MySQL单表访问方法
参考:MySQL是怎样运行的:从根儿上理解MySQL
了解表的访问方法,对于我们诊断SQL性能非常有用,对于Oracle而言,我们直接通过执行计划就能看到表的访问方式,如下:访问表使用了index range scan

对于MySQL而言,习惯了Oracle的执行计划的dba,猛的接触MySQL执行计划的时候多少有点不太习惯,我们需要了解MySQL如何定义表的访问方法:
如下执行计划,type列,就代表了MySQL访问表是通过那种方式进行访问的,这里的类型是index,对比Oracle,那么就是索引全扫描(索引快速全扫描)。知道了如下的执行计划访问的含义,那么我们就很容易判定,key_part1、key_part2、key_part3,是一个联合索引,相关结果被索引覆盖。

一:前期准备
1.创建测试表
CREATE TABLE single_table ( id INT NOT NULL AUTO_INCREMENT, key1 VARCHAR(100), key2 INT, key3 VARCHAR(100), key_part1 VARCHAR(100), key_part2 VARCHAR(100), key_part3 VARCHAR(100), common_field VARCHAR(100), PRIMARY KEY (id), KEY idx_key1 (key1), UNIQUE KEY idx_key2 (key2), KEY idx_key3 (key3), KEY idx_key_part(key_part1, key_part2, key_part3) ) Engine=InnoDB CHARSET=utf8;
2.批量插入数据
DELIMITER $$ DROP PROCEDURE IF EXISTS `proc_auto_insertdata`$$ CREATE PROCEDURE `proc_auto_insertdata`() BEGIN DECLARE i INTEGER DEFAULT 1; WHILE i <= 10000 DO insert into single_table values(null,CONCAT(i,'abc'),i,CONCAT(i,'a3'),CONCAT(i,'part1'),CONCAT(i,'part2'),CONCAT(i,'part3'),CONCAT(i,'comm')); SET i = i + 1; END WHILE; END$$ DELIMITER ; CALL proc_auto_insertdata();
二:案例演示及说明
2.1 const方式访问单表
1.有时候我们通过主键来访问一条记录
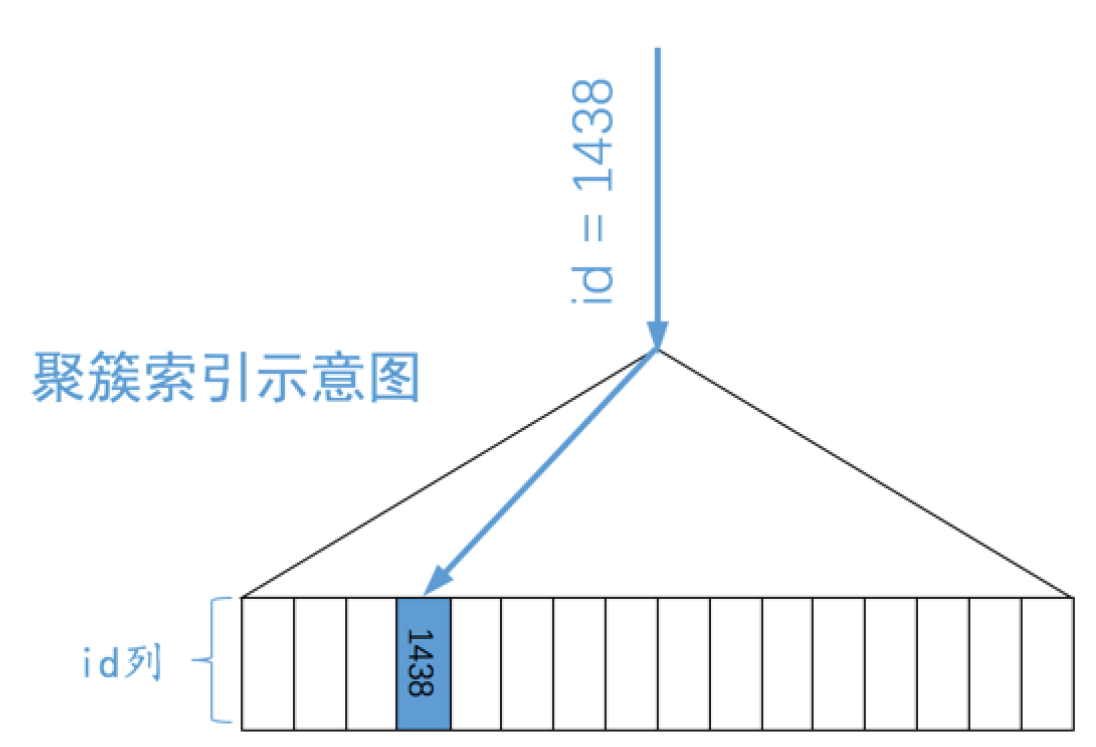
SELECT * FROM single_table WHERE id = 1438;
root@localhost [user]>explain SELECT * FROM single_table WHERE id = 1438; +----+-------------+--------------+------------+-------+---------------+---------+---------+-------+------+----------+-------+ | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+--------------+------------+-------+---------------+---------+---------+-------+------+----------+-------+ | 1 | SIMPLE | single_table | NULL | const | PRIMARY | PRIMARY | 4 | const | 1 | 100.00 | NULL | +----+-------------+--------------+------------+-------+---------------+---------+---------+-------+------+----------+-------+
我们通过主键访问数据定位对应的用户记录,大概流程如下:
2.通过唯一二级索引访问
SELECT * FROM single_table WHERE key2 = 3841;
root@localhost [user]>explain SELECT * FROM single_table WHERE key2 = 3841; +----+-------------+--------------+------------+-------+---------------+----------+---------+-------+------+----------+-------+ | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+--------------+------------+-------+---------------+----------+---------+-------+------+----------+-------+ | 1 | SIMPLE | single_table | NULL | const | idx_key2 | idx_key2 | 5 | const | 1 | 100.00 | NULL | +----+-------------+--------------+------------+-------+---------------+----------+---------+-------+------+----------+--------
