大数据架构:全网最全大数据架构生态
1、数据采集框架
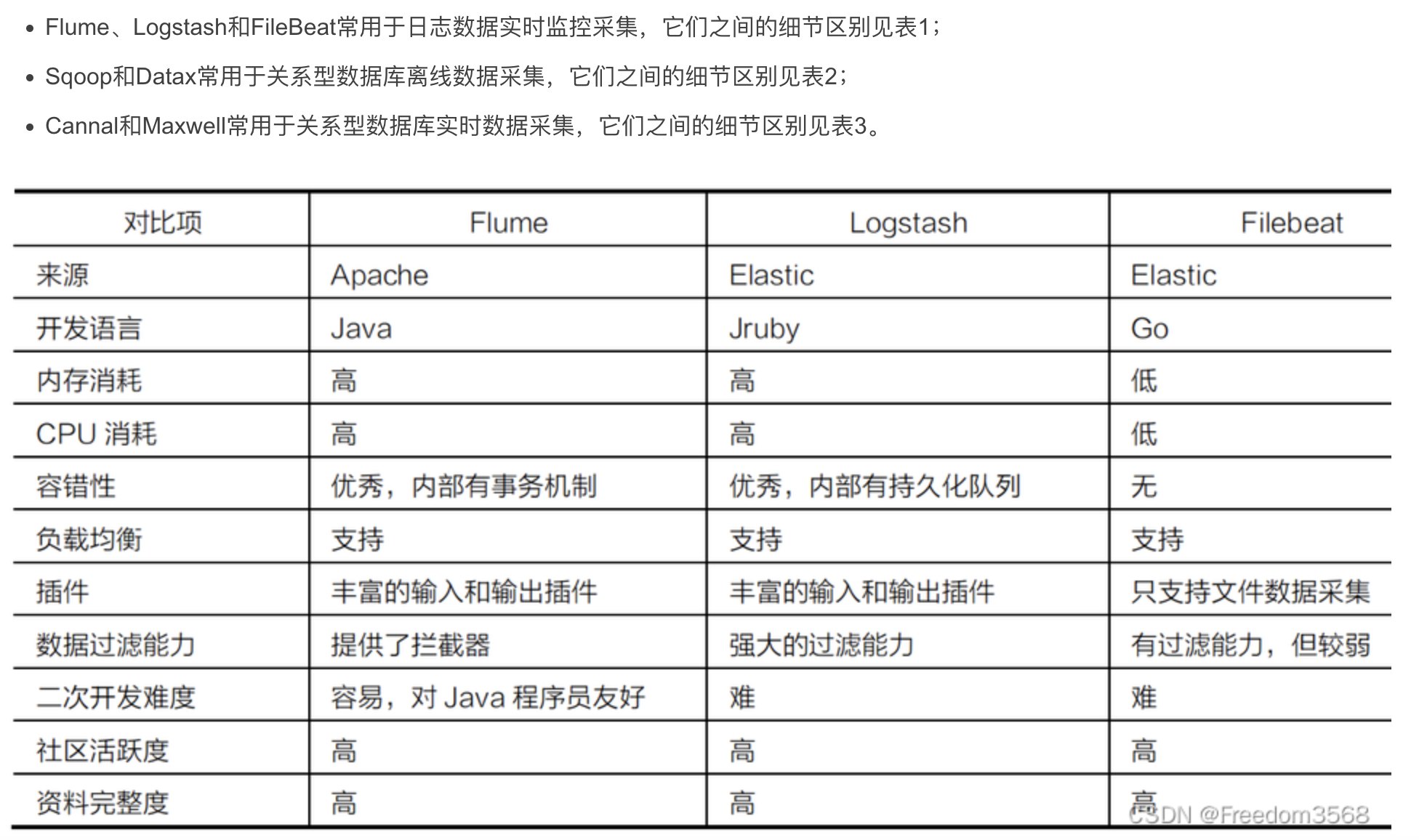
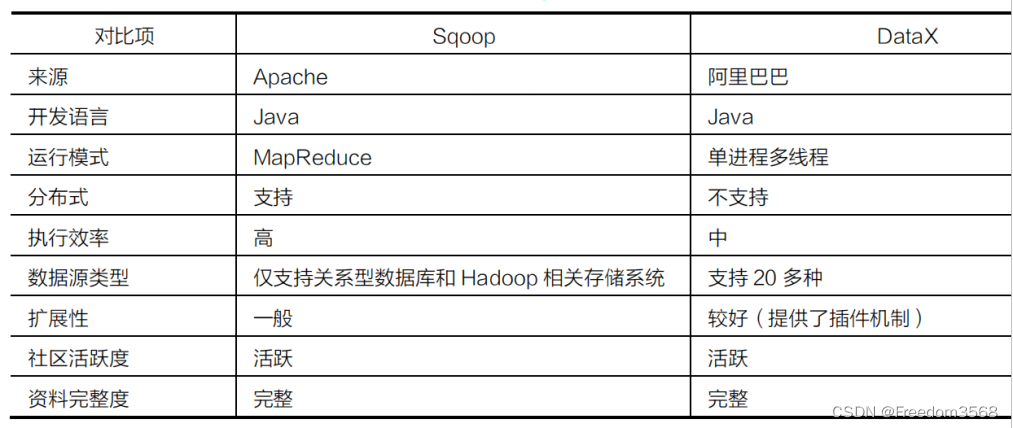
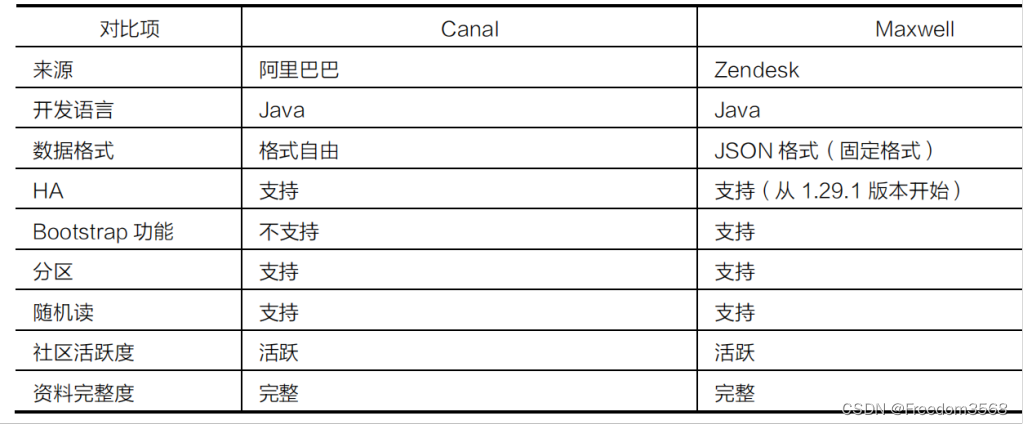
----------------------------------------------------------------------
2、数据存储框架

----------------------------------------------------------------------
3、分布式资源管理调度框架

----------------------------------------------------------------------
4、数据计算框架


----------------------------------------------------------------------
5、数据分析技术框架

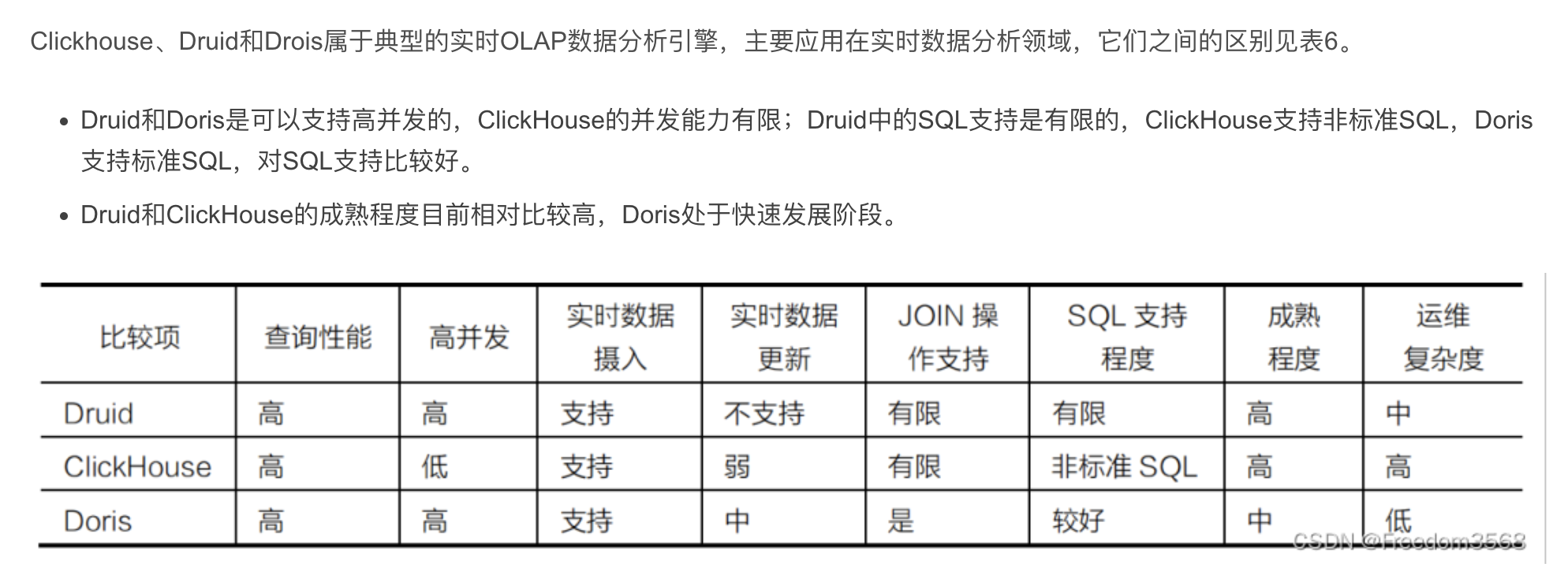
----------------------------------------------------------------------
6、任务调度框架
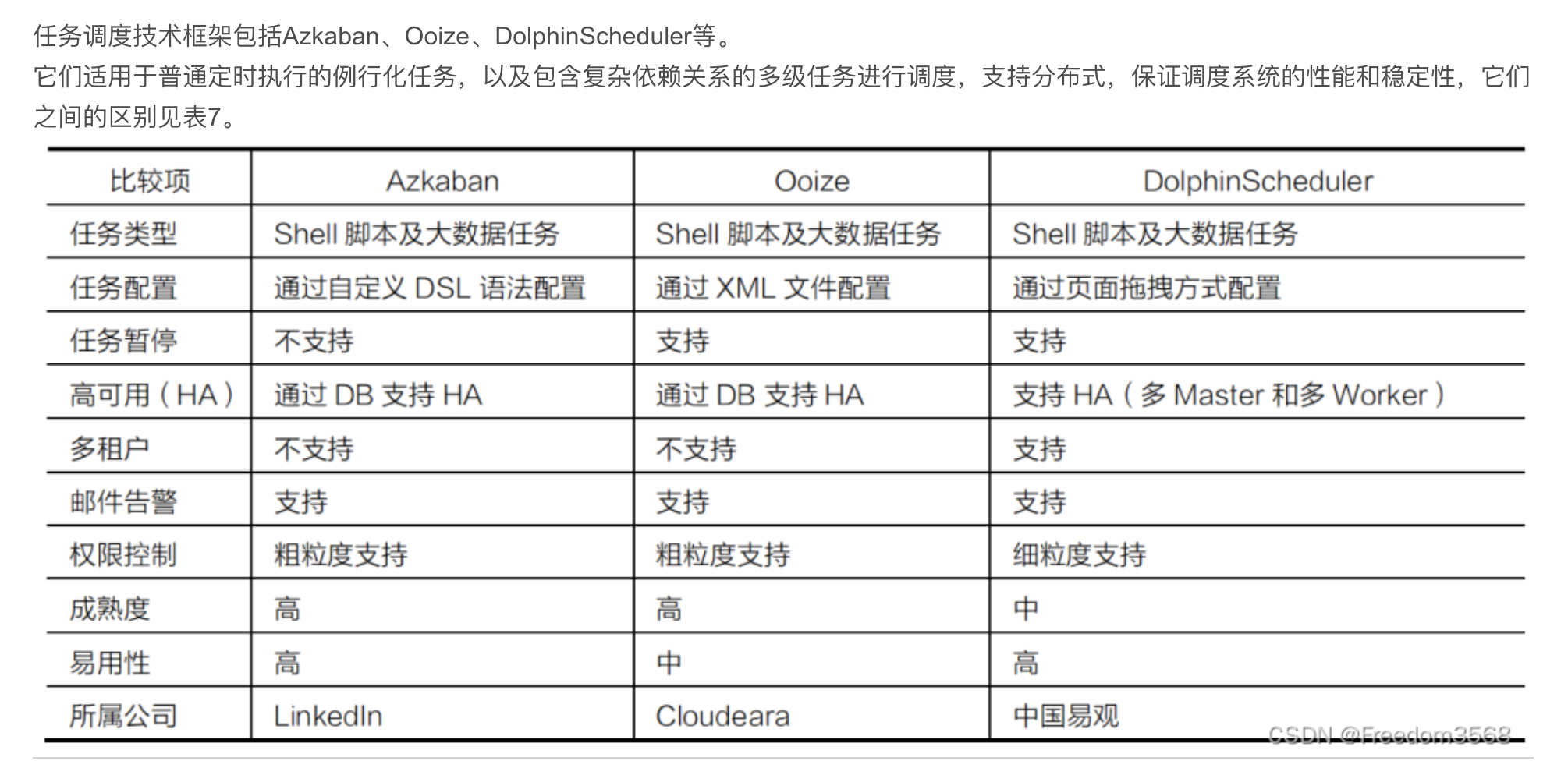
----------------------------------------------------------------------
7、基础框架

----------------------------------------------------------------------
8、数据检索框架
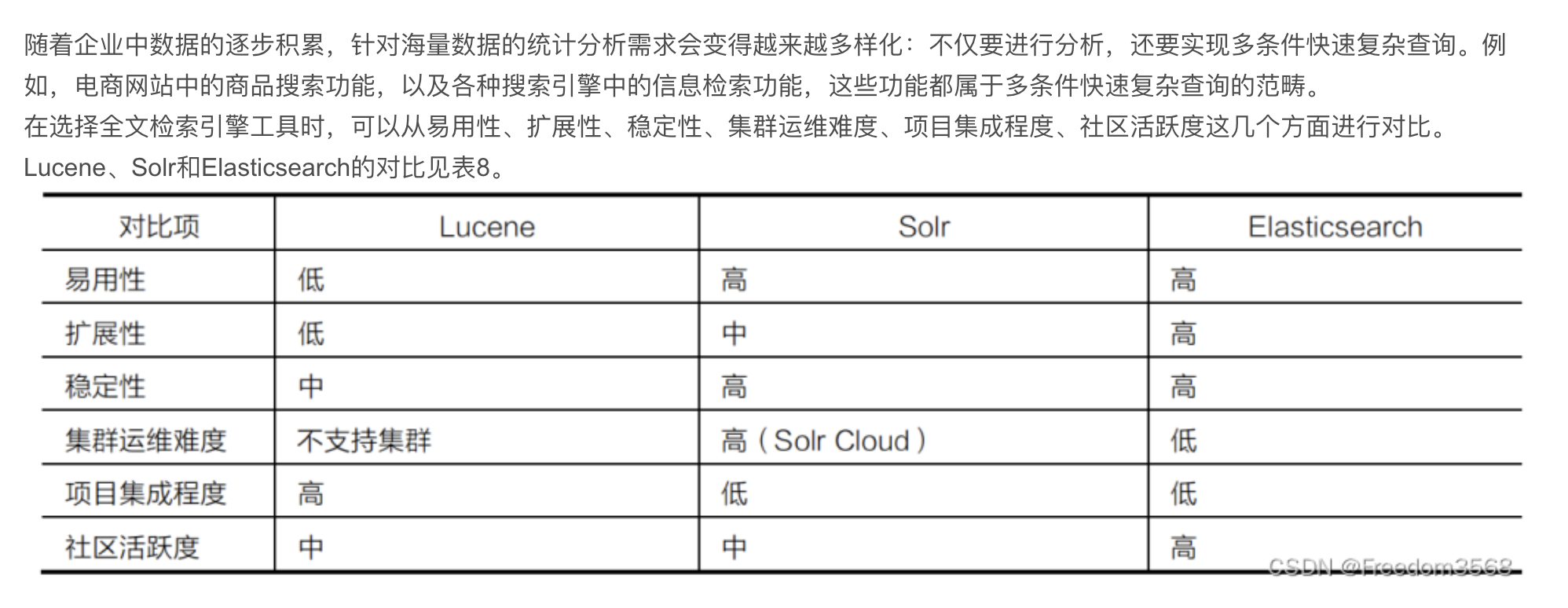
----------------------------------------------------------------------
9、集群安装管理框架

----------------------------------------------------------------------
总结
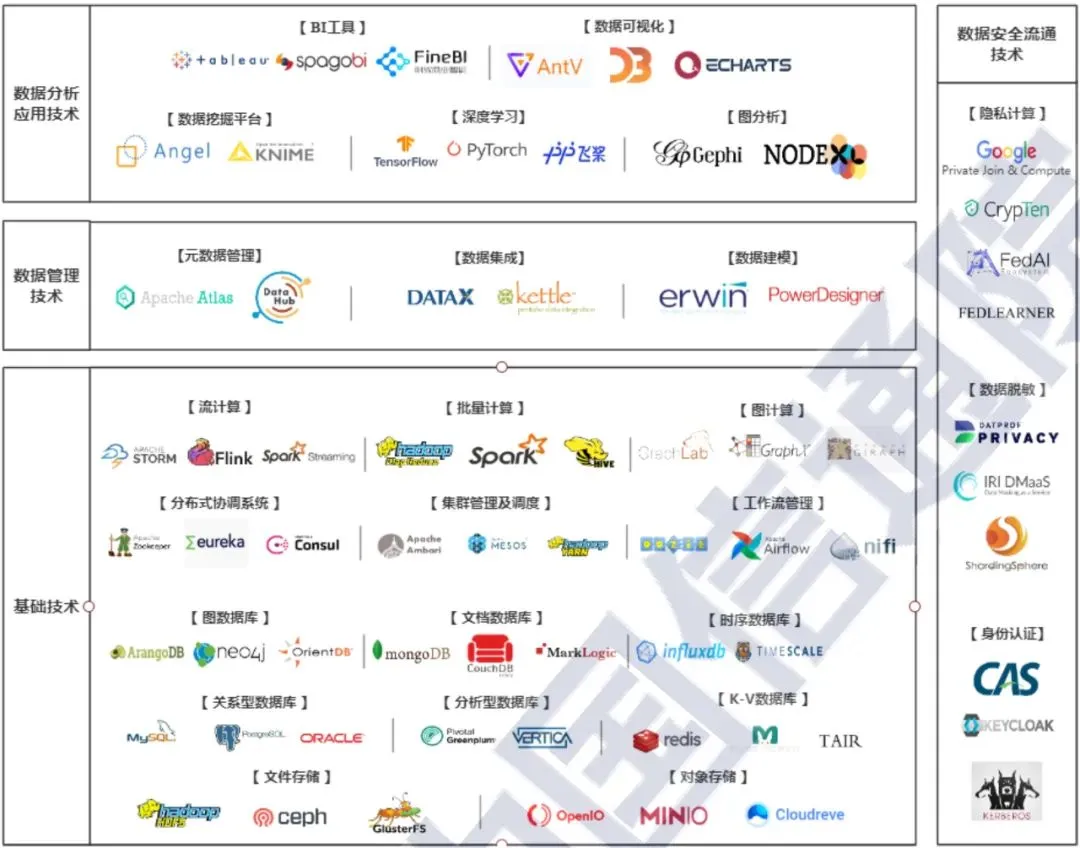
-------------------------------------------------
从这张图谱可以看到,大数据技术体系可以归纳总结为数据分析应用技术、数据管理技术、基础技术、数据安全流通技术四大方向,每个方向大数据技术的产生都有其独特的背景。
1、基础技术:主要为应对大数据时代的多种数据特征而产生
大数据时代数据量大,数据源异构、数据时效性高等特征催生了高效完成海量异构数据存储与计算的技术需求。面对迅速而庞大的数据量,传统集中式计算架构出现难以逾越的瓶颈,传统关系型数据库单机的存储及计算性能有限,出现了规模并行化处理(MPP)的分布式计算架构,如分析型数据库GreenGreenplum。
面对分布式架构带来的海量分布式系统间信息协同的问题,出现了以Zoomkeeper为代表的分布式协调系统;为了将分布式集群中的硬件资源以一定的策略分配给不同的计算引擎和计算任务,出现了Yarn等集群管理及调度引擎;面对海量计算任务带来的管理复杂度大幅提升问题,出现了面向数据任务的灵活调度工作流平台。
面向海量网页内容及日志等非结构化数据,出现了基于Apache Hadoop和Spark生态体系的分布式批处理计算框架;面向对于时效性数据进行实时计算反馈的需求,出现了Apache Storm、Flink等分布式流处理计算框架。
