
词向量聚类实验
实验描述:
本实验的目的是将词向量聚类并有效的表示。将要表示的词是从一个大规模语料中人工抽取出来的,部分所表示的词的示例如下:
家居: 卫生间 灯饰 风格 颇具匠心 设计师 沙发 避风港 枕头 流连忘返 奢华
房产: 朝阳区 物业 房地产 区域 市场 别墅 廉租房 经适房 拆迁 华润置地
步骤1:
首先进行分词,然后利用gensim工具训练词向量。
##### 分词
import jieba
src = 'cnews.train.txt'
tgt = 'train.txt'
jieba.load_userdict('dic.txt')
def _cws(seq):
seq_list = jieba.cut(seq)
return ' '.join(seq_list)
ft = open(tgt,'w',encoding='utf-8')
with open(src,'r',encoding='utf-8') as fl:
for line in fl.readlines():
line = line.strip('\n').split('\t')
seq = _cws(line[1])
ft.write(seq+'\n')
ft.close()
##### 训练词向量
#!/usr/bin/env python
# -*- coding: utf-8 -*-
import logging
import os.path
import sys
import multiprocessing
from gensim.corpora import WikiCorpus
from gensim.models import Word2Vec, doc2vec
from gensim.models.word2vec import LineSentence
if __name__ == '__main__':
program = os.path.basename(sys.argv[0])
logger = logging.getLogger(program)
logging.basicConfig(format='%(asctime)s: %(levelname)s: %(message)s')
logging.root.setLevel(level=logging.INFO)
logger.info("running %s" % ' '.join(sys.argv))
inp = "baike_final.txt"
outp2 = "word_vector.src"
model = Word2Vec(LineSentence(inp), size=100, window=5, min_count=1,workers=multiprocessing.cpu_count(), sg=1, iter=5, negative=20)
model.wv.save_word2vec_format(outp2, binary=False)
步骤2:对单词进行可视化
import numpy as np
from sklearn.manifold import TSNE
import matplotlib.pyplot as plt
import gensim
import matplotlib as mpl
import random
random.seed(0)
np.random.seed(0)
mpl.rcParams['font.sans-serif'] = ['FangSong']
mpl.rcParams['axes.unicode_minus'] = False
def plot_with_labels(low_dim_embs, labels, filename,flag=None):
assert low_dim_embs.shape[0] >= len(labels), 'More labels than embeddings'
print('绘制词向量中......')
plt.figure(figsize=(10, 10)) # in inches
#length = np.linalg.norm(low_dim_embs, axis=1) ###对词向量进行标准化
#low_dim_embs = low_dim_embs / length[:, np.newaxis]
for i, label in enumerate(labels):
x, y = low_dim_embs[i, :]
plt.scatter(x, y,color=flag[i])
plt.annotate(label, xy=(x, y),xytext=(5, 2),textcoords='offset points',ha='right',va='bottom')
plt.savefig(filename)
plt.show()
def load_txt_vec(file, threshold=0, dtype='float'):
print('读取词向量文件中......')
header = file.readline().split(' ')
count = int(header[0]) if threshold <= 0 else min(threshold, int(header[0]))
dim = int(header[1])
words = []
matrix = np.empty((count, dim), dtype=dtype)
for i in range(count):
word, vec = file.readline().split(' ', 1)
words.append(word)
matrix[i] = np.fromstring(vec, sep=' ', dtype=dtype)
return (words, matrix)
if __name__ == '__main__':
try:
w2v_txt_file = open('vec.txt', 'r',encoding='utf-8', errors='surrogateescape')
words, vectors = load_txt_vec(w2v_txt_file)
tsne = TSNE(perplexity=30, n_components=2, init='pca', n_iter=5000, m ethod='exact')
plot_only = 100
low_dim_embs = tsne.fit_transform(vectors[:plot_only])
labels = [words[i] for i in range(plot_only)]
colors = ["red", "blue", "yellow", "green", "black", "purple", "pink", "grey", "brown", "orange"]
plot_with_labels(low_dim_embs, labels, '1w2v.png', flag=sorted(colors* 10))
except ImportError as ex:
print('Please install gensim, sklearn, numpy, matplotlib, and scipy to show embeddings.')
