阿里云-存储
https://www.aliyun.com/storage/storage?spm=5176.21040285.J_3207526240.19.56316908YSIhtV

什么是云服务器ECS
为什么选择云服务器ECS
选择云服务器ECS,您可以轻松构建具有以下优势的计算资源:
- 无需自建机房,无需采购以及配置硬件设施。
- 分钟级交付,快速部署,缩短应用上线周期。
- 快速接入部署在全球范围内的数据中心和边界网关协议BGP(Border Gateway Protocol)机房。
- 成本透明,按需使用,支持根据业务波动随时扩展和释放资源。
- 提供GPU和FPGA等异构计算服务器、弹性裸金属服务器以及通用的x86架构服务器。
- 支持通过内网访问其他阿里云服务,形成丰富的行业解决方案,降低公网流量成本。
- 提供虚拟防火墙、角色权限控制、内网隔离、防病毒攻击及流量监控等多重安全方案。
- 提供性能监控框架和主动运维体系。
- 提供行业通用标准API,提高易用性和适用性。
更多选择理由,请参见云服务器ECS的优势和应用场景。
产品架构
云服务器ECS主要包含以下功能组件:
- 实例:云上的虚拟计算服务器,内含vCPU、内存、操作系统、网络、磁盘等基础组件。实例的计算性能、内存性能和适用业务场景由实例规格决定,其具体性能指标包括实例vCPU核数、内存大小、网络性能等。
- 镜像:提供实例的操作系统、初始化应用数据及预装的软件。操作系统支持多种Linux发行版和多种Windows Server版本。
- 块存储:块设备类型产品,具备高性能和低时延的特性。提供基于分布式存储架构的云盘以及基于物理机本地存储的本地盘。
- 快照:某一时间点云盘的数据状态文件。常用于数据备份、数据恢复和制作自定义镜像等。
- 安全组:由同一地域内具有相同保护需求并相互信任的实例组成,是一种虚拟防火墙,用于设置实例的网络访问控制。
- 网络:
- 专有网络(Virtual Private Cloud):逻辑上彻底隔离的云上私有网络。您可以自行分配私网IP地址范围、配置路由表和网关等。
- 经典网络:所有经典网络类型实例都建立在一个共用的基础网络上。由阿里云统一规划和管理网络配置。
更多功能组件详情,请参见云服务器ECS产品详情页。

产品计费
云服务器ECS的资源中,计算资源(vCPU和内存)、镜像、块存储、公网带宽、快照等资源涉及计费。
- 包年包月:按一定时长购买资源,先付费后使用。
- 按量付费:按需开通和释放资源,先使用后付费。
- 抢占式实例:通过竞价模式抢占库存充足的计算资源,相对按量付费实例有一定的折扣,但是存在回收机制。
- 预留实例券:搭配按量付费实例使用的抵扣券,承诺使用指定配置的实例(包括实例规格、地域可用区等),以折扣价抵扣计算资源的账单。
- 节省计划:搭配按量付费实例使用的折扣权益计划,承诺使用稳定数量的资源(以元/小时为单位衡量),以折扣价抵扣计算资源、系统盘等资源的账单。
- 存储容量单位包:搭配按量付费存储产品使用的资源包,承诺使用指定容量的存储资源,以折扣价抵扣块存储、NAS、OSS等资源的账单。
详细的计费规则,请参见计费概述。详细的价格信息,请参见云产品定价页。如果想了解最新的活动,请参见云服务器ECS产品详情页。
管理工具
通过注册阿里云账号,您可以在任何地域下,通过阿里云提供的以下途径创建、使用或者释放云服务器ECS:
- ECS管理控制台:具有交互式操作的Web服务页面。关于管理控制台的操作,请参见常用操作导航。
- ECS API:支持GET和POST请求的RPC风格API。关于API说明,请参见API参考。以下为调用云服务器ECS API的常用开发者工具:
- 命令行工具CLI:基于阿里云API建立的灵活且易于扩展的管理工具。您可基于命令行工具封装阿里云的原生API,扩展出您需要的功能。
