校招Java后端不知道做什么项目放到简历上?电商支付实战项目与相关面试题万字总结一条龙服务
接下来我将用一篇万字长文,总结好这个项目以达到可以正面硬钢面试官的水平,如果作为一个毫无头绪的大学生的你,简历中需要一个还算拿得出手的项目,那么在2023年的今天,足矣作为一个还算OK的项目写进你的简历。当然,这只能算简历中的第一个项目,你还需要一个更好一些的项目作为重头戏。(具体视频教程联系我)
因本人写下这篇文章时依旧才学疏浅,在本项目中暂时不考虑软件工程中所谓的各种可行性,需求分析,以及E-R图之类的东西。或者是所谓的企业级开发流程。但是还是会带你慢慢分析本项目的思路,这些思路也都是你现在所考虑不到的,本项目应当作为一个学习过程,不必过多焦虑,利用好本项目所学到的思路,以后再去分析你自己要做的项目。
该项⽬使用的是SpringBoot的SSM框架,数据库采⽤MySQL+Redis,消息中间件采⽤ RabbitMQ的一个 仿电商系统+通⽤型⽀付系统 的双系统项⽬,实现了支付、购物车、商品管理、用户管理、订单管理、地址管理等。
注意,建议学完除了Redis和RabbitMQ 的其他技术栈,若有不会,请打开我主页的其他文章,比如说Mybatis和Mysql的体系笔记,以及SpringBoot的注解笔记。或者找我获取笔记配套视频教程 or 自己在b站学也可。
简历书写
微电商支付系统(自己命名,不要和课程名字一样) 2021.9 ~ 2021.12(时间不能太短,至少3+个月)
项目介绍: 使用 SpringBoot + MyBatis + MySQL + Redis + RabbitMQ 进行系统的搭建,该项目是高仿微电 商系统+通用支付系统的双系统项目,实现了支付、购物车、商品管理、用户管理、订单管理、地址管理等。 (项目介绍,如果你很熟悉,也可以包装成参加比赛,毕业课设等)
我的职责:负责后端的实现,具体如下: 1、对后端各模块业务的逻辑进行实现,如购物车模块、订单模块的增删改查等。 2、使用 session 对用户登录状态进行保持,解决 HTTP 的无状态以及保证信息安全。 3、使用 Redis 实现了高性能购物车,减少 MySQL 数据库的压力。(购物车这里有很大概率被问) 4、使用 RabbitMQ 消息队列消费支付消息,异步处理消息,实现高性能。(MQ也是很大概率被问) 5、将支付模块独立成系统,实现与电商系统的解耦。 学习收获(可有可无)自己写吧,主要突然自己解决问题能力得到提升,对 xx 知识的理解更加深刻,对对接第三方平台接口怎么样怎么样,反正自己写吧,根据你自己的学习收获来
1.项目总体问题:
这个项目是做什么的?
该项⽬使用的是SpringBoot的SSM框架,数据库采⽤MySQL+Redis,消息中间件采⽤ RabbitMQ的一个 仿电商系统+通⽤型⽀付系统 的双系统项⽬。
完整的业务流程包括:用户登录或注册 → 查看商品列表 → 点击查看商品详细信息 → 点击加入购物车 → 想结算时点击购物车 → 可以选取购物车内的最终需要购买商品之后点击购买 → 选择收货地址(可以新增、删除)→ 确定提交下单(此时已经是提交下单成功了)→ 跳转支付界面(选择微信or支付宝)→ 显示实时生成的付款二维码 → 10分钟之内扫码付款(若未付款,需要重新生成订单) → 收到来自微信官方发来的支付结果通知 → 支付系统获取支付结果后通过消息队列MQ发给电商系统 → 电商系统接受MQ的消息再对数据库中的订单状态进行更改。
为什么要做这个项目?
因为我们学校的Javaweb期末大作业需要完成⼀个后端项目,然后我自己对微信支付这块比较感兴趣,并且这也是⼀个非常好的思考学习技术的机会,所以就想通过这个项目锻炼自己的业务开发的能力,并借此提升⾃⼰使⽤Java、数据库、框架和中间件的⽔平。
项⽬是不是跟着视频做的?
不是跟着视频,因为自己已经体系的学过相应的知识,当时也跟着视频做过一个简单的项目了,所以基本的开发流程已经知晓。这个项目一开始就是打算完整的自己写出来的而不是跟视频。所以就想着再真真正正的自己设计并实现⼀个项目,以此来锻炼自己学过的⼀些知识,不过说实话也确实也就做过一个很简单的项目,所以我通过 GitHub 和一些技术平台稀土掘金什么的,搜索⼀些项目教程,看看别⼈都是怎么做的,了解了一些基本的流程。然后再基于自己的一个理解,做出了这个项目。
2.数据库问题:
在设计数据库时我们可以从这2点开始梳理一下自己的思路。
-
表关系
-
表结构
-
唯一索引(不可重复)
-
单索引,组合索引(加快查询速度)
-
时间戳(方便业务、排查问题使用)
对于大多数企业级应用系统而言,数据库是整个应用系统的基石,因此数据库的表设计(也被称为schema设计)也就成为整个系统设计的重中之重。表设计的不好或者不合理,不仅会影响系统性能,而且会增加开发和集成的复杂性,甚至埋下隐患,最终会导致一系列的问题,例如数据不一致性问题等。概括而言,需要根据业务需求和系统功能,采用如下步骤设计表。
-
确定数据库类型。
-
判断表的类型,并据此构建表的列,确定表名。
-
设计表的主键以及表之间的关联关系。
-
优化设计,评估访问性能并根据查询模式添加索引。
应用系统往往涉及很多表,这些表的设计存在先后顺序,而表之间也具有各种关联和依赖关系。因此,表的设计并不是一蹴而就的,步骤2、3和4在大多数时候也不是清晰可分的,甚至整个设计也是一个循环迭代的过程,需要在多个步骤之间反复多次,以逐步的细化和优化。
-
表关系是怎么设计的?
数据库无非是表关系和表结构,都是需要结合电商⽀付的场景结合自己⽣活中购买商品的场景。不过之前一直没有分析过电商支付的业务逻辑,所以我特意去淘宝上逛了一下,具体分析了一下一个商品下单的一个流程,构思了一下大概需要几张表,之间有什么关系。那么我接下来具体说说表关系有哪些。
表关系分析:
我们打开淘宝,肯定是先跳出来登录界面,所以要存储登录和注册的信息 → 用户表
用户登录之后做什么事?→ 开始浏览各个商品,这些商品从哪来?→ 需要商品表
每个商品有各自的类别,可以点击不同的品牌,不同的材质,尺寸选取符合条件的商品出来?→ 需要商品分类表
用户最后选好商品之后,进行下单,订单是不是要存储好?→ 所以需要一个订单表
订单生成好之后?是不是要开始支付了 → 同理,还需要一个支付表
诶我们发现,支付前是不是还需要填写下地址?→ 收货地址表
支付时我们发现,订单一张表还不够,是不是还需要订单之中更细致的每个商品详细信息?→ 订单详情表
其次想⼀下表与表之间的关系
⽤户和收货地址。⼀个⽤户可以有多个收货地址 —— ⼀对多的关系。
分类和商品。⼀个分类,下⾯有多个商品 —— ⼀对多的关系。
订单和订单详情。⼀个订单有多个订单详情 —— ⼀对多的关系。
订单和⽀付。⼀个订单只能⽀付⼀次 —— ⼀对⼀的关系。
⽤户和商品,商品和订单他们有什么对应关系吗?其实没什么对应关系。
⽤户和订单是有对应关系的,⼀个⽤户可以有多个订单 —— 一对多的关系。
商品和订单的关系,⼀个商品可以被多个⽤户下多个订单。那⼀个订单它⼜可以买多个商品,相当于是多对多关系,所以我们没必要把它强⾏关联。
在设计的时候其实一边画图一遍想的,看一下总体的图吧。
总体关系图:
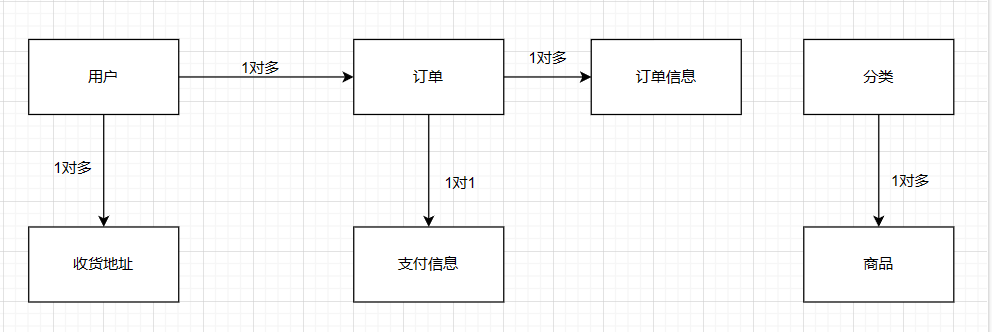
接下来就是具体每张表的字段和结构设计了
表结构是怎么设计的?
