阿里云的自研InfluxDB集群方案剖析
2年前写的一篇旧文,文中的分析,以及探讨的问题和观点,至今仍有意义。
本文将以阿里云在GIAC的分享《云原生InfluxDB高可用架构设计》为例,剖析阿里云的自研InfluxDB集群方案的当前实现,在分析中会尽量聚焦的相对确定的技术、架构等,考虑到非一线信息,在个别细节上难免存在理解偏差,欢迎私聊讨论:
微信公众号:influxdb-dev
FreeTSDB技术交流群(QQ):663274123
0x0 初步结论
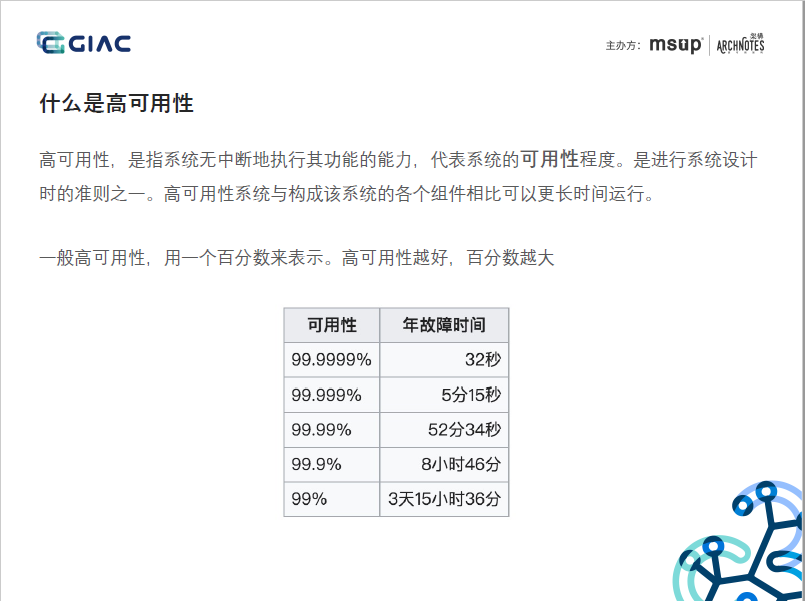
目前是一个过渡性质的公测方案,具备数据一致性,但接入性能有限,缺乏水平扩展能力。缺乏自定义副本数和水平扩展等能力,通过Raft或Anti-entroy提升了数据的可靠性,但受限于节点和副本的强映射,集群接入性能有限,约等同于单机接入性能,另外,基于时序分片和分布式迭代器等核心功能未提及,可能仍在预研中。
