CSAPP Lab-4 Architecture Lab
本次实验是有关书上第四章设计的 Y86-64 处理器的,实验分为三个部分,分别是编写几个简单的 Y86-64 程序、使用一条新指令扩展 SEQ 模拟器以及优化 Y86-64 的基准测试程序和处理器设计。
实验准备
需要简单复习一下 Y86-64 的指令集架构以及处理器架构呢。
指令集架构
指令集:

指令功能码:
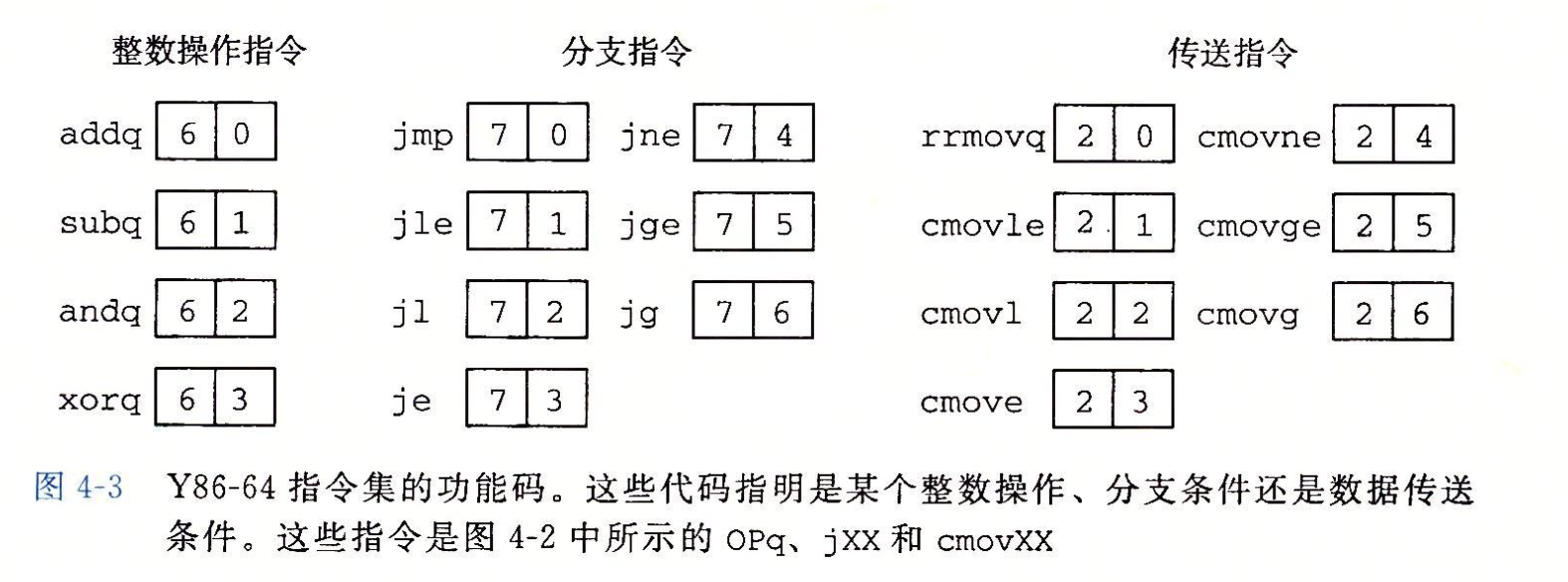
程序员可见状态:
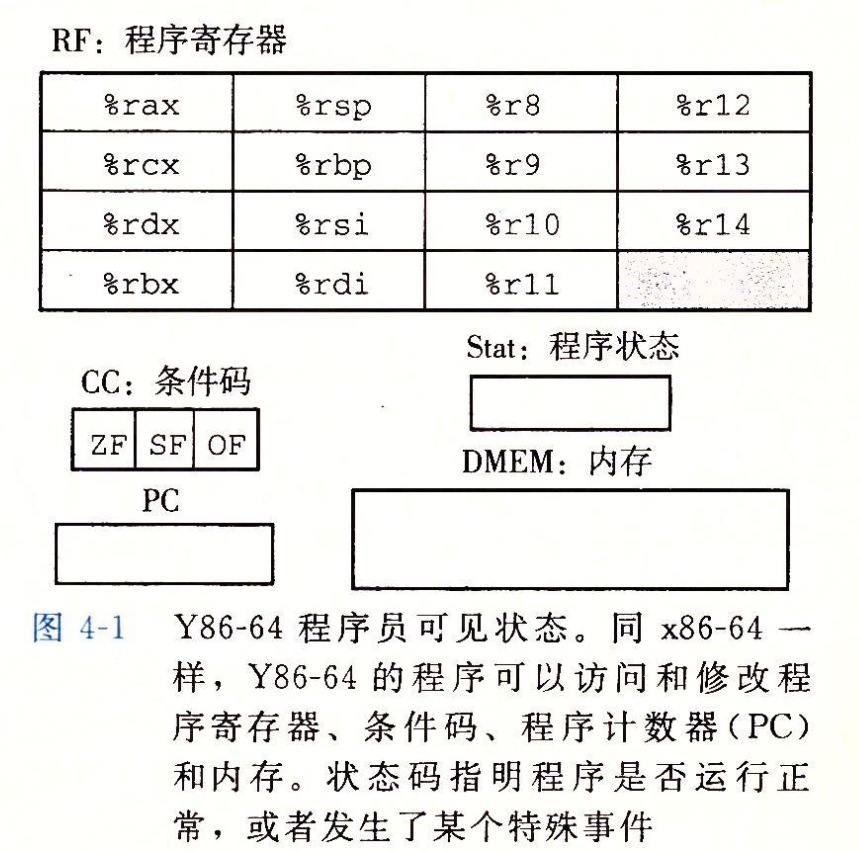
以及,书上这一章似乎没有提到,但是根据上一章的内容,我们一般将 %rdi, %rsi, %rdx, %rcx 用作参数的传递,而 %rbx, %rbp, %r12~%r15 是被调用者保存寄存器,被调用的函数有义务在使用之前保存寄存器的内容。
处理器架构
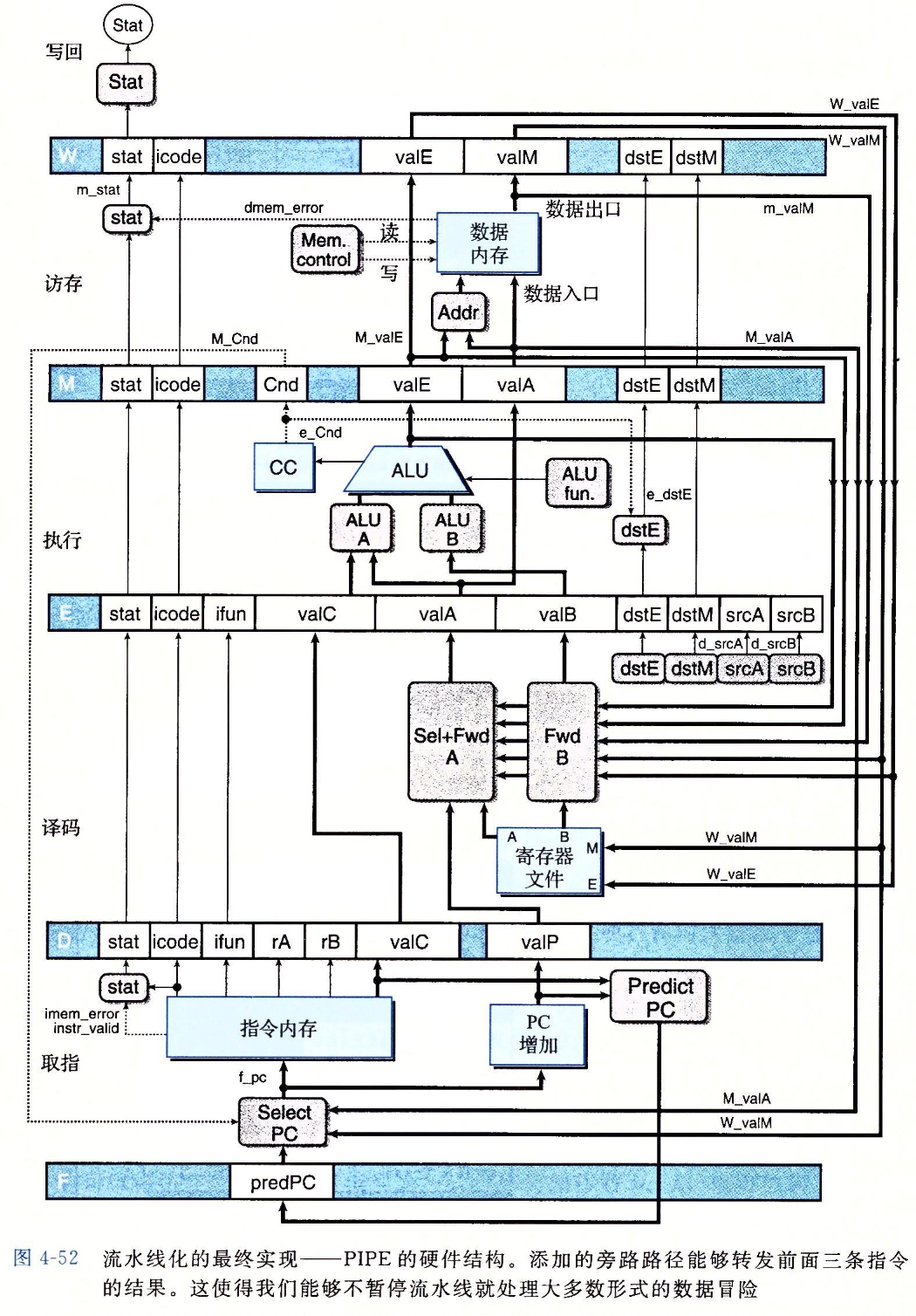
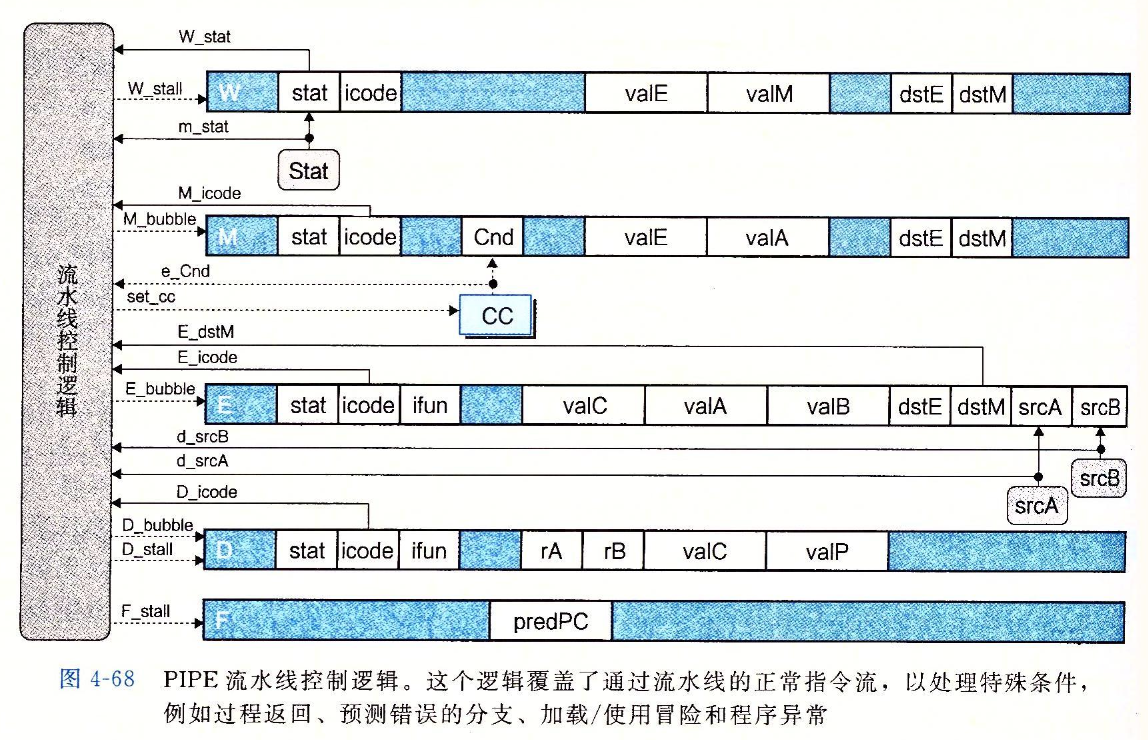
这两张图是 PIPE 的硬件结构和流水线控制逻辑,当然并不完整。在我们需要的时候,我们会补充相应的示意图。
Y86-64 的程序结构
书本给我们提供了一个典型的 Y86-64 汇编程序,这将是我们完成 Part A 的参考。

其中,程序从 0x0 开始执行,首先将栈地址(在程序的末尾标识出来)放入 %rsp 寄存器,然后调用 main 函数,main 函数运行结束后终止程序。下面是预定义的全局数据,然后就是各个函数过程。
Part A
Part A 需要我们写三个 Y86-64 的程序,每个程序分别完成了三个函数,并发起对这些函数的调用。
这个 Part 不是很难,只需要根据汇编程序的书写语法、分支循环的转化方法以及 Y86-64 指令集的一些约束来写就可以了。
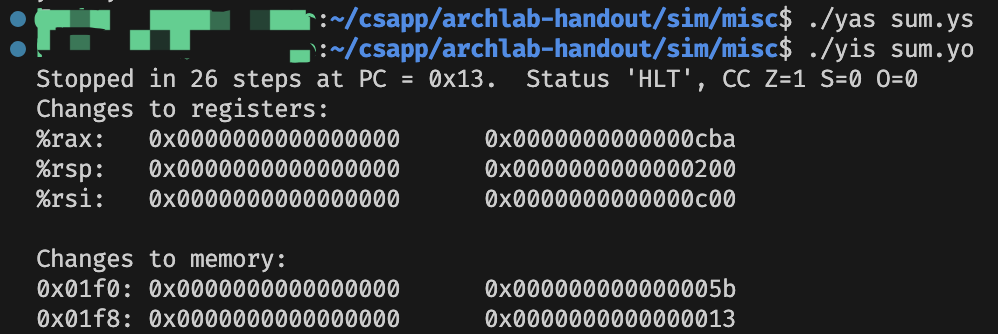
sum.ys: Iteratively sum linked list elements
要被我们转译的函数如下:
/* sum_list - Sum the elements of a linked list */
long sum_list(list_ptr ls)
{
long val = 0;
while (ls) {
val += ls->val;
ls = ls->next;
}
return val;
}
这个程序是对一个链表的迭代求和。实验给我们提供了一组示例数据:
# Sample linked list
.align 8
ele1:
.quad 0x00a
.quad ele2
ele2:
.quad 0x0b0
