阿里云-数据库
https://www.aliyun.com/product/outline/index?spm=5176.161322.J_3207526240.20.58de592cmotafw

什么是PolarDB
PolarDB是阿里巴巴自研的新一代云原生关系型数据库,在存储计算分离架构下,利用了软硬件结合的优势,为用户提供具备极致弹性、高性能、海量存储、安全可靠的数据库服务。PolarDB 100%兼容MySQL 5.6/5.7/8.0,PostgreSQL 11,高度兼容Oracle。
PolarDB采用存储和计算分离的架构,所有计算节点共享一份数据,提供分钟级的配置升降级、秒级的故障恢复、全局数据一致性和免费的数据备份容灾服务。PolarDB既融合了商业数据库稳定可靠、高性能、可扩展的特征,又具有开源云数据库简单开放、自我迭代的优势,例如PolarDB MySQL引擎作为超级MySQL,性能最高可以提升至MySQL的6倍,而成本只有商用数据库的1/10,每小时最低只需1.3元即可体验完整的产品功能。PolarDB MySQL引擎100%兼容原生MySQL和RDS MySQL,您可以在不修改应用程序任何代码和配置的情况下,将MySQL数据库迁移至PolarDB MySQL引擎。
- 计算与存储分离,共享分布式存储。
采用计算与存储分离的设计理念,满足业务弹性扩展的需求。各计算节点通过分布式文件系统(PolarFileSystem)共享底层的存储(PolarStore),极大降低了用户的存储成本。
- 一写多读,读写分离。
PolarDB集群版采用多节点集群的架构,集群中有一个主节点(可读可写)和至少一个只读节点。当应用程序使用集群地址时,PolarDB通过内部的代理层(PolarProxy)对外提供服务,应用程序的请求都先经过代理,然后才访问到数据库节点。代理层不仅可以做安全认证和保护,还可以解析SQL,把写操作发送到主节点,把读操作均衡地分发到多个只读节点,实现自动的读写分离。对于应用程序来说,就像使用一个单点的数据库一样简单。
产品优势
- 大容量
最高100 TB,您不再需要因为单机容量的天花板而去购买多个实例做分片,由此简化应用开发,降低运维负担。
- 低成本
- 共享存储:计算与存储分离,每增加一个只读节点只收取计算资源的费用,而传统的只读节点同时包含计算和存储资源,每增加一个只读节点需要支付相应的存储费用。
- 弹性存储:存储空间无需配置,根据数据量自动伸缩,您只需为实际使用的数据量按小时付费。
- 存储包:PolarDB推出了预付费形式的存储包。当您的数据量较大时,推荐您使用存储包,相比按小时付费,预付费购买存储包有折扣,购买的容量越大,折扣力度越大。
- 计算包:PolarDB首创计算包,用于抵扣计算节点的费用,计算包兼顾了包年包月付费方式的经济性和按量付费方式的灵活性。您还可以将计算包与自动扩缩容配合使用,在业务峰值前后实现自动弹性升降配,轻松应对业务量波动。
- 高性能
大幅提升OLTP性能,支持超过50万次/秒的读请求以及超过15万次/秒的写请求。
- 分钟级扩缩容
存储与计算分离的架构,配合容器虚拟化技术和共享存储,增减节点只需5分钟。存储容量自动在线扩容,无需中断业务。
- 读一致性
集群地址利用LSN(Log Sequence Number)确保读取数据时的全局一致性,避免因为主备延迟引起的不一致。
LSN称为日志的逻辑序列号(log sequence number),在innodb存储引擎中,lsn占用8个字节。LSN的值会随着日志的写入而逐渐增大。
根据LSN,可以获取到几个有用的信息:
1.数据页的版本信息。
2.写入的日志总量,通过LSN开始号码和结束号码可以计算出写入的日志量。
3.可知道检查点的位置。
实际上还可以获得很多隐式的信息。
- 毫秒级延迟(物理复制)
利用基于Redo的物理复制代替基于Binlog的逻辑复制,提升主备复制的效率和稳定性。即使对大表进行加索引、加字段等DDL操作,也不会造成数据库的延迟。
- 秒级快速备份
不论多大的数据量,全库备份只需30秒,而且备份过程不会对数据库加锁,对应用程序几乎无影响,全天24小时均可进行备份。
如何使用PolarDB
您可以通过以下方式管理PolarDB集群,包括创建集群、创建数据库、创建账号等。
创建PolarDB集群后,您可以通过以下方式连接PolarDB集群:
- DMS:您可以通过DMS连接PolarDB集群,在Web界面进行数据库开发工作。
- 客户端:您可以使用通用的数据库客户端工具连接PolarDB集群。例如,MySQL-Front、pgAdmin等。
相关概念
了解以下概念,将帮助您更好地选购和使用PolarDB:
- 集群:PolarDB集群版采用集群架构,一个集群版集群中可包含一个主节点和最多15个只读节点。
- 地域:地域是指物理的数据中心。一般情况下,PolarDB集群应该和ECS实例位于同一地域,以实现最高的访问性能。
- 可用区:可用区是指在某个地域内拥有独立电力和网络的物理区域。同一地域的不同可用区之间没有实质性区别。
- 规格:每个节点的资源配置,例如2核8 GB。
相关服务
- ECS:ECS是云服务器,通过内网访问同一地域的PolarDB集群时,可实现PolarDB集群的最佳性能。ECS搭配PolarDB集群是典型的业务访问架构。
- Redis:Redis提供持久化的内存数据库服务。当业务访问量较大时,ECS 、PolarDB和Redis的组合可以支持更多的读请求,同时减少响应时间。
- MongoDB:提供稳定可靠、弹性伸缩、完全兼容MongoDB协议的数据库服务。数据结构多样时,可以选择将结构化数据存储在PolarDB,将非结构化数据存储在MongoDB,满足业务的多样化存储需求。
- DTS:您可以使用数据传输服务DTS将本地数据库迁移到云上的PolarDB。
- OSS:对象存储服务OSS是阿里云提供的海量、安全、低成本、高可靠的云存储服务。
PolarDB技术内幕
本文档介绍PolarDB云数据库的性能优点以及共享存储、物理复制和使用场景中优化的过程。
背景信息
传统的关系型数据库有着悠久的历史,从上世纪60年代开始就已经在航空领域发挥作用。因为其严谨的一致性保证以及通用的关系型数据模型接口,获得了越来越多的应用。2000年以后,随着互联网应用的出现,很多场景下,并不需要传统关系型数据库提供的一致性以及关系型数据模型。由于快速膨胀和变化的业务场景,对可扩展性(Scalability)以及可靠性(Reliable)更加需要,而这又正是传统关系型数据库的薄弱之处。新的适合这种业务特点的数据库出现,就是我们常说的NoSQL。由于缺乏一致性及事务支持,很多业务场景被NoSQL拒之门外。缺乏统一的高级的数据模型和访问接口,又让业务代码承担了更多的负担。数据库的历史就这样经历了多重否定,又螺旋上升的过程。
PolarDB就是在这种背景下出现的,由阿里巴巴自主研发的下一代关系型分布式云原生数据库。在兼容传统数据库生态的同时,突破了传统单机硬件的限制,为用户提供大容量、高性能、极致弹性的数据库服务。
核心技术之共享存储

PolarDB采用了Share Storage的整体架构。采用RDMA高速网络互连的众多Chunk Server一起向上层计算节点提供块设备服务。一个集群可以支持一个Primary和多个Secondary节点,分别以读写和只读的挂载模式通过RDMA挂载在Chunk Server上。
PolarDB的计算节点通过libpfs挂载在PolarStores上,数据按照Chunk为单位拆分,再通过本机的PolarSwritch分发到对应的ChunkServer。每个ChunkServer维护一组Chunk副本,并通过ParallelRaft保证副本间的一致性。PolarCtl则负责维护和更新整个集群的元信息。
Bypass Kernel
软件设计中,在绑定CPU,非阻塞IO的模式下, 通过状态机代替操作系统的线程调度,达到Bypass Kernel的目的。
ParallelRaftPolarStore中采用三副本的方式来保证数据的高可用,需要保证副本间的一致性。工业界有成熟的Raft协议及实现,但Raft由于对可理解的追求,要求顺序确认以及顺序提交。而副本的确认提交速度会直接影响整个PolarStore的性能。为了获得更好的访问速度,PolarStore提出了ParallelRaft协议,在Raft协议的框架下,利用块设备访问模式中方便判定访问冲突的特点,允许一定程度的乱序确认和乱序提交。

核心技术之物理复制
采用了共享存储的模式之后,Secondary上依然需要从Primary上的复制逻辑来刷新内存结构,如果Buffer Pool以及各种Cache。由于读写节点和只读节点访问的是同一份数据,传统的基于binlog的逻辑复制方式不再可用,这时逻辑复制由于最终执行顺序的变化,导致主从之间出现不同的物理数据结构。因此DB层基于Redo Log的物理复制的支持是必不可少的。

不同于逻辑复制自上而下的复制方式,物理复制方式是自下而上的。从共享存储中读取并重放REDO,重放过程会直接修改Buffer Pool中的Page,同步B+Tree及事务信息,更新Secondary上的各种内存Cache。除了支持共享存储外,物理复制还可以减少一份日志写入。由于整个复制过程不需要等到事务提交后才开始,显著的减少了复制延迟:

交易场景优化
针对双十一峰值交易场景,PolarDB也做了大量优化。
Blink Tree- 同一时刻,整个B+Tree只能有一个SMO操作。
- 正在执行SMO操作的B+Tree分支上的读取操作会被阻塞,直到整个SMO操作完成。
- 通过优化加锁,支持同一时刻多个SMO同时进行操作,这样原本等待在其它分支执行SMO的插入操作就无需等待,从而提高写入性能;
- 引入Blink Tree来替换B+Tree,通过缩小SMO的加锁粒度,将原本需要将所有涉及SMO的各层Page加锁直到整个SMO完成后才释放的逻辑,优化成Ladder Latch,即逐层加锁。修改完一层即可放锁然后去加上一层Page锁继续修改。这样原本被SMO阻塞的读操作会有机会在SMO操作过程中执行。通过对每个节点增加一个后继链接的方式,使得在Page Split的中间状态也可以完成对Page安全的访问,如下图所示,传统的B+Tree必须通过一把锁来Block整个Page Split过程中对所影响的Page的访问。而Blink Tree则不需要,即使Split还在进行中,父节点到子节点的链接还没有完成建立,依然可以通过前一个节点的后继链接找到正确的子节点。并且通过特殊处理确保访问到正确的Page,从而提高读取性能。
![Blink Tree]()

通过对B+Tree的优化,可以将交易场景下PolarDB的读写性能提升20%。
Simulated AIOInnoDB中存在simulated AIO逻辑,用于支持运行在不包含AIO的系统下。PolarDB下的共享存储文件系统没有AIO,所以采用的是simulated AIO的逻辑。但是原版中的simulated AIO基于本地存储设计,与分布式存储的特性并不适配。为了进行IO合并,原版的simulated IO设计,将所有异步IO请求按照目标地址进行组织,存放在同一个IO数组中,方便将目标地址连续的小IO合并成大IO来操作,以提升IO的吞吐。但是这个设计与分布式存储是不相适配的,连续的大IO操作,会使得同一时刻,只有一个或少量存储节点处在服务状态,浪费了其它存储节点资源;
- 合理的选择IO合并和拆解,充分利分布式存储的多节点优势;
- 建立状态有序的IO服务队列,减少高负载下的IO服务开销。

通过重新设计,性能有很大幅度的提升,如下图:


稳定性也有了很大的提升,如下图:

 Partitioned Lock System
Partitioned Lock System
PolarDB采用的是2PL+MVCC的并发控制方式。也就是用多版本数据构建Snapshot来服务读请求,从而避免读写之间的访问冲突。而写之间的冲突需要通过两阶段锁来保证,包括表锁、记录锁和谓词锁等。当需要加锁时,之前的做法都需要在log_sys中先获得一把全局的mutex保护。
在峰值的交易场景中,大量的写入会导致mutex成为瓶颈。因此PolarDB采取了Partition Lock System的方式,将log_sys改造成由多个LockSysShard组成,每个Shard中都有自己局部的mutex,从而将这个瓶颈打散。尤其是在这种大压力的写入场景下明显的提升写入性能。
 Lockless Transaction System
Lockless Transaction System
PolarDB中支持Snapshot Isolation的隔离级别,通过保留使用的Undo版本信息来支持对不同版本的记录的访问,即MVCC。而实现MVCC需要事务系统有能力跟踪当前Active及已经Commit的事务信息。在之前的实现中每当有写事务开始时,需要分配一个事务ID,并将此ID添加到Transaction System中的一个活跃事务列表中。当有读请求需要访问数据时,会首先分配一个ReadView,其中包括当前已分配最大的事务ID,以及当前活跃事务列表的一个备份。每当读请求访问数据时,会通过从Index开始的Roll ptr访问到此记录所有的历史版本,通过对比某个历史版本的事务ID和ReadView中的活跃事务列表,可以判断是不是需要的版本。

