质量看板开发实践(一):利用python获取jira数据-基础篇
最近一段时间,写了一个简易的测试质量看板,能够从不同维度查看缺陷分布情况;另外由于公司用的jira,所以也汇总了故事卡以及每个人的故事点情况
初版的效果如下:
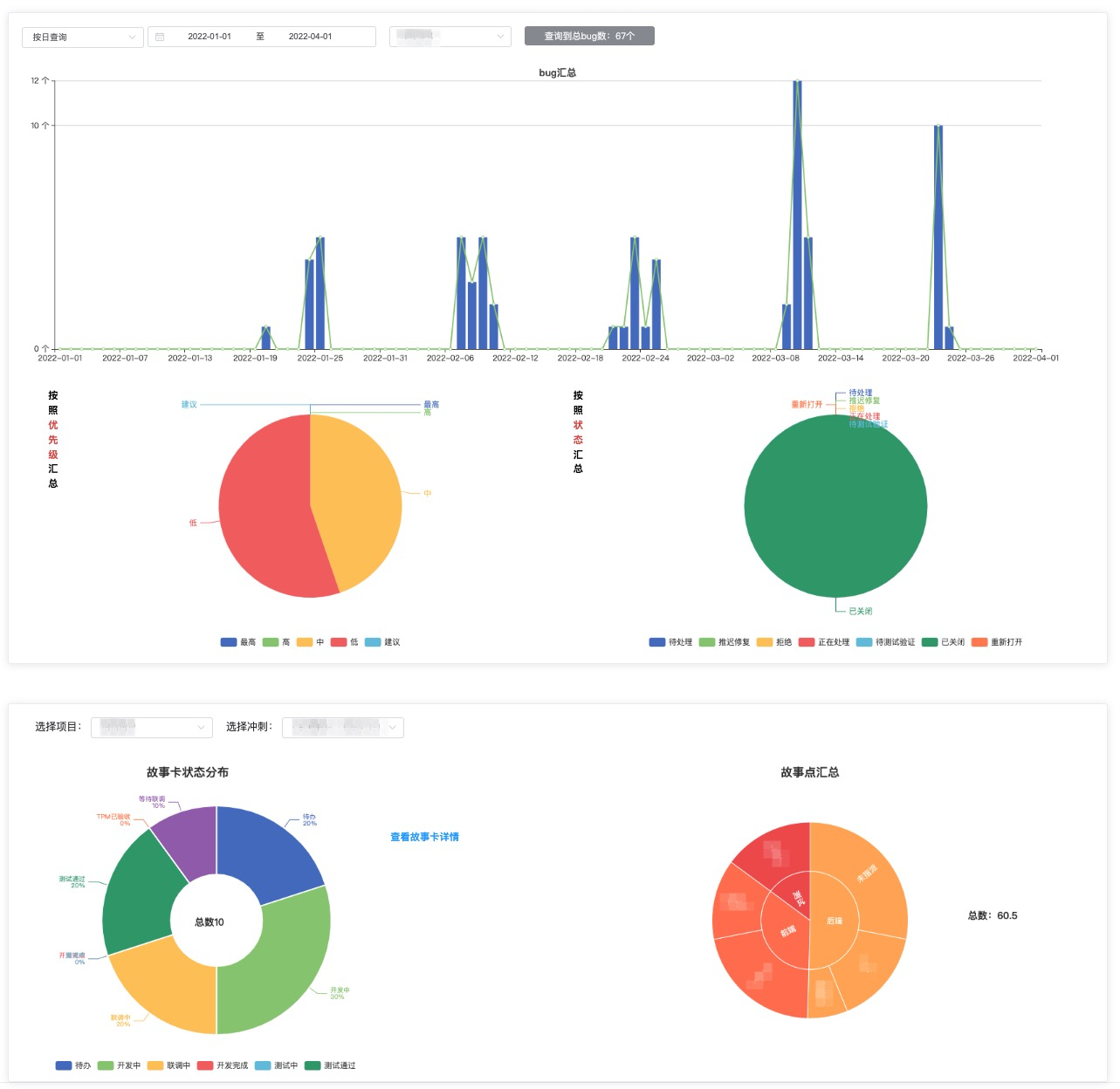
从本篇开始,将会写一系列文章把整个开发过程记录下来,包括但不限于:
1、后端如何提取jira中的数据,例如每个项目的bug情况、故事卡情况等;
2、提取数据后,如何进行组装,构造出前端需要的数据格式;
3、前端如何处理后端返回的数据,学习如何调整基本的样式;
4、利用echarts绘图时,调整图标的样式;
本篇为这个系列的第一章,先来学习一下怎样提取jira的数据
最初我打算登录公司内部的jira系统,看看能否抓一下登录的接口,然后再进行相关的操作,但是经过一番尝试后,最终以失败告终......
