
Prometheus 搭建监控系统
安装准备
这里我的服务器IP是192.168.125.156,登入,建立相应文件夹
mkdir -p /data2/promethues/promethues mkdir -p /data2/promethues/promethues/server mkdir -p /data2/promethues/promethues/client touch /data2/promethues/promethues/server/rules.yml chmod 777 /home/chenqionghe/promethues/server/rules.yml
下面开始三大套件的学习
安装Prometheus Server
通过docker方式
首先创建一个配置文件/data2/promethues/test/prometheus.yml
挂载之前需要改变文件权限为777,要不会引起修改宿主机上的文件内容不同步的问题
global: scrape_interval: 60s # 默认抓取间隔,15秒向目标抓取一次数据。 evaluation_interval: 60s rule_files: - /etc/prometheus/rules.yml scrape_configs: - job_name: prometheus static_configs: - targets: ['192.168.125.156:9090'] labels: instance: prometheus
运行
docker run --name=prometheus -d \ -p 9090:9090 \ -v /data2/promethues/test/prometheus.yml:/etc/prometheus/prometheus.yml \ -v /data2/promethues/server/rules.yml:/etc/prometheus/rules.yml \ prom/prometheus --config.file=/etc/prometheus/prometheus.yml
访问http://192.168.125.156:9090
我们会看到如下界面
访问http://192.168.125.156:9090/metrics
我们配置了9090端口,默认prometheus会抓取自己的/metrics接口
在Graph选项已经可以看到监控的数据

二.安装客户端提供metrics接口
通过node exporter提供metrics
docker run -d \ --name=node-exporter \ -p 9100:9100 \ prom/node-exporter
然后把这两些接口再次配置到prometheus.yml, 重新载入配置
global:
scrape_interval: 60s
evaluation_interval: 60s
rule_files:
- /etc/prometheus/rules.yml
scrape_configs:
- job_name: prometheus
static_configs:
- targets: ['192.168.125.156:9090']
labels:
instance: prometheus
- targets: ['192.168.125.156:9100']
labels:
group: 'client-node-exporter'
可以看到接口都生效了

三.配置告警规则
vi /data2/promethues/server/rules.yml
groups: - name: example rules: # Alert for any instance that is unreachable for >5 minutes. - alert: InstanceDown expr: up == 0 for: 5m labels: severity: page annotations: summary: "Instance {{ $labels.instance }} down" description: "{{ $labels.instance }} of job {{ $labels.job }} has been down for more than 5 minutes." # Alert for any instance that has a median request latency >1s. - alert: APIHighRequestLatency expr: api_http_request_latencies_second{quantile="0.5"} > 1 for: 10m annotations: summary: "High request latency on {{ $labels.instance }}"
description: "{{ $labels.instance }} has a median request latency above 1s (current value: {{ $value }}s)"
参考官方文档
https://prometheus.io/docs/prometheus/latest/configuration/alerting_rules/#defining-alerting-rules
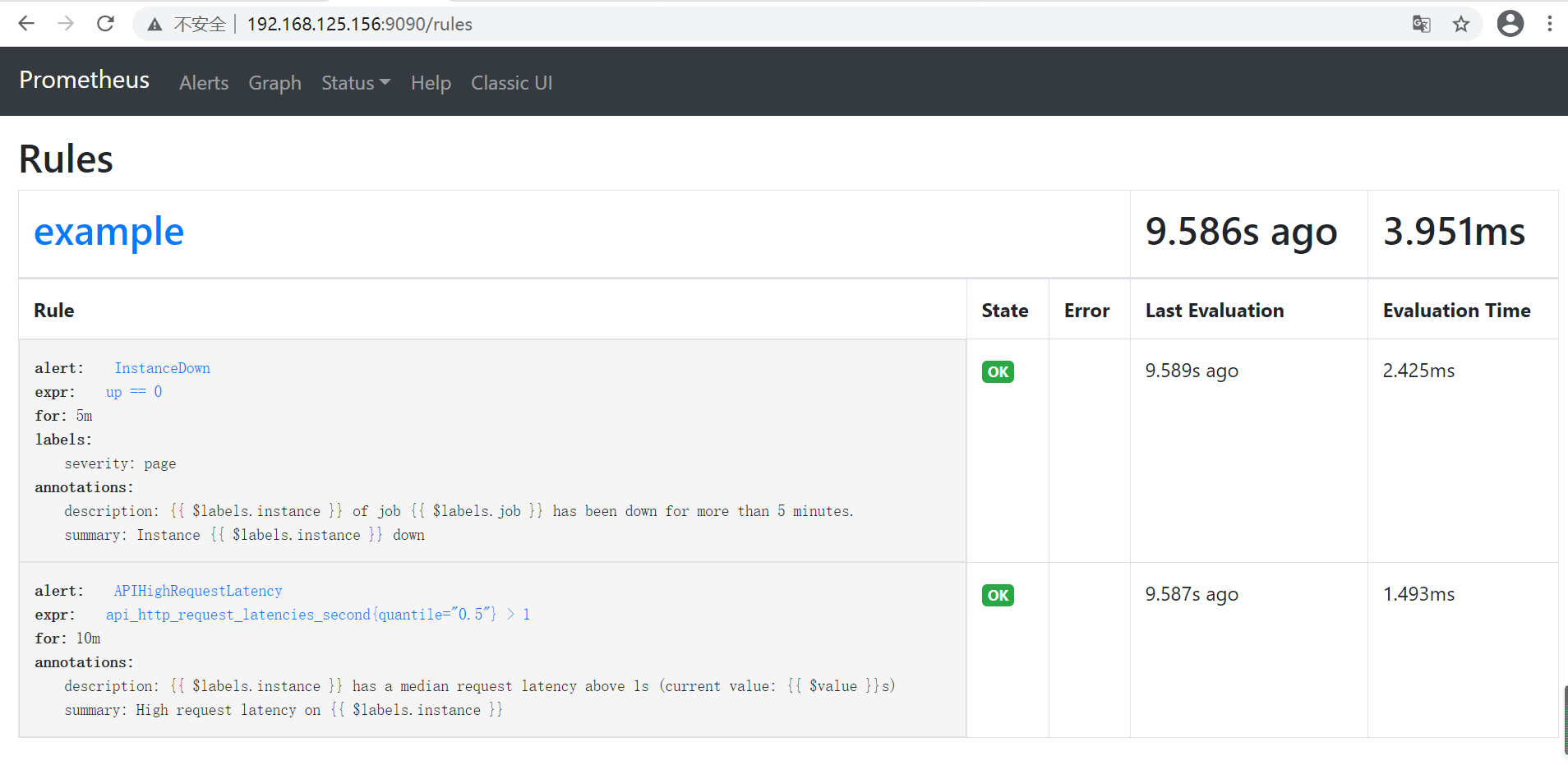
这个规则文件里,包含了两条告警规则:InstanceDown 和 APIHighRequestLatency。顾名思义,InstanceDown 表示当实例宕机时(up === 0)触发告警,APIHighRequestLatency 表示有一半的 API 请求延迟大于 1s 时(api_http_request_latencies_second{quantile="0.5"} > 1)触发告警。配置好后,需要重启下 Prometheus server,然后访问http://192.168.125.156:9090/rules可以看到刚刚配置的规则:
访问 http://192.168.177.156:9090/alerts 可以看到根据配置的规则生成的告警:
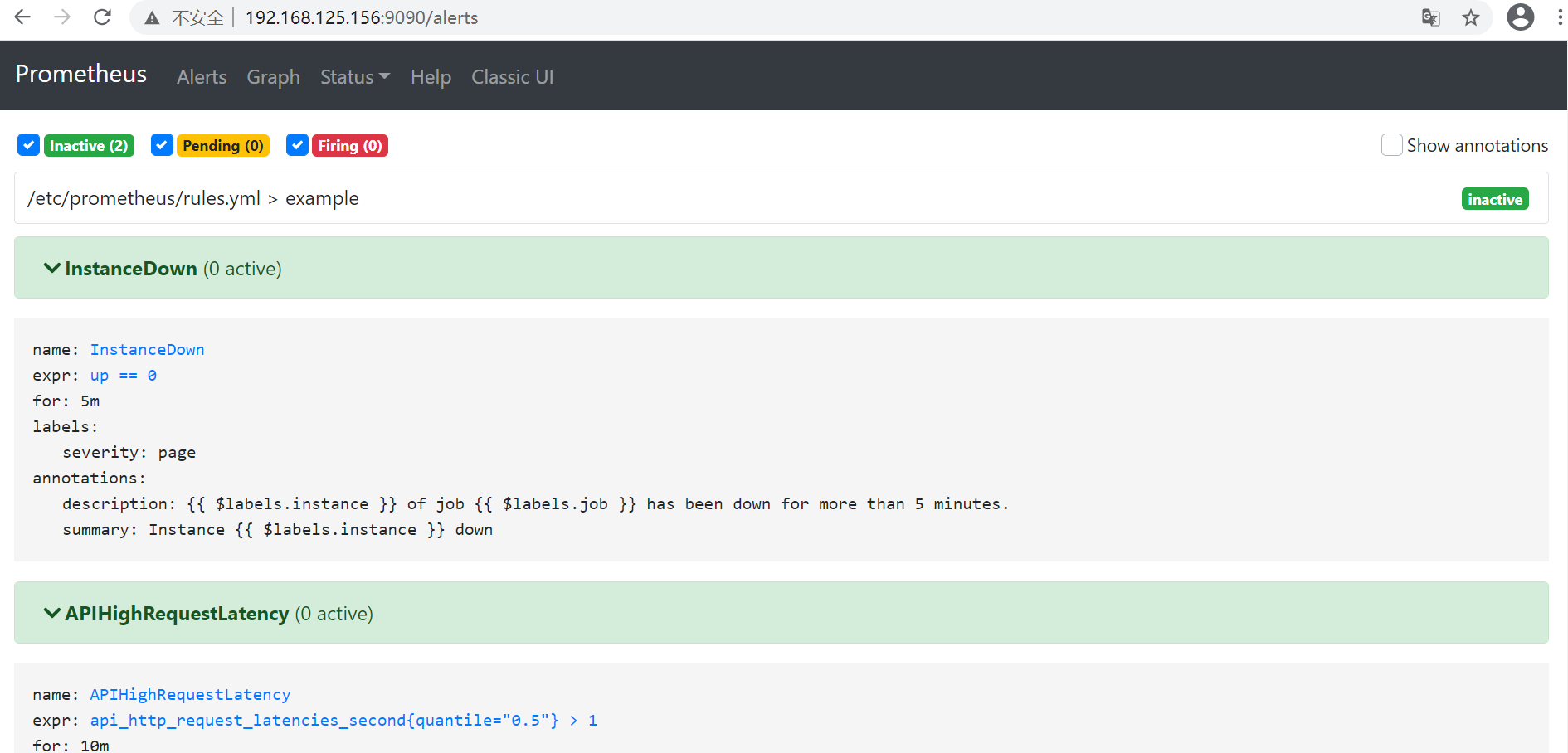
