
音视频领域里面,JPEG编码是最常用的图片编码格式。接下去几篇文章打算从JPEG图片编码开始到视频编解码,学习总结下音视频的编码原理、相关文件协议,现在让我们先进入jpeg编码。
一、JPEG有损编解码简介
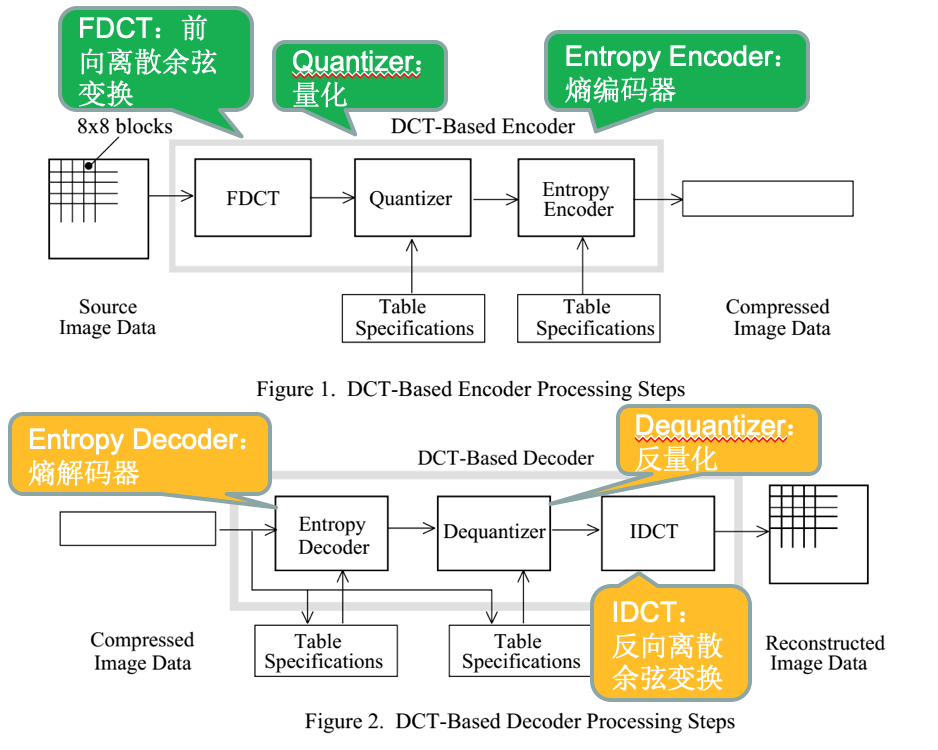
如上图所示,为jpeg编解码的流程图。图片编码:离散余弦变换->量化->熵编码,图片解码:熵解码->反量化->反向离散余弦变换。
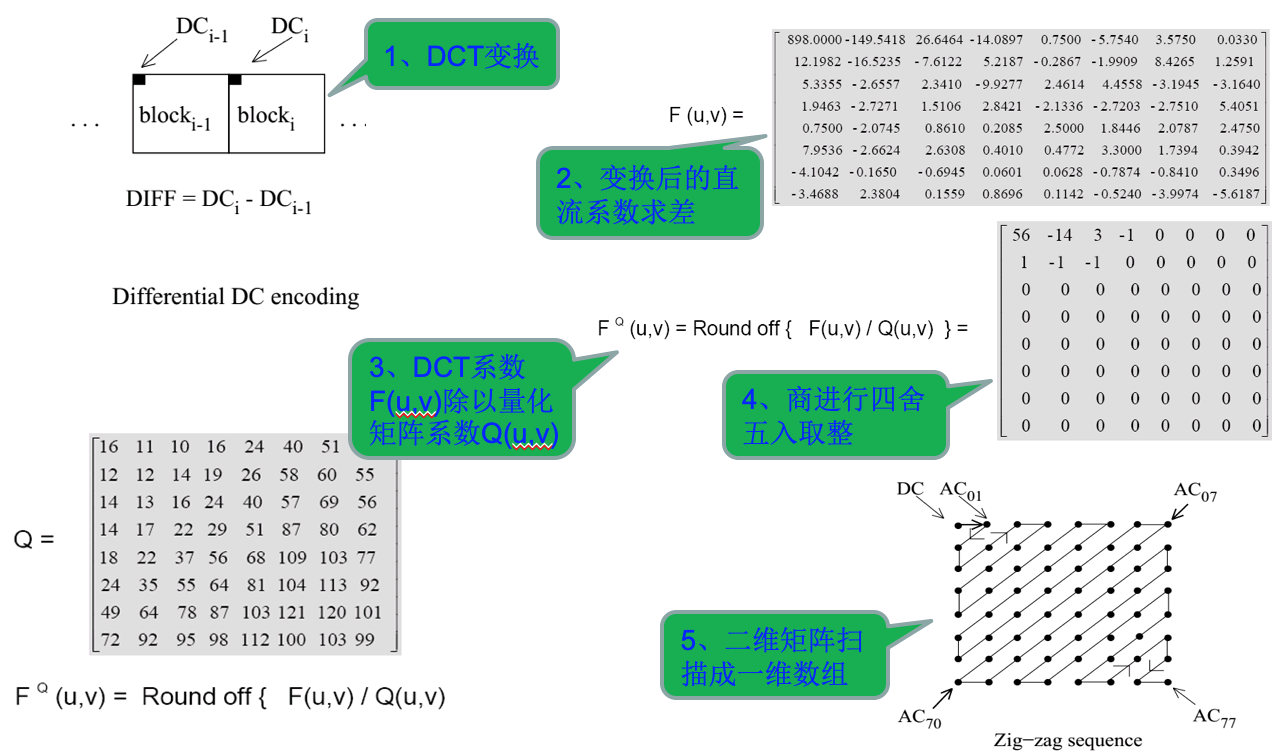
如上图所示,有损编码的数据处理过程。损失主要在量化阶段引入,由于量化不可逆。
二、图像分割
JPEG算法的第一步,图像被分割成大小为8X8的小块,这些小块在整个压缩过程中都是单独被处理的。

三、色彩空间转化
JPEG编码的第二步,做色彩空间转换,将输入待编码图片转成统一的色彩格式。所谓色彩空间,是指表达颜色的数学模型,比如我们常见的“RGB”模型,就是把颜色分解成红绿蓝三种分量,这样一张图片就可以分解成三张灰度图。数学表达上,每一个8X8的图案,可以表达成三个8X8的数据分别为R、G、B的矩阵,其中的数值的范围一般在[0,255]之间。