第十章 数据库
数据库
1.1 初始数据库
1.1.1 使用数据库的原因
- 很多功能如果只是通过操作文件来改变数据是非常繁琐的,程序员需要做很多事情
- 对于多台机器或者多个进程操作用一份数据,程序员自己解决并发和安全问题比较麻烦
- 需要自己处理一些数据备份,容错的措施
1.1.2 使用数据库的好处
- 本质:C/S架构的,操作数据文件的一个管理软件
- 好处:
- 帮助我们解决并发问题
- 能够帮助我们用更简单更快速的方式完成数据的增删改查
- 能够给我们提供一些容错、高可用的机制
- 帮助我们进行权限的认证
1.1.3 数据库管理系统(DBMS)
- 含义:专门用来管理数据文件,帮助用户更简洁的操作数据的软件
- 相关概念:
- DataBase Management System,简称DBMS
- 数据库服务器:运行数据库管理软件
- 数据库管理员DBA:管理数据库
- 数据库(DataBase,简称DB):即文件夹,用来组织文件/表
- 数据库是长期存放在计算机内、有组织、可共享的数据集合
- 数据库中的数据按一定的数据模型组织、描述和储存,具有较小的冗余度、较高的数据独立性和易扩展性,并可为各种用户共享
- 表:即文件,用来存放多行内容/多条记录
- 数据(Data):描述事物的符号记录称为数据
- 分类:
- 关系型数据库:
- sql server
- oracle:收费的、比较严谨、安全性比较高
- 国企、事业单位使用
- 银行、金融行业使用
- mysql:开源的、免费的
- 小公司使用
- 互联网公司使用
- sqllite:类似mysql
- 非关系型数据库:
- redis
- mongodb
- 关系型数据库:
1.1.4 SQL语句
- 定义:结构化查询语句
- 分类:
- DDL:数据库定义语言,创建库、创建表
- 创建用户
- create user '用户名'@'%' 表示网络可以通讯的所有ip地址都可以使用这个用户名
- create user '用户名'@'192.168.12.%' 表示192.168.12.0网段的用户可以使用这个用户名
- create user '用户名'@'192.168.12.87' 表示只有一个ip地址可以使用这个用户名
- 创建库
- create database day38;
- 创建表
- create table 表名(字段名 数据类型(长度),字段名 数据类型(长度),)
- 创建用户
- DML:数据库操纵语言,存数据,删除数据
- 数据的增删改查
- 增 insert into
- 删 delete from
- 改 update
- 查 select
- select user(); 查看当前用户
- select database(); 查看当前所在的数据库
- show
- show databases: 查看当前的数据库有哪些
- show tables; 查看当前的库中有哪些表
- desc 表名; 查看表结构
- use 库名; 切换到这个库下
- 数据的增删改查
- DCL:数据库控制语言
- grant:给用户授权
- grant select on 库名.* to '用户名'@'ip地址/段' identified by '密码'
- grant select,insert
- grant all
- revoke
- grant:给用户授权
- DDL:数据库定义语言,创建库、创建表
- 常用SQL语句示例:
- 查看当前用户是谁:select user();
- 设置密码:set password = password('密码');
- 创建用户:create user 's21'@'192.168.12.%' identified by '123';
- 用户连接:mysql -us21 -p123 -h192.168.12.87
- 数据库授权:grant all on day37.* to 's21'@'192.168.12.%';
- 授权并创建用户:grant all on day37.* to 'alex'@'%' identified by '123';
1.2 mysql的基本知识
1.2.1 安装mysql遇到的问题
- 操作系统的问题
- 缺失dll文件
- 安装路径的问题
- 不能有空格
- 不能有中文
- 不能带着有转义的特殊字符开头的文件夹名
- 安装之后发现配置有问题
- 再修改配置往往不能生效
- 卸载之后重装
- mysqld remove
- 把所有的配置、环境变量修改到正确的样子
- 重启计算机 - 清空注册表
- 再重新安装
1.2.2 mysql的CS架构
- mysqld install:安装数据库服务
- net start mysql:启动数据库的server端
- net stop mysql:停止数据库的server端
- 客户端可以是python代码也可以是一个程序
- mysql.exe是一个客户端
- mysql -u用户名 -p密码
1.2.3 mysql中的用户和权限
- 在安装数据库之后,有一个最高权限的用户root
- mysql -uroot -p
- 我们的mysql客户端不仅可以连接本地的数据库,也可以连接网络上的某一个数据库的server端
- mysql -us21 -p123 -h192.168.12.87
1.2.4 mysql表中的存储引擎(存储方式)
1、myisam
- mysql5.5以下的默认存储引擎
- 存储文件个数:表数据、表结构、索引(mysiam里只有辅助索引,需要回表查询,所以有单独存放索引这个文件)
- 支持表级锁
- 不支持行级锁,不支持事务,不支持外键
2、innodb
- mysq;5.6以上版本的默认存储方式
- 存储的文件个数:表结构、表数据(在树的叶子节点存储着实际数据)
- 支持行级锁,表级锁
- 支持事务
- 支持外键
3、memory(内存)
- 存储的文件个数:表结构
- 优势:增删改查都很快
- 劣势:重启数据消失/容量有限
4、其他:
- 查看配置项:
- 查看与存储引擎相关的:show variable like '%engine%'
5、面试相关:
- 用什么数据库 : mysql
- 版本是什么 :5.6
- 都用这个版本么 :不是都用这个版本,但大部分还是用的这个版本
- 存储引擎 :innodb
- 为什么要用这个存储引擎:
- 支持事务、支持外键、支持行级锁
- 能够更好的处理并发的修改问题
1.2.5 mysql中的数据类型
1、数值类型
- int默认是有符号的 (建表的时候不用规定大小,默认是11)
- create table day (id1 int(4),id2 int(11));
- 设置成无符号:create table t5 (id1 int unsigned,id2 int);
- 它能表示的数字的范围不被宽度约束
- 它只能约束数字的显示宽度
小数:float
- create table day (f1 float(5,2),d1 double(5,2));
- create table day (f1 float,d1 double);
- 小数:decimal
- create table day (d1 decimal,d2 decimal(25,20));
2、日期和时间类型:
-
年:year
-
create table today(y year);
-
YYYY(1901/2155)
-
-
年月日:date
-
create table today(d date);
-
YYYY-MM-DD(1000-01-01/9999-12-31)
-
-
时分秒:time
-
create table today(t time);
-
HH:MM:SS('-838:59:59'/'838:59:59')
-
-
年月日时分秒:datetime、timestamp
- create table today(dt datetime, ts timestamp);
-
将datetime设置为有timestamp的功能,不能为空,自动填充当前时间等,就在创建表时,在datetime后面加上NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP
- create table today(dt datetime NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP);
datetime与timestamp的区别
在实际应用的很多场景中,MySQL的这两种日期类型都能够满足我们的需要,存储精度都为秒,但在某些情况下,会展现出他们各自的优劣。
下面就来总结一下两种日期类型的区别。
1.DATETIME的日期范围是1001——9999年,TIMESTAMP的时间范围是1970——2038年。
2.DATETIME存储时间与时区无关,TIMESTAMP存储时间与时区有关,显示的值也依赖于时区。在mysql服务器,
操作系统以及客户端连接都有时区的设置。
3.DATETIME使用8字节的存储空间,TIMESTAMP的存储空间为4字节。因此,TIMESTAMP比DATETIME的空间利用率更高。
4.DATETIME的默认值为null;TIMESTAMP的字段默认不为空(not null),默认值为当前时间(CURRENT_TIMESTAMP),
如果不做特殊处理,并且update语句中没有指定该列的更新值,则默认更新为当前时间。
3、字符串类型
- 定长的单位:char char(50),你写2个字符,他也是
- create table day (name char(5));
- 手机号码、身份证号,使用char
- 用户名、密码,使用char
- 变长的单位:varchar
- create table day (name varchar(5));
- 评论、微博、说说、微信状态,使用varchar
- 哪一个存储方式好?