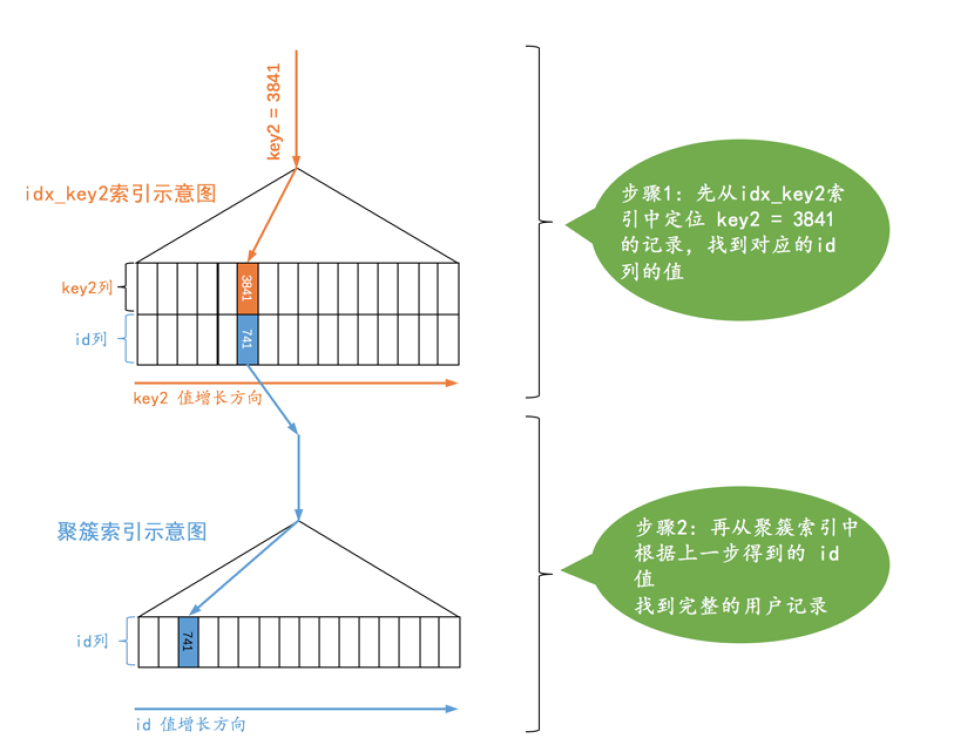
从上图可以看到查询的执行分两步,第一步先从idx_key2对应的b+数索引中根据key2列与常数的的等值比较条件定位到一条二级索引,然后根据记录的id值到聚簇索引中获取到完整的用户记录。MySQL认为通过主键或者二级唯一索引与常数的的等值比较来定位一条记录像做火箭一样快,所以MySQL把这种通过主键或者唯一二级索引列来定位一条记录的访问方法定义为:const,意思就是常数级别的,代价是可以忽略不计的,不过这种const访问方法只能在主键列或者二级唯一索引和一个常数进行等值比较时才有效,如果主键或者唯一二级索引是由多个列构成的话,索引中的每个列都需要与常数进行等值比较,这个const访问方法才有效(这是因为只有该索引中全部列都采用了等值比较才可以定位唯一的一条记录)
3.唯一二级索引等值查询null值
#当我们选择null值的时候,因为在二级索引中,null值可能是多个,无法做到唯一匹配,因此访问的类型是ref
root@localhost [user]>SELECT * FROM single_table WHERE key2 is null;
root@localhost [user]>explain SELECT * FROM single_table WHERE key2 is null; +----+-------------+--------------+------------+------+---------------+----------+---------+-------+------+----------+-----------------------+ | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+--------------+------------+------+---------------+----------+---------+-------+------+----------+-----------------------+ | 1 | SIMPLE | single_table | NULL | ref | idx_key2 | idx_key2 | 5 | const | 1 | 100.00 | Using index condition | +----+-------------+--------------+------------+------+---------------+----------+---------+-------+------+----------+-----------------------+
2.2 ref方式访问单表
有时候我们使用二级非唯一索引进行等值查询数据,如下:
SELECT * FROM single_table WHERE key1 = '9998abc';
root@localhost [user]>explain SELECT * FROM single_table WHERE key1 = '9998abc'; +----+-------------+--------------+------------+------+---------------+----------+---------+-------+------+----------+-------+ | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+--------------+------------+------+---------------+----------+---------+-------+------+----------+-------+ | 1 | SIMPLE | single_table | NULL | ref | idx_key1 | idx_key1 | 303 | const | 1 | 100.00 | NULL | +----+-------------+--------------+------------+------+---------------+----------+---------+-------+------+----------+-------+
