阿里云-数据库-ClickHouse
https://help.aliyun.com/product/144466.html
云数据库ClickHouse是开源列式数据库管理系统ClickHouse在阿里云上的托管服务,用户可以在阿里云上便捷地购买云资源,搭建自己的ClickHouse集群。
产品架构
云数据库ClickHouse分为社区兼容版和云原生版,在开源版本基础上提升了稳定性、安全性和可运维性。
社区兼容版架构
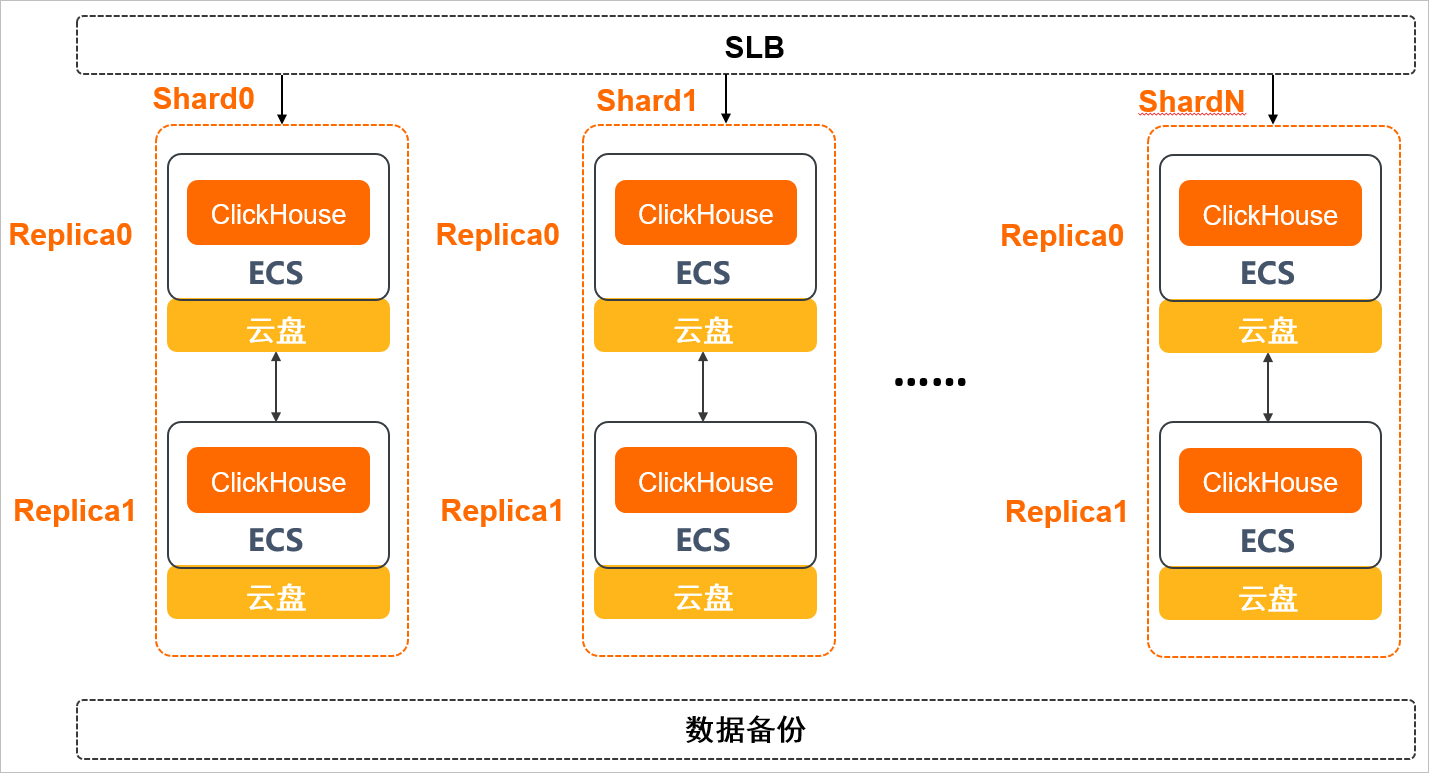
- 节点和节点完全对等,每一个节点都可以承载查询请求和写入请求,以及后台数据的计算和操作。
- 每个云数据库ClickHouse社区兼容版集群包含1个或多个分片(Shard),每个分片内部包含1个或多个副本(Replica)。
- 所有节点都部署在阿里云弹性计算服务器ECS之上,底层采用高可靠的云盘作为持久化存储介质。
云原生版架构
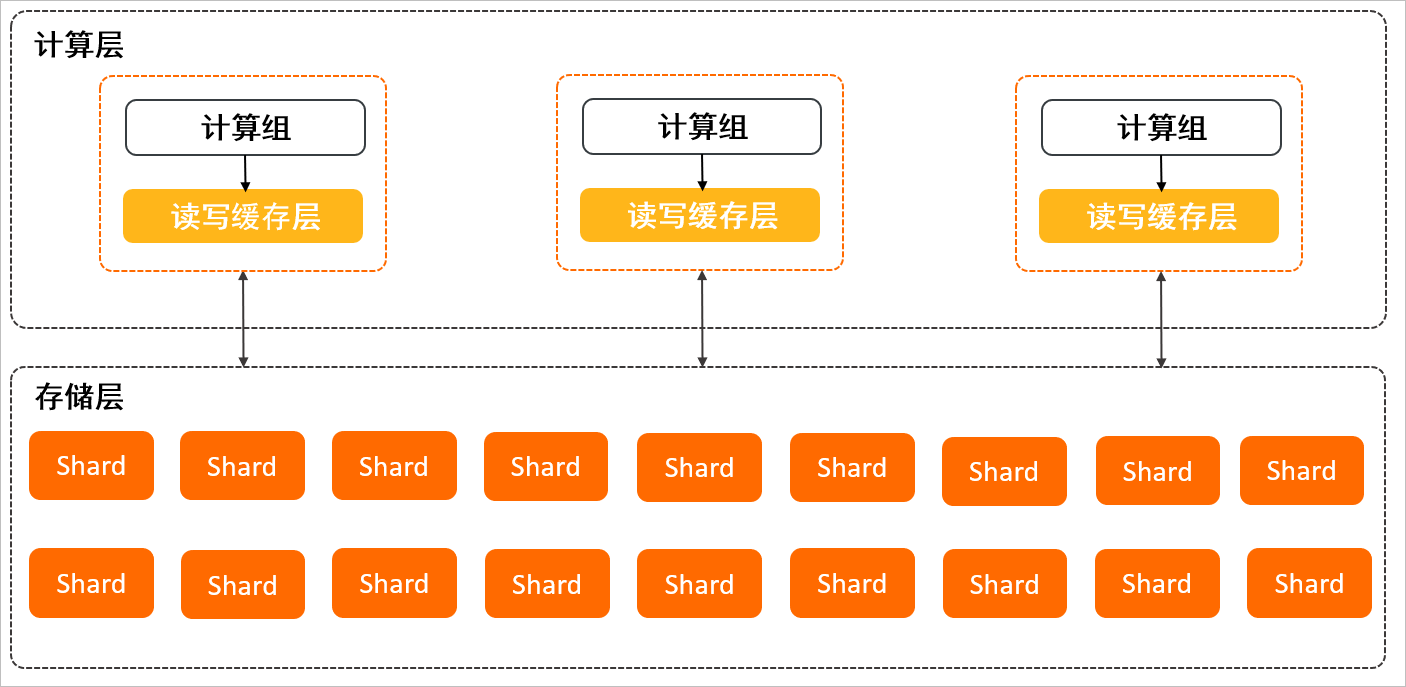
- 计算层包含计算组和读写缓存层,计算组支持变配,读写缓存层用于加速请求处理。
- 存储层解耦计算层,用于数据的持久化存储,数据按照逻辑分片(Shard)分布,根据用户需求按量收费,可以动态调整,不用提前设置存储空间。
云原生版的更多信息,具体请参见ClickHouse云原生版产品解析。
产品特性
云数据库ClickHouse是面向联机分析处理的列式数据库,支持SQL查询,且查询性能好,特别是基于大宽表的聚合分析查询性能非常优异,比其他分析型数据库速度快一个数量级。
- 数据压缩比高。
- 多核并行计算。
- 向量化计算引擎。
- 支持嵌套数据结构。
- 支持稀疏索引。
- 支持数据Insert和Update。
ClickHouse官网地址,请参见https://clickhouse.yandex/。
ClickHouse中文文档链接,请参见https://clickhouse.yandex/docs/zh/。
增强特性
- 增强安全性:增加用户管理、白名单等功能。
- 可视化运维:版本升级、故障切换等。
- 可扩展性:多规格选配、弹性扩容。
- 数据生态:打通云上各个数据源,方便数据同步和迁移。
本文介绍了云数据库ClickHouse的产品优势和特点。
核心能力
| 核心优势 | 描述 |
|---|---|
| 高可靠存储引擎 | 基于阿里飞天分布式系统的云盘存储,充分利用云平台存储可靠性特性。 |
| 扩展性强 | 提供数据库扩容管理模块,能便捷地按需对集群进行扩容,无需手动进行数据搬迁。 |
