

Python从无到有搭建接口(API)自动化测试框架
转自:https://www.csdn.net/tags/MtTaMgwsMTg2MjI4LWJsb2cO0O0O.html
Python从无到有搭建接口(API)自动化测试框架 2021-01-03 23:51:03
-
目录
1、前言
自动化测试,是测试道路上不可或缺的重要部分,现在有很多自动测试工具,基本可以满足软件市场的测试要求,但使用工具让人知其然而不知其所以然,学会了也只是一个自动化测试工具人,所以学会自动化框架,是摆脱工具人、提升自己、加薪升职的必经之路;
天王刘德华说:学到了要教人。
这是一个已经学会了的人分享的一点知识,希望测试同胞们在前进路上路过我这篇博客时,如得感觉有一点点的帮助,请留下您的一个赞。
观看此文时,需要有入门级的Python代码基础,如没有,请先去找视频教程学习一段时间。
本文所有讲解代码与执行结果用截图展示,这为了是让您看着可以有个写代码的过程,提升自己;当然如果不想写,也可以只接跳转每一小节末尾,整体代码展示,可以"使用程序员高阶技能ctrl+c, ctrl+v"自行学习。
代码库:魂尾/testApi
2、思路
1、搭建一个目录框架
如下图

common目录里内容含义
setApirequest.py 实现API接口请求的模块,实现发送post/get等方法;
getCase.py 实现读取data目录里的用例文件数据的,设计执行格式,输出JSON用例集;
getConfig.py 实现读取config目录下的配置文件;
initPath.py 实现获取框架文件路径,方便其他模块使用目录方法;
log.py 实现日志打印统一入口,将文件输出到log目录里;
operatorDB.py 实现读写数据的方法;
parameteriZation.py 实现数据参数化的实体类;
sendEmail.py\ SendMsg.py 实现实时发送测试报告至邮件与企业微信的方法;
kemel目录里内容含义
methodFactory.py 实现各方法调用的统一入口;
commKeyworl.py 公共方法、主要是分装所有底层模块的操作入口,并提供一些特殊性的公共方法;
testcase目录里内容含义
图片里目录中没有添加文件。应该是这个文件tsetCase.py,实现解析getCase.py里输出的JSON用例集,执行用例的,检查执行结果的模块,因为Unitest库的要求,此用例解析目录与文件必须以test开头,当然含义也见名思义。
其他目录
data用例文件目录,log输出日志目录、report输出测试报告目录,library引入三方模块目录(ddt数据驱动模块,HTMLRunner测试报告格式化输出模块)
library引入两个三方库的下载路径(重要文件,不或或缺):
ddt:自动代测试数据驱动ddt.py-互联网文档类资源-CSDN下载
HTMLRunner: HTMLTestRunnerNew.py针对《Python从无到有搭建接口(API)自动化测试框架》的测试报告,非此框架勿下载_htmltestrunnernew-互联网文档类资源-CSDN下载
5、分层概念
一个软件MCV的层次概念
M是底层,模型层,封装功能的代码,属于底层代码 。
C是中层,控制层,封装所有底层的接入方法。
V是高层,会话层,运行执行等方法操作。
MVC的区分(分层概念)
common目录下的模块都是M
kemel目录下的模块是C
test_Case.py, testRun.py等运行模块是V
3、正文
一、路径模块-initPath.py
1、了解如何获取当前绝对路径:
先了解python是如何取得当前目录的,我们可以使用内置库os来实现
首先我们得知道 __file__在python中代表当前文件,
然后在菜鸟教程里找到os.path的库,知道获取绝对路径的方法 os.path.abspath(path)

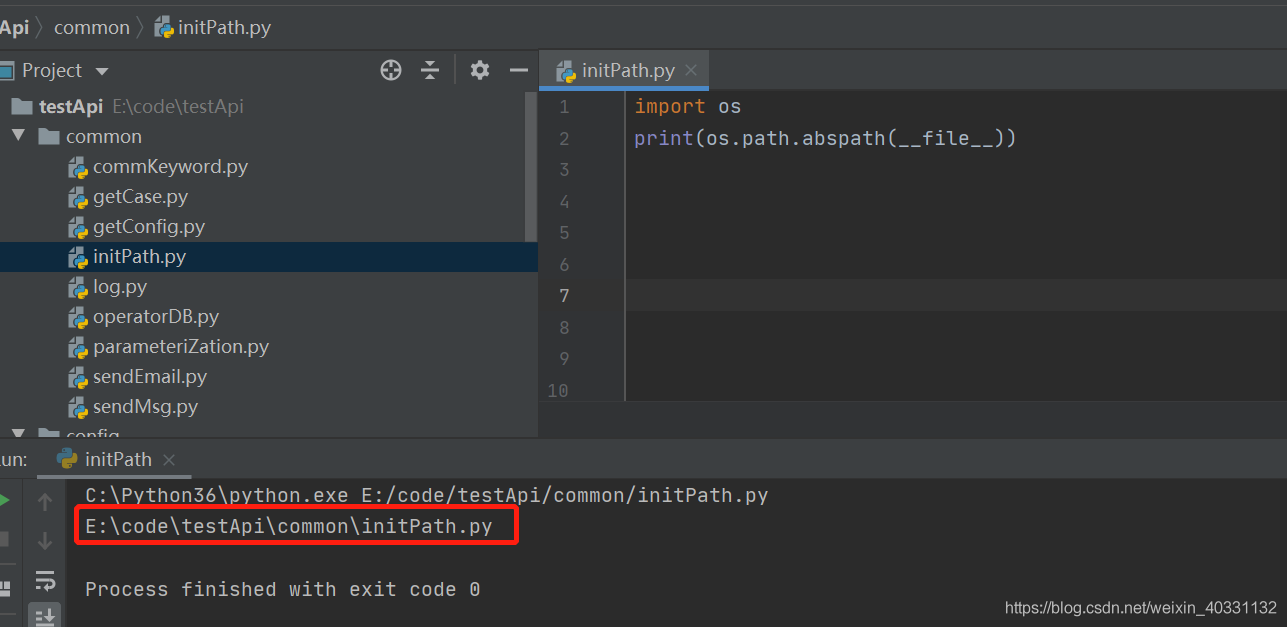
然后开始在initPath.py写代码打印一下os.path.abspath(__file__)方法
见下图,打印出了initPath.py的绝对路径。
2、获取文件路径,不包含本身文件名
在菜鸟找到了os.path,dirname()方法

在initPath.py里使用打印一下这个方法,然后我们希望是\的路径,所以使用os.path.dirname(os.path.abspath(__file__))这个代码取路径

然后我们再增加一层,os.path.dirname(os.path.dirname(os.path.abspath(__file__))),我们是要获取工程根目录路径的。如下图

3、拼接所有路径
我们要拼接目录,需要一个方法,进入菜鸟网,找到os.path.join(path1, path2),合成路径方法

直接写initPath.py的代码了,将项目下所有文件夹的路径都定义好了。打印如下图

initPath.py的代码段
import os #get project dir BASEDIR = os.path.dirname(os.path.dirname(os.path.abspath(__file__))) #get common dir COMMONDIR = os.path.join(BASEDIR, 'common') #get config dir CONFDIR = os.path.join(BASEDIR, 'config') #get data dir DATADIR = os.path.join(BASEDIR, 'data') #get library dir LIBDIR = os.path.join(BASEDIR, 'library') #get log dir LOGDIR = os.path.join(BASEDIR, 'log') #get report dir REPORTDIR = os.path.join(BASEDIR, 'report') #get testcaset dir CASEDIR = os.path.join(BASEDIR, 'testcases')二、配置文件模块-getConfig.py
1、我们先了解一下配置文件
在计算机领域,配置文件:是一种计算机文件,可以为一些计算机程序配置参数和初始设置。
具体文件类型与相关知识点不多说,我们这里使用一ini配置文件,内容格式如下
[about]
aaa = bbb
ccc = ddd
其实about是节点,aaa = bbb是参数,key = value的意思
所以在config/baseCon.ini下配置添加一些配置,如下图