对于这个查询,我们当然可以选择全表扫描来逐一对比搜索条件是否满足要求,我们也可以先使用二级索引找到对应记录的id值,然后再会表到聚簇索引中查找完整的用户记录,由于普通二级索引并不限制索引列值的唯一性,索引可以找到很多条对应的记录,也就是说使用二级索引来执行查询条件的代价取决于等值匹配到的二级索引记录条数,如果匹配的记录较少,则回表的代价还是比较低的,所以MySQL可能选择使用索引而不是使用全表扫描的方式来执行查询,设计MySQL开发人员就把这种搜索条件为二级索引列与常数等值比较,采用二级索引来执行查询的访问方法称为:ref。如下采用ref访问方法执行查询的图示:
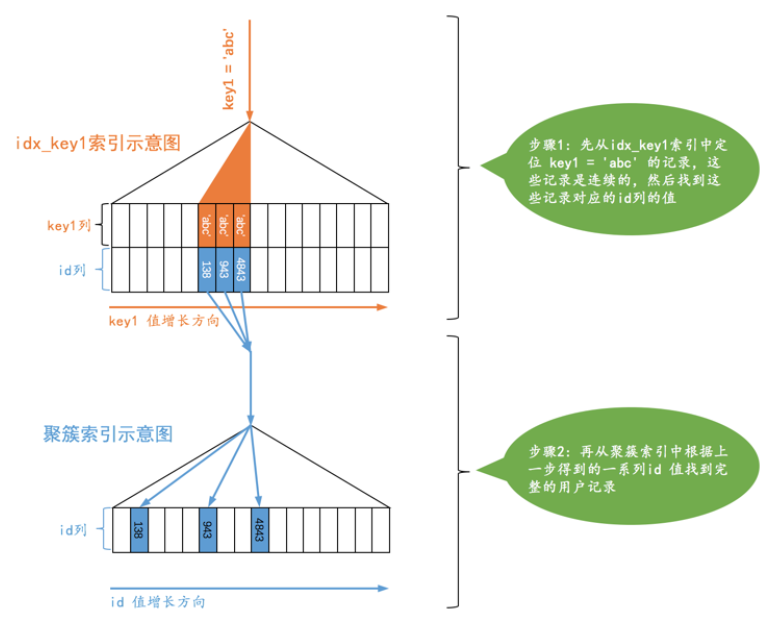
从上图可以看出,对于普通的二级索引来说,通过索引进行等值比较后,可能匹配到多条连续的记录,而不是像主键或者唯一二级索引那样最多只能匹配到一条记录,所以这种ref访问方法比const差了一点,但是在二级索引等值比较时匹配的记录数较少时效率还是很高的(如果匹配的二级索引记录太多那么会表的成本就太大了),跟做高铁差不多,不过需要注意下面两种情况:
- 二级索引列为null的情况
- 不论是普通的二级索引,还是唯一的二级随你,他们的索引列对于null值的数量并不限制,所以我们采用key is null这种形式的搜索条件最多只能使用ref的访问方法,而不是const访问方法
- 对于某个包含多个索引列的二级索引来说,只要是最左边的连续索引列是与常数等值比较就可以采用ref的访问方法,比如如下几个查询
root@localhost [user]>explain SELECT * FROM single_table WHERE key_part1 = '10000part1'; +----+-------------+--------------+------------+------+---------------+--------------+---------+-------+------+----------+-------+ | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+--------------+------------+------+---------------+--------------+---------+-------+------+----------+-------+ | 1 | SIMPLE | single_table | NULL | ref | idx_key_part | idx_key_part | 303 | const | 1 | 100.00 | NULL | +----+-------------+--------------+------------+------+---------------+--------------+---------+-------+------+----------+-------+ 1 row in set, 1 warning (0.00 sec) root@localhost [user]>explain SELECT * FROM single_table WHERE key_part1 = '10000part1' and key_part2 = '10000part2'; +----+-------------+--------------+------------+------+---------------+--------------+---------+-------------+------+----------+-------+ | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+--------------+------------+------+---------------+--------------+---------+-------------+------+----------+-------+ | 1 | SIMPLE | single_table | NULL | ref | idx_key_part | idx_key_part | 606 | const,const | 1 | 100.00 | NULL | +----+-------------+--------------+------------+------+---------------+--------------+---------+-------------+------+----------+-------+ 1 row in set, 1 warning (0.00 sec) root@localhost [user]>explain SELECT * FROM single_table WHERE key_part1 = '10000part1' and key_part2 = '10000part2' and key_part3='10000part3'; +----+-------------+--------------+------------+------+---------------+--------------+---------+-------------------+------+----------+-------+ | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+--------------+------------+------+---------------+--------------+---------+-------------------+------+----------+-------+ | 1 | SIMPLE | single_table | NULL | ref | idx_key_part | idx_key_part | 909 | const,const,const | 1 | 100.00 | NULL | +----+-------------+--------------+------------+------+---------------+--------------+---------+-------------------+------+----------+-------+
但是如果最左边的连续索引列并不是全部等值比较的话,他的访问方法就不能称为ref了,比如如下查询:
root@localhost [user]>explain SELECT * FROM single_table WHERE key_part1 = '10000part1' AND key_part2 > '10000part2'; +----+-------------+--------------+------------+-------+---------------+--------------+---------+------+------+----------+-----------------------+ | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+--------------+------------+-------+---------------+--------------+---------+------+------+----------+-----------------------+ | 1 | SIMPLE | single_table | NULL | range | idx_key_part | idx_key_part | 606 | NULL | 1 | 100.00 | Using index condition | +----+-------------+--------------+------------+-------+---------------+--------------+---------+------+------+----------+-----------------------+
2.3 ref_or_null访问方式
有时候我们不仅想查找某个二级索引列的值等于某个常数的记录,还想把该列的值为null的记录也找出来,如下查询
SELECT * FROM single_table WHERE key1 = '9998abc' OR key1 IS NULL;
root@localhost [user]>explain SELECT * FROM single_table WHERE key1 = '9998abc' OR key1 IS NULL; +----+-------------+--------------+------------+-------------+---------------+----------+---------+-------+------+----------+-----------------------+ | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+--------------+------------+-------------+---------------+----------+---------+-------+------+----------+-----------------------+ | 1 | SIMPLE | single_table | NULL | ref_or_null | idx_key1 | idx_key1 | 303 | const | 2 | 100.00 | Using index condition | +----+-------------+--------------+------------+-------------+---------------+----------+---------+-------+------+----------+-----------------------+
当我们使用二级索引而不是全表扫描的方式执行该查询时,这种类型的查询使用的访问方法就称为ref_or_null,这个ref_or_null访问的方法执行过程如下:
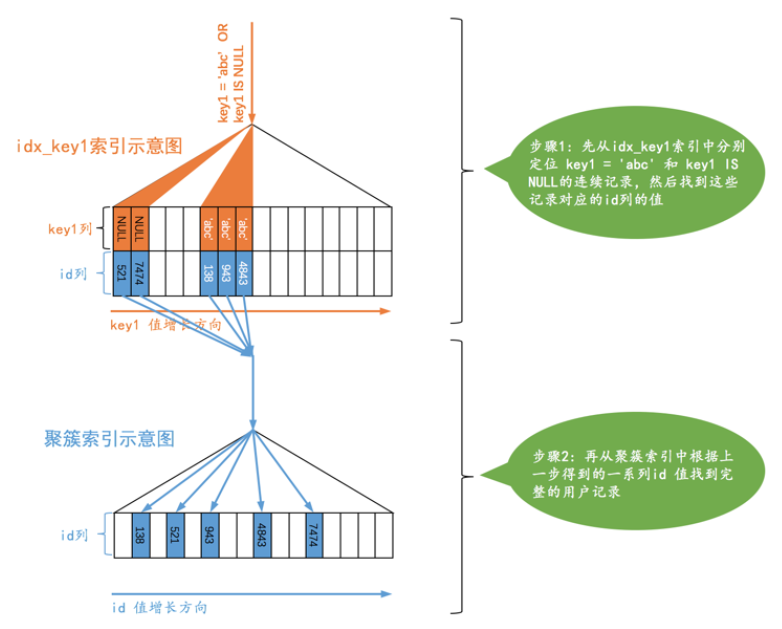
可以看到,上边的查询相当于先分别从idx_key1索引对应的b+数索引中找出key1 is null和key1='998abc'两个连续的记录范围,然后根据这些二级索引记录中的id值再回表查找完整的用户记录
2.4 range访问方式
