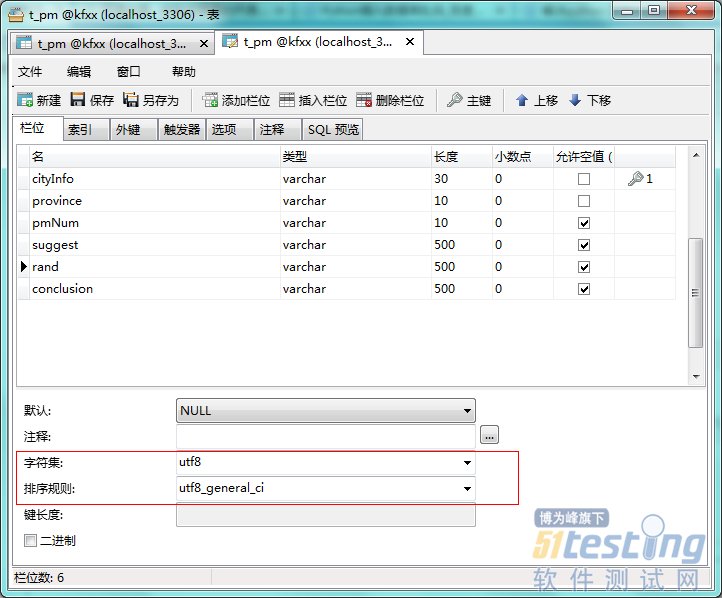
4. 保证插入的数据格式是utf-8,分为保证读取的页面格式是utf-8和字符串格式也是utf-8
#解决乱码问题
|
html_1 = urllib2.urlopen(cityURL,timeout=120).read()
mychar = chardet.detect(html_1)
bianma = mychar['encoding']
if bianma == 'utf-8' or bianma == 'UTF-8':
html = html_1
else :
html = html_1.decode('gb2312','ignore').encode('utf-8')
|
|
chapter_soup = BeautifulSoup(html)
city = chapter_soup.find('div',class_ = 'row-fluid').find('h1').get_text()
province = chapter_soup.find('a',class_ = 'province').get_text()
pmNum = chapter_soup.find('div',class_ = 'row-fluid').find('span').get_text()
suggest = chapter_soup.find('div',class_ = 'row-fluid').find('h2').get_text()
rand = chapter_soup.find('div',class_ = 'row-fluid').find('h2').find_next_sibling('h2').get_text()
face = chapter_soup.find('div',class_ = 'span4 pmemoji').find('h1').get_text()
conclusion = chapter_soup.find('h1',class_ = 'review').get_text()
print city.encode('utf-8')
cur.execute('insert into t_pm values(\''+city.encode('utf-8')
+'\',\''+province.encode('utf-8')
+'\',\''+pmNum.encode('utf-8')
+'\',\''+suggest.encode('utf-8')
+'\',\''+rand.encode('utf-8')
+'\',\''+conclusion.encode('utf-8')+'\')')
|
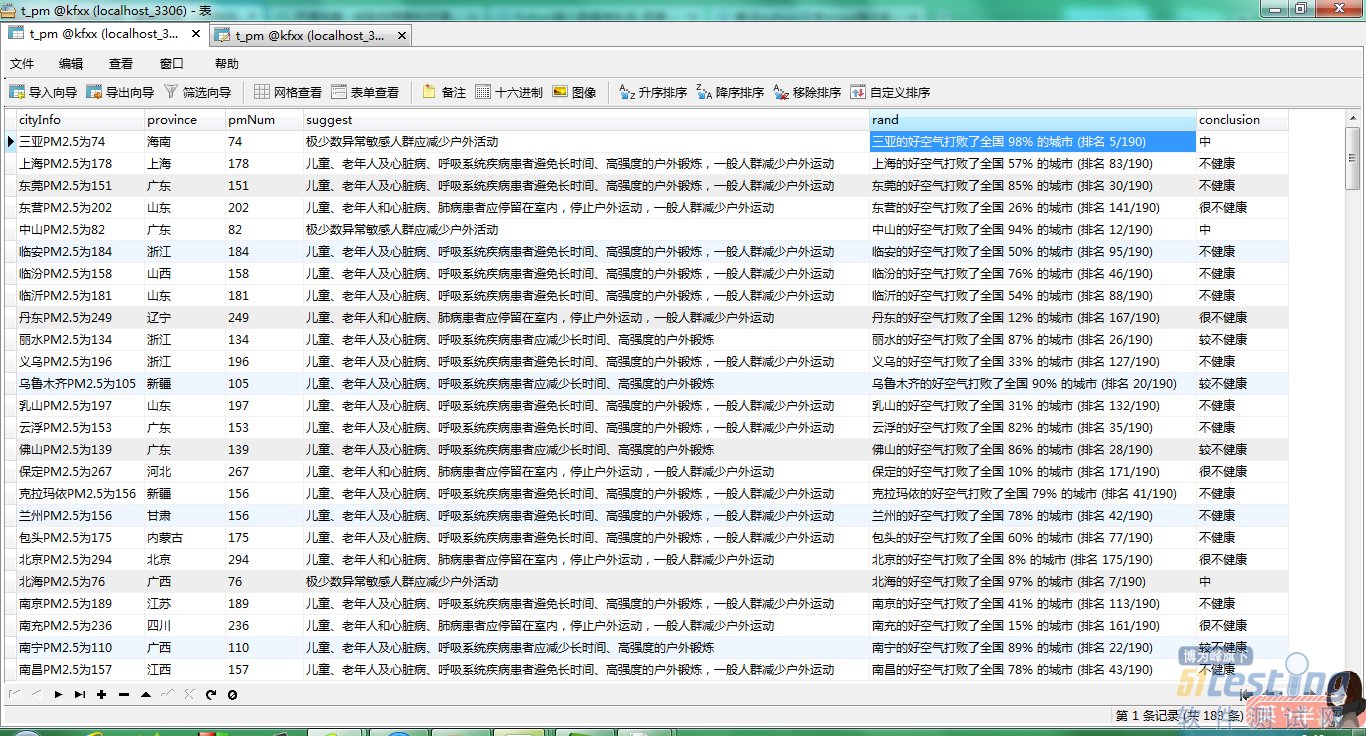
完成,插入的数据都是中文了,看效果图:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号