

Spark中的CombineKey()详解
CombineKey()是最常用的基于键进行聚合的函数,大多数基于键聚合的函数都是用它实现的。和aggregate()一样,CombineKey()可以让用户返回与输入数据的类型不同的返回值。要理解CombineKey()需要先理解它在数据处理时是如何处理每个元素的。由于CombineKey()会遍历分区中的所有元素,因此每个元素的键要么还没有遇到,要么就是和之前的额某个元素的键相同。
如果遇到的是一个新元素,CombineKey()会使用一个叫做createCombiner()的函数来创建那个键对应的累加器的初始值,需要注意的是,这一过程会在每个分区中第一次出现各个键时发生,而不是在整个RDD中第一次出现时发生。
如果这是一个在处理当前分区之前已经遇到的键,它会使用mergeValue()方法将该键的累加器对应的值与这个新的值进行合并。
由于每个分区都是独立处理的,因此对于同一个键可以有多个累加器。如果有两个或者更多的分区都有对应同一个键的累加器,就需要使用用户提供的mergeCombiners()方法将各个分区的结果进行合并。
如果已知数据在进行combineByKey() 时无法从map 端聚合中获益的话,可以禁用它。例如,由于聚合函数(追加到一个队列)无法在map 端聚合时节约任何空间,groupByKey() 就把它禁用了。如果希望禁用map 端组合,就需要指定分区方式。就目前而言,你可以通过传递rdd.partitioner 来直接使用源RDD 的分区方式。
combineByKey() 有多个参数分别对应聚合操作的各个阶段,因而非常适合用来解释聚合操作各个阶段的功划分。为了更好地演示combineByKey() 是如何工作的,下面来看看如何计算各键对应的平均值:
在Python 中使用combineByKey() 求每个键对应的平均值
sumCount = nums.combineByKey((lambda x: (x,1)), (lambda x, y: (x[0] + y, x[1] + 1)), (lambda x, y: (x[0] + y[0], x[1] + y[1]))) sumCount.map(lambda key, xy: (key, xy[0]/xy[1])).collectAsMap()
在Scala 中使用combineByKey() 求每个键对应的平均值
val result = input.combineByKey(
(v) => (v, 1),
(acc: (Int, Int), v) => (acc._1 + v, acc._2 + 1),
(acc1: (Int, Int), acc2: (Int, Int)) => (acc1._1 + acc2._1, acc1._2 + acc2._2)
).map{ case (key, value) => (key, value._1 / value._2.toFloat) }
result.collectAsMap().map(println(_))
在Java 中使用combineByKey() 求每个键对应的平均值
public static class AvgCount implements Serializable {
public AvgCount(int total, int num) { total_ = total; num_ = num; }
public int total_;
public int num_;
public float avg() { returntotal_/(float)num_; }
}
Function<Integer, AvgCount> createAcc = new Function<Integer, AvgCount>() {
public AvgCount call(Integer x) {
return new AvgCount(x, 1);
}
};
Function2<AvgCount, Integer, AvgCount> addAndCount =
new Function2<AvgCount, Integer, AvgCount>() {
public AvgCount call(AvgCount a, Integer x) {
a.total_ += x;
a.num_ += 1;
return a;
}
};
Function2<AvgCount, AvgCount, AvgCount> combine =
new Function2<AvgCount, AvgCount, AvgCount>() {
public AvgCount call(AvgCount a, AvgCount b) {
a.total_ += b.total_;
a.num_ += b.num_;
return a;
}
};
AvgCount initial = new AvgCount(0,0);
JavaPairRDD<String, AvgCount> avgCounts =
nums.combineByKey(createAcc, addAndCount, combine);
Map<String, AvgCount> countMap = avgCounts.collectAsMap();
for (Entry<String, AvgCount> entry : countMap.entrySet()) {
System.out.println(entry.getKey() + ":" + entry.getValue().avg());
}
combineByKey() 数据流示意图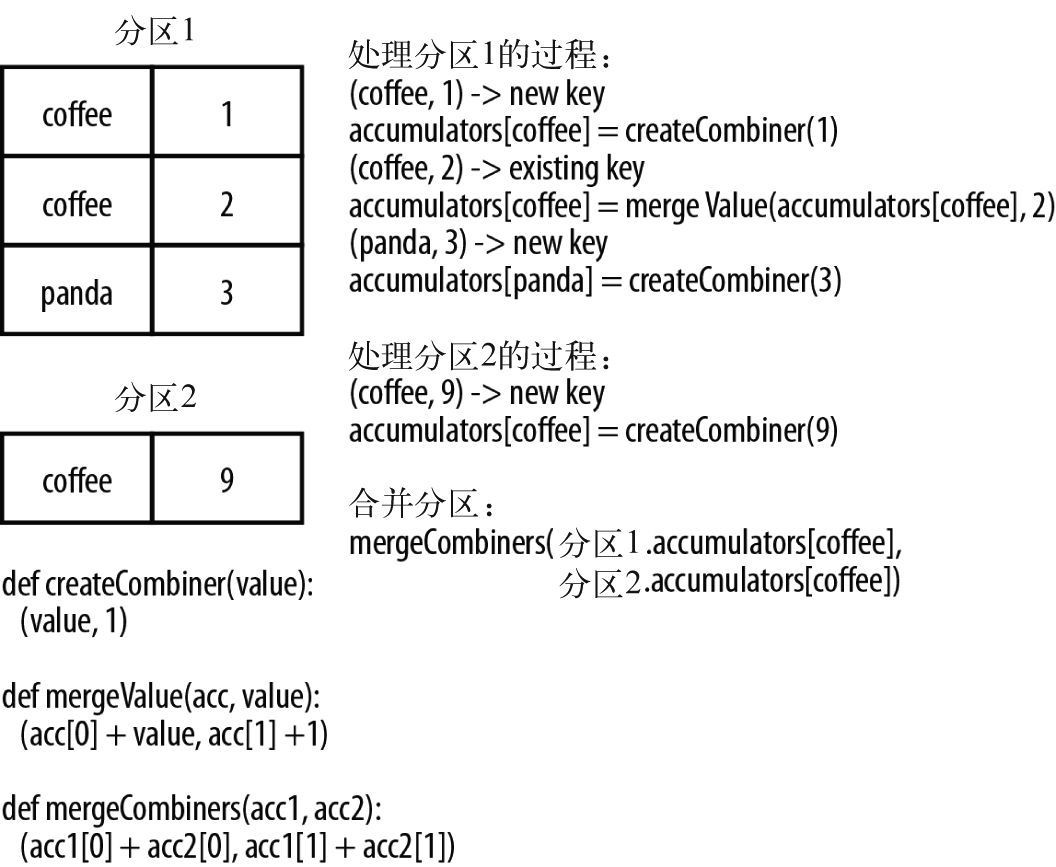
有很多函数可以进行基于键的数据合并。它们中的大多数都是在combineByKey() 的基础上实现的,为用户提供了更简单的接口。不管怎样,在Spark 中使用这些专用的聚合函数,始终要比手动将数据分组再归约快很多。

