

InfluxDB从原理到实战 - 什么是InfluxDB
0x00 什么是InfluxDB
InfluxDB是一个由InfluxData开发的开源时序型数据库,专注于海量时序数据的高性能读、高性能写、高效存储与实时分析等,在DB-Engines Ranking时序型数据库排行榜上排名第一,广泛应用于DevOps监控、IoT监控、实时分析等场景。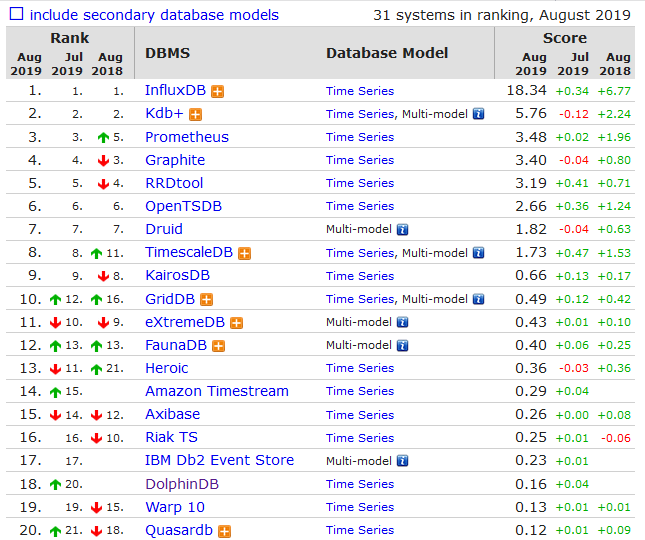
InfluxDB部署简单、使用方便,在技术实现上充分利用了Go语言的特性,无需任何外部依赖即可独立部署。提供类似于SQL的查询语言,接口友好,使用方便。丰富的聚合运算和采样能力,提供灵活的数据保存策略(Retention Policy)来设置数据的保留时间和副本数,在保障数据可靠性的同时,及时删除过期数据,释放存储空间,提供灵活的连续查询(Continues Query)来实现对海量数据的采样。支持协议种类多,除了HTTP、UDP等原生协议,还兼容CollectD、Graphite、OpenTSDB、Prometheus等组件的通讯协议。