面对大型社交网络、知识图谱的应用要求出现了以对象+关系存储和处理为核心的分布式图计算引擎和图数据库,如GraphX、neo4j等;面对海量网页、视频等非结构化的文件存储需求,出现了mongoDB等分布式文档数据库;面向海量设备、系统和数据运行产生的海量日志进行高效分析的需求,出现了influxdb等时序数据库;面对海量的大数据高效开放查询的要求,出现了以Redis为代表的K-V数据库。
面向大规模数据集的高效、可靠及低成本的存取问题,出现了HDFS、OpenIO等分布式文件存储和对象存储解决方案。
2、数据管理类技术:助力提升数据质量与可用性
技术总是随着需求的变化而不断发展提升,在较为基本和急迫的数据存储、计算需求已经在一定程度满足后,如何将数据转化为价值成为了下一个主要需求。
最初,企业与组织内部的大量数据因缺乏有效的管理,普遍存在着数据质量低、获取难、整合不易、标准混乱等问题,使得数据后续的使用存在众多障碍,在此情况下,用于数据整合的数据集成技术,如DataX、用于数据架构管理的数据建模技术,如ERWIN,用于数据资产管理的元数据技术,如Apache atlas,纷纷出现。
3、数据分析应用技术:发掘数据资源的内蕴价值
在拥有充足的产出计算能力以及高质量可用数据的情况下,如何将数据中蕴涵的价值充分挖掘并同相关的具体业务结合以实现数据的增值成为了关键。
各种用以发掘数据价值的数据分析技术纷纷出现,包括ECHARTS、BI工具为代表的简单统计分析与可视化展现技术,以传统机器学习、基于深度神经网络的深度学习、图分析引擎为基础的挖掘分析建模技术等等。
4、数据安全流通技术:助力安全合规的数据使用及共享
在数据价值释放初现曙光的同时,数据安全问题也愈加凸显,数据泄露、数据丢失、数据滥用等安全事件层出不穷,对国家、企业和个人用户造成了恶劣影响,如何应对大数据时代下严峻的数据安全威胁,在安全合规的前提下共享及使用数据成为了备受瞩目的问题、访问控制、身份识别、数据加密、数据脱敏等传统数据保护手段正积极向更加适应大数据场景的方向不断发展,同时,侧重于实现安全数据流通的隐私计算技术也成为了热点发展方向。
下面笔者将针对这些技术的基本概念和相关产品做个概述,方便你建立起较为完整的大数据全景技术框架。
一、基础技术
1、流计算
流计算秉承一个基本理念,即数据的价值随着时间的流逝而降低,如用户点击流。因此,当事件出现时就应该立即进行处理,而不是缓存起来进行批量处理。为了及时处理流数据,就需要一个低延迟、可扩展、高可靠的处理引擎,实时获取来自不同数据源的海量数据,经过实时分析处理,获得有价值的信息,主要的产品为STORM、Spark Streaming及Flink等等。
产品举例:
STORM:一个开源的分布式实时计算框架,可以以简单、可靠的方式进行大数据流的处理
Spark Streaming:接收实时输入的数据流,并将数据拆分为一系列批次,然后进行微批处理,Spark Streaming 能够将数据流进行极小粒度的拆分,使得其能够得到接近于流处理的效果,但其本质上还是批处理
Flink:一种针对流数据+批数据的计算框架,其把批数据看作流数据的一种特例,延迟性较低(毫秒级),且能够保证消息传输不丢失不重复
2、批量计算
批量计算是指对静态数据的批量处理,即当开始计算之前数据已经准备到位,主要用于数据挖掘和验证业务模型,包括MapReduce、spark、hive等等。
产品举例:
Hadoop MapReduce:一种编程模型,用于大规模数据集(大于1TB)的并行运算,概念"Map(映射)"和"Reduce(归约)"是它们的主要思想,极大地方便了编程人员在不会分布式并行编程的情况下,将自己的程序运行在分布式系统上
spark:拥有Hadoop MapReduce所具有的优点,但不同于MapReduce的是Job中间输出结果可以保存在内存中,从而不再需要读写HDFS,因此Spark能更好地适用于数据挖掘与机器学习等需要迭代的场景
hive:基于Hadoop的一个数据仓库工具,用来进行数据提取、转化、加载,这是一种可以存储、查询和分析存储在Hadoop中的大规模数据的机制
