
作业
一、思维业务作业
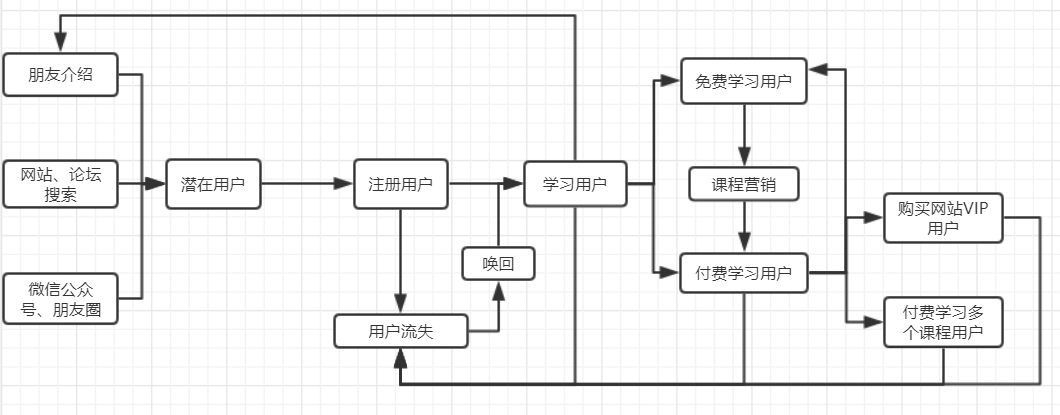
天善学院的数据分析框架
思考:
1.任何一个公司都是以盈利为目的,这里天善作为一个线上学习平台,核心应该是用户,以用户学习付费课程而盈利
2.以用户为核心,就涉及了用户生命周期,适用于AARRR框架
下面是基于AARRR框架画出来的天善学院的数据分析框架:
二、Excel作业
此作业内容在第三周excel博客中也有详细介绍。
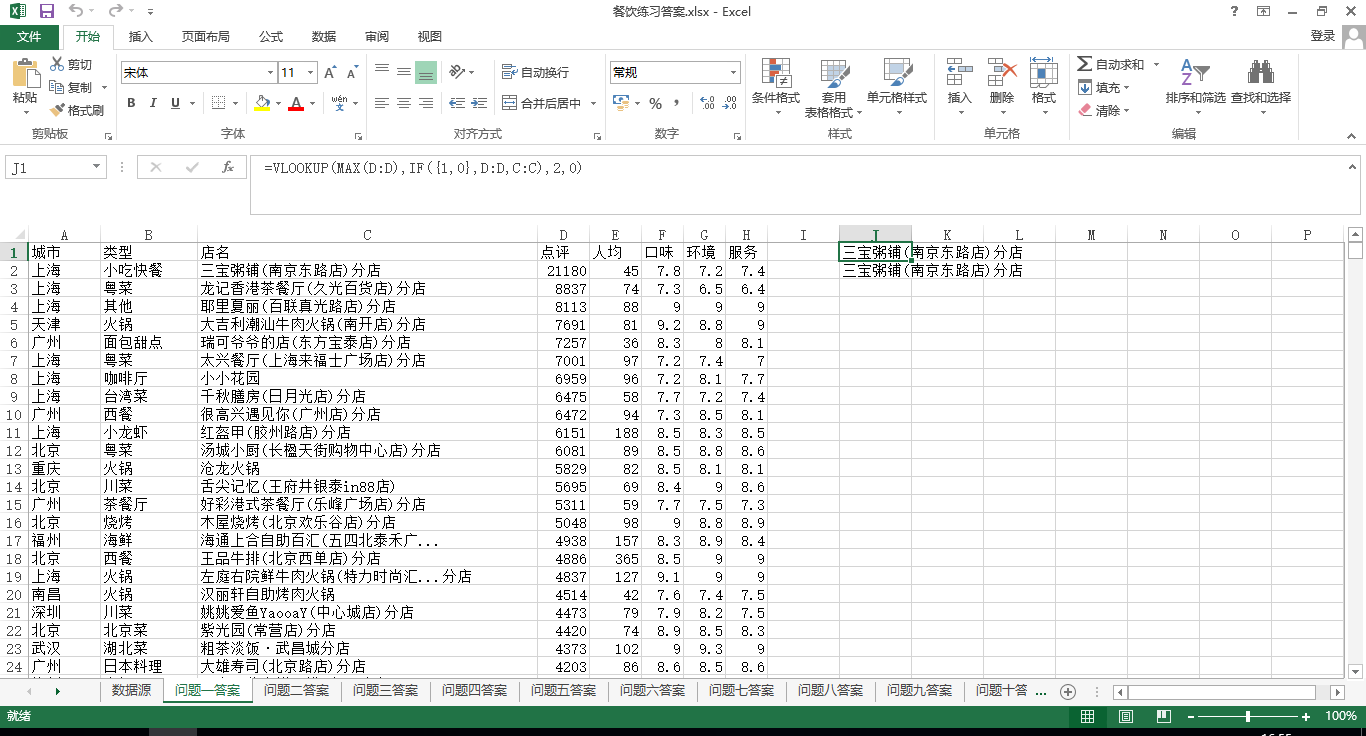
1.全国点评数最高的饭店是哪家?