强大完整的生态,TICK是一个集成了采集、存储、分析、可视化等能力的开源时序中台,由Telegraf、 InfluxDB、Chronograf、Kapacitor 4个组件以一种灵活松散组合、但紧密配合互为补充的方式构成,各个模块项目配合、互为补充,专注于DevOps监控、IoT监控、实时分析等场景。
Telegraf是一个用于采集和上报指标的服务器程序,采集当前运行主机的指定指标,如,CPU负载等,通过标准的InfluxDB API上报InfluxDB。
InfluxDB是专注于时序数据场景(如,DevOps监控、IoT监控、实时分析等)的高性能时序型数据库,支持灵活的自定义保留策略(Retention Policy)和类SQL的操作接口等。
Chronograf是可视化的UI界面层,通过图形界面暂时InfluxDB中的数据,并支持Kapacitor告警等。
Kapacitor是一个事件处理和告警引擎,支持灵活强大的自定义功能,也支持集成对接第三系统,如,HipChat等。
0x01 InfluxDB的优势
InfluxDB专注于DevOps监控、IoT监控等场景,针对时序存储、高性能读写、实时操作、高可用性而设计的一套软件,从零设计架构和开发,InfluxDB通过实现高度可扩展的数据接收和存储引擎,可以高效地实时收集、存储、查询、可视化显示和执行预定义操作。