3、图计算
以图作为数据模型来表达问题并予以解决的过程,包括GraphLab、GraphX、Giraph及Gelly等等。
产品举例:
GraphLab:由CMU(卡内基梅隆大学)的Select 实验室在2010 年提出的一个基于图像处理模型的开源图计算框架,框架使用C++语言开发实现。该框架是面向机器学习(ML)的流处理并行计算框架,可以运行在多处理机的单机系统、集群或是亚马逊的EC2 等多种环境下。框架的设计目标是像MapReduce一样高度抽象,可以高效执行与机器学习相关的、具有稀疏的计算依赖特性的迭代性算法,并且保证计算过程中数据的高度一致性和高效的并行计算性能
GraphX:一个分布式图处理框架,它是基于Spark平台提供对图计算和图挖掘简洁易用的而丰富的接口,极大的方便了对分布式图处理的需求
Giraph:Facebook搞的图计算引擎,基于hadoop,编程模型接近于Pregel,主要卖点是支持大图
4、分布式协调系统
分布式协调技术主要用来解决分布式环境当中多个进程之间的同步控制,让他们有序的去访问某种临界资源,防止造成"脏数据"的后果,主要包括Zoomkeeper、eureka、consul等等。
产品举例:
Zoomkeeper:一个分布式的,开放源码的分布式应用程序协调服务,是Google的Chubby一个开源的实现,是Hadoop和Hbase的重要组件。它是一个为分布式应用提供一致性服务的软件,提供的功能包括:配置维护、域名服务、分布式同步、组服务等
eureka:Eureka是Netflix开发的服务发现框架,本身是一个基于REST的服务,主要用于定位运行在AWS域中的中间层服务,以达到负载均衡和中间层服务故障转移的目的
consul:google开源的一个使用go语言开发的服务发现、配置管理中心服务。内置了服务注册与发现框架、分布一致性协议实现、健康检查、Key/Value存储、多数据中心方案,不再需要依赖其他工具
5、集群管理及调度
主要负责将集群中的硬件资源以一定的策略分配给不同的计算任务,主要包括Ambori、MESOS、YARN等等。
产品举例:
Ambori:一种基于Web的工具,支持Apache Hadoop集群的供应、管理和监控。Ambari已支持大多数Hadoop组件,包括HDFS、MapReduce、Hive、Pig、 Hbase、Zookeeper、Sqoop和Hcatalog等等
MESOS:可以将整个数据中心的资源(包括CPU、内存、存储、网络等)进行抽象和调度,让应用共享集群资源,并无需关心资源的分布情况
YARN:一种新的 Hadoop 资源管理器,它是一个通用资源管理系统,可为上层应用提供统一的资源管理和调度,它的引入为集群在利用率、资源统一管理和数据共享等方面带来了巨大好处
6、工作流管理
工作流含义很广,这里指能对各种数据任务进行灵活编排和调度的工具,包括Airflow、nifi、Oozie等等,很多企业大数据工作流管理都跟自身的数据开发管理平台紧耦合。
产品举例:
Airflow:Airbnb 开源的一个用 Python 编写的工作流管理平台,用于编排复杂计算工作流和数据处理流水线。如果您发现自己运行的是执行时间超长的 cron 脚本任务,或者是大数据的批处理任务,Airflow 可能是能帮助您解决目前困境的神器
nifi:Apache支持下基于可视化流程设计的数据分发平台,是大数据的搬运、提取、推送、转换、聚合、分发的开源软件工具,能够与Hadoop生态系统的大数据存储和各种文件、REST服务、SOAP服务、消息服务等联合使用,构成一体化的数据流服务
Oozie:起源于雅虎,主要用于管理与组织Hadoop工作流。Oozie的工作流必须是一个有向无环图,实际上Oozie就相当于Hadoop的一个客户端,当用户需要执行多个关联的MR任务时,只需要将MR执行顺序写入workflow.xml,然后使用Oozie提交本次任务,Oozie会托管此任务流