问起来就说:打个比方,比如说我们的什么什么表,然后讲讲索引怎么设计,时间戳怎么设计,具体的业务逻辑需要存储什么字段之类的。还有一个点就说表与表之间是要关联的,所以要想到数据是不是会变化,如果会变化,是不是在其他的表中进行存储?比如说我们的订单详情表。
用户表:
设一个用户⾃增id作为主键,然后是⽤户名,密码(使⽤MD5加密),邮箱,手机。⽤户可能会忘记密码,所以我们设置了⼀个找回密码的问题和答案。还有⼀个字段是角色,他是管理员还是普通⽤户。最后两个字段是创建和更新时间。主要是为了以后排查业务问题,出现了差错到时候可以查看修改时间来debug之类的
CREATE TABLE `mall_user` (
`id` int(11) NOT NULL AUTO_INCREMENT COMMENT '用户id',
`username` varchar(50) NOT NULL COMMENT '用户名',
`password` varchar(50) NOT NULL COMMENT '用户密码,MD5加密',
`email` varchar(50) DEFAULT NULL,
`phone` varchar(20) DEFAULT NULL,
`question` varchar(100) DEFAULT NULL COMMENT '找回密码问题',
`answer` varchar(100) DEFAULT NULL COMMENT '找回密码答案',
`role` int(4) NOT NULL COMMENT '角色0-管理员,1-普通用户',
`create_time` datetime NOT NULL COMMENT '创建时间',
`update_time` datetime NOT NULL COMMENT '最后一次更新时间',
PRIMARY KEY (`id`),
UNIQUE KEY `user_name_unique` (`username`) USING BTREE
) ENGINE=InnoDB DEFAULT CHARSET=utf8;收货地址表:
收货地址这个就很普通了,省份城市邮政编码详细地址,这个没有什么特别要注意的。
CREATE TABLE `mall_shipping` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`user_id` int(11) DEFAULT NULL COMMENT '用户id',
`receiver_name` varchar(20) DEFAULT NULL COMMENT '收货姓名',
`receiver_phone` varchar(20) DEFAULT NULL COMMENT '收货固定电话',
`receiver_mobile` varchar(20) DEFAULT NULL COMMENT '收货移动电话',
`receiver_province` varchar(20) DEFAULT NULL COMMENT '省份',
`receiver_city` varchar(20) DEFAULT NULL COMMENT '城市',
`receiver_district` varchar(20) DEFAULT NULL COMMENT '区/县',
`receiver_address` varchar(200) DEFAULT NULL COMMENT '详细地址',
`receiver_zip` varchar(6) DEFAULT NULL COMMENT '邮编',
`create_time` datetime DEFAULT NULL,
`update_time` datetime DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;分类表:
主键设计为自增的类别id,然后是字段parentid⽗类id,当ID等于0的时候说明是根结点。分类我们这⾥是⽀持多级分类的,这个分类其实是⼀个树状的结构。
为什么需要 parent_id ,可以想想我们的分类是不是一个大类别有很多小类别,其实长得很像一个树,所以我们需要一个值来区分 根 和 叶子 节点。然后还要考虑一下展示顺序的问题,比如说(一)(二)(三)要按照顺序来排列,所以用个值来标注一下哪个先展示。
CREATE TABLE `mall_category` (
`id` int(11) NOT NULL AUTO_INCREMENT COMMENT '类别Id',
`parent_id` int(11) DEFAULT NULL COMMENT '父类别id当id=0时说明是根节点,一级类别',
`name` varchar(50) DEFAULT NULL COMMENT '类别名称',
`status` tinyint(1) DEFAULT '1' COMMENT '类别状态1-正常,2-已废弃',
`sort_order` int(4) DEFAULT NULL COMMENT '排序编号,同类展示顺序,数值相等则自然排序',
`create_time` datetime DEFAULT NULL COMMENT '创建时间',
`update_time` datetime DEFAULT NULL COMMENT '更新时间',
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;商品表:
一些商品该有的东西
CREATE TABLE `mall_product` (
`id` int(11) NOT NULL AUTO_INCREMENT COMMENT '商品id',
`category_id` int(11) NOT NULL COMMENT '分类id,对应mall_category表的主键',
`name` varchar(100) NOT NULL COMMENT '商品名称',
`subtitle` varchar(200) DEFAULT NULL COMMENT '商品副标题',
`main_image` varchar(500) DEFAULT NULL COMMENT '产品主图,url相对地址',
`sub_images` text COMMENT '图片地址,json格式,扩展用',
`detail` text COMMENT '商品详情',
`price` decimal(20,2) NOT NULL COMMENT '价格,单位-元保留两位小数',
`stock` int(11) NOT NULL COMMENT '库存数量',
`status` int(6) DEFAULT '1' COMMENT '商品状态.1-在售 2-下架 3-删除',
`create_time` datetime DEFAULT NULL COMMENT '创建时间',
`update_time` datetime DEFAULT NULL COMMENT '更新时间',
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;订单表:
各个id都是同理,可以看到最下⾯paymenttime,starttime,endtime,closetime很多个时间,⽀付时间、发货时间、交易完成,交易关闭好多个时间。
搞这么多时间是原因可能是要求前端界面就要求展示这些时间,那他要展示,我必须得存着,不然怎么拿得出这些数据呢? 原因⼆是⽅便排查问题。假如有⼀个⽤户投诉过来了,说那个订单很久没有收到货,那 你肯定要过来看时间。这到底是卡在哪⼀步了,是吧?原因三是为了数据分析。我想知 道我们平台从⽤户⽀付到最终发出获取,这段时间平均大 概要多久呢?这时候你要把所 有的数据给他查出来,做个统计。
这四个字段,这四个时间你是怎么想出来的呢?为什么要设定这四个字段?