这里我们将一个实例停掉,可以看到有一条 alert 的状态是 PENDING,这表示已经触发了告警规则,但还没有达到告警条件。这是因为这里配置的 for 参数是 5m,也就是 5 分钟后才会触发告警,我们等 5 分钟,可以看到这条 alert 的状态变成了 FIRING。

安装AlterManager
mkdir -p /data2/promethues/alertmanager cd !$
创建配置文件alertmanager.yml
global: smtp_smarthost: 'smtp.163.com:25' # smtp地址 smtp_from: 'hjfxxxx@163.com' # 谁发邮件 smtp_auth_username: 'hjfxxxx@163.com' # 邮箱用户 smtp_auth_password: 'xxxxxx' # 邮箱授权码
smtp_require_tls: false route: group_by: ["alertname"] # 分组名 group_wait: 10s # 当收到告警的时候,等待三十秒看是否还有告警,如果有就一起发出去 group_interval: 10s # 发送警告间隔时间 repeat_interval: 1h # 重复报警的间隔时间 receiver: mail # 全局报警组,这个参数是必选的,和下面报警组名要相同 receivers: - name: 'mail' email_configs: - to: 'hjfxxxx@163.com'
启动alertmanager
docker run -d -p 9093:9093 \ --name alertmanager \ -v /data2/promethues/alertmanager/alertmanager.yml:/etc/alertmanager/alertmanager.yml \ prom/alertmanager
访问9093端口

关掉node-exporter,这个时候再访问 Alertmanager,可以看到 Alertmanager 已经接收到告警了:

下面的问题就是如何让 Alertmanager 将告警信息发送给我们了,上面alertmanager.yml已经配置了邮件告警的方式
再到/data2/promethues/test/prometheus.yml,添加
global: scrape_interval: 60s evaluation_interval: 60s rule_files: - /etc/prometheus/rules.yml scrape_configs: - job_name: prometheus static_configs: - targets: ['192.168.125.156:9090'] labels: instance: prometheus - targets: ['192.168.125.156:9100'] labels: group: 'client-node-exporter' alerting: alertmanagers: - static_configs: - targets: ["192.168.125.156:9093"]
