XMU《UNIX 系统程序设计》第一次实验报告 (同步与异步 write 的效率比较)
实验一 同步与异步 write 的效率比较
一、实验内容描述
编写程序,比较在同步和异步的条件下 write 系统调用的效率差异。
程序要求从 stdin 读入数据,输出到以命令参数给出的文件中,并以列表的格式给出输出消耗的时间。

1、编写程序
timewrite <outfile> [sync]
不得变更程序的名字和使用方法。sync 参数为可选,若有,则输出文件用O_SYNC 打开。
例:
timewrite <f1 f2 # 表示输出文件f2不用O_SYNC 打开。
timewrite f1 sync <f2 # 表示输出文件f1用O_SYNC 打开。
2、显示的时间应当尽量接近 write 操作过程所花的时间。不要将从磁盘读文件的时间计入显示结果中。
3、严格按 P55 表 3-2 的结果格式输出(BUFFSIZE 从 256 开始起算直至 128K),抬头和分割线省略。
4、10月15日晚上24点(零点)为实验完成截止期。时间获取可以用库函数times,请自行掌握它的功用。
二、设计与实现
程序大概分为如下几个部分:
-
参数读取。此部分中,主要从命令行参数中读取输入文件,以及是否需要同步。如果参数不符合要求,就打印提示信息并退出。
-
打开输出文件。此部分中,根据是否需要同步,确定
open函数的参数,并保存文件描述符。 -
读取输入并保存至输入缓冲区。此部分中可以划分成三步:
- 确定输入文件长度:使用
lseek函数定位到文件末尾,利用其返回值得到文件长度,并重新定位回文件开头。 - 申请缓冲区:使用
malloc申请能够存放完整输入文件内容的缓冲区。 - 读取:使用
read系统调用,读取输入文件的内容并保存至缓冲区。
- 确定输入文件长度:使用
-
循环枚举输出的缓冲长度
BUFFSIZE,在循环中,分为以下几个部分:- 调用
times函数记录输出之前的时间。 - 输出。具体地,每次以当前枚举的
BUFFSIZE的缓冲区大小循环输出,直到输出结束。 - 再次调用
times函数获得输出之后的时间。 - 打印当前缓冲区对应的输出消耗时间。
- 调用
-
关闭文件描述符,结束程序。
此外,在编写程序时,为了更方便地处理系统调用返回错误代码的情况,我将许多系统调用封装成了对应的首字母大写的形式,比如将 read 函数封装成 Read函数,在 Read 函数中,我调用 read 并对其返回值进行判断,如果返回 -1 则说明遇到错误,则打印错误并退出程序。
#include <fcntl.h>
#include <unistd.h>
#include <sys/times.h>
#include <stdio.h>
#include <string.h>
#include <stdlib.h>
int Open(char *path, int flags);
off_t Lseek(int fd, off_t offset, int whence);
void *Malloc(size_t size);
ssize_t Read(int fd, void *buf, size_t size);
ssize_t Write(int fd, void *buf, size_t size);
int Close(int fd);
int main(int argc, char *argv[]) {
int fd;
// 参数读取和处理
if (argc < 2 || argc > 3 || (argc == 3 && strcmp(argv[2], "sync") != 0)) {
fprintf(stderr, "usage: %s <outfile> [sync]\n", argv[0]);
exit(0);
}
// 打开输出文件
if (argc == 3) { // 如果指定了使用同步输出