然而,这就导致每当有读事务开始时,都需要在整个拷贝过程中对当前活跃事务列表加锁,从而阻塞了新的写事务的ID加入。同样写事务和写事务之间也有访问活跃事务列表的冲突。从而活跃事务列表在这里变成一个明显的性能瓶颈,在双十一这种大压力的读写场景下尤为明显。
对此,我们将Tansaction System中的活跃事务列表改造成无锁Hash实现,写事务添加ID以及读事务拷贝到ReadView都可以并发进行。大大提升了性能。
集群版
基本介绍
PolarDB MySQL引擎集群版使用计算与存储分离的架构,计算层的数据库节点可以从2个动态扩展到最多16个。多个数据库节点构成PolarDB MySQL引擎数据库引擎层,在数据库引擎层之上是支持读写分离、负载均衡等功能的数据库代理层(PolarProxy)。PolarDB MySQL引擎通过数据库代理层对外提供了2~10个集群地址。PolarDB MySQL引擎集群版的存储动态扩展对业务无感知,存储容量最高可达100 TB,且按照存储空间的实际使用量进行收费(详情请参见存储空间计费规则)。PolarDB集群版支持将数据分布在多个可用区(AZ)内,提供AZ级别的故障容灾能力。当一个可用区不可用时,您即可在几分钟内将数据库服务快速切换到另外一个可用区(详情请参见多可用区部署)。PolarDB MySQL引擎集群版还提供多节点的动态扩缩容,仅需约5分钟时间即可增加节点进行横向扩容,对业务无影响(详情请参见增加或删除节点)。
PolarDB MySQL引擎集群版支持两种子系列:
- 独享规格:每个集群会独占所分配到的计算资源(如CPU),而不会与同一服务器上的其他集群共享资源,性能更加稳定可靠。
- 通用规格:同一服务器上的不同集群,会互相充分利用彼此空闲的计算资源(如CPU),通过复用计算资源享受规模红利,性价比更高。
更多关于集群版的介绍,请参见产品架构。
适用场景
集群版是PolarDB MySQL引擎推荐的主流系列,它免费提供快速备份数据、恢复数据和全球数据库功能,同时还支持快速弹性扩缩容、并行查询加速等企业级功能,推荐在生产环境中使用。
单节点
基本介绍
PolarDB MySQL引擎单节点采用突发性能型规格,共享计算资源池提升资源利用率,单节点的架构也无需Proxy代理节省资源成本。与集群版一样,PolarDB MySQL引擎单节点的存储动态扩展也对业务无感知,并按照存储空间的实际使用量进行收费。同时,PolarDB单节点集群无需日志同步,省去了Redo日志同步和解析的开销,性能上也有不错的表现。
适用场景
高性价比的PolarDB MySQL引擎单节点是个人用户测试、学习的最佳选择,也可作为初创企业的入门级产品。
挑战和诉求:历史数据归档
- 历史数据归档的挑战
大部分业务数据的读写特征,都是最新产生的数据会被更频繁地读取或更新,而更久之前的数据(如1年前的聊天记录或订单信息)很少被访问。 随着业务发展,数据库系统中会积累大量访问频率很低甚至为0的数据,这些数据的积累容易导致如下问题:
- 历史数据和最新数据存储在同一数据库系统中,导致磁盘空间不足。
- 大量数据共享数据库系统的内存、缓存空间、磁盘IOPS等,导致性能问题。
- 数据量太大导致数据备份时间过长甚至备份失败;同时如何存放备份数据也是一个问题。
针对如上问题,一种做法是对历史数据做归档,将长期不使用的数据迁移至以文件形式存储的廉价存储设备上,如阿里云OSS或者阿里云数据库DBS服务。然而,在实际业务中,历史数据并不完全是静态的,针对几个月甚至几年前的历史数据,依旧可能存在实时地、低频地查询甚至更新需求。例如,在阿里巴巴内部,对淘宝或天猫历史订单的查询、对企业级办公软件钉钉历史聊天记录的查询或对菜鸟海量历史物流订单的查询等。
- 历史数据归档的诉求
为了解决历史数据的读取和更新问题,可以使用一个单独的数据库用来存储归档的数据,即历史库。业务对单独的历史库一般有如下诉求:
- 具备大容量存储空间,支持业务持续将线上数据保存到历史库中,而无需担心容量问题。
- 与在线数据库系统使用相同的访问接口,如都支持MySQL协议等,确保应用程序端无需修改任何代码即可同时访问在线库和历史库。
- 成本低廉,如支持通过压缩减少数据所占磁盘空间、使用廉价存储介质等,确保可以使用较小的代价保存海量的数据。
- 具备一定的读写能力,能够满足低频读写的需求。
MySQL作为世界上使用最广泛的开源数据库系统,一直缺乏一个既能满足大容量低成本要求,又具备一定读写能力的历史数据归档存储方案。虽然业界曾经推出过一些高压缩引擎,如TokuDB、MyRocks等,但受限于单物理机磁盘容量限制,存储的数据量有限。
解决方案:PolarDB历史库
为应对如上历史数据归档存储方面的挑战和诉求,PolarDB基于如下技术创新和突破,推出了历史库产品系列:
- 阿里巴巴自研的基于LSM-tree架构的存储引擎X-Engine提供了强大的数据压缩能力,满足了归档数据库低存储成本的要求。通过LSM-Tree(Log-Structured Merge-Tree)层次化架构和Zstandard(ZSTD)压缩算法实现了更高的数据压缩率,对比使用InnoDB作为存储引擎,最高可节省70%的存储空间。更多关于X-Engine存储引擎的详情,请参见X-Engine简介。但由于采用了X-Engine引擎,在使用历史库时也存在一些限制(尤其是与MySQL的兼容性限制),具体限制请参见使用限制。
- PolarDB借助于共享分布式存储服务,实现了存储容量在线平滑扩容,同时计算资源和存储资源间采用高速网络互联,并通过RDMA协议进行数据传输,使I/O性能不再成为瓶颈。集成到PolarDB的X-Engine引擎同样获得了这些技术优势。
如下技术创新将X-Engine移植进PolarDB,从而进入PolarDB双引擎时代:
- 合并X-Engine的事务WAL日志流和InnoDB的REDO日志流,实现了一套日志流和传输通道同时服务于InnoDB引擎和X-Engine引擎,管控逻辑以及与共享存储的交互逻辑无需做任何改变,同时未来新增其他引擎时也可以复用这套架构。
- 将X-Engine的IO模块对接到PolarDB InnoDB所使用的用户态文件系统PFS上,实现了InnoDB与X-Engine共享同一个分布式块设备。同时依靠底层分布式存储实现了快速备份。
多主架构集群版
随着PolarDB MySQL引擎客户的不断增加,大规模头部客户不断涌入,部分头部客户业务体量规模庞大,使得目前PolarDB MySQL引擎的单写(一写多读)架构在特定场景下,写性能出现瓶颈。
PolarDB MySQL引擎全新推出多主架构,实现从一写多读架构到多写多读架构的升级,主要面向多租户、游戏、电商等高并发读写的应用场景。

集群中所有的数据文件都存放在共享存储(PolarStore)中,各个RW节点通过分布式文件系统(PolarFileSystem)共享底层存储(PolarStore)中的数据文件。用户可以通过集群地址访问整个集群,数据库代理会自动转发SQL命令到正确的RW节点。
核心优势和能力
- 支持不同数据库在不同计算节点并发写入。
- 集群版支持1个写节点和最多15个只读节点,多主架构集群版最多可支持32个节点同时写入。
- 支持数据库跨节点动态调度,秒级完成切换,极大提升集群整体并发读写能力。
适用场景
- SaaS多租户场景:满足高并发性能需求,实现租户间负载均衡
场景特点:租户的数据库数量变化较快,负载变化较大,需要经常在不同的实例之间调配数据库资源,以便达到最佳用户体验。
解决方案:多主架构可帮助客户快速将租户的数据库在不同RW节点间进行切换,从而实现负载均衡。
- 分服游戏场景:更好的性能和扩展能力,支持世界服架构
场景特点:在游戏成长期,数据库负载较大,且呈现为不断增长的趋势特点。通常表现为在游戏成长期期间,会不断增加数据库,导致RW节点负荷也不断增加。而在游戏衰退期,数据库负载逐渐减少,数据库会不断合并,导致RW节点的负荷也呈减少趋势。
解决方案:游戏成长期,可快速将部分数据库切换到新的RW节点,实现负载均衡;游戏衰退期,可快速将数据库聚合到少量RW节点,快速降低运作成本。
产品系列对比
产品系列适用场景对比
| 系列 | 说明 | 适用场景 |
|---|---|---|
| 单节点 | 采用突发性能型规格,共享计算资源池提升资源利用率,单节点的架构无需Proxy代理节省资源成本。
详细信息,请参见单节点。 |
|
| 历史库 | 历史库是PolarDB MySQL引擎中具有较高数据压缩率的产品系列,使用了X-Engine作为默认存储引擎,提供了超大存储容量,满足了归档数据库低存储成本的要求。详细信息,请参见历史库。 | 对计算诉求不高但需要存储一些归档类数据(如钉钉消息等数据)的业务。 |
| 集群版 | 使用计算与存储分离的架构,提供更快弹性扩缩容、更大存储容量、更低主备延迟。
详细信息,请参见集群版。 |
|
什么是云原生分布式数据库PolarDB-X
产品简介
PolarDB-X是阿里巴巴自主设计研发的高性能云原生分布式数据库产品,为用户提供高吞吐、大存储、低延时、易扩展和超高可用的云时代数据库服务。
PolarDB-X始终保持对阿里巴巴集团“双十一购物狂欢节”所有相关业务的全面支撑。历经十余年淬炼,PolarDB-X具备了强数据一致性、高系统稳定性、快速集群弹性等核心关键特性,并在司法财税、交通物流、电力能源等公共事业领域有广泛深入应用。
PolarDB-X坚定遵循自主可控、开放生态的发展思路,持续围绕MySQL开源生态构建分布式能力,以求最大程度降低用户的学习使用成本。
产品特点
云原生+MySQL生态PolarDB-X已作为标准云产品在世界范围内的13个地区提供服务。依托云资源和容器化部署能力,PolarDB-X可以在数分钟内完成集群创建和变配,整个过程中用户无需进行手工干预。同时PolarDB-X支持按量付费模式,从而帮助用户精准降本。
阿里云及开源社区的多种生态工具对PolarDB-X持续提供不断完善的支持,包括但不限于以下产品:数据传输服务DTS、数据库备份DBS、数据管理服务DMS、数据库自治服务DAS、数据集成Data Integration、云监控、性能测试PTS。
PolarDB-X积极拥抱并努力回馈MySQL生态,目前已经形成对MySQL生态从协议、语法、事务行为、账号体系、安全到命令行工具的全方位兼容。
存储计算分离架构旨在最大限度地发挥其云数据库的弹性扩展能力,PolarDB-X采用了基于存储计算分离的Shared-Nothing系统架构,该架构使用户可以根据业务需要进行分层容量规划。
PolarDB-X的存储节点(DN)基于阿里巴巴自研的跨可用区部署的三节点强一致数据库X-DB构建。X-DB使用InnoDB引擎,提供MySQL语法全兼容能力,以及对复杂查询的处理能力。X-DB结合PolarDB-X面向HTAP的CBO查询优化器,可精确控制计算下推行为,从而获得更佳的整体性能。
透明分布式体验让用户以使用单机MySQL数据库的体验,操作分布式数据库是PolarDB-X一贯追求的目标。为此PolarDB-X提供了简单易用的透明分布式能力:
默认主键拆分,让移植到PolarDB-X的数据和业务摆脱对设计“分区键”的依赖。
高性能强一致分布式事务,PolarDB-X采用自研X-Paxos协议,保证数据存储在故障切换过程中RPO=0的基础上,使用TSO策略和分布式的MVCC能力保证了分布式事务的隔离性和一致性。
分布式线性扩展,PolarDB-X基于一致性Hash的分区策略,有效的进行负载均衡和热点抑制,且在扩展过程中保持计算下推和数据一致性的同时实现业务零感知,并行和流控能力为扩展期间业务连续性提供了有力保障。
全局Binlog和全局一致性备份,分别解决分布式数据库各节点数据库向下游流转的难题及各节点备份时间差造成的恢复一致性问题。
多种部署形态为满足不同行业客户对部署形态的需求,PolarDB-X提供公共云、专有云、专有云DBStack、软件版四种部署形态:
- 公共云:高速迭代,稳定服务,完全托管。目前面向世界范围内13个地区提供高性能云原生分布式数据库服务。
- 专有云(ApsaraStack):集成阿里云核心产品,满足对安全性、隔离性有合规要求的行业客户。
- 专有云DBStack:轻量级数据库管理服务平台,集成阿里云核心数据库产品,满足构建高性能、高可用、低成本的全场景数据库解决方案用户需求。
强一致分布式事务
ACID分布式事务
- 原子性(Atomicity)
- 一致性(Consistency)
- 隔离性(Isolation)
- 持久性(Durability)

