软工实践寒假作业(2/2)
寒假作业(2/2)
| 这个作业属于哪个课程 | 2021春软件工程实践S班 |
|---|---|
| 这个作业要求在哪里 | 作业要求 |
| 这个作业目标 | 深度阅读构建之法;学会提问题;完成WordCount编程;了解学习单元测试 |
| 其他参考文献 | 百度、github、CSDN、博客园 |
🚩PART①:阅读《构建之法》并提问
《构建之法》3.2 软件工程师的思维误区
“不分主次,想解决所有依赖问题:想马上动手解决所有主要问题和次要问题,而不是根据现有条件找到一个足够好的方案”
疑问&思考🤔:
我们在编写代码的时候确实会遇到一个问题,但是因为代码都是有相关联性的,所以往往会牵扯出一链子的问题。那么这时候难道不是顺着这条思路去改代码吗?什么叫做根据现有条件找到一个足够好的方法呢?
就还是以作者举的小飞的例子,小飞本来要去自习,发现自行车没气去借打气筒,借打气筒要送围巾,就开始织围巾。确实这个结果偏离了最开始的计划,或许最开始小飞发现自行车没气决定走路去自习是不是作者认为的足够好的方法呢?
那么我的问题和思考归结于是不是要评估这个问题所依赖的一链子问题是不是过于复杂?对于不复杂的例子就可以马上动手顺着思路去解决,对于复杂的问题就先放着,看看有没有更快捷的方法?
《构建之法》4 两人合作
疑问&思考🤔:
阅读《构建之法》第一次知道结对编程,感觉结对编程这种形式对我来很新颖,两个人一起写一个代码工作量直接减少一半欸:),但我觉得也有些局限。首先结对的两个人水平相差怎么样,一个人很牛一个人相对的菜。会不会导致牛人写的时候,另一个人看的时候觉得“哇,牛,这个好,写的好快,性能也好...”。等到这个人写的时候,厉害的人在旁边看的觉得这不行这不对,开始指导最后恨不得自己把键盘鼠标抢过来。那么对于结对编程的人是不是要有一个基本的水平要求?
《构建之法》9 项目经理
疑问&思考🤔:
通过对第九章的阅读了解了PM,同时知道PM需要的能力很多。我在网络上收集了一下PM需要的基本技能:
1.研发/测试 2.运营3.设计4.市场5.职能部门6.其他技能比如word、excel、ppt等基础技能还要有思维、管理、沟通能力7.产品,熟悉高效的产品工具:Auxre、墨刀、Xmind、ProcessON7.多关注各网站和APP。多看行业报告和商业计划书,多看别人的产品。
那么PM是由程序员逐渐去往PM培养成长起来的呢还是一开始的职业目标就向PM方向发展?比如软件工程的大学生发现对于写代码开发不怎么感冒,能不能就轻于写代码开发,而尽早去点亮作为PM的技能树呢?
《构建之法》13 软件测试
疑问&思考🤔:
书中认为测试人员测试的软件功能100%符合要求,测试人员也都按照SPEC去测试。但是如果用户恨你的软件,那么就说明是测试人员的责任。我想请问的是这里是不是把测试人员的责任看的太大,首先我认同作者的好的测试人员要做易用性测试,去站在用户的角度考虑,但是我也考虑到用户在运用软件发现有问题或者不好的地方,是不是说明这个软件的需求分析之类的做的不够好,而不是去指责测试的不到位。像易用性测试这样的更像是一个附加的测试条件,有点像之前提到的Ad hoc Test。
比如之前的微信,我们很经常会用微信打开别人分享的链接,之后在链接里看到另一篇文章也不错,再打开看看,然后就在微信里面开始循环的浏览信息。这个时候突然有一条微信进来,我要去看看。结果回复完信息之后找不到之前循环浏览的网页了。这是我之前使用微信的一个痛点,但是惊喜的是后来微信增加了一个float window的功能,就解决了这个问题。请问这样的是测试的责任吗?
