
1.介绍:
kafka是一个分布式的信息流式处理的工具。
1.1 Kafka的特性:
高吞吐量、低延迟每个topic可以分多个partition, consumer group 对partition进行consume操作。
可扩展性:kafka集群支持热扩展。
持久性、可靠性:消息被持久化到本地磁盘,并且支持数据备份防止数据丢失
容错性:允许集群中节点失败(若副本数量为n,则允许n-1个节点失败)。
高并发:支持数千个客户端同时读写。
1.2 Kafka流程:
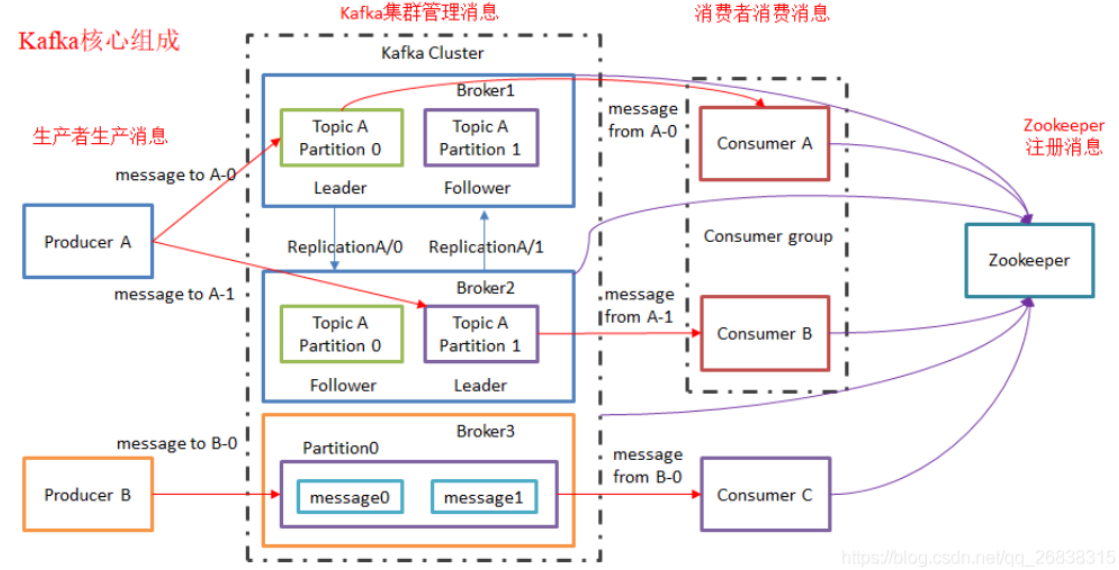
Kafka中发布订阅的对象是topic。我们可以为每类数据创建一个topic,把向topic发布消息的客户端称作producer,从topic订阅消息的客户端称作consumer。Producers和consumers可以同时从多个topic读写数据。一个kafka集群由一个或多个broker服务器组成,它负责持久化和备份具体的kafka消息。
Producers往Brokers里面的指定Topic中写消息,Consumers从Brokers里面拉去指定Topic的消息,然后进行业务处理。
一个topic实际是由多个partition组成的,遇到瓶颈时,可以通过增加partition的数量来进行横向扩容。单个parition内是保证消息有序。
正常的topic相当于一个MQ的队列,发布者发送message必须指定topic,然后Kafka会根据接收到的message进行load balance,均匀的分布到topic的不同的partition上,一个消费者组要全部消费这个topic上的所有partition,所以一个消费者组如果多个消费者,那么这里面的消费者是不能消费到全部消息的。
订阅topic是以一个消费组来订阅的,一个消费组里面可以有多个消费者。同一个消费组中的两个消费者,不会同时消费一个partition。换句话来说,就是一个partition,只能被消费组里的一个消费者消费,但是可以同时被多个消费组消费。因此,如果消费组内的消费者如果比partition多的话,那么就会有个别消费者一直空闲。
1.3 zookeeper作用:
zookeeper是为了解决分布式一致性问题的工具。
kafka 很多说不需要安装zk的是因为他们都使用了kafka自带的zk,至于kafka为什么使用zk,你首先要知道zk的作用, 作为去中心化的集群模式。需要要消费者知道现在那些生产者(对于消费者而言,kafka就是生产者)是可用的。如果没了zk消费者如何知道呢?如果每次消费者在消费之前都去尝试连接生产者测试下是否连接成功,效率呢?所以kafka需要zk,在kafka的设计中就依赖了zk了。
安装kafka之前需要先安装zookeeper集群,虽然卡夫卡有自带的zk集群,但是建议还是使用单独的zk集群。
具体原因:
kafka使用zookeeper来实现动态的集群扩展,不需要更改客户端(producer和consumer)的配置。broker会在zookeeper注册并保持相关的元数据(topic,partition信息等)更新。而客户端会在zookeeper上注册相关的watcher。一旦zookeeper发生变化,客户端能及时感知并作出相应调整。这样就保证了添加或去除broker时,各broker间仍能自动实现负载均衡。这里的客户端指的是Kafka的消息生产端(Producer)和消息消费端(Consumer)·
Kafka使用zk的分布式协调服务,将生产者,消费者,消息储存(broker,用于存储信息,消息读写等)结合在一起。
同时借助zk,kafka能够将生产者,消费者和broker在内的所有组件在无状态的条件下建立起生产者和消费者的订阅关系,实现生产者的负载均衡。
1.3.1 broker在zk中注册
kafka的每个broker(相当于一个节点,相当于一个机器)在启动时,都会在zk中注册,告诉zk其brokerid,在整个的集群中,broker.id/brokers/ids,当节点失效时,zk就会删除该节点,就很方便的监控整个集群broker的变化,及时调整负载均衡。
1.3.2 topic在zk中注册
在kafka中可以定义很多个topic,每个topic又被分为很多个分区。一般情况下,每个分区独立在存在一个broker上,所有的这些topic和broker的对应关系都有zk进行维护
1.3.3 consumer(消费者)在zk中注册
所以,Zookeeper作用:管理broker、consumer。
1.4kafka中角色分解
1.4.1 概述
kafka里面的消息是有topic来组织的,简单的我们可以想象为一个队列
- 一个topic就是一个消息队列,然后它把每个topic又分为很多个partition(片段)
这个是为了做并行的,更加方便扩展,而且提高了吞吐量
在每个partition内部消息强有序,相当于有序的队列,其中每个消息都有个序 号 offset,比如0到12,从前面读往后面写。
- 一个partition对应一个broker(相当于经纪人),一个broker可以管理多个partition
比如说,topic有6个partition,有两个broker,那每个broker就管3个partition。
partition可以想象为一个文件,当数据发过来的时候它就往这个partition上面追加就行,消息不经过内存缓冲,直接写入文件
kafka和很多消息系统不一样,很多消息系统是消费完了就把它删掉,而kafka是根据时间策略删除,而不是消费完就删除,在kafka里面没有一个消费完这么个概念,只有过期这样一个概念。
producer自己决定往哪个partition里面去写,这里有一些的策略,譬如hash。
consumer自己维护消费到哪个offset,每个consumer都有对应的组
组内:是queue消费模型,各个consumer消费不同的partition,因此一个消息在group内只消费一次
组间:是发布/订阅消费模型,各个组各自独立消费,互不影响,因此一个消息只被每个组消费一次
- Topic可以类比为数据库中的库
- partition可以类比为数据库中的表
- 一个topic就是一个消息队列,然后它把每个topic又分为很多个partition
- 一个topic可以有多个消费者组
- 同一个消费者组内的消费者在消费同一个topic时,这个topic中相同的数据只能被消费一次,即每个partion只会把消息发给该消费者组中的一个消费者
