
反反爬虫技术:解决网站字体加密

如上图我们可以发现有些数据的数字变成了加密字体,我就去查看了一下网站的代码,结果发现网站的代码显示是这样的:
原来有些网站上使用了字体加密技术,为了解决这个问题,我找了大量的资料,可是网上的很多方法由于网站反爬技术的进步或者网站更新了字体加密规则已经不能使用了,于是我就开始了破解字体加密的艰辛历程。
解决方法
方法一: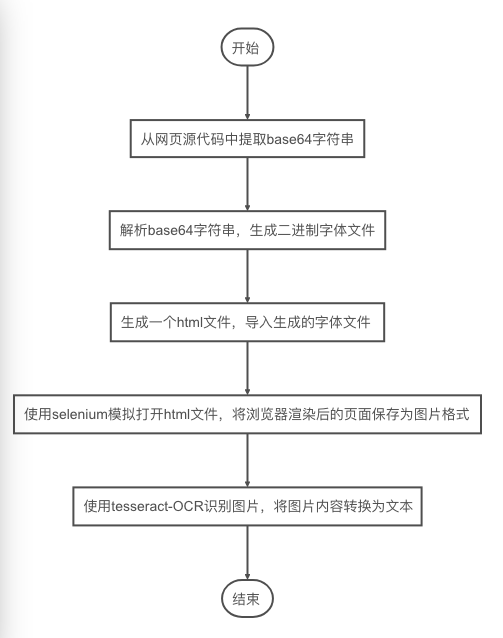
代码如下:
from selenium import webdriver from selenium.webdriver.firefox.options import Options import pytesseract from PIL import Image from fontTools.ttLib import TTFont def font_parse(url, font_str1, font_str2, font_str3): """ 解析乱码的数字 :param rental: :param house_type: :param toward_floor: :return: """ response = requests.get(url) base64_string = response.text.split("base64,")[1].split("'")[0].strip() bin_data = base64.decodebytes(base64_string.encode()) with open("base.woff", r"wb") as f: f.write(bin_data) html = '''<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8"> <title>Title</title> <style type="text/css"> @font-face { font-family: myFirstFont; src: url(base64.woff); } div { font-family: myFirstFont; font-size: 32px; text-align: center; } </style> </head> <body> <div>%s</div> <div>%s</div> <div>%s</div> </body> </html> ''' % (font_str1, font_str2, font_str3) # 将生成的HTML字符串写入html文件中 with open("font_parse.html", r"wb") as f: f.write(bytes(html, encoding="utf-8")) # 使用selenium在浏览器中加载html文件 options = Options() options.add_argument("-headless") browser = webdriver.Firefox(executable_path="E:/python/geckodriver", firefox_options=options) browser.get(r"file:///E:\python\practice\practice06\font_parse\font_parse.html") # 最大化窗口,因为每一次爬取只能看到视窗内的图片 browser.maximize_window() # 将网页保存为图片格式 browser.save_screenshot("font_parse.png") browser.close() image = Image.open('font_parse.png') # 利用tesseract-OCR识别库识别图片中的文字,chi_sim是简体中文语言库 result = pytesseract.image_to_string(image, lang="chi_sim") result_list = result.splitlines() return result_list
1.url是你要爬取网站的网址,font_str是需要解析的加密字符,可以根据需求定义font_str(1, 2, …n)的个数,在html字符串里面修改div的个数并在‘%()’里面写入对应的参数
2.executable_path=“E:/python/geckodriver"里面的路径换成自己电脑上‘geckodriver’所在的位置
3.browser.get(r"file:///E:\python\practice\practice06\font_parse\font_parse.html”)里面的路径换成html文件保存的路径
4.tesseract识别英文和数字比较简单,识别中文需要下载中文语言库,放在“Tesseract-OCR\tessdata”文件夹里面。有一点需要说明一下:tesseract对于单个字符的识别不太好,我试了几次识别单个数字字符发现识别的结果为空,大家使用tesseract时尽量避免这个问题
这个方法可以解决目前大部分网站的字体加密,不过这个方法比较麻烦,而且使用selenium模拟打开浏览器会造成程序运行速度非常慢,爬取得数据较少时可以使用,当爬取大量数据时这个方法就不太实用了,于是就有了下面的进阶方法。
方法二:
代码如下:
text = "鑶驋龒龒" im = Image.new("RGB", (60, 25), (255, 255, 255)) dr = ImageDraw.Draw(im) font = ImageFont.truetype('base.woff', 18) dr.text((10, 5), text, font=font, fill="#000000") #im.show() im.save("t.png")
利用此代码替换方法一代码中selenium模拟打开网页并保存网页为图片的部分,可以节约大量的代码运行所需的时间
方法三:
import base64 from fontTools.ttLib import TTFont import re from PIL import Image, ImageDraw, ImageFont html = open("test.html", 'r', encoding="utf-8").read() base64_string = html.split("base64,")[1].split("'")[0] bin_data = base64.decodebytes(base64_string.encode()) with open("base.woff", r"wb") as f: f.write(bin_data) font_list = re.findall('&#x(\w+)', html) for font_secret in font_list: one_font = int(font_secret, 16) font = TTFont('base.woff') # font.saveXML('test.xml') c = font['cmap'].tables[2].ttFont.tables['cmap'].tables[1].cmap # print("c::::::", c) gly_font = c[one_font] b = font['cmap'].tables[2].ttFont.getReverseGlyphMap() # print("b:::::::", b) print(b[gly_font] - 1)
1.提取加密字体的十六进制格式除了可以使用正则直接提取出来,有些也可以把加密的字体用“unicode_escape”编码格式解析一下生成字体对应的十六进制,但是不同网站的编码格式可能不同,需要大家自己验证。
2.最后一行的代码对(从“b”字典里取出对应的数字字符再减一)是我根据58网站上的信息与解析之后的信息进行比对后发现的规则,我并不确定其他网站是不是也是这样。
3.这个方法是别人告诉我的,代码比较简单,但是原理比较复杂,我对于这个代码的运行原理也不是太了解,不过并不影响使用。我验证了一下这个代码,也成功解决了文字加密问题,大家有兴趣的可以去深入了解一下。
关于b和c打印之后是结果如下图:
大家最好能够自己打印看一下。生成的xml文件这里不太好粘贴,大家也最好能够生成之后看一下,加深对代码的理解。
利用“unicode_escape”编码格式解析的代码如下:
from fontTools.ttLib import TTFont def font_parse(text): """ 解析乱码的数字 :param rental: :param house_type: :param toward_floor: :return: """ decryption_text = "" for alpha in text: hex_alpha = alpha.encode('unicode_escape').decode()[2:] if len(hex_alpha) == 4: one_font = int(hex_alpha, 16) font = TTFont('base.woff') font_dict = font['cmap'].tables[2].ttFont.tables['cmap'].tables[1].cmap b = font['cmap'].tables[2].ttFont.getReverseGlyphMap() if one_font in font_dict.keys(): gly_font = font_dict[one_font] item_text = str(b[gly_font] - 1) else: item_text = alpha

