CSAPP Lab-8 Proxy lab
终于到最后一个 Lab 啦!
这个 Lab 的任务是实现一个代理服务器,将客户端发送的请求转发到服务端。
这个 Lab 分为三个任务,第一个任务需要实现这个代理服务,第二个任务支持处理并发请求,第三个任务需要实现缓存。
Part I: Implementing a sequential web proxy
这个部分其实很好写,很多部分都可以照抄下发文件中的 tiny 服务器的内容。
main 函数
main 函数完全复制了 tiny 程序的 main。
大概过程就是使用一个 while 循环,不停地等待客户端连接,一旦连接成功,就调用 doit 函数进行处理。
int main(int argc, char **argv)
{
int listenfd, connfd;
char hostname[MAXLINE], port[MAXLINE];
socklen_t clientlen;
struct sockaddr_storage clientaddr;
/* Check command line args */
if (argc != 2) {
fprintf(stderr, "usage: %s <port>\n", argv[0]);
exit(1);
}
listenfd = Open_listenfd(argv[1]);
while (1) {
clientlen = sizeof(clientaddr);
connfd = Accept(listenfd, (SA *)&clientaddr, &clientlen); //line:netp:tiny:accept
Getnameinfo((SA *) &clientaddr, clientlen, hostname, MAXLINE,
port, MAXLINE, 0);
printf("Accepted connection from (%s, %s)\n", hostname, port);
doit(connfd); //line:netp:tiny:doit
Close(connfd); //line:netp:tiny:close
}
}
parseUrl 函数:URL 切分
首先我们在程序中定义了一个 URL 结构体,存放一个 URL 的 host、端口和路径。
typedef struct URL {
char host[MAXLINE];
char port[MAXLINE];
char path[MAXLINE];
} URL;
然后,对于一个传入的 URL 字符串,我们首先忽略掉 http:// 这种协议标识,可以通过查找 // 字符串来实现。
然后,我们找到第一个 / 字符,在这个字符后面的就是路径了。如果找不到这个字符,我们就认为访问的是根路径 /。随后我们将这个字符设置为 '\0',方便之后端口的读取。
然后,我们通过 : 字符来定位端口,: 后面的就是端口,如果找不到 : 那么就认为端口是 80,然后我们将这个字符设置为 '\0'。
最后,剩下的字符串就是 host 了。
void parseUrl(char *s, URL *url) {
char *ptr = strstr(s, "//");
if (ptr != NULL) s = ptr + 2;
ptr = strchr(s, '/');
if (ptr != NULL) {
strcpy(url->path, ptr);
*ptr = '\0';
}
ptr = strchr(s, ':');
if (ptr != NULL) {
strcpy(url->port, ptr + 1);
*ptr = '\0';
} else strcpy(url->port, "80");
strcpy(url->host, s);
}
readClient 函数:从客户端读取请求并生成新请求
