程序员之路自我分析-个人想法
(善用工具、提升思想、开阔眼界、多学习、多体验、实操很重要)
意:个人想法
发展方向 不走技术路线 就是 管理路线。
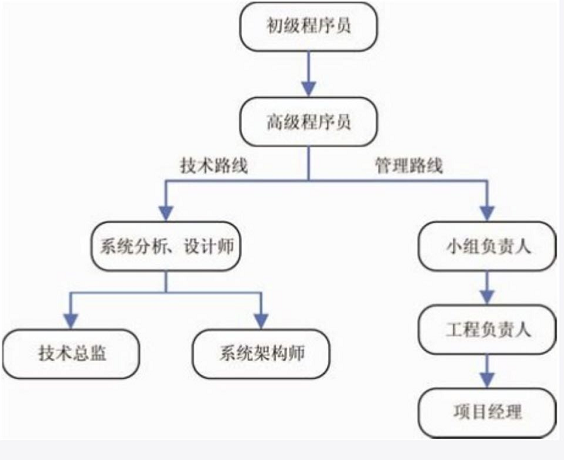
领导才能 不管是哪个方向发展,还是要提升自我的高度。继续努力。
- MySQL InnoDB、Mysaim的特点?
- 乐观锁和悲观锁的区别??
- 行锁和表锁的区别?
- 数据库隔离级别是什么?有什么作用?
- MySQL主备同步的基本原理。
- 如何优化数据库性能(索引、分库分表、批量操作、分页算法、升级硬盘SSD、业务优化、主从部署)
- SQL什么情况下不会使用索引(不包含,不等于,函数)
- 一般在什么字段上建索引(过滤数据最多的字段)
- MySQL,B+索引实现,行锁实现,SQL优化
- 如何解决高并发减库存问题
- 数据库事务的几种粒度
- 事务四大特性(ACID)
- 数据库隔离级别,每个级别会引发什么问题,mysql默认是哪个级别
- MYSQL的两种存储引擎区别(事务、锁级别等等),各自的适用场景
- 数据库的优化(从sql语句优化和索引两个部分回答)
- 索引有B+索引和hash索引,各自的区别
- B+索引数据结构,和B树的区别
- 索引的分类(主键索引、唯一索引),最左前缀原则,哪些情况索引会失效
- 聚集索引和非聚集索引区别。
- 有哪些锁(乐观锁悲观锁),select时怎么加排它锁
- 关系型数据库和非关系型数据库区别
- MVCC机制
- 数据库三范式,根据秒杀场景设计数据表
- 数据库的主从复制
- 死锁怎么解决
- mysql并发情况下怎么解决(通过事务、隔离级别、锁)
- redis数据结构有哪些
- redis队列应用场景
- redis和Memcached(支持数据持久化)
- Redis,RDB和AOF,如何做高可用、集群
- mapreduce过程
- hbase和传统数据库的区别
- hbase读数据过程
- hbase master和regionserver的交互
- hbase的ha,zookeeper在其中的作用,master宕机的时候,哪些能正常工作,读写数据?region分裂?
- 数据倾斜
- mysql索引,哪些索引?实现原理?哪些存储引擎支持B树索引,哪些支持hash索引?
- 为啥mysql索引要用B+树而MongoDB用B树?
- Mysql查询优化?
- 主键和唯一索引的区别
- 事务的隔离机制,mysql默认是哪一级
- MyISAM和InnoDB存储引擎的区别
- mysql查询优化,慢查询怎么去定位?
- mysql中的各种锁,乐观锁,悲观锁(排他锁,共享锁);行锁,表锁是怎么实现的?
- mapreduce支持哪些join,map端?reduce端?semi join?semi join你可以通过什么算法去优化?
- mapreduce实现二次排序
- 用mapreduce实现两表join
- 用mapreduce实现一个存储kv数据的文件,对里面的v进行全量排序
- zookeeper实现原理,zab协议以及原子广播协议
- paxos协议,multi-paxos,zab,raft各种分布式协议内容,使用场景
- hadoop namenode的ha,主备切换实现原理,日志同步原理,QJM中用到的分布式一致性算法(就是paxos算法)
- spark运行架构
- spark运行原理,从提交一个jar到最后返回结果,整个过程
- spark的stage划分是怎么实现的?拓扑排序?怎么实现?还有什么算法实现?
- spark rpc,spark2.0为啥舍弃了akka,而用netty?
- spark的各种shuffle,与mapreduce的对比
- spark的各种ha,master的ha,worker的ha,executor的ha,driver的ha,task的ha,在容错的时候对集群或是task有什么影响?
- spark的内存管理机制,spark1.6前后对比分析
- spark2.0做出了哪些优化?tungsten引擎?cpu与内存两个方面分别说明
- spark rdd、dataframe、dataset区别
- callable runnable 区别
- synchronized与lock区别
- 类加载机制
- gc算法
- spark数据倾斜
- spark shuffle
- spark 内存管理
- 各种排序算法,时间复杂度,空间复杂度,spark和hadoop中shuffle中各个阶段用到的排序算法把这几种排序算法的使用场景表现得淋漓尽致啊。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号