如果你的应用程序时Oracle数据库,那么将字符串写入到大字段(Blob)列中是一种常见的操作,现作简单介绍:
先建立一个简单的表:
(
ID VARCHAR2(10),
ORIGNDATA BLOB
)
ORIGNDATA 列为BLOB大字段数据类型.
然后直接上两个方法:
 View Code
View Code

public void InsertStringToClob()
{
System.Data.OracleClient.OracleConnection con = new System.Data.OracleClient.OracleConnection();
con.ConnectionString = "Data Source=Orcl; User Id=gctest; Password=his;";//数据库连接串
con.Open();
using (OracleCommand cmd = new OracleCommand())
{
cmd.CommandType = CommandType.Text;
cmd.Connection = con;
cmd.CommandText = @"
insert into EMRSIGNINFO(ID,ORIGNDATA) values(
'1',
:temp
)
";
OracleParameter param = cmd.Parameters.Add(":temp", OracleType.Blob);
param.Direction = ParameterDirection.Input;
string strOriginText = @"CzFe3B9mgc1kv3bYldRbMqp9AkCW84EPjBOZZYI+Y0yYgFaDRk4kjmvAuDyF3OAPbCyXoSdzLImG2Y956y/KJV8d3cS0sfjeBLFiFbUXdXfzzgZ23c
r44QlMreS9+lIOV0jyd+yX3Spse34rNJwa/aD8i6LTXRCFxfb6Tx1GRj4=CzFe3B9mgc1kv3bYldRbMqp9AkCW84EPjBOZZYI+Y0yYgFaDRk4kjmvAuDyF3OAPbCyXoSdzLImG2Y956y
/KJV8d3cS0sfjeBLFiFbUXdXfzzgZ23cr44QlMreS9+lIOV0jyd+yX3Spse34rNJwa/aD8iCzFe3B9mgc1kv3bYldRbMqp9AkCW84EPjBOZZYI+Y0yYgFaDRk4kjmvAuDyF3OA
PbCyXoSdzLImG2Y956y/KJV8d3cS0sfjeBLFiFbUXdXfzzgZ23cr44QlMreS9+lIOV0jyd+yX3Spse34rNJwa/aD8i6LTXRCFxfb6Tx1GRj4=6LTXRCFxfb6Tx1GRj4=";
param.Value = CompressString(strOriginText);
try
{
cmd.ExecuteNonQuery();
}
catch (Exception ex)
{
MessageBox.Show(ex.Message);
}
}
con.Close();
}
//读取大字段中存储的字符串
public string ReadClobToString()
{
string strSql = "select * from EMRSIGNINFO where id='1'";
string result=string.Empty;
System.Data.OracleClient.OracleConnection con = new System.Data.OracleClient.OracleConnection();
con.ConnectionString = "Data Source=Orcl; User Id=gctest; Password=his;";
con.Open();
using (OracleCommand cmd = new OracleCommand())
{
cmd.CommandType = CommandType.Text;
cmd.Connection = con;
cmd.CommandText = strSql;
try
{
OracleDataReader reader = cmd.ExecuteReader();
while (reader.Read())
{
result = DecompressString((byte[])reader[1]);
}
}
catch (Exception ex)
{
}
}
con.Close();
return result;
}
针对以上的几点说明:
1、大字段数据列在sql语句中使用冒号(:)加一个任意名称进行占位,如以上第一个方法中的sql语句中的:temp 。然后为Command添加参数,参数名称也为:temp,参数类型为OracleType.Blob。
2、参数的值(Value)应该是 一个 Byte[]类型。在第一个方法中,对参数赋值时采用了一个方法CompressString将字符串转换为Byte[]类型数据。
如果上面直接将字符串对参数赋值 param.Value = strOriginText;将产生如下错误:
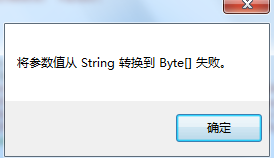
3、第二个方法中读取大字段的时候:使用Read(),当读取到大字段的数据时,先将数据转换为byte[]类型,然后使用一个方法将字节数组解压缩为字符串。
4、微软已经不推荐使用OracleConnection 、OracleCommand 等,而是推荐使用Oracle开发的ODP.NET,这会比微软为Oracle开发的适配器强大。此处为演示,使用大家熟知的了。
5、以上程序没有添加任何其他考虑,比如:如果大字段中的数据可为空,那么在读取的时候此处(byte[])reader[1]会报错,因为reader[1]是一个System.DBNull类型,是不能转换为byte[]类型的。这些都是没有考虑到的哦。另外也没有考虑如果是多个大字段的话如何处理,如果是一个sql语句中要写入多个大字段列,可以使用params语法,具体不介绍。