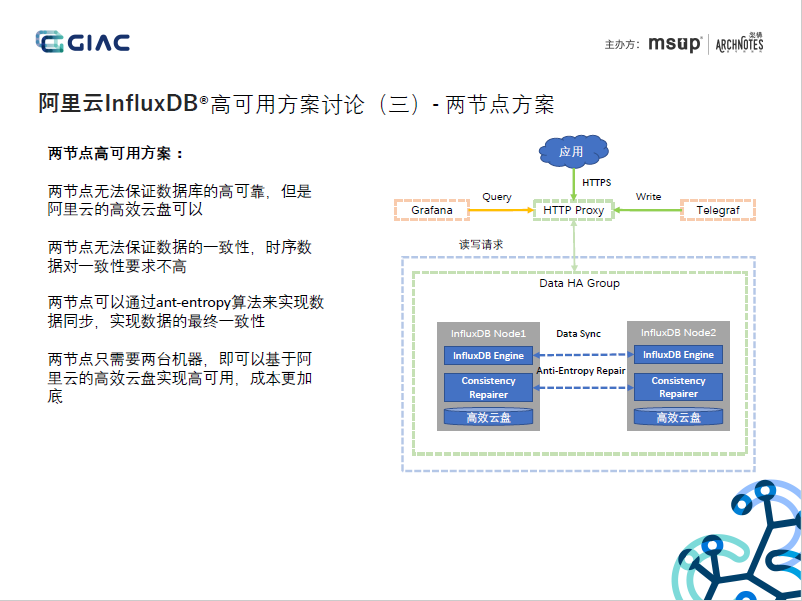
0x1 集群方案剖析
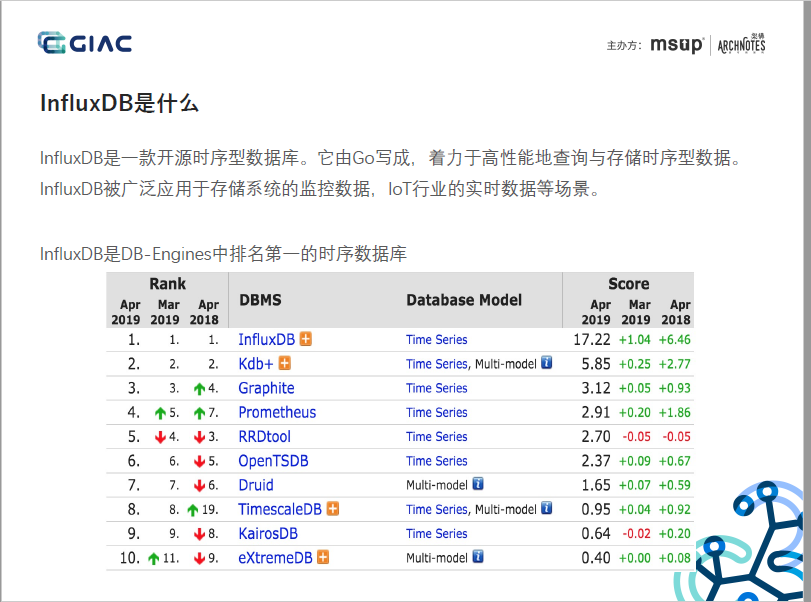
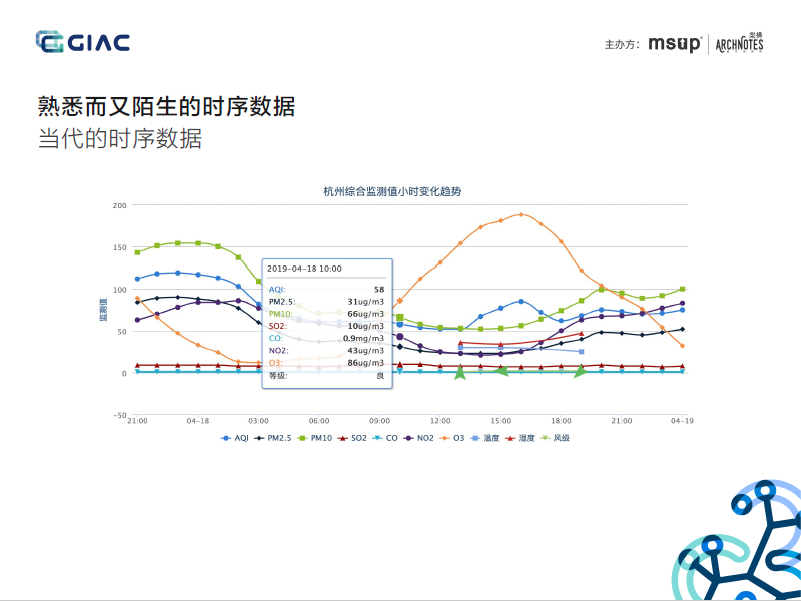
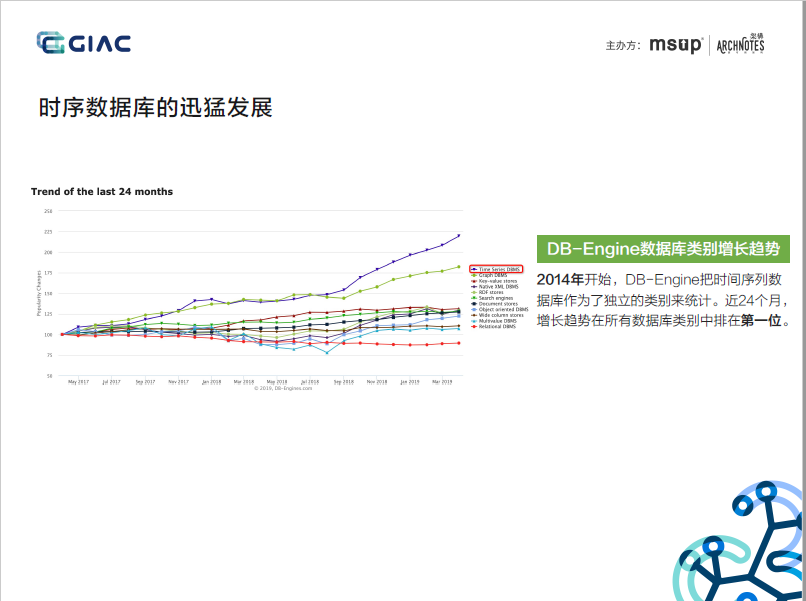
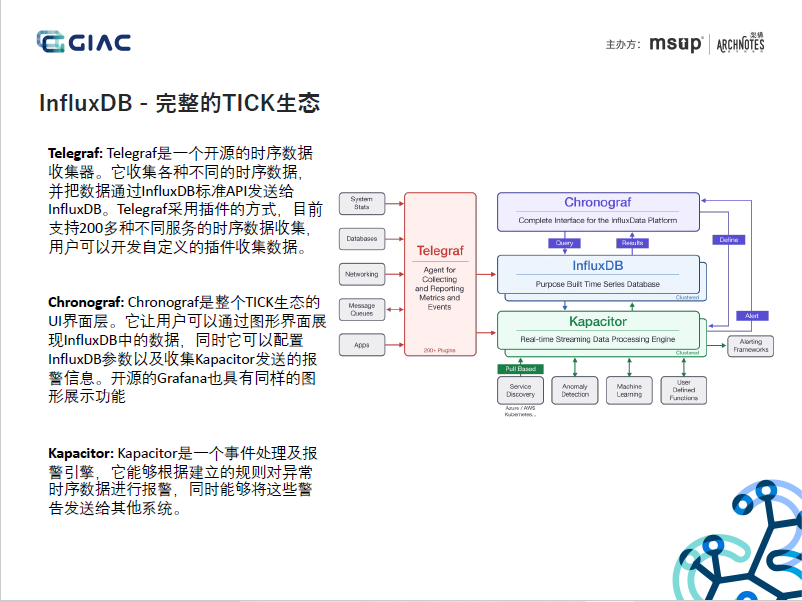
1. 背景补充:InfluxDB是DB-Engines上排名第一的TSDB,针对时序数据多写、少读、成本敏感等特点而设计的TSDB,并做了多轮架构迭代和优化,是一款实时、高性能、水平扩展(InfluxDB Enterprise)、具有成本优势的TSDB。