在JPEG压缩算法中,需要把图案转换成为YCbCr模型,这里的Y表示亮度(Luminance),Cb和Cr分别表示绿色和红色的“色差值”。

为什么JPEG编码要使用YCbCr模型呢?对于人眼来说,图像中明暗的变化更容易被感知到,这是由于人眼的构造引起的。视网膜上有两种感光细胞,能够感知亮度变化的视杆细胞,以及能够感知颜色的视锥细胞,由于视杆细胞在数量上远大于视锥细胞,所以我们更容易感知到明暗细节。有损压缩首先要做的事情就是“把重要的信息和不重要的信息分开”,尽量保留重要信息,不重要的信息删减,达到压缩的目的。基于YCbCr色彩模型的特点,可以将亮度和色差分开表示。这样编码时可以针对人眼敏感的亮度分量着重处理,不敏感的色差分量做部分损失。

从上图看,对图片做YC分离可以明显看到,亮度图的细节更加丰富,人眼更加敏感。JPEG把图像转换为YCbCr之后,就可以根据数据的重要程度的不同,针对性地做不同的处理。
三、变换
JPEG算法中的核心内容,离散余弦变换(Discrete cosine transform),简称DCT。离散余弦变换属于傅里叶变换的另外一种形式,没错,就是大名鼎鼎的傅里叶变换。