2、读取baseCon.ini里的配置项
获取配置文件路径:
读取配置文件之前,我们得先得到文件baseCon.ini的绝对路径,
先引用已经定义好的config的绝对路径,然后使用os.path.join(path1, path2)方法将baseCon.ini的绝对路径生成,具体代码如下图

了解configparser
ConfigParser 是用来读取配置文件的包。三方库,所以需要通过命令 pip install configparser 来下载。
在代码里直接导入ConfigParser类,然后创建其对像,调用方法read(),读取配置文件,具体代码如下图

仔细学习上面的路子,下面就开始着手封装configparser了,这个库已经很完美了,不过我们后续读取配置文件时需要将读取文件这个步骤也省略,所以稍加封装。
封装configparser配置文件读取
封装的代码运行如下图

nyCof.saveData()方法添加了配置项,写到了baseCon.ini里面

getConfig.py的代码段:
import os from common.initPath import CONFDIR from configparser import ConfigParser # conPath = os.path.join(CONFDIR, 'baseCon.ini') # print(conPath) # cnf = ConfigParser() # cnf.read(conPath, encoding='utf-8') #第一个参数是文件路径,第二个参数是读取的编码 # # print('baseCon.ini里所有节点{}'.format(cnf.sections())) #打印所有节点名称 # print('db下的所有key:{}'.format(cnf.options('db'))) #打印db节点下的所有key # print('db下的所有Item:{}'.format(cnf.items('db'))) #打印db节点下的所有item # print('db下的host的value:{}'.format(cnf.get('db', 'host'))) #打印某个节点的某个value """ 定义Config继续ConfigParser """ class Config(ConfigParser): def __init__(self): """ 初始化 将配置文件读取出来 super(). 调用父类 """ self.conf_name = os.path.join(CONFDIR, 'baseCon.ini') super().__init__() super().read(self.conf_name, encoding='utf-8') def getAllsections(self): """ :return: 返回所有的节点名称 """ return super().sections() def getOptions(self, sectioName): """ :param sectioName: 节点名称 :return: 返回节点所有的key """ return super().options(sectioName) def getItems(self, sectioName): """ :param sectioName: 节点名称 :return: 返回节点的所有item """ return super().items(sectioName) def getValue(self, sectioName, key): """ :param sectioName: 节点的名称 :param key: key名称 :return: 返回sectioName下key 的value """ return super().get(sectioName, key) def saveData(self, sectioName, key, value): """ 添加配置 :param sectioName: 节点名称 :param key: key名 :param value: 值 :return: """ super().set(section=sectioName, option=key, value=value) super().write(fp=open(self.conf_name, 'w')) myCof = Config() #print(myCof.getAllsections()) #print(myCof.getOptions('db')) #print(myCof.getItems('db')) #print(myCof.getValue('db', 'host')) #myCof.saveData('db', 'newKey', 'newValue')三、读取用例模块-getCase.py
读取用例是框架的比较重要,与独立的模块,不过读取用例前,我们先要设计用例文件与用户格式,一般我们可以将用例放在excel里,或者建立一个mysql数据库,将excel里的数据导入到里面,但后者比较麻烦,所以本文只接读取excel文件里的用例
1、设计用例文件与用例格式
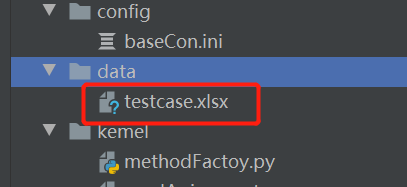
在data目录里新增一个testcase.xlsx的excel文件,目录如下图:
打开testcase.xlsx,在sheet1里设计用例表头,如下图:

用例字段的含义:
case_id:id,自己设定数字,只为了输出报告时识别用例的位置
api:url里的接口路由,也是为了输出报告时识别用例的正确性
title: 可以是用例的中文标题,也可以自定义方法中参数化接收数据的变量,格式可以是,abc或${abc}
method: 请求类型 post/get ,或者自定义的方法名称
url: 接口请求中的url,可以被参数化
headers: 接口请求中的headers, 可以被参数化
data: 接口请求中的data, 可以被参数化
checkey:用例检查点的检查方法
expected: 用例检查点的检查值
Test_result: 用例执行完成后,回写给用例的状态,pass/fail,不过我一般不用。
用例示例如下图:

2、设计用例集JSON格式
格式如下:
[ #用例集 { #第一条用例 key1: value1, #用例里的字段与字段值 key2: value2 ... }, { #第二条用例 key1:value1, #用例里的字段与字段 key2: value2 ... }, .... ]根据用例excel文件,具体的JSON用例串应该下面是这样子的,前面字段是excel列表数据,最后一个是sheet_name是表示了sheet页名称。一般接口用例按模块编写,一个模块一个sheet页,以此字段区分,为后面输出测试报告做准备。
[
{
'case_id':1,
'api': 'publickey',
'title':'url',
'method':'设置变量',
'url':'https://www.adbcde.com.cn/',
'headers':'Host:www.adbcde.com.cn',
'data':'userToken=16029513602050&loginpassword=qwert12345&loginphone=15361828291',
'checkey':'结果包含',
'expected':'"return_code": "SUCCESS"',
'Test result':None,
'sheet_name':'sheet1',
},
{
......
}
.....
]
3、openpyxl库学习
读写excel的库有很多,因为用例要求不高,所以选择openpyxl库来封装用例代码
安装使用命令 pip install openpyxl
开始写代码
操作excel用例之前,要得到文件的绝对路径

获取绝对路径成功,接下来开始读取excel里的文件了,
读取excel文件内容
步聚如下图,1、先打开excel文件,2、遍历一下sheet页输出名称,3遍历输出Sheet1里的数据,这三个写后,就表名,excel可以读取成功了。openpyxl也学完了

4、封装用例类
我定义的用例是一个excel文件一个项目,在工作中,应该不止一个项目,所以有可能在data目录里有多个excel文件,我们需要执行哪个呢,所以此能用到前面写的配置文件,在里面加一个case节点,增加执行用例文件名称
一个用例文件中肯定有很多注释的用例,所以定义一个 # 来区分注释用例。两个定义如下图