上图是测试加密字体解析之后的结果。
方法四:
response = requests.get(url) base64_string = response.text.split("base64,")[1].split("'")[0].strip() bin_data = base64.decodebytes(base64_string.encode()) with open("base.woff", r"wb") as f: f.write(bin_data)
这个代码在前面几个方法中都会用到,用于生成网站上的加密字体所用的字体库
下载FontCreator软件,打开生成的"base.woff"字体库,软件会自动生成字体库的对应关系,如下图:


根据此软件解析出来的字体库对应关系,可以建立一个字体查询字典,如:{“9f92”: “0”, “EC3A”: “上”, …},然后根据“方法三”介绍的利用正则或者“unicode_escape”编码格式解析将加密字体转换为十六进制格式并利用此十六进制数字在字体查询字典里面查询加密字体对应的真实字体。
这个方法很简单,但是字体查询字典需要手动建立而不能自动生成,如果爬取的网站的字体对应关系不变的话可以使用。然而对于如58同城之类的网站每次刷新之后网页的字体对应关系都会变化,这个方法就不适用了。
结尾:
以上就是我解决网站字体加密的方法,至于如何把这些方法应用到爬虫程序里面,相信大家只要好好研究一下,应该都是没有问题的,我就不再赘述了。大神们如果有其他解决方法可以在评论里留言,最好能够在评论里留下链接,希望能和大家一起进步。
转载于 https://blog.csdn.net/litang199612/article/details/83413002