TSO中心授时
PolarDB-X分布式事务支持MVCC多版本,分布式的版本号依赖于中心授时服务来生成全局单调递增的时间戳,基于中心授时为版本提供事务的一致性读取。
PolarDB-X元数据服务(GMS)基于Paxos共识协议提供一个具备三节点高可用性的服务,PolarDB-X的计算节点(CN)会通过RPC接口和元数据服务(GMS)进行通讯并获取中心授时。
事务2PC提交
BEGIN;
UPDATE account SET balance = balance - 20 WHERE name = 'Alice';
UPDATE account SET balance = balance + 20 WHERE name = 'Bob';
COMMIT;
如果事务内写入的数据涉及多个分区,PolarDB-X的计算节点将会使用两阶段提交(Two-phase Commit Protocol,简称2PC)方式提交事务,即便在事务提交过程中发生节点宕机等问题,基于2PC的事务恢复机制也能确保事务原子性。
MVCC多版本
SELECT SUM(balance) FROM account;因查询操作的数据涉及多个分区,PolarDB-X首先会获取中心授时确定读取版本,读取过程中会对每行数据的MVCC多版本进行可见性判断,确保只会读取在全局时间戳之前已完成提交的事务。
例如转账事务在多个数据节点的提交有先后时间差,已提交的分支事务因为数据版本号不满足可见性,正在提交的事务数据全部不可见,从而确保总额数据读取的一致性。
分布式事务的下游生态
读写分离的一致性
事务型的分布式数据库一般会采用读写分离的模式提升读的性能,因此分布式事务除了保障主库的一致性以外,还需要保证用户在使用读写分离模式下对于备库的一致性。
PolarDB-X产品支持主实例和只读实例,主实例是由基于Paxos多数派协议的Leader/Follower角色组成,只读实例是由基于Paxos协议的Learner角色组成。PolarDB-X针对分布式事务一致性的设计,除了在存储节点(DN)的leader主副本中保存事务信息之外,也会将数据的事务多版本信息同步到learner副本中,可以保证只读实例上的多个分区数据的读的一致性,具体特性请参见混合负载HTAP。
例如,主库中写入了一个版本为100的数据,而下一次的查询中带着中心授时返回的版本为101。当查询被路由到只读的learner节点时,即使learner节点有数据复制延迟,PolarDB-X也可以阻塞读来满足读的一致性。
全局变更日志CDC
事务型的分布式数据库除了面向在线业务的高并发写入以外,一般还需要将在线数据同步给下游的灾备数据、汇聚业务或数据仓库系统等,下游业务对于事务日志的一致性也有比较强的诉求,例如事务不能乱序、事务原子性、DDL支持同步等。
MySQL binlog是MySQL数据库中记录变更数据的二进制日志,它可以看做是一个消息队列,队列中按顺序保存了MySQL中详细的增量变更信息,通过消费队列中的变更条目,下游系统或工具实现了与MySQL的实时数据同步,这样的机制也称为CDC(Change Data Capture,增量数据捕捉)。
PolarDB-X存储节点(DN)在变更日志设计上也会保存分布式事务信息,通过PolarDB-X日志组件(CDC)收集分布式下多个存储节点(DN)的日志流,进行汇总、重组、排序、落盘等过程,提供满足分布式事务一致性语义的二进制日志,并全面兼容MySQL binlog协议和生态。具体特性请参见全局日志变更。
备份恢复的一致性
传统关系型数据库一般会采用数据库的全量备份来保证数据安全。在遇到数据异常、数据库被删的风险时,需要通过数据库的备份集进行快速恢复,其中数据恢复也要保证事务的一致性。另外,分布式数据库通常数据存储规模更大,对于备份恢复的一致性有更大的挑战。
PolarDB-X在存储节点(DN)的数据和变更日志中都保存了分布式事务的中心授时(包含了时间戳信息),任意时间点的数据恢复(PITR,point-in-time recovery)都可以快速将时间戳转化为分布式的中心授时,在备份恢复中按数据的版本可见性进行处理,同时PolarDB-X结合分布式的多节点并行来全面提升备份恢复的效率。具体特性请参见数据备份与恢复。
云数据库RDS简介
阿里云关系型数据库RDS(Relational Database Service)是一种稳定可靠、可弹性伸缩的在线数据库服务。基于阿里云分布式文件系统和SSD盘高性能存储,RDS支持MySQL、SQL Server、PostgreSQL和MariaDB TX引擎,并且提供了容灾、备份、恢复、监控、迁移等方面的全套解决方案,彻底解决数据库运维的烦恼。
数据库引擎
以下是对四种数据库引擎的介绍:
- 云数据库RDS MySQL
MySQL是全球最受欢迎的开源数据库,作为开源软件组合LAMP(Linux + Apache + MySQL + Perl/PHP/Python)中的重要一环,广泛应用于各类应用。
Web 2.0时代,风靡全网的社区论坛软件系统Discuz!和博客平台WordPress均基于MySQL实现底层架构。Web 3.0时代,阿里巴巴、Facebook、Google等大型互联网公司都采用更为灵活的MySQL构建了成熟的大规模数据库集群。
阿里云数据库RDS MySQL基于阿里巴巴的MySQL源码分支,经过双11高并发、大数据量的考验,拥有优良的性能和吞吐量。此外,阿里云数据库MySQL版还拥有经过优化的读写分离、什么是数据库代理、智能调优等高级功能。
当前RDS MySQL支持5.5、5.6、5.7和8.0版本。
- 云数据库RDS SQL Server
SQL Server是发行最早的商用数据库产品之一,作为Windows平台(IIS + .NET + SQL Server)中的重要一环,支撑着大量的企业应用。SQL Server自带的Management Studio管理软件内置了大量图形工具和丰富的脚本编辑器。您通过可视化界面即可快速上手各种数据库操作。
阿里云数据库RDS SQL Server不仅拥有高可用架构和任意时间点的数据恢复功能,强力支撑各种企业应用,同时也包含了微软的License费用,您无需再额外支出License费用。
当前RDS SQL Server支持以下版本:
- SQL Server 2008 R2 企业版
- SQL Server 2012 Web版、标准版、企业版
- SQL Server 2014 标准版、企业版
- SQL Server 2016 Web版、标准版、企业版
- SQL Server 2017 标准版、企业集群版
- SQL Server 2019 标准版、企业集群版
- 云数据库RDS PostgreSQL
PostgreSQL是全球最先进的开源数据库。作为学院派关系型数据库管理系统的鼻祖,它的优点主要集中在对SQL规范的完整实现以及丰富多样的数据类型支持,包括JSON数据、IP数据和几何数据等,而大部分商业数据库都不支持这些数据类型。
除了完美支持事务、子查询、多版本控制(MVCC)、数据完整性检查等特性外,阿里云数据库RDS PostgreSQL还集成了高可用和备份恢复等重要功能,减轻您的运维压力。
当前RDS PostgreSQL支持9.4、10、11、12和13版本。
- 云数据库RDS MariaDB TX
MariaDB是MySQL的一个分支,主要由开源社区维护,采用GPL授权许可。MariaDB的目的是完全兼容MySQL,包括API和命令行,使之能轻松成为MySQL的代替品。在存储引擎方面,MariaDB 10.0.9版起使用XtraDB(代号为Aria)来代替MySQL的InnoDB。
阿里云引入的MariaDB TX企业级解决方案,良好兼容Oracle,对PL/SQL有优秀的兼容性。MariaDB TX是一个建立在 MariaDB Server、MariaDB MaxScale和MariaDB Cluster之上的事务性数据库平台,包括数据库连接器和管理工具,提供技术支持以及专家服务——创建了完整的企业数据库解决方案。
当前RDS MariaDB TX支持10.3版本。
什么是OceanBase
OceanBase是由蚂蚁金服、阿里巴巴完全自主研发的分布式关系型数据库,始创于2010年。
OceanBase具有数据强一致、高可用、高性能、在线扩展、高度兼容SQL标准和主流关系型数据库、低成本等特点。OceanBase至今已成功应用于支付宝全部核心业务:交易、支付、会员、账务等系统以及阿里巴巴淘宝(天猫)收藏夹、P4P广告报表等业务。除在蚂蚁金服和阿里巴巴业务系统中获广泛应用外,从2017年开始,OceanBase开始服务外部客户,客户包括南京银行、浙商银行、人保健康险等。
产品优势
-
高性能:OceanBase采用了读写分离的架构,把数据分为基线数据和增量数据。其中增量数据放在内存里(MemTable),基线数据放在SSD盘(SSTable)。对数据的修改都是增量数据,只写内存。所以DML是完全的内存操作,性能非常高。
-
低成本:OceanBase通过数据编码压缩技术实现高压缩。数据编码是基于数据库关系表中不同字段的值域和类型信息,所产生的一系列的编码方式,它比通用的压缩算法更懂数据,从而能够实现更高的压缩效率。
-
高兼容:兼容常用MySQL/ORACLE功能及MySQL/ORACLE前后台协议,业务零修改或少量修改即可从MySQL/ORACLE迁移至OceanBase。
-
高可用:数据采用多副本存储,少数副本故障不影响数据可用性。通过“三地五中心”部署实现城市级故障自动无损容灾。
产品优势与应用场景
OceanBase是一款金融级的分布式关系数据库,具备高性能、高可用、强一致、可扩展和兼容性高等典型优势,适用于对性能、成本和扩展性要求高的金融场景。
主要特性
- 高性能:存储采用读写分离架构,计算引擎全链路性能优化,准内存数据库性能。
- 低成本:使用PC服务器和低端SSD,高存储压缩率降低存储成本,高性能降低计算成本,多租户混部充分利用系统资源。
- 高可用:数据采用多副本存储,少数副本故障不影响数据可用性。通过“三地五中心”部署实现城市级故障自动无损容灾。
- 强一致:数据多副本通过paxos协议同步事务日志,多数派成功事务才能提交。缺省情况下读、写操作都在主副本进行,保证强一致。
- 可扩展:集群节点全对等,每个节点都具备计算和存储能力,无单点瓶颈。可线性、在线扩展和收缩。
- 兼容性:兼容常用MySQL/ORACLE功能及MySQL/ORACLE前后台协议,业务零修改或少量修改即可从MySQL/ORACLE迁移至OceanBase。
应用场景
OceanBase的产品定位是一款分布式关系数据库,经过多年蚂蚁金服内部业务的打磨,目前已经支持蚂蚁金服100%核心交易系统,稳定支撑阿里、蚂蚁内部上百个关键业务以及浙商银行、南京银行等多个外部客户。OceanBase产品适用于金融、证券等涉及交易、支付和账务等对高可用、强一致要求特别高,同时对性能、成本和扩展性有需求的金融属性场景,以及各种关系型结构化存储的OLTP应用。OceanBase天然的Share-Nothing分布式架构对于各种OLAP型应用也有很好的支持,例如云数据库OceanBase适用于以下典型场景:
- 金融级数据可靠性需求
金融环境下通常对数据可靠性有更高的要求,OceanBase每一次事务提交,对应日志总是会在多个数据中心实时同步,并持久化。即使是数据中心级别的灾难发生,总是可以在其他的数据中心恢复每一笔已经完成的交易,实现了真正金融级别的可靠性要求。
![]()
- 让数据库适应飞速增长的业务
业务的飞速成长,通常会给数据库带来成倍压力。OceanBase作为一款真正意义的分布式关系型数据库,由一个个独立的通用计算机作为系统各个节点,数据根据容量大小、可用性自动分布在各个节点,当数据量不断增长时,OceanBase可以自动扩展节点的数量,满足业务需求。
![]()
- 连续不间断的服务
企业连续不间断的服务,通常意味着给客户最流畅的产品体验。分布式的OceanBase集群,如果某个节点出现异常时,可以自动剔除此服务节点,该节点对应的数据有多个其他副本,对应的数据服务也由其他节点提供。甚至当某个数据中心出现异常,OceanBase可以在短时间内将服务节点切换到其他数据中心,可以保证业务持续可用。
![]()