- 不同的消费者组消费同一个topic互不影响
- 一台kafka服务器节点就是一个broker。一个集群由多个broker组成。一个broker可以容纳多个topic。
1.4.2.Producer
消息生产者,就是向kafka broker发消息的客户端。生产者负责将记录分配到topic的指定 partition(分区)中
生产者会决定发送到哪个Partition,有两种发送的机制:
- 轮询(Round robin)
先随机到某一个partition上一直持续的写,大概写个十分钟,再随机到一个partition再去写,所以一般建议生产消息都按照建个key来按照hash去分,还可以自定义按照key怎么去分
- key的hash
如果key为null,就是轮询,否则就是按照key的hash
1.4.3.Consumer
消息消费者,向kafka broker取消息的客户端。每个消费者都要维护自己读取数据的offset。
每个consumer都有自己的消费者组group
同一个消费者组内的消费者在消费同一个topic时,这个topic中相同的数据只能被消费一次
不同的消费者组消费同一个topic互不影响
低版本0.9之前将offset保存在Zookeeper中,0.9及之后保存在Kafka的“__consumer_offsets”主题中。
1.4.4.Consumer Group
每个消费者都会使用一个消费组名称来进行标识。同一个组中的不同的消费者实例,可以分布在多个进程或多个机器上。
消费者组,由多个consumer组成。
一个topic可以有多个消费者组。topic的消息会复制(不是真的复制,是概念上的)到所有的CG,但每个partion只会把消息发给该CG中的一个consumer。
消费者组内每个消费者负责消费不同分区的数据,一个分区只能由一个消费者消费;
消费者组之间互不影响。
所有的消费者都属于某个消费者组,即消费者组是逻辑上的一个订阅者。
如果所有的消费者实例在同一消费组中,消息记录会负载平衡到每一个消费者实例(单播)。即每个消费者可以同时读取一个topic的不同分区!
消费者组是kafka用来**实现一个topic消息的广播(发给所有的消费者)和单播(发给任意一个消费者)**的手段。
如果需要实现广播,只要每个消费者有一个独立的消费者组就可以了。
如果需要实现单播,只要所有的消费者在同一个消费者组。用消费者组还可以将消费者进行自由的分组而不需要多次发送消息到不同的topic。
1.4.5.Broker
kafka集群的server,一台kafka服务器节点就是一个broker,负责处理消息读、写请求,存储消息,在kafka cluster这一层这里,其实里面是有很多个broker
一个集群由多个broker组成。一个broker可以容纳多个topic。
broker是组成kafka集群的节点,broker之间没有主从关系,各个broker之间的协调依赖于zookeeper,如数据在哪个节点上之类的
Kafka集群中有一个broker会被选举为Controller,负责管理集群broker的上下线,所有topic的分区副本分配和leader选举等工作。
Controller的管理工作都是依赖于Zookeeper的。
1.4.6.Topic
Topic 就是数据主题,kafka建议根据业务系统将不同的数据存放在不同的topic中。如:日志的消息可以放在一个topic,金额的消息可以放在一个topic,不同类别的消息放在不同的topic内,这次取消息更方便
Kafka中的Topics总是多订阅者模式,一个topic可以拥有一个或者多个消费者来订阅它的数据
一个大的Topic可以分布式存储在多个kafka broker中
Topic可以类比为数据库中的库
一个topic就是一个消息队列,然后它把每个topic又分为很多个partition
这个是为了做并行的,更加方便扩展,而且提高了吞吐量
在每个partition内部消息强有序,相当于有序的队列,其中每个消息都有个序号offset,比如0到12,从前面读往后面写。
1.4.7.Partition
一个topic可以分为多个partition,通过分区的设计,topic可以不断进行扩展。即一个Topic的多个分区分布式存储在多个broker(服务器)上。此外通过分区还可以让一个topic被多个consumer进行消费。以达到并行处理。分区可以类比为数据库中的表。
partition内部有序,但一个topic的整体(多个partition间)不一定有序
kafka只保证按一个partition中的顺序将消息发给consumer,partition中的每条消息都会被分配一个有序的id(offset),每个partition内部消息是一个强有序的队列,但不保证一个topic的整体(多个partition间)的顺序。
一个partition对应一个broker,一个broker可以管理多个partition
比如说,topic有6个partition,有两个broker,那每个broker就管3个partition。
partition可以很简单想象为一个文件,partition对应磁盘上的目录,当数据发过来的时候它就往这个partition上面追加,消息不经过内存缓冲,直接写入文件
kafka为每个主题维护了分布式的分区(partition)日志文件,每个partition在kafka存储层面是append log。任何发布到此partition的消息都会被追加到log文件的尾部,在分区中的每条消息都会按照时间顺序分配到一个单调递增的顺序编号,也就是我们的offset,offset是一个long型的数字,我们通过这个offset可以确定一条在该partition下的唯一消息。在partition下面是保证了有序性,但是在topic下面没有保证有序性。
每个partition都会有副本,可以在创建topic时来指定有几个副本
1.4.8.Offset
kafka的存储文件都是按照offset.kafka来命名,用offset做名字的好处是方便查找。例如你想找位于2049的位置,只要找到2048.kafka的文件即可。当然the first offset就是00000000000.kafka
数据会按照时间顺序被不断第追加到分区的一个结构化的commit log中!每个分区中存储的记录都是有序的,且顺序不可变!