readClient 函数会从客户端读取请求的全部内容,并生成即将发送到服务端的新请求。
首先,从第一行读取 URL 扔给 parseUrl 函数提取。
然后,设置默认的 Hosts header 为 URL 中的 host。接着从接下来读取到的 headers 中,如果是 Hosts 那么就更新 Hosts,如果是 User-Agent、Connection 和 Proxy-Connection,那么就忽略(因为我们有我们要设定的专属 header)。其余的 header 收集起来,稍后一并作为新请求发过去。
最后,向新请求字符串中写入我们生成的 HTTP 头和 headers。
void readClient(rio_t *rio, URL *url, char *data) {
char host[MAXLINE];
char line[MAXLINE];
char other[MAXLINE];
char method[MAXLINE], urlstr[MAXLINE], version[MAXLINE];
Rio_readlineb(rio, line, MAXLINE);
sscanf(line, "%s %s %s\n", method, urlstr, version);
parseUrl(urlstr, url);
sprintf(host, "Host: %s\r\n", url->host);
while (Rio_readlineb(rio, line, MAXLINE) > 0) {
if (strcmp(line, "\r\n") == 0) break;
if (strncmp(line, "Host", 4) == 0) strcpy(host, line);
if (strncmp(line, "User-Agent", 10) &&
strncmp(line, "Connection", 10) &&
strncmp(line, "Proxy-Connection", 16)) strcat(other, line);
}
sprintf(data, "%s %s HTTP/1.0\r\n"
"%s%s"
"Connection: close\r\n"
"Proxy-Connection: close\r\n"
"%s\r\n", method, url->path, host, user_agent_hdr, other);
}
doit 函数
doit 函数的功能是处理成功连接的套接字接口。
首先就是调用 readClient 函数处理读入和生成新的请求。
然后调用 open_clientfd 函数连接服务器。
接着,向服务器发送新的请求。
最后,将服务器发送回来的结果读入,发送到客户端套接字。
void doit(int connfd) {
rio_t rio;
char line[MAXLINE];
Rio_readinitb(&rio, connfd);
URL url;
char data[MAXLINE];
readClient(&rio, &url, data);
int serverfd = open_clientfd(url.host, url.port);
if (serverfd < 0) printf("Connection failed!\n");
rio_readinitb(&rio, serverfd);
Rio_writen(serverfd, data, strlen(data));
int len;
while ((len = Rio_readlineb(&rio, line, MAXLINE)) > 0)
Rio_writen(connfd, line, len);
Close(serverfd);
}
测试结果
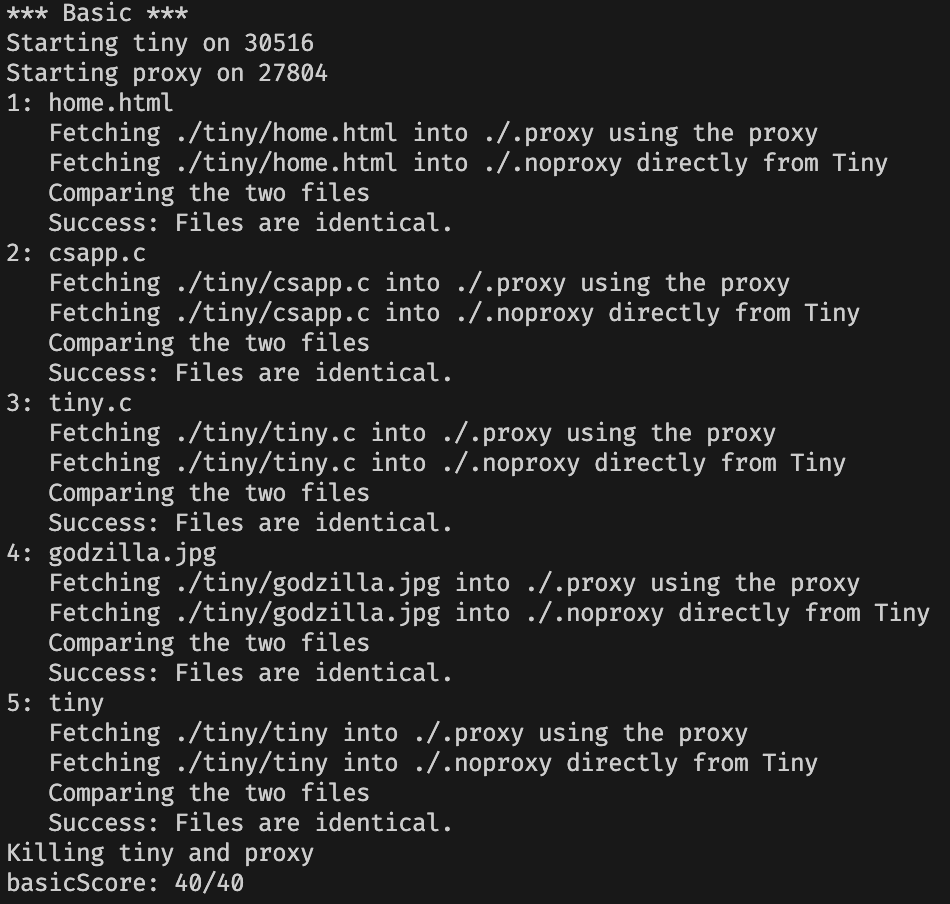
完美通关!