print(ex)
其显示结果如图所示:
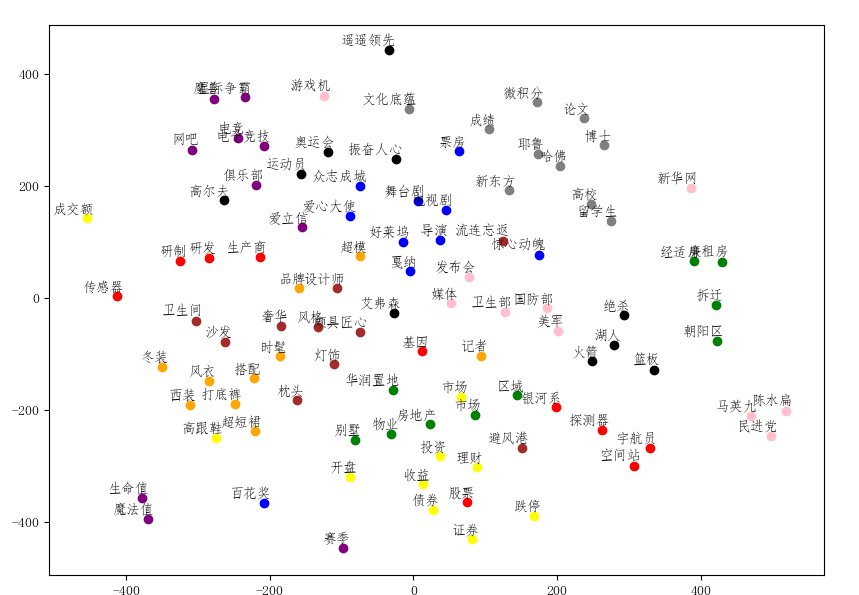
归一化之后的结果为:
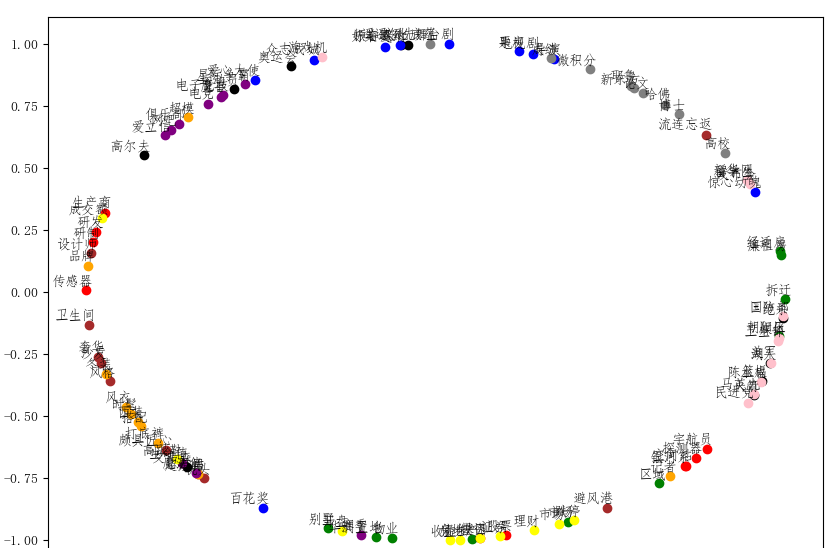
在进行词表示的时候,取模是将词向量的长度进行归一化,取模之后进行显示,考虑的仅仅是词于词之间的语义关系。
步骤3:对词进行聚类
import json
from sklearn.cluster import KMeans
from sklearn import metrics
import numpy as np
import random
random.seed(1)
src = 'vec.json'
tgt = 'classification.json'
labels = ['0','1','2','3','4','5','6','7','8','9']
flag=sorted(labels * 10)
features = []
with open(src,'r',encoding='utf-8') as fl:
for line in fl.readlines():
line = line.strip('\n')
line = json.loads(line)
for ss in line.items():
features.append(ss[1])
def fun(features):
temp = []
for ss in features:
cmp = []
for s in ss:
a = eval(s)
cmp.append(a)
temp.append(cmp)
return temp
score =[]
features = fun(features)
clf = KMeans(n_clusters=10,max_iter=10000,n_init = 10)
pred = clf.fit_predict(features)
with open(src,'r',encoding='utf-8') as fl:
with open(tgt,'w',encoding='utf-8') as ft:
fl = fl.readlines()
for i in range(10):
for e,flag in enumerate(pred):
tmp = []
if flag == i:
line = fl[e].strip('\n')
line = json.loads(line)
tmp.append(str(flag))
tmp.append(line)
json_data = json.dumps(tmp,ensure_ascii=False)
ft.write(json_data+'\n')
可视化结果为:
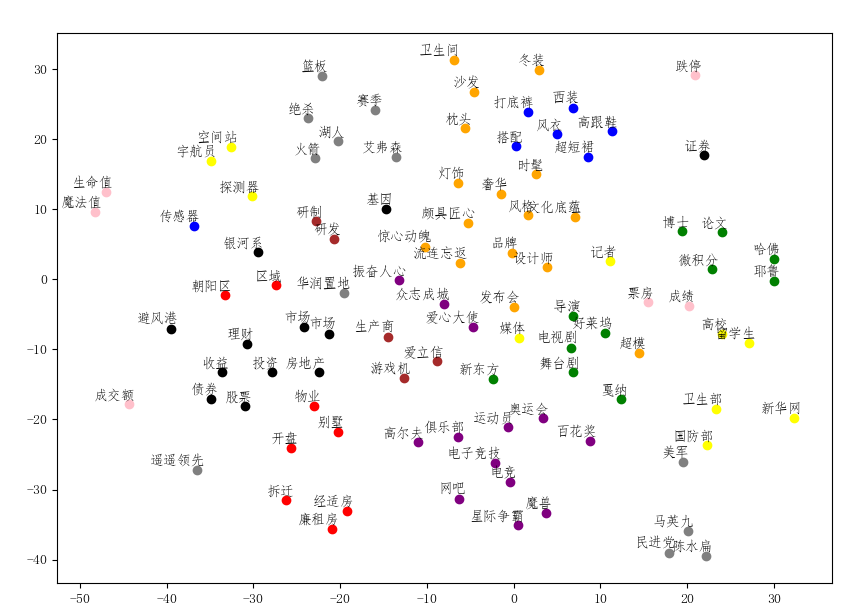
对聚类结果的评测指标:
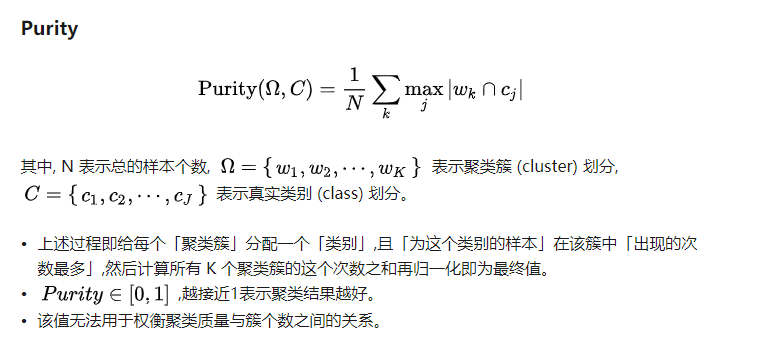


首先计算RI指数:
import json
src = 'classification.json'
tgt = 'tgt.json'
cmp = [i for i in range(10)]
with open(src,'r',encoding='utf-8') as fl:
with open(tgt,'w',encoding='utf-8') as ft:
fl = fl.readlines()
dic ={}
for i in cmp:
temp = []
#print(i)
for e in range(len(fl)):
line = fl[e]
line = line.strip('\n')
line = json.loads(line)
if eval(line[0]) == i:
#temp.append(i)
for ss in line[1].items():
temp.append(ss[0])
dic[i] = temp
json_data = json.dumps(dic,ensure_ascii=False)
ft.write(json_data+'\n')
print(dic)
将数据处理成这种可以查询的形式:
{0: ['朝阳区', '物业', '区域', '别墅', '廉租房', '经适房', '拆迁', '开盘'],