但在2016年,Paul Dix基于商业化和持久运营的考虑,尚未成熟的集群能力在v0.11.1版后,选择闭源,推出了收费版的InfluxDB Enterprise和InfluxDB Cloud。
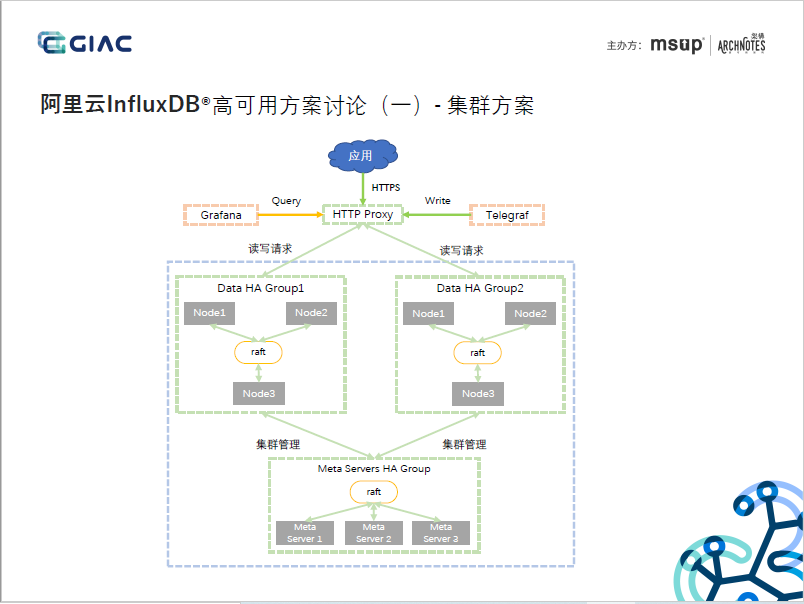
2. 通过Raft协议实现Meta节点的数据一致性,考虑到Meta节点存放的是Database/Rention Policy/Shard Group/Shard Info等元信息,这些信息敏感,是系统稳定运行的的关键,CP的分布式架构,合适。
3. 通过Raft协议实现Data节点的数据一致性,考虑到Data节点存储的是具体的时序数据,性能和水平扩展性是挑战,对一致性性要求不高(PPT中亦提到这一点),采用CP的分布式架构,节点和副本强映射,不仅对实时性有影响,集群接入性能亦有限,约等同于单机接入性能,不能很好的支持海量数据的实时接入的时序需求。