其实是根据订单的状态来的。想想刚开始下单的时候是新订单,新订单我记录⼀个下单时间,下单时间其实createtime已经有了。接着之后⽤户会去⽀付,所以有⼀个⽀付完成的时间。下完单之后,⽤户也可以不⽀付,他可能会取消,那么取消就有⼀个交易关闭的时间。总之你可以根据订单状态⼀旦有变化,就记录对应的变化。
CREATE TABLE `mall_order` (
`id` int(11) NOT NULL AUTO_INCREMENT COMMENT '订单id',
`order_no` bigint(20) DEFAULT NULL COMMENT '订单号',
`user_id` int(11) DEFAULT NULL COMMENT '用户id',
`shipping_id` int(11) DEFAULT NULL,
`payment` decimal(20,2) DEFAULT NULL COMMENT '实际付款金额,单位是元,保留两位小数',
`payment_type` int(4) DEFAULT NULL COMMENT '支付类型,1-在线支付',
`postage` int(10) DEFAULT NULL COMMENT '运费,单位是元',
`status` int(10) DEFAULT NULL COMMENT '订单状态:0-已取消-10-未付款,20-已付款,40-已发货,50-交易成功,60-交易关闭',
`payment_time` datetime DEFAULT NULL COMMENT '支付时间',
`send_time` datetime DEFAULT NULL COMMENT '发货时间',
`end_time` datetime DEFAULT NULL COMMENT '交易完成时间',
`close_time` datetime DEFAULT NULL COMMENT '交易关闭时间',
`create_time` datetime DEFAULT NULL COMMENT '创建时间',
`update_time` datetime DEFAULT NULL COMMENT '更新时间',
PRIMARY KEY (`id`),
UNIQUE KEY `order_no_index` (`order_no`) USING BTREE
) ENGINE=InnoDB DEFAULT CHARSET=utf8;订单信息表:
每下⼀个订单我可能包含多个商品。所以我们需要⼀个明细表来记录,明细表⾥⾯有ordernumber就是订单号了。再往下是商品ID、商品的名称、商品图⽚以及 ⽣成订单时商品的单价。为什么要存这么多呢?只存⼀个商品ID不就⾏了吗?有了商品ID剩下的商品名称、图⽚都可以去商品表⾥⾯查。现在存这么多,不是占⽤空间吗?这个空间还非占不可。想想商品的名称,还有图⽚以及它的单价,这些都是可变的。拿商品价格来说,昨天卖三⽑钱⼀件的,明天可能卖五⽑钱⼀件。 所以我肯定要记录⽤户购买那⼀瞬间这些商品属性的值是多少,这⼀点⾮常重要。
表关联的时候,⼀定要想到数据是不是会变化的。如果是会变化的那就该考虑给他做⼀个存档在其他表中了。
CREATE TABLE `mall_order_item` (
`id` int(11) NOT NULL AUTO_INCREMENT COMMENT '订单子表id',
`user_id` int(11) DEFAULT NULL,
`order_no` bigint(20) DEFAULT NULL,
`product_id` int(11) DEFAULT NULL COMMENT '商品id',
`product_name` varchar(100) DEFAULT NULL COMMENT '商品名称',
`product_image` varchar(500) DEFAULT NULL COMMENT '商品图片地址',
`current_unit_price` decimal(20,2) DEFAULT NULL COMMENT '生成订单时的商品单价,单位是元,保留两位小数',
`quantity` int(10) DEFAULT NULL COMMENT '商品数量',
`total_price` decimal(20,2) DEFAULT NULL COMMENT '商品总价,单位是元,保留两位小数',
`create_time` datetime DEFAULT NULL,
`update_time` datetime DEFAULT NULL,
PRIMARY KEY (`id`),
KEY `order_no_index` (`order_no`) USING BTREE,
KEY `order_no_user_id_index` (`user_id`,`order_no`) USING BTREE
) ENGINE=InnoDB DEFAULT CHARSET=utf8;支付信息表:
所以我们的字段怎么设计?⾃增ID订单号,⽀付平台,1是⽀付宝,2是微信。platform number是第三⽅⽀付平台给我们的⼀个订单号,每次发起⽀付时⾃⼰有⼀个订单号,请求⽀付平台之后,他会返回给我们⼀个⽀付平台的订单号。 支付之后,支付超时?支付失败?支付成功?如果忘记了这些信息,是不是会导致重复多次支付或者没给钱就发货了?所以要有一个字段是⽀付状态。当然还有最重要的支付金额,没有金额的支付还叫什么支付呢是吧。
DROP TABLE IF EXISTS `mall_pay_info`;
CREATE TABLE `mall_pay_info` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`user_id` int(11) DEFAULT NULL COMMENT '用户id',
`order_no` bigint(20) NOT NULL COMMENT '订单号',
`pay_platform` int(10) DEFAULT NULL COMMENT '支付平台:1-支付宝,2-微信',
`platform_number` varchar(200) DEFAULT NULL COMMENT '支付流水号',
`platform_status` varchar(20) DEFAULT NULL COMMENT '支付状态',
`pay_amount` decimal(20,2) NOT NULL COMMENT '支付金额',
`create_time` datetime DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
`update_time` datetime DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '更新时间',
PRIMARY KEY (`id`),
UNIQUE KEY `uqe_order_no` (`order_no`),
UNIQUE KEY `uqe_platform_number` (`platform_number`)
) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8;由于具体每个表的数据过于庞大,建议点击我的置顶随笔联系我发你。当然你要是不嫌麻烦可以自己插入点数据作为测试。
索引怎么设计的?
-
唯一索引(不可重复)保证数据的唯⼀性
所谓唯一索引,就是每个表中有一个不能重复的值,比如说id或者名字
-
单索引,组合索引(加快查询速度)
其实这个涉及到MySQL的底层原理了,个人推荐一本书,《MySQL是怎样运行的》,强烈建议去搞PDF或者花个20块买本掘金小册看,看完之后面试关于MySQL的问题基本可以迎刃而解。由于需要的篇幅过长,就不进行过多讲解,大概就是给某些经常需要出现在where语句里的列名建立一个索引,这样可以加快查询速度。
为什么要设计时间戳?
这个其实是业务才需要使用的东西,一般给每个表设立2个时间戳,一个是创建时间,一个是最后一次更新的时间,到时候有bug可以通过打印日志的方式高效率排查错误。比如说某个订单出现了问题,可以通过时间戳来校验。(方便业务、排查问题使用)
MySQL 某条语句执行的好慢,访问数据库超时了,怎么排查?
-
根据故障时段,推断出故障是跟哪个功能有关。
-
根据系统能在流量峰值过后⾃动恢复这⼀现象,排除是其他后台服务被⼤量请求打死的可能性(内存溢出、栈溢出或者进程直接挂掉)。然后可以把排查问题的重点 放到 MySQL 上。
-
观察 MySQL 的 CPU 利⽤率,假如很⾼的话⼀般来说就是SQL导致的,去分析慢查询日志(慢 SQL 的⽇志中,会有这样⼀些信息:SQL、执⾏次数、执⾏时长。)找到可能的烂SQL。
-
修改⽐较烂的SQL,或者适当做做缓存,再来看慢查询⽇志还有没有那个SQL,没有了说明改对了。
-
再查看 MySQL的 CPU 利⽤率,如果还不正常就继续观察 CPU 利⽤率曲线变化规律,推断可能的问题比如缓存使⽤不当,刷新得太慢或者其他原因,这个时候就想办法去对症下药了做针对性地预防和改进。
针对慢SQL,为了让整个系统更加健壮,不⾄于因为某⼀个小的失误,就导致全站无法访问,可以这样设计:
-
上线⼀个定时监控和杀掉慢 SQL 的脚本。这个脚本每分钟执⾏⼀次,检测上⼀分钟内,有没有执⾏时间超过⼀分钟(这个阈值可以根据实际情况调整)的慢 SQL,如 果发现,直接杀掉这个会话。这样可以有效地避免⼀个慢 SQL 拖垮整个数据库的悲 剧。即使出现慢 SQL,数据库也可以在⾄多 1 分钟内⾃动恢复,避免数据库⻓时间不可⽤。代价是,可能会有些功能,之前运⾏是正常的,这个脚本上线后,就会出现问题。但是,这个代价还是值得付出的,并且,可以反过来督促开发⼈员更加小心,避免写出慢 SQL。
-
做某个模块相应的降级⽅案。⽐如⾸⻚,做⼀个简单静态页面的首页 ,只要包含商品搜索栏、⼤的品类和其他顶级功能模块⼊⼝的链接就可以了。在 Nginx 上做⼀个 策略,如果请求⾸⻚数据超时的时候,直接返回这个静态的⾸⻚作为替代。这样后 续即使⾸⻚再出现任何的故障,也可以暂时降级,⽤静态⾸⻚替代。⾄少不会影响 到⽤户使⽤其他功能。
-
优化缓存置换策略
前两个⽅法容易实施,不需要对系统做很⼤的改造,并且效果也⽴竿⻅影。
那假如找到慢的 SQL 了怎么优化呢?
第⼀:索引优化。使⽤索引避免全表扫描,毕竟SQL执⾏速度的快慢关键还是语句需要 扫描数据的⾏数,同时尽量只获取需要的列。避免索引失效,特定业务 可以设置联合索引让需要查询返回的列都在索引中避免回表操作。具体查看《MySQL是怎样运行的》的7.4节
第⼆:排序优化。排序也是可能完成慢SQL的因素,尤其是数据量⼤,需要使⽤外部排序的时候⼜可以与磁盘IO性能扯上关系等,常⻅的问题还有limit m,n m很⼤⼜⽆法使⽤索引的时候,可以通过查询排序数据⾥⾯最小的。
第三:join优化。多表联合查询的时候,尽量使⽤小表驱动⼤表。具体查看《MySQL是怎样运行的》的11.2节
第四:避免⼤事务。将⼤事务复杂的SQL,拆分成多个⼩的SQL单个表执⾏,获取的结果在程序中进⾏封装,尽量减小事务粒度,减少锁表的时间。最后假如 SQL 本身没问题了,但是还是慢,那就可能是数据库自己的慢导致的 SQL 慢了。⾸先看看数据库参数设置有没有问题,其次还有数据量到达⼀定规模后,单机性能容易受限导致数据库响应慢;读写分离,从库提供读服务,错误的认为从库只需要提供 查询服务采⽤了达不到性能指标的机器,其实是主库承受的数据更新压力,从库⼀个不落的都要承受,还要更多的提供查询服务。
3.用户问题:
⽤户管理是怎么实现的?