答:方法一:可以用函数公式解决,在逻辑函数学习那里已经介绍过了
=VLOOKUP(MAX(D:D),IF({1,0},D:D,C:C),2,0)
或者为=INDEX(C:C,MATCH(MAX(D:D),D:D,0))
方法二:其实按照秦老师说的排序方法应该更简洁。
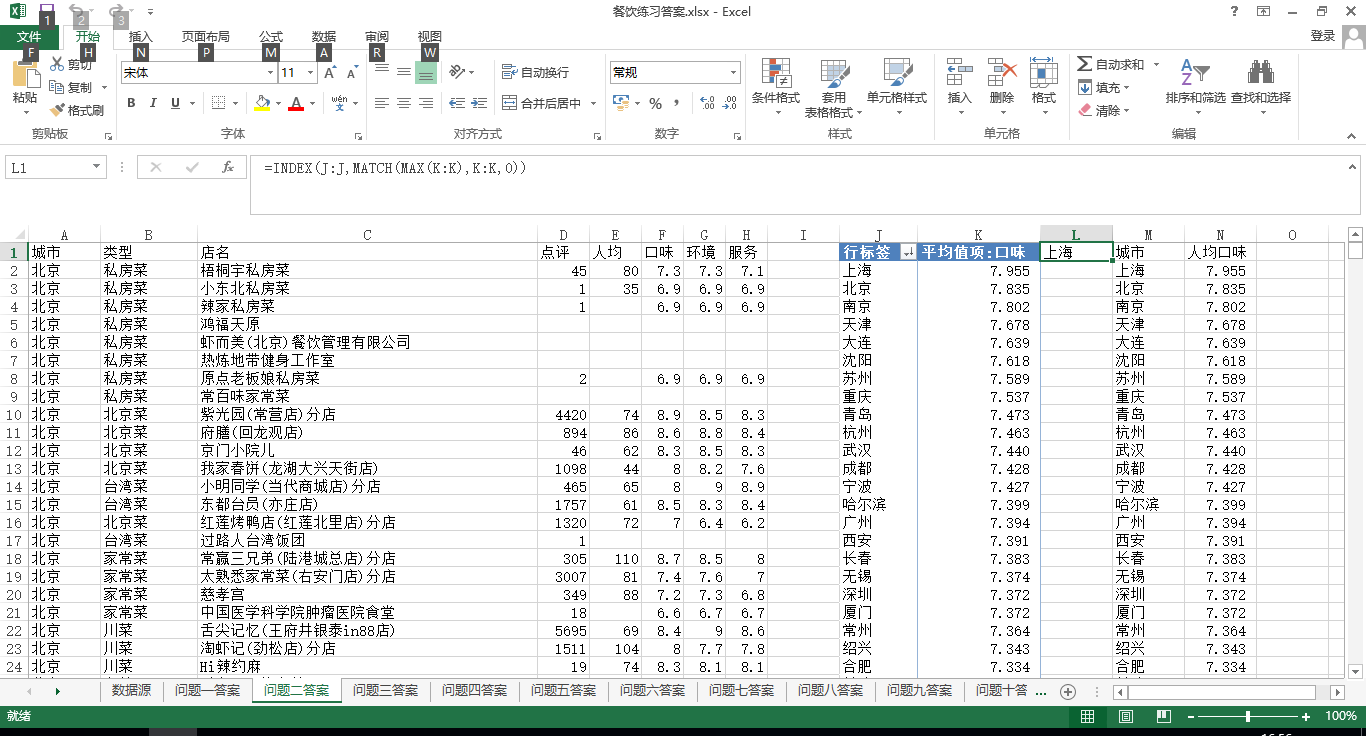
2.哪个城市的饭店人均口味最好?