傅里叶是法国著名的数学家和物理学家,1807年,39岁的傅里叶在他的一篇论文里提出了一个想法,他认为任何周期性的函数,都可以分解为为一系列的三角函数的组合,这个想法一开始并没有得到当时科学界的承认,比如当时著名的数学家拉格朗日提出质疑,三角函数无论如何组合,都无法表达带有“尖角”的函数,一直到1822年拉格朗日死后,傅里叶的想法才正式在他的著作《热的解析理论》一书中正式发表。
傅里叶变换如今广泛应用于数学、物理、信号处理等等领域,变换除了它在数学上的意义外,还有其哲学上的伟大意义,那就是,世上任何复杂的事物,都可以分解为简单的事物的组合,而这个过程只需要借助数学工具就可以了。但是当年拉格朗日的质疑是正确的,三角函数的确无法表达出尖角形状的函数,不过只要三角函数足够多,可以无限逼近最终结果。比如下面这张图,就动态描述了一个矩形方波,是如何做傅里叶分析的。
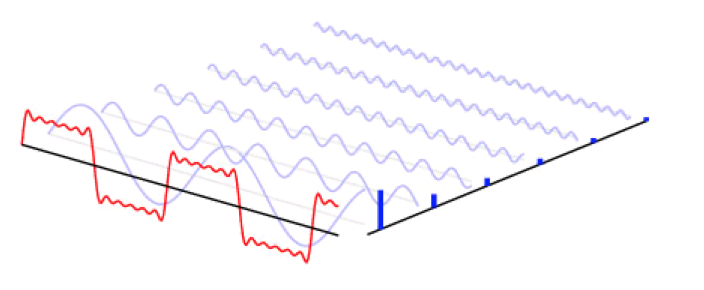
当我们要处理的不再是函数,而是一堆离散的数据时,并且这些数据是对称的话,那么傅里叶变化出来的函数只含有余弦项,这种变换称为离散余弦变换。DCT能够将空域的信号转换到频域上,具有良好的去相关性的性能。