7、图数据库
NoSQL数据库的一种类型,它应用图形理论存储实体之间的关系信息。最常见例子就是社会网络中人与人之间的关系。关系型数据库用于存储“关系型”数据的效果并不好,其查询复杂、缓慢、超出预期,而图形数据库的独特设计恰恰弥补了这个缺陷,主要包括ArangoDB、neo4j、OrientDB等等。
产品举例:
ArangoDB:一个原生多模型数据库,兼有key/value键/值对、graph图和document文档数据模型,提供了涵盖三种数据模型的统一的数据库查询语言,并允许在单个查询中混合使用三种模型
neo4j:一个高性能的NOSQL图形数据库,它将结构化数据存储在网络上而不是表中。它是一个嵌入式的、基于磁盘的、具备完全的事务特性的Java持久化引擎,但是它将结构化数据存储在网络(从数学角度叫做图)上而不是表中,Neo4j也可以被看作是一个高性能的图引擎,该引擎具有成熟数据库的所有特性
OrientDB:一个开源的多模型 NoSQL 数据库,支持原生图形、文档全文、响应性、地理空间和面向对象等概念。它使用 Java 编写,速度非常快:在普通硬件上,每秒可存储 220,000 条记录。对于文档数据库,它还支持 ACID 事务处理
8、文档数据库
文档数据库被用来管理文档,在传统的数据库中,信息被分割成离散的数据段,而在文档数据库中,文档是处理信息的基本单位,包括mongoDB、CouchDB、MarkLogic等等。
产品举例:
mongoDB:一个基于分布式文件存储的数据库。由 C++ 语言编写。旨在为 WEB 应用提供可扩展的高性能数据存储解决方案,它支持的数据结构非常松散,是类似json的bson格式,因此可以存储比较复杂的数据类型。Mongo最大的特点是它支持的查询语言非常强大
CouchDB:一个开源的面向文档的数据库管理系统,可以通过 RESTful JavaScript Object Notation (JSON) API 访问。术语 “Couch” 是 “Cluster Of Unreliable Commodity Hardware” 的首字母缩写,它反映了 CouchDB 的目标具有高度可伸缩性,提供了高可用性和高可靠性,即使运行在容易出现故障的硬件上也是如此
MarkLogic:一种NoSQL数据库,能同时储存结构化和非结构化数据解决方案,包括JSON、XML、RDF、坐标、二进制数据(PDF、图片、视频)等等,而不仅仅是结构化的数据存储
9、时序数据库
主要用于指处理带时间标签(按照时间的顺序变化,即时间序列化)的数据,带时间标签的数据也称为时间序列数据,主要包括influxdb、TIMESCALE等等。
产品举例:
influxdb:一个由InfluxData开发的开源时序型数据库。它由Go写成,着力于高性能地查询与存储时序型数据
TIMESCALE:唯一支持完整SQL的开放源代码时间序列数据库。为快速摄取和复杂查询优化,TimescaleDB易于使用,如传统的关系数据库,但按以前为NoSQL数据库保留的方式进行缩放
10、分析型数据库
面向分析应用的数据库,与传统的数据库不同,它可以对数据进行在线统计、数据在线分析、随即查询等操作,是数据库产品一个重要的分支,主要包括Greenplum、VERTICA、GBASE等等。
产品举例:
Greenplum:Greenplum DW/BI软件可以在虚拟化x86服务器上运行无分享(shared-nothing)的大规模并行处理MPP架构
VERTICA:一款基于列存储的MPP (massively parallel processing)架构的数据库
Clickhouse:一款MPP架构的列式存储数据库,其从OLAP场景需求出发,定制开发了一套全新的高效列式存储引擎,并且实现了数据有序存储、主键索引、稀疏索引、数据Sharding、数据Partitioning、TTL、主备复制等丰富功能。以上功能共同为ClickHouse极速的分析性能奠定了基础