答:方法一:使用数据透视表处理,选择地区为行标签,值为口味设置为求平均值。要得到口味最好的店可以用函数进行查找,也可以对口味列进行降序排列。
方法二:使用AVERAGEIF函数解决,先把城市这列复制到M列,然后使用删除重复项功能,在N2输入函数公式:=AVERAGEIF(A:A,M2,F:F),最后再排序即可得到。
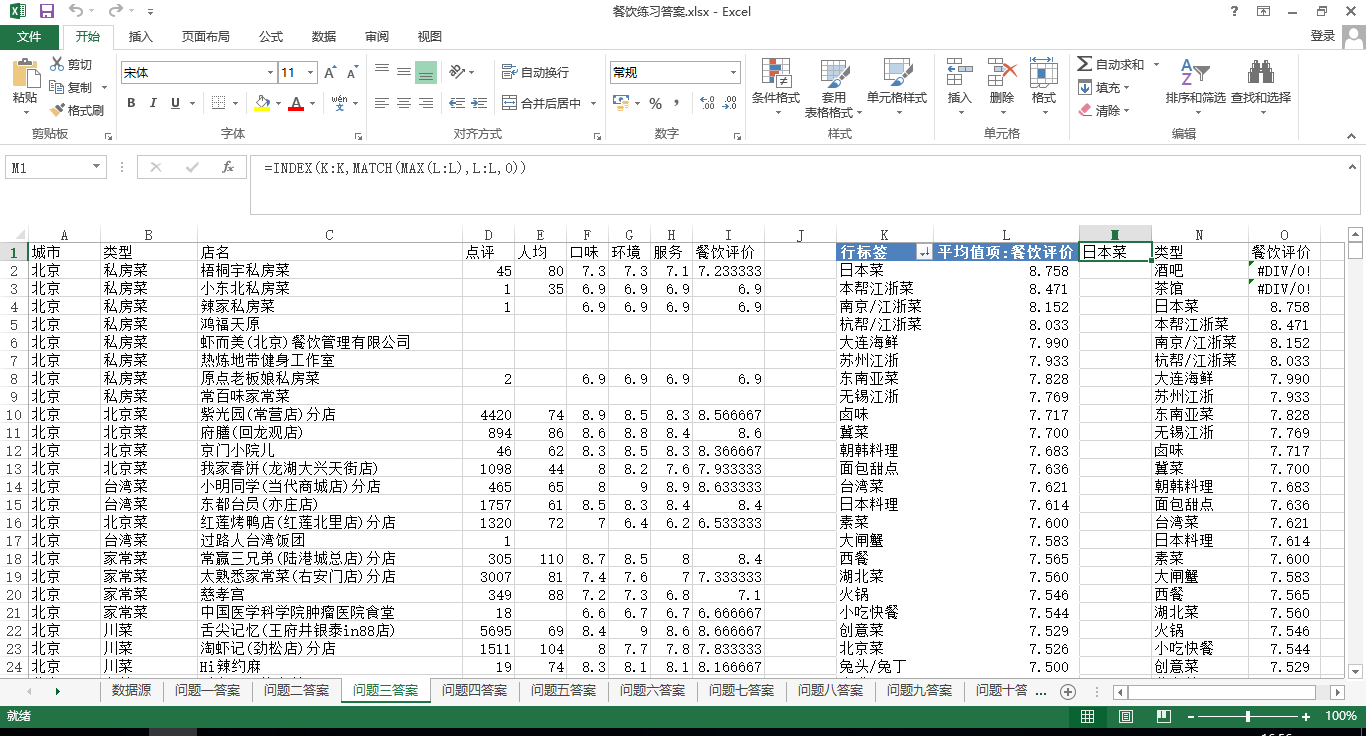
3.哪个类型的餐饮评价最好?
答:这里餐饮评价具体指哪个指标, 在这里我姑且认为是口味,环境,服务三者的平均值,所以应该插入一列名为餐饮评价,然后在建立数据透视表。选择类型为行标签,值为餐饮评价求平均值。(另一种方法与第二题一样的,注意这里因为茶馆和酒吧都没有评价数据,所以使用函数计算会报错,但是不影响结果。)
