Kubernetes Pod状态和生命周期管理
Pod是kubernetes中你可以创建和部署的最小也是最简的单位。Pod代表着集群中运行的进程。
Pod中封装着应用的容器(有的情况下是好几个容器),存储、独立的网络IP,管理容器如何运行的策略选项。Pod代表着部署的一个单位:kubernetes中应用的一个实例,可能由一个或者多个容器组合在一起共享资源。
Docker是kubernetes中最常用的容器运行时,但是Pod也支持其他容器运行时。
在Kubernetes集群中Pod有如下两种方式:
一个Pod中运行一个容器。“每个Pod中一个容器”的模式是最常见的用法;在这种使用方式中,你可以把Pod想象成单个容器的封装,Kubernetes管理的是Pod而不是直接管理容器。
在一个Pod中同时运行多个容器。一个Pod也可以同时封装几个需要紧密耦合互相协作的容器,它们之间共享资源。这些在同一个Pod中的容器可以互相协作成为一个service单位——一个容器共享文件,另一个“sidecar”容器来更新这些文件。Pod将这些容器的存储资源作为一个实体来管理。
Pod中共享的环境包括Linux的namespace、cgroup和其他可能的隔绝环境,这一点跟Docker容器一致。在Pod的环境中,每个容器可能还有更小的子隔离环境。
Pod中的容器共享IP地址和端口号,它们之间可以通过localhost互相发现。它们之间可以通过进程间通信,例如SystemV信号或者POSIX共享内存。不同Pod之间的容器具有不同的IP地址,不能直接通过IPC通信。
Pod中的容器也有访问共享volume的权限,这些volume会被定义成pod的一部分并挂载到应用容器的文件系统中。
就像每个应用容器,pod被认为是临时(非持久的)实体。在Pod的生命周期中讨论过,pod被创建后,被分配一个唯一的ID(UID),调度到节点上,并一致维持期望的状态直到被终结(根据重启策略)或者被删除。如果node死掉了,分配到了这个node上的pod,在经过一个超时时间后会被重新调度到其他node节点上。一个给定的pod(如UID定义的)不会被“重新调度”到新的节点上,而是被一个同样的pod取代,如果期望的话甚至可以是相同的名字,但是会有一个新的UID。
Pod中如何管理多个容器
Pod中可以同时运行多个进程(作为容器运行)协同工作。同一个Pod中的容器会自动的分配到同一个node上。同一个Pod中的容器共享资源、网络环境和依赖,它们总是被同时调度。
注意在一个Pod中同时运行多个容器是一种比较高级的用法。只有当你的容器需要紧密配合协作的时候才考虑用这种模式。例如,你有一个容器作为web服务器运行,需要用到共享的volume,有另一个“sidecar”容器来从远端获取资源更新这些文件,如下图所示:
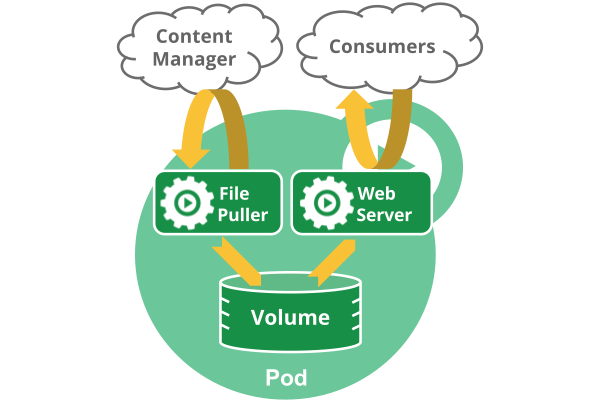
Pod中可以共享两种资源:网络和存储
网络:每个pod都会被分配一个唯一的IP地址。Pod中的所有容器共享网络空间,包括IP地址和端口。Pod内部的容器可以使用localhost互相通信。Pod中的容器与外界通信时,必须分配共享网络资源(例如使用宿主机的端口映射)。
存储:可以为一个Pod指定多个共享的Volume。Pod中的所有容器都可以访问共享的volume。Volume也可以用来持久化Pod中的存储资源,以防容器重启后文件丢失。
使用Pod
你很少会直接在kubernetes中创建单个Pod。因为Pod的生命周期是短暂的,用后即焚的实体。当Pod被创建后(不论是由你直接创建还是被其它Controller),都会被Kubernetes调度到集群的Node上。直到Pod的进程终止、被删掉、因为缺少资源而被驱逐、或者Node故障之前这个Pod都会一直保持在那个Node上。
注意:重启Pod中的容器跟重启Pod不是一回事。Pod只提供容器的运行环境并保持容器的运行状态,重启容器不会造成Pod重启。
Pod不会自愈。如果Pod运行的Node故障,或者是调度器本身故障,这个Pod就会被删除。同样的,如果Pod所在Node缺少资源或者Pod处于维护状态,Pod也会被驱逐。Kubernetes使用更高级的称为Controller的抽象层,来管理Pod实例。虽然可以直接使用Pod,但是在Kubernetes中通常是使用Controller来管理Pod的。
Controller可以创建和管理多个Pod,提供副本管理、滚动升级和集群级别的自愈能力。例如,如果一个Node故障,Controller就能自动将该节点上的Pod调度到其他健康的Node上。
Pod对象的生命周期
Pod对象自从其创建开始至其终止退出的时间范围称为其生命周期。在这段时间中,Pod会处于多种不同的状态,并执行一些操作;其中,创建主容器(main container)为必需的操作,其他可选的操作还包括运行初始化容器(init container)、容器启动后钩子(post start hook)、容器的存活性探测(liveness probe)、就绪性探测(readiness probe)以及容器终止前钩子(pre stop hook)等,这些操作是否执行则取决于Pod的定义。如下图所示:
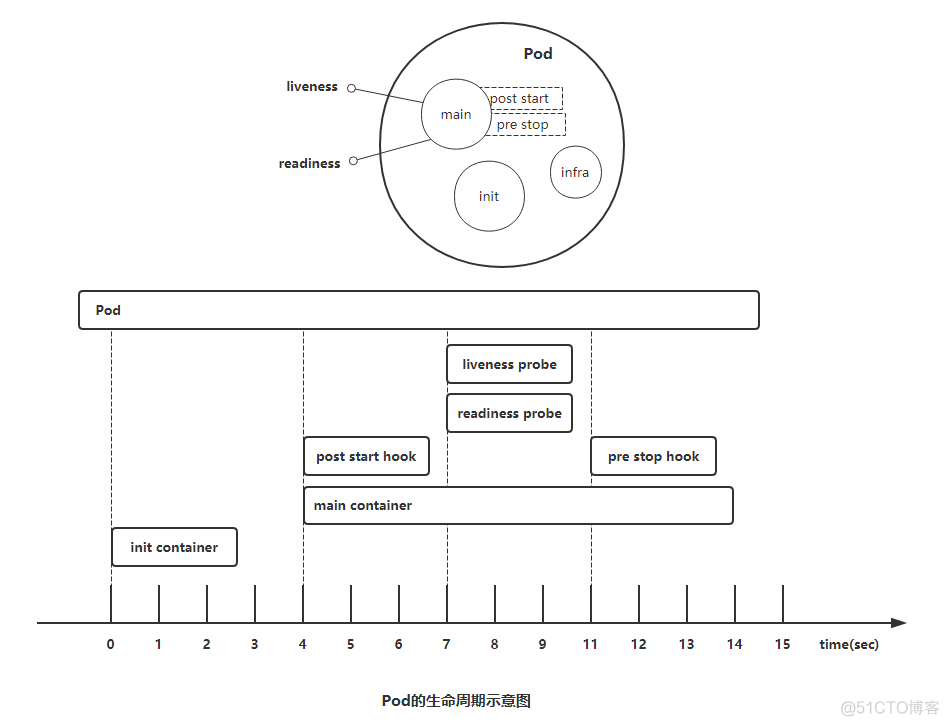
Pod phase
Pod的status字段是一个PodStatus的对象,PodStatus中有一个phase字段。
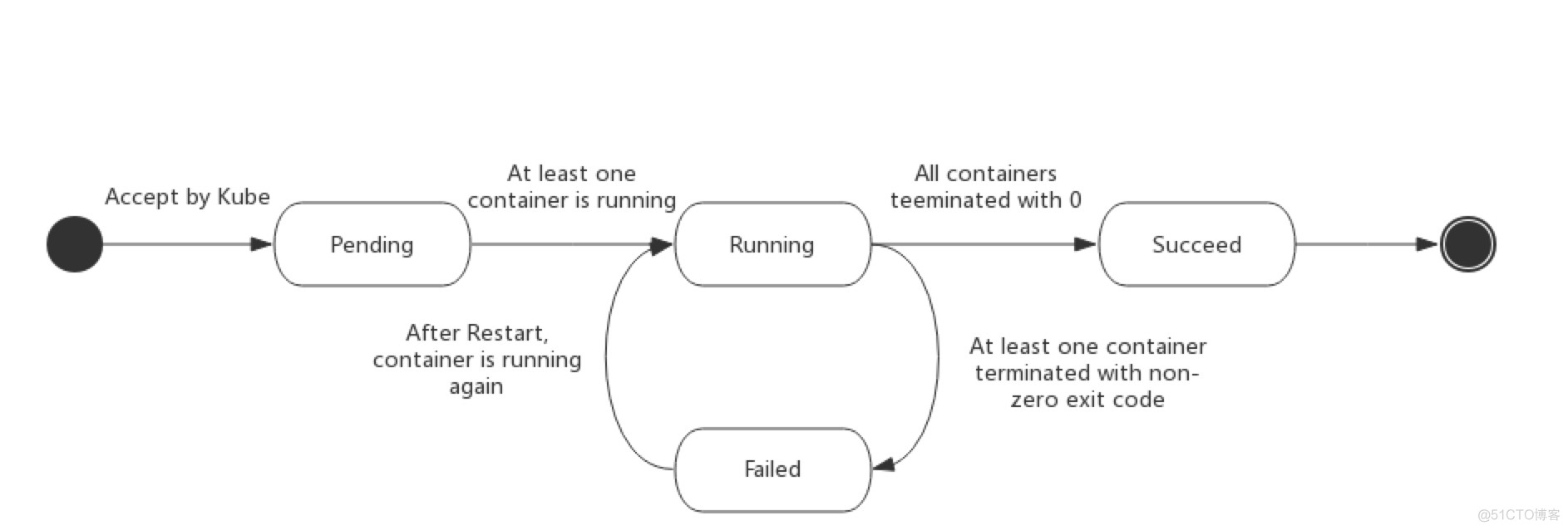
无论是手动创建还是通过Deployment等控制器创建,Pod对象总是应该处于其生命进程中以下几个相位(phase)之一。
挂起(Pending):API Server创建了pod资源对象已存入etcd中,但它尚未被调度完成,或者仍处于从仓库下载镜像的过程中。
运行中(Running):Pod已经被调度至某节点,并且所有容器都已经被kubelet创建完成。
成功(Succeeded):Pod中的所有容器都已经成功终止并且不会被重启
失败(Failed):Pod中的所有容器都已终止了,并且至少有一个容器是因为失败终止。即容器以非0状态退出或者被系统禁止。
未知(Unknown):Api Server无法正常获取到Pod对象的状态信息,通常是由于无法与所在工作节点的kubelet通信所致。
Pod的创建过程
Pod是kubernetes的基础单元,理解它的创建过程对于了解系统运作大有裨益。如下图描述了一个Pod资源对象的典型创建过程。
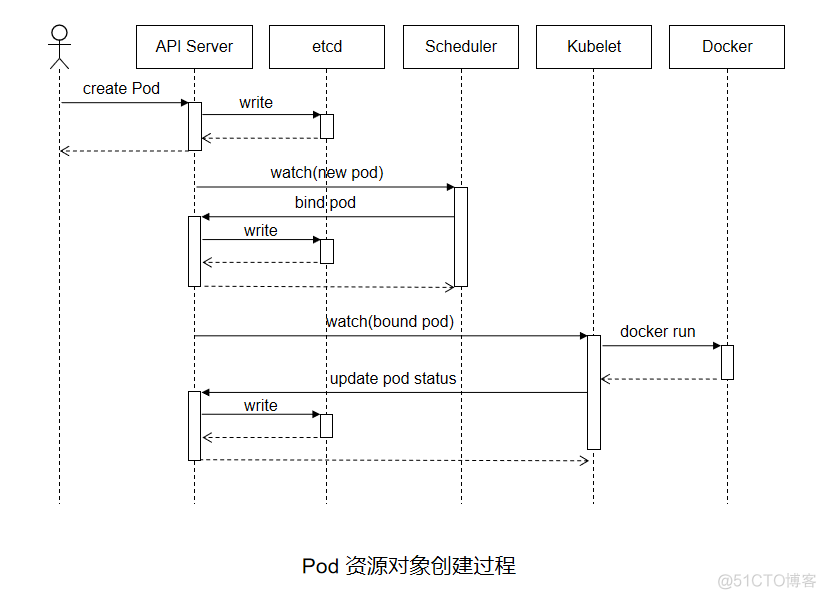
用户通过kubectl或其他API客户端提交了Pod Spec给API Server。
API Server尝试着将Pod对象的相关信息存入etcd中,待写入操作执行完成,API Server即会返回确认信息至客户端。
API Server开始反映etcd中的状态变化。
所有的kubernetes组件均使用“watch”机制来跟踪检查API Server上的相关的变动。
kube-scheduler(调度器)通过其“watcher”觉察到API Server创建了新的Pod对象但尚未绑定至任何工作节点。
kube-scheduler为Pod对象挑选一个工作节点并将结果信息更新至API Server。
调度结果信息由API Server更新至etcd存储系统,而且API Server也开始反映此Pod对象的调度结果。
Pod被调度到的目标工作节点上的kubelet尝试在当前节点上调用Docker启动容器,并将容器的结果状态返回送至API Server。
API Server将Pod状态信息存入etcd系统中。
在etcd确认写入操作成功完成后,API Server将确认信息发送至相关的kubelet,事件将通过它被接受。
Pod生命周期中的重要行为
1)初始化容器
初始化容器(init container)即应用程序的主容器启动之前要运行的容器,常用于为主容器执行一些预置操作,它们具有两种典型特征。
1)初始化容器必须运行完成直至结束,若某初始化容器运行失败,那么kubernetes需要重启它直到成功完成。(注意:如果pod的spec.restartPolicy字段值为“Never”,那么运行失败的初始化容器不会被重启。)
2)每个初始化容器都必须按定义的顺序串行运行。
2)容器探测
容器探测(container probe)是Pod对象生命周期中的一项重要的日常任务,它是kubelet对容器周期性执行的健康状态诊断,诊断操作由容器的处理器(handler)进行定义。Kubernetes支持三种处理器用于Pod探测:
ExecAction:在容器内执行指定命令,并根据其返回的状态码进行诊断的操作称为Exec探测,状态码为0表示成功,否则即为不健康状态。
TCPSocketAction:通过与容器的某TCP端口尝试建立连接进行诊断,端口能够成功打开即为正常,否则为不健康状态。
HTTPGetAction:通过向容器IP地址的某指定端口的指定path发起HTTP GET请求进行诊断,响应码为2xx或3xx时即为成功,否则为失败。
任何一种探测方式都可能存在三种结果:“Success”(成功)、“Failure”(失败)、“Unknown”(未知),只有success表示成功通过检测。
容器探测分为两种类型:
存活性探测(livenessProbe):用于判定容器是否处于“运行”(Running)状态;一旦此类检测未通过,kubelet将杀死容器并根据重启策略(restartPolicy)决定是否将其重启;未定义存活检测的容器的默认状态为“Success”。
就绪性探测(readinessProbe):用于判断容器是否准备就绪并可对外提供服务;未通过检测的容器意味着其尚未准备就绪,端点控制器(如Service对象)会将其IP从所有匹配到此Pod对象的Service对象的端点列表中移除;检测通过之后,会再将其IP添加至端点列表中。
什么时候使用存活(liveness)和就绪(readiness)探针?