完整代码:链接
Part II: Dealing with multiple concurrent requests
这一部分的任务是实现处理并发请求。
这一部分很简单,课本上讲过怎么处理,只需要将课本上的处理方法搬过来就行了。
课本上使用的是一种预线程化的方法实现的,这里不做讲解了,大家可以看看书上 12.5.4 和 12.5.5 节,分别在 P704 和 P708。
main 函数
没什么区别,就是加入了一个初始化生产者-消费者模型,以及创建 NTHREADS 个线程。还有在循环内部不再是直接执行,而是加入缓冲区。
int main(int argc, char **argv)
{
int listenfd, connfd;
char hostname[MAXLINE], port[MAXLINE];
socklen_t clientlen;
struct sockaddr_storage clientaddr;
pthread_t tid;
/* Check command line args */
if (argc != 2) {
fprintf(stderr, "usage: %s <port>\n", argv[0]);
exit(1);
}
sbuf_init(&sbuf, SBUFSIZE);
for (int i = 0; i < NTHREADS; ++i)
Pthread_create(&tid, NULL, thread, NULL);
listenfd = Open_listenfd(argv[1]);
while (1) {
clientlen = sizeof(clientaddr);
connfd = Accept(listenfd, (SA *)&clientaddr, &clientlen); //line:netp:tiny:accept
Getnameinfo((SA *) &clientaddr, clientlen, hostname, MAXLINE,
port, MAXLINE, 0);
printf("Accepted connection from (%s, %s)\n", hostname, port);
sbuf_insert(&sbuf, connfd);
}
}
线程执行函数
和书上的例子没有区别,每次从缓冲区取出一个套接字以后就执行 doit 函数。
void thread(void *vargp) {
Pthread_detach(pthread_self());
while (1) {
int connfd = sbuf_remove(&sbuf);
doit(connfd);
Close(connfd);
}
}
测试结果
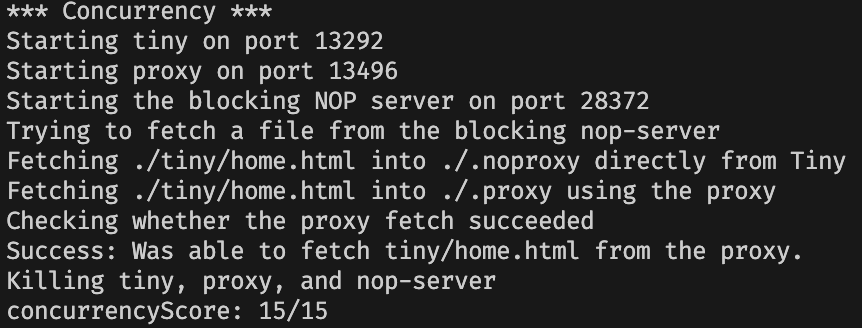
下载完整程序:链接。
Part III: Caching web objects
第三个任务就是实现缓存一些网页对象。
具体地,当我们的代理访问了一个服务器网页的时候,我们需要将这个网页缓存下来,在之后的请求中就不需要再次从服务器那里请求这个网页了。