fd = Open(argv[1], O_WRONLY | O_CREAT | O_TRUNC | O_SYNC);
} else {
fd = Open(argv[1], O_WRONLY | O_CREAT | O_TRUNC);
}
// 读取输入并保存至输入缓冲区
off_t len = Lseek(STDIN_FILENO, 0, SEEK_END); // 定位到输入文件末尾并从返回值中读取移动距离,从而得到文件长度
Lseek(STDIN_FILENO, 0, SEEK_SET); // 重新定位回文件开头
char *buf = Malloc(len + 10); // 申请缓冲区空间
ssize_t readn = Read(STDIN_FILENO, buf, len); // 读取输入文件
if (readn != len) { // 如果输入读取不完整,则输出错误提示并退出
fprintf(stderr, "read failed!\n");
exit(1);
}
long dida = sysconf(_SC_CLK_TCK); // 获取时钟嘀嗒数
printf("BUFFSIZE\tUser CPU\tSys CPU\t\tCLOCK\t\tLoops\n"); // 输入表头
for (int buffsize = 512; buffsize <= 131072; buffsize *= 2) { // 枚举 BUFFSIZE
Lseek(fd, 0, SEEK_SET); // 定位到输出文件开头
struct tms tmst, tmed;
clock_t st = times(&tmst); // 记录输出前的时间
char *pos = buf;
ssize_t writen;
int loops = 0;
while (pos < buf + len) { // 重复以 BUFFSIZE 作为输出缓冲大小,直到全部输入完成
int size = buffsize < buf + len - pos ? buffsize : buf + len - pos; // 将 buffsize 和输入内容剩余长度比较,得到实际应该输入的长度
writen = Write(fd, pos, size);
if (writen != size) { // 如果实际输出长度不等于 size 说明输出错误
fprintf(stderr, "write failed!\n");
exit(1);
}
pos += size;
++loops;
}
clock_t ed = times(&tmed); // 记录输出结束时间
printf("%d\t\t%.2lf\t\t%.2lf\t\t%.2lf\t\t%d\n", buffsize, (tmed.tms_utime - tmst.tms_utime) / (double)dida, (tmed.tms_stime - tmst.tms_stime) / (double)dida, (ed - st) / (double)dida, loops); // 输出本次 buffsize 相关的时间
}
Close(fd); // 关闭文件描述符
return 0;
}
// 被封装的系统调用
void err_sys(char *msg) {
fprintf(stderr, msg);
exit(1);
}
int Open(char *path, int flags) {
int fd = open(path, flags);
if (fd == -1)
err_sys(" file failed!");
return fd;
}
off_t Lseek(int fd, off_t offset, int whence) {
off_t ret = lseek(fd, offset, whence);
if (ret == -1)
err_sys("lseek failed!");
