

spark的task调度器(FAIR公平调度算法)
FAIR 调度策略的树结构如下图所示:
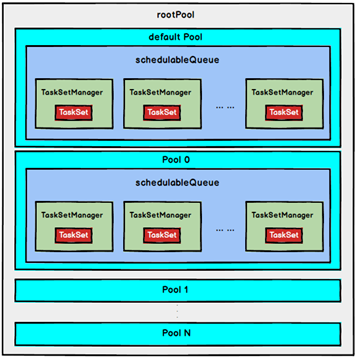
FAIR 调度策略内存结构
FAIR 模式中有一个 rootPool 和多个子 Pool, 各个子 Pool 中存储着所有待分配的 TaskSetMagager 。
在 FAIR 模 式 中 , 需 要 先 对 子 Pool 进 行 排 序 , 再 对 子 Pool 里 面 的
TaskSetMagager 进行排序,因为 Pool 和 TaskSetMagager 都继承了 Schedulable 特质, 因此使用相同的排序算法。
排序过程的比较是基于 Fair-share 来比较的,每个要排序的对象包含三个属性:
runningTasks 值( 正在运行的 Task 数)、minShare 值、weight 值,比较时会综合考量 runningTasks 值, minShare 值以及 weight 值。
注意,minShare、weight 的值均在公平调度配置文件 fairscheduler.xml 中被指定,调度池在构建阶段会读取此文件的相关配置。
1) 如果 A 对象的 runningTasks 大于它的 minShare, B 对象的 runningTasks 小于它的 minShare,那么 B 排在 A 前面; ( runningTasks比 minShare小的先执行)
2) 如果 A 、B 对象的 runningTasks 都小于它们的 minShare ,那么就比较runningTasks 与 minShare 的比值( minShare 使用率),谁小谁排前面;( minShare使用率低的先执行)
3) 如果 A 、B 对象的 runningTasks 都大于它们的 minShare ,那么就比较runningTasks 与 weight 的比值( 权重使用率),谁小谁排前面。(权重使用率低的先执行)
4) 如果上述比较均相等,则比较名字。
整体上来说就是通过 minShare 和 weight 这两个参数控制比较过程, 可以做到让 minShare 使用率和权重使用率少( 实际运行 task 比例较少) 的先运行。
private[spark] class FairSchedulingAlgorithm extends SchedulingAlgorithm {
override def comparator(s1: Schedulable, s2: Schedulable): Boolean = {
val minShare1 = s1.minShare
val minShare2 = s2.minShare
默认为0,除非通过fair的配置文件进行了配置指定
val runningTasks1 = s1.runningTasks
val runningTasks2 = s2.runningTasks
如果是TaskSetManager时,就是taskSet中运行的task的个数,
如果是Pool实例是表示是所有使用这个poolName的所有的TaskSetManager正在运行的task的个数.
val s1Needy = runningTasks1 < minShare1
val s2Needy = runningTasks2 < minShare2
只有在minShare在fair的配置文件中显示配置,同时大于正在运行的task的个数时,才会为true
val minShareRatio1 = runningTasks1.toDouble / math.max(minShare1, 1.0).toDouble
val minShareRatio2 = runningTasks2.toDouble / math.max(minShare2, 1.0).toDouble
运行的task的个数针对于minShare的比重
val taskToWeightRatio1 = runningTasks1.toDouble / s1.weight.toDouble
val taskToWeightRatio2 = runningTasks2.toDouble / s2.weight.toDouble
得到正在运行的task个数针对于pool的weight的比重
var compare: Int = 0
这里首先根据正在运行的task的个数是否已经达到调度队列中最小的分片的个数来进行排序,
如果s1中运行运行的个数小于s1的pool的配置的minShare,返回true,表示s1排序在前面.
如果s2中运行的task的个数小于s2的pool中配置的minShare(最小分片数)的值,表示s1小于s2,这时s2排序应该靠前.
if (s1Needy && !s2Needy) {
return true
} else if (!s1Needy && s2Needy) {
return false
} else if (s1Needy && s2Needy) {
这种情况表示s1与s2两个队列中,正在运行的task的个数都已经大于(不小于)了两个子调度器中配置的minShare的个数时,根据两个子调度器队列中正在运行的task的个数对应此调度器中最小分片的值所占的比重最小的一个排序更靠前
compare = minShareRatio1.compareTo(minShareRatio2)
} else {
这种情况表示s1与s2两个子调度器的队列中,正在运行的task的个数都还没有达到配置的最小分片的个数的情况,比较两个队列中正在运行的task的个数对应调度器队列的weigth的占比,最小的一个排序更靠前
compare = taskToWeightRatio1.compareTo(taskToWeightRatio2)
}
if (compare < 0) {
true
} else if (compare > 0) {
false
} else {
如果两个根据上面的计算,排序值都相同,就看看这两个调度器的名称,按名称的字节序来排序了.
s1.name < s2.name
}
}
}

