MySQL-带你上官网看索引
2022-12-22 11:54 杭伟 阅读(206) 评论(0) 收藏 举报在我之前的一篇文章中,有引用一个讨论用Hash还是Tree的问题,DB中关于查找类数据结构,除了树,还有Hash(HashMap,HashSet)。
存储数据结构之争
B+树主要是照顾磁盘IO这种特殊的性质应运而生的;然而在内存够多够大时,Hash某些时候比Tree结构有用得多。
但是Hash做索引的缺点也非常明显:
1,Hash冲突造成的散列不均匀,线性查找浪费时间;
2,不支持范围查询,避免不了全表扫描;
3,内存空间要求高。
MySQL中,InnoDB和MyISAM默认的索引是B+ Tree索引;Memory则同时支持Hash和Tree索引(可在创建时直接指定使用何种索引,具体移步)。
同时,Memory这种存储引擎“断电即毁”的特性也不再推荐使用。
B树和B+树之争
前置知识:知道mysql中索引即数据,数据即索引(页的存储结构);知道为何采用B树(多路平衡查找树),知道为何实际采用了B+树。
1,B+树空间利用率更高。B+树只在叶子节点存储实际数据,非叶子节点,B+树有了更多的空间存储索引,这样B+树越靠近矮胖,IO减少,
磁盘读写代价低,检索效率变高。
2,B+树查询效率更稳定。B+树的检索,任何检索路径都需要从根节点到叶子节点(只有叶子节点有数据),时间复杂度固定在O(LogN);
B树则在O(1)和O(LogN)之间。即二分查找。
3,B+树范围查询性能更优。 B+树的叶子节点使用了双向链表连接在一起,而且是严格的顺序存储,从左到右从小到大。
4,B+树由于叶子节点使用了链表进行串联,除了支持随机检索,还支持顺序检索。
一些常见概念
回表: 查询计划不是使用主键索引,即通过二级索引查找目标;而二级索引的B+树只存储了主键数据(索引列,主键),
如仍需要其它数据,需要再次根据主键去主键索引所在B+树查找一次数据的过程,即回表。
回表引发的问题:某些情况,使用了索引,但仍然触发了全表扫描(explain type='All')。因为此时查询优化器对比了回表IO次数和全表扫描的IO次数,选择了全表扫描。
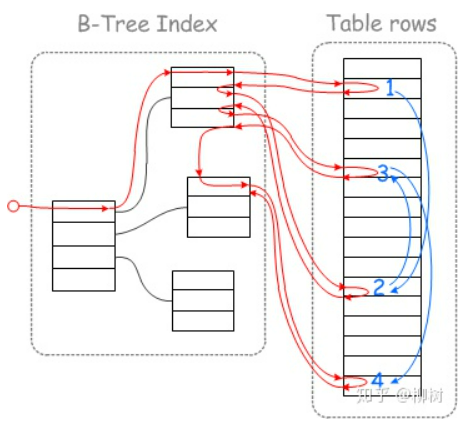
MRR:MRR全称:Multi-Range Read Optimization(多范围读取优化),动机是减少随机磁盘访问的次数,实现对基表数据的更顺序扫描。
官网的解释在这。即把随机磁盘读转化为顺序磁盘读,提高查询性能(磁头运动&磁盘预读)。本质在做一件以空间换时间的事情。
下面这个图很形象借用一下:(红线表示查询路线,蓝线表示磁盘/磁头运动路线)
未开启MRR:
开启MRR:
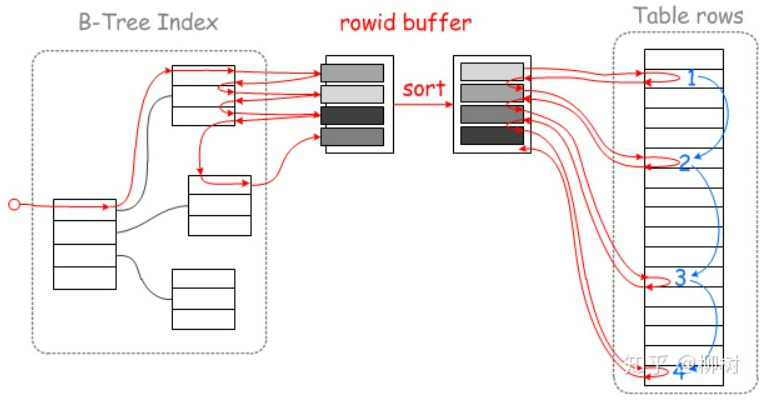
上面的图来自文章MySQL的MRR到底是什么?
以空间换时间,这个空间指的是内存,内存大小设置在系统变量read_rnd_buffer_size,设置请参考官网。
使用SQL命令:SELECT @@optimizer_switch
查看MRR是否已开启(默认开启)