- OpenAPI开发者门户:提供快速检索接口、在线调用API和动态生成SDK示例代码等服务。
- 阿里云SDK:提供Java、Python、PHP等多种编程语言的SDK。
- 资源编排(Resource Orchestration Service):通过创建一个描述您所需的所有阿里云资源的模板,然后资源编排将根据模板,自动创建和配置资源。
- 运维编排服务(Operation Orchestration Service):自动化管理和执行运维任务。您可以在执行模板中定义执行任务、执行顺序、执行输入和输出等,通过执行模板达到自动化完成运维任务的目的。
- Terraform:能够通过配置文件在阿里云以及其他支持Terraform的云商平台调用计算资源,并对其进行版本控制的开源工具。
- 阿里云App:移动端类型的管理工具。
- Alibaba Cloud Toolkit:阿里云针对IDE平台为开发者提供的一款插件,用于帮助您高效开发并部署适合在云端运行的应用。
部署建议
您可以从以下维度考虑如何启动并使用云服务器ECS:
- 地域和可用区
地域指阿里云的数据中心,地域和可用区决定了ECS实例所在的物理位置。一旦成功创建实例后,其元数据(仅专有网络VPC类型ECS实例支持获取元数据)将确定下来,并无法更换地域。您可以从用户地理位置、阿里云产品发布情况、应用可用性、以及是否需要内网通信等因素选择地域和可用区。例如,如果您同时需要通过阿里云内网使用云数据库RDS,RDS实例和ECS实例必须处于同一地域中。更多详情,请参见地域和可用区。
- 高可用性
为保证业务处理的正确性和服务不中断,建议您通过快照实现数据备份,通过跨可用区、部署集、负载均衡(Server Load Balancer)等实现应用容灾。
- 网络规划
阿里云推荐您使用专有网络VPC,可自行规划私网IP,全面支持新功能和新型实例规格。此外,专有网络VPC支持多业务系统隔离和多地域部署系统的使用场景。更多详情,请参见专有网络(Virtual Private Cloud)。
- 安全方案
相关服务
使用云服务器ECS的同时,您还可以选择以下阿里云服务:
- 根据业务需求和策略的变化,使用弹性伸缩(Auto Scaling)自动调整云服务器ECS的数量。更多详情,请参见弹性伸缩。
- 使用专有宿主机(Dedicated Host)部署ECS实例,可让您独享物理服务器资源、降低上云和业务部署调整的成本、满足严格的合规和监管要求。更多详情,请参见专有宿主机DDH。
- 使用容器服务Kubernetes版在一组云服务器ECS上通过Docker容器管理应用生命周期。更多详情,请参见容器服务Kubernetes版。
- 通过负载均衡(Server Load Balancer)对多台云服务器ECS实现流量分发的负载均衡目的。更多详情,请参见负载均衡。
- 通过云监控(CloudMonitor)制定实例、系统盘和公网带宽等的监控方案。更多详情,请参见云监控。
- 在同一阿里云地域下,采用关系型云数据库(Relational Database Service)作为云服务器ECS的数据库应用是典型的业务访问架构,可极大降低网络延时和公网访问费用,并实现云数据库RDS的最佳性能。云数据库RDS支持多种数据库引擎,包括MySQL、SQL Server、PostgreSQL、PPAS和MariaDB。更多详情,请参见关系型云数据库。
- 在云市场获取由第三方服务商提供的基础软件、企业软件、网站建设、代运维、云安全、数据及API、解决方案等相关的各类软件和服务。您也可以成为云市场服务供应商,提供软件应用及服务。更多详情,请参见云市场文档。
什么是对象存储OSS
阿里云对象存储OSS(Object Storage Service)是一款海量、安全、低成本、高可靠的云存储服务,可提供99.9999999999%(12个9)的数据持久性,99.995%的数据可用性。多种存储类型供选择,全面优化存储成本。
