
理解MapReduce
A.编写map函数,reduce函数
#!/usr/bin/env python
import sys
for line in sys.stdin:
line=line.strip()
words=line.split()
for word in words:
print '%s\t%s' % (word,1)
#!/usr/bin/env python
from operator import itemgetter
import sys
current_word=None
current_count=0
word=None
for line in sys.stdin:
line=line.strip()
word,count=line.split('\t',1)
try:
count=int(count)
except ValueError:
continue
if current_word==word:
current_count+=count
else:
if current_word:
print '%s\t%s' % (current_word,current_count)
current_count=count
current_word=word
if current_word==word:
print '%s\t%s' % (current_word,current_count)
B.将其权限作出相应修改
chmod a+x /home/hadoop/wc/mapper.py chmod a+x /home/hadoop/wc/reducer.py
C.本机上测试运行代码
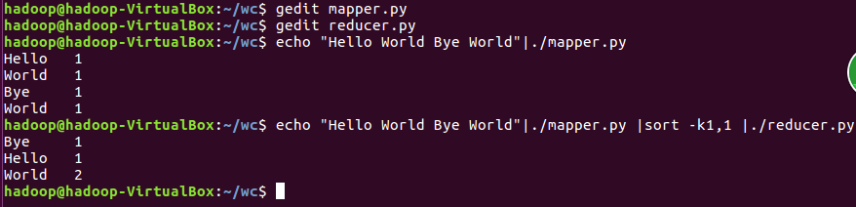
D.放到HDFS上运行
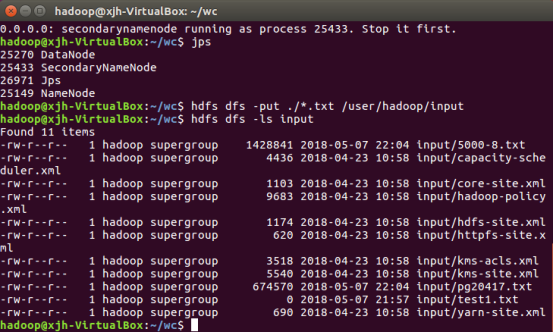
a.将之前爬取的文本文件上传到hdfs上
b.用Hadoop Streaming命令提交任务
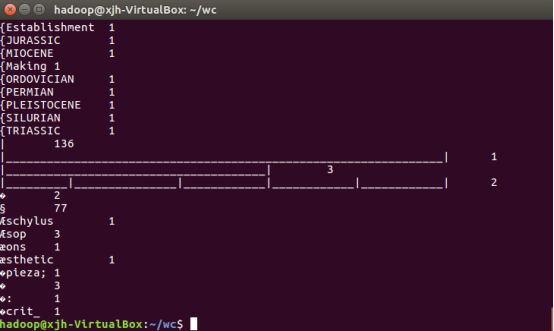
E.查看运行结果
A.气象数据集下载地址为:ftp://ftp.ncdc.noaa.gov/pub/data/noaa
按学号后三位下载不同年份月份的数据(例如201506110136号同学,就下载2013年以6开头的数据,看具体数据情况稍有变通)
mkdir qx cd qx wget -D --accept-regex=REGEX -p data -r -c ftp://ftp.ncdc.noaa.gov/pub/data/noaa/2008/8*
B.解压数据集,并保存在文本文件中
C.对气象数据格式进行解析
cd qx/data/ftp.ncdc.noaa.gov/pub/data/noaa/2008 sudo zcat 8*.gz >qxdata.txt head qxdata.txt
编写map函数,reduce函数
#!/usr/bin/env python
import sys
for i in sys.stdin:
i = i.strip()
d = i[15:23]
t = i[87:92]
print '%s\t%s' % (d,t)
#!/usr/bin/env python
from operator import itemggetter
import sys
current_word = None
current_count = 0
word = None
for i in sys.stdin:
i = i.strip()
word,count = i.split('\t', 1)
try:
count = int(count)
except ValueError:
continue
if current_word == word:
if current_count > count:
current_count = count
else:
if current_word:
print '%s\t%s' % (current_word, current_count)
current_count = count
current_word = word
if current_word == word:
print '%s\t%s' % (current_word, current_count)
将其权限作出相应修改
chmod a+x /home/hadoop/qx/mapper.py chmod a+x /home/hadoop/qx/reducer.py
本机上测试运行代码
放到HDFS上运行
将之前爬取的文本文件上传到hdfs上
用Hadoop Streaming命令提交任务
start-dfs.sh jps hdfs dfs -put ./*.txt /user/hadoop/input hdfs dfs -ls input

 浙公网安备 33010602011771号
浙公网安备 33010602011771号