

bufferd对象详解
使用buffer类处理二进制数据
在客户端javascript脚本代码中,对于二进制数据并没有提供一个很好的支持。然后在nodejs中需要处理像TCP流或文件流时,必须要处理二进制数据。因此在node.js中,定义了一个Buffer类,该类用来创建一个专门存放二进制数据的缓存区。
一:创建Buffer对象
在node.js中,Buffer类是一个可以在任何模块被利用的全局类,不需要为该类的使用而加载任何模块。可以使用new关键字来创建该类的实例对象。Buffer类可以使用三种方式来构造函数,第一种方式如下:
new Buffer(size)
被创建的buffer对象拥有一个length属性,属性值为缓存区的大小。如下:
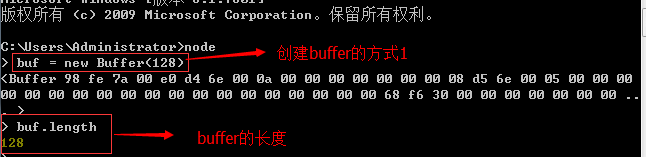
我们现在也可以使用Buffer对象的fill方法来初始化缓存区中的所有内容,如下所示:
buf.fill(value,[offset],[end]);
在Buffer对象的fill方法中,可以使用三个参数,第一个参数为必须指定的参数,参数值为需要被写入的数值,第二个参数与第三个参数为可选参数,其中第二个参数用于指定从第几个字节处开始写入被指定的数值,默认值为0,即从缓存区的起始位置写入,第三个参数用于指定将数值一直写入到第几个字节处,默认值为Buffer对象的大小,即书写到缓存区的底部。
现在我们希望从buffer对象的缓存区的第10字节处开始写入1,一直到缓存区底部,如下所示:

我们现在也可以在缓存区的第20到第30字节处(从第20字节开始,不包含第30字节)填入2,演示如下:

Buffer类的第二种形式的构造函数是直接使用一个数组来初始化缓存区,代码如下所示:
new Buffer(array)
演示如下:

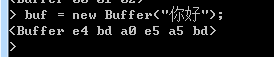
Buffer类的第三种形式的构造函数是直接使用一个字符串来初始化缓存区,代码如下:
new Buffer(str,[encoding]);
第一个参数为必须指定的参数,参数值为用于初始化换出区的字符串,第二个参数值为一个用于指定文字编码格式的字符串,默认值为utf-8
如下所示:
在Node.js中,将自动执行字符串的输入输出时的编码与解码处理,默认使用utf-8编码,可以使用编码格式如下表所示:
| 编码 | 说明 |
| ascii | ASCLL字符串 |
| utf8 | UTF-8字符串 |
| utf16le | UTF-16LE字符串 |
| ucs2 | UCS2字符串 |
| base64 | 经过BASE64编码后的字符串 |
| binary | 二进制数据(不推荐使用) |
| hex | 使用16进制数值表示的字符串 |
当使用字符串参数来创建buffer对象并初始化缓存区时,如果使用不同的编码格式,则缓存区中的数据也会有所不同,如下演示:
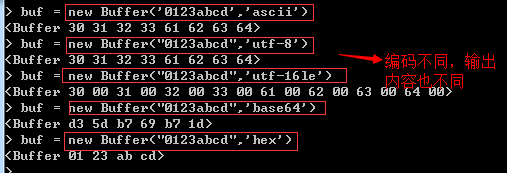
二:字符串的长度与缓存区的长度
在node.js中,一个字符串的长度与根据该字符串所创建的缓存区的长度并不相同,因为在计算字符串的长度时,是以文字作为一个单位,而在计算缓存区的长度时,是以字节作为一个单位。
比如针对 ”我喜爱编程”这个字符串,该字符串对象的length属性值与根据该字符串创建的buffer对象的length属性值并不相同。因为字符串对象的length属性值获取的是文字个数,而buffer对象的length属性值获取的是缓存区的长度,即缓存区中的字节。
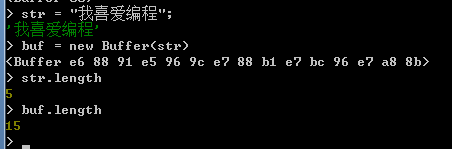
另外,可以使用0开始的序号来取出字符串对象或缓存区中的数据。但是,在获取数据时,字符串对象是以文字作为一个单位,而缓存区对象是以字节作为一个单位。比如,针对一个引用了字符串对象的str变量来说,str[2]获取的是第三个文字,而针对一个引用了缓存区对象的buf对象来说,buf[2]获取的是缓存区中的第三个字节数据转换为整数后的数值。如下:

而buffer对象是可以被修改的。可以通过序号来修改其中某个字节处的数据。如下:

Buffer对象还有一个用于取出指定位置处数据的slice方法,该方法的使用方法与string对象的slice方法相同。

注意:由于buffer对象的slice方法并不是复制缓存区中的数据,而是与该数据共享内存区域,因此,如果修改使用slice方法取出的数据,则缓存区中保存的数据也将被修改。如下演示:
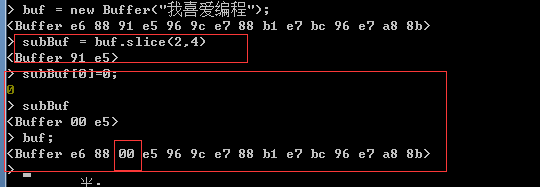
三:Buffer对象与字符串对象之间的相互转换;
1. Buffer对象的toString方法
可以使用Buffer对象的toString方法将Buffer对象中保存的数据转换为字符串,使用方法如下所示:
buf.toString([encoding],[start],[end]);
在Buffer对象的toString方法中,可以使用三个可选参数,第一个参数用于指定Buffer对象中保存的文字编码格式,默认参数值为utf8,第二个及第三个用于指定被转换数据的起始位置和终止位置,以字节为单位。toString方法返回经过转换后的字符串。
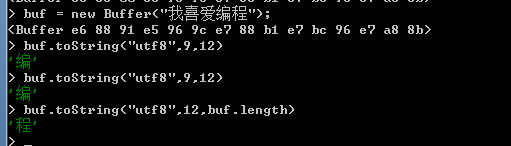
四:Buffer对象的write方法
如果要将字符串当做二进制数据来使用,只需将该字符串作为Buffer类的构造函数的参数来创建Buffer对象即可。但是有时候我们需要向已经创建好的Buffer对象中写入字符串,这时候我们可以使用Buffer对象的write方法,代码如下所示:
buf.write(string,[offset],[length],[encoding]);
在buffer对象的write方法中,可以使用四个参数,第一个参数为必须指定的参数,后三个参数为可选参数,第一个参数用于指定需要写入的字符串,第二个参数offset与第三个参数length用于指定字符串转换为字节数据的写入位置。字节数据的书写位置为从第1+offset个字节开始到offset+length个字节为止(列如offset为3,length为8,写入位置为从第4个字节开始到第11个字节为止,包括第4个字节与第11个字节)。第四个参数用于指定写入字符串时使用的编码格式,默认是utf8格式。
如下代码演示:

五:Buffer对象与JSON对象之间的相互转换
在Node.js中,可以使用JSON.stringfy方法将Buffer对象中保存的数据转换为一个字符串,也可以使用JSON.parse方法将一个经过转换后的字符串还原为一个数组。
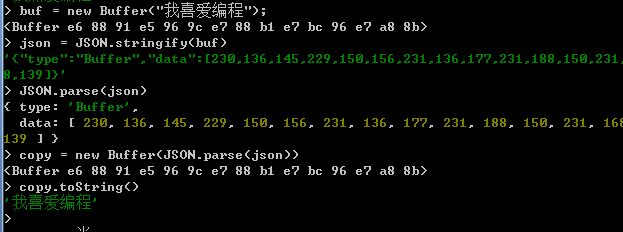
六:复制缓存数据。
当需要将Buffer对象中保存的二进制数据复制到另一个Buffer对象中时,可以使用Buffer对象的copy方法,copy方法的使用方法如下所示:
buf.copy(targetBuffer,[targetStart],[sourceStart],[sourceEnd]);
在Buffer对象的copy方法中,使用四个参数,第一个参数为必须指定的参数,其余三个参数均为可选参数。第一个参数用于指定复制的目标Buffer对象。第二个参数用于指定目标Buffer对象中从第几个字节开始写入数据,参数值为一个小于目标的Buffer对象长度的整数值,默认值为0(从开始处写入数据)。第三个参数用于指定从复制源Buffer对象中获取数据时的开始位置,默认值为0,即从复制源Buffer对象中的第一个字节开始获取数据,第四个参数用于指定从复制源Buffer对象中获取数据时的结束位置,默认值为复制源Buffer对象的长度,即一直获取完毕复制源Buffer对象中的所有剩余数据。
比如如下:将a中buffer对象中的内容复制到b中的buffer对象中,复制的目标起始位置为b的buffer对象中的第11字节处(第11字节处开始写入)。如下所示:
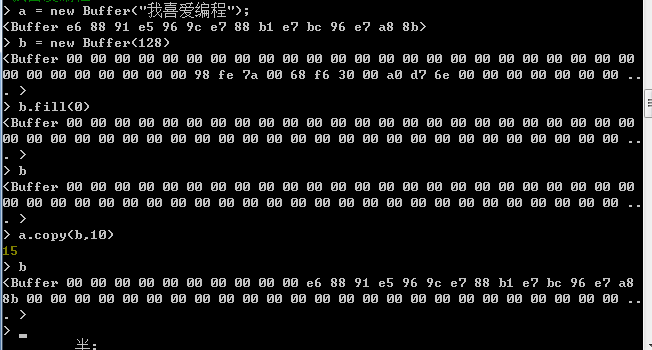
七:Buffer类的类方法
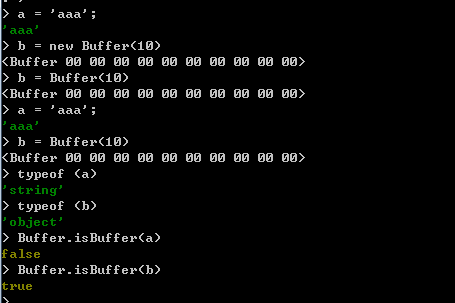
- isBuffer方法
isBuffer方法用于判断一个对象是否为一个Buffer对象,使用方法如下:
Buffer.isBuffer(obj)
在isBuffer方法中,使用一个参数,用于指定需要被判断的对象,如果对象为Buffer对象,方法返回true,否则返回false。演示如下:
2. byteLength方法;
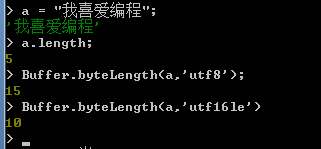
可以使用byteLength方法计算一个指定字符串的字节数,使用方法如下所示:
Buffer.byteLength(string,[encoding]);
在byteLength方法中,使用两个参数,第一个参数为必须输入的参数,用于指定需要计算字节数的字符串,第二个参数为可选参数,用于指定按什么编码方式来计算字节数。默认值为utf8.
如下演示:
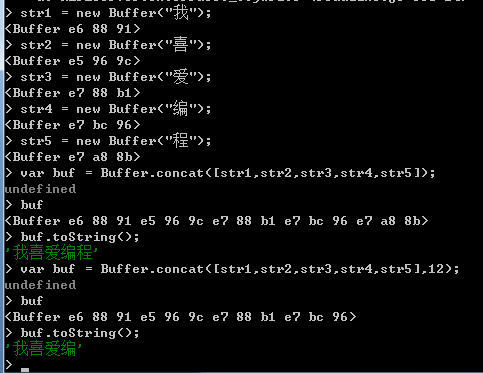
3. concat方法。
concat方法用于将几个Buffer对象结合创建为一个新的Buffer对象,使用方法如下所示:
Buffer.concat(list,[totalLength])
在concat方法中,使用两个参数,第一个参数为必须指定的参数,参数值为一个存放了多个buffer对象的数组,concat方法将把其中的所有Buffer对象链接创建为一个Buffer对象;第二个参数为可选参数,用于指定被创建的Buffer对象的长度,当省略该参数时,被创建的Buffer对象为第一个参数数组中所有Buffer对象的长度的合计值。
如果一个参数值为一个空数组或第二个参数值等于0,那么concat方法返回一个长度为0的Buffer对象。
如果第一个参数值数组中只有一个Buffer对象,那么concat方法直接返回该Buffer对象。
如果第一个参数值数组中拥有一个以上的Buffer对象,那么concat方法返回被创建的Buffer对象。
如下演示:
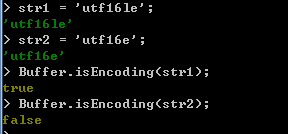
4. isEncoding方法。
isEncoding方法用于检测一个字符串是否为一个有效的编码格式字符串,使用方法如下所示:
Buffer.isEncoding(encoding);
在isEncoding方法中,使用一个参数,用于指定需要被检测的字符串。如果该字符串为有效的编码格式字符串,则方法返回true,如果该字符串不是一个有效的编码格式字符串,则方法返回false。如下演示:


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· 阿里巴巴 QwQ-32B真的超越了 DeepSeek R-1吗?
· 【译】Visual Studio 中新的强大生产力特性
· 10年+ .NET Coder 心语 ── 封装的思维:从隐藏、稳定开始理解其本质意义
· 【设计模式】告别冗长if-else语句:使用策略模式优化代码结构