- char :定长,简单粗暴,浪费空间,存取速度快
- varchar :变长,精准,节省空间,存取速度慢(截取不好截取)
4、enum和set类型
- 单选(枚举):enum
- 选择性别:男、女
- 多选 set
- 选择兴趣爱好等
- create table people(name char(12),gender enum('male','female'),hobby set('抽烟','喝酒','烫头','洗脚'));
- insert into people values('alex','不详','抽烟,喝酒,洗脚,洗脚,按摩');
- enum:不详无法写入,只能在male和female中二选一
- set:自动去重,洗脚只写入一次,按摩无法写入,不在选项中
- insert into people values('alex','不详','抽烟,喝酒,洗脚,洗脚,按摩');
1.2.6 mysql中的约束
约束条件与数据类型的宽度一样,都是可选参数
作用:用于保证数据的完整性和一致性
主要分为:
PRIMARY KEY (PK) 标识该字段为该表的主键,可以唯一的标识记录
FOREIGN KEY (FK) 标识该字段为该表的外键
NOT NULL 标识该字段不能为空
UNIQUE KEY (UK) 标识该字段的值是唯一的
AUTO_INCREMENT 标识该字段的值自动增长(整数类型,而且为主键)
DEFAULT 为该字段设置默认值
UNSIGNED 无符号
ZEROFILL 使用0填充
- 设置某一个数字无符号:unsigned
- 设置某一个字段不能为空:not null
- 给某个字段设置默认值:default
- 设置某一个字段不能重复:unique
- 联合唯一:unique(字段1,字段2),说明字段1加上字段2不能重复
- 设置某一个int类型的字段自动增加:auto_increment
- 默认非空:auto_increment自带not null效果
- 自增字段必须是数字且必须是唯一的:设置条件为 int 和 unique
- 主键(设置某一个字段非空且不能重复):primary key
- 一张表只能设置一个主键
- 一张表最好设置一个主键
- 约束这个字段非空(not null)且唯一(unique)
- 指定的第一个非空且唯一的字段会被定义成主键
- 联合主键:primary key(字段1,字段2),说明字段1和字段2都非空且唯一
- 外键:foregin key
- 和references一起使用
- 关联的字段至少是唯一的,一般都是关联外表的主键
- 要先创建外表,在创建有外键的表
- 级联删除、更新
#表类型必须是innodb存储引擎,且被关联的字段,
create table department(
id int primary key,
name varchar(20) not null,
)engine=innodb;
#dpt_id是外键,关联父表中(department主键id),并需要设置同步更新同步删除。
create table t2(
id int primary key,
name varchar(20) not null,
dpt_id int , #外键.
constraint fyk_name foregin key(dpt_id) reference department(id)
on delete cascade
on update cascade
)engine = innodb;
#先往父表department中插入记录
insert into department values
(1,'欧德博爱技术有限事业部'),
(2,'艾利克斯人力资源部'),
(3,'销售部');
#再往子表employee中插入记录
insert into employee values
(1,'egon',1),
(2,'alex1',2),
(3,'alex2',2),
(4,'alex3',2),
(5,'李坦克',3),
(6,'刘飞机',3),
(7,'张火箭',3),
(8,'林子弹',3),
(9,'加特林',3)
;
1.2.7 mysql中的函数
一、数学函数
ROUND(x,y)
返回参数x的四舍五入的有y位小数的值
RAND()
返回0到1内的随机值,可以通过提供一个参数(种子)使RAND()随机数生成器生成一个指定的值。
二、聚合函数(常用于GROUP BY从句的SELECT查询中)
AVG(col)返回指定列的平均值
COUNT(col)返回指定列中非NULL值的个数
MIN(col)返回指定列的最小值
MAX(col)返回指定列的最大值
SUM(col)返回指定列的所有值之和
GROUP_CONCAT(col) 返回由属于一组的列值连接组合而成的结果
三、字符串函数
CHAR_LENGTH(str)
返回值为字符串str 的长度,长度的单位为字符。一个多字节字符算作一个单字符。
CONCAT(str1,str2,...)
字符串拼接
如有任何一个参数为NULL ,则返回值为 NULL。
CONCAT_WS(separator,str1,str2,...)