| 数据闭环流通 | 与云上日志系统、数据库、数据应用工具无缝集成,能便捷地进行数据同步,降低数据迁移工作量。 |
| 专业服务能力 | 阿里云提供专业的数据库专家,给用户提供技术支持和服务。 |
| 特性 | 功能介绍 | 详细描述 |
|---|---|---|
| 架构灵活 | 支持单节点、单副本、多节点、多副本多种架构 |
节点数量:最低支持创建一个节点的集群,也支持创建若干个节点的集群。 动态升降配:支持节点规格升降配,节点数可扩缩容,后台自动进行数据迁移,无需手动搬迁数据 。 副本数量:支持创建单副本集群,也支持创建多副本集群。 |
| 数据安全 | 访问白名单和一键恢复,多层网络安全防护 |
VPC私有网络:实例部署在利用OverLay技术在物理网络基础上构建的专有VPC虚拟网络上,在TCP层直接进行网络隔离保护。 DDoS防护:在网络入口实时监测,当发现超大流量攻击时,对源IP进行清洗,清洗无效情况下可以直接将恶意IP拉进黑洞。 IP白名单配置:支持配置访问IP白名单规则,直接从访问源进行风险控制。 |
| 便捷运维 | 专业监控和数据库管理平台 |
监控平台:提供CPU使用率、IOPS、连接数、磁盘空间等实例信息实时监控及报警,随时随地了解实例动态。 可视化管理平台:管理控制平台对实例重启等操作可便捷的进行一键式操作。 可视化DMS平台:专业的DMS数据管理平台,提供可视化的数据管理、数据查询工作台。 数据库内核版本管理:提供数据库内核版本升级管理操作模块,降低内核版本管理成本。 |
云数据库ClickHouse应用场景介绍。
交互式报表
- 基于ClickHouse和BI工具构建实时运营监控报表
- 利用ClickHouse构建实时交互式报表,实时分析订单、收入、用户数等核心业务指标;构建用户来源分析系统,跟踪各渠道PV、UV来源。
- 海量数据实时多维查询
- 在数亿至数百亿记录规模大宽表,数百以上维度自由查询,响应时间通常在100毫秒以内。让业务人员能持续探索式查询分析,无需中断分析思路,便于深挖业务价值,具有非常好的查询体验。
用户画像分析
随着数据时代的发展,各行各业数据平台的体量越来越大,用户个性化运营的诉求也越来越突出,用户标签系统,做为个性化千人千面运营的基础服务,应运而生。如今,几乎所有行业(如互联网、游戏、教育等)都有实时精准营销的需求。通过系统生成用户画像,在营销时通过条件组合筛选用户,快速提取目标群体。
- 基于ClickHouse构建用户特征行为分析系统