11、KV数据库
是一种以键值对存储数据的一种数据库,类似java中的map。可以将整个数据库理解为一个大的map,每个键都会对应一个唯一的值。key-value分布式存储系统查询速度快、存放数据量大、支持高并发,非常适合通过主键进行查询,但不能进行复杂的条件查询,主要包括redis、TAIR及memcached等等。
产品举例:
redis:一个开源的使用 ANSI C 语言编写、遵守 BSD 协议、支持网络、可基于内存、分布式、可选持久性的键值对(Key-Value)存储数据库,并提供多种语言的 API
TAIR:是阿里云数据库Redis企业版,是基于阿里集团内部使用的Tair产品研发的云上托管键值对缓存服务。Tair作为一个高可用、高性能的分布式NoSQL数据库,专注于多数据结构的缓存与高速存储场景,完全兼容Redis协议
memcached:是一个自由开源的、高性能、分布式内存对象缓存系统。
12、文件存储
文件存储的数据是以一个个文件的形式来管理,操作对象是文件和文件夹,存储协议是NFS、SAMBA(SMB)、POSIX等,它跟传统的文件系统如Ext4是一个类型的,但区别在于分布式文件存储提供了并行化的能力,主要包括HDFS、ceph、GlusterFS等等。
产品举例:
HDFS:指被设计成适合运行在通用硬件(commodity hardware)上的分布式文件系统(Distributed File System),是一个高度容错性的系统,适合部署在廉价的机器上,能提供高吞吐量的数据访问,非常适合大规模数据集上的应用
ceph:是一个统一的分布式存储系统,设计初衷是提供较好的性能、可靠性和可扩展性
GlusterFS:一个可扩展的网络文件系统,相比其他分布式文件系统,GlusterFS具有高扩展性、高可用性、高性能、可横向扩展等特点,并且其没有元数据服务器的设计,让整个服务没有单点故障的隐患
13、对象存储
也称为基于对象的存储,是一种数据存储,其中每个数据单元存储为称为对象的离散单元。对象可以是离散单元,类似于pdf,音频,图像或视频文件。这些对象实际上可以是任何类型的数据和任何大小的数据。对象存储中的所有对象都存储在单个平面地址空间中,而没有文件夹层次结构。一个对象通常包含三个部分:对象的数据、对象的元数据以及一个全局唯一的标识符(即对象的ID),采用分布式架构,容量和处理能力弹性扩展,存储协议是S3、Swift等,主要包括OpenIO、MINIO及Cloudreve等等。
产品举例:
OpenIO:一个开源的对象存储解决方案,用于大规模面向性能要求的低延迟的存储架构,特别为体积小量大的存储对象,发布容易,添加存储设备无需对数据进行重新分配
MINIO:GlusterFS创始人之一Anand Babu Periasamy发布新的开源项目。Minio兼容Amason的S3分布式对象存储项目,采用Golang实现,客户端支Java,Python,Javacript, Golang语言。Minio可以做为云存储的解决方案用来保存海量的图片,视频,文档。由于采用Golang实现,服务端可以工作在Windows,Linux, OS X和FreeBSD上
Cloudreve:一款国人开发的开源免费的网盘系统,借助Cloudreve你能够快速搭建起公私兼备的网盘。Cloudreve支持使用七牛云存储、阿里云OSS、又拍云、Amazon S3等对象存储作为存储后端,也支持本地服务器、远程服务器和OneDrive等作为存储后端,另外也支持aria2离线下载
二、数据管理技术
1、元数据管理
元数据管理统一管控业务元数据、技术元数据、管理元数据等等,并面向开发人员、最终用户提供元数据服务,对业务系统和数据分析平台的开发、维护过程提供支持,元数据管理软件包括Apache atlas等等,各个行业大多有自己独特的元数据管理软件。