字符串拼接(自定义连接符)
CONCAT_WS()不会忽略任何空字符串。 (然而会忽略所有的 NULL)。
CONV(N,from_base,to_base)
进制转换
例如:
SELECT CONV('a',16,2); 表示将 a 由16进制转换为2进制字符串表示
FORMAT(X,D)
将数字X 的格式写为'#,###,###.##',以四舍五入的方式保留小数点后 D 位, 并将结果以字符串的形式返回。若 D 为 0, 则返回结果不带有小数点,或不含小数部分。
例如:
SELECT FORMAT(12332.1,4); 结果为: '12,332.1000'
INSERT(str,pos,len,newstr)
在str的指定位置插入字符串
pos:要替换位置其实位置
len:替换的长度
newstr:新字符串
特别的:
如果pos超过原字符串长度,则返回原字符串
如果len超过原字符串长度,则由新字符串完全替换
INSTR(str,substr)
返回字符串 str 中子字符串的第一个出现位置。
LEFT(str,len)
返回字符串str 从开始的len位置的子序列字符。
LOWER(str)
变小写
UPPER(str)
变大写
REVERSE(str)
返回字符串 str ,顺序和字符顺序相反。
SUBSTRING(str,pos) , SUBSTRING(str FROM pos) SUBSTRING(str,pos,len) , SUBSTRING(str FROM pos FOR len)
不带有len 参数的格式从字符串str返回一个子字符串,起始于位置 pos。带有len参数的格式从字符串str返回一个长度同len字符相同的子字符串,起始于位置 pos。 使用 FROM的格式为标准 SQL 语法。也可能对pos使用一个负值。假若这样,则子字符串的位置起始于字符串结尾的pos 字符,而不是字符串的开头位置。在以下格式的函数中可以对pos 使用一个负值。
mysql> SELECT SUBSTRING('Quadratically',5);
-> 'ratically'
mysql> SELECT SUBSTRING('foobarbar' FROM 4);
-> 'barbar'
mysql> SELECT SUBSTRING('Quadratically',5,6);
-> 'ratica'
mysql> SELECT SUBSTRING('Sakila', -3);
-> 'ila'
mysql> SELECT SUBSTRING('Sakila', -5, 3);
-> 'aki'
mysql> SELECT SUBSTRING('Sakila' FROM -4 FOR 2);
-> 'ki'
四、日期和时间函数
CURDATE()或CURRENT_DATE() 返回当前的日期
CURTIME()或CURRENT_TIME() 返回当前的时间
DAYOFWEEK(date) 返回date所代表的一星期中的第几天(1~7)
DAYOFMONTH(date) 返回date是一个月的第几天(1~31)
DAYOFYEAR(date) 返回date是一年的第几天(1~366)
DAYNAME(date) 返回date的星期名,如:SELECT DAYNAME(CURRENT_DATE);
FROM_UNIXTIME(ts,fmt) 根据指定的fmt格式,格式化UNIX时间戳ts
HOUR(time) 返回time的小时值(0~23)
MINUTE(time) 返回time的分钟值(0~59)
MONTH(date) 返回date的月份值(1~12)
MONTHNAME(date) 返回date的月份名,如:SELECT MONTHNAME(CURRENT_DATE);
NOW() 返回当前的日期和时间
QUARTER(date) 返回date在一年中的季度(1~4),如SELECT QUARTER(CURRENT_DATE);
WEEK(date) 返回日期date为一年中第几周(0~53)
YEAR(date) 返回日期date的年份(1000~9999)
重点:
DATE_FORMAT(date,format) 根据format字符串格式化date值
mysql> SELECT DATE_FORMAT('2009-10-04 22:23:00', '%W %M %Y');
-> 'Sunday October 2009'
mysql> SELECT DATE_FORMAT('2007-10-04 22:23:00', '%H:%i:%s');
-> '22:23:00'
mysql> SELECT DATE_FORMAT('1900-10-04 22:23:00',
-> '%D %y %a %d %m %b %j');
-> '4th 00 Thu 04 10 Oct 277'
mysql> SELECT DATE_FORMAT('1997-10-04 22:23:00',
-> '%H %k %I %r %T %S %w');
-> '22 22 10 10:23:00 PM 22:23:00 00 6'
mysql> SELECT DATE_FORMAT('1999-01-01', '%X %V');
-> '1998 52'
mysql> SELECT DATE_FORMAT('2006-06-00', '%d');
-> '00'
五、加密函数
MD5()
计算字符串str的MD5校验和
PASSWORD(str)
返回字符串str的加密版本,这个加密过程是不可逆转的,和UNIX密码加密过程使用不同的算法。
六、控制流函数
CASE WHEN[test1] THEN [result1]...ELSE [default] END
如果testN是真,则返回resultN,否则返回default
CASE [test] WHEN[val1] THEN [result]...ELSE [default]END
如果test和valN相等,则返回resultN,否则返回default
IF(test,t,f)
如果test是真,返回t;否则返回f
IFNULL(arg1,arg2)
如果arg1不是空,返回arg1,否则返回arg2
NULLIF(arg1,arg2)
如果arg1=arg2返回NULL;否则返回arg1
1.2 库操作
- 创建库:create database 数据库的名字;
- 删除库:drop database 数据库的名字;
- 查看当前有多少个数据库:show databases;
- 查看当前使用的数据库:select database();
- 切换到这个数据库(文件夹)下:use 数据库的名字;
1.3 表操作
-
增
- 创建表:create table 表名(字段名 数据类型(长度));
- create table day (id int,name char(4)); mysql5.6版本默认是engine=innodb
- create table day (id int,name char(4)) engine=myisam;
- create table day (id int,name char(4)) engine=memory;
- 创建表:create table 表名(字段名 数据类型(长度));
-
删
- 删除表:drop table 表名;
- delete from 表名;用这个表结构还在
- truncate table 表名; 清表用这个,表结构就没了。
- drop table student
-
改
- 修改表名:alter table 表名 rename 新表名;
- 添加字段:alter table 表名 add 字段名 数据类型(宽度) 约束;