- 利用ClickHouse对人群标签数据进行实时筛选并进行群体画像统计;自定义条件对海量明细日志记录进行过滤,分析用户行为。
- 用户分群统计
- 构建用户特征大宽表,任意选择用户属性标签数据和筛选条件,进行人群特征统计分析。
- 访客来源分析展示
- 通过批量离线计算对用户访问日志中的用户行为进行关联,生成用户行为路径大宽表同步到ClickHouse,基于ClickHoue构建交互式访客来源探索分析可视化系统。
基本概念
地域(Region)
购买云数据库ClickHouse的服务器所处地理位置。您需要在购买云数据库ClickHouse服务时指定Region,Region一旦指定后就不允许更改。
可用区(Zone)
同一地域下,电力、网络隔离的物理区域,可用区之间内网互通,可用区内网络延时更小。
ClickHouse集群(Cluster)
在物理构成上,ClickHouse集群是由多个ClickHouse Server实例组成的分布式数据库。这些ClickHouse Server根据购买规格的不同而可能包含1个或多个副本(Replica)、1个或多个分片(Shard)。在逻辑构成上,一个ClickHouse集群可以包含多个数据库(Database)对象。
副本配置(Edition)
- 双副本版:每个节点包含两个副本,某个副本服务不可用的时候,同一分片的另一个副本还可以继续服务。
- 单副本版:每个节点只有1个副本,该副本服务不可用时,会导致整个集群不可用,需要等待此副本完全恢复服务状态,集群才能继续提供稳定服务。
- 双副本版的资源以及对应的购买成本都是单副本版的2倍。
- 由于底层云盘提供高可靠保证,即便是单副本版也能确保数据不会丢失。
分片(Shard)
在超大规模海量数据处理场景下,单台服务器的存储、计算资源会成为瓶颈。为了进一步提高效率,云数据库ClickHouse将海量数据分散存储到多台服务器上,每台服务器只存储和处理海量数据的一部分,在这种架构下,每台服务器被称为一个分片(Shard)。
副本(Replica)
为了在异常情况下保证数据的安全性和服务的高可用性,云数据库ClickHouse提供了副本机制,将单台服务器的数据冗余存储在2台或多台服务器上。
计算组
计算组由一个或者多个ECS资源构成,是云原生版集群的最小可见计算资源粒度。
数据库(Database)
数据库是云数据库ClickHouse集群中的最高级别对象,内部包含表(Table)、列(Column)、视图(View)、函数、数据类型等。
表(Table)
表是数据的组织形式,由多行、多列构成。