如果容器中的进程能够在遇到问题或不健康的情况下自行崩溃,则不一定需要存活探针,kubelet将根据Pod的restartPolicy自动执行正确的操作。
如果希望容器在探测失败时被杀死并重新启动,那么请指定一个存活探针,并指定restartPolicy为Always或OnFailure。
如果要仅在探测成功时才开始向Pod发送流量,请指定就绪探针。在这种情况下,就绪探针可能与存活探针相同,但是spec中的就绪探针的存在意味着Pod将在没有接收到任何流量的情况下启动,并且只有在探针探测成功才开始接收流量。
如果希望容器能够自行维护,可以指定一个就绪探针,该探针检查与存活探针不同的端点。
注意:如果只想在Pod被删除时能够排除请求,则不一定需要使用就绪探针;在删除Pod时,Pod会自动将自身置于未完成状态,无论就绪探针是否存在。当等待Pod中的容器停止时,Pod仍处于未完成状态。
容器的重启策略
PodSpec中有一个restartPolicy字段,可能的值为Always、OnFailure和Never。默认为Always。restartPolicy适用于Pod中的所有容器。而且它仅用于控制在同一节点上重新启动Pod对象的相关容器。首次需要重启的容器,将在其需要时立即进行重启,随后再次需要重启的操作将由kubelet延迟一段时间后进行,且反复的重启操作的延迟时长依次为10秒、20秒、40秒... 300秒是最大延迟时长。事实上,一旦绑定到一个节点,Pod对象将永远不会被重新绑定到另一个节点,它要么被重启,要么终止,直到节点发生故障或被删除。
Always:但凡Pod对象终止就将其重启,默认值
OnFailure:仅在Pod对象出现错误时方才将其重启
Never:从不重启
Pod存活性探测示例
设置exec探针示例
[root@k8s-master ~]# vim manfests/liveness-exec.yaml
apiVersion: v1
kind: Pod
metadata:
name: liveness-exec-pod
namespace: default
labels:
test: liveness-exec
spec:
containers:
- name: liveness-exec-container
image: busybox:latest
imagePullPolicy: IfNotPresent
command: ["/bin/sh","-c","touch /tmp/healthy; sleep 30; rm -f /tmp/healthy; sleep 3600"]
livenessProbe:
exec:
command: ["test","-e","/tmp/healthy"]
initialDelaySeconds: 1
periodSeconds: 3
[root@k8s-master ~]# kubectl create -f manfests/liveness-exec.yaml #创建pod
pod/liveness-exec-pod created
[root@k8s-master ~]# kubectl get pods #查看pod
NAME READY STATUS RESTARTS AGE
liveness-exec-pod 1/1 Running 0 6s
#等待一段时间后再次查看其状态
[root@k8s-master ~]# kubectl get pods
NAME READY STATUS RESTARTS AGE
liveness-exec-pod 1/1 Running 2 2m46s
上面的资源清单中定义了一个pod对象,基于busybox镜像启动一个运行“touch /tmp/healthy; sleep 30; rm -rf /tmp/healthy; sleep 3600"命令的容器,此命令在容器启动时创建了/tmp/healthy文件,并于60秒之后将其删除。存活性探针运行”test -e /tmp/healthy"命令检查/tmp/healthy文件的存在性,若文件存在则返回状态码0,表示成功通过测试。在60秒内使用“kubectl describe pods/liveness-exec-pod”查看其详细信息,其存活性探测不会出现错误。而超过60秒之后,再执行该命令查看详细信息,可以发现存活性探测出现了故障,并且还可通过“kubectl get pods"查看该pod的重启的相关信息。
设置HTTP探针示例
基于HTTP的探测(HTTPGetAction)向目标容器发起一个HTTP请求,根据其响应码进行结果判定,响应码如2xx或3xx时表示测试通过。通过该命令”# kubectl explain pod.spec.containers.livenessProbe.httpGet“查看httpGet定义的字段
host <string>:请求的主机地址,默认为Pod IP,也可以在httpHeaders中使用“Host:”来定义。
httpHeaders <[]Object>:自定义的请求报文首部。
port <string>:请求的端口,必选字段。
path <string>:请求的HTTP资源路径,即URL path。
scheme <string>:建立连接使用的协议,仅可为HTTP或HTTPS,默认为HTTP。
[root@k8s-master ~]# vim manfests/liveness-httpget.yaml
apiVersion: v1
kind: Pod
metadata:
name: liveness-http
namespace: default
labels:
test: liveness
spec:
containers:
- name: liveness-http-demo
image: nginx:1.12
imagePullPolicy: IfNotPresent
ports:
- name: http
containerPort: 80
lifecycle:
postStart:
exec:
command: ["/bin/sh", "-c", "echo Healthz > /usr/share/nginx/html/healthz"]
livenessProbe:
httpGet:
path: /healthz
port: http
scheme: HTTP
[root@k8s-master ~]# kubectl create -f manfests/liveness-httpget.yaml #创建pod
pod/liveness-http created
[root@k8s-master ~]# kubectl get pods #查看pod
NAME READY STATUS RESTARTS AGE
liveness-http 1/1 Running 0 7s
[root@k8s-master ~]# kubectl describe pods/liveness-http #查看liveness-http详细信息
......
Containers:
liveness-http-demo:
......
Port: 80/TCP
Host Port: 0/TCP
State: Running
Started: Mon, 09 Sep 2019 15:43:29 +0800
Ready: True
Restart Count: 0
......
上面清单中定义的httpGet测试中,通过lifecycle中的postStart hook创建了一个专用于httpGet测试的页面文件healthz,请求的资源路径为"/healthz",地址默认为Pod IP,端口使用了容器中顶一个端口名称http,这也是明确了为容器指明要暴露的端口的用途之一。并查看健康状态检测相关的信息,健康状态检测正常时,容器也将正常运行。下面通过“kubectl exec”命令进入容器删除由postStart hook创建的测试页面healthz。再次查看容器状态
[root@k8s-master ~]# kubectl exec pods/liveness-http -it -- /bin/sh #进入到上面创建的pod中
# rm -rf /usr/share/nginx/html/healthz #删除healthz测试页面
#
[root@k8s-master ~]# kubectl get pods
NAME READY STATUS RESTARTS AGE
liveness-http 1/1 Running 1 10m
[root@k8s-master ~]# kubectl describe pods/liveness-http
......
Containers:
liveness-http-demo:
......
Port: 80/TCP
Host Port: 0/TCP
State: Running
Started: Mon, 09 Sep 2019 15:53:04 +0800
Last State: Terminated
Reason: Completed
Exit Code: 0
Started: Mon, 09 Sep 2019 15:43:29 +0800
Finished: Mon, 09 Sep 2019 15:53:03 +0800
Ready: True
Restart Count: 1
......
