对象池-线程池-连接池原理
一、设计与原理
1、基础案例
首先看一个基于common-pool2对象池组件的应用案例,主要有工厂类、对象池、对象三个核心角色,以及池化对象的使用流程:
import org.apache.commons.pool2.BasePooledObjectFactory;
import org.apache.commons.pool2.PooledObject;
import org.apache.commons.pool2.impl.DefaultPooledObject;
import org.apache.commons.pool2.impl.GenericObjectPool;
import org.apache.commons.pool2.impl.GenericObjectPoolConfig;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
public class ObjPool {
public static void main(String[] args) throws Exception {
// 声明对象池
DevObjPool devObjPool = new DevObjPool() ;
// 池中借用对象
DevObj devObj = devObjPool.borrowObject();
System.out.println("Idle="+devObjPool.getNumIdle()+";Active="+devObjPool.getNumActive());
// 使用对象
devObj.devObjInfo();
// 归还给对象池
devObjPool.returnObject(devObj);
System.out.println("Idle="+devObjPool.getNumIdle()+";Active="+devObjPool.getNumActive());
// 查看对象池
System.out.println(devObjPool.listAllObjects());
}
}
/**
* 对象定义
*/
class DevObj {
private static final Logger logger = LoggerFactory.getLogger(DevObj.class) ;
public DevObj (){
logger.info("build...dev...obj");
}
public void devObjInfo (){
logger.info("dev...obj...info");
}
}
/**
* 对象工厂
*/
class DevObjFactory extends BasePooledObjectFactory<DevObj> {
@Override
public DevObj create() throws Exception {
// 创建对象
return new DevObj() ;
}
@Override
public PooledObject<DevObj> wrap(DevObj devObj) {
// 池化对象
return new DefaultPooledObject<>(devObj);
}
}
/**
* 对象池
*/
class DevObjPool extends GenericObjectPool<DevObj> {
public DevObjPool() {
super(new DevObjFactory(), new GenericObjectPoolConfig<>());
}
}
案例中对象是完全自定义的;对象工厂中则重写两个核心方法:创建和包装,以此创建池化对象;对象池的构建依赖定义的对象工厂,配置采用组件提供的常规配置类;可以通过调整对象实例化的时间以及创建对象的个数,初步理解对象池的原理。
2、接口设计
1.1 PooledObjectFactory 接口
- 工厂类,负责对象实例化,创建、验证、销毁、状态管理等;
- 案例中
BasePooledObjectFactory类则是该接口的基础实现;
1.2 ObjectPool 接口
- 对象池,并且继承