ALTER TABLE 表名 ADD 字段名 数据类型 [完整性约束条件…], ADD 字段名 数据类型 [完整性约束条件…]; ALTER TABLE 表名 ADD 字段名 数据类型 [完整性约束条件…] FIRST; 添加到最前面 ALTER TABLE 表名 ADD 字段名 数据类型 [完整性约束条件…] AFTER 字段名; #在字段名后面加- 删除字段:alter table 表名 drop 字段名;
- 修改字段:
- 修改已经存在的字段的类型、宽度、约束:使用modify
- alter table 表名 modify name varchar(12) not null;
- 修改已经存在的字段的类型、宽度、约束和字段名字:使用change
- alter table 表名 change name new_name varchar(12) not null;
- 特殊:有三个字段依次是:id name age
- 交换name和age的位置:alter table 表名 modify age int not null after id;
- 将age放在第一位:alter table 表名 modify age int not null first;
- 修改已经存在的字段的类型、宽度、约束:使用modify
查:
- 查看当前文件夹中有多少张表:show tables;
- 查看表的结构
- 能够看到和这张表相关的所有信息:show create table 表名\G; (\G按照格式打印)
- 只能查看表的字段的基础信息:desc 表名; / describe 表名;
1.3.1 表与表之间的关系
1、两张表中的数据之间的关系
多对一:foregin key ,永远在多的那张表中设置外键
- 很多学生都是一个班级的,学生是多,班级是一
- 两张表:学生表和班级表,学生表关联班级表
一对一:foregin key + unique,后出现的后一张表中的数据作为外键,并且要约束这个外键是唯一的
- 一个学生是一个客户,两张表:学生表和客户表
- 客户作为外表,在学生中设置外键(先有学生在有客户)
多对多:产生第三张表,把两个关联关系的字段作为第三张表的外键
- 一本书有多个作者,一个作者有多本书,两张表:书名表和作者表
1.4 数据操作
1.4.1 数据的增删改查
- 增:insert
- insert into 表名 values (值....);
- 所有的在这个表中的字段都需要按照顺序被填写在这里
- insert into 表名(字段名,字段名。。。) values (值....);
- 所有在字段位置填写了名字的字段和后面的值必须是一一对应
- insert into 表名(字段名,字段名。。。) values (值....),(值....),(值....);
- 所有在字段位置填写了名字的字段和后面的值必须是一一对应
- value单数:一次性写入一行数据,values复数:一次性写入多行数据
- 写入角度:
- 第一个角度:写入一行内容还是写入多行
- insert into 表名 values (值....);
- insert into 表名 values (值....),(值....),(值....);
- 第二个角度:
- 是把这一行所有的内容都写入:insert into 表名 values (值....);
- 还是按指定字段写入:insert into 表名(字段1,字段2) values (值1,值2);
- 第一个角度:写入一行内容还是写入多行
- insert into 表名 values (值....);
- 删:delete
- delete from 表名 where 条件;
- 删除id=1那行的数据:delete from student where id=1;
- delete from 表名;
- 删除所有的数据:delete from student;
- delete from 表名 where 条件;
- 改:update
- update 表名 set 字段名=新值;
- 修改所有的数据:update student set name = 'yuan';
- update 表名 set 字段名=新值 where 条件;
- 修改id=2那行的数据:update student set name = 'wusir' where id=2;
- update 表名 set 字段名=新值;
- 查:
- 单表查询
- 多表查询
1.4.2 单表查询
1.4.2.1关键字的执行优先级(重点)
重点中的重点:关键字的执行优先级
from
where
group by
having
select
distinct
order by
limit
1.找到表:from
2.拿着where指定的约束条件,去文件/表中取出一条条记录
3.将取出的一条条记录进行分组group by,如果没有group by,则整体作为一组
4.将分组的结果进行having过滤
5.执行select
6.去重
7.将结果按条件排序:order by
8.限制结果的显示条数
- select 语句
- select * from 表名;
- select 字段,字段.. from 表名:
- distinct去重:select distinct 字段,字段.. from 表名;
- 对int类型四则运算:select 字段*5 from 表名;
- 重命名:
- select 字段 as 新名字,字段 as 新名字 from 表名;
- select 字段 新名字 from 表名;
- 字符串拼接:使用concat()函数
- select concat('姓名:',name,'年薪:',salary*12) as 表名;
- where 语句
- 比较运算:
- 大于:>,小于: <,等于: =,大于等于:>=,小于等于:<=,不等于:!= 或 <>
- 逻辑运算:条件的拼接
- 与:and,或:or,非:not
- 身份运算:关于null
- is null:查看为NULL的信息
- is not null:查看不为NULL的信息
- select * from employee where salary not in (20000,30000,3000,19000,18000,17000)
- 范围筛选
- 多选一:字段名 in (值1,值2,值3)
- select * from employee where salary in (20000,30000,3000,19000,18000,17000)
- 在一个模糊的范围里
- 在一个数值区间:between + and
- select emp_name from employee where salary between 10000 and 20000;
- 字符串的模糊查询:like + 通配符
- 通配符 %:匹配任意长度的任意内容
- 通配符 _ :匹配一个字符长度的任意内容
- 正则匹配:regexp,更加细粒度的匹配的时候
- select * from 表 where 字段 regexp 正则表达式
- select * from employee where emp_name regexp '^j[a-z]{5}';
- select * from 表 where 字段 regexp 正则表达式
- 查看岗位是teacher且名字是jin开头的员工姓名、薪资
- select emp_name,salary from employee where post='teacher' and emp_name like 'jin%';
- select emp_name,salary from employee where post='teacher' and emp_name regexp '^jin.*';