通过上面测试可以看出,当发起http请求失败后,容器将被杀掉后进行了重新构建。
设置TCP探针
基于TCP的存活性探测(TCPSocketAction)用于向容器的特定端口发起TCP请求并建立连接进行结果判定,连接建立成功即为通过检测。相比较来说,它比基于HTTP的探测要更高效、更节约资源,但精确度略低,毕竟连接建立成功未必意味着页面资源可用。通过该命令”# kubectl explain pod.spec.containers.livenessProbe.tcpSocket“查看tcpSocket定义的字段
host <string>:请求连接的目标IP地址,默认为Pod IP
port <string>:请求连接的目标端口,必选字段
[root@k8s-master ~]# vim manfests/liveness-tcp.yaml
apiVersion: v1
kind: Pod
metadata:
name: liveness-tcp-pod
namespace: default
labels:
test: liveness-tcp
spec:
containers:
- name: liveness-tcp-demo
image: nginx:1.12
imagePullPolicy: IfNotPresent
ports:
- name: http
containerPort: 80
livenessProbe:
tcpSocket:
port: http
上面清单中定义的tcpSocket测试中,通过向容器的80端口发起请求,如果端口正常,则表明正常运行。
livenessProbe行为属性
[root@k8s-master ~]# kubectl explain pods.spec.containers.livenessProbe
KIND: Pod
VERSION: v1
RESOURCE: livenessProbe <Object>
exec command 的方式探测,例如 ps 一个进程是否存在
failureThreshold 探测几次失败 才算失败, 默认是连续三次
initialDelaySeconds 初始化延迟探测,即容器启动多久之后再开始探测,默认为0秒
periodSeconds 每隔多久探测一次,默认是10秒
successThreshold 处于失败状态时,探测操作至少连续多少次的成功才算通过检测,默认为1秒
timeoutSeconds 存活性探测的超时时长,默认为1秒
httpGet http请求探测
tcpSocket 端口探测
Pod就绪性探测示例
Pod对象启动后,容器应用通常需要一段时间才能完成其初始化过程,例如加载配置或数据,甚至有些程序需要运行某类的预热过程,若在这个阶段完成之前即接入客户端的请求,势必会等待太久。因此,这时候就用到了就绪性探测(readinessProbe)。
与存活性探测机制类似,就绪性探测是用来判断容器就绪与否的周期性(默认周期为10秒钟)操作,它用于探测容器是否已经初始化完成并可服务于客户端请求,探测操作返回”success“状态时,即为传递容器已经”就绪“的信号。
就绪性探测也支持Exec、HTTPGet和TCPSocket三种探测方式,且各自的定义机制也都相同。但与存活性探测触发的操作不同的是,探测失败时,就绪探测不会杀死或重启容器以保证其健康性,而是通知其尚未就绪,并触发依赖于其就绪状态的操作(例如,从Service对象中移除此Pod对象)以确保不会有客户端请求接入此Pod对象。
这里只是示例http探针示例,不论是httpGet还是exec还是tcpSocket和存活性探针类似。
设置HTTP探针示例
#终端1:
[root@k8s-master ~]# vim manfests/readiness-httpget.yaml #编辑readiness-httpget测试pod的yaml文件
apiVersion: v1
kind: Pod
metadata:
name: readiness-http
namespace: default
labels:
test: readiness-http
spec:
containers:
- name: readiness-http-demo
image: nginx:1.12
imagePullPolicy: IfNotPresent
ports:
- name: http
containerPort: 80
readinessProbe:
httpGet:
path: /index.html
port: http
scheme: HTTP
[root@k8s-master ~]# kubectl create -f manfests/readiness-httpget.yaml #创建pod
pod/readiness-http created
[root@k8s-master ~]# kubectl get pods 查看pod状态
NAME READY STATUS RESTARTS AGE
liveness-tcp-pod 1/1 Running 1 7d18h
readiness-http 1/1 Running 0 7s
#新打开一个终端2进入到容器里面
[root@k8s-master ~]# kubectl exec pods/readiness-http -it -- /bin/sh #进入上面创建的pod
# rm -f /usr/share/nginx/html/index.html #删除nginx的主页面文件
# ls /usr/share/nginx/html
50x.html
#
#回到终端1上面查看pod状态
[root@k8s-master ~]# kubectl get pods #查看pod状态
NAME READY STATUS RESTARTS AGE
liveness-tcp-pod 1/1 Running 1 7d18h
readiness-http 0/1 Running 0 2m44s
通过上面测试可以看出,当我们删除了nginx主页文件后,readinessProbe发起的测试就会失败,此时我们再查看pod的状态会发现并不会将pod删除重新启动,只是在READY字段可以看出,当前的Pod处于未就绪状态。
----------------------------------------------------------------------------------------------------
控制器的必要性
自主式Pod对象由调度器调度到目标工作节点后即由相应节点上的kubelet负责监控其容器的存活状态,容器主进程崩溃后,kubelet能够自动重启相应的容器。但对出现非主进程崩溃类的容器错误却无从感知,这便依赖于pod资源对象定义的存活探测,以便kubelet能够探知到此类故障。但若pod被删除或者工作节点自身发生故障(工作节点上都有kubelet,kubelet不可用,因此其健康状态便无法保证),则便需要控制器来处理相应的容器重启和配置。
常见的工作负载控制器
Pod控制器由master的kube-controller-manager组件提供,常见的此类控制器有:
ReplicationController
ReplicaSet:代用户创建指定数量的pod副本数量,确保pod副本数量符合预期状态,并且支持滚动式自动扩容和缩容功能
Deployment:工作在ReplicaSet之上,用于管理无状态应用,目前来说最好的控制器。支持滚动更新和回滚功能,还提供声明式配置。
DaemonSet:用于确保集群中的每一个节点只运行特定的pod副本,常用于实现系统级**后台任务。比如ELK服务
StatefulSet:管理有状态应用
Job:只要完成就立即退出,不需要重启或重建
CronJob:周期性任务控制,不需要持续后台运行
Pod控制器概述
Kubernetes的核心功能之一还在于要确保各资源对象的当前状态(status)以匹配用户期望的状态(spec),使当前状态不断地向期望状态“和解”(reconciliation)来完成容器应用管理。而这些则是kube-controller-manager的任务。
创建为具体的控制器对象之后,每个控制器均通过API Server提供的接口持续监控相关资源对象的当前状态,并在因故障、更新或其他原因导致系统状态发生变化时,尝试让资源的当前状态想期望状态迁移和逼近。
List-Watch是kubernetes实现的核心机制之一,在资源对象的状态发生变动时,由API Server负责写入etcd并通过水平触发(level-triggered)机制主动通知给相关的客户端程序以确保其不会错过任何一个事件。控制器通过API Server的watch接口实时监控目标资源对象的变动并执行和解操作,但并不会与其他控制器进行任何交互。
Pod和Pod控制器
Pod控制器资源通过持续性地监控集群中运行着的Pod资源对象来确保受其管控的资源严格符合用户期望的状态,例如资源副本的数量要精确符合期望等。通常,一个Pod控制器资源至少应该包含三个基本的组成部分:
标签选择器:匹配并关联Pod资源对象,并据此完成受其管控的Pod资源计数。
期望的副本数:期望在集群中精确运行着的Pod资源的对象数量。
Pod模板:用于新建Pod资源对象的Pod模板资源。
ReplicaSet控制器
ReplicaSet概述
ReplicaSet是取代早期版本中的ReplicationController控制器,其功能基本上与ReplicationController相同
ReplicaSet(简称RS)是Pod控制器类型的一种实现,用于确保由其管控的Pod对象副本数在任意时刻都能精确满足期望的数量。ReplicaSet控制器资源启动后会查找集群中匹配器标签选择器的Pod资源对象,当前活动对象的数量与期望的数量不吻合时,多则删除,少则通过Pod模板创建以补足。
ReplicaSet能够实现以下功能:
确保Pod资源对象的数量精确反映期望值:ReplicaSet需要确保由其控制运行的Pod副本数量精确吻合配置中定义的期望值,否则就会自动补足所缺或终止所余。
确保Pod健康运行:探测到由其管控的Pod对象因其所在的工作节点故障而不可用时,自动请求由调度器于其他工作节点创建缺失的Pod副本。
弹性伸缩:可通过ReplicaSet控制器动态扩容或者缩容Pod资源对象的数量。必要时还可以通过HPA控制器实现Pod资源规模的自动伸缩。
创建ReplicaSet
核心字段
spec字段一般嵌套使用以下几个属性字段:
replicas <integer>:指定期望的Pod对象副本数量
selector <Object>:当前控制器匹配Pod对象副本的标签选择器,支持matchLabels和matchExpressions两种匹配机制
template <Object>:用于定义Pod时的Pod资源信息
minReadySeconds <integer>:用于定义Pod启动后多长时间为可用状态,默认为0秒
ReplicaSet示例
#(1)命令行查看ReplicaSet清单定义规则
[root@k8s-master ~]# kubectl explain rs
[root@k8s-master ~]# kubectl explain rs.spec