这个顺序是通过一个称之为offset的id来唯一标识!因此也可以认为offset是有序且不可变的!
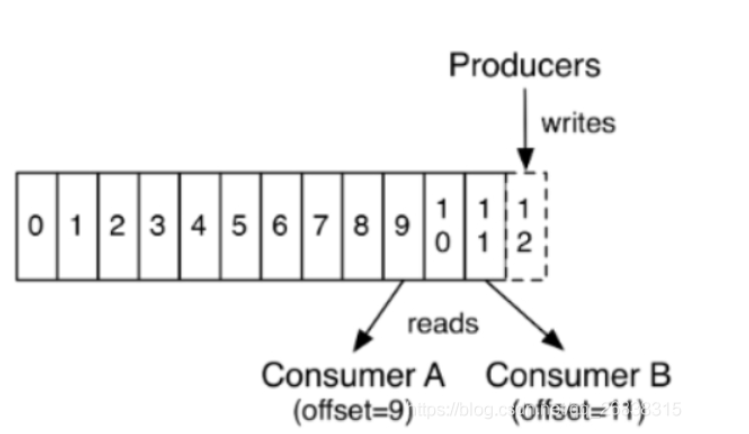
在每一个消费者端,会唯一保存的元数据是offset(偏移量),即消费在log中的位置,偏移量由消费者所控制。通常在读取记录后,消费者会以线性的方式增加偏移量,但是实际上,由于这个位置由消费者控制,所以消费者可以采用任何顺序来消费记录。例如,一个消费者可以重置到一个旧的偏移量,从而重新处理过去的数据;也可以跳过最近的记录,从"现在"开始消费。
这些细节说明Kafka 消费者是非常廉价的—消费者的增加和减少,对集群或者其他消费者没有多大的影响。比如,你可以使用命令行工具,对一些topic内容执行 tail操作,并不会影响已存在的消费者消费数据。
图1 Topic拓扑结构
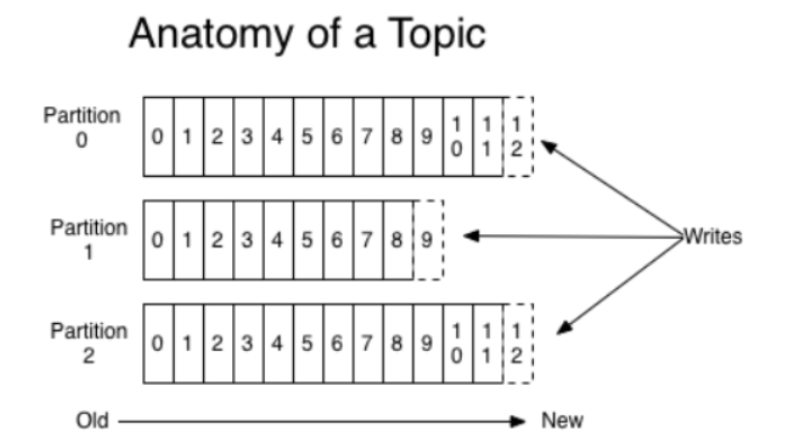
图2 数据流
1.4.9.持久化
Kafka 集群保留所有发布的记录—无论他们是否已被消费—并通过一个可配置的参数——保留期限来控制。举个例子, 如果保留策略设置为2天,一条记录发布后两天内,可以随时被消费,两天过后这条记录会被清除并释放磁盘空间。
Kafka的性能和数据大小无关,所以长时间存储数据没有什么问题。
1.4.10.Replica副本机制
副本,为保证集群中的某个节点发生故障时,该节点上的partition数据不丢失,且kafka仍然能够继续工作,kafka提供了副本机制,一个topic的每个分区都有若干个副本,一个leader和若干个follower。
日志的分区partition (分布)在Kafka集群的服务器上。每个服务器在处理数据和请求时,共享这些分区。每一个分区都会在已配置的服务器上进行备份,确保容错性。
每个分区都有一台 server 作为 “leader”,零台或者多台server作为 follwers 。leader server 处理一切对 partition (分区)的读写请求,而follwers只需被动的同步leader上的数据。当leader宕机了,followers 中的一台服务器会自动成为新的 leader。通过这种机制,既可以保证数据有多个副本,也实现了一个高可用的机制!
同一个partition可能会有多个replication(对应 server.properties 配置中的 default.replication.factor=N)。没有replication的情况下,一旦broker 宕机,其上所有 partition 的数据都不可被消费,同时producer也不能再将数据存于其上的patition。引入replication之后,同一个partition可能会有多个replication,而这时需要在这些replication之间选出一个leader,producer和consumer只与这个leader交互,其它replication作为follower从leader 中复制数据。
基于安全考虑,每个分区的Leader和follower一般会错在在不同的broker!
