scrapy爬虫笔记(1):提取首页图片下载链接
之前在写爬虫时,都是自己写整个爬取过程,例如向目标网站发起请求、解析网站、提取数据、下载数据等,需要自己定义这些实现方法等
这个周末把之前买的一个scrapy爬虫课程翻了出来(拉钩教育《52讲轻松搞定网络爬虫》,有兴趣的可以去看看),初步学习了一下scrapy的使用方法,刚好把以前写好的一个爬虫用scrapy改造一下,加深学习印象,也好做个对比
本次爬取的网站仍然是图片素材网站:https://imgbin.com/free-png/water
之前的爬虫过程如下:https://www.cnblogs.com/hanmk/p/12747093.html
scrapy官方文档:https://scrapy-chs.readthedocs.io/zh_CN/0.24/intro/overview.html
接下来使用scrapy来爬取该网站的图片素材,本节的目标是:提取图片的下载url,并且只提取第一页,暂时不做后续处理
1.网站分析

如上,一个图片占用一个div标签,定位到div下的img标签,然后提取 data-original属性的内容即可
因为这次只提取这一页的图片,所以可以先不考虑翻页导致url的变化(后续会逐步完善)
2.新建一个scrapy项目
打开cmd命令行窗口或者打开pycharm并切换到Terminal终端,任意切换到一个目录,然后输入如下命令
scrapy startproject imgbin
3.新建一个spider
进入刚刚创建好的项目目录,执行如下命令
scrapy genspider images imgbin.com
完成上述步骤后,会得到如下工程文件目录
4.编辑items.py
import scrapy class ImgbinItem(scrapy.Item): # define the fields for your item here like: # name = scrapy.Field() img_src = scrapy.Field()
因为我只需要提取图片下载链接,所以这里也只定义了一个字段用来存储提取到的图片url
5.编写spider文件,解析response
import scrapy from scrapy import Request from imgbin.items import ImgbinItem class ImagesSpider(scrapy.Spider): name = 'images' allowed_domains = ['imgbin.com'] start_urls = ['http://imgbin.com/'] def start_requests(self): base_url = "https://imgbin.com/free-png/naruto" yield Request(url=base_url, callback=self.parse) def parse(self, response): images = response.xpath("//img[@class='photothumb lazy']") for image in images: item = ImgbinItem() item["img_src"] = image.xpath("./@data-original").extract_first() yield item
(1) 首先导入了 Request 模块以及定义好的 ImgbinItem
(2) ImagesSpider类下有3个属性
-
name: 用于区别Spider。 该名字必须是唯一的,也可以为不同的Spider设定相同的名字; -
allowed_domains:允许爬取的域名,如果初始或后续的请求链接不是这个域名下的,则请求链接会被过滤掉;
-
start_urls: 包含了Spider在启动时进行爬取的url列表。 如果当没有定义 start_requests() 方法,默认会从这个列表开始抓取;
(3) 定义了 start_requests()方法
(4) 完善parse()方法
parse() 是spider的一个方法。 被调用时,每个初始URL完成下载后生成的 Response 对象将会作为唯一的参数传递给该函数。 该方法负责解析返回的数据(response data),提取数据(生成item)以及生成需要进一步处理的URL的 Request 对象。
images = response.xpath("//img[@class='photothumb lazy']"),使用xpath方式提取所有class属性为 photothumb lazy 的img标签,并将其赋给变量images;
item["img_src"] = image.xpath("./@data-original").extract_first(),利用for循环遍历所有images标签,并逐个提取内部的图片下载链接,并赋值给item中的"img_src"字段。注意"./@data-original",表示提取当前img标签里面的数据;
yield item,将最后的item对象返回
这样,第一页的所有图片的下载链接就都提取出来了
6.运行查看结果
打开cmd窗口,进入项目目录,执行以下命令
scrapy crawl images
结果如下,打印出了一个个图片下载链接

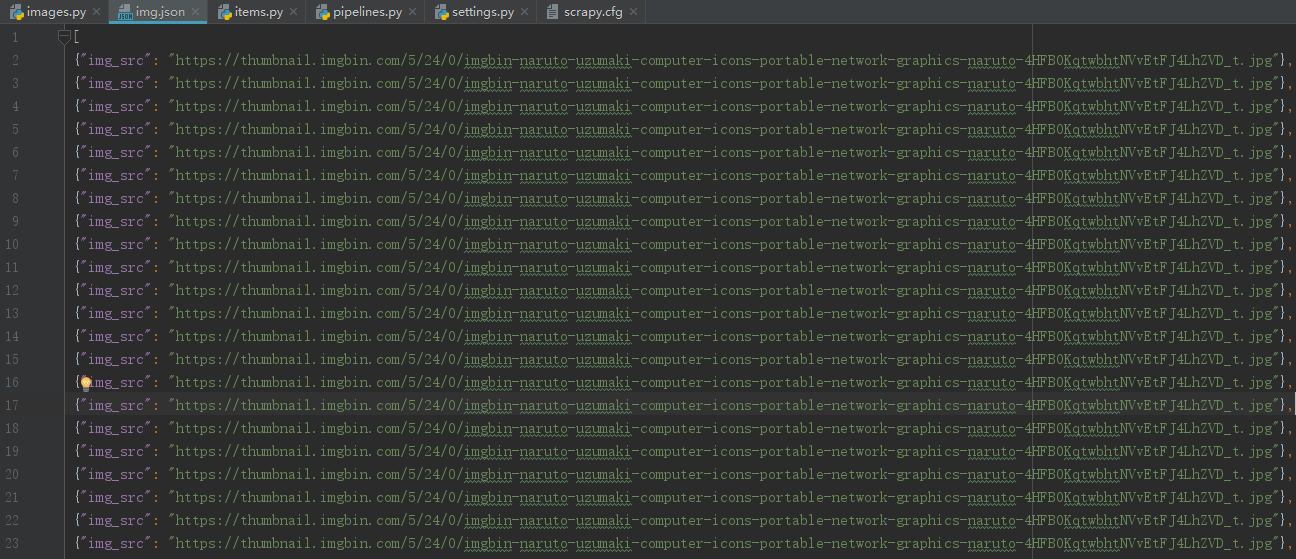
将结果存储到json文件中
scrapy crawl images -o img.json

 浙公网安备 33010602011771号
浙公网安备 33010602011771号