[root@k8s-master ~]# kubectl explain rs.spec.template
#(2)创建ReplicaSet示例
[root@k8s-master ~]# vim manfests/rs-demo.yaml
apiVersion: apps/v1 #api版本定义
kind: ReplicaSet #定义资源类型为ReplicaSet
metadata: #元数据定义
name: myapp
namespace: default
spec: #ReplicaSet的规格定义
replicas: 2 #定义副本数量为2个
selector: #标签选择器,定义匹配Pod的标签
matchLabels:
app: myapp
release: canary
template: #Pod的模板定义
metadata: #Pod的元数据定义
name: myapp-pod #自定义Pod的名称
labels: #定义Pod的标签,需要和上面的标签选择器内匹配规则中定义的标签一致,可以多出其他标签
app: myapp
release: canary
spec: #Pod的规格定义
containers: #容器定义
- name: myapp-containers #容器名称
image: ikubernetes/myapp:v1 #容器镜像
imagePullPolicy: IfNotPresent #拉取镜像的规则
ports: #暴露端口
- name: http #端口名称
containerPort: 80
#(3)创建ReplicaSet定义的Pod
[root@k8s-master ~]# kubectl apply -f manfests/rs-demo.yaml
replicaset.apps/myapp created
[root@k8s-master ~]# kubectl get rs #查看创建的ReplicaSet控制器
NAME DESIRED CURRENT READY AGE
myapp 4 4 4 3m23s
[root@k8s-master ~]# kubectl get pods #通过查看pod可以看出pod命令是规则是前面是replicaset控制器的名称加随机生成的字符串
NAME READY STATUS RESTARTS AGE
myapp-bln4v 1/1 Running 0 6s
myapp-bxpzt 1/1 Running 0 6s
#(4)修改Pod的副本数量
[root@k8s-master ~]# kubectl edit rs myapp
replicas: 4
[root@k8s-master ~]# kubectl get rs -o wide
NAME DESIRED CURRENT READY AGE CONTAINERS IMAGES SELECTOR
myapp 4 4 4 2m50s myapp-containers ikubernetes/myapp:v2 app=myapp,release=canary
[root@k8s-master ~]# kubectl get pods --show-labels
NAME READY STATUS RESTARTS AGE LABELS
myapp-8hkcr 1/1 Running 0 2m2s app=myapp,release=canary
myapp-bln4v 1/1 Running 0 3m40s app=myapp,release=canary
myapp-bxpzt 1/1 Running 0 3m40s app=myapp,release=canary
myapp-ql2wk 1/1 Running 0 2m2s app=myapp,release=canary
更新ReplicaSet控制器
修改Pod模板:升级应用
修改上面创建的replicaset示例文件,将镜像ikubernetes/myapp:v1改为v2版本
[root@k8s-master ~]# vim manfests/rs-demo.yaml
spec: #Pod的规格定义
containers: #容器定义
- name: myapp-containers #容器名称
image: ikubernetes/myapp:v2 #容器镜像
imagePullPolicy: IfNotPresent #拉取镜像的规则
ports: #暴露端口
- name: http #端口名称
containerPort: 80
[root@k8s-master ~]# kubectl apply -f manfests/rs-demo.yaml #执行apply让其重载
[root@k8s-master ~]# kubectl get pods -o custom-columns=Name:metadata.name,Image:spec.containers[0].image
Name Image
myapp-bln4v ikubernetes/myapp:v1
myapp-bxpzt ikubernetes/myapp:v1
#说明:这里虽然重载了,但是已有的pod所使用的镜像仍然是v1版本的,只是新建pod时才会使用v2版本,这里测试先手动删除已有的pod。
[root@k8s-master ~]# kubectl delete pods -l app=myapp #删除标签app=myapp的pod资源
pod "myapp-bln4v" deleted
pod "myapp-bxpzt" deleted
[root@k8s-master ~]# kubectl get pods -o custom-columns=Name:metadata.name,Image:spec.containers[0].image #再次查看通过ReplicaSet新建的pod资源对象。镜像已使用v2版本
Name Image
myapp-mdn8j ikubernetes/myapp:v2
myapp-v5bgr ikubernetes/myapp:v2
扩容和缩容
可以直接通过vim 编辑清单文件修改replicas字段,也可以通过kubect edit 命令去编辑。kubectl还提供了一个专用的子命令scale用于实现应用规模的伸缩,支持从资源清单文件中获取新的目标副本数量,也可以直接在命令行通过“--replicas”选项进行读取。
[root@k8s-master ~]# kubectl get rs #查看ReplicaSet
NAME DESIRED CURRENT READY AGE
myapp 2 2 2 154m
[root@k8s-master ~]# kubectl get pods #查看Pod
NAME READY STATUS RESTARTS AGE
myapp-mdn8j 1/1 Running 0 5m26s
myapp-v5bgr 1/1 Running 0 5m26s
#扩容
[root@k8s-master ~]# kubectl scale replicasets myapp --replicas=5 #将上面的Deployments控制器myapp的Pod副本数量提升为5个
replicaset.extensions/myapp scaled
[root@k8s-master ~]# kubectl get rs #查看ReplicaSet
NAME DESIRED CURRENT READY AGE
myapp 5 5 5 156m
[root@k8s-master ~]# kubectl get pods #查看Pod
NAME READY STATUS RESTARTS AGE
myapp-lrrp8 1/1 Running 0 8s
myapp-mbqf8 1/1 Running 0 8s
myapp-mdn8j 1/1 Running 0 6m48s
myapp-ttmf5 1/1 Running 0 8s
myapp-v5bgr 1/1 Running 0 6m48s#收缩
[root@k8s-master ~]# kubectl scale replicasets myapp --replicas=3
replicaset.extensions/myapp scaled
[root@k8s-master ~]# kubectl get rs
NAME DESIRED CURRENT READY AGE
myapp 3 3 3 159m
[root@k8s-master ~]# kubectl get pods
NAME READY STATUS RESTARTS AGE
myapp-mdn8j 1/1 Running 0 10m
myapp-ttmf5 1/1 Running 0 3m48s
myapp-v5bgr 1/1 Running 0 10m
删除ReplicaSet控制器资源
使用Kubectl delete命令删除ReplicaSet对象时默认会一并删除其管控的各Pod对象,有时,考虑到这些Pod资源未必由其创建,或者即便由其创建也并非自身的组成部分,这时候可以添加“--cascade=false”选项,取消级联关系。
[root@k8s-master ~]# kubectl get rs
NAME DESIRED CURRENT READY AGE
myapp 3 3 3 162m
[root@k8s-master ~]# kubectl get pods
NAME READY STATUS RESTARTS AGE
myapp-mdn8j 1/1 Running 0 12m
myapp-ttmf5 1/1 Running 0 6m18s
myapp-v5bgr 1/1 Running 0 12m
[root@k8s-master ~]# kubectl delete replicasets myapp --cascade=false
replicaset.extensions "myapp" deleted
[root@k8s-master ~]# kubectl get rs
No resources found.
[root@k8s-master ~]# kubectl get pods
NAME READY STATUS RESTARTS AGE
myapp-mdn8j 1/1 Running 0 13m
myapp-ttmf5 1/1 Running 0 7m
myapp-v5bgr 1/1 Running 0 13m
#通过上面的示例可以看出,添加--cascade=false参数后再删除ReplicaSet资源对象时并没有将其管控的Pod资源对象一并删除。
Deployment控制器
Deployment概述
Deployment(简写为deploy)是kubernetes控制器的又一种实现,它构建于ReplicaSet控制器之上,可为Pod和ReplicaSet资源提供声明式更新。
Deployment控制器资源的主要职责是为了保证Pod资源的健康运行,其大部分功能均可通过调用ReplicaSet实现,同时还增添部分特性。
事件和状态查看:必要时可以查看Deployment对象升级的详细进度和状态。
回滚:升级操作完成后发现问题时,支持使用回滚机制将应用返回到前一个或由用户指定的历史记录中的版本上。