《构建之法》2 个人技术和流程
疑问&思考🤔:
这部分有涉及到单元测试,正好这次的实践的作业WordCount里也有单元测试的部分,里面对于好的单元测试的标准对于这次实践真的是很实用。但是里面提到单元测试应该是可重复的,用随机数去单元测试不好,又提到也要用随机数出去增加测试真实性,但不是在单元测试中,那请问是在什么时候用随机数去测试呢?在这个部分我也有上网搜索,但是结果都是程序中含有随机数生成器怎么进行单元测试,并没有对于什么时候可以使用随机数去测试的解答。但是也有以外的收获,现在确实很多机器算法启发式算法都又用到随机数的生成,而我在网上搜索到别人的分享,比如说可以用桩对象或者是模拟对象。
冷知识
1946年,第一台电子计算机ENIAC在美国诞生,从此实际上一些最聪明,最有创造力的人开始进入这个行业,在他们身上形成了一种独特的技术文化,这种文化的发展过程中涌现了很多“行话”。20世纪60年代初,麻省理工学院有一个学生团体叫做“铁路模型技术俱乐部”(简称TMRC),他们把解决难题的方法称为hack。
这里的hack有两个意思,既可以指很巧妙的很便捷的解决方法(cool hack 或neat hack),也可以指比较笨拙,不那么优雅的解决方法(ugly hack 或 quick hack)。hack的字典意思是砍木头,在这些学生看来,解决一个计算机难题就好像砍到一颗大树。那么相应的,完成这种hack的过程就被成为hacking,而从事hacking的人就是hacker,也就是黑客。
这个词被发明的时候,“黑客”完全是正面意义上的称呼。TMRC使用这个词是带有敬意的,因为在他们看来,如果要完成一个hack,就必然包含着高度的革新、独树一帜的风格、精湛的技艺。最能干的人会自豪地称自己为黑客。
真正的黑客致力于改变世界,让世界运转的更好。媒体对黑客的定义过于片面,而且影响了大众对黑客的看法。而那些恶意入侵计算机系统的人应该被成为cracker(入侵者)。
参考来源
我认为我们要区分hacker和cracker的区别,其实我们现实当中都把cracker也定义为hacker,但是我认为真正的黑客是有黑客精神的,而不是一味的去进行破坏。黑客是实干家,是优秀的程序员,人活着的意义在于创造,那么黑客是激进的创造者。 我还了解到黑客的口头禅是:
Talk is cheap, show me the code .
:)少废话,放码过来哈哈哈哈哈哈哈哈
真正的黑客一定是个优秀的程序员,他们追求分享,进步、计算机的自由使用。他们也理解原理,推崇技术,想方设法解决问题,这正是我们需要学习的地方。
🚩PART②:WordCount编程
项目地址
hannah-shaw /PersonalProject-Java
PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 30 | 43 |
| ·Estimate | ·估计这个任务需要多少时 | 30 | 43 |
| ·Development | ·开发 | 780 | 1030 |
| ·Analysis | ·需求分析(包括学习新技术) | 120 | 260 |
| ·Design Spec | ·生成设计文档 | 30 | 60 |
| ·Design Review | ·设计复审 | 10 | 15 |
| ·Coding Standard | ·代码规范 | 30 | 25 |
| ·Design | ·具体设计 | 90 | 110 |
| ·Coding | ·具体编码 | 360 | 400 |
| ·Code Review | ·代码复审 | 20 | 10 |
| ·Test | ·测试(自我测试,修改代码,提交修改) | 120 | 150 |
| Reporting | 报告 | 135 | 145 |
| ·Test Repor | ·测试报告 | 90 | 100 |
| ·Size Measurement | ·计算工作量 | 15 | 10 |
| ·Postmortem & Process Improvement Plan | ·事后总结, 并提出过程改进计划 | 30 | 35 |
| 合计 | 1030 | 1217 |
解题思路描述
一、需求分解
首先根据作业要求,把大需求分解成以下小part
- 读取文件内数据
- 统计文件字符数
- 统计文件单词总数
- 统计文件有效行数
- 统计出现频率最高的10个单词
- 以UTF-8格式输出到指定文件
二、读取文件数据
用BufferedReader中包装InputStreamReader类读取数据再存储到字符串,方便之后统计。
三、统计文件字符数
将读取文件数据部分生成的字符串转化为字符数组,然后按题目要求判断是不是Ascii码:32~126,空格,水平制表符,换行符,是的话就增加计数。
四、统计文件单词数
首先单词不分大小写,那可以先把所有字母转为小写。
因为非字母数字符号也属于分隔符,可以统一先转化为空格,便于之后判断。
现在得到的就是只由小写字母与数字加上空格的数据,把数据按空格拆分,组成字符串的集合。按照要求判断就可以得到合法的单词总数。
因为后面还有要求统计出现频率最高的单词,所以这里可以把合法单词和出现次数统计出来,于是可以使用MAP来保存键值对。
五、统计文件有效行数
我的想法是统计出所有行数减去空白行就是有效行数。
六、出现频率最高的10个单词
基于前面已经统计好的MAP里的数据,排序输出前十到list。
代码规范制定链接
设计与实现过程
一、类构建组织