Closeable接口,管理对象生命周期,以及活跃和空闲对象的数据信息获取; - 案例中
GenericObjectPool类是对于该接口的实现,并且是可配置化的方式;
1.3 PooledObject 接口
- 池化对象,基于包装类被维护在对象池中,并且维护一些附加信息用来跟踪,例如时间、状态;
- 案例中采用
DefaultPooledObject包装类,实现该接口并且线程安全,注意工厂类中的重写;
3、运行原理
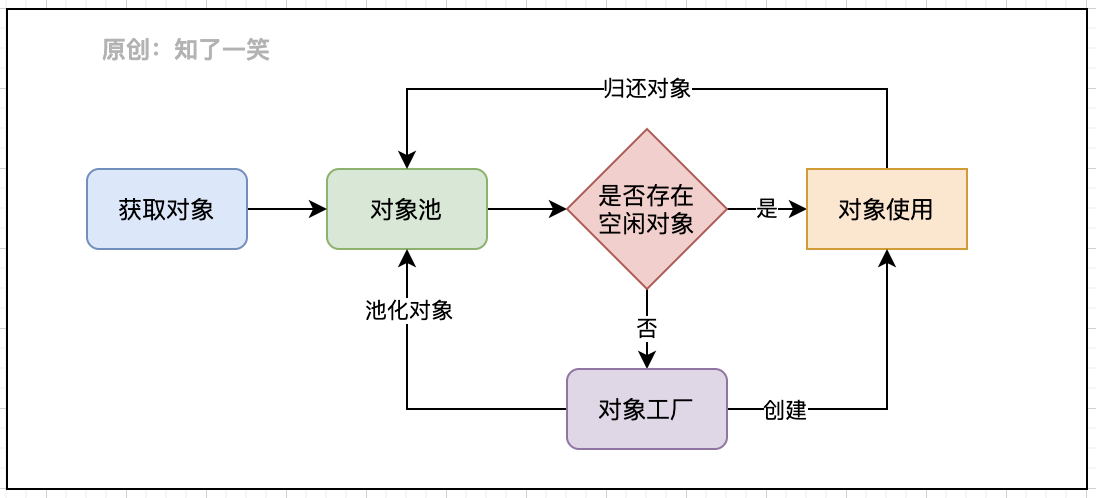
通过对象池获取对象,可能是通过工厂新创建的,也可能是空闲的对象;当对象获取成功且使用完成后,需要归还对象;在案例执行过程中,不断查询对象池中空闲和活跃对象的数量,用来监控池的变化。
二、构造分析
1、对象池
public GenericObjectPool(final PooledObjectFactory<T> factory,final GenericObjectPoolConfig<T> config);
在完整的构造方法中,涉及到三个核心对象:工厂对象、配置对象、双端阻塞队列;通过这几个对象创建一个新的对象池;在config中提供了一些简单的默认配置:例如maxTotal、maxIdle、minIdle等,也可以扩展自定义配置;
2、双端队列
private final LinkedBlockingDeque<PooledObject<T>> idleObjects;
public GenericObjectPool(final PooledObjectFactory<T> factory,final GenericObjectPoolConfig<T> config) {
idleObjects = new LinkedBlockingDeque<>(config.getFairness());
}
LinkedBlockingDeque支持在队列的首尾操作元素,例如添加和移除等;操作需要通过主锁进行加锁,并且基于两个状态锁进行协作;
// 队首节点
private transient LinkedBlockingDeque.Node<E> first;
// 队尾节点
private transient LinkedBlockingDeque.Node<E> last;
// 主锁
private final InterruptibleReentrantLock lock;
// 非空状态锁
private final Condition notEmpty;
// 未满状态锁
private final Condition notFull;
关于链表和队列的特点,在之前的文章中有单独分析过,此处的源码在JDK的容器中也很常见,这里不在赘述,对象池的整个构造有大致轮廓之后,下面再来细看对象的管理逻辑。
三、对象管理
1、添加对象
创建一个新对象并且放入池中,通常应用在需要预加载的场景中;涉及到两个核心操作:工厂创建对象,对象池化管理;
public void GenericObjectPool.addObject() throws Exception ;
2、借用对象
public T GenericObjectPool.borrowObject(final long borrowMaxWaitMillis) throws Exception ;
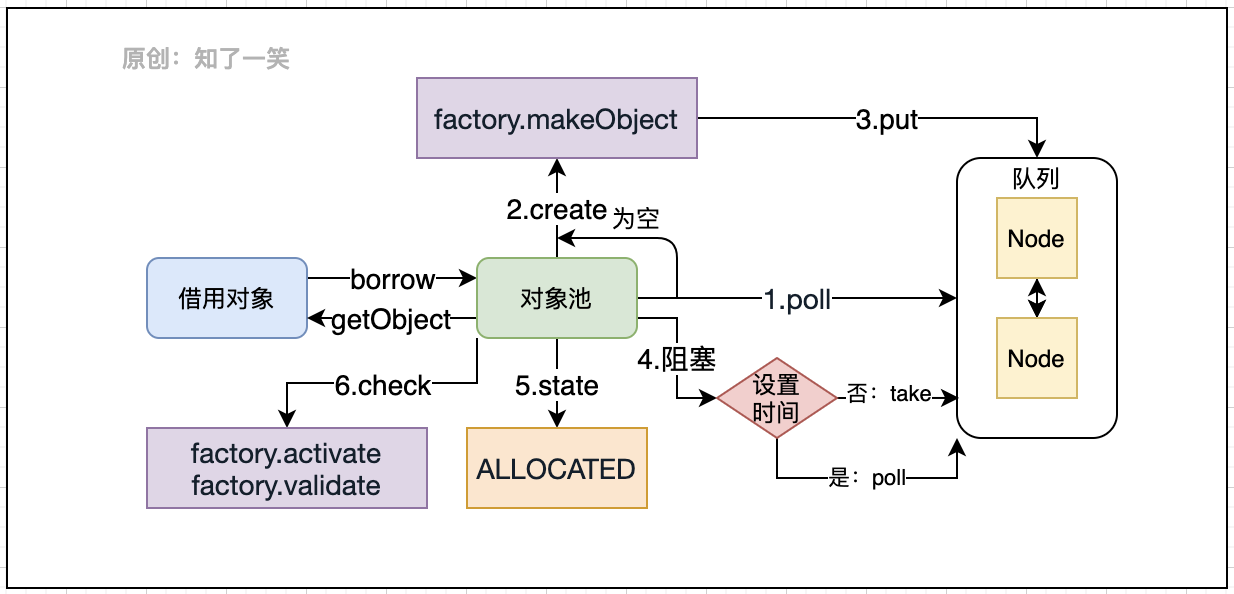
首先从队列中获取对象;如果没有获取到,调用工厂创建方法,之后池化管理;对象获取之后会改变状态为ALLOCATED使用中;最后经过工厂的确认,完成对象获取动作;
3、归还对象
public void GenericObjectPool.returnObject(final T obj) ;
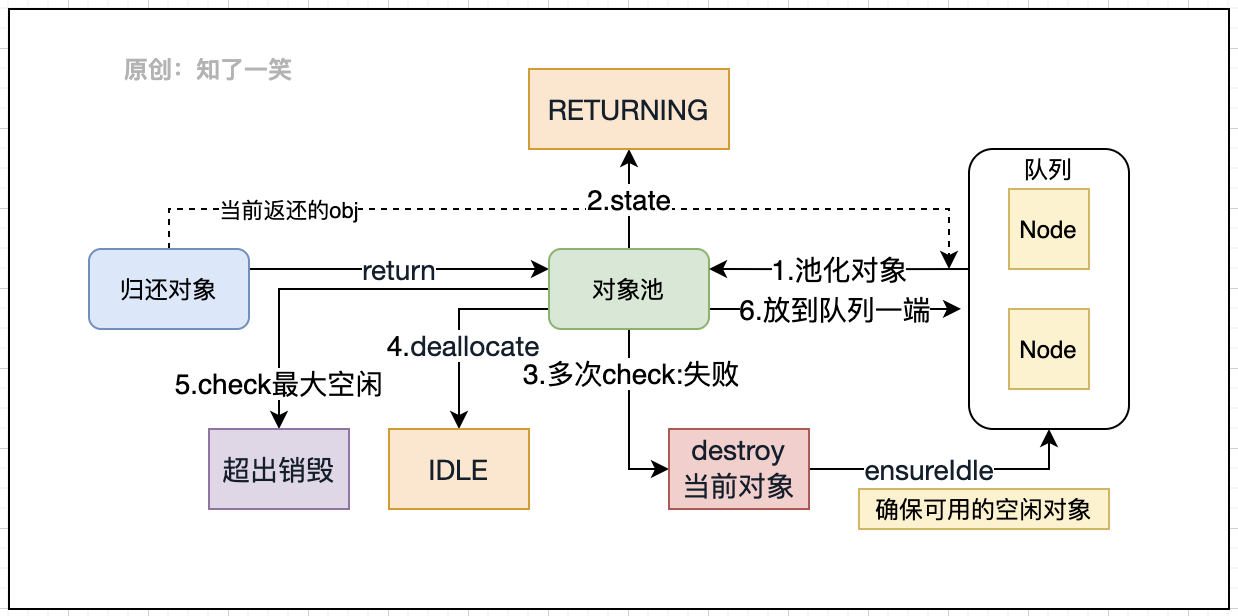
归还对象的时候,首先转换为池化对象和标记RETURNING状态;经过多次校验判断,如果失败则销毁该对象,并重新维护对象池中可用的空闲对象;最终对象被标记为空闲状态,如果不超出最大空闲数,则对象被放到队列的某一端;
4、对象状态
关于池化对象的状态在PooledObjectState类中有枚举和描述,在图中只是对部分几个状态流转做示意,更多细节可以参考状态类;