版本记录:对Deployment对象的每一个操作都予以保存,以供后续可能执行的回滚操作使用。
暂停和启动:对于每一次升级,都能够随时暂停和启动。
多种自动更新方案:一是Recreate,即重建更新机制,全面停止、删除旧有的Pod后用新版本替代;另一个是RollingUpdate,即滚动升级机制,逐步替换旧有的Pod至新的版本。
创建Deployment
Deployment其核心资源和ReplicaSet相似
#(1)命令行查看ReplicaSet清单定义规则
[root@k8s-master ~]# kubectl explain deployment
[root@k8s-master ~]# kubectl explain deployment.spec
[root@k8s-master ~]# kubectl explain deployment.spec.template
#(2)创建Deployment示例
[root@k8s-master ~]# vim manfests/deploy-demo.yaml
apiVersion: apps/v1 #api版本定义
kind: Deployment #定义资源类型为Deploymant
metadata: #元数据定义
name: deploy-demo #deployment控制器名称
namespace: default #名称空间
spec: #deployment控制器的规格定义
replicas: 2 #定义副本数量为2个
selector: #标签选择器,定义匹配Pod的标签
matchLabels:
app: deploy-app
release: canary
template: #Pod的模板定义
metadata: #Pod的元数据定义
labels: #定义Pod的标签,需要和上面的标签选择器内匹配规则中定义的标签一致,可以多出其他标签
app: deploy-app
release: canary
spec: #Pod的规格定义
containers: #容器定义
- name: myapp #容器名称
image: ikubernetes/myapp:v1 #容器镜像
ports: #暴露端口
- name: http #端口名称
containerPort: 80
#(3)创建Deployment对象
[root@k8s-master ~]# kubectl apply -f manfests/deploy-demo.yaml
deployment.apps/deploy-demo created
#(4)查看资源对象
[root@k8s-master ~]# kubectl get deployment #查看Deployment资源对象
NAME READY UP-TO-DATE AVAILABLE AGE
deploy-demo 2/2 2 2 10s
[root@k8s-master ~]# kubectl get replicaset #查看ReplicaSet资源对象
NAME DESIRED CURRENT READY AGE
deploy-demo-78c84d4449 2 2 2 20s
[root@k8s-master ~]# kubectl get pods #查看Pod资源对象
NAME READY STATUS RESTARTS AGE
deploy-demo-78c84d4449-22btc 1/1 Running 0 23s
deploy-demo-78c84d4449-5fn2k 1/1 Running 0 23s
---
说明:
通过查看资源对象可以看出,Deployment会自动创建相关的ReplicaSet控制器资源,并以"[DEPLOYMENT-name]-[POD-TEMPLATE-HASH-VALUE]"格式为其命名,其中的hash值由Deployment自动生成。而Pod名则是以ReplicaSet控制器的名称为前缀,后跟5位随机字符。
更新策略
ReplicaSet控制器的应用更新需要手动分成多步并以特定的次序进行,过程繁杂且容易出错,而Deployment却只需要由用户指定在Pod模板中要改动的内容,(如镜像文件的版本),余下的步骤便会由其自动完成。Pod副本数量也是一样。
Deployment控制器支持两种更新策略:滚动更新(rollingUpdate)和重建创新(Recreate),默认为滚动更新
滚动更新(rollingUpdate):即在删除一部分旧版本Pod资源的同时,补充创建一部分新版本的Pod对象进行应用升级,其优势是升级期间,容器中应用提供的服务不会中断,但更新期间,不同客户端得到的相应内容可能会来自不同版本的应用。
重新创建(Recreate):即首先删除现有的Pod对象,而后由控制器基于新模板重行创建出新版本的资源对象。
Deployment控制器的滚动更新操作并非在同一个ReplicaSet控制器对象下删除并创建Pod资源,新控制器的Pod对象数量不断增加,直到旧控制器不再拥有Pod对象,而新控制器的副本数量变得完全符合期望值为止。如图所示
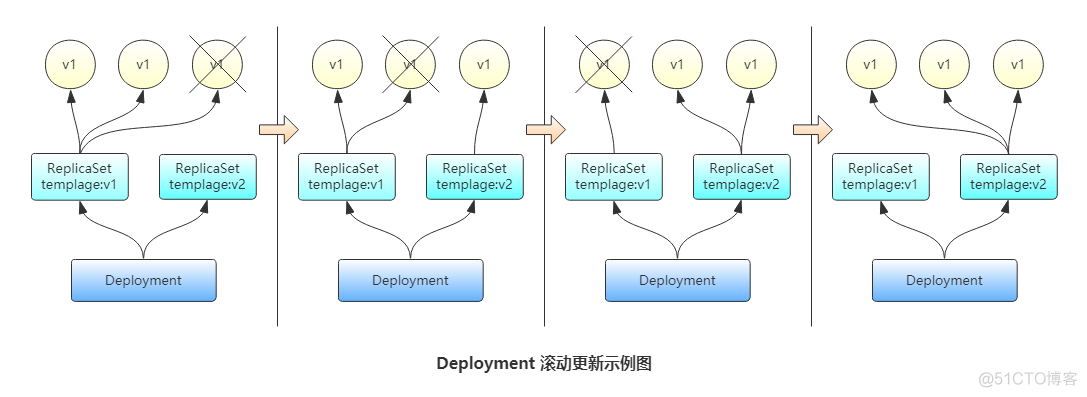
滚动更新时,应用还要确保可用的Pod对象数量不低于某阀值以确保可以持续处理客户端的服务请求,变动的方式和Pod对象的数量范围将通过kubectl explain deployment.spec.strategy.rollingUpdate.maxSurge和kubectl explain deployment.spec.strategy.rollingUpdate.maxUnavailable两个属性同时进行定义。其功能如下:
maxSurge:指定升级期间存在的总Pod对象数量最多可超出期望值的个数,其值可以是0或正整数,也可以是一个期望值的百分比;例如,如果期望值为3,当前的属性值为1,则表示Pod对象的总数不能超过4个。
maxUnavailable:升级期间正常可用的Pod副本数(包括新旧版本)最多不能低于期望值的个数,其值可以是0或正整数,也可以是期望值的百分比;默认值为1,该值意味着如果期望值是3,则升级期间至少要有两个Pod对象处于正常提供服务的状态。
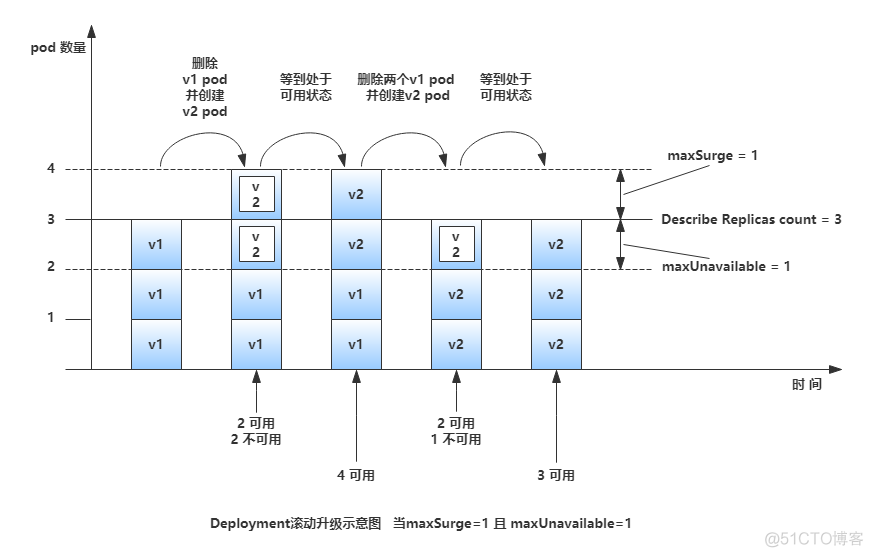
maxSurge和maxUnavailable属性的值不可同时为0,否则Pod对象的副本数量在符合用户期望的数量后无法做出合理变动以进行滚动更新操作。
Deployment控制器可以保留其更新历史中的旧ReplicaSet对象版本,所保存的历史版本数量由kubectl explain deployment.spec.revisionHistoryLimit参数指定。只有保存于revision历史中的ReplicaSet版本可用于回滚。
注:为了保存版本升级的历史,需要在创建Deployment对象时于命令中使用“--record”选项。
Deployment更新升级
修改Pod模板相关的配置参数便能完成Deployment控制器资源的更新。由于是声明式配置,因此对Deployment控制器资源的修改尤其适合使用apply和patch命令来进行;如果仅只是修改容器镜像,“set image”命令更为易用。
1)首先通过set image命令将上面创建的Deployment对象的镜像版本改为v2版本
#打开1个终端进行升级
[root@k8s-master ~]# kubectl set image deployment/deploy-demo myapp=ikubernetes/myapp:v2
deployment.extensions/deploy-demo image updated
#同时打开终端2进行查看pod资源对象升级过程
[root@k8s-master ~]# kubectl get pods -l app=deploy-app -w
NAME READY STATUS RESTARTS AGE
deploy-demo-78c84d4449-2rvxr 1/1 Running 0 33s
deploy-demo-78c84d4449-nd7rr 1/1 Running 0 33s
deploy-demo-7c66dbf45b-7k4xz 0/1 Pending 0 0s
deploy-demo-7c66dbf45b-7k4xz 0/1 Pending 0 0s
deploy-demo-7c66dbf45b-7k4xz 0/1 ContainerCreating 0 0s
deploy-demo-7c66dbf45b-7k4xz 1/1 Running 0 2s
deploy-demo-78c84d4449-2rvxr 1/1 Terminating 0 49s
deploy-demo-7c66dbf45b-r88qr 0/1 Pending 0 0s
deploy-demo-7c66dbf45b-r88qr 0/1 Pending 0 0s
deploy-demo-7c66dbf45b-r88qr 0/1 ContainerCreating 0 0s
deploy-demo-7c66dbf45b-r88qr 1/1 Running 0 1s
deploy-demo-78c84d4449-2rvxr 0/1 Terminating 0 50s
deploy-demo-78c84d4449-nd7rr 1/1 Terminating 0 51s
deploy-demo-78c84d4449-nd7rr 0/1 Terminating 0 51s
deploy-demo-78c84d4449-nd7rr 0/1 Terminating 0 57s
deploy-demo-78c84d4449-nd7rr 0/1 Terminating 0 57s
deploy-demo-78c84d4449-2rvxr 0/1 Terminating 0 60s
deploy-demo-78c84d4449-2rvxr 0/1 Terminating 0 60s
#同时打开终端3进行查看pod资源对象变更过程
[root@k8s-master ~]# kubectl get deployment deploy-demo -w
NAME READY UP-TO-DATE AVAILABLE AGE
deploy-demo 2/2 2 2 37s
deploy-demo 2/2 2 2 47s
deploy-demo 2/2 2 2 47s
deploy-demo 2/2 0 2 47s
deploy-demo 2/2 1 2 47s
deploy-demo 3/2 1 3 49s
deploy-demo 2/2 1 2 49s
deploy-demo 2/2 2 2 49s
deploy-demo 3/2 2 3 50s
deploy-demo 2/2 2 2 51s
# 升级完成再次查看rs的情况,以下可以看到原的rs作为备份,而现在启动的是新的rs
[root@k8s-master ~]# kubectl get rs
NAME DESIRED CURRENT READY AGE
deploy-demo-78c84d4449 0 0 0 4m41s
deploy-demo-7c66dbf45b 2 2 2 3m54s