.quad ele3
ele3:
.quad 0xc00
.quad 0
这个部分很简单,我的程序是:
# sum_list - Sum the elements of a linked list
# by Irilsy
# Execution begins at address 0
.pos 0
irmovq stack, %rsp # Set up stack pointer
call main # Execute main program
halt # Terminate program
# Sample linked list
.align 8
ele1:
.quad 0x00a
.quad ele2
ele2:
.quad 0x0b0
.quad ele3
ele3:
.quad 0xc00
.quad 0
main:
irmovq ele1, %rdi
call sum_list
ret
sum_list:
xorq %rax, %rax
jmp test
loop:
mrmovq (%rdi), %rsi
addq %rsi, %rax
mrmovq 8(%rdi), %rdi
test:
andq %rdi, %rdi
jne loop
ret
# Stack starts here and grows to lower addresses
.pos 0x200
stack:
在 main 函数中,我们示例数据的地址放入 %rdi,然后调用 sum_list 函数。
在 sum_list 函数中,我们用 %rax 代表 val,第一句指令将 val 清空。while 循环我们使用跳转到中间的方法实现,直接 jmp 到条件判断的位置。在循环内部,我们仍旧使用 %rdi 代表 ls 指针,(%rdi) 就是 ls->val,8(%rdi) 就是 ls->next。循环体的三句话按照含义模拟即可。在条件判断的地方,我们使用 andq 作为与 \(0\) 的比较。
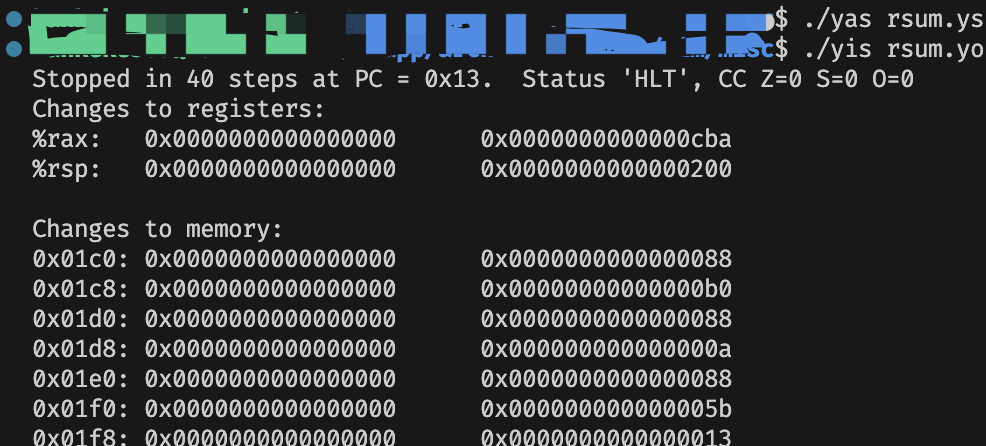
rsum.ys: Recursively sum linked list elements
这次要被我们转写的函数是:
/* rsum_list - Recursive version of sum_list */
long rsum_list(list_ptr ls)
{
if (!ls)
return 0;
else {
long val = ls->val;
long rest = rsum_list(ls->next);
return val + rest;
}
}
示例数据与前一个程序相同。这个版本是递归版的 sum_list,使用递归的方法对一个链表求和。
也很容易,按照含义模拟即可:
# rsum_list - Sum the elements of a linked list
# by Irilsy
# Execution begins at address 0
.pos 0
irmovq stack, %rsp # Set up stack pointer
call main # Execute main program
halt # Terminate program
# Sample linked list
.align 8
ele1:
.quad 0x00a
.quad ele2
ele2:
.quad 0x0b0
.quad ele3
ele3:
.quad 0xc00
.quad 0
main:
irmovq ele1, %rdi
call rsum_list
ret
rsum_list:
xorq %rax, %rax
andq %rdi, %rdi
je end
pushq %rbx
mrmovq (%rdi), %rbx
mrmovq 8(%rdi), %rdi
call rsum_list
addq %rbx, %rax
popq %rbx
end:
ret
# Stack starts here and grows to lower addresses
.pos 0x200
stack:
与 sum.ys 基本一致,区别在于 rsum_list 函数的写法。仍然使用 %rax 代表 val。在函数的开头就把 %rax 清零,方便下一句的判断中如果 ls 指针为空可以直接返回。
然后,我们从内存中取出 (%rdi)(ls->val),但是需要递归调用,这个时候有两种处理方法,第一种是不把这个数据留在寄存器中,而是存储在内存里,在递归调用结束后再取出。还有一种是使用被调用者保存的寄存器 %rbx,在使用之前将 %rbx 的内容保存进栈中,然后将我们取出的数据放进 %rbx,在调用前不用特别保存,因为任何函数在使用这个寄存器前都会保存的。我是用的是第二种方法。
在调用结束后,我们将返回值和 %rbx 中的 ls->val 加起来返回即可。
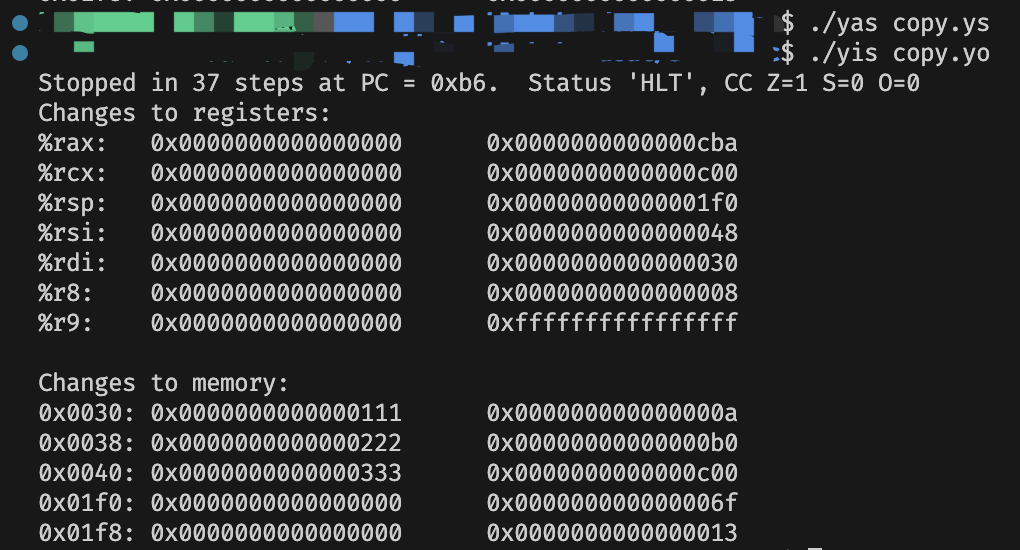
copy.ys: Copy a source block to a destination block
这次要我们转译的函数是下面这个:
/* copy_block - Copy src to dest and return xor checksum of src */
long copy_block(long *src, long *dest, long len)
{
long result = 0;
while (len > 0) {
long val = *src++;