什么是云数据库Redis版
云数据库Redis版(ApsaraDB for Redis)是兼容开源Redis协议标准、提供混合存储的数据库服务,基于双机热备架构及集群架构,可满足高吞吐、低延迟及弹性变配等业务需求。
为什么选择云数据库Redis版
- 硬件部署在云端,提供完善的基础设施规划、网络安全保障和系统维护服务,您可以专注于业务创新。
- 支持String(字符串)、List(链表)、Set(集合)、Sorted Set(有序集合)、Hash(哈希表)、Stream(流数据)等多种数据结构,同时支持Transaction(事务)、Pub/Sub(消息订阅与发布)等高级功能。
- 在社区版的基础上推出企业级内存数据库产品,提供性能增强型、持久内存型、容量存储型和混合存储型(已停售)供您选择。
实例类型
| 版本类型 | 简介 |
|---|---|
| 云数据库Redis社区版 | 兼容开源Redis的高性能内存数据库产品,支持主从双副本、集群、读写分离等架构。 |
| 云数据库Redis企业版 |
Redis企业版作为云数据库Redis社区版的基础上开发的强化版Redis服务,从访问延时、持久化需求、整体成本这三个核心维度考量,基于DRAM、NVM和ESSD云盘等存储介质,推出了多种不同形态的产品,为您提供更强的性能、更多的数据结构和更灵活的存储方式,满足不同场景下的业务需求。 |
实例架构
云数据库Redis版支持灵活的多种部署架构,能够满足不同的业务场景。
| 架构类型 | 说明 |
|---|---|
| 标准版-单副本 | 适用于纯缓存场景,支持单节点集群弹性变配,满足高QPS(Queries per Second)场景,提供超高性价比。 |
| 标准版-双副本 | 系统工作时主节点(Master)和副本(Replica)数据实时同步,若主节点发生故障,系统会快速将业务切换至备节点,全程自动且对业务无影响,保障服务高可用性。 |
| 集群版-单副本 | 单副本集群版实例采用集群架构,每个分片服务器采用单副本模式。适用于纯缓存类业务或者QPS压力较大的业务场景。 |
| 集群版-双副本 | 集群(Cluster)实例采用分布式架构,每个数据分片都支持主从切换(master-replica),能够自动进行容灾切换和故障迁移,保障服务高可用。同时提供多种规格,您可以根据业务压力选择对应规格,还可以随着业务的发展自由变配规格。集群版支持两种连接模式: |
| Redis读写分离版 | 与标准版-双副本架构类似,读写分离实例采用主从(Master-Replica)架构提供高可用,主节点挂载只读副本(Read Replica)实现数据复制,支持读性能线性扩展。 只读副本可以有效缓解热点key带来的性能问题,适合高读写比的业务场景。 读写分离实例提供非集群版和集群版:
|
架构信息查询导航
云数据库Redis版支持三种架构类型:标准版、集群版与读写分离版。标准版、集群版都有单副本和双副本两种节点类型。您可根据业务场景选用不同架构的实例。
架构概览
如需了解以下实例架构的详细信息,请单击架构名称跳转到相应的文档。
| 实例架构 | 支持的系列 | 简介 | 适用场景 |
|---|---|---|---|
| 标准版-双副本 |
|
标准版-双副本采用主从(master-replica)双副本架构,提供高可用切换。 |
|
| 标准版-单副本 | 社区版 | 标准版-单副本采用单节点架构。 |
|
| 集群版-双副本 |
|
双副本集群版实例采用集群架构,每个分片服务器采用主从(master-replica)双副本模式。 |
|
| 集群版-单副本 | 社区版 | 单副本集群版实例采用集群架构,每个分片服务器采用单副本模式。 |
|
| 读写分离版 |
|
Redis读写分离版本由代理服务器(Proxy Servers)、主备(Master and Replica)节点及只读(Read-Only)节点组成。 |
|
标准版-双副本
标准版-双副本采用主从架构,不仅能提供高性能的缓存服务,还支持数据高可靠。
简介
标准版-双副本模式采用主从(master-replica)模式搭建。主节点提供日常服务访问,备节点提供HA高可用,当主节点发生故障,系统会自动在30秒内切换至备节点,保证业务平稳运行。

集群版-双副本
云数据库Redis版提供双副本集群版实例,可轻松突破Redis自身单线程瓶颈,满足大容量、高性能的业务需求。集群版支持代理和直连两种连接模式,您可以根据本章节的说明,选择适合业务需求的连接模式。
代理模式
集群架构的本地盘实例默认采用代理(proxy)模式,支持通过一个统一的连接地址(域名)访问Redis集群,客户端的请求通过代理服务器转发到各数据分片,代理服务器、数据分片和配置服务器均不提供单独的连接地址,降低了应用开发难度和代码复杂度。代理模式的服务架构图和组件说明如下。

| 组件 | 说明 |
|---|---|
| 代理服务器(proxy servers) | 单节点配置,集群版结构中会有多个Proxy组成,系统会自动对其实现负载均衡及故障转移。
说明 关于Proxy的详细介绍即特性说明,请参见Redis Proxy特性说明。
|
| 数据分片(data shards) | 每个数据分片均为双副本(分别部署在不同机器上)高可用架构,主节点发生故障后,系统会自动进行主备切换保证服务高可用。 |
| 配置服务器(config server) | 采用双副本高可用架构,用于存储集群配置信息及分区策略。 |
各组件的数量和配置由Redis实例的规格决定,不支持自定义修改,但您可以通过变更实例配置调整集群的大小,或者将实例调整为其它架构。
读写分离版
针对读多写少的业务场景,云数据库Redis推出了读写分离版的产品形态,提供高可用、高性能、灵活的读写分离服务,满足热点数据集中及高并发读取的业务需求,最大化地节约运维成本。
组件介绍
读写分离版主要由主备节点、只读节点、Proxy(代理)节点和高可用系统组成。

| 组件 | 说明 |
|---|---|
| 主节点 | 承担写请求的处理,同时和只读节点共同承担读请求的处理。 |
| 备节点 | 作为数据备份使用,不对外提供服务。 |
| 只读节点 | 承担读请求的处理。只读节点采取链式复制架构,扩展只读节点个数可使整体实例性能呈线性增长。同时,采用优化后的binlog执行数据同步,可最大程度地规避全量同步。 |
| Proxy(代理)节点 | 客户端和Proxy节点建立连接后,Proxy节点会自动识别客户端发起的请求类型,按照权重负载均衡(暂不支持自定义权重),将请求转发到不同的数据节点中。例如将写请求转发给主节点,将读请求转发给主节点或只读节点。
说明
|
| 高可用系统 | 自动监控各节点的健康状态,异常时发起主备切换或重搭只读节点,并更新相应的路由及权重信息。 |
什么是云数据库MongoDB版
云数据库MongoDB版(ApsaraDB for MongoDB)完全兼容MongoDB协议,基于飞天分布式系统和高可靠存储引擎,提供多节点高可用架构、弹性扩容、容灾、备份恢复、性能优化等功能。
MongoDB的数据结构
MongoDB是面向文档的NoSQL(非关系型)数据库,它的数据结构由字段(Field)和值(Value)组成,类似于JSON对象,示例如下:
{
name:"张三",
sex:"男性",
age:30
}MongoDB的存储结构
MongoDB的存储结构区别于传统的关系型数据库,由如下三个单元组成:
-
文档(Document):MongoDB中最基本的单元,由BSON键值对(key-value)组成。相当于关系型数据库中的行(Row)。
-
集合(Collection):一个集合可以包含多个文档,相当于关系型数据库中的表格(Table)。
-
数据库(Database):等同于关系型数据库中的数据库概念,一个数据库中可以包含多个集合。您可以在MongoDB中创建多个数据库。
部署建议
您可以从以下维度考虑如何创建并使用MongoDB实例:
-
地域和可用区
地域指阿里云的数据中心,可用区是指在同一地域内,电力和网络互相独立的物理区域。地域和可用区决定了MongoDB实例所在的物理位置,一旦成功创建MongoDB实例后将无法更换地域。更多详情,请参见地域和可用区。
您可以从用户地理位置、阿里云产品发布情况、应用可用性以及是否需要内网通信等因素选择地域和可用区。例如,您的应用部署在云服务器ECS(Elastic Compute Service)上,需要使用MongoDB实例作为该应用的数据库,那么在创建MongoDB实例时,应当选择与ECS实例相同的地域和可用区。
同一可用区内的ECS实例和MongoDB实例通过内网连接时,网络延时最小。
-
网络规划
阿里云推荐您使用专有网络VPC,您可自行规划私网IP地址段。专有网络是一种隔离的网络环境,安全性和性能均高于传统的经典网络,您可以使用默认的专有网络,也可以自行事先创建,详情请参见新建实例场景下配置专有网络。
-
安全方案
针对用户重点关注的数据安全,云数据库MongoDB版提供了全面的安全保障。您可以通过同城容灾、RAM授权、审计日志、网络隔离、白名单、密码认证、透明数据加密TDE等多手段保障数据库数据安全。详情请参见云数据库MongoDB版数据安全最佳实践。
如何使用云数据库MongoDB版
您可以通过以下方式管理MongoDB实例,进行实例创建、网络设置、数据库创建、账号创建等操作:
创建MongoDB实例后,您可以通过以下方式访问MongoDB实例:
-
DMS:您可以通过DMS连接MongoDB副本集实例,在Web界面进行数据库开发工作。
-
Mongo Shell:MongoDB官方命令行工具,您可以通过Mongo Shell连接MongoDB副本集实例,对数据库进行管理操作。
-
客户端:云数据库MongoDB版完全兼容MongoDB协议,您可以使用通用的数据库客户端工具访问MongoDB实例。例如Robo 3T、Studio 3T等。
相关服务
-
ECS:云服务器ECS(Elastic Compute Service)通过内网访问同一地域的MongoDB实例时,可实现最佳性能。ECS搭配MongoDB实例是典型的业务访问架构。
-
DTS:您可以使用数据传输服务DTS(Data Transmission Service)将本地MongoDB数据库迁移上云。
-
OSS:对象存储服务OSS(Object Storage Service)是阿里云提供的海量、安全、低成本、高可靠的云存储服务。
-
DAS:数据库自治服务DAS(Database Autonomy Service)帮助企业打通混合云数据库架构,提供多环境统一管理、快速弹性、容灾切换的能力,您可以通过DAS查询云数据库MongoDB的实时性能和实时操作,分析慢日志、管理存储空间等操作。
-
DLA:云原生数据湖分析DLA(Data Lake Analytics)是新一代大数据解决方案,采取计算与存储完全分离的架构,提供弹性的Serverless SQL与Serverless Spark服务,满足在线交互式查询、流处理、批处理、机器学习等诉求。相关链接:
-
云HBase:云HBase是基于Apache HBase和HBase生态构建的低成本一站式数据处理平台,又称HBase X-Pack。云Spark分析引擎支持对接云数据库MongoDB版,提供分析MongoDB数据库的能力。
系统架构
系统架构图

主要组件说明
- 任务控制
MongoDB实例支持多种管理控制任务,如创建实例、变更配置以及备份实例等。任务系统会根据您下发的操作指令,进行灵活控制并进行任务跟踪及出错管理。
- HA控制系统
高可用探测模块,用于探测MongoDB实例的运行状况。如果判断主节点实例不可用,则切换主备节点并通知用户,您也可以手动切换主备节点,保障MongoDB实例的高可用。具体请参见切换主备节点并通知用户和切换节点角色。
- 日志收集系统
- 监控系统
收集MongoDB实例的性能监控信息,包括基础指标、磁盘容量、网络请求以及操作次数等核心信息。详情请参见基本监控和高级监控。
- 备份系统
针对MongoDB实例进行备份处理,将生成的备份文件存储至OSS(Object Storage Service)中。目前MongoDB备份系统支持用户自定义备份策略的自动备份和手动备份,保存7天内的备份文件。详情请参见自动备份MongoDB数据和手动备份MongoDB数据。
- 在线迁移系统
当实例所运行的物理机出现故障,在线迁移系统会根据备份系统中的备份文件重新搭建实例,保障业务不受影响。详情请参见数据迁移和同步方案概览。
副本集架构
云数据库MongoDB版自动搭建好副本集,您可以直接操作副本集中的主节点和从节点。容灾切换、故障迁移等高级功能为您整体打包好,实例使用过程中对您完全透明。
副本集架构
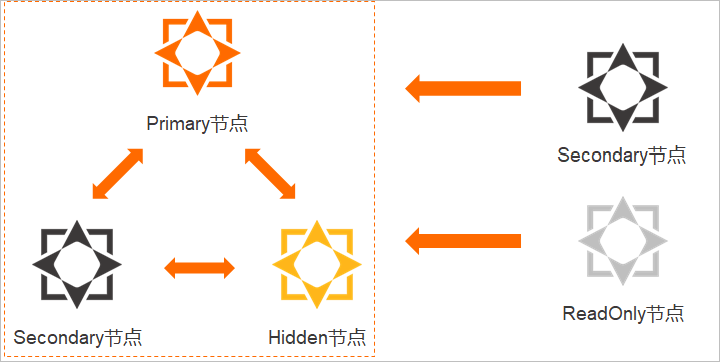
| 节点 | 功能 | 说明 |
|---|---|---|
| 主节点(Primary节点) | 负责读写操作的节点。 | 每个副本集实例中只能有一个主节点。 |
| 从节点(Secondary节点) | 通过操作日志(oplog)同步主节点的数据,可在主节点故障时通过选举成为新的主节点,保障高可用。 | 通过从节点的连接地址进行连接时,只能读取数据不能写入数据。 |
| 隐藏节点(Hidden节点) | 通过操作日志(oplog)同步主节点的数据,可在从节点故障时接替该故障节点成为新的从节点,也可在只读节点故障时接替该故障节点成为新的只读节点,保障高可用。 |
|
| 只读节点(ReadOnly节点) | 通过操作日志(oplog)从延迟最低的主节点或从节点同步数据,应用于有大量读请求的场景,以减轻主节点和从节点的访问压力。两个或以上只读节点可以使用ReadOnly Connection String URI连接实现读请求负载均衡。
说明 更多信息,请参见MongoDB只读节点简介。
|
|
分片集群架构
分片集群架构提供Mongos、Shard和ConfigServer三种组件。您可以自由选择Mongos和Shard的个数和配置,创建具备不同服务性能的MongoDB分片集群实例。
分片集群架构

| 组件名称 | 架构 | 说明 |
|---|---|---|
| Mongos | 单节点架构 |
负责将读写操作路由到对应Shard中。 您可以通过购买多个Mongos实现负载均衡及故障转移。单个分片集群实例默认支持最多32个Mongos,如果业务需要32个以上的Mongos,您可以提交工单申请。 |
| Shard | 副本集架构(主备三节点(主节点、从节点和隐藏节点)+只读节点) |
负责存储数据库数据。 您可以通过购买多个Shard来横向扩展实例的数据存储和读写并发能力。单个分片集群实例默认支持最多32个Shard,如果业务需要32个以上的Shard,您可以提交工单申请。 |
| ConfigServer | 副本集架构(三节点) |
负责存储Shard的元数据,即各Shard中包含哪些数据。 ConfigServer为固定配置,暂不支持修改。配置如下:
|
Serverless架构
MongoDB Serverless版通过租户ID和命名空间的方式在Mongos层面实现数据的逻辑隔离。
产品架构