- leader
每个分区多个副本的“主”,生产者发送数据的对象,以及消费者消费数据的对象都是leader。
- follower
每个分区多个副本中的“从”,实时从leader中同步数据,保持和leader数据的同步。leader发生故障时,某个follower会成为新的follower。
1.4.11.zookeeper
元数据信息存在zookeeper中,包括:broker,topic,partition的元数据消息(存储消费偏移量,topic话题信息,partition信息)。kafka0.8之前还可以存储消费者offset
Kafka集群中有一个broker会被选举为Controller,负责管理集群broker的上下线,所有topic的分区副本分配和leader选举等工作。
Controller的管理工作都是依赖于Zookeeper的。
可供参看链接:https://blog.csdn.net/qq_26838315/article/details/106883403
1.5工作流程相关分析
相信大家和我一样,以上东西第一次了解的时候很蒙圈,不过没关系,我们看具体流程
1.5.1 发送数据
producer就是生产者,是数据的入口。注意看图中的红色箭头,Producer在写入数据的时候永远的找leader,不会直接将数据写入follower!那leader怎么找呢?写入的流程又是什么样的呢?我们看下图:

发送的流程就在图中已经说明了,就不单独在文字列出来了!需要注意的一点是,消息写入leader后,follower是主动的去leader进行同步的!producer采用push模式将数据发布到broker,每条消息追加到分区中,顺序写入磁盘,所以保证同一分区内的数据是有序的!写入示意图如下:

上面说到数据会写入到不同的分区,那kafka为什么要做分区呢?相信大家应该也能猜到,分区的主要目的是:
1、 方便扩展。因为一个topic可以有多个partition,所以我们可以通过扩展机器去轻松的应对日益增长的数据量。
2、 提高并发。以partition为读写单位,可以多个消费者同时消费数据,提高了消息的处理效率。
熟悉负载均衡的朋友应该知道,当我们向某个服务器发送请求的时候,服务端可能会对请求做一个负载,将流量分发到不同的服务器,那在kafka中,如果某个topic有多个partition,producer又怎么知道该将数据发往哪个partition呢?kafka中有几个原则:
1、 partition在写入的时候可以指定需要写入的partition,如果有指定,则写入对应的partition。
2、 如果没有指定partition,但是设置了数据的key,则会根据key的值hash出一个partition。
3、 如果既没指定partition,又没有设置key,则会轮询选出一个partition。
保证消息不丢失是一个消息队列中间件的基本保证,那producer在向kafka写入消息的时候,怎么保证消息不丢失呢?其实上面的写入流程图中有描述出来,那就是通过ACK应答机制!在生产者向队列写入数据的时候可以设置参数来确定是否确认kafka接收到数据,这个参数可设置的值为0、1、all。
0代表producer往集群发送数据不需要等到集群的返回,不确保消息发送成功。安全性最低但是效率最高。
1代表producer往集群发送数据只要leader应答就可以发送下一条,只确保leader发送成功。
all代表producer往集群发送数据需要所有的follower都完成从leader的同步才会发送下一条,确保leader发送成功和所有的副本都完成备份。安全性最高,但是效率最低。
最后要注意的是,如果往不存在的topic写数据,能不能写入成功呢?kafka会自动创建topic,分区和副本的数量根据默认配置都是1。
1.5.2 保存数据
Producer将数据写入kafka后,集群就需要对数据进行保存了!kafka将数据保存在磁盘,可能在我们的一般的认知里,写入磁盘是比较耗时的操作,不适合这种高并发的组件。Kafka初始会单独开辟一块磁盘空间,顺序写入数据(效率比随机写入高)。
- Partition 结构
前面说过了每个topic都可以分为一个或多个partition,如果你觉得topic比较抽象,那partition就是比较具体的东西了!Partition在服务器上的表现形式就是一个一个的文件夹,每个partition的文件夹下面会有多组segment文件,每组segment文件又包含.index文件、.log文件、.timeindex文件(早期版本中没有)三个文件, log文件就实际是存储message的地方,而index和timeindex文件为索引文件,用于检索消息。

如上图,这个partition有三组segment文件,每个log文件的大小是一样的,但是存储的message数量是不一定相等的(每条的message大小不一致)。文件的命名是以该segment最小offset来命名的,如000.index存储offset为0~368795的消息,kafka就是利用分段+索引的方式来解决查找效率的问题。
- Message结构
上面说到log文件就实际是存储message的地方,我们在producer往kafka写入的也是一条一条的message,那存储在log中的message是什么样子的呢?消息主要包含消息体、消息大小、offset、压缩类型……等等!我们重点需要知道的是下面三个:
1、 offset:offset是一个占8byte的有序id号,它可以唯一确定每条消息在parition内的位置!
2、 消息大小:消息大小占用4byte,用于描述消息的大小。
3、 消息体:消息体存放的是实际的消息数据(被压缩过),占用的空间根据具体的消息而不一样。
- 存储策略
无论消息是否被消费,kafka都会保存所有的消息。那对于旧数据有什么删除策略呢?
1、 基于时间,默认配置是168小时(7天)。
2、 基于大小,默认配置是1073741824。
需要注意的是,kafka读取特定消息的时间复杂度是O(1),所以这里删除过期的文件并不会提高kafka的性能!
1.5.3 消费数据
消息存储在log文件后,消费者就可以进行消费了。与生产消息相同的是,消费者在拉取消息的时候也是找leader去拉取。
多个消费者可以组成一个消费者组(consumer group),每个消费者组都有一个组id!同一个消费组者的消费者可以消费同一topic下不同分区的数据,但是不会组内多个消费者消费同一分区的数据!!!是不是有点绕。我们看下图:

图示是消费者组内的消费者小于partition数量的情况,所以会出现某个消费者消费多个partition数据的情况,消费的速度也就不及只处理一个partition的消费者的处理速度!如果是消费者组的消费者多于partition的数量,那会不会出现多个消费者消费同一个partition的数据呢?上面已经提到过不会出现这种情况!多出来的消费者不消费任何partition的数据。所以在实际的应用中,建议消费者组的consumer的数量与partition的数量一致!
在保存数据的小节里面,我们聊到了partition划分为多组segment,每个segment又包含.log、.index、.timeindex文件,存放的每条message包含offset、消息大小、消息体……我们多次提到segment和offset,查找消息的时候是怎么利用segment+offset配合查找的呢?假如现在需要查找一个offset为368801的message是什么样的过程呢?我们先看看下面的图:

1、 先找到offset的368801message所在的segment文件(利用二分法查找),这里找到的就是在第二个segment文件。
2、 打开找到的segment中的.index文件(也就是368796.index文件,该文件起始偏移量为368796+1,我们要查找的offset为368801的message在该index内的偏移量为368796+5=368801,所以这里要查找的相对offset为5)。由于该文件采用的是稀疏索引的方式存储着相对offset及对应message物理偏移量的关系,所以直接找相对offset为5的索引找不到,这里同样利用二分法查找相对offset小于或者等于指定的相对offset的索引条目中最大的那个相对offset,所以找到的是相对offset为4的这个索引。
3、 根据找到的相对offset为4的索引确定message存储的物理偏移位置为256。打开数据文件,从位置为256的那个地方开始顺序扫描直到找到offset为368801的那条Message。
这套机制是建立在offset为有序的基础上,利用segment+有序offset+稀疏索引+二分查找+顺序查找等多种手段来高效的查找数据!至此,消费者就能拿到需要处理的数据进行处理了。那每个消费者又是怎么记录自己消费的位置呢?在早期的版本中,消费者将消费到的offset维护zookeeper中,consumer每间隔一段时间上报一次,这里容易导致重复消费,且性能不好!在新的版本中消费者消费到的offset已经直接维护在kafk集群的__consumer_offsets这个topic中!