- 在一个数值区间:between + and
- 多选一:字段名 in (值1,值2,值3)
- 比较运算:
- group by 分组
- 分组:会把在group by后面的这个字段中的每一个不同的项都保留下来,并且把值是这一项的的所有行归为一组
- select * from employee group by post;
- 可以完成去重:select 字段名 from 表名 group by 字段名;
- 相当于:select distinct 字段名 from 表名;
- 聚合:把很多行的同一个字段进行一些统计,最终的到一个结果
- count(字段):统计这个字段有多少项
- 统计表有多少项:select count(*) from 表名;
- sum(字段):统计这个字段对应的数值的和
- avg(字段):统计这个字段对应的数值的平均值
- min(字段):统计这个字段对应的数值的最小值
- max(字段):统计这个字段对应的数值的最大值
- count(字段):统计这个字段有多少项
- 分组聚合:总是根据会重复的项来进行分组,分组总是和聚合函数一起用
- 求部门的最高薪资或者求公司的最高薪资都可以通过聚合函数取到
- 但是要得到对应的人,就必须通过多表查询
- 求最晚入职的员工,实际上是最大的入职日期,即使用max(),反之亦然
- 示例:
- 求各个部门的人数
- select count(*) from employee group by post
- 求公司里 男生 和女生的人数
- select count(id) from employee group by sex
- 求各部门年龄最小的
- select post,min(age) from employee group by post
- 求各个部门的人数
- 求部门的最高薪资或者求公司的最高薪资都可以通过聚合函数取到
- 分组:会把在group by后面的这个字段中的每一个不同的项都保留下来,并且把值是这一项的的所有行归为一组
- having 语句:过滤组
- 执行顺序:
- 总是先执行where,再执行group by分组
- 所以相关先分组,之后再根据分组做某些条件筛选的时候,where都用不上
- 只能用having来完成
- 建议:普通的条件判断用where,不要用having
- 示例:部门人数大于3的部门
- select post from employee group by post having count(*) > 3;
- 执行顺序:
- order by 排序
- 默认是升序asc 从小到大:order by 某一个字段 asc;
- 指定降序排列desc 从大到小:order by 某一个字段 desc;
- 指定先根据第一个字段升序排列,在第一个字段相同的情况下,再根据第二个字段排列 :
- order by 第一个字段 asc,第二个字段 desc;
- limit 限制查询数量
- 取前n个:imit n == limit 0,n
- 考试成绩的前三名
- 入职时间最晚的前三个
- 分页:limit m,n,从m+1开始取n个
- 员工展示的网页
- limit n offset m == limit m,n 从m+1开始取n个
- 取前n个:imit n == limit 0,n
- 单表查询顺序
- from 表
- where 条件
- group by 分组
- having 过滤组
- select 需要显示的列
- order by 排序
- limit 前n条
1.4.3 多表查询
- 两张表连在一起:select * from emp,department;
- 连表查询:把两张表连在一起查
- 内连接:inner join
- 两张表条件不匹配的项不会出现再结果中
- select * from emp inner join department on emp.dep_id = department.id;
- 外连接:
- 左外连接:left join
- 永远显示全量的左表中的数据
- select * from emp left join department on emp.dep_id = department.id;
- 右外连接:right join
- 永远显示全量的右表中的数据
- select * from emp right join department on emp.dep_id = department.id;
- 全外连接:mysql中没有全外连接
- 要实现全外连接,就使用左外连接union右外连接
- select * from emp left join department on emp.dep_id = department.id union select * from department right join emp on emp.dep_id = department.id;
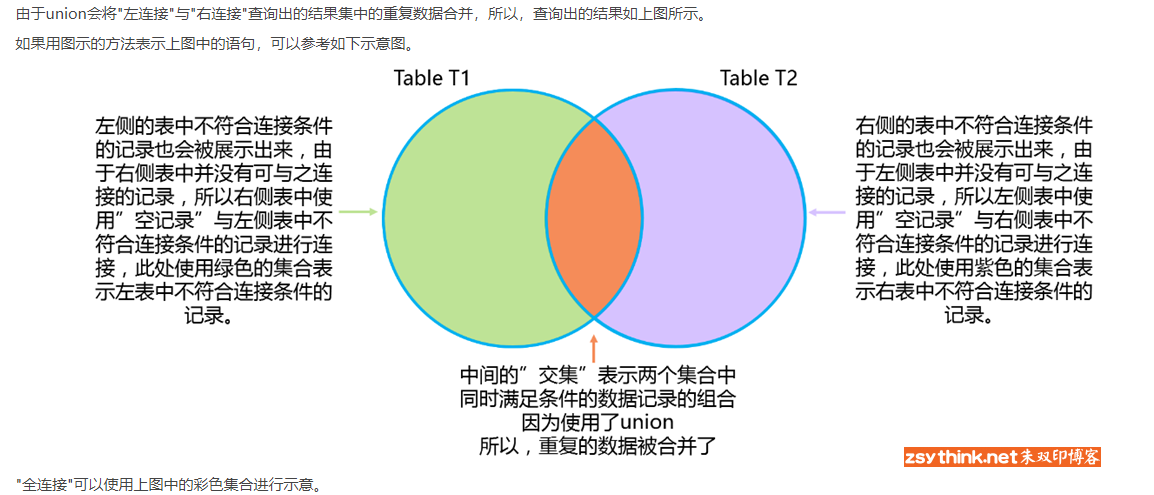
- 左外连接:left join
- 连接的语法:
- select 字段 from 表1 xxx join 表2 on 表1.字段 = 表2.字段;
- 常用:内链接和左外链接
- 示例:查询大于部门内平均年龄的员工名、年龄
- select * from emp inner join (select dep_id,avg(age) avg_age from emp group by dep_id) as d on emp.dep_id = d.dep_id where emp.age > d.avg_age;
- 内连接:inner join
- 子查询:常用逻辑查询拼接
- 示例一:找技术部门的所有人的姓名
- 先找到部门表技术部门的部门id
- select id from department where name = '技术';
- 再找emp表中部门id = 200
- select name from emp where dep_id = 查询结果;
- 子查询:select name from emp where dep_id = (select id from department where name = '技术');
- 先找到部门表技术部门的部门id
- 示例二:查看不足1人的部门名(子查询得到的是有人的部门id
- 查emp表中有哪些部门id
- select dep_id from emp group by dep_id;
- 再看department表中
- select * from department where id not in (查询结果)
- 子查询:select * from department where id not in (select dep_id from emp group by dep_id);
- 查emp表中有哪些部门id
- 示例一:找技术部门的所有人的姓名
1.5 Navicat工具与pymysql模块
1.5.1 Navicat
官网下载:https://www.navicat.com/en/products/navicat-for-mysql
掌握:
#1. 测试+链接数据库
#2. 新建库
#3. 新建表,新增字段+类型+约束
#4. 设计表:外键
#5. 新建查询
#6. 备份库/表
#注意:
批量加注释:ctrl+?键
批量去注释:ctrl+shift+?键
1.5.2 pymysql模块
1.5.2.1 介绍
之前我们都是通过MySQL自带的命令行客户端工具mysql来操作数据库,那如何在python程序中操作数据库呢?这就用到了pymysql模块,该模块本质就是一个套接字客户端软件,使用前需要事先安装