1: ['风衣', '搭配', '超短裙', '西装', '打底裤', '传感器', '高跟鞋'],
2: ['留学生', '高校', '记者', '媒体', '国防部', '新华网', '卫生部', '探测器', '宇航员', '空间站'],
3: ['电视剧', '导演', '舞台剧', '戛纳', '好莱坞', '微积分', '博士', '哈佛', '耶鲁', '新东方', '论文']}
src1 = 'ss.txt'
lb_dic = {}
with open(src1,'r',encoding='utf-8') as fl:
for line in fl.readlines():
line = line.strip('\n').split(' ')
for i in range(1,len(line)):
lb_dic[line[i]]=line[0]
首先计算TP的值:
def _tp_judge(ss):
TP = 0
for i in range(len(ss)):
for j in range(i,len(ss)):
if lb_dic[ss[i]] == lb_dic[ss[j]]:
TP+=1
return TP
tp_num = 0
for ww in dic.items():
ss = ww[1]
a = _tp_judge(ss)
tp_num+=a
计算FP的值:
def _fp_judge(ss):
FP = 0
for i in range(len(ss)):
for j in range(i,len(ss)):
if lb_dic[ss[i]] != lb_dic[ss[j]]:
FP+=1
print(FP)
return FP
fp_num = 0
for ww in dic.items():
ss = ww[1]
a = _fp_judge(ss)
fp_num+=a
计算FN的值:
cmp = [i for i in range(10)]
with open(src,'r',encoding='utf-8') as fl:
fl = fl.readlines()
fn_dic ={}
for i in cmp:
temp = []
#print(i)
for e in range(len(fl)):
line = fl[e]
line = line.strip('\n')
line = json.loads(line)
if eval(line[0]) == i:
#temp.append(i)
for ss in line[1].items():
fn_dic[ss[0]]=i
print(fn_dic)
将数据处理成如下形式:
{'朝阳区': 0, '物业': 0, '区域': 0, '别墅': 0, '廉租房': 0,
'经适房': 0, '拆迁': 0, '开盘': 0, '风衣': 1, '搭配': 1, '超短裙': 1,
'西装': 1, '打底裤': 1, '传感器': 1, '高跟鞋': 1, '留学生': 2, '高校': 2,
'记者': 2, '媒体': 2, '国防部': 2, '新华网': 2, '卫生部': 2, '探测器': 2,
'宇航员': 2, '空间站': 2, '电视剧': 3, '导演': 3, '舞台剧': 3, '戛纳': 3}
src1 = 'ss.txt'
fn_lb_dic = {}
with open(src1,'r',encoding='utf-8') as fl:
for line in fl.readlines():
cmp = []
line = line.strip('\n').split(' ')
for i in range(1,len(line)):
cmp.append(line[i])
fn_lb_dic[line[0]]=cmp
print(fn_lb_dic)
将数据处理成如下形式:
{'体育:': ['高尔夫', '奥运会', '振奋人心', '遥遥领先', '绝杀', '篮板', '运动员', '火箭', '湖人', '艾弗森'],
'娱乐:': ['爱心大使', '电视剧', '导演', '惊心动魄', '舞台剧', '百花奖', '戛纳', '众志成城', '票房', '好莱坞'],
'家居:': ['卫生间', '灯饰', '风格', '颇具匠心', '设计师', '沙发', '避风港', '枕头', '流连忘返', '奢华']}