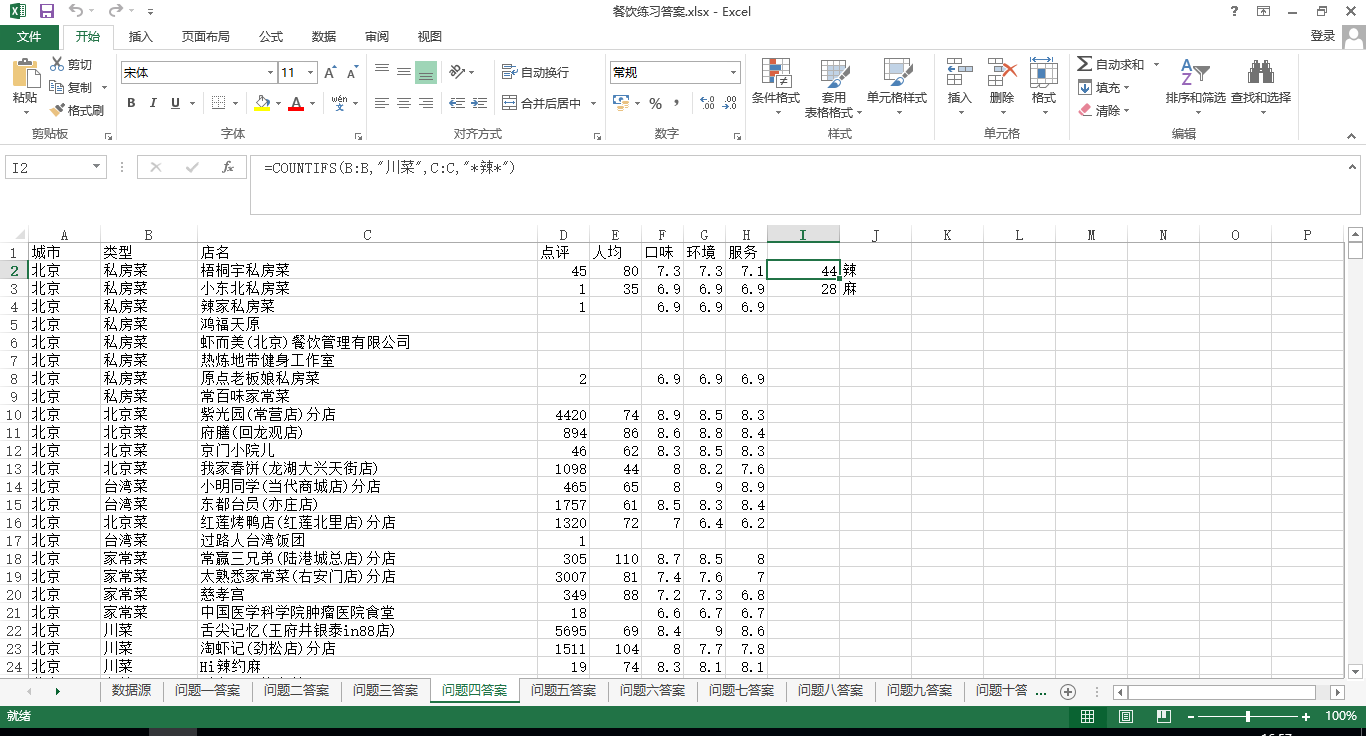
4.类型为川菜的店中,有多少个带「辣」字,又有多少个带「麻」字?
答:首先类型是川菜,然后还需要店名带辣(麻)字,这里有两个条件并且是求个数,那么可以使用函数countifs。
=COUNTIFS(B:B,"川菜",C:C,"*辣*")
=COUNTIFS(B:B,"川菜",C:C,"*麻*")
5.口味、环境、服务,三个评价都在8.0以上的饭店有几家?它们在哪个城市的占比最多?
答:这里的第一问就是三个条件求个,同样的是countifs函数。
=COUNTIFS(F:F,">=8.0",G:G,">=8.0",H:H,">=8.0")
第二问也是差不多,它多了个条件就是城市。做法是:先复制城市列到J列,然后删除重复项,再K2中输入函数公式:
=COUNTIFS(A:A,J2,F:F,">=8.0",G:G,">=8.0",H:H,">=8.0")/456
再对K列进行降序排列即可。

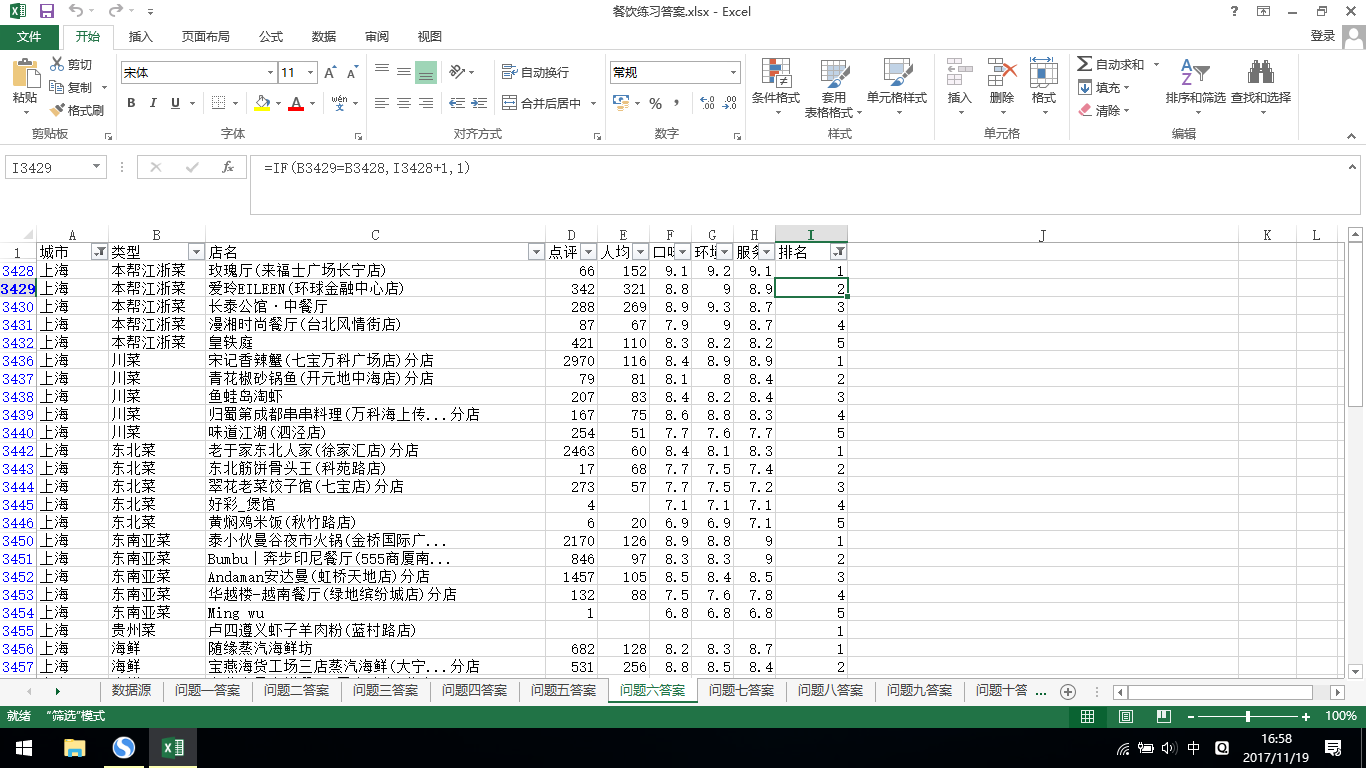
6.上海地区中,各个类型饭店服务前五名?
答:先对数据源进行筛选出上海地区,然后按类型的升序排序再按服务的降序排序,插入辅助列写出排名并筛选出前五名即可。
7.没有评价的饭店有几家?
答:求饭店的家数,肯定要用到计数函数,这里有两种写法。
=COUNTIF(D2:D5864,"")
或者为=COUNTA(C2:C5864)-COUNT(D2:D5864)
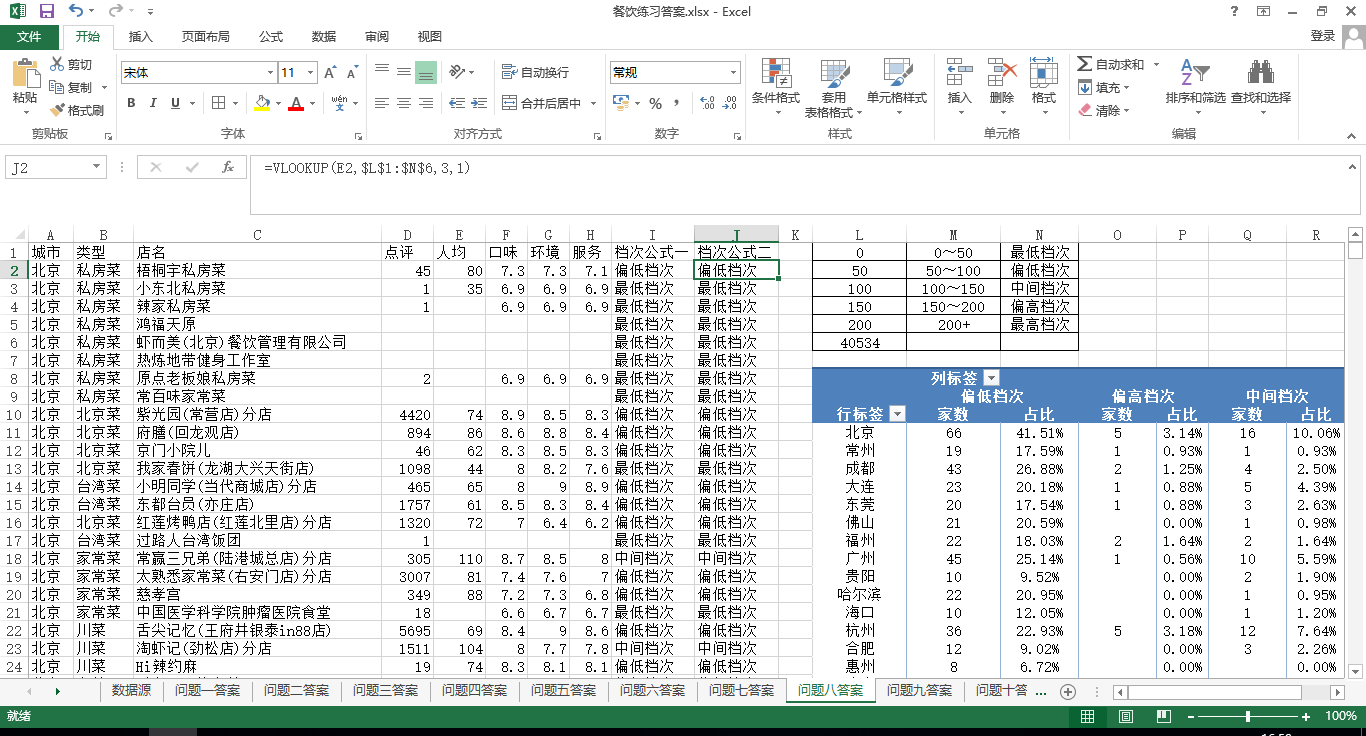
8.将人均价格划分成0~50,50~100,100~150,150~200,200+这几个档次, 各个城市分别有几家?其中占比又是多少?