可以参考在上述案例中使用到的DefaultPooledObject默认池化对象类中相关方法,结合状态枚举,可以理解不同状态之间的校验和转换。
四、Redis应用
Lettuce作为Redis高级的客户端组件,通信层使用Netty组件,并且是线程安全,支持同步和异步模式,支持集群和哨兵模式;作为当下项目中常用的配置,其底层对象池基于common-pool2组件。
1、配置管理
基于如下配置即表示采用Lettuce组件,其中涉及到池的几个参数配置:最小空闲、最大活跃、最大空闲;这里可以对比GenericObjectPoolConfig中的配置:
spring:
redis:
host: ${REDIS_HOST:127.0.0.1}
lettuce:
pool:
min-idle: 10
max-active: 100
max-idle: 100
2、源码分析
围绕对象池的特点,自然去追寻源码中关于:配置、工厂、对象几个核心的角色类;从上述配置参数切入,可以很容易发现如下几个类:

2.1 配置转换
// 连接配置
class LettuceConnectionConfiguration extends RedisConnectionConfiguration {
private static class PoolBuilderFactory {
// 构建对象池配置
private GenericObjectPoolConfig<?> getPoolConfig(RedisProperties.Pool properties) {
GenericObjectPoolConfig<?> config = new GenericObjectPoolConfig<>();
config.setMaxTotal(properties.getMaxActive());
config.setMaxIdle(properties.getMaxIdle());
config.setMinIdle(properties.getMinIdle());
return config;
}
}
}
这里将配置文件中Redis的相关参数,构建到GenericObjectPoolConfig类中,即配置加载过程;
2.2 对象池构造
class LettucePoolingConnectionProvider implements LettuceConnectionProvider {
// 对象池核心角色
private final GenericObjectPoolConfig poolConfig;
private final BoundedPoolConfig asyncPoolConfig;
private final Map<Class<?>, GenericObjectPool> pools = new ConcurrentHashMap(32);
LettucePoolingConnectionProvider(LettuceConnectionProvider provider, LettucePoolingClientConfiguration config) {
this.poolConfig = clientConfiguration.getPoolConfig();
this.asyncPoolConfig = CommonsPool2ConfigConverter.bounded(this.config);
}
}
在构造方法中获取对象池的配置信息,这里并没有直接实例化池对象,而是采用ConcurrentHashMap容器来动态维护;
2.3 对象管理
class LettucePoolingConnectionProvider implements LettuceConnectionProvider {
// 获取Redis连接
public <T extends StatefulConnection<?, ?>> T getConnection(Class<T> connectionType) {
GenericObjectPool pool = (GenericObjectPool)this.pools.computeIfAbsent();
StatefulConnection<?, ?> connection = (StatefulConnection)pool.borrowObject();
}
// 释放Redis连接
public void release(StatefulConnection<?, ?> connection) {
GenericObjectPool<StatefulConnection<?, ?>> pool = (GenericObjectPool)this.poolRef.remove(connection);
}
}
在获取池对象时,如果不存在则根据相关配置创建池对象,并维护到Map容器中,然后从池中借用Redis连接对象;释放对象时首先判断对象所属的池,将对象归还到相应的池中。
最后总结,本文从对象池的一个简单案例切入,主要分析common-pool2组件关于:池、工厂、配置、对象管理几个角色的源码逻辑,并且参考其在Redis中的实践,只是冰山一角,像这种通用型并且应用范围广的组件,很值得时常去读一读源码,真的令人惊叹其鬼斧天工的设计。
一、线程池简介
1、池化思想
在项目工程中,基于池化思想的技术应用很多,例如基于线程池的任务并发执行,中间件服务的连接池配置,通过对共享资源的管理,降低资源的占用消耗,提升效率和服务性能。
池化思想从直观感觉上理解,既有作为容器的存储能力(持续性的承接),也要具备维持一定量的储备能力(初始化的提供),同时作为容器又必然有大小的限制,下面通过这个基础逻辑来详细分析Java中的线程池原理。
2、线程池
首先熟悉JVM执行周期的都知道,在内存中频繁的创建和销毁对象是很影响性能的,而线程作为进程中运行的基本单位,通过线程池的方式重复使用已创建的线程,在任务执行动作上避免或减少线程的频繁创建动作。
线程池中维护多个线程,当收到调度任务时可以避免创建线程直接执行,并以此降低服务资源的消耗,把相对不确定的并发任务管理在相对确定的线程池中,提高系统服务的稳定性。下文基于JDK1.8围绕ThreadPoolExecutor类深入分析。
二、原理与周期
1、类图设计