def _fn_judge(ss):
FN = 0
for i in range(len(ss)):
for j in range(i,len(ss)):
if fn_dic[ss[i]] != fn_dic[ss[j]]:
FN+=1
print(FN)
return FN
fn_num = 0
for ww in fn_lb_dic.items():
ss = ww[1]
a = _fn_judge(ss)
fn_num+=a
计算RI的值:
num = (100*99)/2
print(num)
tn_num = num-(fn_num+fp_num+tp_num)
RI = (tn_num+tp_num)/num
print(RI)
计算Purity
def _judge_label(param): pass ## 返回一共多少个类别 count = 0 ## dic是聚类之后生成的簇的字典,return final_ for ss in dic.items(): _dic = {} #print(ss) cmp = ss[1] for ww in cmp: lb = lb_dic[ww] if lb not in _dic: _dic[lb] = 1 else: _dic[lb] +=1 _dic = sorted(_dic.items(),key = lambda item:item[1],reverse=True) print(_dic) #print(_dic[0][1]) count += _dic[0][1] print(count/100)
注:ss.txt文件中的数据格式示例:
体育: 高尔夫 奥运会 振奋人心 遥遥领先 绝杀 篮板 运动员 火箭 湖人 艾弗森
娱乐: 爱心大使 电视剧 导演 惊心动魄 舞台剧 百花奖 戛纳 众志成城 票房 好莱坞
classification.json文件中的数据格式示例:
["0", {"朝阳区": ["-0.1384889", "-0.20243359", "0.102069065", "0.23184149", "-0.046311297", "0.14353138", "0.5543517", "0.29026467", "0.45963597", "-0.17217028", "-0.46954596", "0.31719774", "0.17761867", "0.29701278", "0.6938801", "-0.14563806", "-0.42253557", "0.19530635", "-0.04560669", "-0.26439634", "0.4578489", "-0.16404046", "-0.80666643", "-0.38364044", "-0.45906314", "-0.3663307", "0.45213446", "0.14570023", "0.65608627", "-0.07094579", "-0.08269144", "0.04528637", "-0.23720852", "-0.31091192", "0.14366734", "-0.14827731", "0.16437379", "-0.7352608", "0.05033749", "-0.9513891", "0.9870362", "-0.12723659", "-0.8449314", "-0.6920033", "-0.7977017", "0.7917335", "-0.16021581", "-0.36755514", "0.34619418", "-0.25134012", "0.2761363", "1.1556392", "0.29476222", "-0.41960797", "0.56152135", "-0.6300105", "0.1123949", "0.0011835459", "0.722344", "0.17237052", "-0.67563206", "-0.4982514", "0.95673597", "-0.25812265", "-0.46021804", "-0.2898547", "0.28434277", "0.39801842", "0.7448203", "0.12801662", "-0.34011438", "-0.24242696", "-