先看一张图
因为HTTP协议是⽆状态⽆连接的协议,服务端对于客户端每次发送的请求都认为它是⼀ 个新的请求,上⼀次会话和下⼀次会话是没有联系的。因为它⽆法保存登录状态,所以 从协议本身来说,它不适合⽤来做会话管理。
因此,我们会使⽤⼀个上层应⽤去实现我们的会话管理功能。这个应⽤可以在切换页面时保持登录状态,并且对⽤户是透明的,这样就使得我们能在短时间内再次访问⼀个登录过的页面,就会保持登录状态。
我采⽤的是基于session的认证: 登录的时候⾸先根据⽤户名查询⽤户,如果查不到或者查询出来密码比对发现错误就返回错误;
查到了密码还正确就是登录成功,把用户数据信息在密码清空后再放到session 的currentUser属性⾥,也放⽤户信息到响应体⾥返回。退出登录的时候再清空。
Web应⽤服务器会给⽤户配置⼀个sessionid,并将它存储在服务器内存中,之后再把这个sessionid发送给⽤户。下次在进⾏需要登录的操作时前端发送请求的时候在请求头⾥带上sessionId,服务器的拦截器拦截判断根据这个session⾥⾯是否有⽤户信息,有说明已经登录过了,没有则返回错误。
有没有可能攻击者盗⽤sessionid绕过身份认证?
假如说浏览器禁⽤cookie,sessionid只能重写在URL中,攻击者发起会话固定攻击怎么办?
攻击者⾸先访问⼀个需要登录的⽹站,获取到 Web 应⽤返回的 sessionid 信息。由于攻击者没有账户密码,所以只能通过发送⼀个诱骗信息url上带着这个sessionid给受害者,使得受害者⽤这个 sessionid 实现登录操作。这样攻击者的 sessionid 就通过了验证,使得攻击者再次⽤这个 sessionid 信息访问被攻击⽹站时,可以直接通过保持登录 的认证。
解决: 只要在⽤户登录时重置 session(session.invalidate()⽅法),然后把登录信息保存到新的 session中即可。 为了安全考虑,Web应⽤通常会给 sessionid 设置⼀个过期时间,使得 sessionid 仅在某个时间段内有效。
浏览器突然关闭了,你⼜如何让⽤户⾃动退出 呢?
-
浏览器关闭的时候,发送请求到后台调⽤退出接⼝,根据 sessionid来删除当前会话 的⽤户信息或者把cookie给⼲死,session没有对应的sessionid等于废了。
-
设置session的有效期⽐如30分钟。写⼀个监听类,session超时的时候会⾃动删除 session对应的⽤户数据;
怎么保证⽤户密码的安全?
每个⽤户需要⼀个盐值,密码要加⼀个盐值再进⾏加密。 这样相同的密码可以⽣成不同的hash值。
或者加密算法MD5 可以换成SHA安全hash算法,安全等级更⾼,但是加密速度更慢。
怎么防⽌别⼈⽤脚本批量注册刷掉⽹站?
可以加⼀个通过邮件、短信向⽤户发送验证码的环节,验证码存在redis⾥,⽤户输⼊验证码和redis⾥的判断,成功才能注册。 对于短信验证码这种开放接⼝,程序逻辑内需要有防刷逻辑。好的防刷逻辑是,对正常使⽤的⽤户毫⽆影响,只有疑似异常使⽤的⽤户才会感受到。对于短信验证码,举两个常见的⽅式来防刷。
第⼀种⽅式,控制相同⼿机号的发送次数和发送频次。
第⼆种⽅式,增加图形验证码。
一些分布式问题
当多点部署服务器的时候,你在服务器a上登录, 服务器b 如何得到⽤户登录信息?
如果每个服务器都有该⽤户的session,如果有很⼤的⽤户量,假如500万⽤户是每个服务器存了8g的session信 息,如果再来500万,岂不是各个服务器均要扩容到16G,即每个服务器都需扩容容量,怎么优化?
如果在多个实例之间处理同⼀个⽤户的登录状态?
这些问题统统采用 JWT、分布式session的方法,不过目前还未细学。只是大概了解有这2个方法,不过校招对分布式要求不高,只是加分项而已,问题不大。
4.商品问题:
商品管理是怎么实现的?
商品信息假如字段越来越多,而且流量上来了怎 么办?
⽆法⼀个系统解决,需要分而治之
-
从存储层面来说,数据区分为:固定结构数据、⾮固定结构数据、富媒体数据
-
从读取层⾯,将数据分为:经常变化数据、非经常变化数据
1.从数据存储到哪的角度:
-
固定结构数据: 商品主标题、副标题、价格,等商品最基本、最主要的信息(任何商品都有的属性)
-
存储到:MySQL中
-
-
非固定结构数据: 商品参数,不同类型的商品,参数基本完全不⼀样。电脑的内存⼤⼩、⼿机的屏幕 尺⼨、酒的度数、⼝红的⾊号等等。
-
存储到不需要固定结构的存储:MongoDB或者MySQL的 json字段中
-
-
富媒体数据: 商品的主图、详情介绍图⽚、视频等富媒体数据
-
存储到:对象存储。并且通过客户端直接调⽤对象存储的API,得到媒体资源在对象存储中的ID或者URL之后,将ID或者URL提交到MySQL中。对象存储⾃带CDN加速服务,响应时间快。比如阿里云OSS
-
2.从数据读取角度:
-
存储到MySQL中的数据,需要设计⼀层缓存层⽐如Redis,应对⾼并发读
-
对于不经常变动的数据: 可以交给前端静态化加速处理
数据量最⼤的图⽚、视频和商品介绍都是从离⽤户最近的 CDN 服务商获取的,速度 快,节约带宽。真正打到商品系统的请求,就是价格这些需要动态获取的商品信息,⼀ 般做⼀次 Redis 查询就可以了,基本不会有流量打到 MySQL 中。这样⼀个商品系统的 存储的架构,把⼤部分请求都转移到了⼜便宜速度⼜快的 CDN 服务器上,可以⽤很少 量的服务器和带宽资源,抗住⼤量的并发请求。
MongoDB 最⼤的特点就是,它的“表结构”是不需要事先定义的
其实,在 MongoDB 中根本没有表结构。由于没有表结构,它⽀持你把任意数据都放在同⼀张表⾥,你甚⾄ 可以在⼀张表⾥保存商品数据、订单数据等这些结构完全不同的数据。
并且,还能⽀持 按照数据的某个字段进⾏查询。它是怎么做到的呢?
MongoDB 中的每⼀⾏数据,在存 储层就是简单地被转化成 BSON 格式后存起来,这个 BSON 就是⼀种更紧凑的 JSON。 所以,即使在同⼀张表⾥⾯,它每⼀⾏数据的结构都可以是不⼀样的。
当然,这样的灵活性也是有代价的,MongoDB 不⽀持 SQL,多表联查和复杂事务⽐较孱弱,不太适合存储⼀般的数据。
但是,对于商品参数信息,数据量⼤、数据结构不统⼀,这些 MongoDB 都可以很好的满⾜。我们也不需要事务和多表联查,MongoDB 简直就是为 了保存商品参数量身定制的⼀样。不过最新的MySQL⽀持json了所以其实不⽤MongoDB也ok
5.支付与订单问题:(重点!!)
订单管理是怎么实现的?
⽀付系统是怎么实现的?
为什么支付系统要独立出来?
把业务和⽀付解耦开来。今天电商系统需要⽀付,明天活动系统需要⽀付,你只需要跳转到⽀付系统就可以发起⽀付。在新增的业务系统的情况下,⽀付系统不需要动一行代码,这就是解耦的优势。
怎么防止重复下单?