上面介绍了几种方法都是对索引列与某一个常数进行的的等值比较才可以使用到(ref_or_null比较奇特,还计算了值为null的情况),但是有的时候我们面对的搜索条件更为复杂,比如如下查询:
SELECT * FROM single_table WHERE key2 IN (1438, 6328) OR (key2 >= 38 AND key2 <= 79);
root@localhost [user]>explain SELECT * FROM single_table WHERE key2 IN (1438, 6328) OR (key2 >= 38 AND key2 <= 79); +----+-------------+--------------+------------+-------+---------------+----------+---------+------+------+----------+-----------------------+ | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+--------------+------------+-------+---------------+----------+---------+------+------+----------+-----------------------+ | 1 | SIMPLE | single_table | NULL | range | idx_key2 | idx_key2 | 5 | NULL | 44 | 100.00 | Using index condition | +----+-------------+--------------+------------+-------+---------------+----------+---------+------+------+----------+-----------------------+ 1 row in set, 1 warning (0.00 sec)
当然我们还可以使用全表扫描的方式来执行这个查询,不过也可以使用二级索引+会表的方式执行,如果采用二级索引+回表的方式来执行的话,那么此时的搜索条件就不只是要求索引与常数的等值匹配了,而是索引列需要匹配某个或某些范围的值,在本查询中key2列的值只要匹配下列3个范围中的任何一个就算是匹配成功
- key2的值为1438
- key2的值为6328
- key2的值在38和79之间
MySQL将这种利用索引进行范围扫描的访问方法称为:range
如果把这几个所谓的key2列的值需要满足的范围在数轴上体现出来的话,那么就应该是下图所示:

也就是从数学的角度看,每一个所谓的范围都是数轴上的一个区间,3个范围就对应3个区间
- 范围1: key2 = 1438
- 范围2: key2 = 6328
- 范围3: key2 ∈ [38, 79] ,注意这里是闭区间。
我们可以把那种索引等值匹配的情况称之为单点区间,上面所说的范围1和范围2都可以称为单点区间,像范围3,这种的我们可以称为连续范围区间。
2.5 index访问方式
如下查询:
root@localhost [user]>SELECT key_part1, key_part2, key_part3 FROM single_table WHERE key_part2 = '123part2'; +-----------+-----------+-----------+ | key_part1 | key_part2 | key_part3 | +-----------+-----------+-----------+ | 123part1 | 123part2 | 123part3 | +-----------+-----------+-----------+
root@localhost [user]>explain SELECT key_part1, key_part2, key_part3 FROM single_table WHERE key_part2 = '123part2'; +----+-------------+--------------+------------+-------+---------------+--------------+---------+------+------+----------+--------------------------+ | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+--------------+------------+-------+---------------+--------------+---------+------+------+----------+--------------------------+ | 1 | SIMPLE | single_table | NULL | index | NULL | idx_key_part | 909 | NULL | 9811 | 10.00 | Using where; Using index | +----+-------------+--------------+------------+-------+---------------+--------------+---------+------+------+----------+--------------------------+ 1 row in set, 1 warning (0.00 sec)