*dest++ = val;
result ^= val;
len--;
}
return result;
}
这个函数的功能是将从 src 开始的 len 个 long 型数据复制到 dest 处,并返回它们的异或和。
实验提供的示例数据是:
# Source block
src:
.quad 0x00a
.quad 0x0b0
.quad 0xc00
# Destination block
dest:
.quad 0x111
.quad 0x222
.quad 0x333
我的写法如下:
# copy_block - Sum the elements of a linked list
# by Irilsy
# Execution begins at address 0
.pos 0
irmovq stack, %rsp # Set up stack pointer
call main # Execute main program
halt # Terminate program
.align 8
# Source block
src:
.quad 0x00a
.quad 0x0b0
.quad 0xc00
# Destination block
dest:
.quad 0x111
.quad 0x222
.quad 0x333
main:
irmovq src, %rdi
irmovq dest, %rsi
irmovq $3, %rdx
call copy_block
ret
copy_block:
xorq %rax, %rax
irmovq $8, %r8
irmovq $-1, %r9
jmp test
loop:
mrmovq (%rdi), %rcx
addq %r8, %rdi
rmmovq %rcx, (%rsi)
addq %r8, %rsi
xorq %rcx, %rax
addq %r9, %rdx
test:
andq %rdx, %rdx
jg loop
# Stack starts here and grows to lower addresses
.pos 0x200
stack:
首先是 main 函数中,src, dest, $3 分别作为 %rdi, %rsi, %rdx 传入 copy_block 函数,也就是前三个参数。
copy_block 函数中,我们使用 %rax 代表 result,val 中间变量存储在 %rcx 中。具体的代码按照含义模拟即可。需要注意的是,因为 Y86-64 指令集不支持使用立即数作为 OPq 运算操作的参数,因此我们使用 %r8 存储 \(8\) 这个值,%r9 存储 \(-1\) 这个值。
Part B
Part B 的任务看上去也不算复杂,就是实现 iaddq 指令,将立即数与寄存器相加。