假如说,⽤户点击“创建订单”的按钮时⼿⼀抖,点了两下,浏览器发了两个 HTTP 请求。
⾸先前端⻚⾯上应该防⽌⽤户重复提交表单,不过这个不可靠,因为⽹络错误会导致重传,很多⾮⽤户操作的部分都会有⾃动重试机制。
大概分为2个方法:
-
利用数据库唯⼀索引约束
解决办法是,让你的订单服务具备幂等性: 我们可以利⽤数据库的主键唯⼀约束特性,在插⼊数据的时候带上主键,来解决创建订单服务的幂等性问题。
具体的做法是这样的:我们给订单系统增加⼀个“⽣成订单号”的服务,这个服务的返回值就是⼀个新的、全局唯⼀的订单号。(企业级是使用分布式唯一id,但是这个项目使用的是当前系统时间 + 一个随机值从而实现订单号大概率是唯一的。
在⽤户进⼊创建订单的页面时,先调⽤这个⽣成订单号服务得到⼀个订单号,在⽤户提交订单的时候,在创建订单的请求中带着这个订单号。
这个订单号也是我们订单表的主键,这样,⽆论是⽤户手抖, 还是各种情况导致的重复请求,这些请求中带的都是同⼀个订单号。订单服务在订单表中插⼊数据的时候,执⾏的这些重复 INSERT 语句中的主键,也都是同⼀个订单号。数据库的唯⼀约束就可以保证,只有⼀次 INSERT 语句是执⾏成功的,这样就实现了创建订单服务幂等性。
还有⼀点需要注意的是,如果是因为重复订单导致插⼊订单表失败,订单服务不要把这个错误返回给前端⻚⾯。否则,就有可能出现这样的情况:⽤户点击创建订单按钮后, ⻚⾯提示创建订单失败,⽽实际上订单却创建成功了。
正确的做法是,遇到这种情况, 订单服务直接返回订单创建成功就可以了。
-
利⽤Redis防重
下单请求的时候加锁,通常我们的服务都是集群部署,所以一般是⽤Redis实现分布式锁。 ⼤概的逻辑: 以requestId为维度,进⾏加锁,如果获取锁失败,就抛⼀个⾃定义的重复下单异常。 如果获取到锁,先check⼀下,是否已经下单,为了提⾼性能,下单完成后,也把下单 的结果放在Redis缓存⾥。
如何解决客户的恶意下单问题?
封IP,nginx中设置,单个IP访问频率和次数多了之后进行拉⿊操作。
如果用户支付成功,但是看到订单的状态还是未支付,于是又去支付了⼀次,会重复支付吗?
⽤户再次发起⽀付请求的时候,⽀付系统会带着要⽀付的订单的ID来⽣成⽀付信息⼊库,⽀付信息中的订单ID是加了唯⼀索引的,只要是同⼀个订单是没办法进⾏重复⽀付的。
订单id是怎么生成的?怎么保证唯⼀性?
如果单纯是⽣成全局唯⼀ID⽅法有很多,⽐如⼩规模系统完全可以⽤MySQL的sequence表,可以每次请求从sequence表⾥拿⼀组id,放到内存,⽤完了再拿。或者 Redis单线程原⼦递增操作来⽣成。⼤规模系统也可以采⽤类似雪花算法之类的⽅式分布 式⽣成全局唯⼀ID。也可以⽤uuid,不过容易导致数据库⻚分离,这个也可以解决,订 单号设为唯⼀索引约束即可,仍然有个⾃增主键,订单号对外⽤,主键不暴露,这样表 空间还是紧密的,其他关联订单表仍然以订单号作外键,不过不⽤订单号作主键的话导 致的就是多⾛⼀次索引,⽽且还会影响插⼊更新性能,各有优劣。 但是订单号这个东⻄⼜有点⼉特殊要求,⽐如在订单号中最好包含⼀些品类、时间等信 息,便于业务处理,再⽐如,订单号它不能是⼀个单纯⾃增的ID,否则别⼈很容易根据 订单号计算出你⼤致的销量,所以订单号的⽣产算法在保证不重复的前提下,⼀般都会 加⼊很多业务规则在⾥⾯,这个每家都不⼀样,算是商业秘密吧。 同时还得尽可能的短。
用户下单这个时刻,正好赶上商品调价怎么处理?
假如说商品可以单独下单的话。⾸先,商品系统需要保存包含价格的商品基本信息的历史数据,对每⼀次变更记录⼀个⾃增的版本号。
在下单的请求中,不仅要带上SKUID, 还要带上版本号。订单服务以请求中的商品版本对应的价格来创建订单,就可以避免下单时突然变价的问题了。 但是,这样改正之后会产⽣⼀个很严重的系统漏洞:⿊客有 可能会利⽤这个机制,以最便宜的历史价格来下单。所以,我们在下单之前需要增加⼀个检测逻辑:请求中的版本号只能是当前版本或者上⼀个版本,并且使⽤上⼀个版本要有⼀个时间限制,⽐如说调价5秒之后,就不再接受上⼀个版本的请求。这样就可以避免这个调价漏洞了。 对于我们系统下单前必须先把商品加⼊购物⻋,所以如果购物⻋看到⼀个价格,下单时会重新检查当前价格和最新价格,如果发⽣变更,⼀般会在下单页面给出提醒,重新刷新当前页面来解决。
假如支付完了微信⼀直不回调怎么办?
设定一个定时任务或者延迟消息,对没有回调的⽀付订单主动查询状态。
怎么防止超卖?
使⽤了MySQL的事务,默认的隔离级别,因为读是快照读MVCC,所以加了排它锁来当前读,然后事务提交锁才会释放,通过悲观锁解决的超卖问题。同时对死锁问题进⾏了优化,加锁是按照商品id排序之后加锁的。 可以将库存放到Redis,然后利⽤Lua原⼦性地检查库存之后再更新扣减。
减库存成功了,但是⽣成订单失败了,该怎办?
⾮分布式的系统中使⽤Spring提供的事务功能即可。
6.购物车与Redis问题
购物车管理是怎么实现的?
在项⽬中基于缓存Redis实现了⾼性能购物⻋。 缓存的数据类型⽤的是hash(是一种K-KV的存储结构)。⾸先redis的key是⽤户id,value是hash,hash⾥⾯的 key是商品id,value是商品id、商品在购物⻋中的数量、商品是否选中的结构体的Json 串。
<⽤户id,<商品id,<商品id,商品num,商品selected>>>。
为什么⽤Redis不直接⽤MySQL?⽤Redis丢数据 了怎么办?
因为购物⻋是写多读多的场景,可以⽤Redis的读写缓存模式来实现,读写都基于 redis 来操作能减少IO次数加快数据操作的性能,提升⽤户体验,同时还能减少对Mysql数据库的压⼒。 如果说怕丢数据的话可以⽤MySQL给Redis提供⼀个备份功能,主存储还是⽤ Redis,⽐如写完Redis之后通过MQ异步备份到MySQL,这样MySQL就起到⼀个备份的 作⽤,同时MySQL备份了数据假如Redis挂了MySQL可以提供降级服务保证可⽤性。
如果项⽬中的Redis挂掉,如何减轻数据库的压力?
组redis集群,主从模式、哨兵模式、集群模式。
主从模式中:如果主机宕机,使⽤slave of no one 断开主从关系并且把从机升级为主机。
哨兵模式中:⾃动监控master / slave的运⾏状态,基本原理是:⼼跳机制+投票裁决。 每个sentinel会向其它sentinel、master、slave定时发送消息(哨兵定期给主或者从和 slave发送ping包,正常则响应pong,ping和pong就叫⼼跳机制),以确认对⽅是否 “活”着,如果发现对⽅在指定时间内未回应,则暂时主观认为对⽅已挂。 若master被判断死亡之后,通过选举算法,从剩下的slave节点中选⼀台升级为 master。并⾃动修改相关配置。
7.MQ问题(一些mq的八股文罢了,慢慢更新)
为什么要使⽤消息队列?