封装代码无法载图全部,先看执行结果,后面读取用例只需要两行代码就可将用例JSON读取出来

getCase.py的代码段
import os import openpyxl from common.initPath import DATADIR from common.getConfig import myCof # #拼接用例文件绝对路径 # caseFile = os.path.join(DATADIR, 'testcase.xlsx') # print(caseFile) # #读取excel文件 # xl = openpyxl.open(filename=caseFile) # #打印caseFile里的sheet页名称 # print('打印所有sheet页') # for sheet in xl: # print(sheet.title) # #打印excel里的所有的行字段数据 # print('打印Sheet1里的所有的行字段数据') # sh = xl['Sheet1'] # data = list(sh.rows) # for da in data: # for k in da: # print(k.value) class Getcase(object): def __init__(self, sheet_name=None): """ 初始化文件名称,sheet名称,excel对像 :param sheet_name: 传入的sheet名称 ,可以为空。 """ filename = myCof.getValue('case', 'testCase') self.note = myCof.getValue('identifier', 'note') self.caseFile = os.path.join(DATADIR, filename) self.sheet_name = sheet_name self.wb = None def openexcel(self): """ 打开excel文件 如果sheet名称不为空,定位到对应sheet页 :return: """ self.wb = openpyxl.open(self.caseFile) if self.sheet_name is not None: self.sh = self.wb[self.sheet_name] def read_excels(self): """ 格式化用例集 用例格式JSON见上面的前面的描述 过滤掉#注释的用例 :return: """ if self.wb is None: self.openexcel() datas = list(self.sh.rows) title = [i.value for i in datas[0]] cases = [] for i in datas[1:]: data = [k.value for k in i] case = dict(zip(title, data)) #将数据格式化中JSON串 try: if str(case['case_id'])[0] is not self.note: # 过滤掉note符号开头的用例,注释掉不收集、不执行 case['sheet'] = self.sh.title cases.append(case) except KeyError: cases.append(case) return cases def read_all_excels(self): """ 遍历所有的sheet页 取得所有用例集,再格式下一次, 过滤掉#注释的sheet页 :return: """ self.openexcel() cases = [] for sheet in self.wb: if sheet.title[0] is not self.note: # 过滤掉note符号开头的sheet页,注释掉的不收集,不执行 self.sh = sheet cases += self.read_excels() return cases def write_excels(self, rows, column, value): """ 回写用例字段 :param rows: :param column: :param value: :return: """ self.openexcel() self.sh.cell(row=rows, column=column, value=value) self.wb.save(self.caseFile) # readExce = Getcase() # print(readExce.read_all_excels())四、数据库操作模块-operatorDB.py
1、pymysql安装
安装pymysql使用命令pip install pymysql
2、pymysql学习
学习之前,我们先把连接数据库的相关配置参数,在配置文件中取出来
如下图,先导入myCof对像,使用getValue取出对应该的配置参数打印成功

pymysql已经导入成功了,连接数据参数也取出来了,接下来开始连接数据,执行SQL语句
连接数据库
如果没连接成功会抛出异常,所以此时需要 try ... except.....来catch异常,打印出来,下图为连接数据库超时,因为还没起Mysql的服务。
这里我们得先配置好一个mysql服务器,方便调试,不懂的可以在网上找教程学习学习,当然直接用公司的测试环境也行,省时少力。

打开mysql服务后,运行,会报一个错,我们将port参数强转化为int类型,他不能为str类型。
强转后,再运行一次,连接成功了

执行SQL
执行SQL语句,我们需要游标,先获取游标,再使用游标执行SQL,一次通过

打印SQL查询的数据

pymysql学习完成,接下来可以封装了
3、封装数据操作
封装的逻辑是,将连接作一个方法,执行SQL写一个方法,关闭连接写一个方法
先看封装好后的执行结果,只需要写四行代码就可以执行SQL语句了。

opeartorDB.py的代码段:
import pymysql from common.getConfig import myCof # host = myCof.getValue('db', 'host') # port = int(myCof.getValue('db', 'port')) # user = myCof.getValue('db', 'user') # pwd = myCof.getValue('db', 'pwd') # database = myCof.getValue('db', 'database') # charset = myCof.getValue('db', 'charset') # try: # #连接数据库 # db = pymysql.connect(host=host, port=port, user=user, password=pwd, database=database, charset=charset) # #获取游标 # cursor = db.cursor() # #执行SQL # cursor.execute("select * from Student where SName = '林小六';") # #获取查询结果 # result = cursor.fetchall() # #打印查询结果 # print(result) # print('执行成功') # except Exception as e: # print('连接失败,原因:{}'.format(str(e))) """ 封装mysql操作 """ class OpeartorDB(object): def __init__(self): """ 初始化方法,习惯性留着 """ pass def connectDB(self): """ 连接数据库 :return: 返回成功失败,原因 """ host = myCof.getValue('db', 'host') port = myCof.getValue('db', 'port') user = myCof.getValue('db', 'user') pwd = myCof.getValue('db', 'pwd') database = myCof.getValue('db', 'database') charset = myCof.getValue('db', 'charset') try: self.db = pymysql.connect(host=host, port=int(port), user=user, password=pwd, database=database, charset=charset) return True, '连接数据成功' except Exception as e: return False, '连接数据失败【' + str(e) + '】' def closeDB(self): """ 关闭数据连接,不关闭会导致数据连接数不能释放,影响数据库性能 :return: """ self.db.close() def excetSql(self, enpsql): """ 执行sql方法, :param enpsql: 传入的sql语句 :return: 返回成功与执行结果 或 失败与失败原因 """ isOK, result = self.connectDB() if isOK is False: return isOK, result try: cursor = self.db.cursor() cursor.execute(enpsql) res = cursor.fetchone() #为了自动化测试的速度,一般场景所以只取一条数据 if res is not None and 'select' in enpsql.lower(): #判断是不是查询, des = cursor.description[0] result = dict(zip(des, res)) #将返回数据格式化成JSON串 elif res is None and ('insert' in enpsql.lower() or 'update' in enpsql.lower()): #判断是不是插入或者更新数据 self.db.commit() #提交数据操作,不然插入或者更新,数据只会更新在缓存,没正式落库 result = '' #操作数据,不需要返回数据 cursor.close() #关闭游标 self.closeDB() #关闭数据连接 return True, result except Exception as e: return False, 'SQL执行失败,原因:[' + str(e) + ']' # sql = 'select * from Student' # oper = OpeartorDB() # isOK, result = oper.excetSql(sql) # print(result)五、日志模块-log.py
1、logging学习
logging是python的基础库,不需要下载,直接导入可用
日志有五个等级,自动测试一般INFO等都打印,所以我们在配置文件里的加上日志参数配置
[log]
level = INFO

打印日志
编写代码,先获取日志等级配置,然后设置日志等级,初始化日志对像,打印日志,因为日志等是INFO,所以debug的日志不会打印,代码如下图

设置日志格式
格式设置如下图

将日志输出到文件
日志文件存放在log目录下,所以先获取导入目录与os
设计日志文件隔一天时间,日志就另新增一个,保留十五天,所以需要导入logging里的一个方法TimedRotatingFileHandler、
from logging.handlers import TimedRotatingFileHandler #导入的方法
代码如下图