为了实现功能独立,我将需求2、3、4、5封装在WordCountMethods类,进行字符数量、行数、单词数、词频的统计;将需求1、6封装进WordCountIO类,:进行文件内容的读取,以及处理结果的写入;最后设计一个WordCount类调用以上两个类的方法去实现WordCount功能。
二、主要方法设计
2.1 WordCountIO/读取文件转化为string形式
FileInputStream fileinputstream=new FileInputStream(filePath);
InputStreamReader inputstreamreader=new InputStreamReader(fileinputstream);
br = new BufferedReader(inputstreamreader);
int c;
while ((c = br.read()) != -1) {
strBud.append((char) c);
}
br.close();
return strBud.toString();
2.1.1 解释思路
最开始我是想到用BufferedReader中包装InputStreamReader类,但是一开始程序用的是BufferedReader类的readline(),后期单元测试的时候发现问题,readline当遇到换行符('\n'),回车符('\r')时会终止读取表示该行文字读取完毕且返回该行文字(不包含换行符和回车符),就会导致无法统计换行符、回车符,于是后来改用read(),读取1个或多个字节,返回一个字符,当读取到文件末尾时,返回-1。(具体改动版本可以参见我的README.md
2.1.2 好处
- BufferedReader会一次性从物理流中读取8k字节内容到内存, 如果外界有请求,就会到这里存取,如果内存里没有才到物理流里再去读。即使读,也是再8k。 而直接读物理流,是按字节来读,对物理流的每次读取,都有IO操作。IO操作是最耗费时间的。 参考来源
- StringBuilder 为动态数组可以有效的降低字符串拼接的损耗,避免频繁使用 s = s+"sss",对于stirng的"+="操作只适用于不在循环内的拼接。参考来源
2.2 WordCountMethods/统计文件有效行数
InputStream inpStr = new FileInputStream(filePath);
BufferedReader br = new BufferedReader(new InputStreamReader(inpStr));
//空白行的正则匹配器
Pattern blankLinePattern = Pattern.compile(BLANK_LINE_REGEX);
String line = null;
while ((line = br.readLine()) != null) {
if (blankLinePattern.matcher(line).find()) {
//是空白行就计数
blankLine++;
}
allLine++;
}
//有效行是总行数减去空白行数
validLine = allLine-blankLine;
return validLine;
2.2.1 解释思路
我的想法是统计出所有行数减去空白行就是有效行数.但是如何判断哪一行是空白行是个关键问题。
我经过上网搜索查阅资料,发现可以使用正则表达式"\s+"
正则表达式中\s+匹配任何空白字符,包括空格、制表符、换页符等等, 等价于[ \f\n\r\t\v]
\f -> 匹配一个换页
\n -> 匹配一个换行符
\r -> 匹配一个回车符
\t -> 匹配一个制表符
\v -> 匹配一个垂直制表符
2.3 WordCountMethods/统计合法单词数
int words = 0;
//先全部转小写
String lowerStr = str.toLowerCase();
//匹配非单词非数字的字符
Pattern pat = Pattern.compile(UN_ALPHABET_NUM_REGEX);
Matcher mat = pat.matcher(lowerStr);
//转换为空格
lowerStr = mat.replaceAll(" ");
//按规定的分隔符拆分
String[] word = lowerStr.split("\\s+");
for (int i = 0; i < word.length; i++) {
String tw = word[i];
//判断是不是要求的单词
if (tw.matches(FIRST_FOUR_APLH_REGEX)) {
words++;
if (!map.containsKey(tw)) {
map.put(tw, 1);
}
else {
int num = map.get(tw);
map.put(tw, num + 1);
}
}
}
2.3.1 解释思路
但是对于MAP的选择我也是选择和修改了很久,一个是Treemap另一个是hashmap。(最后是基于单元测试和性能分析,用比较大的数据去跑用treemap的代码和用hashmap的代码,发现treemap更快)(具体改动版本可以参见我的README.md
Treemap是基于红黑树,时间复杂度为O(logn),但是结果是排好序的,对于后面的统计出现频率最高的单词比较友好不用再排序。hashmap是基于哈希表,hashmap的时间复杂度为O(1),但是可以优化HashMap空间的使用调优初始容量和负载因子。
Java中HashMap和TreeMap的区别深入理解
2.4 WordCountMethods/统计出现频率最高的单词