参考https://www.cnblogs.com/sujing/p/10960832.html解说非常棒
2.安装zk
环境:centos7 三台机器
- kafka_2.11-2.4.0.tgz
- zookeeper-3.4.13.tar.gz
- jdk1.8(这里不做过多安装步骤)
-
KafkaManager2.0.0.0
安装包
-
链接:https://pan.baidu.com/s/1XFT5cUpGhrDazcMu_9Rfkw
提取码:awv0
虽然kafka内置了zookeeper,但是建议大家还是先安装zookeeper,因为生产环境时集群时,一般都是独立zookeeper:
2.1创建三个目录分别放置zookeeper,kafka,kafka-manager
1 | mkdir /data/disk04/kafka-manager /data/disk04/zookeeper /data/disk04/kafka |
2.2解压zookeeper
1 | $ tar -zvxf /data/disk04/zookeeper/zookeeper-3.4.13.tar.gz |
2.3创建zk的数据目录
1 | mkdir /data/disk04/zookeeper/zk-data |
2.4配置zk配置文件
三台机器上的zookeeper.properties文件配置相同,data.Dir 为zk的数据目录,server.1、server.2、server.3 为集群信息。
tickTime:CS通信心跳数
1 2 3 4 5 | $ cd zookeeper-3.4.13/confcp zoo_sample.cfg zoo_sample.cfg.bakvi zoo_sample.cfgzk的数据目录dataDir=/data/disk04/zookeeper/zk-data |
Zookeeper 服务器之间或客户端与服务器之间维持心跳的时间间隔,也就是每个 tickTime 时间就会发送一个心跳。
tickTime以毫秒为单位。
tickTime:该参数用来定义心跳的间隔时间,zookeeper的客户端和服务端之间也有和web开发里类似的session的概念,而zookeeper里最小的session过期时间就是tickTime的两倍。
initLimit:LF初始通信时限
集群中的follower服务器(F)与leader服务器(L)之间 初始连接 时能容忍的最多心跳数(tickTime的数量)
syncLimit:LF同步通信时限
集群中的follower服务器(F)与leader服务器(L)之间 请求和应答 之间能容忍的最多心跳数(tickTime的数量)
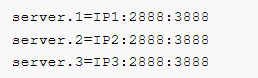
server.A=B:C:D
A:其中 A 是一个数字,表示这个是服务器的编号;
B:是这个服务器的 ip 地址;
C:Zookeeper服务器之间的通信端口;
D:Leader选举的端口。
2888端口号是zookeeper服务之间通信的端口
3888端口是zookeeper与其他应用程序通信的端口
1 2 3 4 5 6 7 8 | maxClientCnxns=0tickTime=2000initLimit=10svncLimit5server.1=IP1:2888:3888server.2=IP2:2888:3888server.3=IP3:2888:3888 |
2.5配置myid
在 dataDir 指定的目录下,创建 myid 文件。
1 | touch /data/disk04/zookeeper/zk-data/myid |
以server.id为准
第一台机器myid中写1

后面的机器依次在相应目录创建myid文件,写上相应配置数字即可。
2.6配置环境变量
为了能够在任意目录启动zookeeper集群,我们需要配置环境变量。
1 2 3 4 5 6 7 8 | vi /etc/profile#set zookeeper environmentexport ZK_HOME=/data/disk04/zookeeper/zookeeper-3.4.13export PATH=$PATH:$ZK_HOME/binsource /etc/profile |
2.7将第一台配置拉取到后两台服务器上
1 | scp -r was@IP1:/data/disk04/zookeeper ./ |
2.8修改2和3台服务器的/etc/profile和myid文件
第2台机器myid文件‘

第3台机器myid文件

2.9日常命令
启动命令
1 | nohup ./zkServer.sh start & |
查看状态命令
1 | zkServer.sh status |
第一台机器

第二台机器

第三台机器

查看日志
1 | ./zkServer.sh start-foreground |
3.安装kafka
3.1 解压安装包
1 | tar -zxvf kafka_2.11-2.4.0.tgz |
3.2创建数据目录以及日志目录
1 | mkdir /data/disk04/kafka/data /data/disk04/kafka/logs |
3.3 编写myid
1 2 | touch /data/disk04/kafka/data/myidecho “1” > /data/disk04/kafka/data/myid |
3.4修改kafka配置文件
1 2 3 4 5 | vi /data/disk04/kafka/kafka_2.11-2.4.0/config/server.propertiesbroker.id=1advertised.listeners=PLAINTEXT://IP1:9092log.dirs=/data/disk04/kafka/logszookeeper.connect=IP1:2181,IP2:2181,IP3:2181 |
其他配置默认即可
第一台机器具体配置’