- Executor 接口
源码注释解读:将来会执行命令,任务提交和执行两个动作会被解耦,传入Runnable任务对象即可,线程池会执行相应调度和任务处理。Executor虽然是ThreadPoolExecutor线程池的顶层接口,但是其本身只是抽象了任务的处理思想。
- ExecutorService 接口
扩展Executor接口,单个或批量的给任务的执行结果生成Future,并增添任务中断或终止的管理方法。
- AbstractExecutorService 抽象类
提供对ExecutorService接口定义的任务执行方法(submit,invokeAll)等默认实现,提供newTaskFor方法用于构建RunnableFuture对象。
- ThreadPoolExecutor 类
维护线程池生命周期,管理线程和任务,通过相应调度机制实现任务的并发执行。
2、基本案例
示例中创建了一个简单的butte-pool线程池,设置4个核心线程执行任务,队列容器设置256大小;在实际业务中,对于参数设定需要考量任务执行时间,服务配置,测试数据等。
public class ThrPool implements Runnable {
private static final Logger logger = LoggerFactory.getLogger(ThrPool.class) ;
/**
* 线程池管理,ThreadFactoryBuilder出自Guava工具库
*/
private static final ThreadPoolExecutor DEV_POOL;
static {
ThreadFactory threadFactory = new ThreadFactoryBuilder().setNameFormat("butte-pool-%d").build();
DEV_POOL = new ThreadPoolExecutor(0, 8,60L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<>(256),threadFactory, new ThreadPoolExecutor.AbortPolicy());
DEV_POOL.allowCoreThreadTimeOut(true);
}
/**
* 任务方法
*/
@Override
public void run() {
try {
logger.info("Print...Job...Run...;queue_size:{}",DEV_POOL.getQueue().size());
Thread.sleep(5000);
} catch (Exception e){
e.printStackTrace();
}
}
}