运行后,输出了testReport文件,里面打印了执行日志

logging基本学习完成 ,再简单封装一下
2、日志模块封装
封装日志这一块,不需要创建对像,因为他本身需要返回一个logging的对象,对象操作对象,别扭,所以在Log类里直接封装一个静态的方法,可以直接类调用方法返回一个logging对象。
调式执行结果与上面一致,但不截图了,直接上代码
log.py代码段
import os import logging from common.getConfig import myCof from common.initPath import LOGDIR from logging.handlers import TimedRotatingFileHandler # # 获取日志等配置参数 # level = myCof.getValue('log', 'level') # # 设置日志格式,%(asctime)s表示时间,%(name)s表示传入的标识名,%(levelname)s表示日志等级,%(message)s表示日志消息 # format = '%(asctime)s - %(name)s-%(levelname)s: %(message)s' # # 设置日志基础等级, 设置 # logging.basicConfig(level=level, format=format) # # 初始化日志对像,Hunwei是name # mylog = logging.getLogger('Hunwei') # #拼接日志目录 # log_path = os.path.join(LOGDIR, 'testReport') # #生成文件句柄,filename是文件路径,when表是时间D表示天,backuCount=15目录下最多15个日志文件,enccoding='utf-8'日志字符格式 # fh = TimedRotatingFileHandler(filename=log_path, when="D", backupCount=15, encoding='utf-8') # #设置历史日志文件名称的格式,会自动按照某天生成对应的日志 # fh.suffix = "%Y-%m-%d.log" # #设置文件输出的日志等级 # fh.setLevel(level) # #设置文件输出的日志格式 # fh.setFormatter(logging.Formatter("%(asctime)s - %(name)s-%(levelname)s: %(message)s")) # #将文件句柄加入日志对象 # mylog.addHandler(fh) # # mylog.debug('debug') # mylog.info('info') # mylog.warn('warm') # mylog.error('error') # mylog.fatal('fatal') class Log(object): @staticmethod def getMylog(): # 获取日志等配置参数 level = myCof.getValue('log', 'level') # 设置日志格式,%(asctime)s表示时间,%(name)s表示传入的标识名,%(levelname)s表示日志等级,%(message)s表示日志消息 format = '%(asctime)s - %(name)s-%(levelname)s: %(message)s' # 设置日志基础等级, 设置 logging.basicConfig(level=level, format=format) # 初始化日志对像,Hunwei是name mylog = logging.getLogger('Hunwei') # 拼接日志目录 log_path = os.path.join(LOGDIR, 'testReport') # 生成文件句柄,filename是文件路径,when表是时间D表示天,backuCount=15目录下最多15个日志文件,enccoding='utf-8'日志字符格式 fh = TimedRotatingFileHandler(filename=log_path, when="D", backupCount=15, encoding='utf-8') # 设置历史日志文件名称的格式,会自动按照某天生成对应的日志 fh.suffix = "%Y-%m-%d.log" # 设置文件输出的日志等级 fh.setLevel(level) # 设置文件输出的日志格式 fh.setFormatter(logging.Formatter("%(asctime)s - %(name)s-%(levelname)s: %(message)s")) # 将文件句柄加入日志对象 mylog.addHandler(fh) #返回logging对像 return mylog #调式代码 mylog = Log.getMylog() # mylog.debug('debug') # mylog.info('info') # mylog.warn('warm') # mylog.error('error') # mylog.fatal('fatal')六、邮件模块-sendEmail.py
1、开启邮箱的SMTP服务
email邮箱提供商都可以开启smtp服务的,如果知道什么是smtp并知道设置的朋友可以略过这一段
以qq邮箱为例
进入qqmail.com登录邮箱,找到【设置】-【账户】,点击POP3/SMTP 开启(下图标记的有误,别被误导了哈)

按描述发送短信

开启之后,我们会得到一个密钥,好好保存,
2、学习使用smtplib库发送带附件的邮件
邮件参数添加到配置文件
host 是邮件服务器,腾讯的是smtp.qq.com,
port 是邮件服务器端口,开通smtp时,腾讯会邮件告之端口号
user是邮箱、pwd是开通smtp时得到的密钥
from_addr 是发送邮箱地址,与user是同一个
to_addr是收件箱,可以做成逗号分隔

连接smtp服务器
一般连接啥服务器没成功都会抛异常呀,所以用一下try,新建一个smtplib的对像,带上服务器与端口,然后使用用户名密码连接

发送邮件
发送邮件之前需要构建一个邮件内容,所以所以email库,可以通过pip install email下载,使用
先构建一个纯文本的内容 ,所以导入 MIMEText,
下面是构建邮件内容与发送成功的截图,msg消息休是邮件内容 ,里面需要文本,发送人,收件人,邮件主题等参数

发送成功后,进入邮箱查看邮件

邮件发送成功后了,基础的已经学会了,还有两种邮件类型、MIMEMultipart多媒体内型,MIMEApplication附件内型,不多赘述,看后面封装代码即可通明
3、封装代码
封装代码前呢,先知道了一般的自动化报告是html格式的,这里我拿了以前的测试放在工程report目录下,方便使用,如下图

封装邮件模块后,两行代码即可发送测试报告。

sendEmail.py的代码段
import os import smtplib from common.getConfig import myCof from email.mime.text import MIMEText #导入纯文本格式 from email.mime.multipart import MIMEMultipart from email.mime.application import MIMEApplication from common.initPath import REPORTDIR # host = myCof.getValue('email', 'host') # port = int(myCof.getValue('email', 'port')) # user = myCof.getValue('email', 'user') # pwd = myCof.getValue('email', 'pwd') # to_addr = myCof.getValue('email', 'to_addr') # #定义纯文本消息 ,From定义发件人, To定义收件人, Subject定义邮件标题 # msg = MIMEText('hello,send by python_test...','plain','utf-8') # msg['From'] = user # msg['To'] = to_addr # msg['Subject'] = '测试邮件发送' # try: # #连接smtp服务对话,创建对像 # smtp = smtplib.SMTP_SSL(host=host, port=port) # #登录服务器 # smtp.login(user=user, password=pwd) # # 发送邮件 # smtp.sendmail(from_addr=user, to_addrs=to_addr, msg=msg.as_string()) # # 结束与服务器的对话 # smtp.quit() # print('发送邮件成功') # except Exception as e: # print('发送邮件失败,原因:{}'.format(str(e))) class SendMail(object): def __init__(self): """ 初始化文件路径与相关配置 """ all_path = [] #获取测试报告目录下的报告文件名称 for maindir, subdir, file_list in os.walk(REPORTDIR): pass #拼接文件绝对路径 for filename in file_list: all_path.append(os.path.join(REPORTDIR, filename)) self.filename = all_path[0] self.host = myCof.get('email', 'host') self.port = myCof.get('email', 'port') self.user = myCof.get('email', 'user') self.pwd = myCof.get('email', 'pwd') self.from_addr = myCof.get('email', 'from_addr') self.to_addr = myCof.get('email', 'to_addr') def get_email_host_smtp(self): """ 连接stmp服务器 :return: """ try: self.smtp = smtplib.SMTP_SSL(host=self.host, port=self.port) self.smtp.login(user=self.user, password=self.pwd) return True, '连接成功' except Exception as e: return False, '连接邮箱服务器失败,原因:' + str(e) def made_msg(self): """ 构建一封邮件 :return: """ # 新增一个多组件邮件 self.msg = MIMEMultipart() with open(self.filename, 'rb') as f: content = f.read() # 创建文本内容 text_msg = MIMEText(content, _subtype='html', _charset='utf8') # 添加到多组件的邮件中 self.msg.attach(text_msg) # 创建邮件的附件 report_file = MIMEApplication(content) report_file.add_header('Content-Disposition', 'attachment', filename=str.split(self.filename, '\\').pop()) self.msg.attach(report_file) # 主题 self.msg['subject'] = '自动化测试报告' # 发件人 self.msg['From'] = self.from_addr # 收件人 self.msg['To'] = self.to_addr def send_email(self): """ 发送邮件 :return: """ isOK, result = self.get_email_host_smtp() if isOK: self.made_msg() self.smtp.send_message(self.msg, from_addr=self.from_addr, to_addrs=self.to_addr) else: return isOK, result # abc = SendMail() # abc.send_email()七、消息模块-sendMsg.py
1、创建企业微信应用
在企业微信建立一个应用,为接收消息的载体,添加相关人员
在Python中实现得到企业微信应用token,
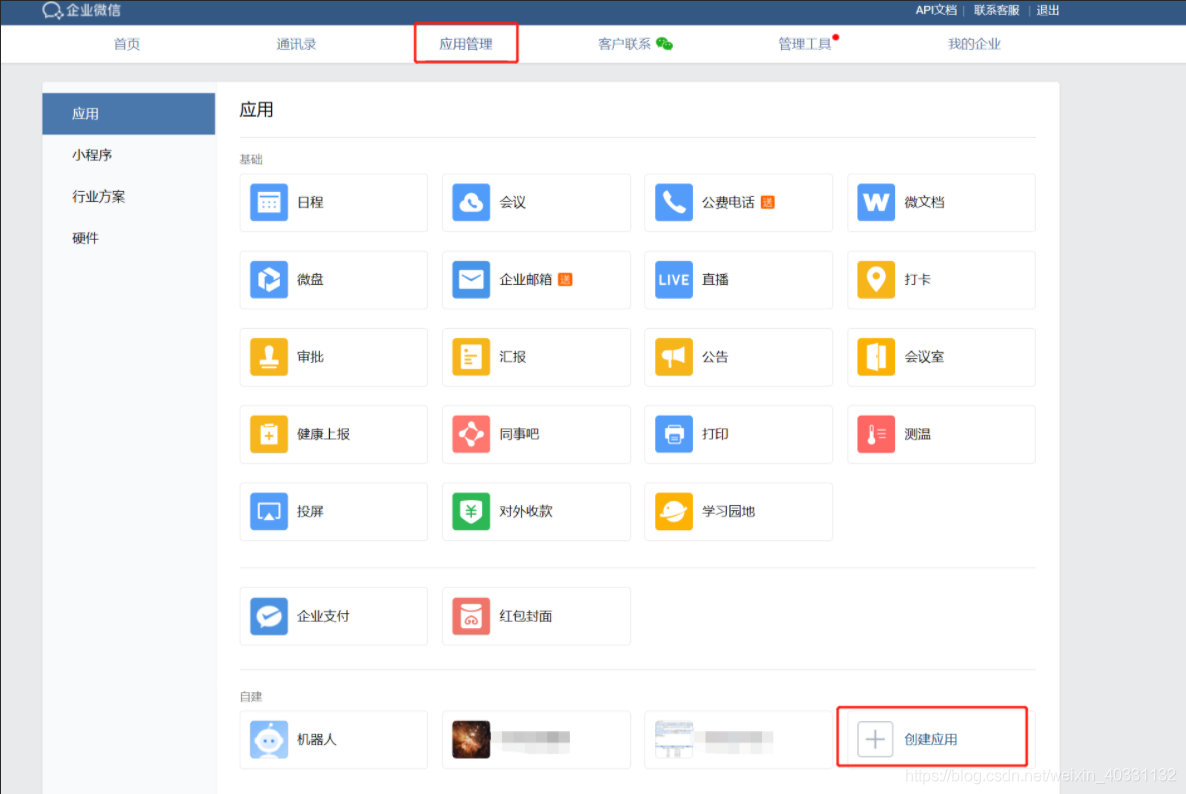
在企业微信官网创建一个公司,或者用公司的企业微信号,获取企业微信的企业ID