6、每个公司自己的产品中都有一套框架来处理这种底层的数据库才做,会对这些操作进行封装,使之在易用性、安全性、复用性等等方面进行增强。可以肯定的是,不会有任何一个公司的代码会写成以上这样。您在公司要操作大字段可能只是简单的调用一个非常简单的方法即可,但是如果有时间还是建议对里面的原理做些了解。如此才能吸取经验、懂得原理,才不会为各种新技术、新工具所迷惑。
7、以上两个方法中使用的DecompressString和DecompressString方法为网上找的轮子。也贴出来吧。要说明的是,需要引用ICSharpCode.SharpZipLib.dll。它的使用说明此处就不介绍了,有兴趣的朋友找谷歌。
View Code
/// 用压缩算法压缩一个字符串
/// </summary>
/// <param name="input">输入的字符串.</param>
/// <returns>返回字节</returns>
public byte[] CompressString(string input)
{
return CompressBytes(Encoding.UTF8.GetBytes(input));
}
/// <summary>
/// Decompress a byte stream of a string that was formerly
/// compressed with the CompressString() routine with the ZIP algorithm.
/// </summary>
/// <param name="input">The buffer that contains the compressed
/// stream with the string.</param>
/// <returns>Returns the decompressed string.</returns>
public string DecompressString(
byte[] input)
{
return Encoding.UTF8.GetString(DecompressBytes(input));
}
/// <summary>
/// 用压缩算法压缩字节
/// </summary>
/// <param name="input">需要压缩的字节</param>
/// <returns>返回压缩的字节</returns>
public byte[] CompressBytes(byte[] input)
{
using (MemoryStream buf = new MemoryStream())
using (ZipOutputStream zip = new ZipOutputStream(buf))
{
Crc32 crc = new Crc32();
zip.SetLevel(9); // 0..9.
ZipEntry entry = new ZipEntry(string.Empty);
entry.DateTime = DateTime.Now;
entry.Size = input.Length;
crc.Reset();
crc.Update(input);
entry.Crc = crc.Value;
zip.PutNextEntry(entry);
zip.Write(input, 0, input.Length);
zip.Finish();
// --
byte[] c = new byte[buf.Length];
buf.Seek(0, SeekOrigin.Begin);
buf.Read(c, 0, c.Length);
// --
zip.Close();
return c;
}
}
/// <summary>
/// Decompress a byte stream that was formerly compressed
/// with the CompressBytes() routine with the ZIP algorithm.
/// </summary>
/// <param name="input">The buffer that contains the compressed
/// stream with the bytes.</param>
/// <returns>Returns the decompressed bytes.</returns>
public byte[] DecompressBytes(
byte[] input)
{
using (MemoryStream mem = new MemoryStream(input))
using (ZipInputStream stm = new ZipInputStream(mem))
using (MemoryStream mem2 = new MemoryStream())
{
ZipEntry entry = stm.GetNextEntry();
if (entry != null)
{
byte[] data = new byte[4096];
while (true)
{
int size = stm.Read(data, 0, data.Length);
if (size > 0)
{
mem2.Write(data, 0, size);
}
else
{
break;
}
}
}
using (BinaryReader r = new BinaryReader(mem2))
{
byte[] c = new byte[mem2.Length];
mem2.Seek(0, SeekOrigin.Begin);
r.Read(c, 0, (int)mem2.Length);
return c;
}
}
}
欢迎大家交换意见,欢迎拍砖。