这个任务可以结合书上 SEQ 结构的设计过程,一边翻书一边完成,不算太难。
首先,我们仿照下图的格式,也为 iaddq 指令做一个表格。
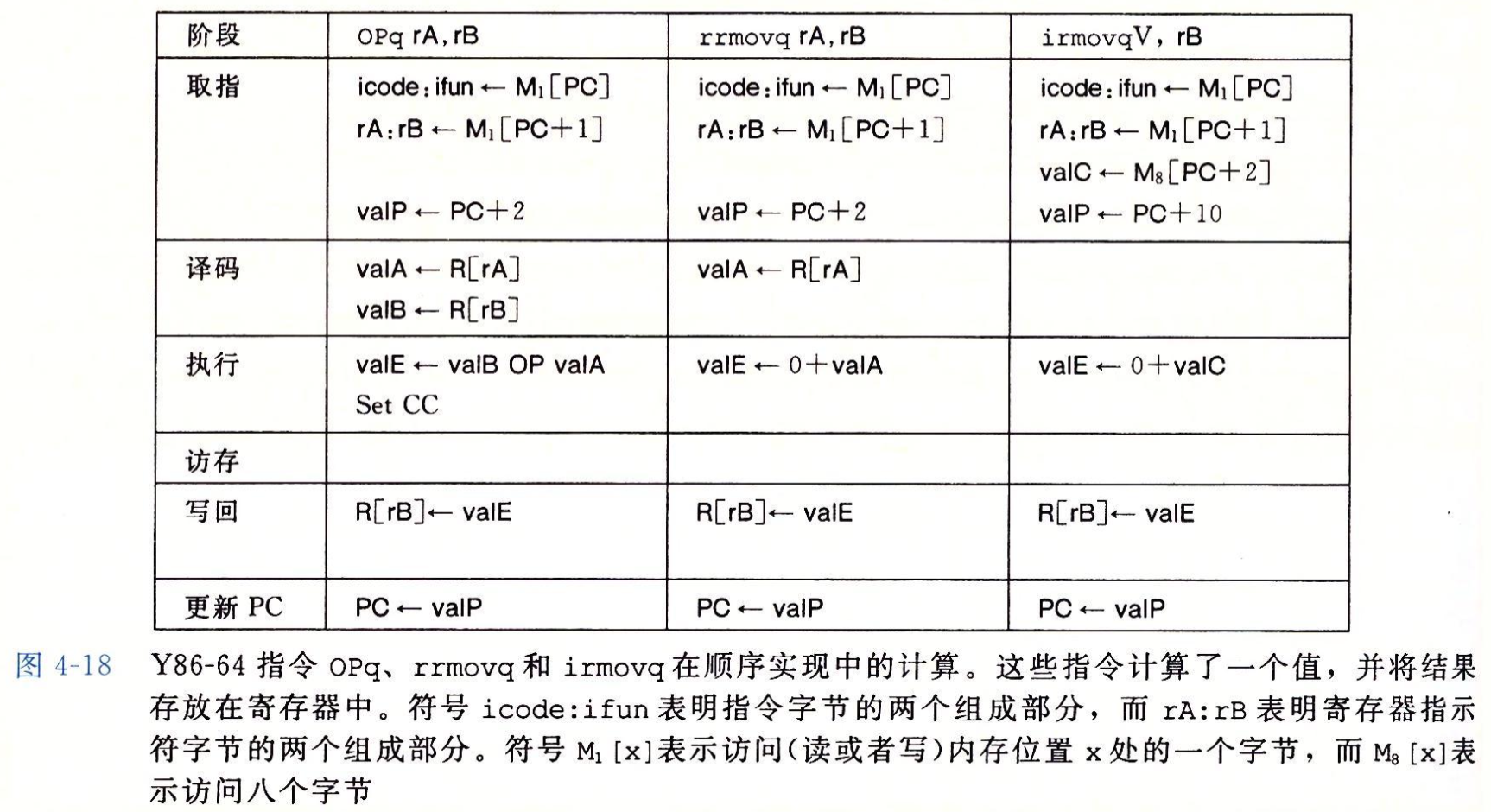
| 阶段 | iaddq V, rB |
|---|---|
| 取指 | Icde: ifun ← M1[PC] rA:rB ← M1[PC + 1] valC ← M8[PC + 2] valP ← PC + 10 |
| 译码 | valB ← R[rB] |
| 执行 | valE ← valB + valA Set CC |
| 访存 | |
| 写回 | R[rB] ← valE |
| 更新 PC | PC ← valP |
然后我们来一个个看每个阶段有哪些信号需要修改。
取指阶段
取指阶段涉及的 HCL 信号如下:
| 信号 | 含义 |
|---|---|
icode, ifun |
指令码和功能码 |
instr_valid |
指令是否合法 |
need_regids |
指令是否需要寄存器指示符字节 |
need_valC |
指令是否包含立即数 |
最后的三个信号都需要修改,修改如下:
bool instr_valid = icode in
{ INOP, IHALT, IRRMOVQ, IIRMOVQ, IRMMOVQ, IMRMOVQ,
IOPQ, IJXX, ICALL, IRET, IPUSHQ, IPOPQ, IIADDQ };
bool need_regids =
icode in { IRRMOVQ, IOPQ, IPUSHQ, IPOPQ,
IIRMOVQ, IRMMOVQ, IMRMOVQ, IIADDQ };
bool need_valC =
icode in { IIRMOVQ, IRMMOVQ, IMRMOVQ, IJXX, ICALL, IIADDQ };
译码阶段和写回阶段
| 信号 | 含义 |
|---|---|
srcA, srcB |
产生值 valA, valB 的寄存器 |
dstE |
计算结果需要作为目的写入的寄存器 |
dstM |
从内存中读取的值需要作为目的写入的寄存器 |
本阶段需要修改的是 srcB 和 dstE。
word srcB = [
icode in { IOPQ, IRMMOVQ, IMRMOVQ, IIADDQ } : rB;
icode in { IPUSHQ, IPOPQ, ICALL, IRET } : RRSP;
1 : RNONE; # Don't need register
];
word dstE = [
icode in { IRRMOVQ } && Cnd : rB;