答:这里按人均价格划分档次,有部分是人均价格为空值默认为零划为第一档(当然把这些清楚也可以)。
做法是:在L1处建立一个档次表,然后用如下公式确定档次
=LOOKUP(E2,$L$1:$L$6,$N$1:$N$6)或者=VLOOKUP(E2,$L$1:$N$6,3,1)
再利用数据透视表进行确定各城市的家数以及占比。
9.将点评、人均、口味、环境、服务这几个指标加工出一个综合评价系数,并且计算哪十家店是最好的(开放题)。
答:这里的评价系数就是秦老师之前讲的指数法,主要考虑的是这些指标如何进行计算确定系数,其中口味、环境、服务是类似的指标可以用线性加权,点评与人均数值上相差比较大,应该用log的方法进行处理。在处理之前应该先清除空值。
10.对上海地区的日本料理,做一次描述性分析(开放题)
答:描述性分析是数据选项卡中数据分析里的描述统计,包含统计的一些指标如最大值,最小值,平均数,中位数,方差等。
首先清楚空白数据,接着筛选出上海地区的日本料理,然后对数据区域进行描述统计。
三、mysql作业
此作业内容在第五周mysql博客中也有详细介绍。
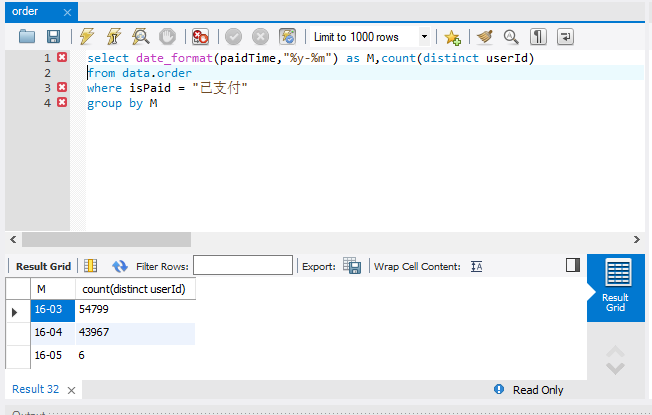
1.统计不同月份的下单人数
分析:首先应过滤出成功购买的数据即是已支付的,然后考虑统计不同月份是按月份分组需要用到groupby关键字,统计人数是计数需要用count函数,这里要注意一个问题因为有的人有多次购买行为,所以统计人数时要去重。
语句:
select date_format(paidTime,"%y-%m") as M,count(distinctuserId)
from data.order
where isPaid = "已支付"
group by M
2.统计用户三月份的回购率和复购率
分析:回购率=本月和下月都购买的人数÷本月购买人数
复购率=购买多次的人数÷总购买人数
(1)回购率要统计本月和下月都购买的人数,在一张表里是没法做到的,需要把表用join关联起来,然后再进行统计
语句:
select t1.M,count(t1.userId),count(t2.userId),
count(t2.userId)/count(t1.userId) as 回购率
from (
selectuserId,date_format(paidTime,"%Y-%m-02") as M from data.order
where isPaid = "已支付"
group by userId,M) as t1
left join (
selectuserId,date_format(paidTime,"%Y-%m-02") as M from data.order
where isPaid = "已支付"
group by userId,M) as t2