但是,缓存的大小不是无限的,这就需要我们在缓存使用满的时候驱逐一部分已经缓存的网页出去。本实验要求我们使用 LRU (最近最少使用)的方法,也就是找到上一次访问时间最远的对象替换掉。
读者-写者模型
因为涉及到多个线程对于「缓存」这个公共资源的读写,因此我们往往需要使用互斥的方法来避免出错。
但是,在很多情况中,只是读与写或者写与写之间会发生冲突,读和读之间不会发生冲突,因此完全使用互斥是很浪费时间的。这就需要读者-写者模型了。
读者-写者模型实现了多个读者可以同时读取,但是读写、写写会互斥。在本实验中,我们采用的是读者优先的策略。
int read_cnt;
sem_t mutex, w; // Both initially = 1
void reader(void)
{
while(1){
P(&mutex);
readcnt++;
if(readcnt==1)
P(&w);
V(&mutex);
// reading
P(&mutex);
readcnt--;
if(readcnt==0)
V(&w);
V(&mutex);
}
}
void writer(void)
{
while(1){
P(&w);
// writing
V(&w)
}
}
几个模型相关的函数
为了方便,在本实验中,我们定义了四个函数,处理读者-写者模型的限制。
void readBegin(Cache *c) {
P(&c->mutex);
if (++c->read_cnt == 1) P(&c->w);
V(&c->mutex);
}
void readEnd(Cache *c) {
P(&c->mutex);
if (--c->read_cnt == 0) V(&c->w);
V(&c->mutex);
}
void writeBegin(Cache *c) {
P(&c->w);
}
void writeEnd(Cache *c) {
V(&c->w);
}
缓存结构
typedef struct Cache {
bool empty; // 是否为空
URL url; // 缓存 URL
char data[MAX_OBJECT_SIZE]; // 缓存内容
int lru; // 上次访问时间
int read_cnt;
sem_t mutex, w; // 读者-写者模型相关信号量
} Cache;
Cache ca[MAX_CACHE];
initCache
初始化缓存。没有什么好解释的
void initCache() {
for (int i = 0; i < MAX_CACHE; ++i) {
ca[i].empty = 1;
Sem_init(&ca[i].mutex, 0, 1);
Sem_init(&ca[i].w, 0, 1);
}
}
getCache
寻找 URL 对应的缓存,如果不存在返回 NULL。
具体地,枚举每一个缓存,判断是否为空,如果不为空判断 URL 是否相等。
urlEqual 函数为判断 URL 相同的函数。
如果找到,要顺便更新一下这个缓存的 LRU,即上次访问时间。
Cache *getCache(URL *url) {