pip3 install pymysql
1.5.2.2 链接、执行sql、关闭(游标)
import pymysql
user=input('用户名: ').strip()
pwd=input('密码: ').strip()
#链接
conn=pymysql.connect(host='localhost',user='root',password='123',database='egon',charset='utf8')
#游标
cursor=conn.cursor() #执行完毕返回的结果集默认以元组显示
#cursor=conn.cursor(cursor=pymysql.cursors.SSCursor) # 以字典显示不缓存游标,主要用于当操作需要返回大量数据的时候
#cursor=conn.cursor(cursor=pymysql.cursors.DictCursor) # 以字典的形式返回操作结果
#cursor=conn.cursor(cursor=pymysql.cursors.SSDictCursor) # 不缓存游标,将结果以字典的形式进行返回
#执行sql语句
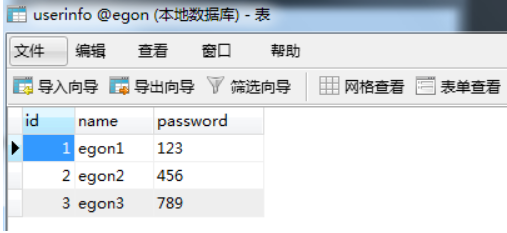
sql='select * from userinfo where name="%s" and password="%s"' %(user,pwd) #注意%s需要加引号
print(sql)
res=cursor.execute(sql) #执行sql语句,返回sql查询成功的记录数目
print(res) #数量
cursor.close()
conn.close()
if res:
print('登录成功')
else:
print('登录失败')
对于大数据量的查询请求,最好使用pymysql.cursors.SSDictCursor游标类,其可以让fetchone依次读取每条数据记录,不用占用非常大的内存,非常适合大数据量的请求。
def get_news(column_id, max_id):
"""
生成器方式获取数据
:return:
"""
conn = pymysql.connect(host=DB_HOST, user=DB_USER, password=DB_PASS, db=DB_NAME, charset='utf8mb4',
cursorclass=pymysql.cursors.SSDictCursor)
sql = "SELECT * FROM `news`"
with conn.cursor() as cursor:
cursor.execute(sql)
result = cursor.fetchone()
while result is not None:
yield result
result = cursor.fetchone()
conn.close()
注意:
因为 SSCursor 是没有缓存的游标,结果集只要没取完,这个 conn 是不能再处理别的 sql,包括另外生成一个cursor也不行的,否则会打乱游标的位置。如果需要干别的,请另外再生成一个连接对象。
每次读取后处理数据要快,不能超过30s,否则 mysql将会断开这次连接,也可以修改net_read_timeout,如set global net_read_timeout = 200 来增加超时间隔,查看用SHOW VARIABLES LIKE '%net_read_timeout%'。
1.5.2.3 execute()之sql注入
sql注入:影响sql语句的正常执行
- 在sql语句中,--代表会注释掉--之后的sql语句
- 防止sql注入:避免用户输入的内容中有类似--这种能影响sql语句的内容
- 解决方式:不要自己拼接用户输入的内容,让pymysql帮忙拼接
最后那一个空格,在一条sql语句中如果遇到select * from t1 where id > 3 -- and name='egon';则--之后的条件被注释掉了
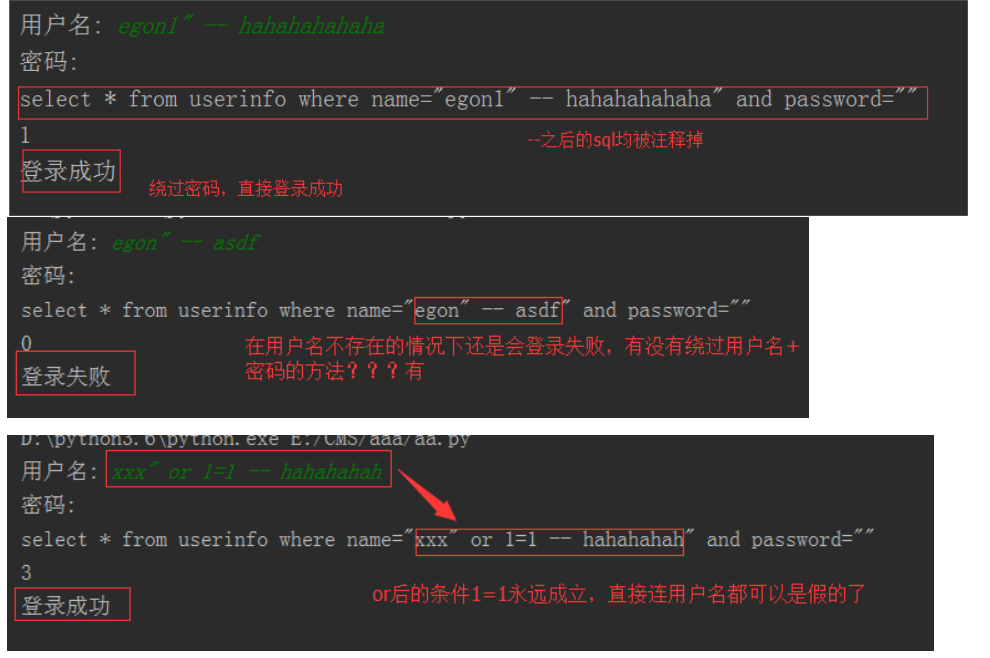
#1、sql注入之:用户存在,绕过密码
egon' -- 任意字符
#2、sql注入之:用户不存在,绕过用户与密码
xxx' or 1=1 -- 任意字符
解决方法:
# 原来是我们对sql进行字符串拼接
# sql="select * from userinfo where name='%s' and password='%s'" %(user,pwd)
# print(sql)
# res=cursor.execute(sql)
#改写为(execute帮我们做字符串拼接,我们无需且一定不能再为%s加引号了)
sql="select * from userinfo where name=%s and password=%s" #!!!注意%s需要去掉引号,因为pymysql会自动为我们加上
res=cursor.execute(sql,[user,pwd]) #pymysql模块自动帮我们解决sql注入的问题,只要我们按照pymysql的规矩来。
1.5.2.4 增、删、改:conn.commit()
import pymysql
#链接
conn=pymysql.connect(host='localhost',user='root',password='123',database='egon')
#游标
cursor=conn.cursor()
#执行sql语句
#part1
# sql='insert into userinfo(name,password) values("root","123456");'
# res=cursor.execute(sql) #执行sql语句,返回sql影响成功的行数
# print(res)
#part2
# sql='insert into userinfo(name,password) values(%s,%s);'
# res=cursor.execute(sql,("root","123456")) #执行sql语句,返回sql影响成功的行数
# print(res)
#part3
sql='insert into userinfo(name,password) values(%s,%s);'
res=cursor.executemany(sql,[("root","123456"),("lhf","12356"),("eee","156")]) #执行sql语句,返回sql影响成功的行数
print(res)
conn.commit() #提交后才发现表中插入记录成功
cursor.close()
conn.close()
1.5.2.5 查:fetchone,fetchmany,fetchall**
# 查
import pymysql
conn = pymysql.connect(host='127.0.0.1', user='root', password="123",database='day40')
# 参数pymysql.cursors.DictCursor将结果设置字典结果输出
cur = conn.cursor(pymysql.cursors.DictCursor) # 数据库操作符:游标
cur.execute('select * from employee where id > 10') # 查询数据
ret = cur.fetchone() # 查询第1条数据
ret = cur.fetchmany(5) # 查询前5条数据
ret = cur.fetchall() # 查询所有数据
print(ret) # 没有参数输出为元组,有参数输出为字典
conn.close()