on t1.userId=t2.userId and t1.M = date_add(t2.M,interval -1 month)
group by t1.M

(2)复购率应该分别统计出总购买人数,至少购买两次的人数,然后再去求比值,其实这里可以按月份分组把每个月的复购率都求出来而不用单独把三月份数据过滤出来求复购率
语句:
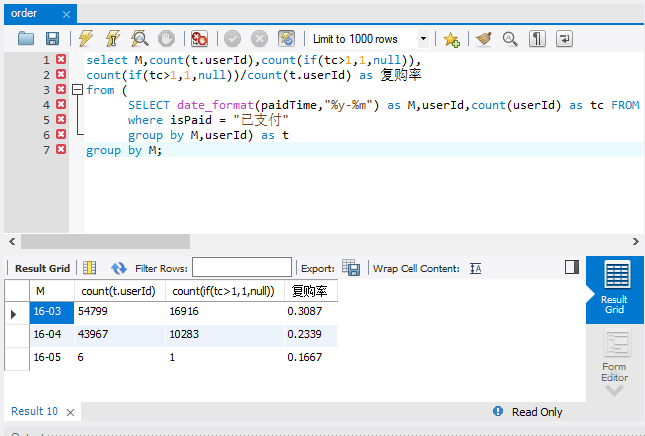
select M,count(t.userId),count(if(tc>1,1,null)),
count(if(tc>1,1,null))/count(t.userId) as 复购率
from (
SELECTdate_format(paidTime,"%y-%m") as M,userId,count(userId) as tc FROMdata.order
where isPaid = "已支付"
group by M,userId) as t
group by M;
3.统计男女用户的消费频次是否有差异
分析:消费频次是指在一段时间内每人的消费次数,计算式子为
消费频次 = 总消费次数 ÷ 总消费人数
按题目要求需要统计男女用户则需要对sex进行分组,性别和消费在不同的表里则需要用join关联表,order表中未支付以及user表中性别的空值都需要过滤,然后在进行统计
语句:
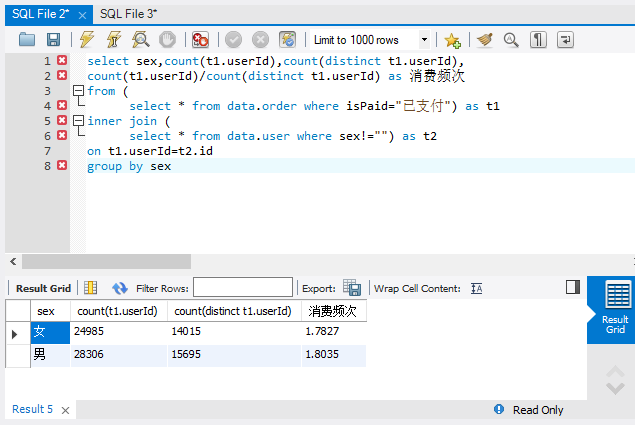
select sex,count(t1.userId),count(distinct t1.userId),
count(t1.userId)/count(distinct t1.userId) as 消费频次
from (select * from data.orderwhere isPaid="已支付") as t1
inner join (select * from data.userwhere sex!="") as t2 on t1.userId=t2.id
group by sex
4.统计多次消费的用户,第一次和最后一次消费间隔是多少?
分析:统计的是多次消费的用户,需要先把这些数据过滤出来,按用户统计则需要对用户进行分组,第一次消费时间和最后一次时间可以分别用min、max函数计算出来,然后求间隔用日期时间函数
语句:
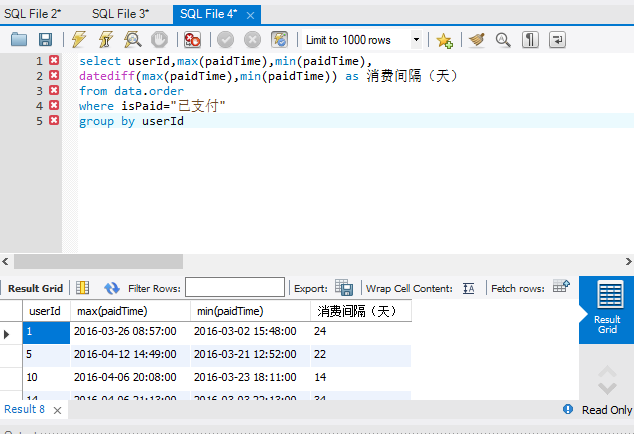
select userId,max(paidTime),min(paidTime),
datediff(max(paidTime),min(paidTime)) as 消费间隔(天)
from data.order
where isPaid="已支付"
group by userId
5.统计不同年龄段,用户的消费金额是否有差异?