产品举例:
Apache atlas:为组织提供开放式元数据管理和治理功能,用以构建其数据资产目录,对这些资产进行分类和管理,并为数据分析师和数据治理团队提供围绕这些数据资产的协作功能
MetaCube:普元发布的全面支撑自服务的大数据治理平台
2、数据集成
数据集成是把不同来源、格式、特点性质的数据在逻辑上或物理上有机地集中,从而为企业提供全面的数据共享。
产品举例:
DataX:DataX 是阿里开源的一个异构数据源离线同步工具,致力于实现包括关系型数据库(MySQL、Oracle等)、HDFS、Hive、ODPS、HBase、FTP等各种异构数据源之间稳定高效的数据同步功能
Kettle:一款国外开源的 ETL 工具,纯 Java 编写,绿色无需安装,数据抽取高效稳定(数据迁移工具)
3、数据建模
数据建模指的是对现实世界各类数据的抽象,包括建立数据库实体以及各实体之间的关系等等,主要包括的产品为erwin、PowerDesigner等等。
产品举例:
erwin:业界领先的数据建模解决方案,提供一个简单的,可视化界面来管理复杂的数据环境
PowerDesigner:Sybase的企业建模和设计解决方案,采用模型驱动方法,将业务与IT结合起来,可帮助部署有效的企业体系架构,并为研发生命周期管理提供强大的分析与设计技术
三、数据分析应用技术
1、BI工具
BI即商业智能,无需编程的数据可视化工具,是一套完整的解决方案,用来将企业中现有的数据进行有效的整合,快速准确的提供报表并提出决策依据,帮助企业做出明智的业务经营决策,包括tableau、FineBI、Power BI、spagobi、Quick BI、QlikView、 iCharts、Grow、Visme、Datawrapper等等。
产品举例:
tableau:人人可用的数据可视化分析工具
FineBI:帆软新一代自助大数据分析BI工具
Power BI:微软用于分析数据和共享见解的一套可视化业务分析工具
spagobi:开源商业智能套件
Quick BI:阿里轻量级自助BI工具服务平台
2、数据可视化开发工具
更为灵活的可视化编程开发工具,包括ECHARTS、D3.js、Plotly、Chart.js、 Google Charts、 Ember Charts、 Chartist.js、Antv等等。
产品举例:
ECHARTS:最初由百度团队开源,基于JavaScript的数据可视化图表库,提供直观,生动,可交互,可个性化定制的数据可视化图表
D3.js:用于数据可视化的开源的JavaScript函数库,被认为是很好的JavaScript可视化框架之一
Plotly:一个知名的、功能强大的数据可视化框架,可以构建交互式图形和创建丰富多样的图表和地图
Antv:蚂蚁金服全新一代数据可视化解决方案,致力于提供一套简单方便、专业可靠、无限可能的数据可视化最佳实践
3、数据挖掘平台
提供机器学习训练和发布的平台,数据挖掘可视化成为一种趋势,包括Angel、KNIME、Rapid Miner、IBM SPSS Modeler、Oracle Data Mining、SAS Data Mining、Apache Mahout、Spark MLlib、Python/R、PAI等等。
产品举例:
Angel:腾讯、香港科技大学等联合研发的使用Java和Scala语言开发,面向机器学习的高性能分布式计算框架
KNIME:一个用户友好、可理解、全面的开源数据集成、处理、分析和探索平台,它有一个图形用户界面,帮助用户方便地连接节点进行数据处理
Rapid Miner:一款不需要编程就可以进行数据分析和数据挖掘的软件,简单易学,人机界面也十分友好
IBM SPSS Modeler:以图形化的界面、简单的拖拽方式来快速构建数据挖掘分析模型著称,,它允许您在不编程的情况下生成各种数据挖掘算法