由于key_part2并不是联合索引的最左索引列,所以我们无法使用ref或者range访问方法来执行这个语句,但是这个查询符合下面两种看情况
- 它的查询列表只有3个列: key_part1 , key_part2 , key_part3 ,而索引idx_key_part 又包含这三个列。
- 搜索条件中只有key_part2 列。这个列也包含在索引idx_key_part 中。
也就是说我们可以直接通过遍历idx_key_part索引的叶子节点的记录来比较key_part2=‘123part'这个条件是否成立,把匹配成功的二级索引记录key_part1,key_part2,key_part3列的值直接加到结果集中就可以了,由于二级索引记录比聚簇索引记录小很多(聚簇索引记录要存储所有用户定义的列以及所谓的隐藏列,而二级索引记录只需要存放索引列和主键),而且这个过程也不需要回表操作,所以直接遍历二级索引比直接遍历聚簇索引的成本要小很多,设计MySQL的程序人员,将采用遍历二级索引记录的执行方式称为:index
2.6 all访问方式
最直接的查询方式就是我们已经提了无数遍测全表扫描,对于innodb表来说也就是直接扫描聚簇索引,设计MySQL的开发人员把这种使用全表扫描执行查询的方式成为:all
2.7 index_merge
当我们索引创建不合理的情况下,会出现索引合并的情况,下面演示案例
1.创建测试表
create table tb_test(id int primary key auto_increment, c1 char(1), c2 char(1), c3 char(1), c4 char(1));
2.创建随即字符串函数
delimiter $$ # 生成随机字符串 create function rand_char() returns char(1) begin declare CHARS char(52) default 'abcdefghijklmnopqrstuvwxyz'; return substr(CHARS,floor(1+RAND()*52), 1); end $$
3.创建insert函数
create procedure insert_tb_test(c int) begin declare i int default 0; set autocommit = 0; repeat set i = i + 1; insert into tb_test(c1,c2,c3,c4) values(rand_char(),rand_char(),rand_char(),rand_char()); until i = c end repeat; set autocommit = 1; end $$ delimiter ;
4.执行insert函数插入数据
call insert_tb_test(1000000);
5.创建索引
alter table tb_test add index idx_tb_test_c1(c1);
alter table tb_test add index idx_tb_test_c2(c2);
alter table tb_test add index idx_tb_test_c3(c3);
alter table tb_test add index idx_tb_test_c4(c4);
6.执行语句,模拟索引合并
root@localhost [user]>explain select * from tb_test where c1='A' and c2='B' and c3='C' and c4='D'\G; *************************** 1. row *************************** id: 1 select_type: SIMPLE table: tb_test partitions: NULL type: index_merge possible_keys: idx_tb_test_c1,idx_tb_test_c2,idx_tb_test_c3,idx_tb_test_c4 key: idx_tb_test_c3,idx_tb_test_c1,idx_tb_test_c2,idx_tb_test_c4 key_len: 4,4,4,4 ref: NULL rows: 1 filtered: 100.00 Extra: Using intersect(idx_tb_test_c3,idx_tb_test_c1,idx_tb_test_c2,idx_tb_test_c4); Using where; Using index 1 row in set, 1 warning (0.00 sec)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号