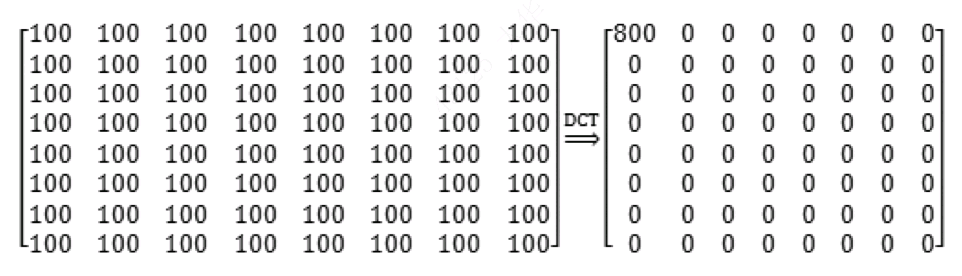
DCT的主要目的:实现定长的时域信号数据转换为频域信号,得到能量高的频域范围,去除冗余。比如一个所有数值都一样的矩阵,经过DCT转换后,将所有级数组合成一个新的矩阵:
下图为一维DCT变换公式:其中,f(i)为原始的信号,F(u)是DCT变换后的系数,N为原始信号的点数,c(u)可以认为是一个补偿系数,可以使DCT变换矩阵为正交矩阵。
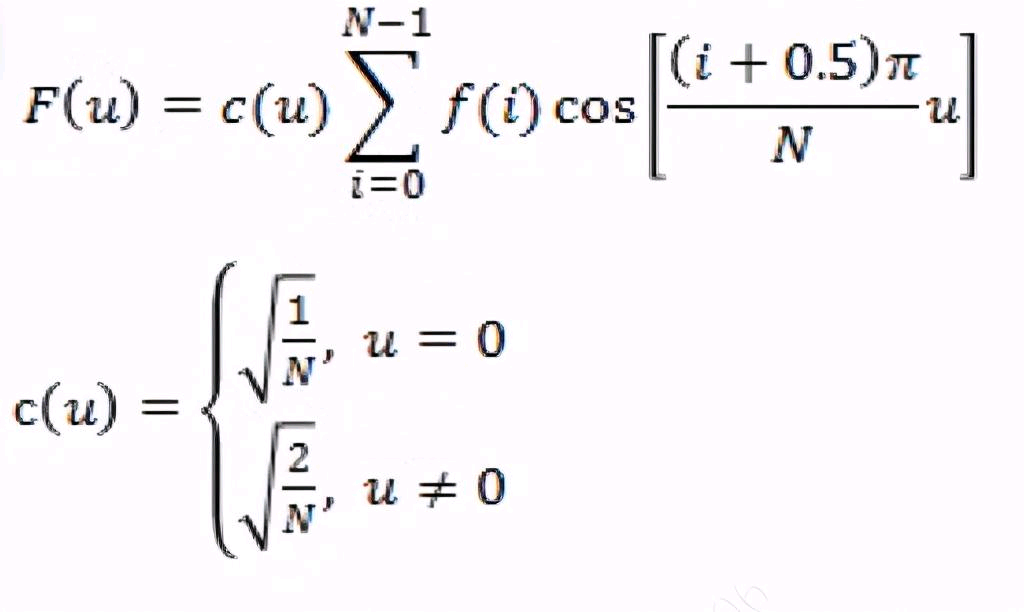
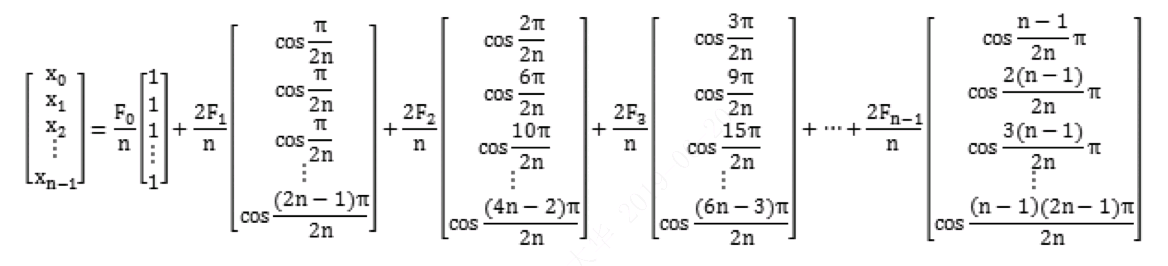
从公式可理解经过DCT变换,求出各个系数,可以把一个数组分解成数个数组的和,如果我们数组视为一个一维矩阵,那么可以把结果看做是一系列矩阵的和。
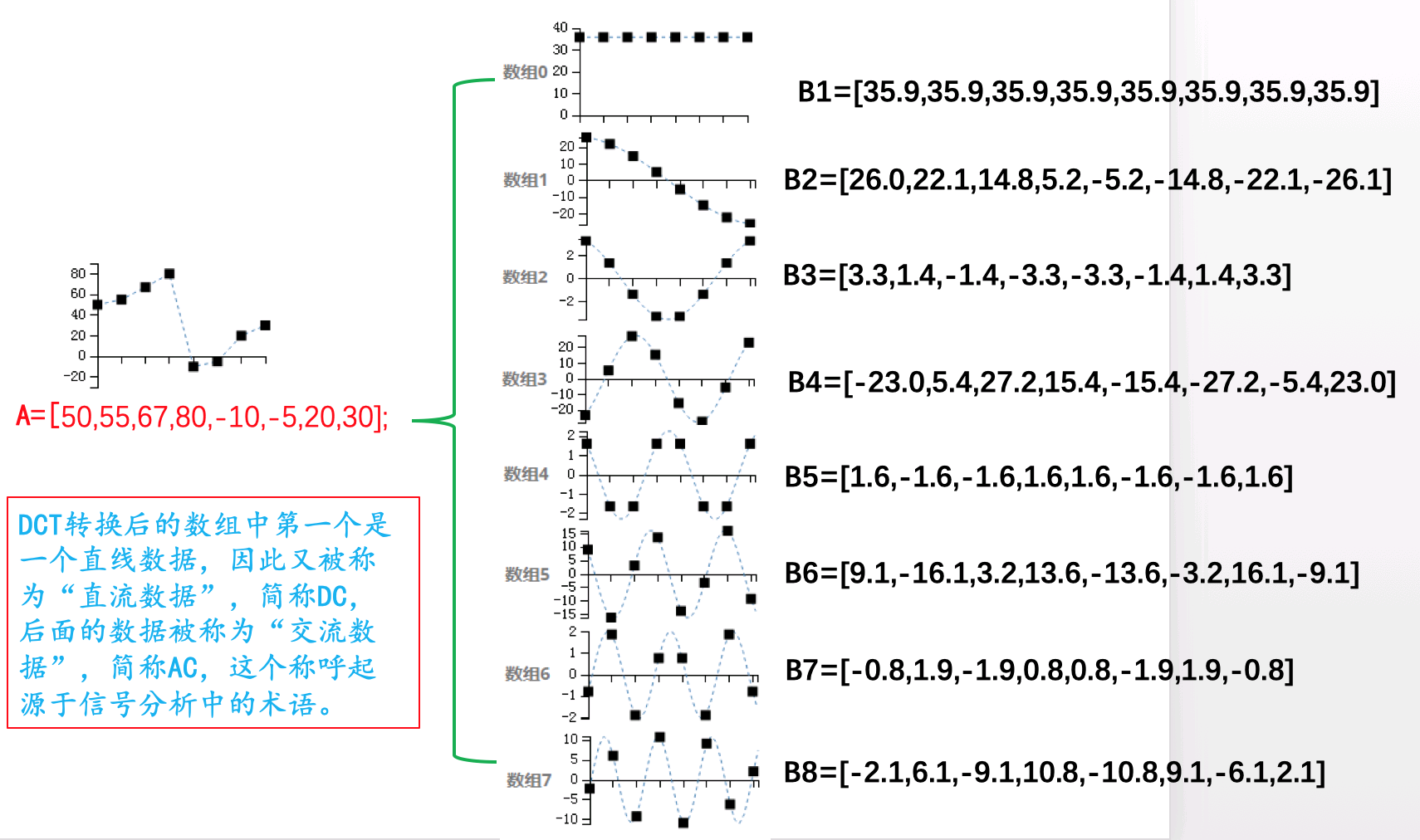
我们下面来看一个实例,如下图所示为离散数据50,55,67,80,-10,-5,20,30的DCT变换,从图中可以形象的看出DCT变换的过程,一维数组通过DCT变换后,被表示为多个余弦函数的叠加。