索引覆盖:查询目标可直接从叶子节点获取数据,不需要回表,即为索引覆盖。
如下图:country_id是二级索引,查找目标刚好只查询主键索引和二级索引键值本身,直接使用二级索引的B+树就能查到。不需要回表,称为索引覆盖。


最左匹配原则(多列索引): 官网的解释在这里。
举例:
有组合索引信息如下:
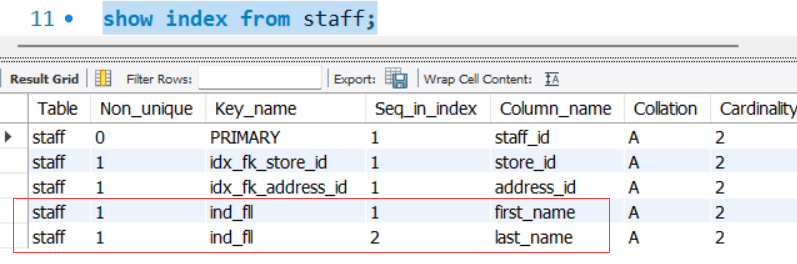
则验证的关键原则是:
-- 最左匹配原则要点: -- 1,组合索引第一列(最左)作为第一个条件,只有接or不走索引,其它情况全部走索引; -- 2,不以最左作为第一个条件,一般都不会走索引,唯有把组合索引条件都加上才会走(内部优化)。 explain select * from staff where first_name='Mike'; -- yes explain select * from staff where last_name='Hillyer'; -- no explain select * from staff where first_name='Mike' and last_name='Hillyer'; -- yes explain select * from staff where last_name='Hillyer' and first_name='Mike'; -- yes(内部优化) explain select * from staff where first_name='Mike' or last_name='Hillyer'; -- no explain select * from staff where first_name='Mike' and(last_name='Hillyer' or last_name=''); -- yes
索引(条件)下推:即ICP,全称是Index Condition Pushdown Optimization,官网的解释在这里。我们一般叫索引下推,其实正式应该称为:索引条件下推。
怎么理解?下推什么呢? 顾名思义,Condition Pushdown,把查询条件往下推。官网的这句:
With ICP enabled, ... , the MySQL server pushes this part of the WHERE condition down to the storage engine.
翻译即是:ICP启用后,把where条件的部分从server层下推到storage engine层。
需要先了解MySQL的大概架构:
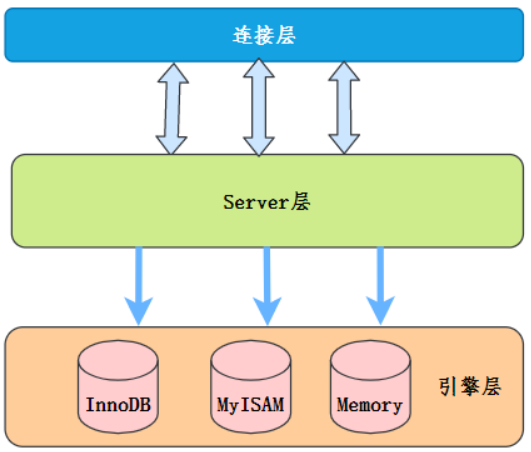
就是,原来where条件筛选在Server层这里,现在下推到存储引擎层去。
举例:
下表中,id是主键,name,age是联合索引。
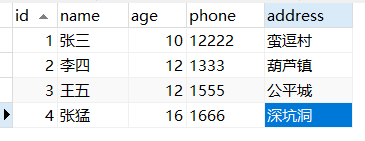
查找姓张且年龄是10岁的记录:select * from tuser where name like '张%' and age=10;

没有使用ICP:二级索引找到主键1和4,分别回表去查找对应的完整记录,Server层再根据where条件的age=10进行筛选。这个过程要回表两次。
使用ICP: 二级索引找到主键1和4,存储引擎层(Server的下层)根据联合索引where条件age=10进行筛选。根据筛选结果再回表查到完整记录。这个过程回表1次。
上面的ICP举例和图片出自这里。
使用执行计划分析时,使用索引下推在Extra栏位会出现:Using index condition信息,具体参见。
MySQL默认启用索引(条件)下推。系统设置变量为:index_condition_pushdown

避免全表扫描:官网的解释在这里。
使用查询计划分析时,对于大型表,应尽力避免type=All的情况。 表扫描非常昂贵。
本文阅读MySQL文档为5.7。
下一篇继续探索索引优化部分。
作者:hangwei
出处:http://www.cnblogs.com/hangwei/
关于作者:专注于开源平台,分布式系统的架构设计与开发、数据库性能调优等工作。如有问题或建议,请多多赐教!
版权声明:本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文链接。
如果您觉得文章对您有帮助,可以点击文章右下角“推荐”一下。您的鼓励是作者坚持原创和持续写作的最大动力!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号