- 如上图所示,在创建实例后,系统会在VPC中为用户申请虚拟IP(VIP),并使用该虚拟IP随机绑定代理资源池内固定的两个Mongos节点,在提供服务时,仅连接其中一个Mongos节点,当该Mongos节点故障无法访问时,系统会自动切换到另一个Mongos节点,同时故障节点会被自动修复挂起备用,保证服务的高可用。
- 通过租户ID(TenantID)+命名空间(Namespace)的方式在Mongos层面实现数据的逻辑隔离。
产品优势
云数据库MongoDB版(ApsaraDB for MongoDB)是阿里云基于飞天分布式系统和高可靠存储引擎研发的完全兼容MongoDB协议,并支持多节点高可用架构、弹性扩容、容灾、备份恢复、性能优化等功能的文档数据库服务。
灵活的部署架构
云数据库MongoDB版具有灵活的部署架构,能够满足不同的业务场景。云数据库MongoDB版不仅支持单节点、副本集和分片集群架构,还支持Serverless架构。MongoDB Serverless版具有资源用量低、简单易用、弹性灵活、价格低廉等优点,完美解决了MongoDB使用门槛高的问题,帮助中小客户轻松上云。
- 单节点架构
适用于开发、测试、学习培训及其他非企业核心数据存储的场景。您可以根据各类场景的差异适配对应的规格配置,为企业降低更多的成本支出。详情请参见单节点架构。
- 副本集架构
适用于读多写少或有临时活动的突发业务场景。副本集实例提供一个可供读写访问的Primary节点(主节点),一个、三个或五个提供高可用的Secondary节点(从节点),一个隐藏的Hidden节点(隐藏节点),0~5个可选的ReadOnly节点(只读节点)。您可以根据业务需要,按需增删Secondary节点和ReadOnly节点,更好地实现读取性能扩展节点。详情请参见副本集架构。
- 分片集群架构
适用于高并发读写的场景。分片集群实例是基于多个副本集(每个副本集使用三节点主从模式+0~5个只读节点)组成,提供Mongos、Shard、ConfigServer三个组件,您可以自由地选择Mongos和Shard节点的个数和配置,无限扩展性能及存储空间,组建不同能力的分片集群实例。详情请参见分片集群架构。
- Serverless架构
适用于中小型客户群体。Serverless形态提供代理、网络资源、命名空间、存储空间的垂直资源隔离能力,提供计算资源按需计费能力,具有资源用量低、简单易用、弹性灵活、价格低廉等优点,完美解决了MongoDB使用门槛高的问题,帮助中小客户轻松上云。详情请参见Serverless架构。
弹性扩容
云数据库MongoDB版提供了变更实例配置功能,方便您快速应对业务变化。您可以根据业务需要变更实例的配置(实例规格、存储空间和节点数量),您也可以设置变更配置的生效时间,将生效时间设置在业务低峰期,避免在变更配置过程中对业务造成影响。详情请参见变更配置方案概览。
应用场景
云数据库MongoDB版支持单节点、副本集和分片集群三种部署架构,具备安全审计、时间点备份等多项企业能力。在互联网、物联网、游戏、金融等领域被广泛采用。
读写分离应用
云数据库MongoDB采用三节点副本集的高可用架构,三个数据节点位于不同的物理服务器上,自动同步数据。Primary节点和Secondary节点提供服务,两个节点分别拥有独立域名,配合MongoDB Driver实现读取压力分配。关于架构说明的详情,请参见云数据库MongoDB系统架构。
灵活多变的业务场景
云数据库MongoDB采用No-Schema的方式,免去您变更表结构的痛苦,非常适用于初创型的业务需求。您可以将模式固定的结构化数据存储在RDS(Relational Database Service)中,模式灵活的业务存储在MongoDB中,高热数据存储在云数据库Redis或云数据库Memcache中,实现对业务数据高效存取,降低存储数据的投入成本。
移动应用
云数据库MongoDB支持二维空间索引,可以很好地支撑基于位置查询的移动类App的业务需求。同时MongoDB动态模式存储方式也非常适合存储多重系统的异构数据,满足移动App应用的需求。
物联网应用
云数据库MongoDB具有高性能和异步数据写入功能,特定场景下可达到内存数据库的处理能力。同时,云数据库MongoDB中的分片集群实例,可按需配置Mongos和Shard组件的配置和个数,性能及存储空间可实现无限扩展,非常适合物联网高并发写入的场景。详情请参见变更配置方案概览。
MongoDB提供二级索引功能满足动态查询的需求,利用MongoDB的map-reduce聚合框架进行多维度的数据分析。
其他各领域应用
- 游戏应用:使用云数据库MongoDB作为游戏服务器的数据库存储用户信息。用户的游戏装备、积分等直接以内嵌文档的形式存储,方便进行查询与更新。
- 物流应用:使用云数据库MongoDB存储订单信息,订单状态在运送过程中会不断更新,以云数据库MongoDB内嵌数组的形式来存储,一次查询就能将订单所有的变更读取出来,方便快捷且一目了然。
- 社交应用:使用云数据库MongoDB存储用户信息以及用户发表的朋友圈信息,通过地理位置索引实现附近的人、地点等功能。并且,云数据库MongoDB非常适合用来存储聊天记录,因为它提供了非常丰富的查询,并在写入和读取方面都相对较快。
- 视频直播:使用云数据库MongoDB存储用户信息、礼物信息等。
- 大数据应用:使用云数据库MongoDB作为大数据的云存储系统,随时进行数据提取分析,掌握行业动态。
什么是云数据库HBase
云数据库HBase是低成本、高扩展、云智能的大数据NoSQL,兼容标准HBase访问协议,提供低成本存储、高扩展吞吐、智能数据处理等核心能力,是为淘宝推荐、花呗风控、广告投放、监控大屏、菜鸟物流轨迹、支付宝账单、手淘消息等众多阿里巴巴核心服务提供支撑的数据库,具备PB规模、千万级并发、秒级伸缩、毫秒响应、跨机房高可用、全托管、全球分布等企业能力。
使用场景
| 代表场景 | 类型 | 存储对象 | 引擎接口 | 优势 |
|---|---|---|---|---|
| 社交分发或聊天信息等 | KV | key和value。 | HBase API | 延迟低、并发高。 |
| 传统关系型数据库升级 | SQL | 关系模型。 | SQL(参见Lindorm产品) | 存储量大、分布式SQL数据库。 |
| 风控或画像 | 表格存储 | 稀疏Table。 | HBase API | 动态Schema、存储量大。 |
| 新闻 | 文档存储 | JSON、XML或HTML。 | HBase API | 存储量大、并发高。 |
| 图片或视频 | 对象存储 | 图片、视频等。 | HBase API | 存储量大。 |
| 传感器或物联网 | 时序数据 | 时间维度的连续数据。 | OpenTSDB或HBase API | 存储量大。 |
| 车联网或运动App | 时空数据 | 有空间维度或轨迹。 | GeoMesa或HBase API | 存储量大,写入性能高。 |
| 全文查询 | 全文 | 全文。 | solr或HBase API | 吞吐量大。 |
产品优势
本文介绍HBase的优势。
| 类别 | 云数据库HBase增强版(Lindorm) | HBase开源版 | |
|---|---|---|---|
| 核心功能 | HBase API | 支持 | 支持 |
| 数据模型 | 支持宽列(HBase API)、表格(SQL-Like API)、队列等多种,对其他模型感兴趣的话,请联系我们。 | 仅支持宽列 | |
| 全局二级索引 | 内置,查询透明、高性能、按需冗余非索引列,请参见二级索引。 | 依赖外部组件,复杂。 | |
| 全文检索 | 智能集成搜索引擎Solr,提供面向海量数据的存储、多维查询、全文索引等统一访问的混合型能力,请参见全文索引服务。 | 不支持 | |
| 性能 | 吞吐性能 | 单机吞吐是开源HBase的7倍,请参见测试结果。 | 无优化 |
| 请求毛刺 | P99延迟是开源HBase的1/10,请参见测试结果。 | 无优化 | |
| 成本 | 数据压缩 | 深度优化的ZSTD算法,JNA重写,可杜绝Core dump,并且基于字典采样优化,压缩率比snappy提高50%,数据压缩比可高达10:1。 | 默认为Snappy,使用ZSTD需依赖Hadoop-3.0,存在Core Dump的概率。 |
| 编码 | IndexableDelta算法,相比DIFF算法,保持相同压缩率,访问速度快一倍。 | 推荐DIFF,随机访问较慢。 | |
| 冷热分离 | 冷热数据自动分层存储,冷数据使用高压缩和廉价存储介质,减少70%成本,热数据可提升访问性能15%,请参见冷热分离。 | 不支持 | |
| 存储介质 | 支持高效云盘、SSD云盘、本地HDD、本地SSD。支持冷存储(OSS)、容量型云盘(超性价比云盘,即将发布)。 | N/A | |
| 可靠性 | 主备双活 | 成熟,支持自动容灾切换、双集群请求并发等高级能力,支持与自建HBase构建混合主备,请参见主备双活。 | 无优化,不支持切换。 |
| 备份恢复 | 支持100TB+规模的数据备份至OSS,并提供与规模无关的RTO(<30分钟)、按需备份、指定时间点恢复等高级能力,请参见开通备份恢复。 | 不支持 | |
| MTTR | 深度优化,宕机恢复速度是开源HBase的10倍。 | 不支持 | |
| 多租户 | 认证与ACL | 支持易用的账号密码认证和ACL管理,请参见用户和ACL管理。 | 较复杂 |
| 资源隔离 | 支持RS Group功能,实现租户间的资源物理隔离。 | 不支持 | |
| 运维诊断 | 运维工具 | 界面化集群管理工具,支持表,Namespace,Group,ACL等管理,请参见集群管理系统。 | HBase Shell |
| 数据查询 | HBase Shell+集群管理系统内支持图形化SQL交互查询,请参见数据查询。 | HBase Shell | |
| 生态 | 数据搬迁 | 支持HBase各个版本之间的在线、跨版本、自动化、高效搬迁,应用零影响、零改造,请参见LTS(原BDS)服务介绍。 | 只能离线迁移 |
| MySQL数据同步 | 请参见LTS(原BDS)服务介绍,支持MySQL数据到HBase的全量同步、在线实时同步。 | 借助工具、不支持在线增量。 | |
| Spark分析 | 产品化深度集成,支持Spark SQL分析HBase,HBase数据到Spark(HDFS/OSS)的增量归档,离线分析结果回流到HBase等。 | 无优化,数据集成需要较大开发。 | |
| MaxCompute | 产品化集成,请参见全量导出MaxCompute。 | 数据集成需要较大开发。 | |
| 日志服务(SLS) | 请参见LTS(原BDS)服务介绍,支持SLS数据到HBase的日志服务(SLS)增量导入。 | 数据集成需要较大开发。 | |
| 服务能力 | 可用性SLA | 提供SLA保障,单集群99.9%,双集群高可用99.99%。 | N/A |
| 运维成本 | 全托管,无需复杂的数据库运维投入。 | N/A | |
| 技术团队 | 由多名Apache社区PMC&Committer组成的专家队伍提供技术服务支持。 | N/A | |
| 实践经验 | 支持9年天猫双十一,阿里部署上万台。 | N/A | |
与传统数据库对