经过第一步的图像分割,被分成了多个8x8的宏块,每个宏块有3个8x8的数据矩阵(YCbCr),所以我们需要进行二维DCT变化。

经过DCT转换,矩阵的“能量”被全部集中在左上角上的直流分量F(0,0)上,其他位置都变成了0。实际图片由于图像本身的连贯性,在8x8的块中数据基本不会有大的的跳跃,经过DCT变化后,被分成直流分量和交流分量,为后面的进一步压缩起到了充分的铺垫作用,是整个JPEG中最重要的一步。经过DCT变换,图像数据已经抽象化,但处于“可逆”的状态,经过IDCT会还原,没有数据损失。
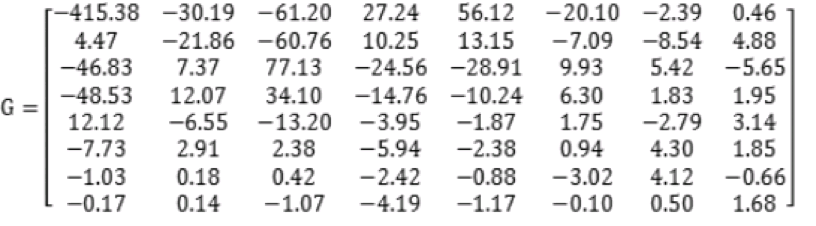
上图数据是一块Y分量经过DCT变化后的数据,可以看到数据之间差异仍然比较大。 在可以损失一部分精度的情况下,如何用更少的空间存储这些浮点数?下一步数据量化负责这块工作。
四、量化
JPEG提供的量子化算法:

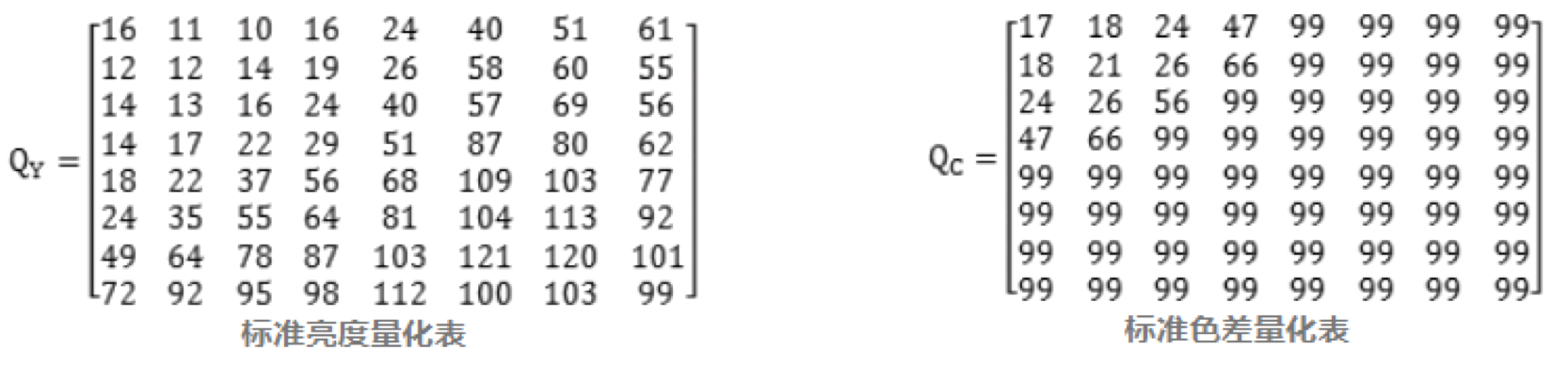
JPEG算法提供了两张标准的量化系数矩阵,分别用于处理亮度数据Y和色差数据Cr以及Cb:

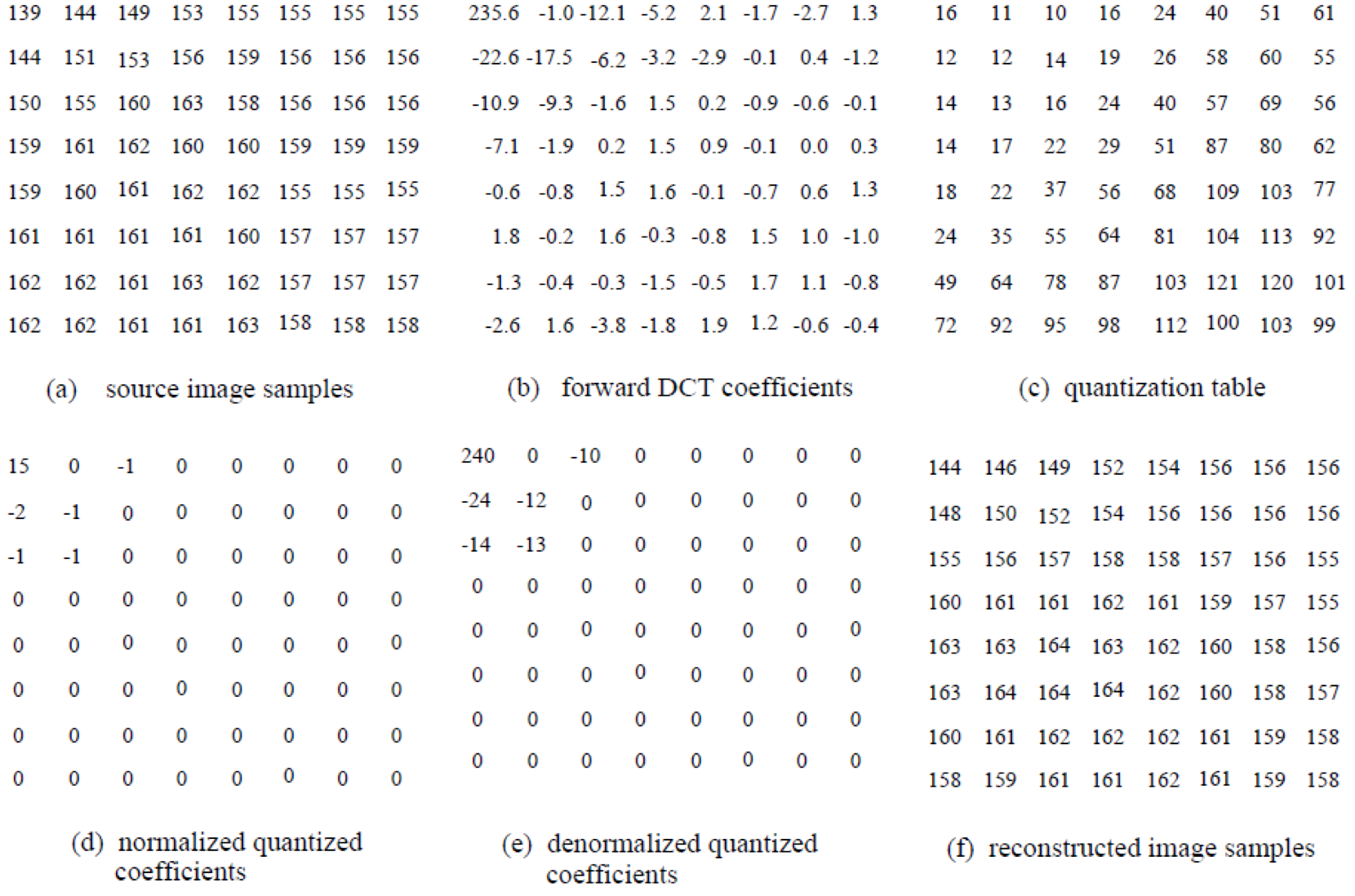
可以看到,数据经过量化后,明细可以看到数据较集中,相互之间差异变小,为后面的熵编码减少了大量冗余。但是在量化阶段引入了精度损失:如下图所示,8x8矩阵数据经过DCT和量化之后,再进行反量化和反变换还原,可以看到由于量化阶段的精度损失,导致还原的数据和原始数据出现了偏离,导致了精度损失。
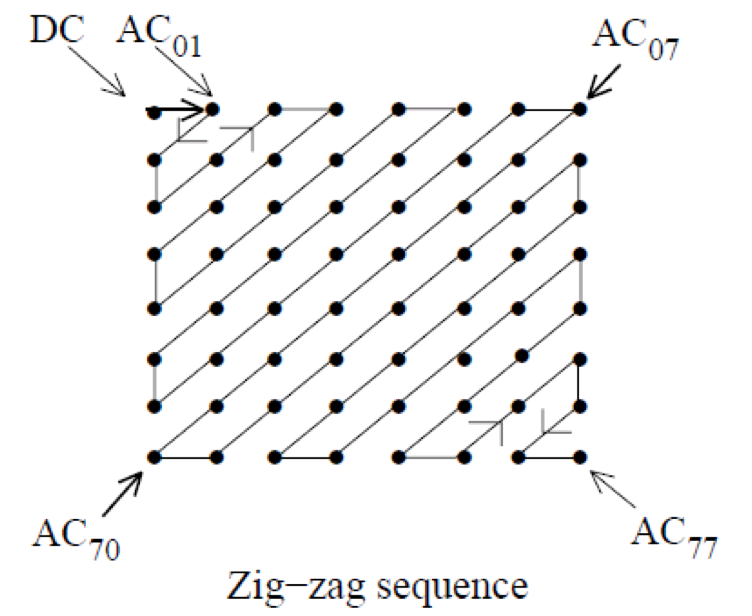
经过量化以后,数据差异大幅降低,为了方便后面的熵编码,需要把二维数据转换为一维数组。用下图Zig-zag方式转换,目的是将不重要的高频部分、能量集中的低频部分尽可能多地集中在一起,所以从左上角到右下角的方向做扫描。
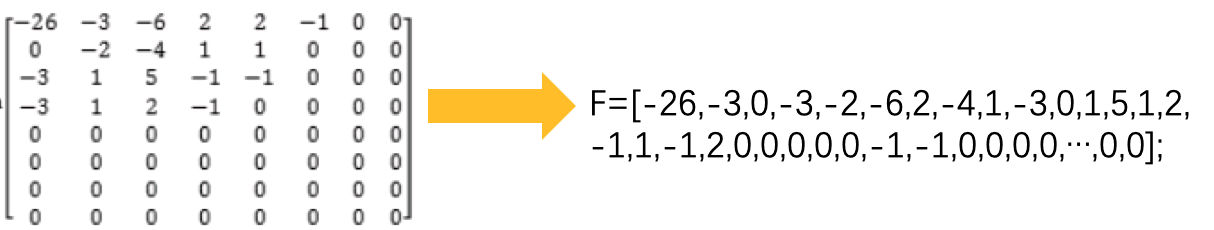
图片数据经过DCT和量化后,已经从空域数据转为抽象的频域数据,并通过量化大幅度去除了冗余,之后使用zig-zag的方式做能量集中扫描,将数据转为一维数组,为最后的熵编码做准备。
五、熵编码