2)Deployment扩容
#1、使用kubectl scale命令扩容
[root@k8s-master ~]# kubectl scale deployment deploy-demo --replicas=3
deployment.extensions/deploy-demo scaled
[root@k8s-master ~]# kubectl get pods
NAME READY STATUS RESTARTS AGE
deploy-demo-7c66dbf45b-7k4xz 1/1 Running 0 10m
deploy-demo-7c66dbf45b-gq2tw 1/1 Running 0 3s
deploy-demo-7c66dbf45b-r88qr 1/1 Running 0 10m
#2、使用直接修改配置清单方式进行扩容
[root@k8s-master ~]# vim manfests/deploy-demo.yaml
spec: #deployment控制器的规格定义
replicas: 4 #定义副本数量为2个
[root@k8s-master ~]# kubectl apply -f manfests/deploy-demo.yaml
deployment.apps/deploy-demo configured
[root@k8s-master ~]# kubectl get pods
NAME READY STATUS RESTARTS AGE
deploy-demo-78c84d4449-6rmnm 1/1 Running 0 61s
deploy-demo-78c84d4449-9xfp9 1/1 Running 0 58s
deploy-demo-78c84d4449-c2m6h 1/1 Running 0 61s
deploy-demo-78c84d4449-sfxps 1/1 Running 0 57s
#3、使用kubectl patch打补丁的方式进行扩容
[root@k8s-master ~]# kubectl patch deployment deploy-demo -p '{"spec":{"replicas":5}}'
deployment.extensions/deploy-demo patched
[root@k8s-master ~]#
[root@k8s-master ~]# kubectl get pods
NAME READY STATUS RESTARTS AGE
deploy-demo-78c84d4449-6rmnm 1/1 Running 0 3m44s
deploy-demo-78c84d4449-9xfp9 1/1 Running 0 3m41s
deploy-demo-78c84d4449-c2m6h 1/1 Running 0 3m44s
deploy-demo-78c84d4449-sfxps 1/1 Running 0 3m40s
deploy-demo-78c84d4449-t7jxb 1/1 Running 0 3s
金丝雀发布
采用先添加再删除的方式,且可用Pod资源对象总数不低于期望值的方式进行,配置如下:
1)添加其总数多余期望值一个
[root@k8s-master ~]# kubectl patch deployment deploy-demo -p '{"spec":{"strategy":{"rollingUpdate":{"maxSurge":1,"maxUnavailable":0}}}}'
deployment.extensions/deploy-demo patched
1.
2.
2)启动更新过程,在修改相应容器的镜像版本后立即暂停更新进度。
[root@k8s-master ~]# kubectl set image deployment/deploy-demo myapp=ikubernetes/myapp:v3 && kubectl rollout pause deployment deploy-demo
deployment.extensions/deploy-demo image updated
deployment.extensions/deploy-demo paused
#查看
[root@k8s-master ~]# kubectl get deployment #查看deployment资源对象
NAME READY UP-TO-DATE AVAILABLE AGE
deploy-demo 6/5 1 6 37m
[root@k8s-master ~]# kubectl get pods -o custom-columns=Name:metadata.name,Image:spec.containers[0].image #查看pod资源对象的name和image
Name Image
deploy-demo-6bf8dbdc9f-fjnzn ikubernetes/myapp:v3
deploy-demo-78c84d4449-6rmnm ikubernetes/myapp:v1
deploy-demo-78c84d4449-9xfp9 ikubernetes/myapp:v1
deploy-demo-78c84d4449-c2m6h ikubernetes/myapp:v1
deploy-demo-78c84d4449-sfxps ikubernetes/myapp:v1
deploy-demo-78c84d4449-t7jxb ikubernetes/myapp:v1
[root@k8s-master ~]# kubectl rollout status deployment/deploy-demo #查看更新情况
Waiting for deployment "deploy-demo" rollout to finish: 1 out of 5 new replicas have been updated...
---
#通过上面查看可以看出,当前的pod数量为6个,因为此前我们定义的期望值为5个,这里多出了一个,且这个镜像版本为v3版本。
#全部更新
[root@k8s-master ~]# kubectl rollout resume deployment deploy-demo
deployment.extensions/deploy-demo resumed
#再次查看
[root@k8s-master ~]# kubectl get deployment #查看deployment资源对象
NAME READY UP-TO-DATE AVAILABLE AGE
deploy-demo 5/5 5 5 43m
[root@k8s-master ~]# kubectl get pods -o custom-columns=Name:metadata.name,Image:spec.containers[0].image #查看pod资源对象的name和image
Name Image
deploy-demo-6bf8dbdc9f-2z6gt ikubernetes/myapp:v3
deploy-demo-6bf8dbdc9f-f79q2 ikubernetes/myapp:v3
deploy-demo-6bf8dbdc9f-fjnzn ikubernetes/myapp:v3
deploy-demo-6bf8dbdc9f-pjf4z ikubernetes/myapp:v3
deploy-demo-6bf8dbdc9f-x7fnk ikubernetes/myapp:v3
[root@k8s-master ~]# kubectl rollout status deployment/deploy-demo #查看更新情况
Waiting for deployment "deploy-demo" rollout to finish: 1 out of 5 new replicas have been updated...
Waiting for deployment "deploy-demo" rollout to finish: 1 out of 5 new replicas have been updated...
Waiting for deployment spec update to be observed...
Waiting for deployment spec update to be observed...
Waiting for deployment "deploy-demo" rollout to finish: 1 out of 5 new replicas have been updated...
Waiting for deployment "deploy-demo" rollout to finish: 1 out of 5 new replicas have been updated...
Waiting for deployment "deploy-demo" rollout to finish: 2 out of 5 new replicas have been updated...
Waiting for deployment "deploy-demo" rollout to finish: 2 out of 5 new replicas have been updated...
Waiting for deployment "deploy-demo" rollout to finish: 2 out of 5 new replicas have been updated...
Waiting for deployment "deploy-demo" rollout to finish: 3 out of 5 new replicas have been updated...
Waiting for deployment "deploy-demo" rollout to finish: 3 out of 5 new replicas have been updated...
Waiting for deployment "deploy-demo" rollout to finish: 3 out of 5 new replicas have been updated...
Waiting for deployment "deploy-demo" rollout to finish: 4 out of 5 new replicas have been updated...
Waiting for deployment "deploy-demo" rollout to finish: 4 out of 5 new replicas have been updated...
Waiting for deployment "deploy-demo" rollout to finish: 4 out of 5 new replicas have been updated...
Waiting for deployment "deploy-demo" rollout to finish: 1 old replicas are pending termination...