应用场景
云数据库HBase是一个键值/宽表型的分布式数据库,适用于任何数据规模,可以提供单个毫秒响应的性能,尤其擅长低成本、高并发的场景,支持水平扩展到PB级存储和千万级QPS,在淘宝、支付宝、菜鸟等众多阿里巴巴核心服务中起到了关键支撑的作用。
背景
HBase的设计之初是为了满足互联网的大数据场景,几乎所有非强事务的结构化、半结构化的存储需求都可以使用HBase来满足。ApsaraDB for HBase是NoSQL(Not only SQL),也支持SQL及二级索引。
大数据场景
云数据库HBase支持海量全量数据的低成本存储、快速批量导入和实时访问,具备高效的增量及全量数据通道,可轻松与Spark、MaxCompute等大数据平台集成,完成数据的大规模离线分析。
- 低成本:高压缩比,数据冷热分离,支持HDD/OSS存储。
- 数据通道:通过BDS构建云HBase与异构计算系统的高效、易用的数据链路。
- 快速导入:通过BulkLoad将海量数据快速导入HBase,效率比传统方式提升一个数量级。
- 高并发:水平扩展至千万级QPS。
- 弹性:存储计算分离架构,支持独立伸缩,自动化扩容。
广告场景
使用云数据库HBase存储广告营销中的画像特征、用户事件、点击流、广告物料等重要数据,提供高并发、低延迟、灵活可靠的能力,帮助您构建领先的实时竞价、广告定位投放等系统服务。
- 低延迟:单个毫秒响应,支持双集群请求并发加速。
- 高并发:水平扩展至千万级QPS。
- 使用灵活:动态列,自由增减特征/标签属性;TTL,数据自动过期。
- 低成本:高压缩比,数据冷热分离,支持HDD/OSS存储。
- 数据通道:通过BDS构建云HBase与异构计算系统的高效、易用的数据链路。
- 高可用:主备双活容灾,请求自动容错,满足99.99% SLA。
车联网
使用云数据库HBase存储车联网中的行驶轨迹、车辆状况、精准定位等重要数据,提供低成本、弹性、灵活可靠的能力,帮助您构建领先的网约车、物流运输、新能源车检测等场景服务。
- 低成本:高压缩比,数据冷热分离,支持HDD/OSS存储。
- 弹性:存储计算分离架构,支持独立伸缩,自动化扩容。
- 使用灵活:动态列,自由增减特征/标签属性;TTL,数据自动过期;多版本。
- 数据通道:通过BDS构建云HBase与异构计算系统的高效、易用的数据链路。
- 低延迟:单个毫秒响应,支持双集群请求并发加速。
- 高可用:主备双活容灾,请求自动容错,满足99.99% SLA。
互联网
使用云数据库HBase存储社交场景中的聊天、评论、帖子、点赞等重要数据,提供易开发、高可用、延迟的能力,帮助您快速构建稳定可靠的现代社交Feed流系统。
金融和零售
使用云数据库HBase存储金融与零售交易中的海量订单记录,金融风控中的用户事件、画像特征、规则模型、设备指纹等重要数据,提供低成本、高并发、灵活可靠的能力,帮助您构建领先的金融交易与风控服务。
- 低成本:高压缩比,数据冷热分离,支持HDD/OSS存储。
- 高并发:水平扩展至千万级QPS。
- 使用灵活:动态列,自由增减特征/标签属性;TTL,数据自动过期;多版本。
- 低延迟:单个毫秒响应,支持双集群请求并发加速。
- 数据通道:通过BDS构建云HBase与异构计算系统的高效、易用的数据链路。
- 高可用:主备双活容灾,请求自动容错,满足99.99% SLA。
数据模型
在HBase中,数据存储在具有行和列的表中,这是与关系数据库(RDBMS)类似的模型,但与之不同的是其具备结构松散、多维有序映射的特点,它的索引排序键由行+列+时间戳组成,HBase表可以被看做一个“稀疏的、分布式的、持久的、多维度有序Map”。
总览