熵编码为哈弗曼编码(Huffman coding),哈弗曼几乎是所有压缩算法的基础,它的基本原理是根据数据中元素的使用频率,调整元素的编码长度,以得到更高的压缩比。我们下面来看下具体的编码过程。
假设量化后zig-zag得到的一维数据为:

1、数据中的0出现的概率非常高,所以首先要做的事情,是对其中的0进行处理,把数据中的非零的数据,以及数据前面0的个数作为一个处理单元。如果其中某个单元的0的个数超过16,则需要分成每16个一组,如果最后一个单元全都是0,则使用特殊字符“EOB”表示,EOB意思就是“后面的数据全都是0”,

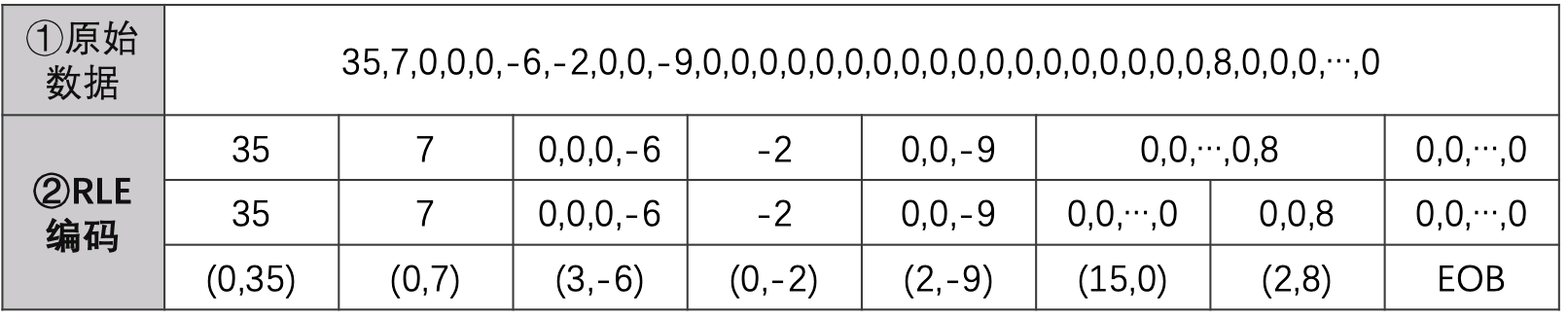
2、处理括号里右边的数字,这个数字的取值范围在-2047~2047之间,JPEG提供了一张标准的码表用于对这些数字编码:
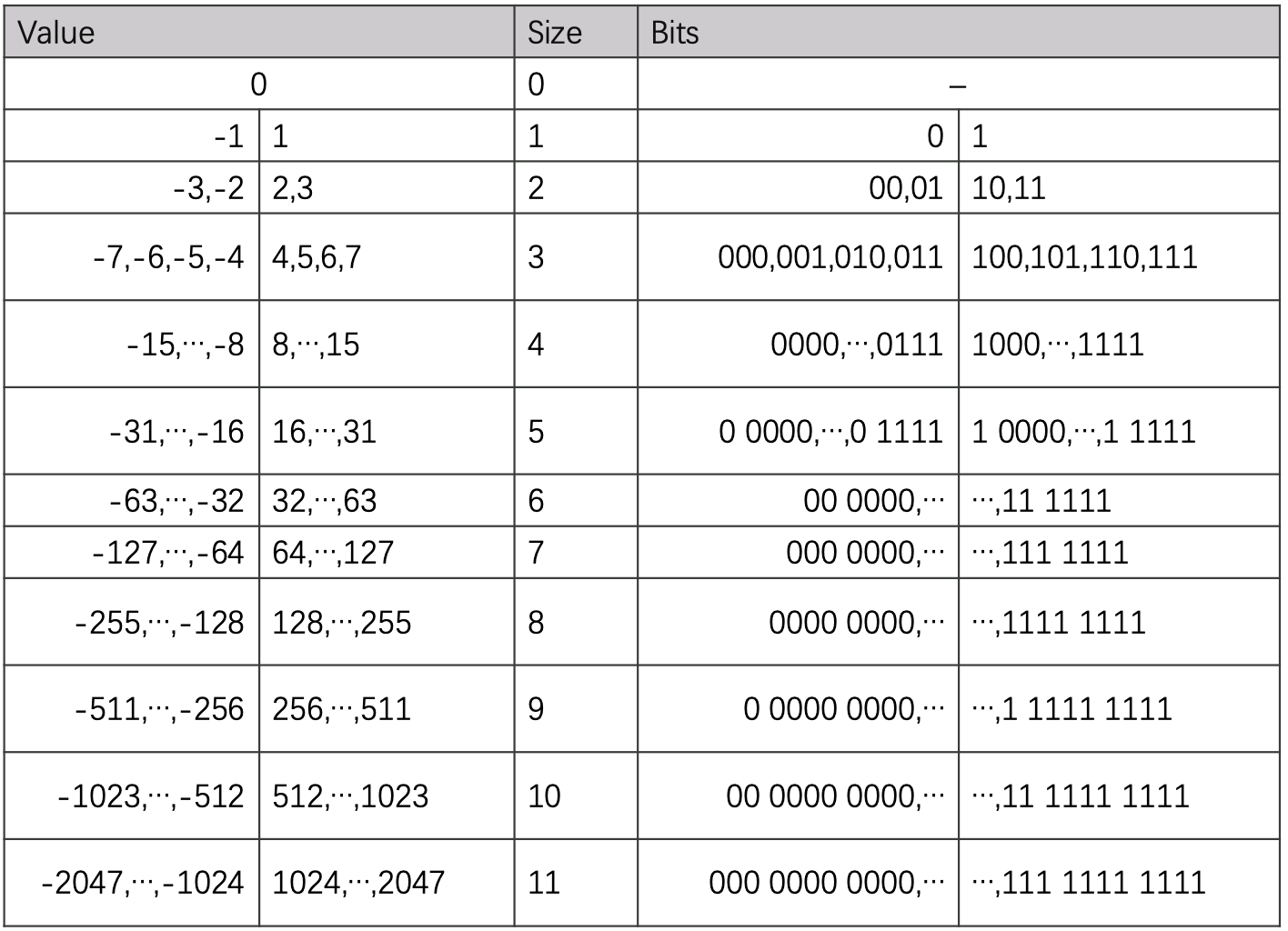
根据标准码表编码之后:
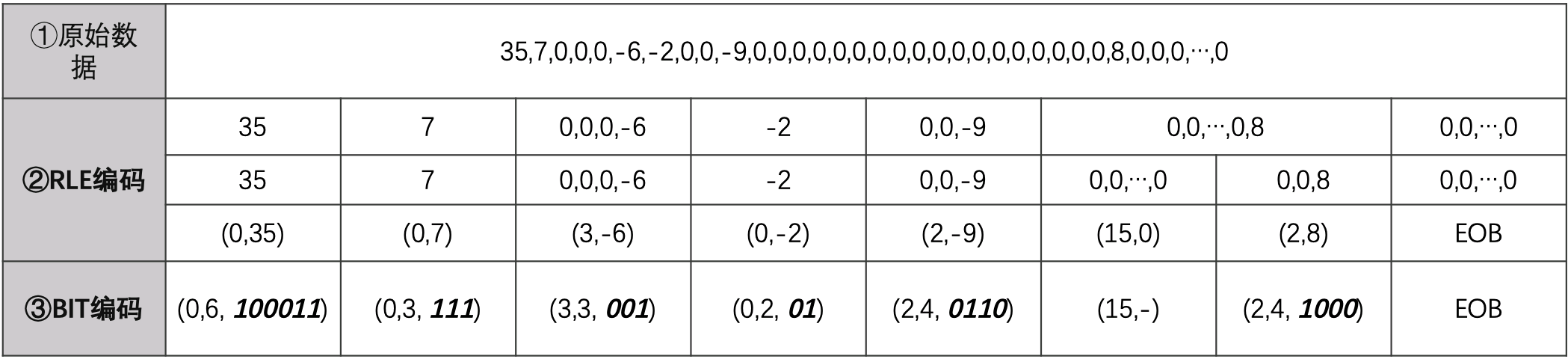
根据协议可以确定的是括号中前两个数字分都在0~15之间,所以这两个数可以合并成一个byte,高四位是前面0的个数,后四位是后面数字的位数。