-
解耦
A 系统跟其它各种乱七⼋糟的系统严重耦合,A 系统产⽣⼀条⽐较关键的数据,很多系 统都需要 A 系统将这个数据发送过来。A 系统要时时刻刻考虑 BCDE 四个系统如果挂了 该咋办?要不要重发,要不要把消息存起来?头发都⽩了啊! 如果使⽤MQ,A 系统产⽣⼀条数据,发送到 MQ ⾥⾯去,哪个系统需要数据⾃⼰去 MQ ⾥⾯消费。如果新系统需要数据,直接从 MQ ⾥消费即可;如果某个系统不需要这 条数据了,就取消对 MQ 消息的消费即可。这样下来,A 系统压根⼉不需要去考虑要给 谁发送数据,不需要维护这个代码,也不需要考虑⼈家是否调⽤成功、失败超时等情 况。 通过⼀个MQ,Pub/Sub 发布订阅消息这么⼀个模型,A 系统就跟其它系统彻底解耦 了。 ⽀付系统模块,调⽤了电商系统模块,互相之间的调⽤有可能以后增加了业务之后会很 复杂,维护起来很麻烦。但是其实这个调⽤是不需要直接同步调⽤接⼝的,如果⽤MQ 给它异步化解耦,也是可以的
-
异步
⼀般互联⽹类的企业,对于⽤户直接的操作,⼀般要求是每个请求都必须在短时间内完成,这样对⽤户才是⽆感知的。 如果使⽤ MQ,那么⽀付系统连续发送 3 条消息到 MQ 队列中,假如耗时 5ms,A 系统 从接受⼀个请求到返回响应给⽤户,总时⻓是 3 + 5 = 8ms,对于⽤户⽽⾔,其实感觉上 就是点个按钮,8ms 以后就直接返回了,爽!⽹站做得真好,真快! 异步化提升⽤户体验,同时消息队列能保证消息的可靠;并且对⽐同步的⽅式,同步的 ⽅式会卡住⽤户,还可能有⽐如浏览器不⼩⼼关闭或者⽤户关闭,导致⻚⾯跳转不了也 就⽆法修改订单数据。
-
削峰
每天 0:00 到 12:00,A 系统⻛平浪静,每秒并发请求数量就 50 个。结果每次⼀到 12:00 ~ 13:00 ,每秒并发请求数量突然会暴增到 5k+ 条。但是系统是直接基于 MySQL 的,⼤量的请求涌⼊ MySQL,每秒钟对 MySQL 执⾏约 5k 条 SQL。 ⼀般的 MySQL,扛到每秒 2k 个请求就差不多了,如果每秒请求到 5k 的话,可能就直 接把 MySQL 给打死了,导致系统崩溃,⽤户也就没法再使⽤系统了。 但是⾼峰期⼀过,到了下午的时候,就成了低峰期,可能也就 1w 的⽤户同时在⽹站上 操作,每秒中的请求数量可能也就 50 个请求,对整个系统⼏乎没有任何的压⼒。 如果使⽤ MQ,每秒 5k 个请求写⼊ MQ,A 系统每秒钟最多处理 2k 个请求,因为 MySQL 每秒钟最多处理 2k 个。A 系统从 MQ 中慢慢拉取请求,每秒钟就拉取 2k 个请 求,不要超过⾃⼰每秒能处理的最⼤请求数量就 ok,这样下来,哪怕是⾼峰期的时候, A 系统也绝对不会挂掉。⽽ MQ 每秒钟 5k 个请求进来,就 2k 个请求出去,结果就导致 在中午⾼峰期(1 个⼩时),可能有⼏⼗万甚⾄⼏百万的请求积压在 MQ 中。 这个短暂的⾼峰期积压是 ok 的,因为⾼峰期过了之后,每秒钟就 50 个请求进 MQ,但 是 A 系统依然会按照每秒 2k 个请求的速度在处理。所以说,只要⾼峰期⼀过,A 系统 就会快速将积压的消息给解决掉。 系统使⽤了消息队列,我们就能够对流量更好的把控。简单来说就是能够扛住⾼并发⼤流量。
Mq怎么选型?
我主要调研了⼏个主流的MQ,Kafka、Rabbitmq、Rocketmq 选型我们主要基于以下⼏个点去考虑:
-
由于我们系统的qps压⼒⽐较⼤,所以性能是⾸要考虑的要素。 Kafka和Rocketmq 都是毫秒级别,Rabbitmq是微妙级别。
-
开发语⾔,由于我们的开发语⾔是java,主要是为了⽅便⼆次开发。 Kafka是Scala和Rocketmq都是Java,Rabbitmq是Erlang
-
对于⾼并发的业务场景是必须的,所以需要⽀持分布式架构的设计。 Kafka和Rocketmq 都⽀持分布式架构,Rabbitmq是主从架构
-
功能全⾯,由于不同的业务场景,可能会⽤到顺序消息、事务消息等。 Kafka只⽀持主要Mq功能⽐较单⼀,Rocketmq 还⽀持顺序、事务消息等 我们的系统是⾯向⽤户的C端系统,未来可能具有⼀定的并发量,对性能也有⽐较⾼的 要求,所以选择了低延迟、吞吐量⽐较⾼,可⽤性⽐较好的RocketMQ。
如何保证消息队列的⾼可⽤?
NameServer⾼可⽤ NameServer因为是⽆状态,且不相互通信的,所以只要集群部署就可以保证⾼可⽤。
如何处理消息重复?
对分布式消息队列来说,同时做到确保⼀定投递和不重复投递是很难的,就是所谓的“有,且仅有⼀次” 。 RocketMQ择了确保⼀定投递,保证消息不丢失,但有可能造成消息重复。 ⽐如消费者消费消息时本地事务执⾏但是提交offset时宕机导致mq给消费者重复推送消息;再⽐如⽣产者发送消息到mq时发送成功未获取到响应然后进⾏消息发送重试导致消息发送多次。
处理消息重复问题,主要由业务端⾃⼰保证,主要的⽅式有两种:业务幂等和消息去重。
-
业务幂等:
第⼀种是保证消费逻辑的幂等性,也就是多次调⽤和⼀次调⽤的效果是⼀样 的。这样⼀来,不管消息消费多少次,对业务都没有影响。 ⽐如你的业务逻辑就是写Redis,那没问题了,反正每次都是 set,天然幂等性。 再⽐如我们项⽬电商系统消费mq消息修改订单状态,只有未⽀付才能变成已⽀付,配合数据库的悲观锁就天然具有业务幂等,假如订单状态不是未⽀付,就没有办法更新订单 状态了,直接抛异常。
-
消息去重:
第⼆种是业务端,对重复的消息就不再消费了。这种⽅法,需要保证每条消息都有⼀个唯⼀的编号,通常是业务相关的,⽐如订单号,消费的记录需要入库,⽽且 需要保证和消息确认这⼀步的原⼦性。 ⽐如可以建⽴⼀个消费记录表,拿到这个消息做数据库的insert操作。给这个消息做⼀ 个唯⼀主键或者唯⼀约束,那么就算出现重复消费的情况,就会导致主键冲突,那么就不再处理这条消息。再比如让⽣产者发送每条数据的时候,⾥⾯加⼀个全局唯⼀的id,类似订单 id 之类的东⻄,然后你这⾥消费到了之后,先根据这个 id 去 Redis ⾥查⼀下,之前消费过吗?如果 没有消费过,你就处理,然后这个 id 写 Redis。如果消费过了,那就别处理了,保证别 重复处理相同的消息。 假如是插⼊操作,兜底的⽅案⽐如基于数据库的唯⼀键来保证重复数据不会重复插⼊多条。因为有唯⼀键约束了,重复数据插⼊只会报错,不会导致数据库中出现脏数据。
如何处理消息丢失的问题?
说⼀下RocketMQ组成,每个⻆⾊作⽤是啥?
如何解决消息队列的延时以及过期失效问题?
怎么处理消息积压
RoctetMQ基本架构?
延时消息了解吗?
RocketMQ怎么实现延时消息的?
死信队列知道吗?
说⼀下RocketMQ的整体⼯作流程?
说说RocketMQ怎么对⽂件进⾏读写的?
消息刷盘怎么实现的呢?
RocketMQ消息⻓轮询了解吗?