0.3204678", "1.298795", "-0.4462184", "-0.060344703", "0.60382426", "-0.18342693", "-0.096174486", "-0.6355714", "-0.17171651", "0.10724717", "0.5793009", "-0.29091367", "0.13196644", "0.6097893", "-0.26113376", "-0.7714975", "0.4343755", "-0.41631258", "-0.08117525", "-0.41429466", "0.24792041", "0.46800923", "0.24307102", "-0.2998296", "-0.05571826", "0.033080667", "0.12935354", "-0.6335654"]}]
["0", {"物业": ["0.21649252", "0.37936735", "-0.27688688", "-0.16372944", "0.33023095", "0.1948151", "1.0928497", "0.17396215", "0.6366656", "-0.53761625", "0.15351042", "-0.6486163", "-0.28322187", "-0.124383435", "0.028312065", "-0.10628245", "-0.3067216", "-0.571357", "-0.3424585", "-0.17725593", "0.057400767", "-0.30003172", "-0.65997154", "0.09322061", "0.2592893", "-0.2973807", "0.09047743", "0.15993215", "0.31192315", "-0.22998796", "0.39004174", "0.7176821", "-0.19427699", "-0.6698311", "-0.88420814", "0.27445787", "0.33690578", "-0.7266952", "-0.34795922", "0.21389268", "0.6480503", "0.60902315", "-0.13365382", "-0.2836483", "-0.33640364", "0.040157873", "-0.69254637", "-0.07615123", "0.21742567", "-0.8085353", "0.3357688", "0.42005894", "0.019965837", "-0.6346853", "0.4982129", "-0.73431104", "-0.50731987", "0.38148776", "-0.4835083", "-0.17213771", "-0.25769734", "0.32378343", "0.6043039", "-0.3443045", "-0.43060115", "-0.32943606", "0.22752339", "0.14163403", "0.75646776", "-0.0654474", "0.24144651", "0.26645514", "-0.071194924", "0.38203463", "-0.08941716", "0.0788296", "0.19273318", "0.03026876", "-0.36909038", "-0.5176391", "-0.27326223", "-0.099675916", "-0.016073491", "-0.101594515", "0.2737673", "0.594221", "-0.35780343", "-0.5114833", "-0.2103526", "0.12272796", "-0.3582389", "-0.31339905", "-0.048890725", "0.37520337", "0.20995434", "0.27567548", "-0.3183832", "-0.13981616", "0.55548304", "-0.8013473"]}]

 浙公网安备 33010602011771号
浙公网安备 33010602011771号