1.5.2.6 获取插入的最后一条数据的自增ID
import pymysql
conn=pymysql.connect(host='localhost',user='root',password='123',database='egon')
cursor=conn.cursor()
sql='insert into userinfo(name,password) values("xxx","123");'
rows=cursor.execute(sql)
print(cursor.lastrowid) #在插入语句后查看
conn.commit()
cursor.close()
conn.close()
1.5.2.7 pymysql的SSCursor踩的生成器的坑
在Python3连接mysql要用到pymysql模块。
一般用的是普通游标,执行select等语句fetchall时是直接存入内存,有内存不够的风险。这时可以用SSCursor,貌似中文叫做流式游标?连接时需要这样:
conn = pymysql.connect(dbhost, dbuser, dbpass, dbname, charset='utf8')
cur = conn.cursor(pymysql.cursors.SSCursor)
# 也可以cur = pymysql.cursors.SSCursor(conn)
总之,在执行select等sql语句后
cur.execute(sql)
可以通过for循环遍历cur,此时cur相当于生成器,不会直接存储所有数据,而是在循环时一条一条生成数据。
for i in cur:
print(i)
或者存储需要的数据
l = (i[0] for i in cur)
# 数据量不大时也可以用列表生成式l = [i[0] for i in cur]
即使只select一种数据,出现的结果也是元组,类似于(1,),而一般需要的数据只是元组里的这个1,若使用
l = (i for i in cur)
由于没有解包元组,得不到想要的结果。
https://blog.csdn.net/xc_zhou/article/details/83830496
1.6 mysql内置功能
事务:事务用于将某些操作的多个SQL作为原子性操作,一旦有某一个出现错误,即可回滚到原来的状态,从而保证数据库数据完整性。
关键字:begin,for update,commit
begin; # 开启事务
select * from emp where id = 1 for update; # 查询id值,for update添加行锁;
update emp set salary=10000 where id = 1; # 完成更新
commit; # 提交事务,此时锁才结束
视图、触发器、存储过程、事务、流程控制见
http://book.luffycity.com/python-book/di-8-zhang-mysql-shu-ju-ku/87-mysqlnei-zhi-gong-neng.html
1.7 索引原理与慢查询优化
1.7.1 索引原理
1、索引的定义:就是建立起的一个在存储表阶段就有的一个存储结构,能在查询的时候加速查询效果。对写的操作无关。
2、索引的重要性:
- 读写比例:10:1
- 读(查询)的速度就至关重要
3、索引的原理:block磁盘预读原理 --减少io操作的次数
- 读磁盘的io操作的时间非常的长,比cpu执行指令的时间长很多
- 尽量的减少IO次数才是读写数据的主要解决的问题
4、数据库的存储方式
- 新的数据结构--树
- 平衡树 balance tree-b树
- 在b树的基础上进行了改良-b+树
- 分支节点和根节点都不在存储实际的数据了,让分支节点和根节点能存储更多的索引信息,就降低了树的高度(就能减少磁盘的IO次数),所有的实际数据都存储在叶子节点中。
- 在叶子节点之间加入了双向的链式结构,方便在查询中的范围条件
- mysql当中所有的b+树索引的高度基本都控制在3层
- io操作的次数非常稳定
- 有利于通过范围查询
- 什么会影响索引的效率---树的高度
- 对哪一列创建索引,选择尽量短的列做索引
- 对区分度高的创建索引,重复率超过10%的不适合做索引
5、聚集索引的辅助索引
- 在innodb中,聚集索引和辅助索引并存,在myisam中,只有辅助索引,没有聚集索引
- 聚集索引--只有主键才叫聚集索引
- 查询速度更快
- 因为所有的数据直接存在树结构的叶子节点
- 辅助索引---除了主键之外的所有索引都是辅助索引
- 查询速度稍慢
- 数据不直接存储在树中
6、索引的种类
- primary key 主键:聚集索引,有约束的作用:非空+唯一,可以联合主键
- unique 自带索引:辅助索引,约束的作用:唯一,联合唯一
- index:辅助索引,没有约束作用,联合索引
7、创建索引:create index index_name on table(字段)
8、删除索引:drop index 索引名 on 表名字;
9、索引是如何发挥作用的?
- select * from table where id ='xxxx';
- 在id字段没有索引的时候,效率低
- 在id字段有索引的时候,效率高
- 查询的不是索引字段是,效率也低
10、索引不生效的原因
- 要查询的数据的范围大,索引不生效 (io查找的次数多)
- 比较运算符:> < = >= <= !=
- between and
- select * from table limit 100000,5; 没命中索引
- select * from talble where id between 100000 and 100005; 命中
- like ,结果范围大,索引不生效
- 如果 abc% 索引生效,%abc索引就不生效
- 如果索引列内容的区分度不高,索引不生效
- 索引列在条件中参与计算,索引不生效
- select * from s1 where id*10 = 10000;
- 对两列 内容进行条件查询
- and
- and条件两端的内容,优先选择一个有索引的,并且树形结构更好的来进行查询
- 两个条件都成立才能完成where条件,先完成范围小的缩小后面条件的压力
- select * from s1 where id =1000000 and email = 'eva1000000@oldboy';
- or
- or条件的,不会进行优化,只是根据条件从左到右依次筛选
- 条件中带有or的要想命中索引,这些条件中所有的列都是索引列
- select * from s1 where id =1000000 or email = 'eva1000000@oldboy';
- and
- 联合索引的最左前缀原则
- 创建联合索引:create index ind_mix on s1(id,name,email); 三个字段做成联合索引
- 在联合索引中如果使用了or条件索引就不能生效
- 最左前缀原则:在联合索引中,条件必须含有在创建索引的时候的第一个索引(id)
- select * from s1 where id =1000000; 能命中索引
- select * from s1 where email = 'eva1000000@oldboy'; 不能命中索引
- 在整个条件中,从开始出现模糊匹配的那一刻,索引就失效了
- select * from s1 where id >1000000 and email = 'eva1000001@oldboy'; 能命中索引
- select * from s1 where id =1000000 and email like 'eva%'; 不能命中索引
- 什么时候用联合索引?