支付名词解释和如何查看开发文档
ID:
ok来介绍三个非常重要的 ID ,截图来自微信官方文档。

微信的appid又分为主要三种
-
小程序的appid
-
公众号的appid
-
移动应用的appid
这三个appid都是我们在支付时需要使用到的东西,具体每种支付方式需要的APPID都放在这里了,但是我们现在只需要知道,Native支付需要的是公众号的appid即可,因为本项目只使用Native支付方式(接下来马上介绍Native支付是什么)

| 公众号 | 微信公众平台 | https://mp.weixin.qg.com/ |
|---|---|---|
| 小程序 | 微信公众平台 | https://mp.weixin.qg.com/ |
| 移动应用 | 微信开放平台 | https://open.weixin.qq.com/ |
但是,其实申请这个一个微信公众平台和开发平台的账号是非常麻烦的,需要各种资料之类的才能申请。请自己有条件的,自己去注册一下搞个公众号。如果没有的,请打开我的主页找置顶文章联系我。
支付方式:
我们打开微信开发者文档,https://pay.weixin.qq.com/wiki/doc/api/index.html
我们可以看到有非常多的支付方式,本项目使用native支付,也就是所谓的扫码支付(是你扫商家,而不是商家扫你),商家扫你是付款码支付。
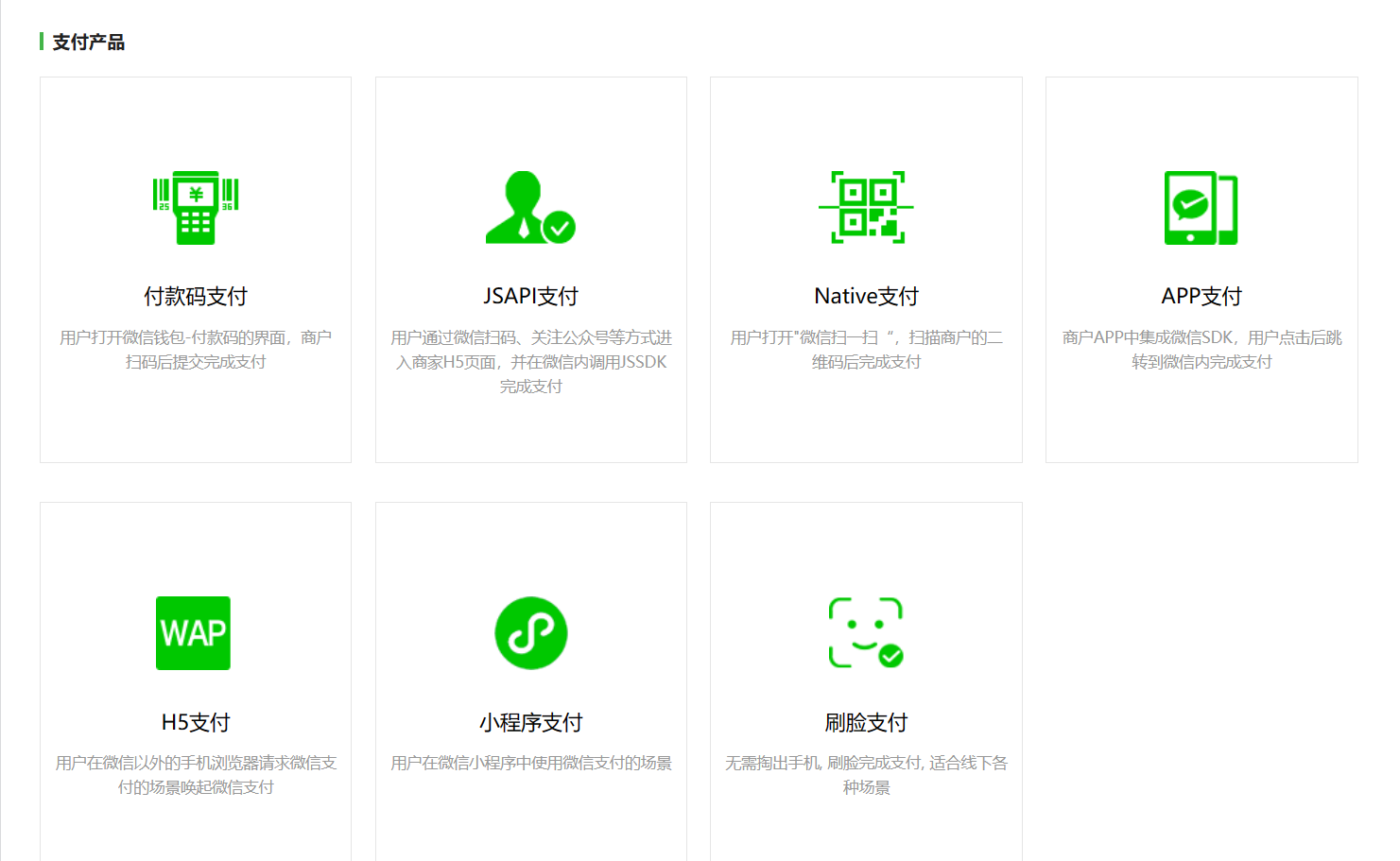
Native支付开发方式:
打开Native开发指引 https://pay.weixin.qq.com/wiki/doc/api/native.php?chapter=6_5&index=3
找到一张非常重要的图,以及业务流程。
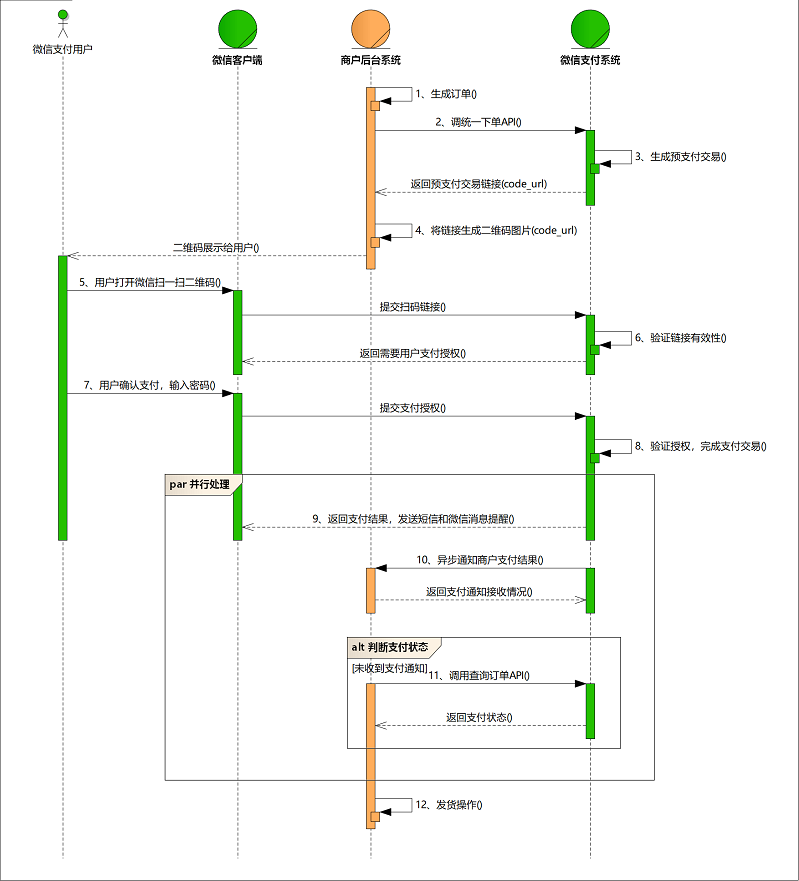
业务流程说明:
(1)商户后台系统根据用户选购的商品生成订单。
(2)用户确认支付后调用微信支付【】生成预支付交易;
(3)微信支付系统收到请求后生成预支付交易单,并返回交易会话的二维码链接code_url。
(4)商户后台系统根据返回的code_url生成二维码。
(5)用户打开微信“扫一扫”扫描二维码,微信客户端将扫码内容发送到微信支付系统。
(6)微信支付系统收到客户端请求,验证链接有效性后发起用户支付,要求用户授权。
(7)用户在微信客户端输入密码,确认支付后,微信客户端提交授权。