通过对上述线程池核心参数的不断调整,以及控制任务执行时间的长短,尤其可以设置一些参数的极端值,观察任务执行的效果,可以初步感知线程池的运行特点,下面围绕该案例展开详细的分析。
3、构造方法
在ThreadPoolExecutor类中提供多个构造方法,以满足不同场景下线程池的构造需求,这里需要描述几个注意事项:
public ThreadPoolExecutor(int corePoolSize,int maximumPoolSize,long keepAliveTime,
BlockingQueue<Runnable> workQueue,ThreadFactory threadFactory)
- 从构造方法的判断中,corePoolSize的大小允许设置为0,在分析任务执行时再细说影响;
- 线程池创建后,不会立即启动核心线程,通常会等到任务提交的时候再去启动;或者主动执行
prestartCoreThread||prestartAllCoreThreads方法; - 在当前版本的JDK中,CoreThread核心线程也是允许超时终止掉的,避免线程长时间闲置;
- 如果允许核心线程超时终止,该方法会校验keepAliveTime必须大于0,否则抛出异常;
4、运行原理

线程池的基本运行逻辑,任务提交之后有三种处理方式:直接分配线程执行;或者被放入任务队列,等待执行;如果直接被拒绝,会返回异常;任务的提交和执行被解耦,构成一个生产消费的模型。
5、生命周期
这里从源码开始逐步分析线程池的核心逻辑,首先看看对于生命周期的状态描述,涉及如下几个核心字段:
private final AtomicInteger ctl = new AtomicInteger(ctlOf(RUNNING, 0));
private static final int COUNT_BITS = Integer.SIZE - 3;
private static final int CAPACITY = (1 << COUNT_BITS) - 1;
// 状态描述
private static final int RUNNING = -1 << COUNT_BITS;
private static final int SHUTDOWN = 0 << COUNT_BITS;
private static final int STOP = 1 << COUNT_BITS;
private static final int TIDYING = 2 << COUNT_BITS;
private static final int TERMINATED = 3 << COUNT_BITS;
ctl控制线程池的状态,包含两个概念字段:workerCount线程池内有效线程数,runState运行状态,具体的运行有5种状态描述:
- RUNNING:接受新任务,处理阻塞队列中的任务;
- SHUTDOWN:不接受新任务,处理阻塞队列中已存在的任务;
- STOP:不接受新任务,不处理阻塞队列中的任务,中断正在进行的任务;
- TIDYING:所有任务都已终止,workerCount=0,线程池进入该状态后会执行
terminated()方法; - TERMINATED: 执行
terminated()方法完后进入该状态;
状态之间的转换逻辑如下:

通过runStateOf()方法可以计算当前的运行状态,这里对于线程池生命周期的定义,以及状态的转换逻辑在ctl字段的源码注释中,更多细节可以参考该处描述文档。
三、任务管理
1、调度逻辑
从上面对线程池有整体的了解之后,现在从任务提交和执行这个核心流程入手,对源码和逻辑进行深入分析。任务调度作为线程池的核心能力,可以直接从execute(task)方法切入。
public void execute(Runnable command) {
// 上文描述的workerCount与runState
int c = ctl.get();
// 核心线程池
if (workerCountOf(c) < corePoolSize){}
// 任务队列
if (isRunning(c) && workQueue.offer(command)){}
// 拒绝策略
else if (!addWorker(command, false)) reject(command);
}
从整体上看,任务调度被放在三个分支步骤中判断,即:核心线程池、任务队列、拒绝策略,下面再细看每个分支的处理逻辑;
1.1 核心线程池
// 如果有效线程数小于核心线程数,新建线程并绑定当前任务
if (workerCountOf(c) < corePoolSize) {
if (addWorker(command, true))
}
1.2 任务队列
// 如果线程池是运行状态,并且任务添加队列成功
if (isRunning(c) && workQueue.offer(command)) {
// 二次校验如果是非运行状态,则移除该任务,执行拒绝策略
int recheck = ctl.get();
if (! isRunning(recheck) && remove(command))
reject(command);
// 如果有效线程数是0,执行addWorker添加方法
else if (workerCountOf(recheck) == 0)
addWorker(null, false);
}
1.3 拒绝策略
// 再次执行addWorker方法,如果失败则拒绝该任务
else if (!addWorker(command, false)) reject(command);
这样execute方法执行逻辑,任务调度的流程如下:

如上图任务被提交到线程池后的核心调度逻辑,任务既然提交自然是希望被执行的,源码中也多处调用addWorker方法添加工作线程。
2、Worker线程
线程池内工作线程被封装在Worker类中,继承AQS并实现Runnable接口,维护线程的创建和任务的执行:
private final class Worker extends AbstractQueuedSynchronizer implements Runnable {
final Thread thread; // 持有线程
Runnable firstTask; // 初始化任务
}
2.1 addWorker 方法
既然添加工作线程,意味有任务需要执行:
- firstTask:新创建的线程第一个执行的任务,允许为空或者null;
- core:传true,新增线程时判断当前线程数是否小于corePoolSize;传false,新增线程时判断当前线程数是否小于maximumPoolSize;
private final HashSet<Worker> workers = new HashSet<Worker>();
private final BlockingQueue<Runnable> workQueue;
private boolean addWorker(Runnable firstTask, boolean core) ;
通过对该方法的源码分析,执行逻辑流程如下:

工作线程创建之后,在HashSet中维护和持有线程的引用,这样就可以对线程池做相应的put或者remove操作,进而对生命周期进行管理。
2.2 runWorker 方法
在Worker类中对于run方法的实现,实际上是委托给runWorker方法,用来周期性执行具体的线程任务,同样分析其执行逻辑:

整个执行流程通过while循环不断获取任务并执行任务,整个过程也需要不断的校验线程池状态,及时的中断线程执行,该方法执行完成后会请求线程销毁动作。
3、任务队列
线程池两大核心能力线程和任务的管理,并且对二者解耦,通过队列中任务的管理构建生产消费模式,不同的队列类型有各自的存取政策;LinkedBlockingQueue创建链表结构的队列,默认的Integer.MAX_VALUE容量过度,需要指定队列大小,按照先进先出的原则管理;
3.1 getTask 方法
在获取任务时,除了必要的线程池状态判断,就是要校验当前任务的线程是否需要超时回收,上面已经提过即使核心线程池也可以设置超时时效,如果没有获取到任务,则认为runWorker方法执行完成:

3.2 reject 方法
不管是线程池还是任务队列,都有容量的边界,当容量达到上限时,就需要拒绝新提交的任务,在上述案例中采用的是ThreadPoolExecutor.AbortPolicy丢弃任务并抛出异常,还有其他几种策略按需选择即可。
四、监控与配置
在大部分的项目中,对于线程池都是直接定义好相关参数,如果需要调整,也基本都需要服务重启来完成,实际上线程池有一些放开的参数调整与查询的方法:

setCorePoolSize 方法
在方法内部经过一系列的逻辑校验,保证线程池平稳的过渡,整个流程严谨且复杂,结合线程池参数获取方法,就可以进行动态化的参数配置与监控,从而实现可控的线程池管理:

最后关于更多线程池的细节问题,可以多阅读源码文档,并结合案例进行实践;线程池的原理在很多组件中都有应用,例如各种连接池,并行计算等,同样值得深入学习和总结。
一、设计与原理
1、基础案例
HiKariCP作为SpringBoot2框架的默认连接池,号称是跑的最快的连接池,数据库连接池与之前两篇提到的线程池和对象池,从设计的原理上都是基于池化思想,只是在实现方式上有各自的特点;首先还是看HiKariCP用法的基础案例:
import com.zaxxer.hikari.HikariConfig;
import com.zaxxer.hikari.HikariDataSource;
import java.sql.Connection;
import java.sql.ResultSet;
import java.sql.Statement;
public class ConPool {
private static HikariConfig buildConfig (){
HikariConfig hikariConfig = new HikariConfig() ;
// 基础配置
hikariConfig.setJdbcUrl("jdbc:mysql://127.0.0.1:3306/junit_test?characterEncoding=utf8");
hikariConfig.setUsername("root");
hikariConfig.setPassword("123456");
// 连接池配置
hikariConfig.setPoolName("dev-hikari-pool");
hikariConfig.setMinimumIdle(4);
hikariConfig.setMaximumPoolSize(8);
hikariConfig.setIdleTimeout(600000L);
return hikariConfig ;
}
public static void main(String[] args) throws Exception {
// 构建数据源
HikariDataSource dataSource = new HikariDataSource(buildConfig()) ;
// 获取连接
Connection connection = dataSource.getConnection() ;
// 声明SQL执行
Statement statement = connection.createStatement();
ResultSet resultSet = statement.executeQuery("SELECT count(1) num FROM jt_activity") ;
// 输出执行结果
if (resultSet.next()) {
System.out.println("query-count-result:"+resultSet.getInt("num"));
}
}
}
2、核心相关类
- HikariDataSource类:汇集数据源描述的相关信息,例如配置、连接池、连接对象、状态管理等;
- HikariConfig类:维护数据源的配置管理,以及参数校验,例如userName、passWord、minIdle、maxPoolSize等;
- HikariPool类:提供对连接池与池中对象管理的核心能力,并实现池相关监控数据的查询方法;
- ConcurrentBag类:抛弃了常规池中采用的阻塞队列作为容器的方式,自定义该并发容器来存储连接对象;
- PoolEntry类:拓展连接对象的信息,例如状态、时间等,方便容器中追踪这些实例化对象;
通过对连接池中几个核心类的分析,也能直观地体会到该源码的设计原理,与上篇总结的对象池应用有异曲同工之妙,只是不同的组件不同的开发者在实现的时候,都具备各自的抽象逻辑。
3、加载逻辑

通过配置信息去构建数据源描述,在构造方法中基于配置再去实例化连接池,在HikariPool的构造中,实例化ConcurrentBag容器对象;下面再从源码层面分析实现细节。
二、容器分析
1、容器结构
容器ConcurrentBag类提供PoolEntry类型的连接对象存储,以及基本的元素管理能力,对象的状态描述;虽然被HikariPool对象池类所持有,但是实际的操作逻辑是在该类中;
1.1 基础属性
其中最为核心的是sharedList共享集合、threadList线程级缓存、handoffQueue即时队列;
// 共享对象集合,存放数据库连接
private final CopyOnWriteArrayList<T> sharedList;
// 缓存线程级连接对象,会被优先使用,避免被争抢
private final ThreadLocal<List<Object>> threadList;
// 等待获取连接的线程数
private final AtomicInteger waiters;
// 标记是否关闭
private volatile boolean closed;
// 即时处理连接的队列,当有等待线程时,通过该队列将连接分配给等待线程
private final SynchronousQueue<T> handoffQueue;
1.2 状态描述
在ConcurrentBag类中的IConcurrentBagEntry内部接口,被PoolEntry类实现,该接口定义连接对象的状态:
- STATE_NOT_IN_USE:未使用,即闲置中;
- STATE_IN_USE:使用中;
- STATE_REMOVED:被废弃;
- STATE_RESERVED:保留态,中间状态,用于尝试驱逐连接对象时;
2、包装对象
容器的基本能力是用来存储连接对象的,而对象的管理则需要很多扩展的跟踪信息,以有效的完成各种场景下的识别,此时就需要借助包装类的引入;
// 业务真正使用的连接对象
Connection connection;
// 最近访问时间
long lastAccessed;
// 最近借出时间
long lastBorrowed;
// 状态描述
private volatile int state = 0;
// 是否驱逐
private volatile boolean evict;
// 生命周期结束时的调度任务
private volatile ScheduledFuture<?> endOfLife;
// 连接生成的Statement对象
private final FastList<Statement> openStatements;
// 池对象
private final HikariPool hikariPool;
这里需要注意FastList类实现List接口,为HiKariCP组件自定义,相比ArrayList类,出于对性能的追求,在元素的管理时,去掉诸多的范围校验。
三、对象管理
基于连接池的常规用法,来看看连接对象具体是如何管理,比如被借出,被释放,被废弃等,以及这些操作下对象的状态转换过程;
1、初始化
上文加载逻辑的描述中,已经提到在构建数据源的时候,会根据配置实例化连接池,在初始化的时候,基于两个核心切入点来分析源码:1.实例化多少连接对象、2.连接对象转换包装对象;
在连接池的构造中执行了checkFailFast方法,在该方法内执行MinIdle最小空闲数的判断,如果大于0,则创建一个包装对象并放入容器中;