创建应用
得到AgentId、Secret
进入新建的应用详情页面,可以得到这两个字段

1、学习发送企业微信消息
资深开发者直接会找企业微信的API开发指南,应该知道怎么封装了。
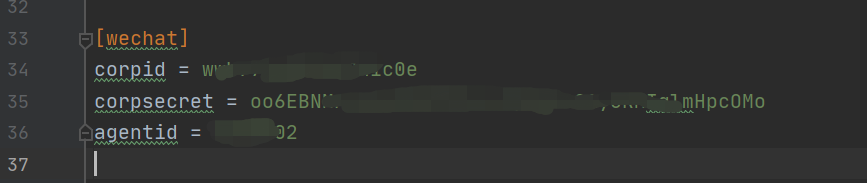
先将创建应该时得到的三个参数配置到baseCon.ini文件里
获取企业微信的token
拼接得获取token的API url,corpid与corpsecret字段为参数,用requests.get()方法请求,从结果集中解析出token字段值

发送消息
发送消息的代码如下图,先拼接发送消息的api的url,需要添加上面得到token值,再构造一个消息,转换成bytes格式的消息休,使用requests.post发送消息

企业微信收到了消息,如下图

2、代码封装
封装完成后,只需要两行代码就可以发送消息了
sendMsg.py的代码段
import requests import json from common.getConfig import myCof # # 获取企业微信的参数 # corpid = myCof.get('wechat', 'corpid') # corpsecret = myCof.get('wechat', 'corpsecret') # agentid = myCof.get('wechat', 'agentid') # # 拼接获取token的API # url = 'https://qyapi.weixin.qq.com/cgi-bin/gettoken?corpid=' + corpid + '&corpsecret=' + corpsecret # # 使用requests请求API,转为JSON格式 # response = requests.get(url) # res = response.json() # #获取token打印 # token = res['access_token'] # print(token) # # 拼接发送消息的api # url = 'https://qyapi.weixin.qq.com/cgi-bin/message/send?access_token=' + token # # 构建一个消息JSON串 # jsonmsg = { # "touser" : "@all", # "msgtype" : "text", # "agentid" : agentid, # "text" : { # "content" : "API接口从无到有" # }, # "safe":0 # } # # 将JSON转成str,再转成bytes格式的消息休 # data = (bytes(json.dumps(jsonmsg), 'utf-8')) # # 使用requests post发送消息 # requests.post(url, data, verify=False) class SendMsg(object): def __init__(self): self.corpid = myCof.get('wechat', 'corpid') self.corpsecret = myCof.get('wechat', 'corpsecret') self.agentid = myCof.get('wechat', 'agentid') def getToken(self): if self.corpid is None or self.corpsecret is None: return False, '企业微信相关信息未配置' url = 'https://qyapi.weixin.qq.com/cgi-bin/gettoken?corpid=' + self.corpid + '&corpsecret=' + self.corpsecret response = requests.get(url) res = response.json() self.token = res['access_token'] return True, '企业微信token获取成功' def sendMsg(self, msg): _isOK, result = self.getToken() if _isOK: url = 'https://qyapi.weixin.qq.com/cgi-bin/message/send?access_token=' + self.token jsonmsg = { "touser" : "@all", "msgtype" : "text", "agentid" : self.agentid, "text" : { "content" : msg }, "safe":0 } data = (bytes(json.dumps(jsonmsg), 'utf-8')) requests.post(url, data, verify=False) else: print(result) # wechatMsg = SendMsg() # wechatMsg.sendMsg('API接口从无到有')八、变量参数化模块-parameteriZation.py
前面七小节已经将自动化测试框架的周边全部弄完了,接下来便开始写核心模块了。
自动化测试工具有很多变量可以配置,分为两大类,系统环境变量(在执行之前,人为配置好的变量,执行完还存在),临时变量(在执行过程参数化的变量,执行完成消失,等待下次参数化)
1、系统环境变量
这个很简单 ,我们直接写在配置文件即可,比如我们需要一个账号与密码,将其设置为系统环境变量,直接在bascCon.ini里添加

然后我们导入 myCon,使用getValue方法就可以取到变量的参数了,

这还是第一步,我们需要设计变量的格式,比如 {aaa}, ${aaa},前者使用{}来标识aaa需要参数化,后者用${}来标识aaa需要参数化,
那就将${}定义为变量的标识符
取变量名
那么我们将如何来取变量名呢,比如,${phone},直接使用是取不到手机号码的,需要将phone取出来。此时我们可以使用正则表达式库,re来处理
正则表达式很强大,规则也很多,在这里不做赘述。re的话是Python的基础库,所以可以在菜鸟站上搜索到教程,我们要用到的方法就这两个


