XMU《UNIX 系统程序设计》第二次实验报告(目录树的遍历)
本实验我提交的代码和环境见:点击下载。
一、实验内容描述
实验目的
掌握与文件和目录树有关的系统调用和库函数。
实验要求
编写程序myfind
命令语法
myfind <pathname> [-comp <filename> | -name <str>...]
命令语义
(1)myfind <pathname> 的功能
除了具有与程序 4-7 相同的功能外,还要输出在 <pathname> 目录子树之下,文件长度不大于 \(4096\) 字节的常规文件,在所有允许访问的普通文件中所占的百分比。程序不允许打印出任何路径名。
(2)myfind <pathname> -comp <filename> 的功能
<filename> 是常规文件的路径名(非目录名,但是其路径可以包含目录)。命令仅仅输出在 <pathname> 目录子树之下,所有与 <filename> 文件内容一致的文件的绝对路径名。不允许输出任何其它的路径名,包括不可访问的路径名。
(3)myfind <pathname> -name <str>...的功能
<str>... 是一个以空格分隔的文件名序列(不带路径)。命令输出在<pathname> 目录子树之下,所有与 <str>... 序列中文件名相同的文件的绝对路径名。不允许输出不可访问的或无关的路径名。
<pathname> 和 <filename> 均既可以是绝对路径名,也可以是相对路径名。<pathname> 既可以是目录,也可以是文件,此时,目录为当前工作目录。
命令要求
- 注意尽可能地提高程序的效率。注意避免因打开太多文件而产生的错误。
- 遍历目录树时,访问结点(目录项)的具体操作应当由遍历函数
dopath携带的函数指针参数决定。这样程序的结构清晰,可扩充性好。 - 10 月 30 日晚上 24 点为实验完成截止期。
二、设计与实现
首先,根据下发的实验指导文档,教材(第三版)图 4-22 提供的程序 ftw8.c 程序中,实现了三个函数。
static int myftw(char *, Myfunc *); static int dopath(Myfunc *); static int cmpfile(const char *, const char *);