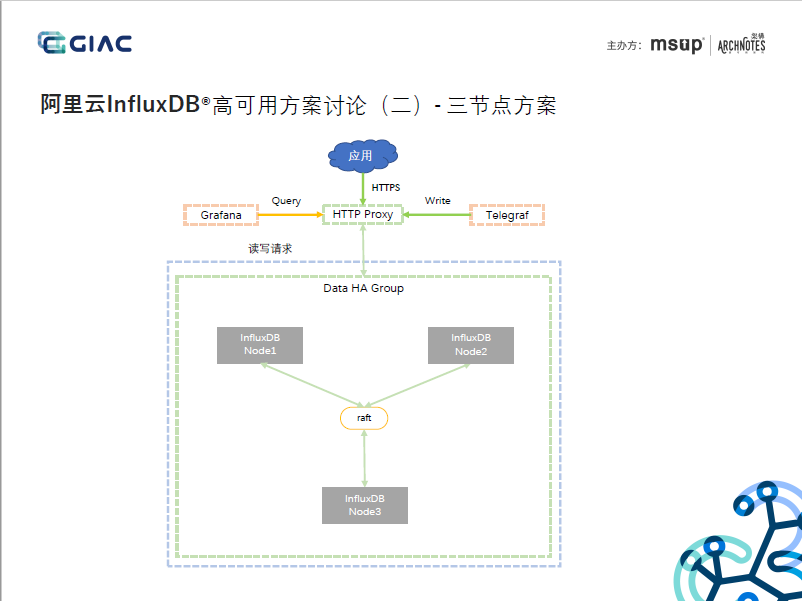
4. 2节点集群方案,通过Anti-entroy实现Data节点的数据一致性,应该还实现了Hinted-handoff能力,AP的分布式架构,但节点和副本还是强映射,未见提及基于时序分配、自定义副本数、分布式迭代器等能力,暂无法水平扩展。
5. 云盘能保障数据的可靠性,但无法保障接入的可用性,可用性敏感的业务或实时要求高的业务,还是推荐多节点的集群模式。
6. 开源版InfluxDB(单机)性能不错,InfluxDB Enterprise性能不错,但如何保障补齐集群能力的卓越性能,取决于集群架构、并发架构等,是由集群功能的开发者决定的,这次未见提及性能数据,期待后续的公布。
0x2 附录