相关术语
- 命名空间(Namespace):对表的逻辑分组,类似于关系型数据库中的Database概念。Namespace可以帮助用户在多租户场景下做到更好的资源和数据隔离。
- 表(Table):HBase会将数据组织进一张张的表里面,一个HBase 表由多行组成。
- 行(Row):HBase中的一行包含一个行键和一个或多个与其相关的值的列。在存储行时,行按字母顺序排序。出于这个原因,行键的设计非常重要。目标是以相关行相互靠近的方式存储数据。常用的行键模式是网站域。如果你的行键是域名,则你可能应该将它们存储在相反的位置(org.apache.www,org.apache.mail,org.apache.jira)。这样表中的所有Apache域都彼此靠近,而不是根据子域的第一个字母分布。
- 列(Column) :HBase中的列由一个列族和一个列限定符组成,它们由冒号(:)字符分隔。
- 列族(Column Family) :由于性能原因,列族在物理上共同存在一组列和它们的值。在HBase中每个列族都有一组存储属性,例如其值是否应缓存在内存中,数据如何压缩或其行编码是如何编码的等等。表中的每一行都有相同的列族,但给定的行可能不会在给定的列族中存储任何内容。列族一旦确定后,就不能轻易修改,因为它会影响到HBase真实的物理存储结构,但是列族中的列标识(Column Qualifier)以及其对应的值可以动态增删。
- 列限定符(Column Qualifier) :列限定符被添加到列族中,以提供给定数据段的索引。鉴于列族的content,列限定符可能是content:html,而另一个可能是content:pdf。虽然列族在创建表时是固定的,但列限定符是可变的,并且在行之间可能差别很大。
- 单元格(Cell) :单元格是行、列族和列限定符的组合,并且包含值和时间戳,它表示值的版本。
- 时间戳(Timestamp) :时间戳与每个值一起编写,并且是给定版本的值的标识符。默认情况下,时间戳表示写入数据时RegionServer上的时间,但可以在将数据放入单元格时指定不同的时间戳值。
概念视图
本节示例是根据BigTable论文进行修改后的示例,在本节的示例中有一个名为表 webtable,其中包含两行(com.cnn.www 和 com.example.www)以及名为 contents、anchor 和 people 的三个列族。在本例中,对于第一行(com.cnn.www), anchor 包含两列(anchor:cssnsi.com,anchor:my.look.ca),并且 contents 包含一列(contents:html)。本示例包含具有行键 com.cnn.www 的行的5个版本,以及具有行键 com.example.www 的行的一个版本。contents:html 列限定符包含给定网站的整个 HTML。anchor列族的列限定符每个包含与该行所表示的站点链接的外部站点以及它在其链接的锚点中使用的文本。people 列族代表与该网站相关的人员。
列名称:按照约定,列名由其列族前缀和限定符组成。例如,列内容:html 由列族contents和html限定符组成。冒号(:)从列族限定符分隔列族。
webtable 表如下所示:
| Row Key | Time Stamp | ColumnFamily contents | ColumnFamily anchor | ColumnFamily people |
|---|---|---|---|---|
| “com.cnn.www” | T9 | (-) | anchor:cnnsi.com =“CNN” | (-) |
| “com.cnn.www” | T8 | (-) | anchor:my.look.ca =“CNN.com” | (-) |
| “com.cnn.www” | T6 | contents:html = “…” | (-) | (-) |
| “com.cnn.www” | T5 | contents:html = “…” | (-) | (-) |
| “com.cnn.www” | T3 | contents:html =“ ……” | (-) | (-) |
| “com.example.www” | T5 | contents:html =“ ……” | (-) | people:author =“John Doe” |
{
"com.cnn.www": {
contents: {
t6: contents:html: "<html>..."
t5: contents:html: "<html>..."
t3: contents:html: "<html>..."
}
anchor: {
t9: anchor:cnnsi.com = "CNN"
t8: anchor:my.look.ca = "CNN.com"
}
people: {}
}
"com.example.www": {
contents: {
t5: contents:html: "<html>..."
}
anchor: {}
people: {
t5: people:author: "John Doe"
}
}
}物理视图
尽管在HBase概念视图中,表格被视为一组稀疏的行的集合,但它们是按列族进行物理存储的。可以随时将新的列限定符(column_family:column_qualifier)添加到现有的列族。
ColumnFamily anchor:
| Row Key | Time Stamp | ColumnFamily anchor |
|---|---|---|
| “com.cnn.www” | T9 | anchor:cnnsi.com = “CNN” |
| “com.cnn.www” | T8 | anchor:my.look.ca = “CNN.com” |
ColumnFamily contents:
| Row Key | Time Stamp | ColumnFamily contents |
|---|---|---|
| “com.cnn.www” | T6 | contents:html = “…” |
| “com.cnn.www” | T5 | contents:html = “…” |
| “com.cnn.www” | T3 | contents:html = “…” |
HBase概念视图中显示的空单元根本不存储。因此,对时间戳为t8的contents:html列值的请求将不返回任何值。同样,在时间戳为t9中一个anchor:my.look.ca值的请求也不会返回任何值。但是,如果未提供时间戳,则会返回特定列的最新值。给定多个版本,最近的也是第一个找到的,因为时间戳按降序存储。因此,如果没有指定时间戳,则对行com.cnn.www中所有列的值的请求将是:时间戳t6中的contents:html,时间戳t9中anchor:cnnsi.com的值,时间戳t8中anchor:my.look.ca的值。
数据排序
所有数据模型操作HBase以排序顺序返回数据。首先按行,然后按列族(ColumnFamily),然后是列限定符,最后是时间戳(反向排序,因此首先返回最新的记录)。
列元数据
ColumnFamily的内部KeyValue实例之外不存储列元数据。因此,尽管HBase不仅可以支持每行大量的列数,而且还能对行之间的一组异构列进行维护,但您有责任跟踪列名。
获得ColumnFamily存在的一组完整列的唯一方法是处理所有行。
ACID
ACID,指数据库事务正确执行的四个基本要素的缩写,即:原子性(Atomicity),一致性(Consistency),隔离性(Isolation),持久性(Durability)。
HBase支持单行操作下的ACID,即对同一行的Put操作保证完全的ACID。
schema设计原则
前提条件
Configuration config = HBaseConfiguration.create();
HBaseAdmin admin = new HBaseAdmin(config);
String table = "Test";
admin.disableTable(table); // 将表下线
HColumnDescriptor f1 = ...;
admin.addColumn(table, f1); // 增加新的列簇
HColumnDescriptor f2 = ...;
admin.modifyColumn(table, f2); // 修改列簇
HColumnDescriptor f3 = ...;
admin.modifyColumn(table, f3); // 修改列簇
admin.enableTable(table);更新
当表或者列簇改变时(包括:编码方式、压力格式、block大小等等),都将会在下次major compaction时或者StoreFile重写时生效。
表模式设计经验
- 地域最大的阈值取值建议在8GB到50GB之间,不宜过小或过大。
- 单个cell不超过10MB,如果超过10MB,请使用mob,若再大可以直接存在HDFS中,在HBase内存储HDFS地址。
- 列簇数量不建议过多,一般1个即可,不建议超过3个。
- 列簇名应尽量简短,因为存储时每个value都包含列簇名(忽略前缀编码,prefix encoding)。
- 对于时序场景,建议rowkey设计为设备ID加上时间,如果采用“时间+设备ID”的方案会导致如下:
- 同一时间点的数据落入同一个地域,导致热点。
- 较早数据随着时间推移、数据过期会留下大量的空地域,带来不必要的开销。
列簇数量
- 现在HBase并不能很好的处理两个或者三个以上的列簇,所以尽量让列簇数量少一些。
- 目前, flush和compaction操作是针对一个地域。所以当一个列簇操作大量数据的时候会引发一个flush。邻近的列簇也有进行flush操作,尽管它们没有操作多少数据。
- compaction操作现在是根据一个列簇下的全部文件的数量触发的,而不是根据文件大小触发的。
- 当很多的列簇在flush和compaction时,会造成很多没用的I/O负载。
说明 减少没用的I/O负载需要将flush和compaction操作只针对一个列簇。
- 尽量在模式中只针对一个列簇操作。将使用率相近的列归为一列簇,这样每次访问时就只用访问一个列簇,提高效率。
列簇基数
如果一个表存在多个列簇,要注意列簇之间基数(如行数)相差不要太大。例如:列簇A有100万行,列簇B有10亿行,按照行键切分后,列簇A可能被分散到很多地域(及RegionServer),这导致扫描列簇A十分低效。
版本数量
行的版本的数量是HColumnDescriptor设置的,每个列簇可以单独设置,默认是3。这个设置是很重要的,因为HBase不会覆盖一个值,只会在值的后面进行追加描述,用时间戳来区分。过早的版本会在执行major compaction时删除,这些在HBase数据模型有描述。这个版本的值可以根据具体的应用增加或减少。不推荐将版本最大值设到一个很高的水平(100或更多),除非历史数据很重要,因为这会导致存储文件变得极大。
最小版本数
和行的最大版本数一样,最小版本数也是通过HColumnDescriptor在每个列簇中设置的。最小版本数缺省值是0,表示该特性禁用。 最小版本数参数和存活时间一起使用,允许配置如“保存最后T秒有价值数据,最多N个版本,但最少约M个版本”(M是最小版本数,M<N)。该参数仅在存活时间对列簇启用,且必须小于行版本数。
支持数据类型
HBase通过Put和Result支持bytes-in/bytes-out接口,所以任何可被转为字节数组的东西可以作为值存入。输入可以是字符串、数字、复杂对象、甚至图像,它们能转为字节。
存在值的实际长度限制,例如:保存10-50MB对象到HBase对查询来说太长,搜索邮件列表获取本话题的对话。HBase的所有行都遵循HBase数据模型包括版本化。设计时需考虑到以上限制以及列簇的块大小。
存活时间
列簇可以设置TTL秒数,HBase在超时后将自动删除数据,HBase里面TTL时间时区是UTC。
存储文件仅包含有过期的行(expired rows),它们可通过minor compaction删除。将hbase.store.delete.expired.storefile设置为false,可禁用此功能;将最小版本数设置成非0值也可达到同样的效果。
- Cell TTLs的数量级是毫秒而不是秒。
- 一个Cell TTL不能超出ColumnFamily TTLs设置的有效时间。
Rowkey设计
HBase的RowKey设计可以说是使用HBase最为重要的事情,直接影响到HBase的性能,常见的RowKey的设计问题及对应访问。
RowKey的行由行键按字典顺序排序,这样的设计优化了扫描,允许存储相关的行或者那些将被一起读的邻近的行。然而,设计不好的行键是导致 hotspotting 的常见原因。当大量的客户端流量( traffic )被定向在集群上的一个或几个节点时,就会发生 hotspotting。这些流量可能代表着读、写或其他操作。流量超过了承载该地域的单个机器所能负荷的量,这就会导致性能下降并有可能造成地域的不可用。在同一 RegionServer 上的其他地域也可能会受到其不良影响,因为主机无法提供服务所请求的负载。设计使集群能被充分均匀地使用的数据访问模式是至关重要的。
为了防止在写操作时出现hotspotting,设计行键时应该使得数据尽量同时往多个地域上写,而避免只向一个地域写,除非那些行真的有必要写在一个地域里。
下面介绍了集中常用的避免hotspotting的技巧,它们各有优劣。
Salting
Salting 从某种程度上看与加密无关,它指的是将随机数放在行键的起始处。进一步说,salting给每一行键随机指定了一个前缀来让它与其他行键有着不同的排序。所有可能前缀的数量对应于要分散数据的地域的数量。如果有几个“hot”的行键模式,而这些模式在其他更均匀分布的行里反复出现,salting就能到帮助。下面的例子说明了salting能在多个RegionServer间分散负载,同时也说明了它在读操作时候的负面影响。
假设行键的列表如下,表按照每个字母对应一个地域来分割。前缀‘a’是一个地域,‘b’就是另一个地域。在这张表中,所有以‘f’开头的行都属于同一个地域。这个例子关注的行和键如下:
foo0001
foo0002
foo0003
foo0004现在,假设想将它们分散到不同的地域上,就需要用到四种不同的salts :a,b,c,d。在这种情况下,每种字母前缀都对应着不同的一个地域。用上这些salts后,便有了下面这样的行键。由于现在想把它们分到四个独立的区域,理论上吞吐量会是之前写到同一地域的情况的吞吐量的四倍。
a-foo0003
b-foo0001
c-foo0004
d-foo0002如果想新增一行,新增的一行会被随机指定四个可能的salt值中的一个,并放在某条已存在的行的旁边。
a-foo0003
b-foo0001
c-foo0003
c-foo0004
d-foo0002由于前缀的指派是随机的,因而如果想要按照字典顺序找到这些行,则需要做更多的工作。从这个角度上看,salting增加了写操作的吞吐量,却也增大了读操作的开销。
Hashing
可用一个单向的 hash 散列来取代随机指派前缀。这样能使一个给定的行在“salted”时有相同的前缀,从某种程度上说,这在分散了RegionServer间的负载的同时,也允许在读操作时能够预测。确定性hash( deterministic hash )能让客户端重建完整的行键,以及像正常的一样用Get操作重新获得想要的行。
考虑和上述salting一样的情景,现在可以用单向hash来得到行键foo0003,并可预测得‘a’这个前缀。然后为了重新获得这一行,需要先知道它的键。可以进一步优化这一方法,如使得将特定的键对总是在相同的地域。
Reversing the Key(反转键)
第三种预防hotspotting的方法是反转一段固定长度或者可数的键,来让最常改变的部分(最低显著位, the least significant digit )在第一位,这样有效地打乱了行键,但是却牺牲了行排序的属性。
单调递增行键/时序数据
在一个集群中,一个导入数据的进程锁住不动,所有的client都在等待一个地域(因而也就是一个单个节点),过了一会后,变成了下一个地域。 如果使用了单调递增或者时序的key便会造成这样的问题。使用了顺序的key会将本没有顺序的数据变得有顺序,把负载压在一台机器上。所以要尽量避免时间戳或者序列(比如1, 2, 3)这样的行键。
如果需要导入时间顺序的文件(如log)到HBase中,可以学习OpenTSDB的做法。它有一个页面来描述它的HBase模式。OpenTSDB的Key的格式是[metric_type][event_timestamp],乍一看,这似乎违背了不能将timestamp做key的建议,但是它并没有将timestamp作为key的一个关键位置,有成百上千的metric_type就足够将压力分散到各个地域了。因此,尽管有着连续的数据输入流,Put操作依旧能被分散在表中的各个地域中。
简化行和列
在HBase中,值是作为一个单元保存在系统的中的,要定位一个单元,需要行,列名和时间戳。通常情况下,如果行和列的名字要是太大(甚至比value的大小还要大)的话,可能会遇到一些有趣的情况。在HBase的存储文件(storefiles)中,有一个索引用来方便值的随机访问,但是访问一个单元的坐标要是太大的话,会占用很大的内存,这个索引会被用尽。要想解决这个问题,可以设置一个更大的块大小,也可以使用更小的行和列名 。压缩也能得到更大指数。
大部分时候,细微的低效不会影响很大。但不幸的是,在这里却不能忽略。无论是列族、属性和行键都会在数据中重复上亿次。
列族
尽量使列族名小,最好一个字符。(如:f 表示)
属性
详细属性名(比如myVeryImportantAttribute)易读,最好还是用短属性名(比如via)保存到HBase。
行键长度
让行键短到可读即可,这样对获取数据有帮助(比如Get vs. Scan)。短键对访问数据无用,并不比长键对get或scan更好。设计行键需要权衡。
字节模式
long类型有8字节,8字节内可以保存无符号数字到18446744073709551615。 如果用字符串保存,假设一个字节一个字符,需要将近3倍的字节数。
示例代码如下所示。
// long
//
long l = 1234567890L;
byte[] lb = Bytes.toBytes(l);
System.out.println("long bytes length: " + lb.length); // returns 8
String s = String.valueOf(l);
byte[] sb = Bytes.toBytes(s);
System.out.println("long as string length: " + sb.length); // returns 10
// hash
//
MessageDigest md = MessageDigest.getInstance("MD5");
byte[] digest = md.digest(Bytes.toBytes(s));
System.out.println("md5 digest bytes length: " + digest.length); // returns 16
String sDigest = new String(digest);
byte[] sbDigest = Bytes.toBytes(sDigest);
System.out.println("md5 digest as string length: " + sbDigest.length); // returns 26不幸的是,用二进制表示会使数据在代码之外难以阅读。下例便是当需要增加一个值时会看到的Shell。
hbase(main):001:0> incr 't', 'r', 'f:q', 1
COUNTER VALUE = 1
hbase(main):002:0> get 't', 'r'
COLUMN CELL
f:q timestamp=1369163040570, value=\x00\x00\x00\x00\x00\x00\x00\x01
1 row(s) in 0.0310 seconds这个Shell尽力在打印一个字符串,但在这种情况下,它决定只将进制打印出来。当在地域名内行键会发生相同的情况。如果知道储存的是什么,那自是没问题,但当任意数据都可能被放到相同单元的时候,这将会变得难以阅读。这是最需要权衡之处。
倒序时间戳
一个数据库处理的通常问题是找到最近版本的值。采用倒序时间戳作为键的一部分可以对此特定情况有很大帮助。该技术包含追加(Long.MAX_VALUE - timestamp)到key的后面,如[key][reverse_timestamp] 。
表内[key]的最近的值可以用[key]进行Scan,找到并获取第一个记录。由于HBase行键是排序的,该键排在任何比它老的行键的前面,所以是第一个。
该技术可以用于代替版本数,其目的是保存所有版本到“永远”(或一段很长时间) 。同时,采用同样的Scan技术,可以很快获取其他版本。
行键和列族
行键在列族范围内。所以同样的行键可以在同一个表的每个列族中存在而不会冲突。
行键不可改
行键不能改变。唯一可以“改变”的方式是删除然后再插入。这是一个常问问题,所以要注意开始就要让行键正确(且/或在插入很多数据之前)。
行键和地域split的关系
如果已经 pre-split(预裂)了表,接下来关键要了解行键是如何在地域边界分布的。为了说明为什么这很重要,可考虑用可显示的16位字符作为键的关键位置(比如“0000000000000000” to “ffffffffffffffff”)这个例子。通过Bytes.split来分割键的范围(这是当用 Admin.createTable(byte[] startKey, byte[] endKey, numRegions)创建地域时的一种拆分手段),这样会分得10个地域。
48 48 48 48 48 48 48 48 48 48 48 48 48 48 48 48 // 0
54 -10 -10 -10 -10 -10 -10 -10 -10 -10 -10 -10 -10 -10 -10 -10 // 6
61 -67 -67 -67 -67 -67 -67 -67 -67 -67 -67 -67 -67 -67 -67 -68 // =
68 -124 -124 -124 -124 -124 -124 -124 -124 -124 -124 -124 -124 -124 -124 -126 // D
75 75 75 75 75 75 75 75 75 75 75 75 75 75 75 72 // K
82 18 18 18 18 18 18 18 18 18 18 18 18 18 18 14 // R
88 -40 -40 -40 -40 -40 -40 -40 -40 -40 -40 -40 -40 -40 -40 -44 // X
95 -97 -97 -97 -97 -97 -97 -97 -97 -97 -97 -97 -97 -97 -97 -102 // _
102 102 102 102 102 102 102 102 102 102 102 102 102 102 102 102 // f但问题在于,数据将会堆放在前两个地域以及最后一个地域,这样就会导致某几个地域由于数据分布不均匀而特别忙。为了理解其中缘由,需要考虑ASCII Table的结构。根据ASCII表,“0”是第48号,“f”是102号;但58到96号是个巨大的间隙,考虑到在这里仅[0-9]和[a-f]这些值是有意义的,因而这个区间里的值不会出现在键空间( keyspace ),进而中间区域的地域将永远不会用到。为了pre-split这个例子中的键空间,需要自定义拆分。
教程1:预裂表( pre-splitting tables ) 是个很好的实践,但pre-split时要注意使得所有的地域都能在键空间中找到对应。尽管例子中解决的问题是关于16位键的键空间,但其他任何空间也是同样的道理。
教程2:16位键(通常用到可显示的数据中)尽管通常不可取,但只要所有的地域都能在键空间找到对应,它依旧能和预裂表配合使用。
以下代码说明如何16位键预分区。
public static boolean createTable(Admin admin, HTableDescriptor table, byte[][] splits)
throws IOException {
try {
admin.createTable( table, splits );
return true;
} catch (TableExistsException e) {
logger.info("table " + table.getNameAsString() + " already exists");
// the table already exists...
return false;
}
}
public static byte[][] getHexSplits(String startKey, String endKey, int numRegions) {
byte[][] splits = new byte[numRegions-1][];
BigInteger lowestKey = new BigInteger(startKey, 16);
BigInteger highestKey = new BigInteger(endKey, 16);
BigInteger range = highestKey.subtract(lowestKey);
BigInteger regionIncrement = range.divide(BigInteger.valueOf(numRegions));
lowestKey = lowestKey.add(regionIncrement);
for(int i=0; i < numRegions-1;i++) {
BigInteger key = lowestKey.add(regionIncrement.multiply(BigInteger.valueOf(i)));
byte[] b = String.format("%016x", key).getBytes();
splits[i] = b;
}
return splits;
}时间序列数据库 TSDB
时间序列数据库 (Time Series Database , 简称 TSDB) 是一种高性能、低成本、稳定可靠的在线时间序列数据库服务,提供高效读写、高压缩比存储、时序数据插值及聚合计算等服务,广泛应用于物联网(IoT)设备监控系统、企业能源管理系统(EMS)、生产安全监控系统和电力检测系统等行业场景;除此以外,还提供时空场景的查询和分析的能力。
TSDB 具备秒级写入百万级时序数据的性能,提供高压缩比低成本存储、预降采样、插值、多维聚合计算、可视化查询结果等功能,解决由设备采集点数量巨大、数据采集频率高造成的存储成本高、写入和查询分析效率低的问题。
TSDB是一个分布式时间序列数据库,具备多副本高可用能力。同时在高负载大规模数据量的情况下可以方便地进行弹性扩容,方便用户结合业务流量特点进行动态规划与调整。
应用场景
背景信息
-
时间序列数据库 TSDB :英文全称为 Time Series Database,提供高效存取时序数据和统计分析功能的数据管理系统。
-
时序数据(Time Series Data):基于稳定频率持续产生的一系列指标监测数据。例如,监测某城市的空气质量时,每秒采集一个二氧化硫浓度的值而产生的一系列数据。
-
度量(Metric):监测数据的指标,例如风力和温度。
-
标签(Tag):度量(Metric)虽然指明了要监测的指标项,但没有指明要针对什么对象的该指标项进行监测。标签(Tag)就是用于表明指标项监测针对的具体对象,属于指定度量下的数据子类别。
一个标签(Tag)由一个标签键(TagKey)和一个对应的标签值(TagValue)组成,例如“城市(TagKey)= 杭州(TagValue)”就是一个标签(Tag)。更多标签示例:机房 = A 、IP = 172.220.XX.XX。
注意:当标签键和标签值都相同才算同一个标签;标签键相同,标签值不同,则不是同一个标签。
在监测数据的时候,指定度量是“气温”,标签是“城市 = 杭州”,则监测的就是杭州市的气温。
-
标签键(TagKey,Tagk):为指标项(Metric)监测指定的对象类型(会有对应的标签值来定位该对象类型下的具体对象),例如国家、省份、城市、机房、IP 等。
-
标签值(TagValue,Tagv):标签键(TagKey)对应的值。例如,当标签键(TagKey)是“国家”时,可指定标签值(TagValue)为“中国”。
-
值(Value):度量对应的值,例如 15 级(风力)和 20 ℃(温度)。
-
时间戳(Timestamp):数据(度量值)产生的时间点。
-
数据点 (Data Point):针对监测对象的某项指标(由度量和标签定义)按特定时间间隔(连续的时间戳)采集的每个度量值就是一个数据点。“一个度量 + N 个标签(N >= 1)+ 一个时间戳 + 一个值”定义一个数据点。
-
时间序列(Time Series):针对某个监测对象的某项指标(由度量和标签定义)的描述。“一个度量 + N 个标签KV组合(N >= 1)”定义为一个时间序列,某个时间序列上产生的数据值的增加,不会导致时间序列的增加。 时间序列的示意图如下:
![]()
-
时间线(Timeline):等同于时间序列的概念。
-
时间精度:时间线数据的写入时间精度——毫秒、秒、分钟、小时或者其他稳定时间频度。例如,每秒一个温度数据的采集频度,每 5 分钟一个CPU使用率的采集频度。
-
数据组(Data Group):如果需要对比不同监测对象(由标签定义)的同一指标(由度量定义)的数据,可以按标签这些数据分成不同的数据组。例如,将温度指标数据按照不同城市进行分组查询,操作类似于该 SQL 语句:
select avg(temperature),city from xx where xx group by city。 -
聚合( Aggregation):当同一个度量(Metric)的查询有多条时间线产生(多个指标采集设备),那么为了将空间的多维数据展现为成同一条时间线,需要进行合并计算,例如,当选定了某个城市某个城区的污染指数时,通常将各个环境监测点的指标数据平均值作为最终区域的指标数据,这个计算过程就是空间聚合。
-
降采样(Downsampling):当查询的时间区间跨度较长而原始数据时间精度较细时,为了满足业务需求的场景、提升查询效率,就会降低数据的查询展现精度,这就叫做降采样,比如按秒采集一年的数据,按照天级别查询展现。
-
数据时效(Data’s Validity Period):数据时效是设置的数据的实际有效期,超过有效期的数据会被自动释放。