163个人邮箱已经收到告警
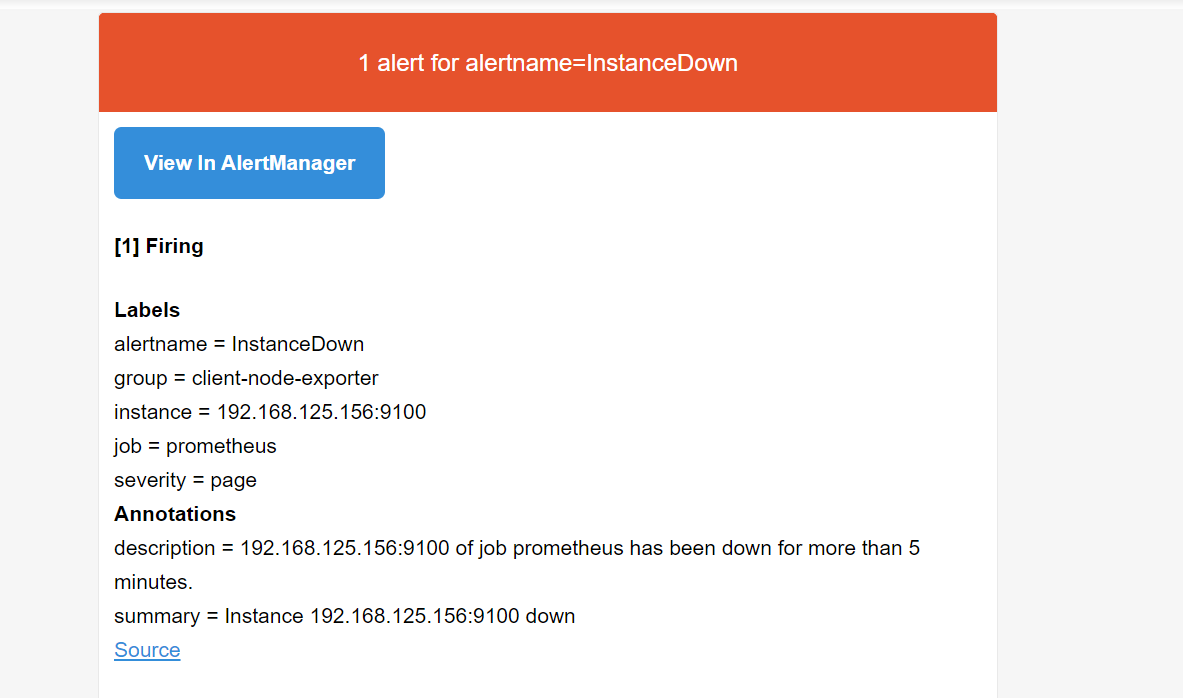
下面继续完善文档,服务器还是192.168.177.156,只不过ip地址变成了157
普罗米修斯监控docker容器
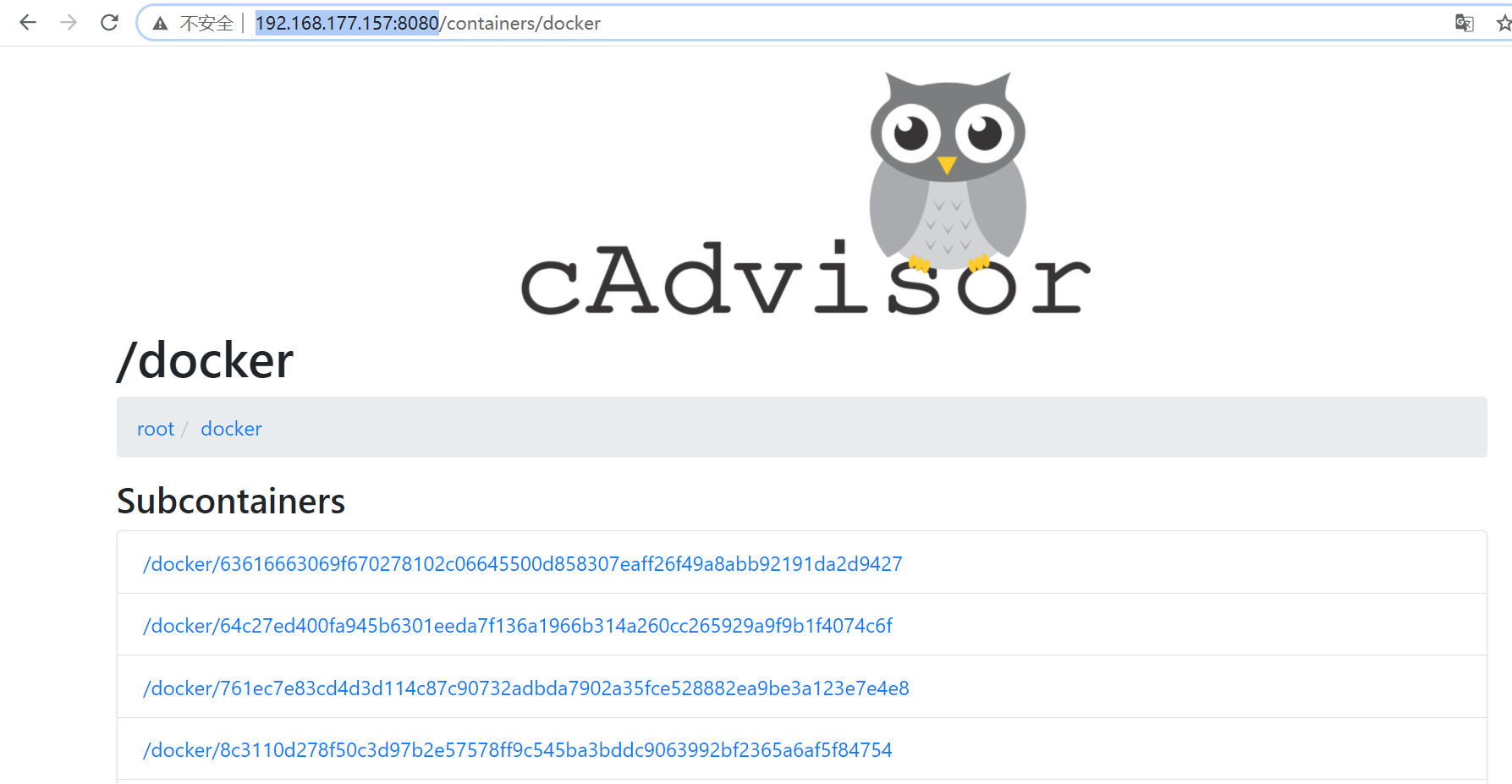
cadvisor 的安装
docker run \ --volume=/:/rootfs:ro \ --volume=/var/run:/var/run:rw \ --volume=/sys:/sys:ro \ --volume=/var/lib/docker/:/var/lib/docker:ro \ --volume=/dev/disk/:/dev/disk:ro \ --publish=8080:8080 \ --detach=true \ --name=cadvisor \ google/cadvisor:latest
当启动成功后,访问http://192.168.177.157:8080/
访问http://192.168.177.157:8080/metrics
修改主配置文件并重启
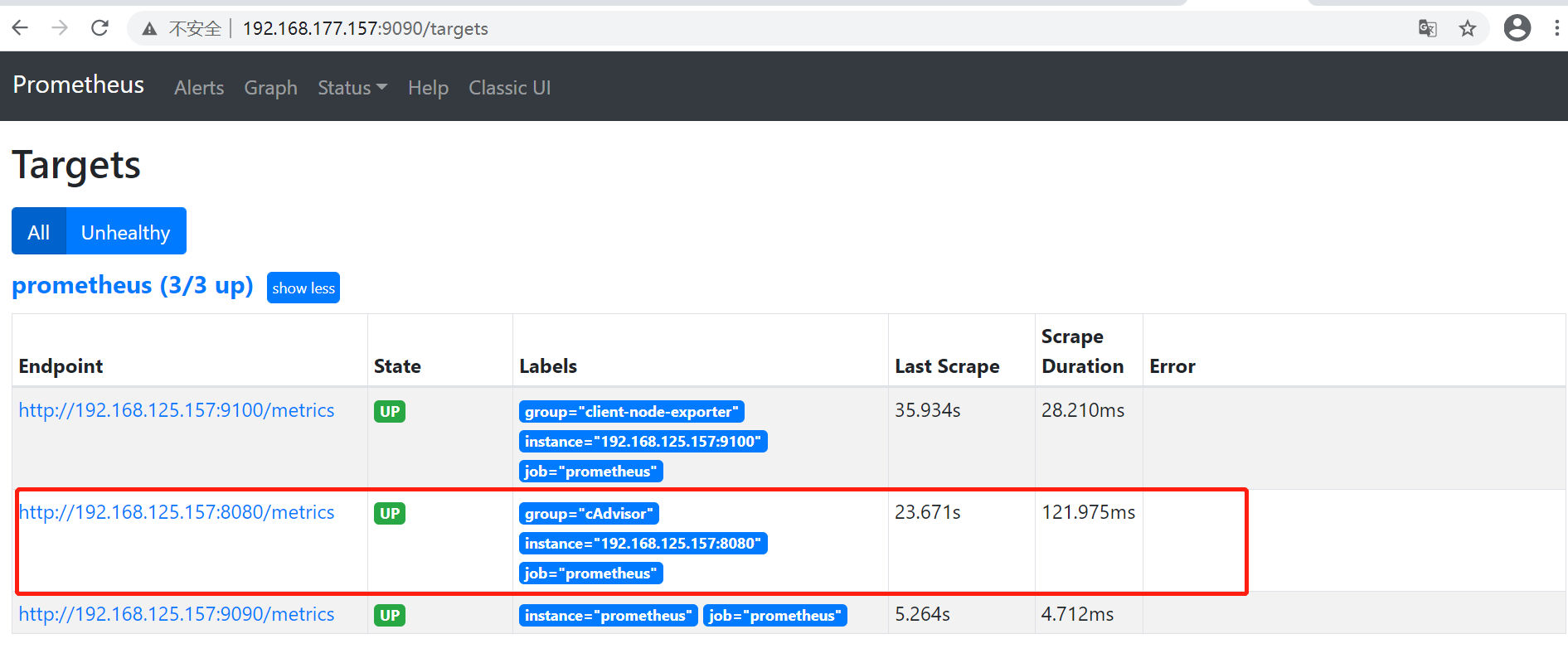
global: scrape_interval: 60s evaluation_interval: 60s rule_files: - /etc/prometheus/rules.yml scrape_configs: - job_name: prometheus static_configs: - targets: ['192.168.125.157:9090'] labels: instance: prometheus - targets: ['192.168.125.157:9100'] labels: group: 'client-node-exporter' - targets: ['192.168.125.157:8080'] labels: group: 'cAdvisor' alerting: alertmanagers: - static_configs: - targets: ["192.168.125.157:9093"]
访问
安装grafana,访问3000端口
docker run -d -p 3000:3000 --name=grafana grafana/grafana
账号:admin
密码:admin
需要修改密码
导入新的模版
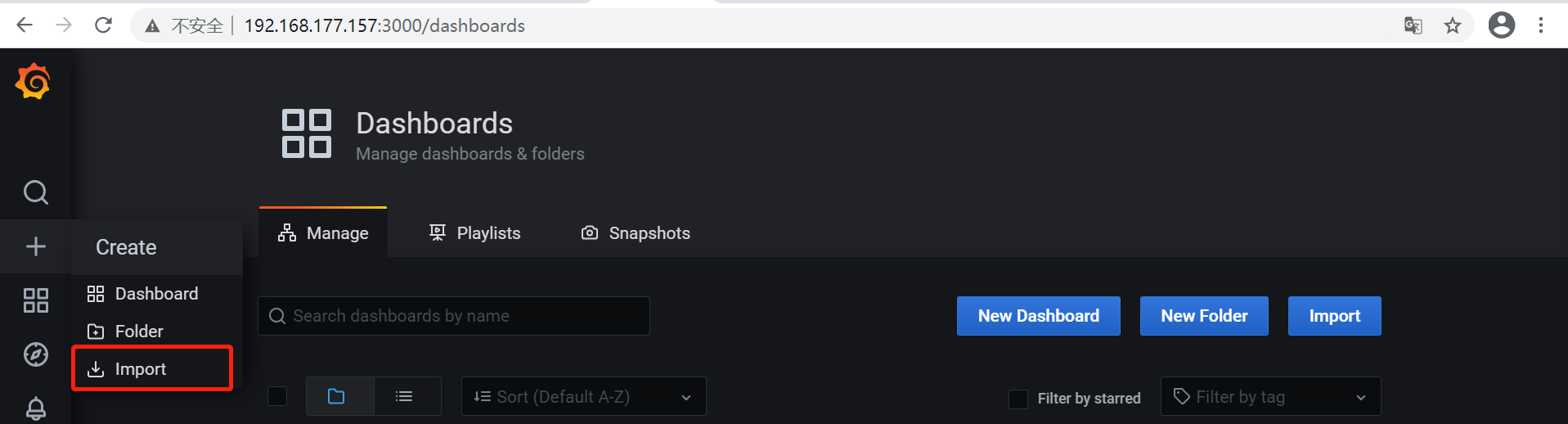
地址:https://grafana.com/grafana/dashboards/11558/revisions
复制链接地址
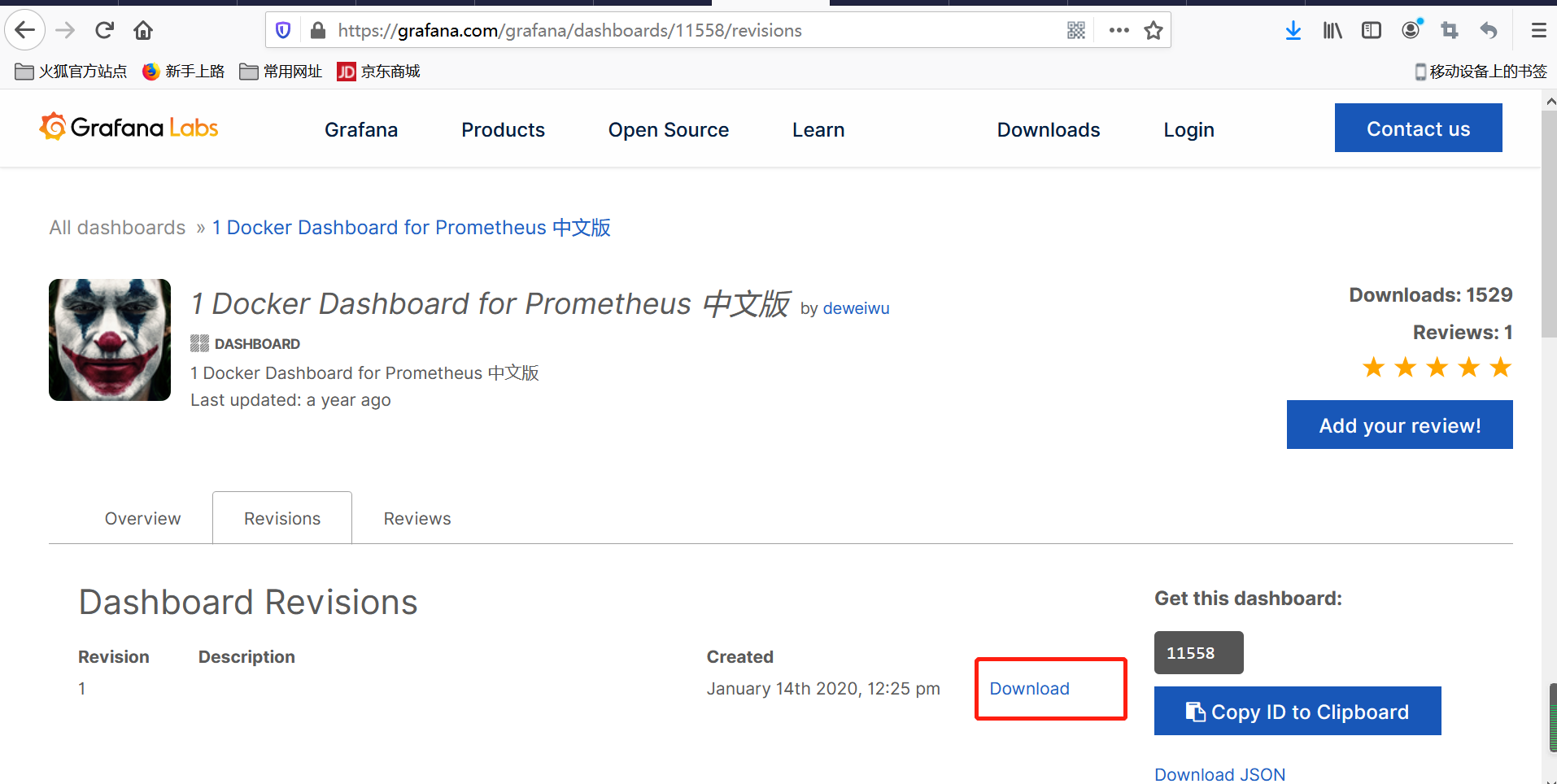
填进去即可

效果显示
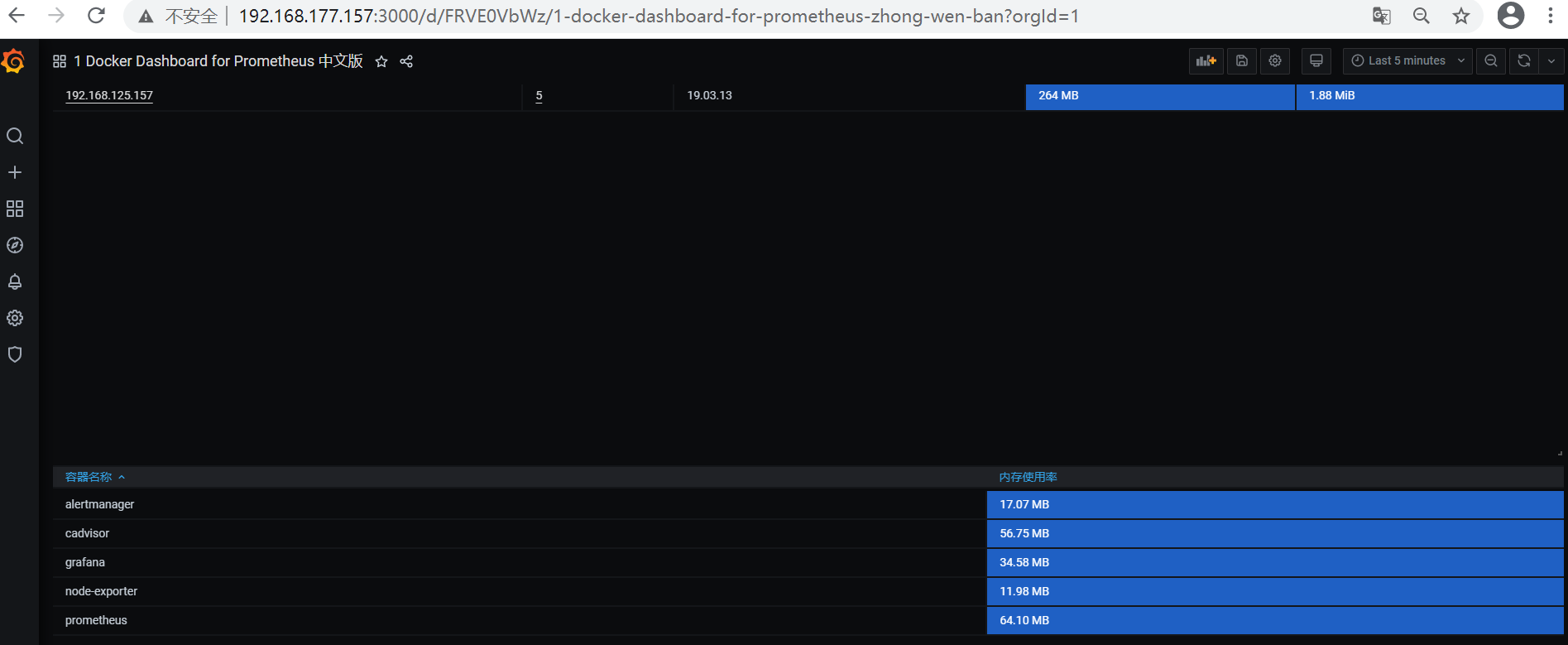
先到这吧
不是每个人都适合与你白头偕老。有的人是拿来成长的,有的人是拿来生活的,有的人是拿来一辈子怀念的。