Cache *ans = NULL;
for (int i = 0; i < MAX_CACHE && ans == NULL; ++i) {
readBegin(&ca[i]);
if (!ca[i].empty && urlEqual(&ca[i].url, url)) ans = &ca[i];
readEnd(&ca[i]);
}
if (ans != NULL) updateLRU(ans);
return ans;
}
fillCache
将一个 URL 和网页内容装载入缓存。
void fillCache(Cache *c, URL *url, char *data) {
writeBegin(c);
c->empty = 0;
urlCopy(&c->url, url);
strcpy(c->data, data);
writeEnd(c);
updateLRU(c);
}
updateLRU
更新 LRU。
这里使用了一个 static 变量,每次调用都会加 \(1\),因此可以作为时钟使用。
void updateLRU(Cache *c) {
static int clock = 0;
writeBegin(c);
c->lru = ++clock;
writeEnd(c);
}
insCache
将一个 URL 及对应的网页插入缓存。
首先判断是否有空余位置,如果有的话可以直接放入。
否则,遍历所有缓存,找到上次访问时间最远的(lru 成员最小的),将之替换掉。
void insCache(URL *url, char *data) {
Cache *pos = NULL;
for (int i = 0; i < MAX_CACHE && pos == NULL; ++i) {
readBegin(&ca[i]);
if (ca[i].empty) pos = &ca[i];
readEnd(&ca[i]);
}
// fprintf(stderr, "insCache: pos = %#p\n", pos);
if (pos != NULL) {
fillCache(pos, url, data);
return;
}
int minLRU = __INT_MAX__;
for (int i = 0; i < MAX_CACHE; ++i) {
readBegin(&ca[i]);
if (!ca[i].empty && ca[i].lru < minLRU) {
minLRU = ca[i].lru;
pos = &ca[i];
}
readEnd(&ca[i]);
}
fillCache(pos, url, data);
}
测试结果
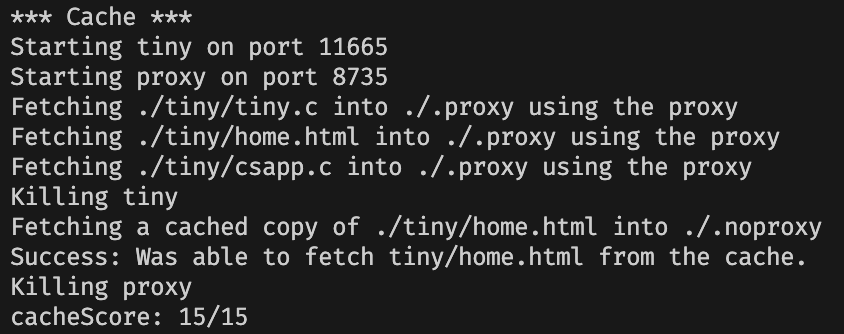
完整程序:链接
总结
先放一下最终得分:
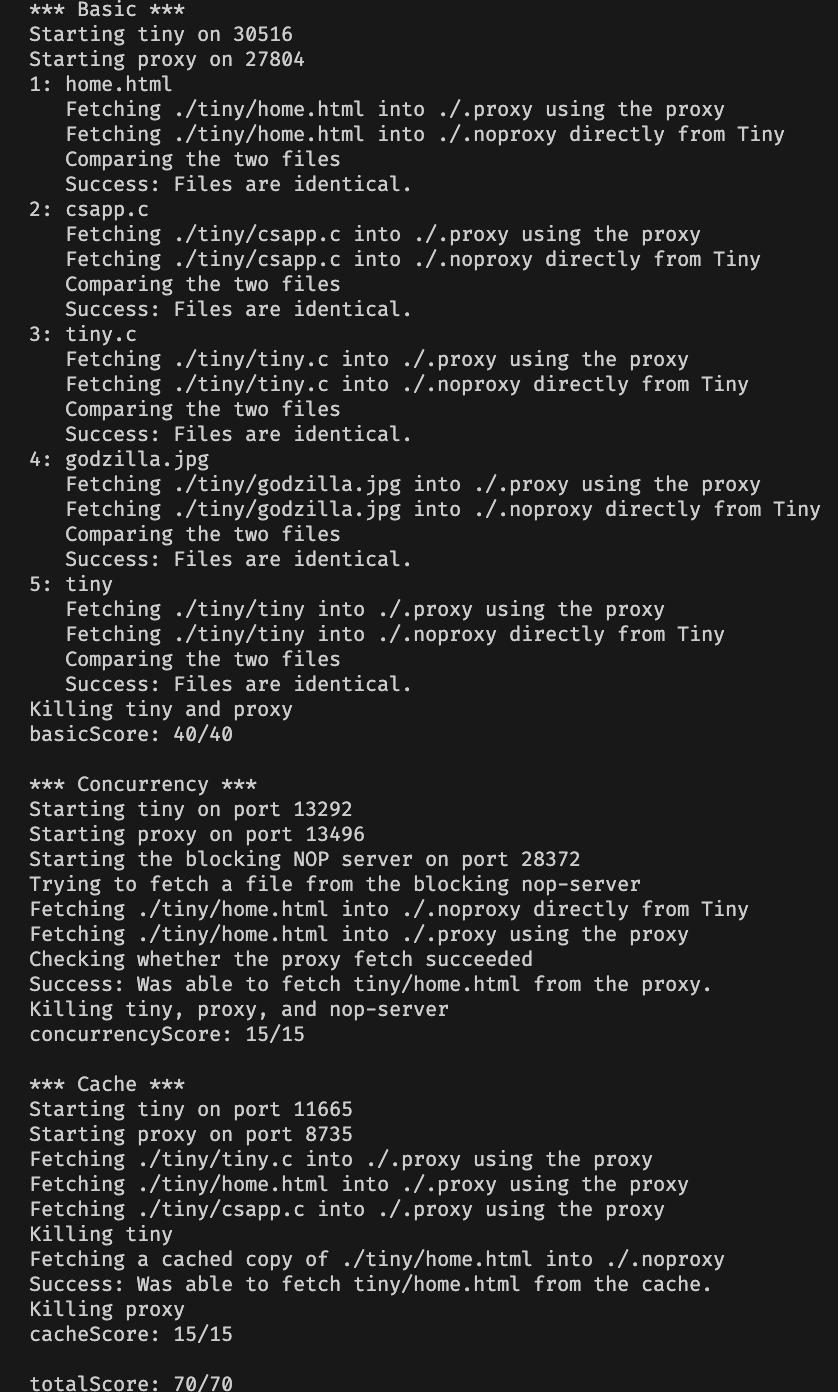
嘿嘿,终于做完 CSAPP 的所有实验啦!
收获很多,这本书算是我真正的计算机启蒙教材吧。
接下来准备去看一些操作系统方向的书籍,希望能找到适合自己的学习方向!