(8)微信支付系统根据用户授权完成支付交易。
(9)微信支付系统完成支付交易后给微信客户端返回交易结果,并将交易结果通过短信、微信消息提示用户。微信客户端展示支付交易结果页面。
(10)微信支付系统通过发送异步消息通知商户后台系统支付结果。商户后台系统需回复接收情况,通知微信后台系统不再发送该单的支付通知。
(11)未收到支付通知的情况,商户后台系统调用【】(查单实现可参考:)。
(12)商户确认订单已支付后给用户发货。
OK一步一步开始来做,首先点开我们的第二步的 —— 统一下单API,大致浏览一遍啊,大概就是知道一件事情,我们要先有这么一大段xml格式的文本
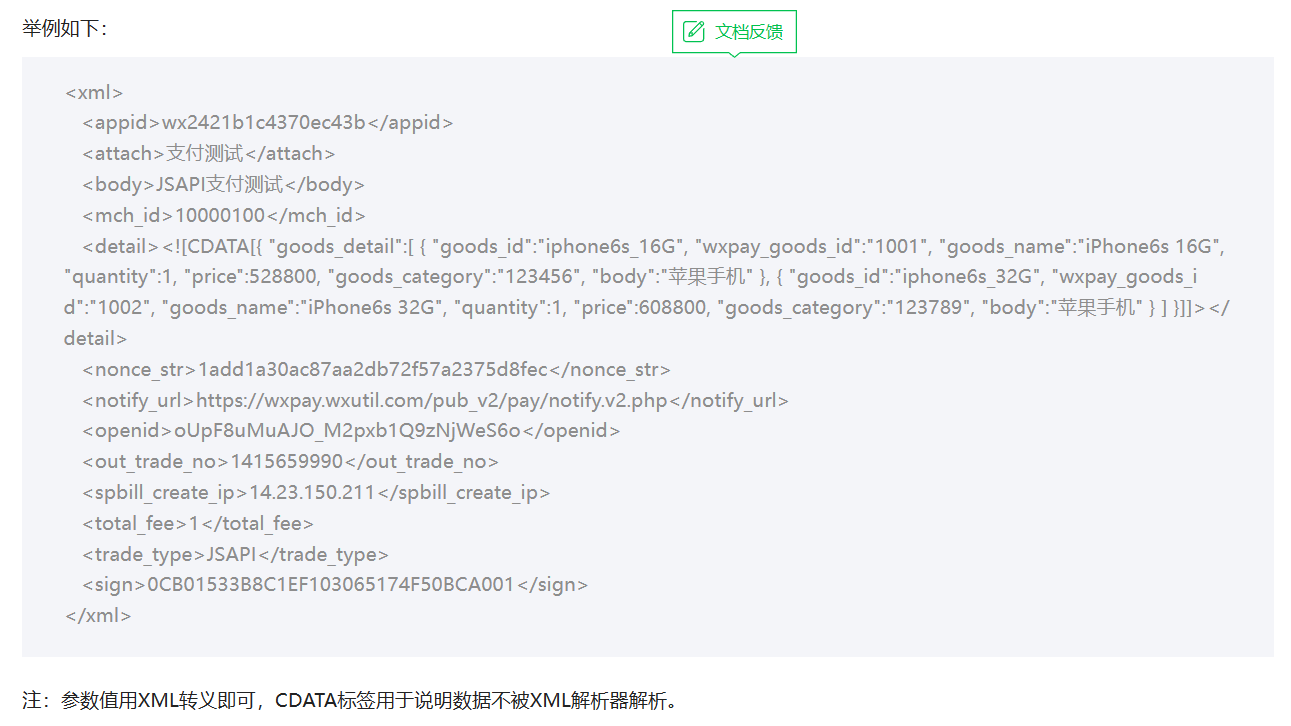
然后带着这么大坨东西去访问这个接口
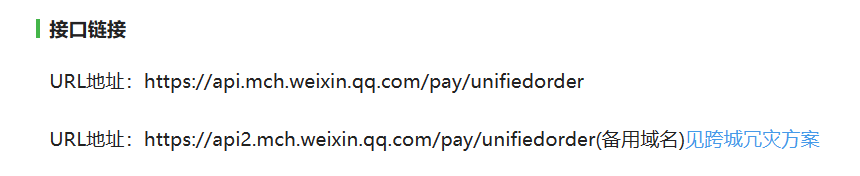
然后接口再给你返回一大坨xml格式的东西
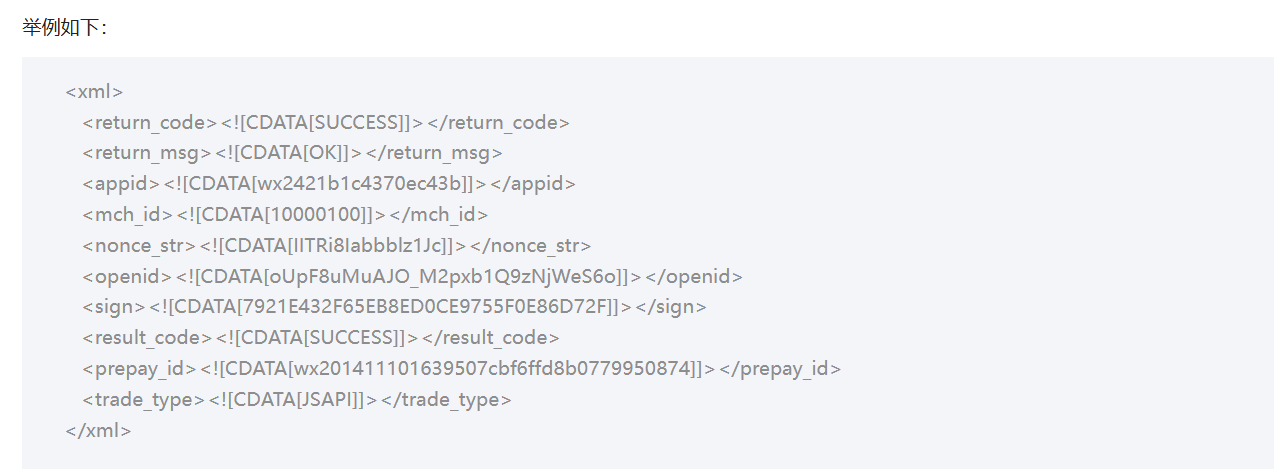
然后我们需要拿到最后的code_url参数里的值,把他转成一个二维码,提供给用户即可。
OK以上的都是微信官方文档的东西,其实看到还是非常繁琐的啊。一般到这了,就可以去Github上找找有没有人替我们做好了简化版的开发方式。(狗头)
经过搜索,我们可以使用一个GitHub上开源的SDK来完成上面的功能
点开里面的文档教程,并记得把Maven引入,其实在上面的配置中已经贴好了。
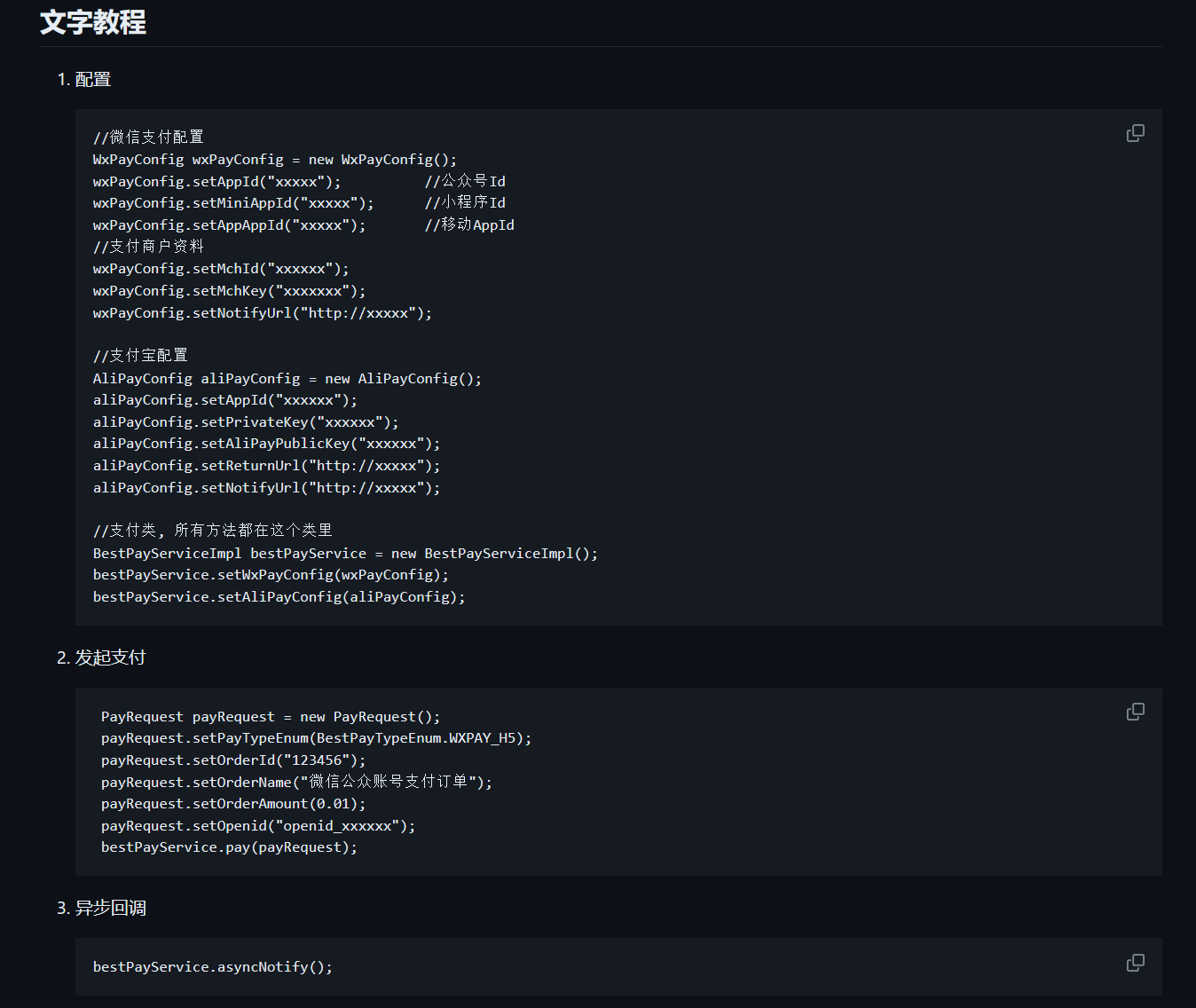
本文作者:翰林猿
本文链接:https://www.cnblogs.com/hanlinyuan/p/17541026.html
版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 2.5 中国大陆许可协议进行许可。



【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】凌霞软件回馈社区,博客园 & 1Panel & Halo 联合会员上线
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】博客园社区专享云产品让利特惠,阿里云新客6.5折上折
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步