具体的,
myftw()函数以所带参数pathname为要遍历的起始目录,计算出该目录下各种不同类型的文件的个数和所占百分比,并显示出来。它调用了另外两个函数,一个是dopath()函数,这是一个递归函数,对指定的起始目录下的每个目录项,按深度优先进行遍历;而对所访问的节点,则调用myfunc()进行处理。
因此,我们其实只需要修改两个函数即可。
main函数:我们需要修改main函数来适应参数处理、myftw函数的调用和结果打印。myfunc函数:原本我们只有一个myfunc函数,现在为了实现三个功能,我们需要写三个myfunc函数。
参数处理
我的代码中,这一部分主要是判断参数是否合法,并根据参数的内容,判断需要执行的任务类型。
static int type; // main if (argc == 2) type = 1; else if (argc == 4 && strcmp(argv[2], "-comp") == 0) type = 2; else if (argc >= 4 && strcmp(argv[2], "-name") == 0) type = 3; else err_quit("usage: myfind <pathname> [-comp <filename> | -name <str>...]");
相对路径转绝对路径
因为题目要求,在 comp 任务和 name 任务中输出的路径名,必须要是绝对路径。
因此在进行递归遍历之前,我把参数传入的相对路径直接转换成了绝对路径。
只需要调用 C 标准库提供的函数即可。
static char realpathname[PATH_MAX]; // main realpath(argv[1], realpathname);
其中,argv[1] 是第二个参数,也就是除了程序名的第一个参数,即 <pathname>。realpathname 是预先定义的一个用来存放绝对路径的字符数组。
进一步的参数处理以及 myftw 函数的调用
static int cmpstrlen; static char *cmpfilename, *cmpstr[MAXLINE]; // main if (type == 1) ret = myftw(realpathname, myfunc1); /* does it all */ else if (type == 2) { struct stat statbuf; cmpfilename = argv[3]; if (lstat(cmpfilename, &statbuf) < 0) err_sys("lstat error"); cmpstrlen = statbuf.st_size; ret = myftw(realpathname, myfunc2); } else { for (int i = 3; i < argc; i++) cmpstr[i - 3] = argv[i]; cmpstrlen = argc - 3; ret = myftw(realpathname, myfunc3); }
如果是类型 1,也就是命令的第一个功能,不需要进行什么准备,直接调用 myftw 即可。
如果是类型 2,那么需要将 argv[3],也就是参数中的 <filename> 拷贝到一个全局变量中,以便在判断文件是否相同的是否访问。同时,我们使用 lstat 函数获得文件的 stat,从而获得这个文件的长度,在后面判断文件是否相同的时候可以先判断长度是否相等。
如果是类型 3,那么需要将参数中传入的所有待比较文件名序列的地址存进一个全局数组中,同时用一个全局变量保存下待比较文件名的个数。
myfunc1
myfunc1 函数可以沿用程序中原有的 myfunc 函数,只需要做一点小小的更改。
static int myfunc1(const char *pathname, const struct stat *statptr, int type) { switch (type) { case FTW_F: switch (statptr->st_mode & S_IFMT) { case S_IFREG: nreg++; if (statptr->st_size <= 4096) cnt4096++; break; case S_IFBLK: nblk++; break; case S_IFCHR: nchr++; break; case S_IFIFO: nfifo++; break; case S_IFLNK: nslink++; break; case S_IFSOCK: nsock++; break; case S_IFDIR: /* directories should have type = FTW_D */ err_dump("for S_IFDIR for %s", pathname); } break; case FTW_D: ndir++; break; case FTW_DNR: err_ret("can't read directory %s", pathname); break; case FTW_NS: err_ret("stat error for %s", pathname); break; default: err_dump("unknown type %d for pathname %s", type, pathname); } return(0); }
在函数中,原本 nreg++; 的位置(这是统计常规文件数量的语句),需要加上本次实验新增的一个任务:
输出在
目录子树之下,文件长度不大于4096字节的常规文件,在所有允许访问的普通文件中所占的百分比
因此,这里判断了文件的大小,如果小于等于 4096,就将一个 long 类型的全局变量 \(+1\),即可统计出文件长度不大于 4096 字节的常规文件的数量。
比较文件内容
根据第二个任务的要求,我们要找出一个目录下和某个 <filename> 文件内容一致的文件。
因此,这就要求我们编写一个函数判断两个文件是否相同。
static int cmpfile(const char *filename1, const char *filename2, const struct stat *statptr) { if (statptr->st_size != cmpstrlen) return 0; int fd1 = open(filename1, O_RDONLY); int fd2 = open(filename2, O_RDONLY); int n1, n2; static char buf1[BUFSIZ], buf2[BUFSIZ]; if (fd1 < 0 || fd2 < 0) err_sys("open error"); while ((n1 = read(fd1, buf1, BUFSIZ)) > 0 && (n2 = read(fd2, buf2, BUFSIZ)) > 0) { if (n1 != n2) goto diff; if (memcmp(buf1, buf2, n1) != 0) goto diff; } if (read(fd1, buf1, BUFSIZ) > 0 || read(fd2, buf2, BUFSIZ) > 0) goto diff; close(fd1), close(fd2); return 1; diff: close(fd1), close(fd2); return 0; }
我采用的方法是首先判断两个文件的长度是否相等,然后逐字节比较。
首先,利用参数传入的文件 statptr,读取出被遍历的文件的长度。如果文件长度不相等,就直接返回。
然后,分别以只读的方式打开两个文件,得到两个文件描述符。
接下来,对每个文件,while 循环,每次都读入 BUFSIZ 长度的缓冲,直到读取结束。对于每次读入,使用 memcmp 函数判断读入的这些字节字节是否相同。为了防止意外情况,我这里又多判断了两个文件一次读入的字节数是否相等,其实可以不判断。
在有一个文件读入结束后,判断两个文件是否全部读入完成,如果不是,也认为两个文件不同。(其实因为已经保证了两个文件长度相等,这里没有必要)
如果上述要求都符合,即可判断两个文件相同。
在返回结果之前,使用 close 关闭文件描述符。
myfunc2
对于递归遍历得到的每个文件,首先判断其是不是一个常规文件。
对于常规文件,调用 cmpfile 判断与参数给定文件是否相同,如果相同,则打印文件路径。
static int myfunc2(const char *pathname, const struct stat *statptr, int type) { if (type != FTW_F || (statptr->st_mode & S_IFMT) != S_IFREG) return 0; if (cmpfile(pathname, cmpfilename, statptr) == 1) printf("%s\n", pathname); return 0; }
myfunc3
对于递归遍历得到的每个文件,首先判断其是不是一个常规文件。
对于常规文件,枚举预先存储在 cmpstr 中的所有文件名,逐个判断文件名是否相同,只要有一个相同,那么就打印文件路径,并立刻返回(以防重复打印)。
static int myfunc3(const char *pathname, const struct stat *statptr, int type) { if (type != FTW_F || (statptr->st_mode & S_IFMT) != S_IFREG) return 0; const char *filename = pathname + strlen(pathname); while (filename >= pathname && *filename != '/') filename--; ++filename; for (int i = 0; i < cmpstrlen; ++i) if (strcmp(filename, cmpstr[i]) == 0) { printf("%s\n", pathname); return 0; } return 0; }
打印
只有 type=1 时需要打印,因为任务二三已经在遍历的过程中打印了。
// main if (type == 1) { ntot = nreg + ndir + nblk + nchr + nfifo + nslink + nsock; if (ntot == 0) ntot = 1; /* avoid divide by 0; print 0 for all counts */ printf("regular files = %7ld, %5.2f %%\n", nreg, nreg*100.0/ntot); printf("regular files not longer than 4096B = %7ld, %5.2f %%\n", cnt4096, cnt4096*100.0/ntot); printf("directories = %7ld, %5.2f %%\n", ndir, ndir*100.0/ntot); printf("block special = %7ld, %5.2f %%\n", nblk, nblk*100.0/ntot); printf("char special = %7ld, %5.2f %%\n", nchr, nchr*100.0/ntot); printf("FIFOs = %7ld, %5.2f %%\n", nfifo, nfifo*100.0/ntot); printf("symbolic links = %7ld, %5.2f %%\n", nslink, nslink*100.0/ntot); printf("sockets = %7ld, %5.2f %%\n", nsock, nsock*100.0/ntot); exit(ret); }
三、实验结果
程序构建
因为我们用到了教材提供的 apue.h,同时也使用了很多声明在其中的函数,而这些函数被定义在了教材下发源代码的 lib 文件夹中。
因此,我们需要先构建 lib 中所有程序的静态链接库。
所幸,教材下发的源代码库中,为我们提供了构建的 Makefile,我们只需要运行 make 即可。
cd apue.3e cd lib make
即可得到链接库文件 libapue.a。