icode in { IIRMOVQ, IOPQ, IIADDQ } : rB;
icode in { IPUSHQ, IPOPQ, ICALL, IRET } : RRSP;
1 : RNONE; # Don't write any register
];
执行阶段
| 信号 | 含义 |
|---|---|
aluA, aluB |
ALU 的两个输入 |
alufun |
ALU 需要执行的功能 |
set_cc |
是否更新条件码 |
除了 alufun 都需要修改。
word aluA = [
icode in { IRRMOVQ, IOPQ } : valA;
icode in { IIRMOVQ, IRMMOVQ, IMRMOVQ, IIADDQ } : valC;
icode in { ICALL, IPUSHQ } : -8;
icode in { IRET, IPOPQ } : 8;
# Other instructions don't need ALU
];
word aluB = [
icode in { IRMMOVQ, IMRMOVQ, IOPQ, ICALL,
IPUSHQ, IRET, IPOPQ, IIADDQ } : valB;
icode in { IRRMOVQ, IIRMOVQ } : 0;
# Other instructions don't need ALU
];
bool set_cc = icode in { IOPQ, IIADDQ };
访存阶段
| 信号 | 含义 |
|---|---|
mem_read |
是否从内存中读取 |
mem_write |
是否向内存中写入 |
mem_addr |
设置内存地址 |
mem_data |
向内存写入的数据 |
Stat |
状态码 |
不需要更新。
更新 PC 阶段
| 信号 | 含义 |
|---|---|
new_pc |
新的 PC 地址 |
不需要更新。
构建和测试
按照实验的文档,我们在终端运行下面的命令构建我们的 SEQ 模拟器。
make VERSION=full
这时我们可能会遇到一个问题,提示 <tk.h> 头文件不存在。
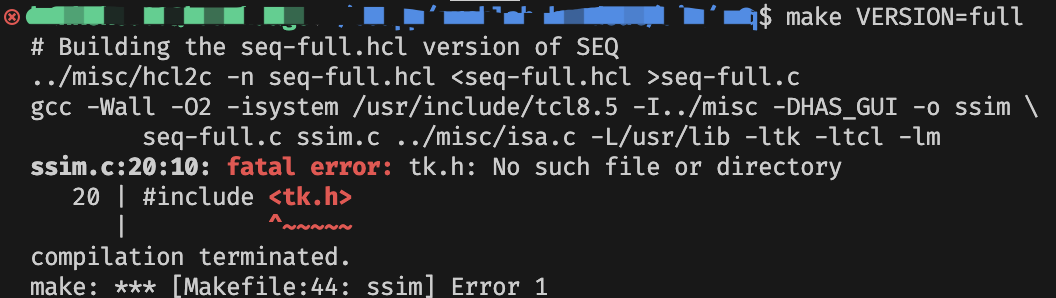
必须要在这个文件夹下的 Makefile 文件中找到这三行注释掉即可。
GUIMODE=-DHAS_GUI
TKLIBS=-L/usr/lib -ltk -ltcl
TKINC=-isystem /usr/include/tcl8.5
编译成功后执行 ./ssim -t ../y86-code/asumi.yo 进行 ISA 测试:
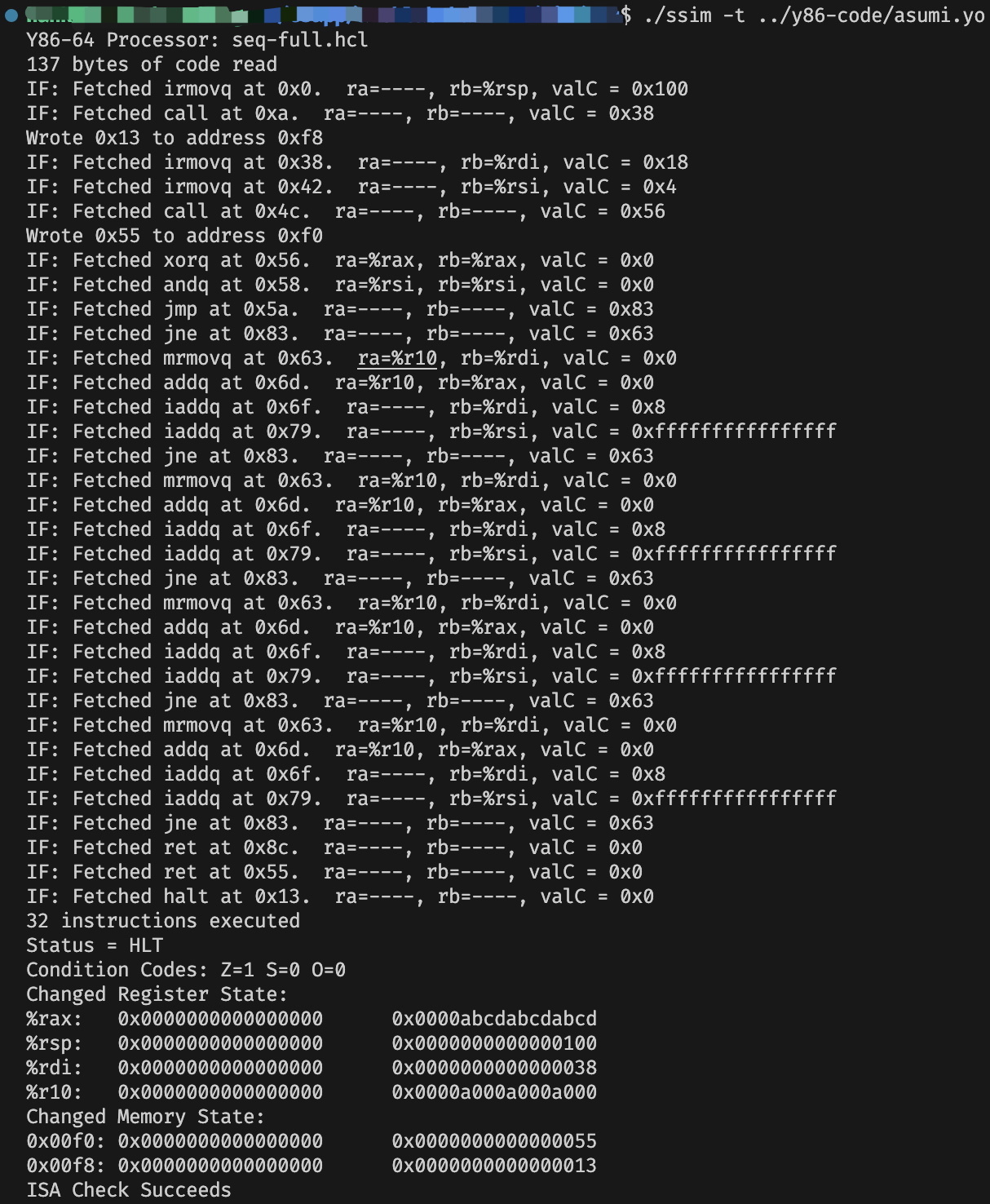
测试成功!