它通过采样和数据保留策略,以支持将高价值、高精度数据保存在内存中,将低价值数据保存到磁盘。作为一套精心设计、架构卓越的专用系统,相比OpenTSDB、MongoDB、Graphite、Cassandra等,InfluxDB的性能优势和成本优势明显。
InfluxDB的写性能是OpenTSDB的5倍,存储效率是OpenTSDB的16.5倍,查询效率是OpenTSDB的3.65倍。
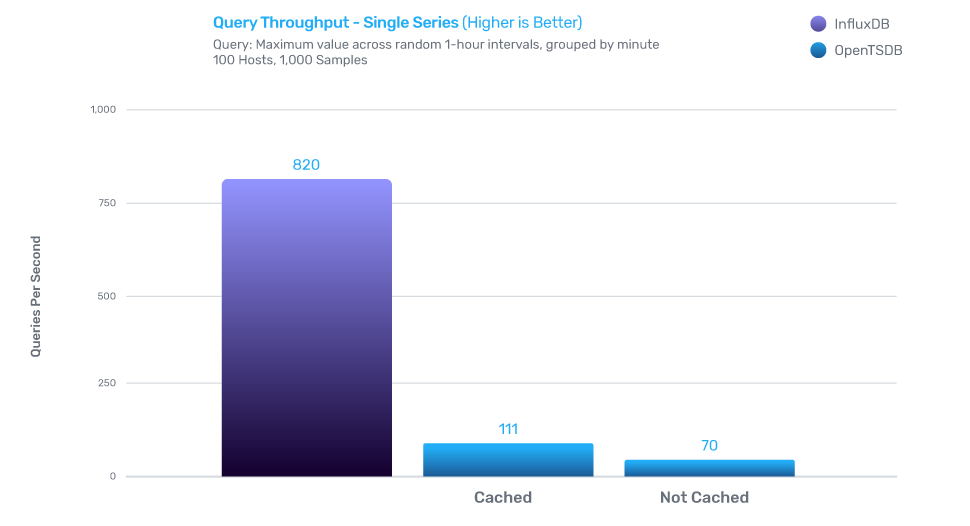
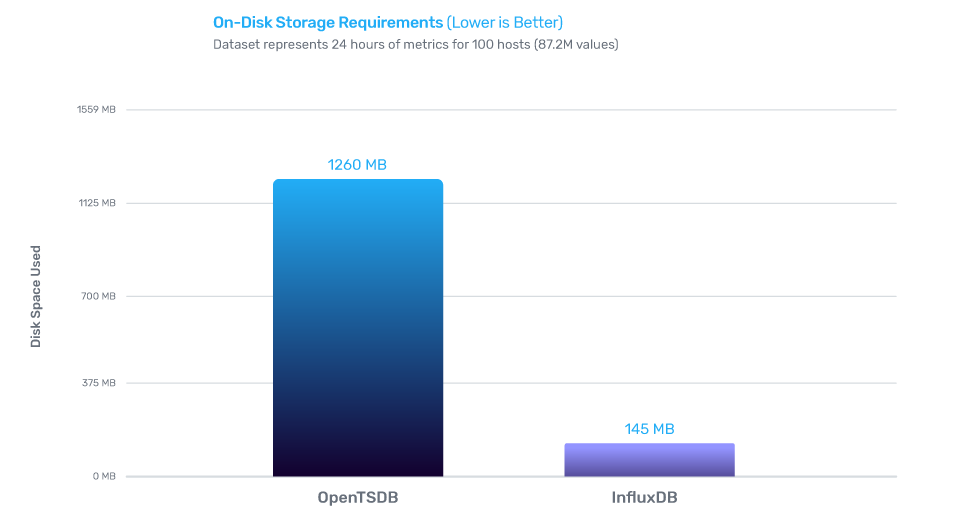
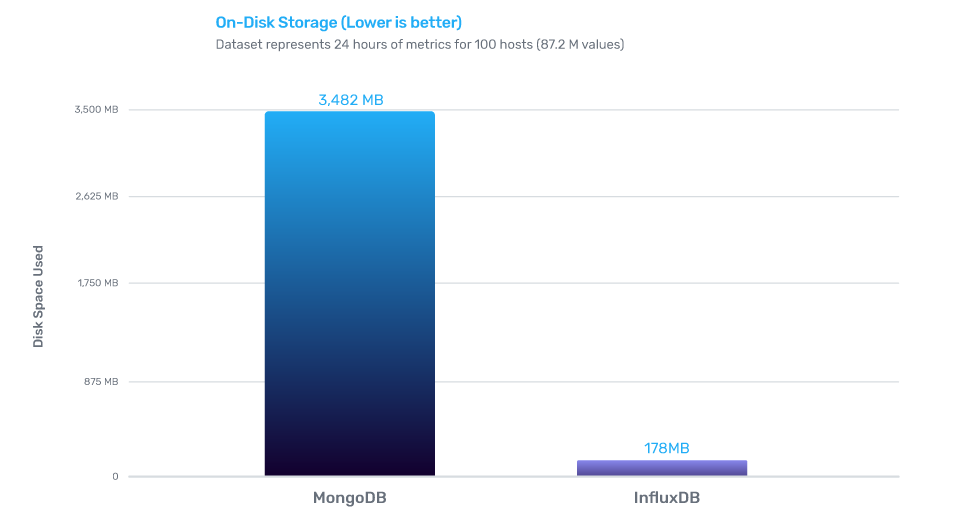
InfluxDB的写性能是MongoDB的2.4倍,存储效率是MongoDB的20倍,查询效率是MongoDB的5.7倍。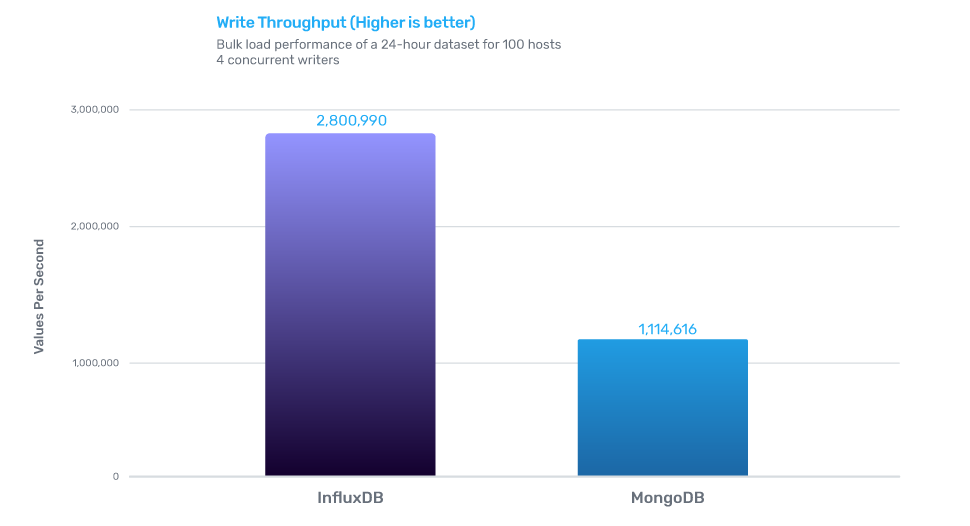

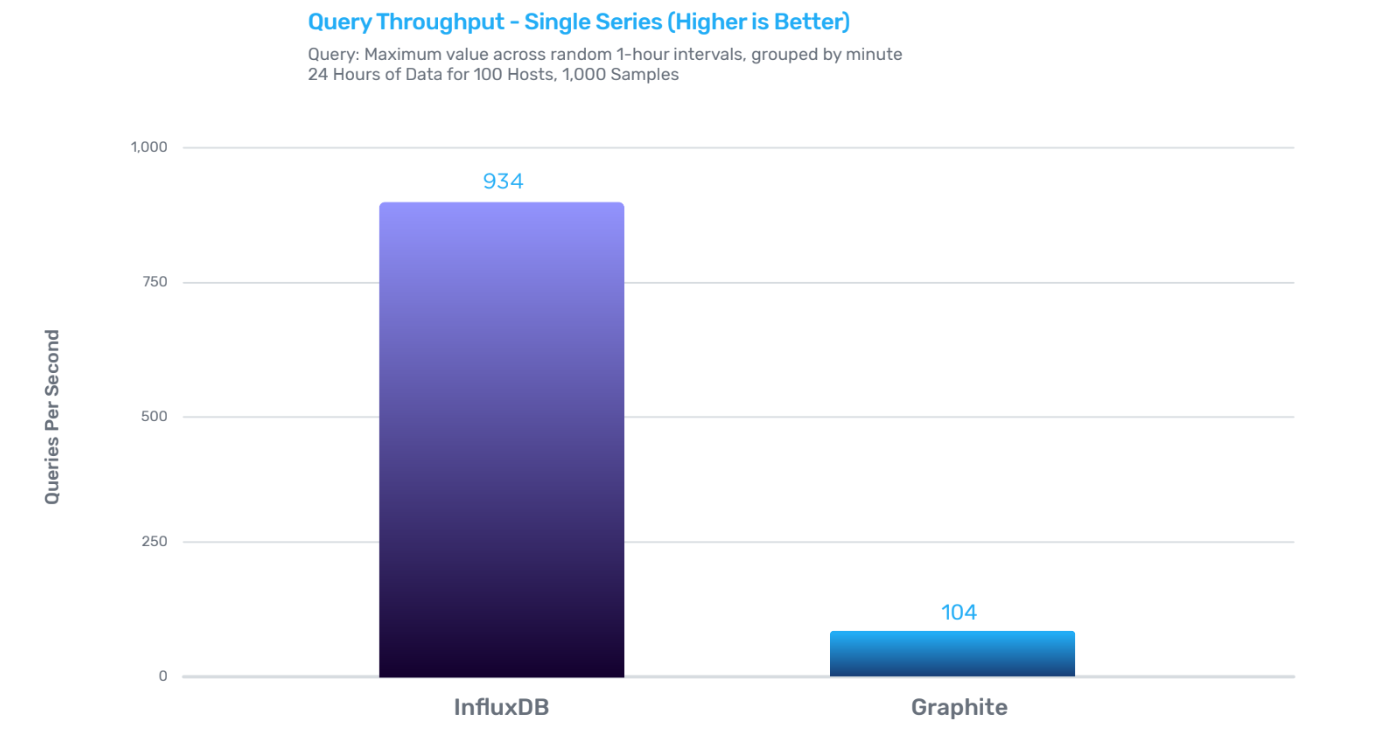
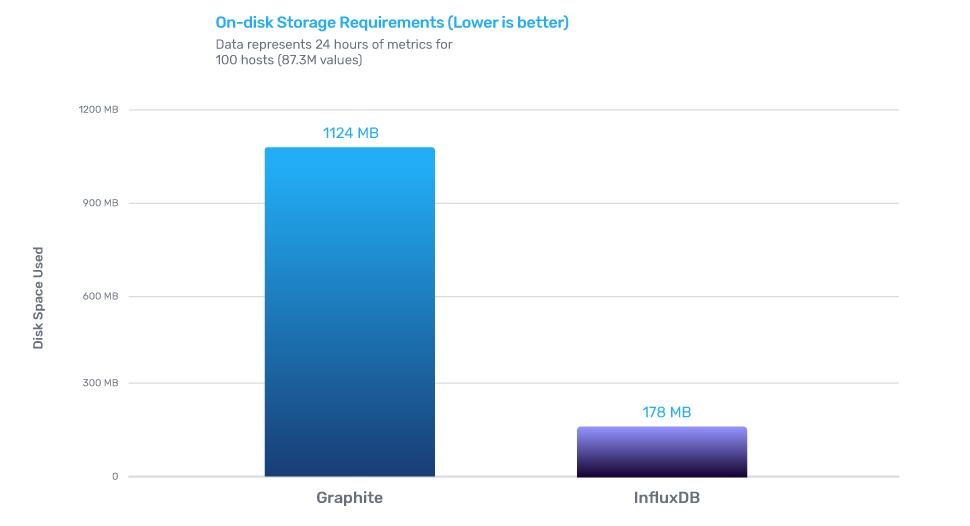