分析:首先应把已支付的人过滤出来,然后在此基础加上按年龄段的分组,使用case……when……then语句。
语句:
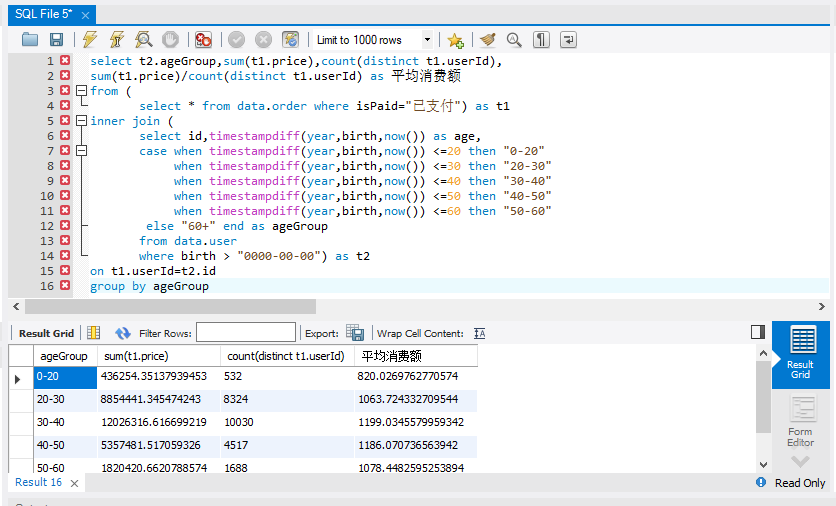
select t2.ageGroup,sum(t1.price),count(distinct t1.userId),
sum(t1.price)/count(distinct t1.userId) as 平均消费额
from (
select * fromdata.order where isPaid="已支付") as t1 inner join (
select id,timestampdiff(year,birth,now()) as age,
case whentimestampdiff(year,birth,now()) <=20 then "0-20"
when timestampdiff(year,birth,now()) <=30 then "20-30"
when timestampdiff(year,birth,now()) <=40then "30-40"
when timestampdiff(year,birth,now()) <=50 then "40-50"
when timestampdiff(year,birth,now()) <=60 then "50-60"
else "60+"end as age Group from data.user
where birth >"0000-00-00") as t2 on t1.userId=t2.id
group by ageGroup
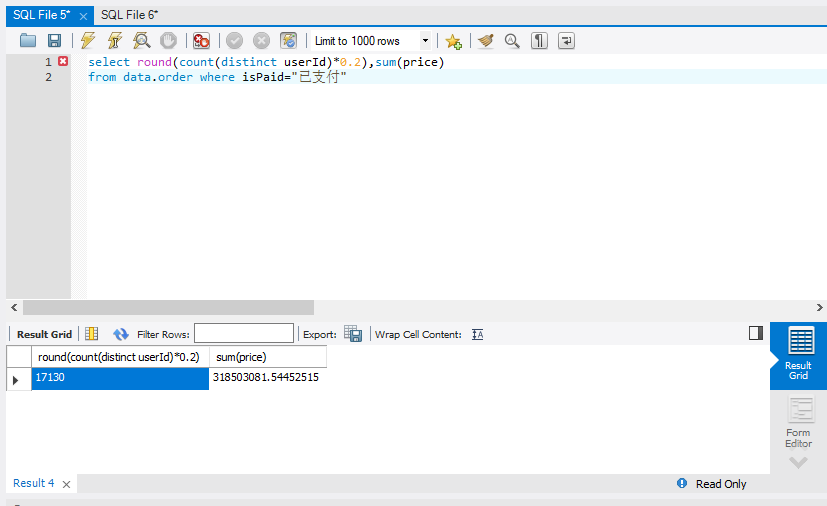
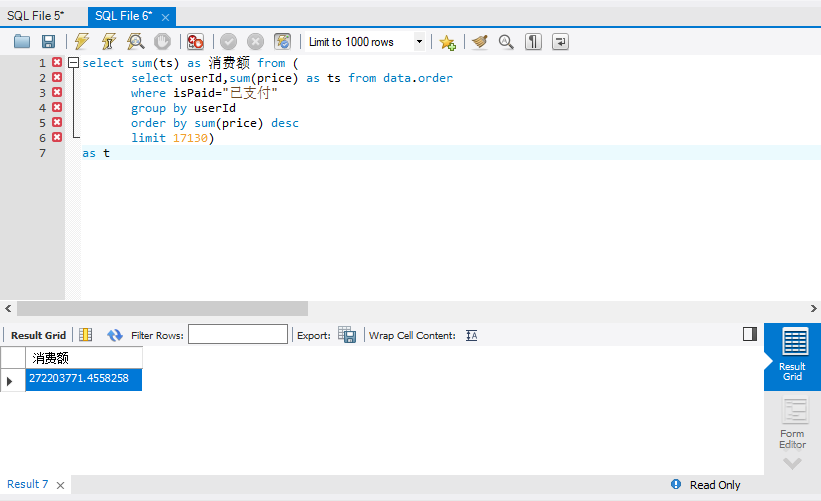
6.统计消费的二八法则,消费的top20%用户,贡献了多少额度
分析:由于limit后面不可以接select语句,所以这题要分两步解决。
第一步,先用select语句查询出支付人数的20%和资金总额
第二步,再把查询的人数写到limit后面
语句:
select round(count(distinct userId)*0.2),sum(price)
from data.order where isPaid="已支付"
select sum(ts) as 消费额 from (
select userId,sum(price) as ts from data.order where isPaid="已支付"
group by userId order by sum(price)desc limit 17130) as t

 浙公网安备 33010602011771号
浙公网安备 33010602011771号