代码如下与执行结果见下图

将变量参数化
就是在上面代码里加上获取配置参数即可,代码与执行结果见下图:变量已经参数化了。

2、临时变量
临时变量,这是个检验Python代码基础的活儿,面向对象,属性,setattr ,getattr等知识点。如果懂了我们只需要在上加几行代码就成了。
先定义一个空类。不给属性与方法,在执行代码的过程中使用setattr给这个空类添加属性与值,这个属性即 临时变量,如果想调用,即可用getattr取属性的值,进行参数化
代码如下与执行结果如下

临时变量参数化
设置好临时变量,参数化过程与系统环境变量的差不多,区别是将myCon.getValue(‘par’, key) 改成getattr(Paramte, key)
代码与执行结果如下图:

3、代码封装
parameteriZation.py的代码段
import re from common.getConfig import myCof # phone = myCof.getValue('par','phone') # print(phone) # pwd = myCof.getValue('par', 'pwd') # print(pwd) #定义一个字符串,里面有两个变量 # data = '{PHONE : ${phone}, PASSWORD: ${pwd}}' # #定义正则匹配规则 # ru = r'\${(.*?)}' # #循环取变量名称 # while re.search(ru, data): # #取值第一个变量 # res = re.search(ru, data) # #取出名称 # key = res.group(1) # #取出环境变量 # value = myCof.getValue('par', key) # #替换变量 # data = re.sub(ru, value, data, 1) # #打印替换后的字符串 # print(data) # 给临时变量的空类 # class Paramete(): # pass # # 设置临时变量 # setattr(Paramete, 'phone', '15381819299') # setattr(Paramete, 'pwd', '654321') # # 直接调用取值打印 # # print('直接打印:' + Paramete().phone) # # 通过getattr打印 # # print('getattr打印:' + getattr(Paramete, 'phone')) # data = '{PHONE : ${phone}, PASSWORD: ${pwd}}' # #定义正则匹配规则 # ru = r'\${(.*?)}' # #循环取变量名称 # while re.search(ru, data): # #取值第一个变量 # res = re.search(ru, data) # #取出名称 # key = res.group(1) # #取出环境变量 # value = getattr(Paramete, key) # #替换变量 # data = re.sub(ru, value, data, 1) # # print(data) class Paramete: pass def replace_data(data): """ 替换变量 :param data: :return: """ ru = r'\${(.*?)}' while re.search(ru, data): res = re.search(ru, data) item = res.group() keys = res.group(1) # 先找系统环境变量,如果有则替换;如果没有则找临时变量 try: value = myCof.get('test_data', keys) except Exception as e: value = getattr(Paramete, keys).encode('utf-8').decode('unicode_escape') finally: data = re.sub(ru, value, data, 1) return data def analyzing_param(param): """ ${abc}取出abc :param param: :return: """ ru = r'\${(.*?)}' if re.search(ru, param): return re.findall(ru, param)[0] return param # print(replace_data('${phone}, ${pwd}'))九、API请求模块-sendApirequests.py
1、requests库下载
第三方库,所以需要用命令:pip install requests 下载
2、requests库学习
requests的请求类型
常用的请求类型都在下图

目前主要的请求是get与post
requests.get(url=‘请求api的url’, params=‘get请求的参数,可以为空’, headers=‘请求头,如果接口没有校验,可以为空’)
requests.post(url=‘请求api的url’, json=‘如果json参数,使用json字段’, data=‘如果是表单格式,使用data参数’, files=‘当数据为文件时,使用file参数’, headers=‘请求头,如果接口没有校验,可以为空’)
post里的可以传json、data、file三种参数,但三个只能传一个。
3、api请求封装
sendApirequest.py代码段
这个文件在kemel目录下面
class SendApirequests(object): def __init__(self): self.session = requests.session() def request_Obj(self, method, url, params=None, data=None, json=None, files=None, headers=None,): opetype = str.lower(method) if opetype == 'get': response = requests.get(url=url, params=params, headers=headers) elif opetype == 'post': response = requests.post(url=url, json=json, data=data, files=files, headers=headers) return response封装代码调用-get