Oracle Data Mining:是 Oracle SQL Developer 的一个扩展,数据分析师通过它能够查看数据、构建和评估多个机器学习/数据挖掘模型以及加速模型部署
SAS Data Mining:提供了一个易于使用的GUI,其描述性和预测性建模提供了更好的理解数据的见解,还包括可升级处理、自动化、强化算法、建模、数据可视化和勘探等先进工具
Apache Mahout:Apache Software Foundation(ASF) 旗下的一个开源项目,提供一些可扩展的机器学习领域经典算法的实现,旨在帮助开发人员更加方便快捷地创建智能应用程序
Spark MLlib:是Spark对常用的机器学习算法的实现库,同时包括相关的测试和数据生成器
Python/R:大家都懂的
4、深度学习引擎
提供深度学习训练和发布的平台,包括TensorFlow、PP飞浆、caffe2、Theano、keras、MXNet等等。
产品举例:
TensorFlow:一个使用数据流图(data flow graphs)进行数值计算的开源软件库,可以看成是一个嵌入Python的编程语言,你写的TensorFlow代码会被Python编译成一张图,然后由TensorFlow执行引擎运行
Theano:Theano 是一个比较低层的库,它支持自动的函数梯度计算,带有 Python 接口并集成了 Numpy,这使得它从一开始就成为了通用深度学习领域最常使用的库之一,由于它不支持多 GPU 和水平扩展,已然开始被遗忘
PyTorch:一个开源的Python机器学习库,本质上是Numpy的替代者,而且支持GPU、带有高级功能,可以用来搭建和训练深度神经网络
caffe2:PyTorch有优秀的前端,Caffe2有优秀的后端,整合起来以后可以进一步最大化开发者的效率
keras:一个由Python编写的开源人工神经网络库,是一个非常高层的库,可以作为Tensorflow、Microsoft-CNTK和Theano的高阶应用程序接口,进行深度学习模型的设计、调试、评估、应用和可视化,Keras 强调极简主义——你只需几行代码就能构建一个神经网络
Deeplearning4j:为Java和Java虚拟机编写的开源深度学习库,是广泛支持各种深度学习算法的运算框架
PP飞浆:百度一个集深度学习核心框架、工具组件和服务平台为一体的技术先进、功能完备的开源深度学习平台
MXNet:亚马逊的一款设计为效率和灵活性的深度学习框架。它允许你混合符号编程和命令式编程,从而最大限度提高效率和生产力
cntk:微软出品的一个开源的深度学习工具包,可以运行在CPU上,也可以运行在GPU上。CNTK的所有API均基于C++设计,因此在速度和可用性上很好
5、图分析
图分析使用基于图的方法来分析连接的数据,可以查询图数据,使用基本统计信息,可视化地探索图、展示图,或者将图信息预处理后合并到机器学习任务中,图分析引擎包括Gephi、NodeXL等等。
产品举例:
Gephi:是开源免费跨平台基于JVM的复杂网络分析软件, 其主要用于各种网络和复杂系统,因它简单、易学、出图美观而备受青睐
NodeXL:是一个功能强大且易于使用的交互式网络可视化和分析工具,它以MS Excel(Excel 2007或者Excel 2010)模板的形式,利用MS Excel作为数据展示和分析平台
Palantir:是一种人和机器的高效结合的平台,它是一个数据分析平台,通过图(graphs)、地图(maps)、统计(statistics)、集合(set theory)论分析结构或非结构化数据
四、数据安全流通技术
1、隐私计算
指在保证数据提供方不泄露敏感数据的前提下,对数据进行分析计算并能验证计算结果的信息技术。广义上是指面向隐私保护的计算系统与技术,涵盖数据的产生、存储、计算、应用、销毁等信息流程全过程,想要达成的效果是使数据在各个环节中“可用不可见”,包括Private Join &Compute、crypten、FedAI及FEDLEARNER等等。