Collections.sort(list,new Comparator<Map.Entry<String, Integer>>(){
//Treemap只要比较出现次数,不用再比较字典序
public int compare(Map.Entry<String, Integer> word1, Map.Entry<String, Integer> word2) {
return word2.getValue() - word1.getValue();
}
2.4.1 解释思路
基于上面选择的Treemap存储到的list当中,因为在map中的数据已经是按字典序排序的了,只要比较频率就可以,那么这里可操作性的点在于怎么取出方便的得到键值对。
3.4.2 好处
这里我使用Map.Entry,它是一个接口,他的用途是表示一个映射项(里面有Key和Value),而Set< Map.Entry<K,V>>表示一个映射项的Set。方法entrySet()返回值就是这个map中各个键值对映射关系的集合。可使用它对map进行遍历。
Map.Entry里有相应的getKey和getValue方法,让我们能够从一个项中取出Key和Value。entrySet的方式整体都是比keySet方式要高一些;
另一种遍历Map的方式: Map.Entry 和 Map.entrySet()
map遍历的几种方式和效率问题
性能改进
- 使用treemap存储键值对
首先是测试3000个单词使用treemap和hashmap在小数据测试下发现两种方法耗时差不多
之后测试300000个单词,可以看出treemap在计算单词数,把单词和次数的键值对存入map时花费时间较大,之后的输出频率最高的10个单词花费时间小。但是相反hashmap在存储的时间比较短相应增加最后输出排序的时间。
- 使用 BufferedReader和StringBuilder
具体详见 3.1 WordCountIO/读取文件转化为string形式
单元测试
一、模块正确性测试
| 单元测试名称 | 测试内容 |
|---|---|
| testCountChars() | 测试字符数(含有字母数字以及两种换行符 |
| testCountLines() | 测试有效行数(含有空行有效行 |
| testCountWords() | 测试单词数含有大写小写字母数字以及分隔符(包含有效单词和无效单词 |
| testHighFreqWord() | 测试输出频率最高的10个单词(包含大小写,非法单词,以及不同单词相同出现次数 |
二、整体正确性测试
| 单元测试名称 | 测试内容 |
|---|---|
| testFile1() | 测试正常含有字母、字符、换行符以及空行的文件 |
| testFile2() | 测试文件中只有换行和空格 |
| testFile3() | 测试正常含有字母、字符、换行符以及空行的文件(最后一行是空行,存在某行以空格加回车结尾 |
| testEmptyFile() | 测试空文件 |
三、异常处理测试
| 单元测试名称 | 测试内容 |
|---|---|
| testNotFoundFile() | 测试输入文件不存在 |
| testParamOne() | 测试输入参数不足两个 |
四、单元测试代码展示
模块测试单词数
含有大写小写字母数字以及分隔符
包含有效单词和无效单词
包含大小写属于同单词
StringBuilder stringBuilder = new StringBuilder();
for (int i = 0; i < 10; i++) {
stringBuilder.append("FILE").append(i).append(",");
}
for (int i = 0; i < 10; i++) {
stringBuilder.append("file").append(i).append("\n");
}
for (int i = 0; i < 10; i++) {
stringBuilder.append("a").append(i).append("\r");
}
for (int i = 0; i < 10; i++) {
stringBuilder.append(i).append("FILE").append("\r");
}
int countWords = WordCountMethods.countWords(stringBuilder.toString());
assertEquals(20,countWords);
模块测试输出频率最高的10个单词
包含大小写,以及相同出现次数按字典序排序
StringBuilder stringBuilder = new StringBuilder();
for (int i = 1991; i < 2001; i++) {
for (int j = 0;j < 10; j++) {
stringBuilder.append("windows").append(i).append(",");
}
}
for (int i = 9; i >= 0; i--) {
for (int j = 0;j < 10; j++) {
stringBuilder.append("LINUX").append(i).append("\n");
}
}
stringBuilder.append("windows").append("2000").append(",");
stringBuilder.append("windows").append("2000").append(",");
stringBuilder.append("windows").append("1999").append(",");