封装代码调用-post
十、公共方法的模块(核心)-commKeyword.py
1、公共方法理念
一个软件MCV的层次概念
M是底层,模型层,前面封装的代码都是这种模块,属于底层代码 。
C是中层,控制层,封装所有底层的接入方法。
V是高层,会话层,界面也操作提供给用户使用。
MVC的区分(分层概念)
common目录下的模块都是M
kemel目录下的模块是C
解析用例与运行文件是V
公共方法、主要是分装所有底层模块的操作入口,并提供一些特殊性的公共方法
什么是特殊的公共方法呢?
比如:自动生成手机号码、自动生成身份证号码,自动生成随机字符串,自动生成全国各地区号,设置变量、拆分字段,获取字符串中的指定字段等等。
2、封装
封装完成公共方法,会与后面的工厂结合起来使用
commKeyword.py的代码段
import json import jsonpath import datetime from common.getConfig import myCof from common.getCase import Getcase from common.operatorDB import OpeartorDB from common.parameteriZation import Paramete, analyzing_param, replace_data from common.sendApirequest import SendApirequests from common.sendEmail import SendMail from common.sendMsg import SendMsg class CommKeyword(object): def __init__(self): self.operatordb = OpeartorDB() self.getCase = Getcase() self.sendApi = SendApirequests() self.sendMail = SendMail() self.sedMsg = SendMsg() def get_exceut_case(self, **kwargs): """ 获取当前执行用例 :return: bl, cases 一参数返回成功与否,二参数用例或失败原因 """ try: cases = self.getCase.read_all_excels() except Exception as e: return False, '获取用例失败,原因:' + str(e) return True, cases def get_current_casefile_name(self, **kwargs): """ 获取执行用例文件名称 :return: 返回用例文件名称 """ try: fileName = myCof.getValue('case', 'testcase') except Exception as e: return False, '参数中未设置用例文件名称,请检查配置文件' return True, fileName def send_api(self, **kwargs): """ 发送用例请求 post, get :param kwargs: 请求的参数 ,有url,headers,data等 :return: bl, cases 一参数返回成功与否,二参数请求结果或失败原因 """ try: url = replace_data(kwargs['url']) method = kwargs['method'] if kwargs['headers'] is None: headers = None else: _isOk, result = self.format_headers(replace_data(kwargs['headers'])) if _isOk: headers = result else: return _isOk, result if kwargs['data'] is not None: try: jsondata = json.loads(replace_data(kwargs['data'])) data = None except ValueError: data = replace_data(kwargs['data']) jsondata = None else: data = None jsondata = None response = self.sendApi.request_Obj(method=method, url=url, json=jsondata, data=data, headers=headers) except Exception as e: return False, '发送请求失败' + str(e) return True, response def set_sheet_dict(self): """ :return: excl文件里面的sheet页信息 """ xlsx = Getcase(myCof.get('excel', 'casename')) sh_dict = xlsx.sheet_count() setattr(Paramete, 'sheetdict', sh_dict) sheetdict = getattr(Paramete, 'sheetdict') return sheetdict def set_common_param(self, key, value): """ :param key: 公共变量名 :param value: 参数 :return: """ setattr(Paramete, key, value) def get_commom_param(self, key): """ :param key: 公共变量名 :return: 取变量值 """ return getattr(Paramete, key) def get_current_sheet_name(self): """ :return: 返回当前执行用例的sheet页名称 """ sh_index = self.get_commom_param('sheetindex') sh_dict = self.get_commom_param('sheetdict') for sh in sh_dict: if sh.title().find(str(sh_index)) != -1: sheet_name = sh_dict[sh.title().lower()] return sheet_name def get_json_value_as_key(self, *args, **kwargs): """ 得到json中key对应的value,存变量param 默认传的参数为: result:用来接收结果的变量 method:调用的方法 ,带不带${ } 都行 param_x:参数,数量不限。格式可为${ }会替换为已存在的数据 """ try: param = kwargs['result'] jsonstr = kwargs['param_1'] key = kwargs['param_2'] except KeyError: return False, '方法缺少参数,执行失败' param = analyzing_param(param) jsonstr = replace_data(jsonstr) key = replace_data(key) if param is None or jsonstr is None or key is None: return False, '传入的参数为空,执行失败' try: result = json.loads(jsonstr) except Exception: return False, '传入字典参数格式错误,执行失败' key = '$..' + key try: value = str(jsonpath.jsonpath(result, key)[0]) except Exception: return False, '字典中[' + jsonstr + ']没有键[' + key + '], 执行失败' setattr(Paramete, param, value) return True, ' 已经取得[' + value + ']==>[${' + param + '}]' def format_headers(self, param): """ 格式化请求头 :param param:excel里读出出来的header,是从浏览器f12里直接copy的 :return: """ if param is None: return False, 'Headers为空' list_header = param.split('\n') headers = {} for li in list_header: buff = li.split(':') try: headers[buff[0]] = buff[1] except IndexError: return False, 'Headers格式不对' return True, headers def set_variable(self, **kwargs): """ 设置变量 :param kwargs: :return: """ try: var = kwargs['result'] param = kwargs['param_1'] except KeyError: return False, '方法缺少参数,执行失败' if var is None or param is None: return False, '传入的参数为空,执行失败' setattr(Paramete, var, param) return True, ' 已经设置变量[' + param + ']==>[${' + var + '}]' def execut_sql(self, **kwargs): """ 执行SQL :param kwargs: :return: """ try: sql = kwargs['param_1'] except KeyError: return False, '方法缺少参数,执行失败' try: var = kwargs['result'] par = kwargs['param_2'] except Exception: var = None isOK, result = self.operatordb.excetSql(sql) if isOK and var is not None: data = result[par] setattr(Paramete, var, data) return True, '执行SQL:[' + sql + ']成功,取得' + par + '的数据[' + data + ']==>[${' + var + '}]' elif isOK and var is None: return True, '执行SQL:[' + sql + ']成功' elif isOK is False: return isOK, result def send_email(self): """ 发送邮件 :return: """ return self.sendMail.send_email() def send_msg(self, **kwargs): """ 发送消息 :param kwargs: :return: """ title = kwargs['title'] url = kwargs['url'] code = kwargs['code'] result = kwargs['result'].encode('utf-8').decode('unicode_escape') nowTime = datetime.datetime.now().strftime('%Y-%m-%d %H:%M:%S') # 现在 msg = nowTime + '\n用例名称:' + title + '\n请求:' + url + '\n响应码:' + code + '\n响应信息:' + result self.sedMsg.sendMsg(msg) # header = 'Access-Control-Allow-Credentials: true\nAccess-Control-Allow-Origin: http://test-hcz-static.pingan.com.cn\naccessToken: 8b1f056249134c4f9fb7b573b25ce08c' # _isOK, headers = format_headers(header) # print(headers, type(headers))十一、工厂封装(核心)-methodFactoy.py
1、工厂的逻辑
工厂是公共方法调用入口。
有人传入关键的文字,而工厂会找到关键文字对应的公共方法,执行方法得到结果,最后返回给调用工厂的人。
那我们如何通过文字找方法呢?
需要用到配置文件,我们在配置文件将前面小节封装的公共方法逐一配置好,
格式:文字=方法名称
如下图:

代码实现,先通过配置文件得到公共方法的名称 ,然后使用getattr方法在公共模块对象上找到公共方法,然后执行方法,可以得到想要的结果。
如下图

如果是在用例里执行,以这种格式写

打印结果与报告展示


这个需要将后面的封闭与用例解析写完才能看到的效果,加油
2、封装
methodFactory.py的代码段
from common.getConfig import myCof from kemel.commKeyword import CommKeyword # #初始化公共方法模块 # comKey = CommKeyword() # #获取所有公共方法配置参数 # comKW = dict(myCof.items('commkey')) # #获取 取用例方法名称 # method_Name = comKW['获取当前执行用例'] # #通过getattr 获取公共方法模块的对应的模块 # func = getattr(comKey, method_Name, None) # #执行前面获取的公共方法得到用例 # cases = func(aa=None) # #打印用例 # print(cases) class MethodFactory(object): def __init__(self): self.comKey = CommKeyword() self.comKW = dict(myCof.items('commkey')) def method_factory(self, **kwargs): """ 用例公共方法工厂 默认传的参数为: result:用来接收结果的变量,格式可为${abc} method:调用的方法,这里设计方法都使用中文 param_x:参数,数量不限。格式可为${abc}会替换为已存在的数据 """ if kwargs.__len__() > 0: try: kwargs['method'] except KeyError: return False, 'keyword:用例[method]字段方法没参数为空.' try: method = self.comKW[str(kwargs['method']).lower()] except KeyError: return False, 'keyword:方法[' + kwargs['method'] + '] 不存在,或未配置.' else: return False, '没有传参' try: func = getattr(self.comKey, method, None) _isOk, reselt = func(**kwargs) return _isOk, reselt except Exception as e: return False, 'keyword:执行失败,估计不存在,异常:' + str(e) # fac = MethodFactory() # print(fac.method_factory(method='获取当前用例文件名称'))十二、解析用例(核心)-testCase.py
1、详情讲解
python 自动了一个单元测试框架unittest,用来做自动化测试是绝好的。
先引用一段理论:
--------------------------------------------
做过自动化测试的同学应该都知道python中的unittest框架,它是python自带的一套测试框架,学习起来也相对较容易,unittest框架最核心的四个概念:
test case:就是我们的测试用例,unittest中提供了一个基本类TestCase,可以用来创建新的测试用例,一个TestCase的实例就是一个测试用例;unittest中测试用例方法都是以test开头的,且执行顺序会按照方法名的ASCII值排序。
test fixure:测试夹具,用于测试用例环境的搭建和销毁。即用例测试前准备环境的搭建(SetUp前置条件),测试后环境的还原(TearDown后置条件),比如测试前需要登录获取token等就是测试用例需要的环境,运行完后执行下一个用例前需要还原环境,以免影响下一条用例的测试结果。
test suite:测试套件,用来把需要一起执行的测试用例集中放到一块执行,相当于一个篮子。我们可以使用TestLoader来加载测试用例到测试套件中。
test runner:用来执行测试用例的,并返回测试用例的执行结果。它还可以用图形或者文本接口,把返回的测试结果更形象的展现出来,如:HTMLTestRunner。
--------------------------------------------
自动化测试流程:是基于unittest中TestCase + ddt data 模式成自动化用例集(俗称数据驱动)。而后被unittest中的test suite套件将用例集中管理起来,最后使用unittest中的test runner将集中起来的用例执行,生成测试报告
解析用例。就是数据驱动这一段。已经封装好在testCase.py中了,可以自行看代码与注释学习
2、封装
testCase.py代码段
import unittest import json from library.ddt import ddt, data from common.log import mylog from kemel.methodFactory import MethodFactory isOK = True e = Exception() @ddt #引用数据驱动装饰器 class TestCase(unittest.TestCase): metFac = MethodFactory() #初始化工厂类 isOK, cases = metFac.method_factory(method='获取当前执行用例') isOK, fileName = metFac.method_factory(method='获取当前用例文件名称') if isOK is False: mylog.error('获取用例失败') quit() #调用工厂公共方法入口 def _opear_keyword(self, **kwargs): return self.metFac.method_factory(**kwargs) #断言方法 def _assert_res_expr(self, rules, reponse, expr): """ 断言方法 :param rules:结果包含、结果等于、结果状态 :param res: :param expr: :return: """ try: res = reponse.json() except Exception: res = reponse.text headers = reponse.headers code = str(reponse.status_code) _reason = 'success' if rules == '结果包含': if type(expr) is str: res = json.dumps(res, ensure_ascii=False) print_result = json.dumps(json.loads(res), sort_keys=True, indent=2, ensure_ascii=False) else: print_result = res try: self.assertIn(expr, res) except AssertionError as e: _isOk = False _reason = '结果:\n【' + print_result + '】\n 不包含校验值:\n 【' + expr + '】' else: _isOk = True _reason = '结果:\n【' + print_result + '】\n 包含有校验值:\n 【' + expr + '】' elif rules == '结果等于': if type(expr) is str: res = json.dumps(res, ensure_ascii=False) print_result = json.dumps(json.loads(res), sort_keys=True, indent=2, ensure_ascii=False) else: print_result = res try: self.assertEqual(expr, res) except AssertionError as e: _isOk = False _reason = '结果:\n【' + res + '】\n 不等于校验值:\n 【' + expr + '】' else: _isOk = True _reason = '结果:\n【' + res + '】\n 等于校验值:\n 【' + expr + '】' elif rules == '结果状态': try: self.assertEqual(expr, code) except AssertionError as e: _isOk = False _reason = '结果:\n【' + code + '】\n 不等于校验值:\n 【' + expr + '】' else: _isOk = True _reason = '结果:\n【' + code + '】\n 等于校验值:\n 【' + expr + '】' elif rules == '头部包含': if type(expr) is str: headers = json.dumps(headers, ensure_ascii=False) print_header = json.dumps(json.loads(headers), sort_keys=True, indent=2, ensure_ascii=False) else: print_header = headers try: self.assertIn(expr, headers) except AssertionError as e: _isOk = False _reason = '结果头:\n【' + print_header + '】\n 不包含校验值:\n 【' + expr + '】' else: _isOk = True _reason = '结果头:\n【' + print_header + '】\n 包含有校验值:\n 【' + expr + '】' elif rules == '头部等于': if type(expr) is str: headers = json.dumps(headers, ensure_ascii=False) print_header = json.dumps(json.loads(headers), sort_keys=True, indent=2, ensure_ascii=False) else: print_header = headers try: self.assertEqual(expr, headers) except AssertionError as e: _isOk = False _reason = '结果头:\n【' + print_header + '】\n 不等于校验值:\n 【' + expr + '】' else: _isOk = True _reason = '结果头:\n【' + print_header + '】\n 等于校验值:\n 【' + expr + '】' return _isOk, _reason #打印用例信息与执行结果,因为是TestCase,最终它们将展示到测试报告中,所以设计输出格式,让报告美美达 def postPinrt(self, **case): if case['interface'] is not None: print('\n------------------------------------------------------------------\n') print('接口:【' + case['interface'] + '】') if case['method'] is not None: print('类型:【' + case['method'] + '】') if case['data'] is not None: print('参数:【' + case['data'] + '】') if 'get' == str.lower(case['method']): if '?' in str(case['url']): url = str(case['url']) a, param = url.split('?') if param is not None: print('参数:【') datalist = str(param).split('&') for data in datalist: print(data) print('】') else: print('【没带参数】') print('\n------------------------------------------------------------------\n') @data(*cases) #,数据驱动装饰器,将用例list中的元素出来,将元素传递给test_audit的case中 def test_audit(self, case): _isOk = True #如果interface为commfun,将调用对应的公共方法 if case['interface'] == 'commfun': """ 如果接口是公共方法,那么字段如下 method:公共方法名 title: 返回接果 url:参数 data:参数 ...暂时四个参数 """ _isOk, _strLog = self._opear_keyword(method=case['method'], result=case['title'], param_1=case['url'], param_2=case['headers'], param_3=case['data'], param_4=case['validaterules']) else: rows = case['case_id'] + 1 title = case['title'] expect = str(case['expected']) #发送请求,用例文件里interface不等于commfun,method为post或get的将被执行 _isOK, result = self.metFac.method_factory(**case) if _isOk: response = result code = str(response.status_code) try: res = json.dumps(response.json()) self.metFac.method_factory(method='设置变量', result='response', param_1=response) #返回json存 except ValueError: res = response.text self.metFac.method_factory(method='设置变量', result='response', param_1=res) #返回html 或xml、 txt存 if case['validaterules'] is None: _isOk = True _strLog = '用例[' + str(case['case_id']) + ']:[' + title + ']执行完成.' else: rules = case['validaterules'] _isOk, _reason = self._assert_res_expr(rules, response, expect) if _isOk: _strLog = '用例[' + str(case['case_id']) + ']:[' + title + ']执行通过. \n 校验结果:\n' + _reason else: _strLog = "用例[" + str(case['case_id']) + ']:[' + title + ']执行不通过.\n 原因:\n' + _reason #报错的接口,给企业微信发送信息 self.metFac.method_factory(title=title, method='发送消息', api=case['interface'], url=case['url'], code=code, result=res) else: _strLog = "用例[" + str(case['case_id']) + ']:[' + title + ']执行不通过. \n 原因:\ n' + result if _isOk: mylog.info(_strLog) print(_strLog) self.postPinrt(**case) else: mylog.error(_strLog) print(_strLog) self.postPinrt(**case) raise十三、最后的运行文件-testRun.py
1、代码封装
testRun.py代码段
写完这个文件的代码,再然后按照第三小节的 ’读取用例模块-getCase.py‘ 里面的规则设计测试用例,然后放支data文件目录里,将配置文件里的用例文件名称配置好,然后执行自动化测试了
import unittest import os from common.initPath import CASEDIR, REPORTDIR from kemel.methodFactory import MethodFactory from library.HTMLTestRunnerNew import HTMLTestRunner class TestRun(object): metFac = MethodFactory() def __init__(self): self.suit = unittest.TestSuite() load = unittest.TestLoader() self.suit.addTest(load.discover(CASEDIR)) self.runner = HTMLTestRunner( stream=open(os.path.join(REPORTDIR, 'report.html'), 'wb'), title='接口自动化测试报告', description='代替手动冒烟、手动回归,做更精准的测试', tester='HunWei' ) def excute(self): self.runner.run(self.suit) self.metFac.method_factory(method='发送邮件') if __name__=='__main__': run = TestRun() run.excute() # from kemel.methodFactory import MethodFactory # abc = MethodFactory() # isOK, cases = abc.method_factory(method='获取当前执行用例') # print(cases)执行后的测试报告如下:




【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· 阿里巴巴 QwQ-32B真的超越了 DeepSeek R-1吗?
· 【译】Visual Studio 中新的强大生产力特性
· 10年+ .NET Coder 心语 ── 封装的思维:从隐藏、稳定开始理解其本质意义
· 【设计模式】告别冗长if-else语句:使用策略模式优化代码结构