因为下发样例程序的 Makefile 集成化比较高,难以将我们实验的代码直接利用原本的 Makefile,所有我选择使用 gcc 直接构建。
接下来,我们将这个文件复制到我们实验目录下面:
cp ~/apue.3e/lib/libapue.a ~/homework/2/

将我们编写的源代码和 apue.h 放入以后,编译程序。
gcc -o myfind myfind.c libapue.a -std=c99
即可编译成功。

运行
测试准备
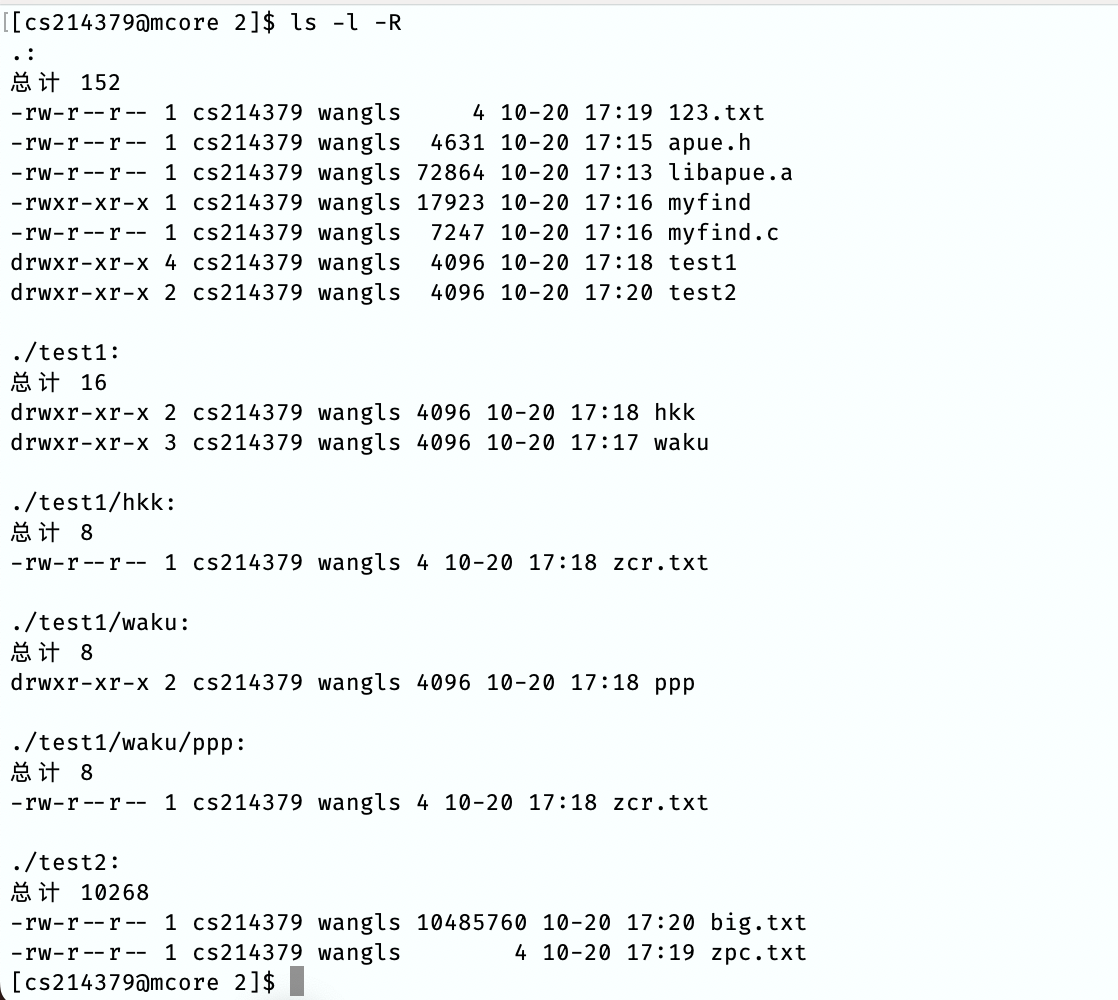
为了进行测试,我建立了几个小文件和一个 10M 的大文件:


得到的目录结构如下图所示:
任务一
首先测试第一个任务:
./myfind .
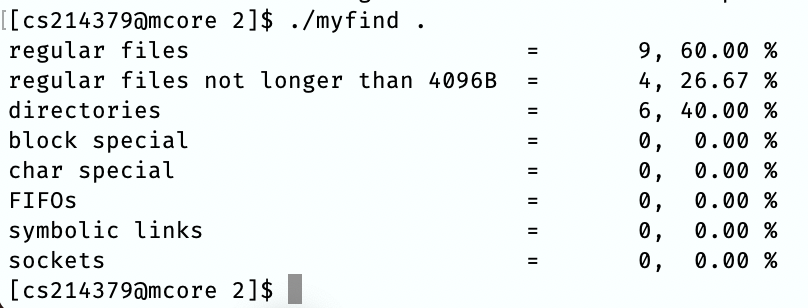
一共有 \(9\) 个常规文件:123.txt,apue.h,libapue.a,myfind,myfind.c,test1/hkk/zcr.txt,test1/waku/ppp/zcr.txt,test2/big.txt,test2/zpc.txt。
一共有 \(6\) 个目录:.,test1,test1/hkk,test1/waku,test1/waku/ppp,test2。
一共有 \(4\) 个不大于 \(4096B\) 的常规文件:test1/waku/ppp/zcr.txt,test1/hkk/zcr.txt,test2/zpc.txt,test2/123.txt。
结果正确。
任务二

根据前面的准备可知,123.txt 的内容是只有一个字符串 "123",而 test1/waku/ppp/zcr.txt 和 test2/zpc.txt 与之相同,其余的文件皆不是。
结果正确。
任务三

根据前面的准备可知,只有 test1/waku/ppp/zcr.txt 和 test1/hkk/zcr.txt 的文件名为 zcr.txt,因此结果正确。
四、实验体会
在这次实验中,我完成了一个目录树遍历以及查找的程序,更深入地理解了文件系统和目录结构。通过实验,我对系统调用和库函数的使用有了更加深刻的认识,特别是在文件和目录的操作方面。
在处理程序参数的过程中,我学到了如何判断参数的合法性并根据参数内容判断需要执行的任务类型。这使我对C语言中命令行参数的处理有了更清晰的认识。
在实现目录树遍历时,我了解了如何递归地访问目录树,并通过遍历函数传递函数指针参数的方式,使程序结构清晰,具有良好的可扩展性。这种设计方式使得程序可以灵活地处理不同类型的文件和目录。
对于文件内容的比较,我选择了逐字节比较的方法。这种方式虽然简单,但确保了文件内容的准确性。在实际应用中,文件内容的比较可能涉及更复杂的算法,但这次实验为我提供了一个基础。
在编写实验报告的过程中,我对整个实验流程进行了详细的总结,包括程序设计、构建、运行和结果分析。这有助于我更好地理解整个实验的目的和过程。
这次实验不仅让我学到了很多关于文件系统和目录操作的知识,也提高了我的编程能力和问题解决的思维方式。通过不断地编写和调试程序,我更加深入地理解了C语言的一些重要概念和技术。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 单元测试从入门到精通
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 上周热点回顾(3.3-3.9)
· winform 绘制太阳,地球,月球 运作规律