B树和B+树
2022-11-25 11:16 杭伟 阅读(61) 评论(0) 收藏 举报上一篇讲到了红黑树,想到说树从二叉树演进到红黑树这样近乎“完美”的数据结构,那直接所有大数据类的场景都用红黑树好了?
也不对。比如:如果新增删除少,查询多,那还是平衡二叉搜索树更具优势。因为它更“平衡”查找效率更高(红黑树高度一般比平衡二叉树要高)。
然后我们所讨论的时间复杂度也更多的是指在内存中操作数据的场景。(另一个主角哈希表更快?)所以使用数据结构需要先考虑业务场景。
本篇还是继续树的部分,把树相关的基础理论过一遍。
因为理解B树和B+树需要一些计算机的其它知识。(没有B-树,早期老外文章说的B树写成了B-tree然后被国人翻译成了B-树一言难尽,B plus - tree呢?)
这里列一些理解B树和B+树的前置知识点:
1,磁盘结构
2,数据是怎样存储在磁盘中的
3,什么是索引,什么是多级索引?
这里说明一下,像mysql这种数据库,分为数据和索引,都是存储在磁盘轨道和扇区组成的块中,数据是数据,索引是索引。
可以这样理解:索引就像新华字典的目录,数据就是后面每一页具体的文字内容。索引(目录)存储了指向数据的指针(页码)。
多级索引指当索引本身的数据量太大,在索引之上再建一级索引。
4,多路树
多阶,比如2-3-4树
5,B树
6,B+树
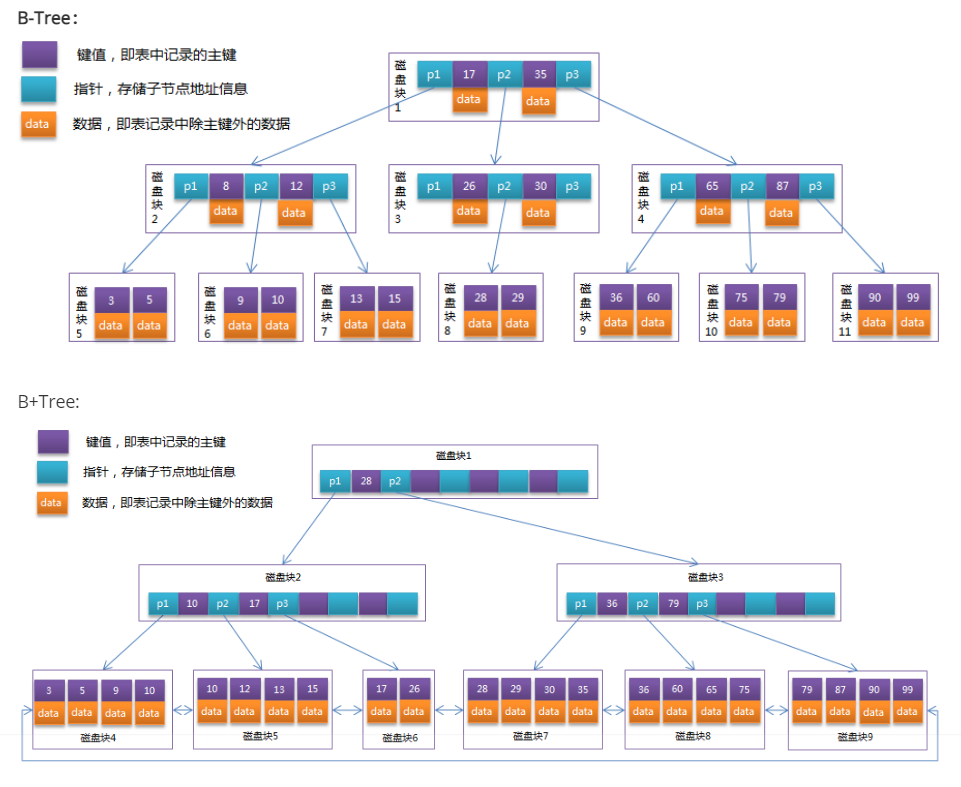
索引树的高度对应磁盘块的数量,磁盘块对应一次IO读取,即树的高度对应磁盘IO的次数。树越矮查询效率越高。
B树和B+树的主要区别:
1,B树的节点都存储了指针+主键+数据,而 B+树只有叶子节点存储主键+数据,并且叶子节点的数据用双向链表进行连接(有序链表);
2,B树的范围查找需要回溯;B+树的范围查找效率高;
加深理解移步
留一个问题:
我们说的mysql索引采用的B+树,那mysql数据又是采用什么数据结构的呢?
作者:hangwei
出处:http://www.cnblogs.com/hangwei/
关于作者:专注于开源平台,分布式系统的架构设计与开发、数据库性能调优等工作。如有问题或建议,请多多赐教!
版权声明:本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文链接。
如果您觉得文章对您有帮助,可以点击文章右下角“推荐”一下。您的鼓励是作者坚持原创和持续写作的最大动力!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号