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 | broker.id=1advertised.listeners=PLAINTEXT://10.135.56.110:9092advertised.host.name=IP1advertised.port=9092num.network.threads=3num.io.threads=8socket.send.buffer.bytes=102400socket.receive.buffer.bytes=102400socket.request.max.bytes=104857600log.dirs=/data/disk04/kafka/logsnum.partitions=40num.recovery.threads.per.data.dir=1offsets.topic.replication.factor=1transaction.state.log.replication.factor=1transaction.state.log.min.isr=1log.retention.hours=168log.segment.bytes=1073741824log.retention.check.interval.ms=300000zookeeper.connect=IP1:2181,IP2:2181,IP3:2181zookeeper.connection.timeout.ms=6000group.initial.rebalance.delay.ms=0 |
具体配置解析
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 246 247 248 249 250 251 252 253 254 255 256 257 258 259 260 261 262 263 264 265 266 267 268 269 270 271 272 273 274 275 276 277 278 279 280 281 282 283 284 285 286 287 288 289 290 291 292 293 294 295 296 297 298 299 300 301 302 303 304 305 306 307 308 309 310 311 312 313 314 315 316 317 318 319 320 321 322 323 324 325 326 327 328 329 330 331 332 333 334 335 336 337 338 339 340 341 | #broker的全局唯一编号,不能重复broker.id=0 #用来监听链接的端口,producer或consumer将在此端口建立连接port=9092 #处理网络请求的线程数量num.network.threads=3 #用来处理磁盘IO的线程数量num.io.threads=8 #发送套接字的缓冲区大小socket.send.buffer.bytes=102400 #接受套接字的缓冲区大小socket.receive.buffer.bytes=102400 #请求套接字的缓冲区大小socket.request.max.bytes=104857600 #kafka消息存放的路径log.dirs=/home/servers-kafka/logs/kafka #topic在当前broker上的分片个数num.partitions=2 #用来恢复和清理data下数据的线程数量num.recovery.threads.per.data.dir=1 #segment文件保留的最长时间,超时将被删除log.retention.hours=168 #滚动生成新的segment文件的最大时间log.roll.hours=168 #日志文件中每个segment的大小,默认为1Glog.segment.bytes=1073741824 #周期性检查文件大小的时间log.retention.check.interval.ms=300000 #日志清理是否打开log.cleaner.enable=true #broker需要使用zookeeper保存meta数据zookeeper.connect=hadoop02:2181,hadoop03:2181,hadoop04:2181 #zookeeper链接超时时间zookeeper.connection.timeout.ms=6000 #partion buffer中,消息的条数达到阈值,将触发flush到磁盘log.flush.interval.messages=10000 #消息buffer的时间,达到阈值,将触发flush到磁盘log.flush.interval.ms=3000 #删除topic需要server.properties中设置delete.topic.enable=true否则只是标记删除delete.topic.enable=true #此处的host.name为本机IP(重要),如果不改,则客户端会抛出:Producerconnection to localhost:9092 unsuccessful 错误!host.name=hadoop02 2、修改producer.properties #指定kafka节点列表,用于获取metadata,不必全部指定metadata.broker.list=hadoop02:9092,hadoop03:9092 # 指定分区处理类。默认kafka.producer.DefaultPartitioner,表通过key哈希到对应分区#partitioner.class=kafka.producer.DefaultPartitioner # 是否压缩,默认0表示不压缩,1表示用gzip压缩,2表示用snappy压缩。压缩后消息中会有头来指明消息压缩类型,故在消费者端消息解压是透明的无需指定。compression.codec=none # 指定序列化处理类serializer.class=kafka.serializer.DefaultEncoder # 如果要压缩消息,这里指定哪些topic要压缩消息,默认empty,表示不压缩。