产品举例:
Private Join Compute:谷歌开源的多方计算 (MPC) 工具 ,以帮助组织机构更好地处理机密数据集,Private Join and Compute 是一种密码协议,可供双方联合用于研究工作,在相互共享数据之前对数据进行加密。该系统确保每一方都不会暴露自己的原始数据,而且所有的标识符以及相关数据仍然是完全加密的而且无法在共享进程中读取。解密和共享的唯一内容以汇总统计信息的形式呈现,然后组织机构可以使用它来发现共性和并收集情报
crypten:Facebook开源的多方安全计算(MPC)的框架,其底层依赖于深度学习框架PyTorch
FedAI:联邦学习生态是一个促进 AI 多方建模的技术社区,使用联邦学习技术能够满足用户隐私保护、数据安全、数据保密和政府法规的要求
FEDLEARNER:字节跳动开源的联邦机器学习平台
2、数据脱敏
指对某些敏感信息通过脱敏规则进行数据的变形,实现敏感隐私数据的可靠保护。在涉及客户安全数据或者一些商业性敏感数据的情况下,在不违反系统规则条件下,对真实数据进行改造并提供测试使用,如身份证号、手机号、卡号、客户号等个人信息都需要进行数据脱敏在,主要包括DATPROF、IRI、ShardingSphere等等。
产品举例:
DATPROF PRIVACY:提供了一种掩盖和生成用于测试数据库的数据的智能方法,它以一种非常简单且经过验证的方式为子集数据库提供了获得专利的算法
IRI:IRI是一家成立于1978年的美国ISV,以CoSort快速数据转换,FieldShield数据屏蔽和RowGen测试数据产品而闻名。IRI还将这些捆绑在一起,并将数据发现,集成,迁移,治理和分析整合到一个称为Voracity的大数据管理平台中
ShardingSphere:Apache ShardingSphere是一套开源的分布式数据库中间件解决方案组成的生态圈,数据脱敏模块属于ShardingSphere分布式治理这一核心功能下的子功能模块。它通过对用户输入的SQL进行解析,并依据用户提供的脱敏配置对SQL进行改写,从而实现对原文数据进行加密,并将原文数据(可选)及密文数据同时存储到底层数据库。在用户查询数据时,它又从数据库中取出密文数据,并对其解密,最终将解密后的原始数据返回给用户
3、身份认证
指通过一定的手段,完成对用户身份的确认,身份验证的方法有很多,基本上可分为:基于共享密钥的身份验证、基于生物学特征的身份验证和基于公开密钥加密算法的身份验证,主要包括CAS、KEYCLOAK、Kerberos等等。
产品举例:
CAS:统一身份认证CAS(Central Authentication Service)是SSO(单点登录SSO(Single Sign ON),指在多个应用系统中,只需登录一次,即可在多个应用系统之间共享登录)的开源实现,利用CAS实现SSO可以很大程度的降低开发和维护的成本
KEYCLOAK:一个为浏览器和 RESTful Web 服务提供 SSO 的集成
Kerberos:一种计算机网络授权协议,用来在非安全网络中,对个人通信以安全的手段进行身份认证
通过《白皮书》的指引,我们对于整个大数据技术体系会有一个基本了解,当然还会有缺失,比如数据分析应用技术大类中缺少了OLAP、基础技术中缺少了HTAP这种混合数据库等等,但已经比较全面了。
虽然我们没法也没必要去理解和掌握每一项大数据技术,但知道有这个技术的存在,大致知道其价值,从而在需要的时候想到它,无论是对于数据管理者或者是技术架构师,都是很重要的。
-------------------------------------------------

 浙公网安备 33010602011771号
浙公网安备 33010602011771号