return ret;
}
void *Malloc(size_t size) {
void *ret = malloc(size);
if (ret == NULL)
err_sys("malloc failed!");
return ret;
}
ssize_t Read(int fd, void *buf, size_t size) {
ssize_t ret = read(fd, buf, size);
if (ret == -1)
err_sys("read failed!");
return ret;
}
ssize_t Write(int fd, void *buf, size_t size) {
ssize_t ret = write(fd, buf, size);
if (ret == -1)
err_sys("write failed!");
return ret;
}
int Close(int fd) {
int ret = close(fd);
if (ret == -1)
err_sys("close failed!");
return ret;
}
三、实验结果
1. 编译程序
源程序名:timewrite.c
输出程序名:time write
gcc timewrite.c -o timewrite -std=c99
因为学校的服务器上的 gcc 版本默认使用 c89,所以需要 -std=c99 才能编译某些常用的 C 语法。
2. 生成输入文件
因为输入文件显然需要很大才能测试出效率差异,因此我这里使用 dd 命令生成一个 1G 的大文件 a.txt,其内容全部为 0。
dd if=/dev/zero of=a.txt bs=1M count=1024

3. 异步输出测试
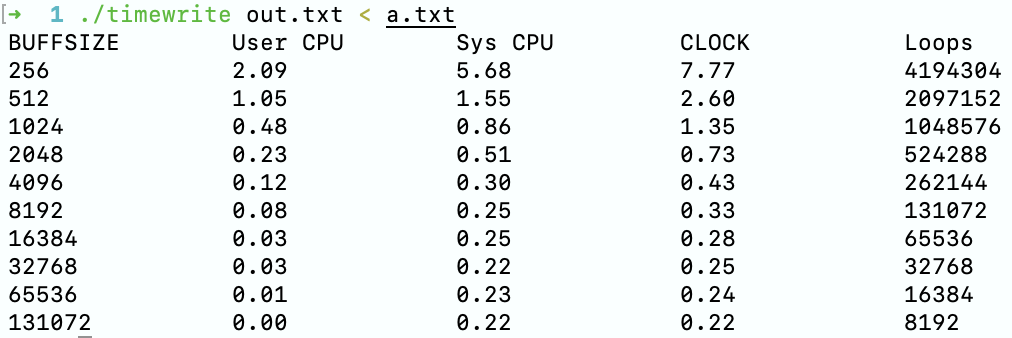
调用编译后的程序,从 a.txt 中输入,输出到 out.txt。
./timewrite out.txt < a.txt
4. 同步输出测试
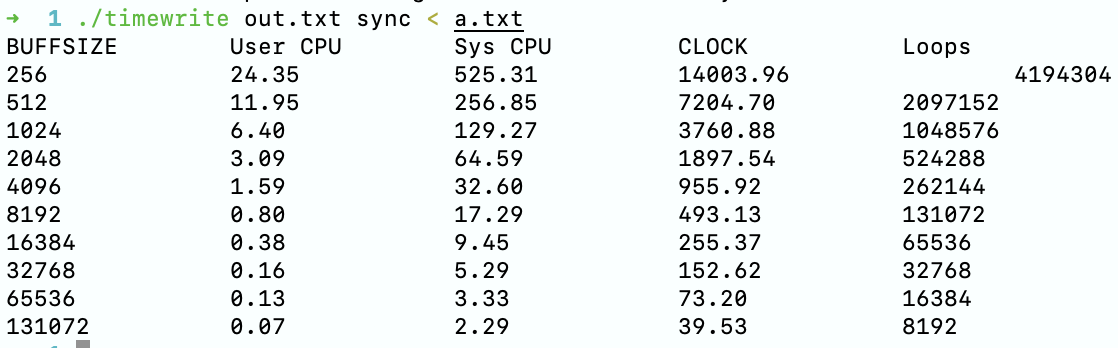
与上一步唯一不同的是,需要在命令中加上 sync 参数,以进行同步输出。
./timewrite out.txt < a.txt
5. 结果分析
可以发现,同步条件下 write 的效率比异步下慢了几个数量级,在每次输出后立刻将修改同步到硬盘的代价是非常大的。
另外,可以观察到同步输出条件下,用户的 CPU 使用时间与系统调用的 CPU 使用时间的和并不等于输出一共消耗的时间,因此可以得到,在同步输出下,主要的时间消耗在与写入硬盘的过程,这个过程实际上不需要 CPU 的参与。
四、实验体会
通过完成本次实验,我深刻体会到同步和异步条件下 write 系统调用的效率差异。在编写程序的过程中,我按照要求创建了名为 timewrite 的程序,并通过命令行参数传递输出文件名和可选的 sync 参数。在同步条件下,程序使用 O_SYNC 打开输出文件,而在异步条件下则不使用该选项。
我注意到,在同步条件下,write 系统调用的效率相对较低,因为程序会等待写入操作完成后才继续执行。这导致了一定的时间开销。相反,在异步条件下,程序在发起写入操作后就能够立即继续执行,而不需要等待写入的完成,因此相对更为高效。
通过严格按照给定的结果格式输出时间信息,我得以清晰地观察到不同BUFFSIZE下的性能表现。从 256 到 128K 的不同缓冲大小,可以看到在异步条件下,效率的提升相对更为显著。这强调了在大规模数据写入时,异步写入的优势。
通过这个实验,我不仅深入理解了同步和异步写入操作的原理,还学到了如何使用 times 库函数获取程序执行时间。这对我理解 Unix 系统程序设计中 I/O 操作的性能优化和调优提供了实际经验。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号