接下来再使用基准程序进行测试:(cd ../y86-code; make testssim)
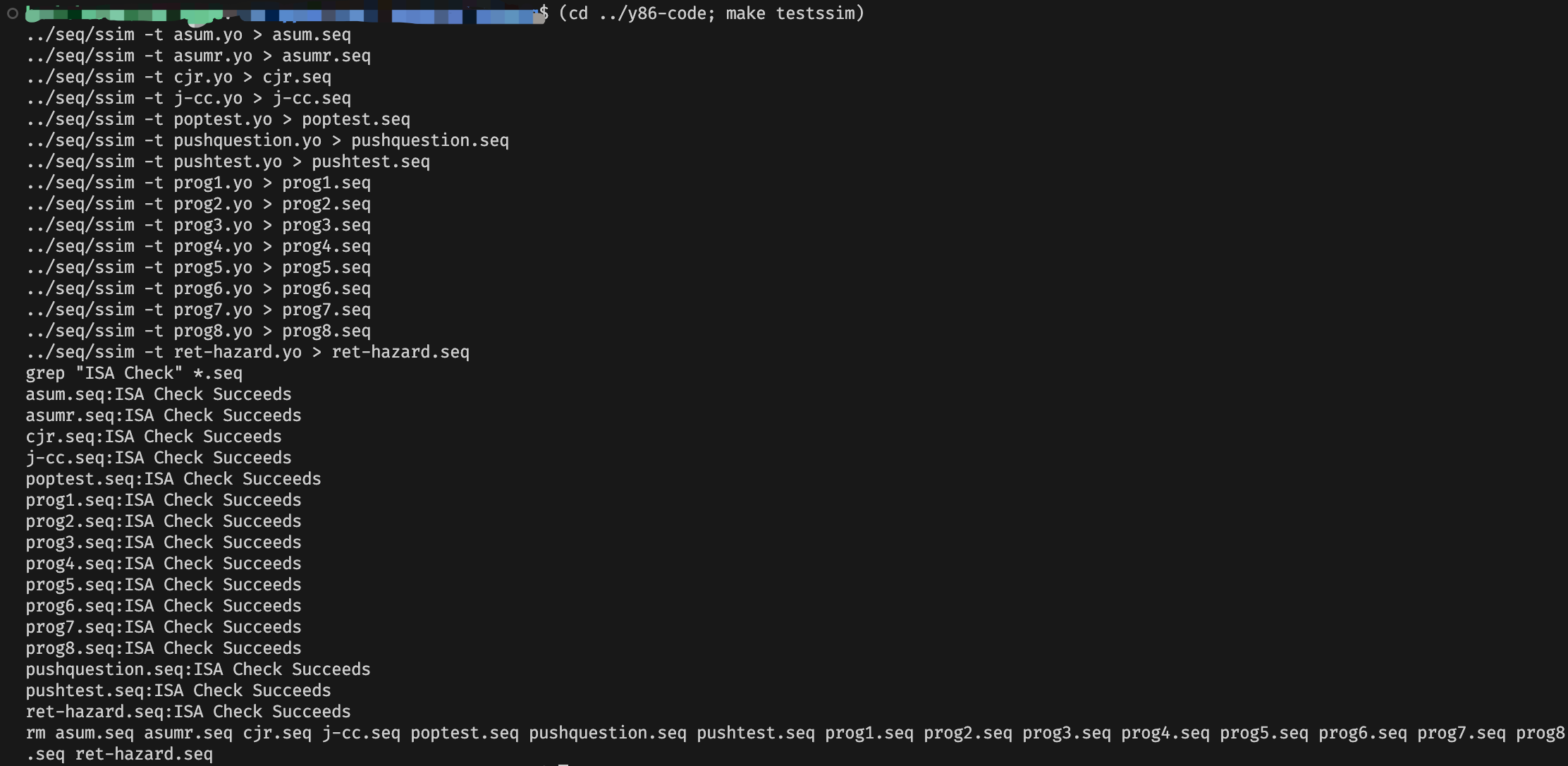
全部成功!
最后是回归测试,运行下面的命令测试除了 iaddq 的所有指令:(cd ../ptest; make SIM=../seq/ssim)。
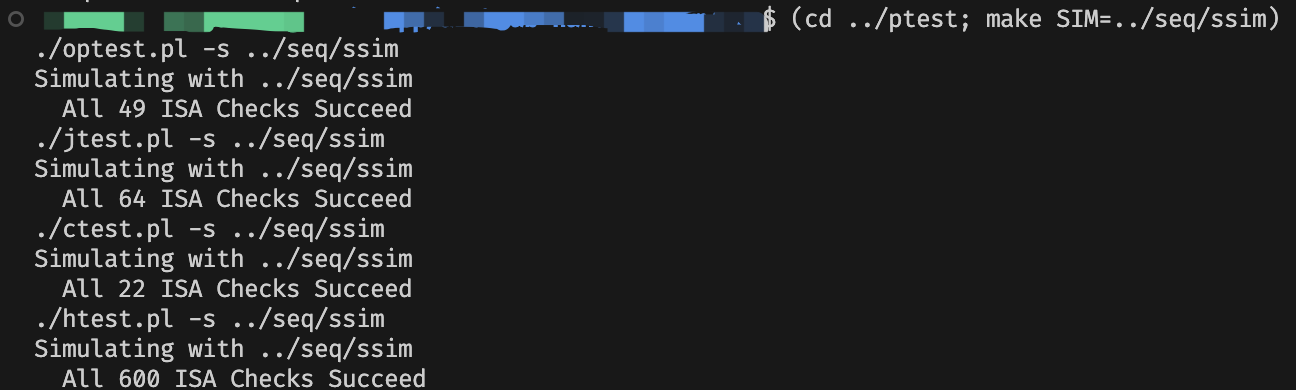
运行下面的命令测试 iaddq 指令:(cd ../ptest; make SIM=../seq/ssim TFLAGS=-i)。
测试通关!
Part C
在这个部分中,实验给我们提供了一个 PIPE 结构的 HCL 实现 pipe-full.hcl,以及一个 Y86-64 程序 ncopy.ys。ncopy.ys 完成了和 Part A 中 copy.ys 类似的功能,不过返回的不是异或和,而是正数的个数。
这个任务的得分是用程序的 CPE 衡量的,如果拷贝 \(N\) 个元素需要 \(C\) 个时钟周期,那么这个程序的 CPE 就是 \(\frac CN\),也就是每元素周期数。如果 CPE 为 \(c\),那么这个部分的得分就是:
也就是说,只有让 CPE 小于 \(7.5\) 才能得到满分!
首先记录一下在什么修改也没有做的情况下,我们的 CPE 和得分:
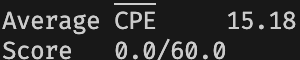
使用 iaddq
原始程序中所有的加法运算都是先将立即数存储到一个寄存器中,然后进行寄存器的加法的。如果我们添加一个 iaddq 指令实现立即数与寄存器相加,那么可以减少一定的操作代价吧。
(不得不说,原始程序在每个循环内部才将立即数存储进寄存器挺傻的……在循环外部预处理以下也不至于那么慢)
pipe-full.hcl 文件修改的方法与 Part B 的部分很类似,这里不再赘述。
修改后的程序如下:
# %rdi = src, %rsi = dst, %rdx = len
ncopy:
xorq %rax,%rax # count = 0;
andq %rdx,%rdx # len <= 0?
jle Done # if so, goto Done:
Loop: mrmovq (%rdi), %r10 # read val from src...
rmmovq %r10, (%rsi) # ...and store it to dst
andq %r10, %r10 # val <= 0?
jle Npos # if so, goto Npos:
iaddq $1, %rax # count++
Npos:
iaddq $-1, %rdx # len--
iaddq $8, %rdi # src++
iaddq $8, %rsi # dst++
andq %rdx,%rdx # len > 0?
jg Loop # if so, goto Loop:
Done:
ret
修改后的 CPE:

还是零分,但是进步不小!