- 只对a或与a有关的,如abc等条件进行索引,而不会对b或c进行单列的索引时,使用联合索引
11、单列索引
- 选择一个区分度高的列建立索引,条件中的列不要参与计算,条件的范围尽量小,使用and作为条件的连接符
- 使用or来连接多个条件时,在满足上述条件的基础上,对or相关的所有列分别创建索引
12、覆盖索引:如果我们使用索引作为条件查询,查询完毕之后,不需要回表查,这就是覆盖索引
13、合并索引:对两个字段分别创建索引,由于sql的条件让两个索引同时生效了,那么这两个索引就成为了合并索引
14、执行计划 : 如果你想在执行sql之前就知道sql语句的执行情况,那么可以使用执行计划
- 情况1:假设30000000条数据,sql:20s
- 使用explain + sql语句 --> 并不会真正的执行sql,而是会给你列出一个执行计划
- 情况2:数据不足时,使用explain + sql语句 --> 并不会真正的执行sql,而是会给你列出一个执行计划
1.7.2 慢查询优化的基本步骤
0.先运行看看是否真的很慢,注意设置SQL_NO_CACHE
1.where条件单表查,锁定最小返回记录表。这句话的意思是把查询语句的where都应用到表中返回的记录数最小的表开始查起,单表每个字段分别查询,看哪个字段的区分度最高
2.explain查看执行计划,是否与1预期一致(从锁定记录较少的表开始查询)
3.order by limit 形式的sql语句让排序的表优先查
4.了解业务方使用场景
5.加索引时参照建索引的几大原则
6.观察结果,不符合预期继续从0分析
今天想测试下 like 'string%' 和 left() 的效率问题 想到了公司DBA大哥曾经用过的mysql 函数
sql_no_cache
顺便说下测试结果。。因为目前mysql 是不支持函数索引的 所以 2是完胜的
1、select sql_no_cache * from test where left( goods_title, 11 ) = 'metersbonwe'
2、select sql_no_cache * from test where goods_title like 'metersbonwe%'
1.8 数据备份和恢复
-
数据备份:使用的不再是mysql.exe,而是mysqldump.exe
#语法: mysqldump -h 服务器 -u用户名 -p密码 数据库名 > 备份文件.sql #示例: #单库备份 mysqldump -uroot -p123 db1 > db1.sql mysqldump -uroot -p123 db1 table1 table2 > db1-table1-table2.sql #多库备份 mysqldump -uroot -p123 --databases db1 db2 mysql db3 > db1_db2_mysql_db3.sql #备份所有库 mysqldump -uroot -p123 --all-databases > all.sql -
数据恢复:
#方法一: [root@egon backup]# mysql -uroot -p123 < /backup/all.sql #方法二: mysql> use db1; mysql> SET SQL_LOG_BIN=0; #关闭二进制日志,只对当前session生效 mysql> source /root/db1.sql #主要使用这种方式
1.9 本章小结
- 数据库分类
- 关系型数据库:
- sql server
- oracle
- mysql
- sqllite
- 非关系型数据库:
- redis
- mongodb
- 关系型数据库:
- 什么是SQL语句?
- 定义:结构化查询语句
- 分类:
- DDL:数据库定义语言,创建库、创建表
- DML:数据库操纵语言,存数据,删除数据
- DCL:数据库控制语言,给用户授权
- mysql的存储引擎及其特点?
- myisam
- 适合做读、插入数据比较频繁的,对修改和删除涉及少的
- 有表级锁,不支持事务、行级锁和外键
- 索引和数据分开存储的,mysql5.5以下默认的存储引擎
- innodb
- 适合并发比较高的,对事务一致性要求高的
- 相对更适应频繁的修改和删除操作,有行级锁、表级锁,外键且支持事务
- 索引和数据是存在一起的,mysql5.6以上默认的存储引擎
- memory
- 数据存在内存中,表结构存在硬盘上,查询速度快,重启数据丢失
- myisam
- mysql的数据类型有哪些?
- 数值类型
- 整数:int
- 小数:float
- 日期和时间类型
- 年:year
- 年月日:date
- 时分秒:time
- 年月日时分秒:datetime、timestamp
- 字符串类型
- 定长的单位:char
- 变长的单位:varchar
- ENUM和SET类型
- 单选(枚举):enum
- 多选:set
- 数值类型
- mysql中的约束有哪些?
- 无符号:unsigned
- 非空:not null
- 默认值:default
- 唯一:unique
- 自增:auto_increment
- 主键:primary key
- 外键:foreign key
- 多表查询的分类
- 连表查询:把两张表连在一起查
- 内连接 inner join:两张表条件不匹配的项不会出现再结果中
- 外连接:
- 左外连接 left join:永远显示全量的左表中的数据
- 右外连接:right join:永远显示全量的右表中的数据
- 子查询
- 连表查询:把两张表连在一起查
- 索引不生效的情况有哪些?
- 要查询的数据的范围大,索引不生效
- 比较运算符:> < >= <= !=
- between and
- like,结果的范围大,索引不生效
- 如果索引列内容的区分度不高,索引不生效
- 索引列在条件中参与计算,索引不生效
- 对两列内容进行条件查询,条件中带有or的,并且这些条件中所有的列不全是索引列,索引不生效
- 在联合索引中,不满足最左前缀原则,索引不生效
- 最左前缀原则 :在联合索引中,条件必须含有在创建索引的时候的第一个索引列
- 要查询的数据的范围大,索引不生效

 浙公网安备 33010602011771号
浙公网安备 33010602011771号