物联网设备无时无刻不在产生海量的设备状态数据和业务消息数据,这些数据有助于进行设备监控、业务分析预测和故障诊断。
背景信息
设备将原始数据通过 MQTT 协议发送到物联网平台,经由物联网平台将数据转发到消息服务系统,继而通过流计算系统对这些数据进行实时计算处理后写入到 TSDB 中存储,或者经由物联网平台直接将原始数据写入 TSDB 中存储。前端的监控系统和大数据处理系统会利用 TSDB 的数据查询和计算分析能力进行业务监控和分析结果的实时展现。

电力化工及工业制造监控分析
传统电力化工以及工业制造行业需要通过实时的监控系统进行设备状态检测,故障发现以及业务趋势分析。
设备通过工业接口协议将自身状态数据和生产业务数据接入工业设备网关,然后通过 MQTT 协议发送到物联网平台,继而传输到云上的消息服务系统并经过流计算系统处理后写入 TSDB,完成时序数据的存储和分析。

系统运维和业务实时监控
通过对大规模应用集群和机房设备的监控,实时关注设备运行状态、资源利用率和业务趋势,实现数据化运营和自动化开发运维。
通过日志或者其他方式对原始指标数据进行采集和实时计算,最后将实时计算的结果数据存储到 TSDB,实现监控和分析的展现。

产品功能
TSDB 提供时序数据的高效读写。对于百万数据点的读取,响应时间小于 5 秒,且最高可以支撑每秒千万数据点的写入。
-
数据写入
TSDB 支持通过 HTTP 协议和 TSDB Java Client 两种方式进行数据写入。
-
数据查询
TSDB 支持通过 HTTP 协议、TSDB Java Client 以及 TSDB 控制台三种方式进行数据的查询操作。您也可以通过 TSDB 产品控制台的数据查询功能进行数据分组、降采样、空间聚合的可视化数据查询展现。
数据管理
-
数据时效设置
您可以通过控制台或者 API 设置数据的有效期。数据时效开启并设置完成后,系统对于定义的过期数据将立即标记失效,并在特定时间进行自动化清理。
-
数据清理
您可以在控制台上根据度量(Metric)进行数据清理,或者通过 API 进行更灵活的数据清理。
高效压缩存储
TSDB 使用高效的数据压缩技术,将单个数据点的平均使用存储空间降为1~2个字节,可以降低90%存储使用空间,同时加快数据写入的速度。
时序数据计算能力
TSDB 提供专业全面的时序数据计算函数,支持降采样、数据插值和空间聚合计算,能满足各种复杂的业务数据查询场景。
监控运维
TSDB 提供实例运维系统,让您可以实时的掌握实例的运行情况、性能指标和存储空间使用情况,并通过设置报警通道,实时发现资源瓶颈。
数据和实例安全
TSDB 提供以下方案保证您的数据和实例的安全:
- 提供 VPC 的实例访问方式,充分保证实例访问的安全性。
- 提供网络白名单功能:您可以通过设置允许访问实例的机器名单,进一步保证实例和数据的访问安全。如果一台机器在 VPC 内部,但不在设置的白名单内,则不能访问实例。
- TSDB 的数据存储默认采取三副本策略,充分保证数据的可用性。
流计算支持
TSDB 已与阿里云流计算(StreamCompute)产品集成。详细的集成说明请参见创建时序数据库结果表
TSDB 实例支持通过 HTTP 协议进行数据写入和查询等操作。
TSDB 提供了一个基于 HTTP 的应用程序编程接口,以便与外部系统集成。几乎所有 TSDB 的特性都可以通过 API 来访问,比如查询时间序列数据、管理元数据和存储数据点。TSDB 的 HTTP API 本质上是 RESTful 的,同时也提供了替代访问策略,因为不是所有 client 都可以遵循严格的 REST 协议。默认数据交换是通过 JSON。所有返回的结果都使用标准的 HTTP 响应代码,并使用特定的格式返回错误。
下表列出了 TSDB 提供的与数据读写和管理相关的所有 API。关于如何使用每个 API 的具体说明,请点击描述中提供的链接查看相应文档。
| API | 描述 |
|---|---|
| /api/put | 写入数据 |
| /api/query | 查询数据 |
| /api/query/last | 查询时间线最新数据点 |
| /api/mput | 多值写入 |
| /api/mquery | 多值查询 |
| /api/query/mlast | 多值查询最新数据点 |
| /api/suggest | 查询 Metric,Tagk,Tagv ,Field |
| /api/dump_meta | 查询 Tagk 下的 Tagv |
| /api/ttl | 设置数据时效 |
| /api/delete_data | 清理数据 |
| /api/delete_meta | 清理时间线 |
时序数据库 InfluxDB® 版
时序数据库 InfluxDB®版是一款专门处理高写入和查询负载的时序数据库,用于存储大规模的时序数据并进行实时分析,包括来自DevOps监控、应用指标和IoT传感器上的数据。
主要特点
InfluxDB®是您处理时序数据的一个绝佳选择,目前有以下特点:
-
专为时间序列数据量身打造的高性能数据存储。TSM引擎提供数据高速读写和压缩等功能。
-
简单高效的HTTP API写入和查询接口。
-
针对时序数据,量身打造类似SQL的查询语言,轻松查询聚合数据。
-
允许对tag建索引,实现快速有效的查询。
-
数据保留策略(Retention policies)能够有效地使旧数据自动失效。
HTTP API
TSDB For InfluxDB®提供了一种与数据库进行交互的简易方法,它使用了HTTP响应码、HTTP认证、JWT令牌和基本(basic)认证,并以JSON格式返回结果。
以下章节假设TSDB For InfluxDB®实例运行在<网络地址>上,端口为3242,并且开启HTTPS。
TSDB For InfluxDB® HTTP路径(endpoint)
|
路径 |
描述 |
|---|---|
|
/debug/pprof |
使用 |
|
/debug/requests |
使用 |
|
/debug/vars |
使用 |
|
/ping |
使用 |
|
/query |
使用 |
|
/write |
使用 |
什么是图数据库GDB
图数据库(Graph Database,简称GDB)是一种支持Property Graph图模型、用于处理高度连接数据查询与存储的实时、可靠的在线数据库服务。它支持Apache TinkerPop Gremlin查询语言,可以帮您快速构建基于高度连接的数据集的应用程序。
图数据库GDB非常适合社交网络、欺诈检测、推荐引擎、实时图谱、网络/IT运营这类高度互连数据集的场景。例如,在一个典型的社交网络中,常常会存在“谁认识谁,上过什么学校,常住什么地方,喜欢什么餐馆”之类的查询,传统关系型数据库对于超过3张表关联的查询十分低效难以胜任,但图数据库可轻松应对社交网络的各种复杂存储和查询场景。
产品优势
- 标准图查询语言
支持属性图,高度兼容Gremlin图查询语言和OpenCypher图查询语言。
- 高度优化的自研引擎
高度优化的自研图计算层和存储层,云盘多副本保障数据超高可靠,支持ACID事务。
- 服务高可用
支持高可用实例,节点故障自动切换,保障业务连续性。
- 易运维
提供备份恢复、自动升级、监控告警、故障切换等丰富的运维功能,大幅降低运维成本。
图数据库与传统关系型数据库相比的优势
传统的关系型数据库和图数据库无论是在模型,存储以及查询优化上都存在极大的差异。比如社交用户关系中的2度查询请求,传统关系型数据库处理起来至少是秒级别的,3度查询更差甚至无法支持。
| 分类 | 图数据库 | 关系型数据库 |
|---|---|---|
| 模型 | 图结构 | 表结构 |
| 存储信息 | 结构化/半结构化数据库 | 高度结构化数据 |
| 2度查询 | 高效 | 低效 |
| 3度查询 | 高效 | 低效/不支持 |
| 空间占用 | 高 | 中 |
产品优势
兼容并包,集多种图查询语言于一身
高度兼容Neo4j、JanusGraph等图数据库引擎,支持 OpenCypher 、Gremlin 查询语言,降低迁移成本和研发门槛。
快速弹性、高可用、易运维、尽享云原生技术惠普
基于云原生架构的图数据库引擎,可快速扩缩容,应对突增业务负载;支持高可用实例、节点故障自动切换,保障业务连续性;提供备份恢复、自动升级、监控告警、故障切换等丰富的运维功能,免去繁琐的运维烦恼。
应用场景
图数据库GDB针对高度互联数据的存储和查询场景进行设计,并在内核层面进行了大量优化,非常适合营收增长、金融风控、商品推荐、社交推荐、循环担保检测、异常指标监控和违规团伙挖掘等场景。
营收增长

金融风控

商品推荐

社交推荐

循环担保检测
金融场景中,债权人所持有的债券是否超过检测抵押物多次担保的价值,对于风险控制尤为重要。图计算中的环检测算法为核心,找到图中闭环连接,帮助金融机构发现抵押物和债权人之间的深层关联关系,从而实现降低风控成本的目的。
异常指标监控
交易如电子支付、移动支付发展的同时,也带来了更为严峻的交易安全问题。为防止违法金融行为带来经济损失,通过使用异常检测算法在网络金融交易领域的应用,准确识别网络金融交易中存在的异常交易情况,及时阻止违法金融行为。通过图数据库,识别支付用户的设备信息、支付环境信息、转账信息、社交信息,检测可能出现的异常风险,提高支付的安全性。
违规团伙挖掘
很多平台上都有团伙作案的场景出现,如团伙性信用卡套现、羊毛党,甚至于团伙性的违法、犯罪性活动。团伙性作案的核心特征是,其成员之间具备某种关联关系,或行为之间具备某些相似特征。通过图结合机器学习的方式,提取团伙关系图谱之中的拓扑关系信息,以已知团伙信息作为样本,训练机器学习模型,针对目标节点进行分类,或其关系进行预测。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号