InfluxDB的写性能是Graphite的12倍,存储效率是Graphite的6.3倍,查询效率是Graphite的9倍。
InfluxDB的写性能是Cassandra的4.5倍,存储效率是Cassandra的2.1倍,查询效率是Cassandra的45倍。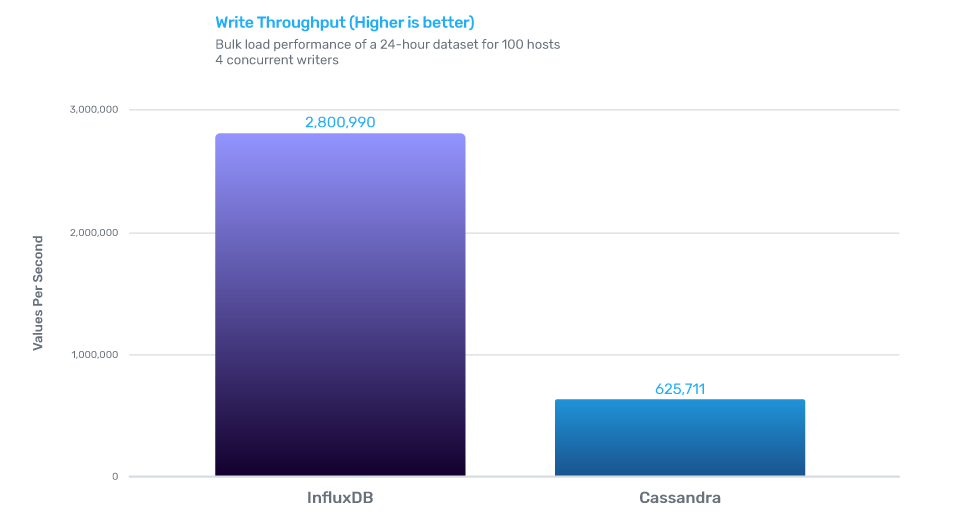


0x03 InfluxDB的特性
InfluxDB是一种时序数据高效读写、压缩存储、实时计算能力为一体的数据库服务,除了具有成本优势的高性能读、高性能写、高存储率,InfluxDB还具有如下特点:
无系统环境依赖,部署方便。无结构化(SchemaLess)的数据模型,灵活强大。原生HTTP管理接口,免插件配置和免第三方依赖。强大的类SQL查询语句的操作接口,学习成本低,上手快。丰富的权限管理功能,精细到“表”级别。丰富的时效管理功能,自动删除过期数据,自定义删除指标数据。低成本存储,采样时序数据,压缩存储。丰富的聚合函数,支持AVG、SUM、MAX、MIN等聚合函数。
后记:
欢迎交流讨论:
微信公众号:influxdb-dev。
InfluxDB技术交流群(QQ):663274123。

