scrapy爬虫笔记(2):提取多页图片并下载至本地
上一节使用scrapy成功提取到 https://imgbin.com/free-png/naruto/ 第一页所有图片的下载链接
本节在之前的基础上,实现如下2个功能:
1、提取前10页的图片下载链接
2、下载图片至本地
一、提取指定页数图片
网站向后翻页,链接的后缀会发生如下变化
https://imgbin.com/free-png/naruto/2
https://imgbin.com/free-png/naruto/3
所以只需要构造一下传入的url即可,例如需要爬取10页图片,则 url 后缀需要从1遍历至10
1、在 settings.py 中,添加一个配置,表示最大爬取页码
MAX_PAGE = 3 # 定义爬取页数
2、编辑 images.py , 修改 start_requests()方法
def start_requests(self): base_url = "https://imgbin.com/free-png/naruto/" for page in range(1, self.settings.get("MAX_PAGE") + 1): url = base_url + str(page) yield Request(url=url, callback=self.parse)
使用 for 循环,达到 url后缀 自增的目的;
self.settings.get("MAX_PAGE") 表示读取settings.py配置文件中定义好的 MAX_PAGE 字段
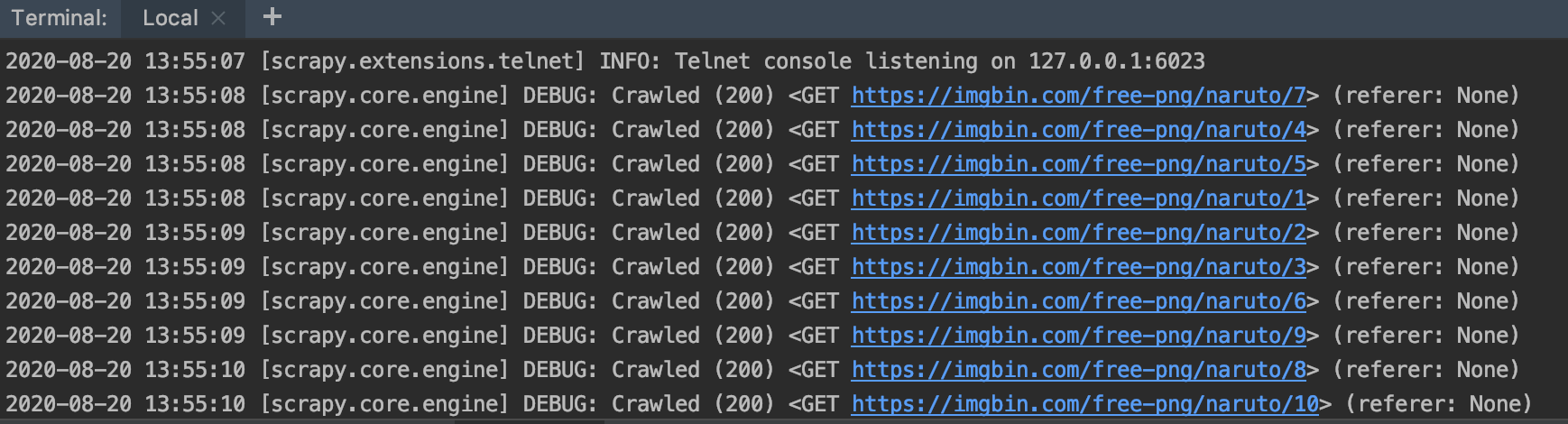
在终端输入 scrapy crawl images 运行一下,得到如下结果,说明发起了10次不同的请求
二、下载图片至本地
1、在 settings.py 中,添加一个配置,表示图片存储路径
IMAGES_STORE = './images' # 图片存储至当前项目目录下的images文件夹,如果没有则会新建一个
2、编辑 pipelines.py 文件 ,定义 Image Pipeline
# Define your item pipelines here # # Don't forget to add your pipeline to the ITEM_PIPELINES setting # See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html # useful for handling different item types with a single interface from itemadapter import ItemAdapter import scrapy from scrapy.exceptions import DropItem from scrapy.pipelines.images import ImagesPipeline from itemadapter import ItemAdapter class ImagePipeline(ImagesPipeline): def file_path(self, request, response=None, info=None): url = request.url file_name = url.split('/')[-1] # 以图片链接最后一段xxx.jpg作为文件名 return file_name def item_completed(self, results, item, info): image_paths = [x['path'] for ok, x in results if ok] if not image_paths: raise DropItem('Item contains no files') return item def get_media_requests(self, item, info): yield scrapy.Request(item['img_src'])
官方文档中有关于上述3个方法的简介:https://doc.scrapy.org/en/latest/topics/media-pipeline.html
(1)重写 file_path()方法,返回文件保存的文件名;
(2)重写 item_completed()方法,当单个Item完成下载时(下载完成或由于某种原因失败),将调用此方法;
参数 results 就是该 Item 对应的下载结果,它是一个列表形式,列表的每一个元素是一个元组,一个元组中包含一个状态码和一个字典,形如
[(True, {'checksum': '2b00042f7481c7b056c4b410d28f33cf', 'path': 'full/0a79c461a4062ac383dc4fade7bc09f1384a3910.jpg', 'url': 'http://www.example.com/files/product1.pdf', 'status': 'downloaded'}), (False, Failure(...))]
image_paths = [x['path'] for ok, x in results if ok], 等号右边是一个列表推导式,等价于
for ok, x in results: if ok: image_paths = [x['path']]
意思是如果results中某一元组结果的状态值为True,则取出该元组内字典中的path值
3、修改 settings.py,添加 ITEM_PIPELINES配置
ITEM_PIPELINES = { 'imgbin.pipelines.ImagePipeline': 300, }
imgbin是该scrapy项目的名称
ImagePipeline是 pipelines.py文件中定义的 Image Pipeline类名
最后在终端执行一下,就可以把前10页的图片下载至本地了

 浙公网安备 33010602011771号
浙公网安备 33010602011771号