循环展开
循环展开可以减少索引改变的次数,提升计算效率。
我采用了 \(8\) 路循环展开。先写出循环展开的 C 程序版本。
word_t ncopy(word_t *src, word_t *dst, word_t len)
{
word_t count = 0;
word_t val;
while (len >= 8) {
val = *src, *dst = val;
if (val > 0) count++;
val = *(src + 1), *(dst + 1) = val;
if (val > 0) count++;
val = *(src + 2), *(dst + 2) = val;
if (val > 0) count++;
val = *(src + 3), *(dst + 3) = val;
if (val > 0) count++;
val = *(src + 4), *(dst + 4) = val;
if (val > 0) count++;
val = *(src + 5), *(dst + 5) = val;
if (val > 0) count++;
val = *(src + 6), *(dst + 6) = val;
if (val > 0) count++;
val = *(src + 7), *(dst + 7) = val;
if (val > 0) count++;
len -= 8, src += 8, dst += 8;
}
while (len) {
val = *src++, *dst++ = val;
if (val > 0) count++;
}
return count;
}
转写为汇编程序:
ncopy:
xorq %rax,%rax # count = 0;
jmp Npos
Loop0:
mrmovq (%rdi), %r10 # read val from src...
rmmovq %r10, (%rsi) # ...and store it to dst
andq %r10, %r10 # val <= 0?
jle Loop1 # if so, goto Npos:
iaddq $1, %rax # count++
Loop1:
mrmovq 8(%rdi), %r10 # read val from src...
rmmovq %r10, 8(%rsi) # ...and store it to dst
andq %r10, %r10 # val <= 0?
jle Loop2 # if so, goto Npos:
iaddq $1, %rax # count++
Loop2:
mrmovq 16(%rdi), %r10 # read val from src...
rmmovq %r10, 16(%rsi) # ...and store it to dst
andq %r10, %r10 # val <= 0?
jle Loop3 # if so, goto Npos:
iaddq $1, %rax # count++
Loop3:
mrmovq 24(%rdi), %r10 # read val from src...
rmmovq %r10, 24(%rsi) # ...and store it to dst
andq %r10, %r10 # val <= 0?
jle Loop4 # if so, goto Npos:
iaddq $1, %rax # count++
Loop4:
mrmovq 32(%rdi), %r10 # read val from src...
rmmovq %r10, 32(%rsi) # ...and store it to dst
andq %r10, %r10 # val <= 0?
jle Loop5 # if so, goto Npos:
iaddq $1, %rax # count++
Loop5:
mrmovq 40(%rdi), %r10 # read val from src...
rmmovq %r10, 40(%rsi) # ...and store it to dst
andq %r10, %r10 # val <= 0?
jle Loop6 # if so, goto Npos:
iaddq $1, %rax # count++
Loop6:
mrmovq 48(%rdi), %r10 # read val from src...
rmmovq %r10, 48(%rsi) # ...and store it to dst
andq %r10, %r10 # val <= 0?
jle Loop7 # if so, goto Npos:
iaddq $1, %rax # count++
Loop7:
mrmovq 56(%rdi), %r10 # read val from src...
rmmovq %r10, 56(%rsi) # ...and store it to dst
iaddq $64, %rdi # src += 8
iaddq $64, %rsi # dst += 8
andq %r10, %r10 # val <= 0?
jle Npos # if so, goto Npos:
iaddq $1, %rax # count++
Npos:
iaddq $-8, %rdx # len -= 8
jge Loop0 # if so, goto Loop:
iaddq $8, %rdx
jle Done
Small:
mrmovq (%rdi), %r10 # read val from src...
rmmovq %r10, (%rsi) # ...and store it to dst
andq %r10, %r10 # val <= 0?
jle Test # if so, goto Npos:
iaddq $1, %rax # count++\
Test:
iaddq $8, %rdi
iaddq $8, %rsi
iaddq $-1, %rdx
jg Small
Done:
ret
成功把 CPE 降低到了 \(9.30\)!
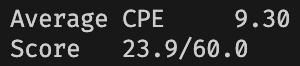
避免加载/使用冒险
注意到下面这样的语句会引起加载/使用冒险,导致一定会引起一个气泡。
mrmovq (%rdi), %r10 # read val from src...
rmmovq %r10, (%rsi) # ...and store it to dst
我们可以将两次从内存中读取和两次向内存写入分别合并起来,以此来避免这样的冒险。
mrmovq (%rdi), %r10
mrmovq 8(%rdi), %r11
rmmovq %r10, (%rsi)
rmmovq %r11, 8(%rsi)
这一步的成果非常显著,我们的 CPE 一下子降低到了 \(8.52\)。
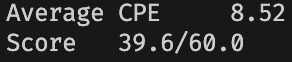
再补一个循环展开
注意到我们上一个版本的循环展开中,因为对于剩余的数据没有进行循环展开,导致这个剩余数据的处理中,依然存在加载/使用冲突。我们在这个版本中,将剩余的数据也进行了循环展开,以及消除气泡。
Npos:
iaddq $-8, %rdx # len -= 8
jge Loop0 # if so, goto Loop:
iaddq $8, %rdx
jmp Test
L2_1:
mrmovq (%rdi), %r10 # read val from src...
mrmovq 8(%rdi), %r11 # read val from src...
rmmovq %r10, (%rsi) # ...and store it to dst
rmmovq %r11, 8(%rsi) # ...and store it to dst
andq %r10, %r10 # val <= 0?
jle L2_2 # if so, goto Npos:
iaddq $1, %rax # count++
L2_2:
iaddq $16, %rdi
iaddq $16, %rsi
andq %r11, %r11 # val <= 0?
jle Test # if so, goto Npos:
iaddq $1, %rax # count++
Test:
iaddq $-2, %rdx
jge L2_1
iaddq $2, %rdx
jle Done
mrmovq (%rdi), %r10 # read val from src...
rmmovq %r10, (%rsi) # ...and store it to dst
andq %r10, %r10 # val <= 0?
jle Done # if so, goto Npos:
iaddq $1, %rax # count++
效果依然十分显著,CPE 降低到 \(8.08\),得分提升到 \(48.3\)。

其它优化
将开头的 xorq %rax, %rax 删去,因为程序运行时 %rax 自动被初始化为 \(0\) 了。但是这个优化不具备普适性,只能在这个程序中使用。
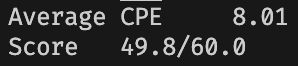
提升并不显著,只有 \(1\) 分左右。
另外,还有一种优化的方法是将循环展开剩余的部分全部展开写出,使用二分查找的方式定位到展开的代码中。这种方法我尝试过,但是不知道为什么实现的效果并不好。还是等以后有空再尝试继续优化这个方面吧!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号