#compressed.topics= # 设置发送数据是否需要服务端的反馈,有三个值0,1,-1# 0: producer不会等待broker发送ack# 1: 当leader接收到消息之后发送ack# -1: 当所有的follower都同步消息成功后发送ack.request.required.acks=0 #在向producer发送ack之前,broker允许等待的最大时间 ,如果超时,broker将会向producer发送一个error ACK.意味着上一次消息因为某种原因未能成功(比如follower未能同步成功)request.timeout.ms=10000 # 同步还是异步发送消息,默认“sync”表同步,"async"表异步。异步可以提高发送吞吐量,也意味着消息将会在本地buffer中,并适时批量发送,但是也可能导致丢失未发送过去的消息producer.type=sync # 在async模式下,当message被缓存的时间超过此值后,将会批量发送给broker,默认为5000ms# 此值和batch.num.messages协同工作.queue.buffering.max.ms = 5000 # 在async模式下,producer端允许buffer的最大消息量# 无论如何,producer都无法尽快的将消息发送给broker,从而导致消息在producer端大量沉积# 此时,如果消息的条数达到阀值,将会导致producer端阻塞或者消息被抛弃,默认为10000queue.buffering.max.messages=20000 # 如果是异步,指定每次批量发送数据量,默认为200batch.num.messages=500 # 当消息在producer端沉积的条数达到"queue.buffering.max.meesages"后# 阻塞一定时间后,队列仍然没有enqueue(producer仍然没有发送出任何消息)# 此时producer可以继续阻塞或者将消息抛弃,此timeout值用于控制"阻塞"的时间# -1: 无阻塞超时限制,消息不会被抛弃# 0:立即清空队列,消息被抛弃queue.enqueue.timeout.ms=-1 # 当producer接收到error ACK,或者没有接收到ACK时,允许消息重发的次数# 因为broker并没有完整的机制来避免消息重复,所以当网络异常时(比如ACK丢失)# 有可能导致broker接收到重复的消息,默认值为3.message.send.max.retries=3 # producer刷新topicmetada的时间间隔,producer需要知道partitionleader的位置,以及当前topic的情况# 因此producer需要一个机制来获取最新的metadata,当producer遇到特定错误时,将会立即刷新#(比如topic失效,partition丢失,leader失效等),此外也可以通过此参数来配置额外的刷新机制,默认值600000topic.metadata.refresh.interval.ms=60000 3、修改consumer.properties # zookeeper连接服务器地址zookeeper.connect=hadoop02:2181,hadoop03:2181,hadoop04:2181 # zookeeper的session过期时间,默认5000ms,用于检测消费者是否挂掉zookeeper.session.timeout.ms=5000 #当消费者挂掉,其他消费者要等该指定时间才能检查到并且触发重新负载均衡zookeeper.connection.timeout.ms=10000 # 指定多久消费者更新offset到zookeeper中。注意offset更新时基于time而不是每次获得的消息。一旦在更新zookeeper发生异常并重启,将可能拿到已拿到过的消息zookeeper.sync.time.ms=2000 #指定消费组group.id=xxx # 当consumer消费一定量的消息之后,将会自动向zookeeper提交offset信息# 注意offset信息并不是每消费一次消息就向zk提交一次,而是现在本地保存(内存),并定期提交,默认为trueauto.commit.enable=true # 自动更新时间。默认60 * 1000auto.commit.interval.ms=1000 # 当前consumer的标识,可以设定,也可以有系统生成,主要用来跟踪消息消费情况,便于观察conusmer.id=xxx # 消费者客户端编号,用于区分不同客户端,默认客户端程序自动产生client.id=xxxx # 最大取多少块缓存到消费者(默认10)queued.max.message.chunks=50 # 当有新的consumer加入到group时,将会reblance,此后将会有partitions的消费端迁移到新 的consumer上,如果一个consumer获得了某个partition的消费权限,那么它将会向zk注册"Partition Owner registry"节点信息,但是有可能此时旧的consumer尚没有释放此节点, 此值用于控制,注册节点的重试次数.rebalance.max.retries=5 # 获取消息的最大尺寸,broker不会像consumer输出大于此值的消息chunk 每次feth将得到多条消息,此值为总大小,提升此值,将会消耗更多的consumer端内存fetch.min.bytes=6553600 # 当消息的尺寸不足时,server阻塞的时间,如果超时,消息将立即发送给consumerfetch.wait.max.ms=5000socket.receive.buffer.bytes=655360 # 如果zookeeper没有offset值或offset值超出范围。那么就给个初始的offset。有smallest、largest、anything可选,分别表示给当前最小的offset、当前最大的offset、抛异常。默认largestauto.offset.reset=smallest # 指定序列化处理类derializer.class=kafka.serializer.DefaultDecoder |