| 类型 | 说明 | 区别 |
|---|---|---|
| 本地表(Local Table) | 数据只会存储在当前写入的节点上,不会被分散到多台服务器上。 |
|
| 分布式表(Distributed Table) | 本地表的集合,它将多个本地表抽象为一张统一的表,对外提供写入、查询功能。当写入分布式表时,数据会被自动分发到集合中的各个本地表中;当查询分布式表时,集合中的各个本地表都会被分别查询,并且把最终结果汇总后返回。 |
| 类型 | 说明 | 区别 |
|---|---|---|
| 单机表(Non-Replicated Table) | 数据只会存储在当前服务器上,不会被复制到其他服务器,即只有一个副本。 |
|
| 复制表(Replicated Table) | 数据会被自动复制到多台服务器上,形成多个副本。 |
功能限制
- 高可用集群必须用复制表引擎。
- 默认所有Server都会自动组成名字为default的集群,DDL需要使用
ON CLUSTER default语句在所有Server上执行。 - 不支持用户自行配置remote_servers。
- 不支持File、URL表引擎。
- 不支持File、URL表函数。
- 不支持用户自定义profile。
对象命名规范限制
| 对象 | 命名规则 | 限制 |
|---|---|---|
| 数据库名 | 以小写字母开头,可包含字母、数字以及下划线(_),但不能包含连续两个及以上的下划线(_),长度不超过64个字符。 | 数据库名不能是system,system是内置数据库。 |
| 表名 | 以字母或下划线(_)开头,可包含字母、数字以及下划线(_),长度为1到127个字符。 | 表名不包含引号、感叹号(!)和空格。表名不能是SQL保留关键字。 |
| 列名 | 以字母或下划线(_)开头,可包含字母、数字以及下划线(_),长度为1到127个字符。 | 列名不包含引号、感叹号(!)和空格。列名不能是SQL保留关键字。 |
| 账号名 | 以小写字母开头,小写字母或数字结尾,可包含小字母、数字以及下划线(_),长度为2到16个字符。 | - |
| 密码限制 | 包含大写字母、小写字母、数字以及特殊字符(!)、(@)、(#)、($)、(%)、(^)、(&)、(*)(())、(_)、(+)、(-)、(=),每个密码至少包含其中三项(大写字母、小写字母、数字以及特殊字符),长度为8到32个字符。 | - |

 浙公网安备 33010602011771号
浙公网安备 33010602011771号