然后按照惯例开始【网上冲浪】,发现原来官方有一个封装好的jira库,可以通过这个库来对jira进行各种操作
1、连接jira
from jira import JIRA import requests jira = JIRA(server='http://jira.xxx.xxx/', basic_auth=('user', 'password'))
server中需要填写公司jira服务的域名;
basic_auth 中需要填写登录jira所需的用户名、密码
也可以按照如下方式连接
jira = JIRA(auth=('user', 'password'), options={'server': 'http://jira.xxx.xxx/'})
这样就得到了一个jira对象,可以通过这个jira对象来查看jira中的项目、缺陷、故事卡等等
2、查看项目project
projects = jira.projects() # 查看所有项目 project = jira.project("project_key") # 查看单个项目,需要输入项目的key
项目对象的主要属性及方法如下:
- key: 项目Key
- id: 项目id
- name: 项目名称
- components: 项目下的模块
- versions: 这个项目中已经创建好的影响版本
- raw: 项目的原始API数据
issue = jira.issue("issue_key") print(issue.raw) print(issue.key)
4、利用jql搜索
用过jira的肯定知道jira有自己专门的一套搜索语言,叫做JQL
我们在jira中做的任何查询操作,都可以转化为对应的jql语句
可以通过它来查询bug、查询故事(story)、子任务等等,用法如下
jql = "project = xxx AND issuetype = 缺陷" issues = jira.search_issues(jql)
它返回的是一个列表(一个符合搜索条件的jira对象集合),并且每个jira对象会包含所有原始信息
可以通过添加fields来指定返回原始信息的哪些字段(建议在进行搜索时加上fields参数,不然查询速度会比较慢)
另外还有一个maxResults参数,它用来控制返回结果的数量,一般设置为-1,表示返回所有结果
issues = jira.search_issues(jql, fields="summary, priority, status, creator, created, customfield_11200", maxResults=-1)
根据需要来指定fields的值,如果不确定自己需要的信息对应fields中的哪个字段,可以打印原始信息看看
常见的fields固定属性包括:
- summary,标题
- creator,创建者
- created,创建时间
- status,状态
- priority,优先级
- assignee,经办人
此外还有一些自定义属性,形如customfield_12309(例如前端负责人、前端故事点、故事卡提测日期等就是这种)
借助强大的jql,我们可以在代码中构造需要的jql语句,查询自己需要的结果
例如,根据创建日期的范围来查询bug,那么jql如下
jql = "project in ({}) AND issuetype = 缺陷 AND created >= {} AND created <= {}".format(project, start_date,end_date)
获取不同sprint的故事卡数据
jql = "project in ({}) AND issuetype = Story AND Sprint in ({})".format(project, sprint)
jql并不需要自己来写,在jira中设置好查询条件后,切换到【高级】,就自动给出对应的jql语句了
![]()
关于jira的学习参考了如下博文:
https://www.cnblogs.com/superhin/p/11693280.html
https://www.cnblogs.com/gcgc/p/12674341.html
https://jira.readthedocs.io/examples.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号