Waiting for deployment "deploy-demo" rollout to finish: 1 old replicas are pending termination...
deployment "deploy-demo" successfully rolled out
回滚Deployment控制器下的应用发布
若因各种原因导致滚动更新无法正常进行,如镜像文件获取失败,等等;则应该将应用回滚到之前的版本,或者回滚到指定的历史记录中的版本。则通过kubectl rollout undo命令完成。如果回滚到指定版本则需要添加--to-revision选项
1)回到上一个版本
[root@k8s-master ~]# kubectl rollout undo deployment/deploy-demo
deployment.extensions/deploy-demo rolled back
[root@k8s-master ~]# kubectl get pods -o custom-columns=Name:metadata.name,Image:spec.containers[0].image
Name Image
deploy-demo-78c84d4449-2xspz ikubernetes/myapp:v1
deploy-demo-78c84d4449-f8p46 ikubernetes/myapp:v1
deploy-demo-78c84d4449-mnmvc ikubernetes/myapp:v1
deploy-demo-78c84d4449-tsl7r ikubernetes/myapp:v1
deploy-demo-78c84d4449-xdt8j ikubernetes/myapp:v1
2)回滚到指定版本
#通过该命令查看更新历史记录
[root@k8s-master ~]# kubectl rollout history deployment/deploy-demo
deployment.extensions/deploy-demo
REVISION CHANGE-CAUSE
2 <none>
4 <none>
5 <none>
#回滚到版本2
[root@k8s-master ~]# kubectl rollout undo deployment/deploy-demo --to-revision=2
deployment.extensions/deploy-demo rolled back
[root@k8s-master ~]# kubectl get pods -o custom-columns=Name:metadata.name,Image:spec.containers[0].image
Name Image
deploy-demo-7c66dbf45b-42nj4 ikubernetes/myapp:v2
deploy-demo-7c66dbf45b-8zhf5 ikubernetes/myapp:v2
deploy-demo-7c66dbf45b-bxw7x ikubernetes/myapp:v2
deploy-demo-7c66dbf45b-gmq8x ikubernetes/myapp:v2
deploy-demo-7c66dbf45b-mrfdb ikubernetes/myapp:v2
DaemonSet控制器
DaemonSet概述
DaemonSet用于在集群中的全部节点上同时运行一份指定Pod资源副本,后续新加入集群的工作节点也会自动创建一个相关的Pod对象,当从集群移除借点时,此类Pod对象也将被自动回收而无需重建。管理员也可以使用节点选择器及节点标签指定仅在具有特定特征的节点上运行指定的Pod对象。
应用场景
运行集群存储的守护进程,如在各个节点上运行glusterd或ceph。
在各个节点上运行日志收集守护进程,如fluentd和logstash。
在各个节点上运行监控系统的代理守护进程,如Prometheus Node Exporter、collectd、Datadog agent、New Relic agent和Ganglia gmond等。
创建DaemonSet
DaemonSet控制器的spec字段中嵌套使用的相同字段selector、template和minReadySeconds,并且功能和用法基本相同,但它不支持replicas,因为毕竟不能通过期望值来确定Pod资源的数量,而是基于节点数量。
这里使用nginx来示例,生产环境就比如使用上面提到的logstash等。
#(1) 定义清单文件
[root@k8s-master ~]# vim manfests/daemonset-demo.yaml
apiVersion: apps/v1 #api版本定义
kind: DaemonSet #定义资源类型为DaemonSet
metadata: #元数据定义
name: daemset-nginx #daemonset控制器名称
namespace: default #名称空间
labels: #设置daemonset的标签
app: daem-nginx
spec: #DaemonSet控制器的规格定义
selector: #指定匹配pod的标签
matchLabels: #指定匹配pod的标签
app: daem-nginx #注意:这里需要和template中定义的标签一样
template: #Pod的模板定义
metadata: #Pod的元数据定义
name: nginx
labels: #定义Pod的标签,需要和上面的标签选择器内匹配规则中定义的标签一致,可以多出其他标签
app: daem-nginx
spec: #Pod的规格定义
containers: #容器定义
- name: nginx-pod #容器名字
image: nginx:1.12 #容器镜像
ports: #暴露端口
- name: http #端口名称
containerPort: 80 #暴露的端口
#(2)创建上面定义的daemonset控制器
[root@k8s-master ~]# kubectl apply -f manfests/daemonset-demo.yaml
daemonset.apps/daemset-nginx created
#(3)查看验证
[root@k8s-master ~]# kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
daemset-nginx-7s474 1/1 Running 0 80s 10.244.1.61 k8s-node1 <none> <none>
daemset-nginx-kxpl2 1/1 Running 0 94s 10.244.2.58 k8s-node2 <none> <none>
[root@k8s-master ~]# kubectl describe daemonset/daemset-nginx
......
Name: daemset-nginx
Selector: app=daem-nginx
Node-Selector: <none>
......
Desired Number of Nodes Scheduled: 2
Current Number of Nodes Scheduled: 2
Number of Nodes Scheduled with Up-to-date Pods: 2
Number of Nodes Scheduled with Available Pods: 2
Number of Nodes Misscheduled: 0
Pods Status: 2 Running / 0 Waiting / 0 Succeeded / 0 Failed
......
通过上面验证查看,Node-Selector字段的值为空,表示它需要运行在集群中的每个节点之上。而当前的节点数是2个,所以其期望的Pod副本数(Desired Number of Nodes Scheduled)为2,而当前也已经创建了2个相关的Pod对象。
注意
对于特殊的硬件的节点来说,可能有的运行程序只需要在某一些节点上运行,那么通过Pod模板的spec字段中嵌套使用nodeSelector字段,并确保其值定义的标签选择器与部分特定工作节点的标签匹配即可。
更新DaemonSet对象
DaemonSet自Kubernetes1.6版本起也开始支持更新机制,相关配置嵌套在kubectl explain daemonset.spec.updateStrategy字段中。其支持RollingUpdate(滚动更新)和OnDelete(删除时更新)两种策略,滚动更新为默认的更新策略。
1.
#(1)查看镜像版本
[root@k8s-master ~]# kubectl get pods -l app=daem-nginx -o custom-columns=NAME:metadata.name,NODE:spec.nodeName,Image:spec.containers[0].image
NAME NODE Image
daemset-nginx-7s474 k8s-node1 nginx:1.12
daemset-nginx-kxpl2 k8s-node2 nginx:1.12
#(2)更新
[root@k8s-master ~]# kubectl set image daemonset/daemset-nginx nginx-pod=nginx:1.14
[root@k8s-master ~]# kubectl get pods -l app=daem-nginx -o custom-columns=NAME:metadata.name,NODE:spec.nodeName,Image:spec.containers[0].image #再次查看
NAME NODE Image
daemset-nginx-74c95 k8s-node2 nginx:1.14
daemset-nginx-nz6n9 k8s-node1 nginx:1.14
#(3)查坎详细信息
[root@k8s-master ~]# kubectl describe daemonset daemset-nginx
......
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal SuccessfulCreate 49m daemonset-controller Created pod: daemset-nginx-6kzg6
Normal SuccessfulCreate 49m daemonset-controller Created pod: daemset-nginx-jjnc2
Normal SuccessfulDelete 40m daemonset-controller Deleted pod: daemset-nginx-jjnc2
Normal SuccessfulCreate 40m daemonset-controller Created pod: daemset-nginx-kxpl2
Normal SuccessfulDelete 40m daemonset-controller Deleted pod: daemset-nginx-6kzg6
Normal SuccessfulCreate 40m daemonset-controller Created pod: daemset-nginx-7s474
Normal SuccessfulDelete 15s daemonset-controller Deleted pod: daemset-nginx-7s474
Normal SuccessfulCreate 8s daemonset-controller Created pod: daemset-nginx-nz6n9
Normal SuccessfulDelete 5s daemonset-controller Deleted pod: daemset-nginx-kxpl2
通过上面查看可以看出,默认的滚动更新策略是一次删除一个工作节点上的Pod资源,待其最新版本Pod重建完成后再开始操作另一个工作节点上的Pod资源。
DaemonSet控制器的滚动更新机制也可以借助于minReadySeconds字段控制滚动节奏;必要时也可以执行暂停和继续操作。其也可以进行回滚操作。
-----------------------------------

 浙公网安备 33010602011771号
浙公网安备 33010602011771号