/*
处理string,生成map(省略
*/
String[] key = {"windows2000","windows1999","linux0","linux1",
"linux2","linux3","linux4","linux5","linux6","linux7"
};
Integer[] values = {12,11,10,10,10,10,10,10,10,10};
for (int i = 0; i < hotWords.size(); i++) {
Map.Entry<String, Integer> temp = hotWords.get(i);
assertEquals(key[i],temp.getKey());
assertEquals(values[i],(Integer)temp.getValue());
}
五、单元测试结果
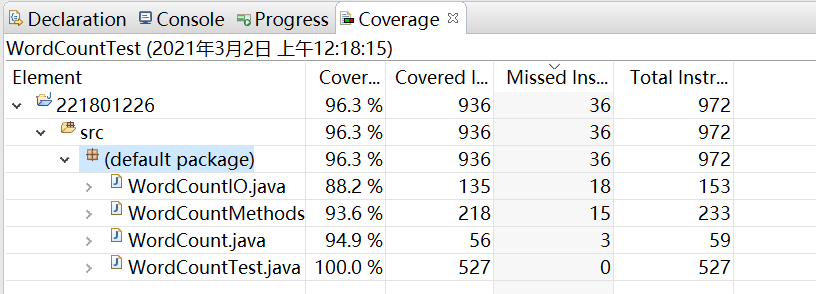
六、测试覆盖率
没到100%的原因是有一些关于文件流关闭打开的错误信息抛出无法测试。
异常处理说明
一、输入参数少于两个
如果参数两个以上,默认选最先输入的两个
if (args.length<2) {
System.out.println("ERROR:参数至少为两个,例如 java WordCount input.txt output.txt");
return;
}
二、读文件无法正常运行
try {
/*
用BufferedReader从文件读取内容(省略
*/
int c;
while ((c = br.read()) != -1) {
strBud.append((char) c);
}
br.close();
} catch (FileNotFoundException e) {
System.out.println("ERROR:文件未找到...\n");
e.printStackTrace();
} catch (IOException e) {
System.out.println("ERROR:字符输入流出错...\n");
e.printStackTrace();
}
三、写文件无法正常运行
/*
构建包含输出结果的StringBuffer(省略
*/
BufferedWriter writer = createFileWriter(filePath);
try {
writer.write(str.toString());
} catch (IOException e){
System.out.println("ERROR:写文件出错...\n");
e.printStackTrace();
} finally {
if (writer != null){
try {
writer.flush();
writer.close();
} catch (IOException e) {
throw new RuntimeException("ERROR:关闭输出流出错..."); }
}
}
心路历程与收获
一、项目之前
首先是重读《构建之法》。这次作业有点像是一个小小小型的项目,不像是之前的作业只要提交代码就可以了而且也没有那么多的规范,在作业的要求里的很多步骤发现和书中章节结合的很好,比如说像在之前的学习和编写代码过程中从来没有接触过单元测试和性能分析 ,但是读了老师的书和博客之后也是有了些基本的了解。 所以对于一些要求也不会不知所云。
第二是关于学习Git和Github,因为之前也没有做过什么大项目,所以对于这个的使用也是很茫然的。所以在PSP表格里的需求分析(包括学习新技术)这一项我的预估时间给了2个小时,但是结果学习时间还是超出了预期,但是还是收获满满。
二、项目之中
第一是养成完成一个小进展就commit一次的习惯,确实很好用,在本地库就可以随时看到我比较之前的代码有什么变动,以及也会保存之前的代码:)。
第二是代码的编写,其实看这个程序的要求不算多也不算是太复杂,但是一个学期没写Java代码确实是有点生疏,有些函数的使用也是边写边查发现还有更好的边改进。
第三是关于单元测试,最初由于是对于单元测试的不熟悉,所以本能的想用普通的方法在写代码的过程中去打开input.txt,写一些测试的例子,再一项一项的用命令行去测试:(,花费了很多时间。
最后是代码都基本完成,才开始用单元测试的插件和具体方法。所幸我有封装每个方法以及分成不同的类,以至于最后的单元测试没有花太多的时间去拆分单元。
第四是性能测试,对于这个也是和单元测试一样我对其是完全陌生的。我之前要是想得到这个方法的运行时间,都是使用Date类在方法首尾得到相减时间long time = endTime - begintime;
在这次项目中我使用的是Jprofiler,确实是很好用可以看出CPU在哪一个函数哪一个方法上运行的时间最多,以及内存的占用情况,方便于对于不同方法的测试和改进。
三、项目结尾
首先是最后审阅这个作业和作业要求的时候发现,自己漏看了commit message的推荐阅读,导致自己这一次的commit message编写不规范qaq。吸取一个教训,以后关于参考的知识要先都看一遍,对于之后的工作也是事半功倍。
第二通过PSP表格,确实这个看起来是一个会比以后实战小得多的项目比预期花了我挺多的时间,主要是花在学习新知识,还有养成习惯上。因为第一次使用PSP表格,有些时间记录的也不是很准确,但是可以看出有一个好的规划是很重要的,写代码不是埋头苦写。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号