public HikariPool(final HikariConfig config) ;
private void checkFailFast() {
final PoolEntry poolEntry = createPoolEntry();
if (config.getMinimumIdle() > 0) {
connectionBag.add(poolEntry);
}
}
需要注意两个问题,创建的连接包装对象,初始状态是0即闲置中;另外虽然案例中设置MinIdle=4的值,但是这里的判断大于0,也只在容器中预先放入一个空闲对象;
2、借用对象
从池中获取连接对象时,实际调用的是容器类中的borrow方法:
public Connection HikariPool.getConnection(final long hardTimeout) throws SQLException ;
public T ConcurrentBag.borrow(long timeout, final TimeUnit timeUnit) throws InterruptedException ;

在执行borrow方法时,涉及如下几个核心步骤与逻辑:
public T borrow(long timeout, final TimeUnit timeUnit) throws InterruptedException
{
// 遍历本地线程缓存
final List<Object> list = threadList.get();
for (int i = list.size() - 1; i >= 0; i--) {
final Object entry = list.remove(i);
final T bagEntry = weakThreadLocals ? ((WeakReference<T>) entry).get() : (T) entry;
if (bagEntry != null && bagEntry.compareAndSet(STATE_NOT_IN_USE, STATE_IN_USE)) { }
}
// 增加等待线程数
final int waiting = waiters.incrementAndGet();
try {
// 遍历Shared共享集合
for (T bagEntry : sharedList) {
if (bagEntry.compareAndSet(STATE_NOT_IN_USE, STATE_IN_USE)) { }
}
// 一定时间内轮询handoff队列
listener.addBagItem(waiting);
timeout = timeUnit.toNanos(timeout);
do {
final T bagEntry = handoffQueue.poll(timeout, NANOSECONDS);
}
} finally {
// 减少等待线程数
waiters.decrementAndGet();
}
}
- 首先反向遍历本地线程缓存,如果存在空闲连接,则返回该对象;如果没有则寻找共享集合;
- 遍历Shared共享集合前,会标记等待线程数加1,如果存在空闲连接则直接返回;
- 当Shared共享集合中也没有空闲连接时,这时当前线程进行一定时间的
handoffQueue队列轮询,可能会有资源的释放,也可能是新添加的资源;
注意这里在遍历集合时,取出的对象都会对状态进行判断和更新,如果得到空闲对象,会更新为IN_USE状态,然后返回;
3、释放对象
从池中释放连接对象时,实际调用的是容器类中的requite方法:
void HikariPool.recycle(final PoolEntry poolEntry) ;
public void ConcurrentBag.requite(final T bagEntry) ;

在释放连接对象时,首先更新对象状态为空闲,然后判断当前是否有等待的线程,在borrow方法中等待线程会进入一定时间的轮询,如果没有的话则把对象放入本地线程缓存中:
public void requite(final T bagEntry) {
// 更新状态
bagEntry.setState(STATE_NOT_IN_USE);
// 等待线程判断
for (int i = 0; waiters.get() > 0; i++) {
if (bagEntry.getState() != STATE_NOT_IN_USE || handoffQueue.offer(bagEntry)) { }
}
// 本地线程缓存
final List<Object> threadLocalList = threadList.get();
if (threadLocalList.size() < 50) {
threadLocalList.add(weakThreadLocals ? new WeakReference<>(bagEntry) : bagEntry);
}
}
注意这里涉及到连接对象的状态从使用中转为NOT_IN_USE空闲;borrow与requite作为连接池中两个核心方法,负责资源创建与回收;
最后本篇文章并没有站在HiKariCP组件的整体设计上构思,只是分析连接池这冰山一角,尽管只是部分源码,但是已经足够彰显出作者对于性能的极致追求,比如:本地线程缓存、自定义容器类型、FastList等;能被普遍采用必然存在诸多支撑的理由。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号