3.5将机器1的配置文件scp到机器2和机器3
1 | scp -r was@IP1:/data/disk04/kafka /data/disk04 |
3.6 修改第二台机器和第三台机器配置文件
1 | vi /data/disk04/kafka/kafka_2.11-2.4.0/config/server.properties |
第二台机器(只显示了修改参数)
1 2 3 4 | broker.id=2advertised.listeners=PLAINTEXT://IP2:9092log.dirs=/data/disk04/kafka/logszookeeper.connect=IP1:2181,IP2:2181,IP3:2181d |
第三台机器(只显示修改参数)
1 2 3 4 | broker.id=3advertised.listeners=PLAINTEXT://IP3:9092log.dirs=/data/disk04/kafka/logszookeeper.connect=IP1:2181,IP2:2181,IP3:2181 |
3.7命令总结
启动kafka
1 | nohup bin/kafka-server-start.sh config/server.properties & |
查看启动后端口
1 | netstat -lnp | grep 9092 |
创建topic
zookeeper后面的参数就是zookeeper配置时的配置,2181为默认端口 replication-factor:设置主题的备份数量(分区的备份数量在配置文件中设置) partitions:指定分区数数量。
1 | kafka-topics.sh --create --zookeeper master:2181,slave1:2181,slave2:2181 --replication-factor 1 --partitions 1 --topic book |
查看所有topic列表
1 | bin/kafka-topics.sh --zookeeper master:2181,slave1:2181,slave2:2181 --list |
查看指定topic信息
1 | bin/kafka-topics.sh --zookeeper master:2181,slave1:2181,slave2:2181 --describe --topic book |
控制台向topic生产数据
1 | bin/kafka-console-producer.sh --broker-list master:9092 --topic book |
控制台消费topic的数据:
--from-beginning:指定从头消费数据。
1 | bin/kafka-console-consumer.sh --zookeeper master:2181 --topic book --from-beginning |
停止kafka
1 | bin/kafka-server-stop.sh |
4.安装Kafka-Manager
4.1介绍
为了简化开发者和服务工程师维护Kafka集群的工作,yahoo构建了一个叫做Kafka管理器的基于Web工具,叫做 Kafka Manager。这个管理工具可以很容易地发现分布在集群中的哪些topic分布不均匀,或者是分区在整个集群分布不均匀的的情况。它支持管理多个集群、选择副本、副本重新分配以及创建Topic。同时,这个管理工具也是一个非常好的可以快速浏览这个集群的工具,有如下功能,这款工具主要支持以下几个功能:
- 管理多个不同的集群;
- 很容易地检查集群的状态(topics, brokers, 副本的分布, 分区的分布);
- 选择副本;
- 产生分区分配(Generate partition assignments)基于集群的当前状态;
- 重新分配分区。
4.2安装
安装kafka2.0.0.2的同学可以参看此文章:https://www.cnblogs.com/coding-farmer/p/12097519.html
我安装kafka-manager-1.3.3.7.zip
链接:https://pan.baidu.com/s/1eQAhsimciKz0DSM7ehMa2A
提取码:1fo8
此链接中的kafka-manager-1.3.3.7.zip已经编译完成
4.2.1解压安装包
1 | unzip kafka-manager-1.3.3.7.zip |
4.2.2修改配置文件中kafka-manager.zkhosts
1 2 3 | vi application.conf kafka-manager.zkhosts="IP1:2181,IP2:2181,IP3:2181" |
4.2.3启动
1 | ./kafka-manager -Dconfig.file=../conf/application.conf -Dhttp.port=8080 & |
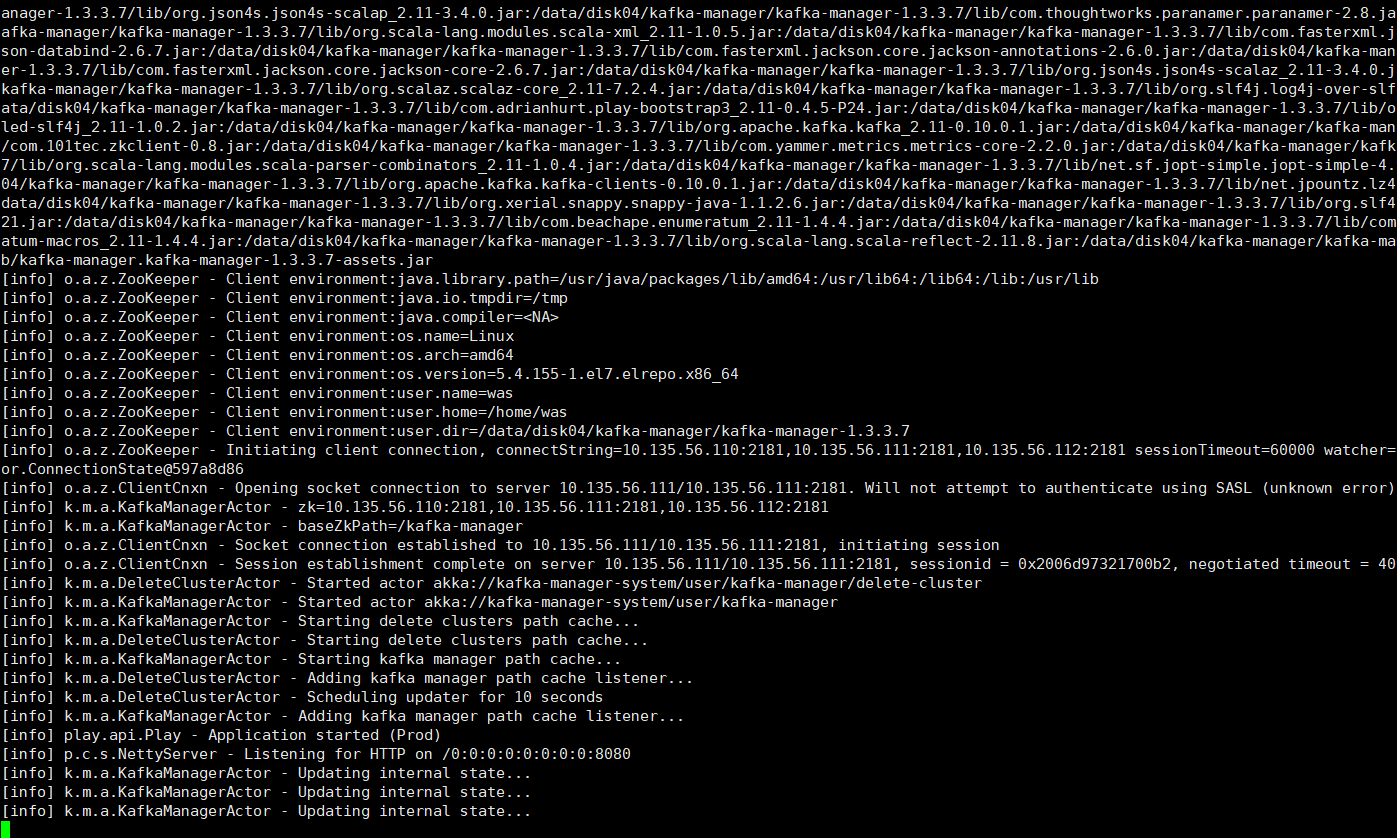
4.2.4浏览器访问
1 | ip:8080 |
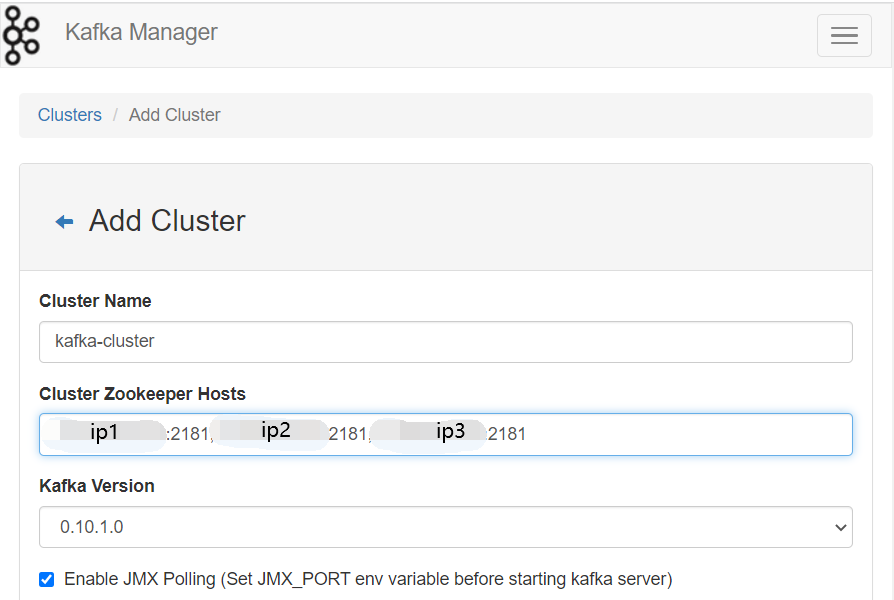
4.2.5监控配置

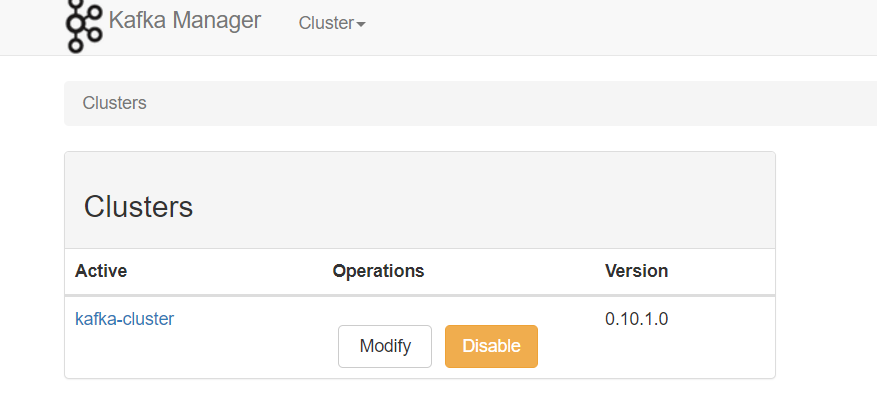
配置完保存会出现
访问http://IP1:8080/clusters/kafka-cluster/brokers

.jpg)

【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 无需6万激活码!GitHub神秘组织3小时极速复刻Manus,手把手教你使用OpenManus搭建本
· C#/.NET/.NET Core优秀项目和框架2025年2月简报
· 葡萄城 AI 搜索升级:DeepSeek 加持,客户体验更智能
· 什么是nginx的强缓存和协商缓存
· 一文读懂知识蒸馏