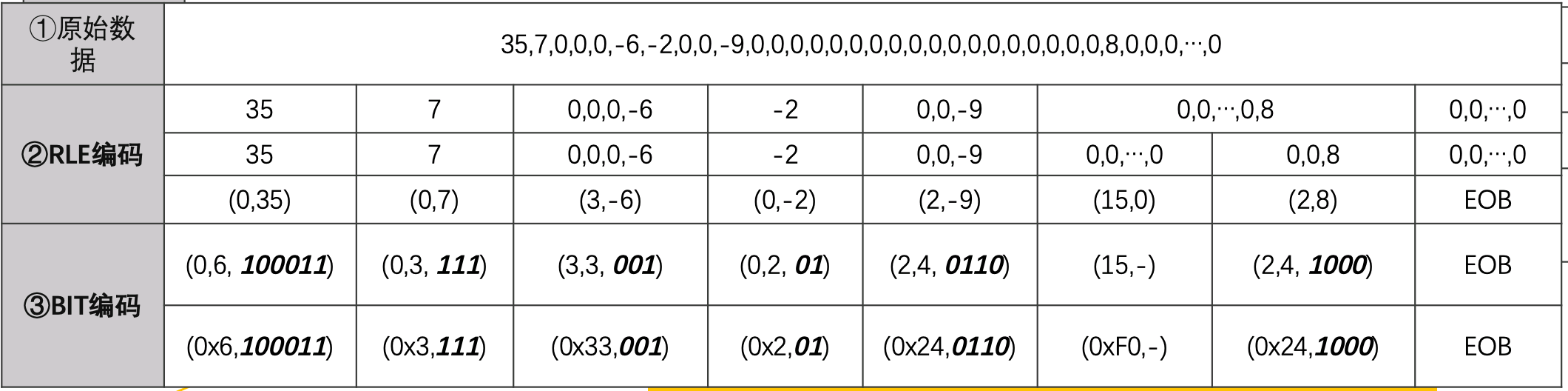
3、处理括号里左边的数字,使用哈弗曼编码。下面这张表,就是一张针对数据中的第一个单元,也就是直流(DC)部分的哈弗曼表,由于直流数据是序列第一个数据,没有前置的0,所以byte只用了4个byte,值的范围在0~11之间。
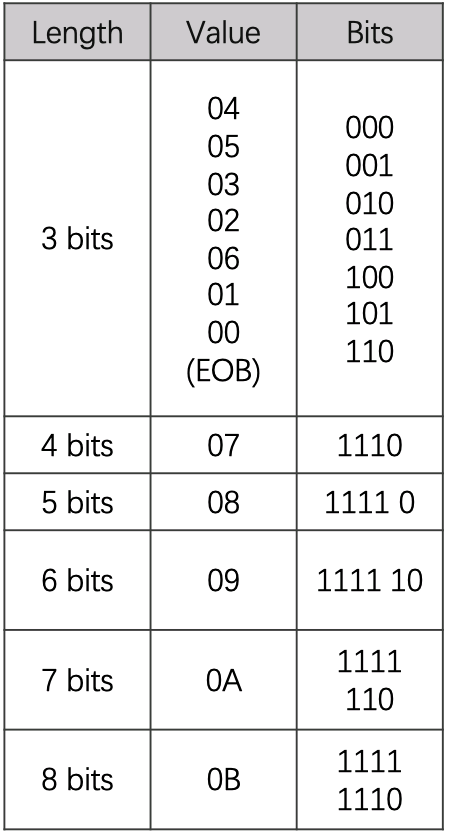
交流分量会出现0,所以值的范围任务高四位可能为0x0~0xf(0的个数最大为15),低四位范围为0~0xb(对应码表中的size),下面这张哈夫曼表对应的就是交流部分的。
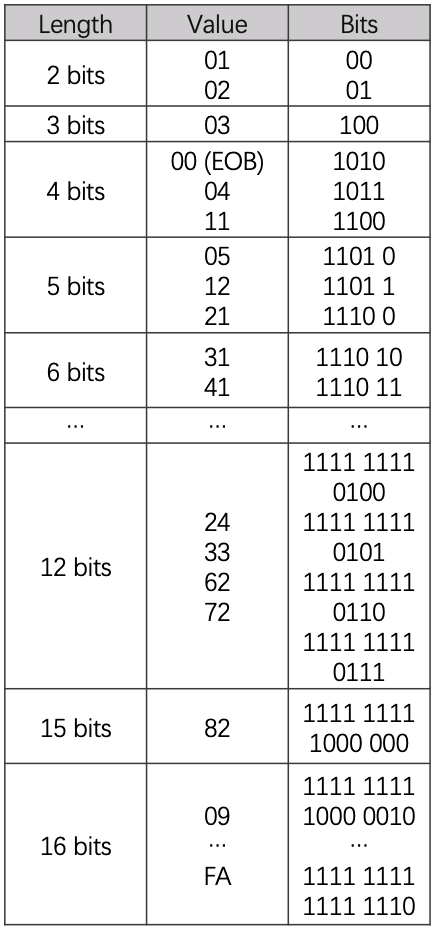
这样分别对直流数据和交流数据编码并且序列后得到了最终的编码数据:
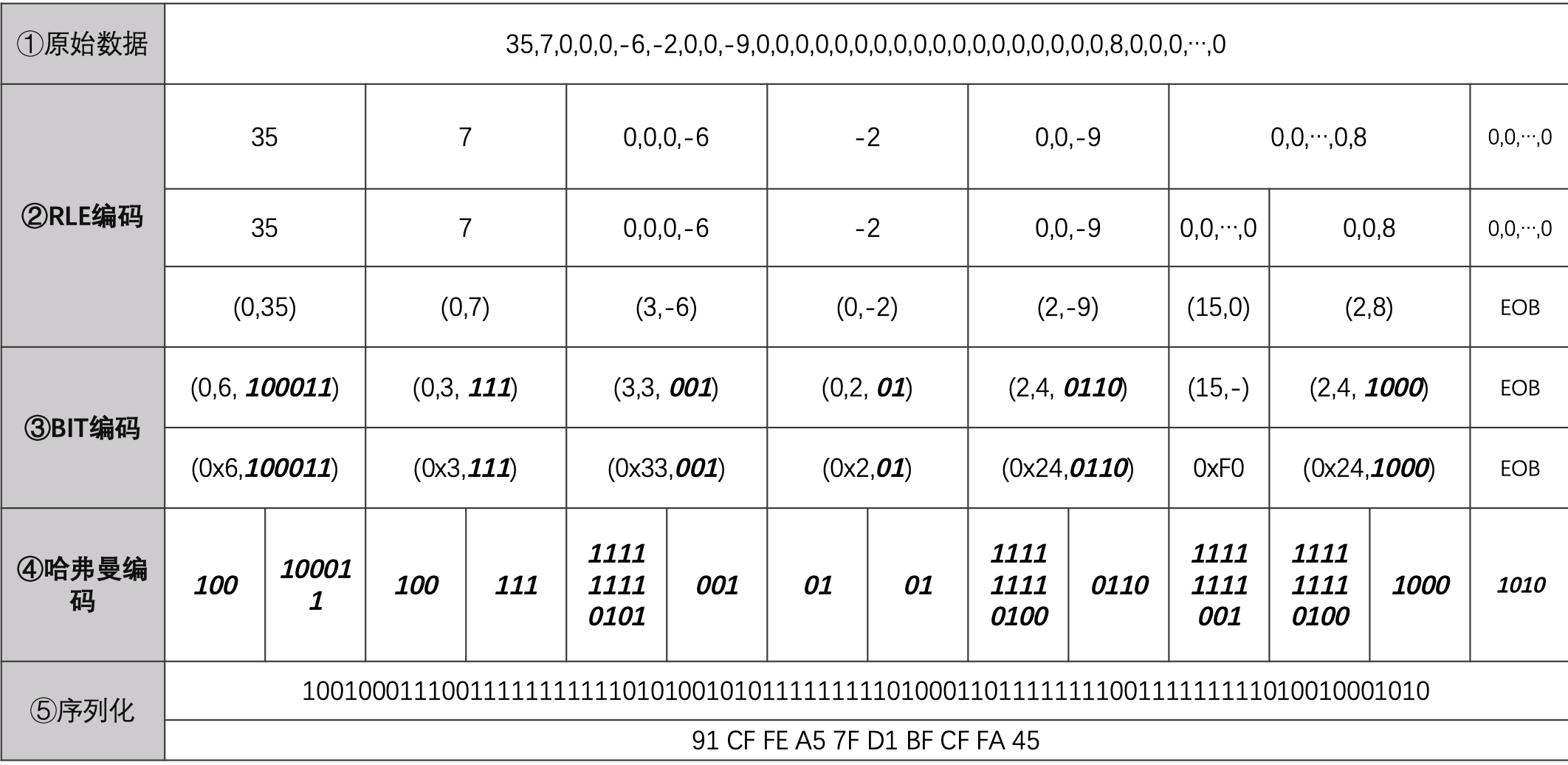
最终我们使用了10个字节的空间保存了原本长度为64的数组,至此JPEG的主要压缩算法结束,这些数据就是保存在jpg文件中的最终编码数据。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号