OSS具有与平台无关的RESTful API接口,您可以在任何应用、任何时间、任何地点存储和访问任意类型的数据。
您可以使用阿里云提供的API、SDK接口或者OSS迁移工具轻松地将海量数据移入或移出阿里云OSS。数据存储到阿里云OSS以后,您可以选择标准存储(Standard)作为移动应用、大型网站、图片分享或热点音视频的主要存储方式,也可以选择成本更低、存储期限更长的低频访问存储(Infrequent Access)、归档存储(Archive)、冷归档存储(Cold Archive)作为不经常访问数据的存储方式。
OSS相关概念
- 存储类型(Storage Class)
OSS提供标准、低频访问、归档、冷归档四种存储类型,全面覆盖从热到冷的各种数据存储场景。其中标准存储类型提供高持久、高可用、高性能的对象存储服务,能够支持频繁的数据访问;低频访问存储类型适合长期保存不经常访问的数据(平均每月访问频率1到2次),存储单价低于标准类型;归档存储类型适合需要长期保存(建议半年以上)的归档数据;冷归档存储适合需要超长时间存放的极冷数据。更多信息,请参见存储类型介绍。
- 存储空间(Bucket)
存储空间是您用于存储对象(Object)的容器,所有的对象都必须隶属于某个存储空间。存储空间具有各种配置属性,包括地域、访问权限、存储类型等。您可以根据实际需求,创建不同类型的存储空间来存储不同的数据。
- 对象(Object)
对象是OSS存储数据的基本单元,也被称为OSS的文件。对象由元信息(Object Meta)、用户数据(Data)和文件名(Key)组成。对象由存储空间内部唯一的Key来标识。对象元信息是一组键值对,表示了对象的一些属性,例如最后修改时间、大小等信息,同时您也可以在元信息中存储一些自定义的信息。
- 地域(Region)
地域表示OSS的数据中心所在物理位置。您可以根据费用、请求来源等选择合适的地域创建Bucket。更多信息,请参见OSS已开通的地域。
- 访问域名(Endpoint)
Endpoint表示OSS对外服务的访问域名。OSS以HTTP RESTful API的形式对外提供服务,当访问不同地域的时候,需要不同的域名。通过内网和外网访问同一个地域所需要的域名也是不同的。更多信息,请参见各个Region对应的Endpoint。
- 访问密钥(AccessKey)
AccessKey简称AK,指的是访问身份验证中用到的AccessKey ID和AccessKey Secret。OSS通过使用AccessKey ID和AccessKey Secret对称加密的方法来验证某个请求的发送者身份。AccessKey ID用于标识用户;AccessKey Secret是用户用于加密签名字符串和OSS用来验证签名字符串的密钥,必须保密。关于获取AccessKey的方法,请参见获取AccessKey。
OSS常见操作
- 创建Bucket
在上传文件(Object)到OSS之前,您需要创建一个用于存储文件的Bucket。Bucket具有各种配置属性,包括地域、访问权限以及其他元数据。创建Bucket的具体操作,请参见创建存储空间。
- 上传文件
Bucket创建完成后,您可以通过多种方式上传不同大小的文件。有关上传文件的具体操作,请参见上传文件。
- 下载文件
文件上传完成后,您可以将文件下载至浏览器默认路径或本地指定路径。有关下载文件的具体操作,请参见下载文件。
- 列举文件
当您Bucket内存储了大量的文件后,您可以选择列举Bucket内的全部或部分文件。有关列举文件的具体操作,请参见列举文件。
- 删除文件
当您不再需要保留上传的文件时,您可以手动删除单个或多个文件,也可以通过配置生命周期规则自动删除单个或多个文件。有关删除文件的具体操作,请参见删除文件。
OSS重要特性
- 版本控制
版本控制是针对存储空间(Bucket)级别的数据保护功能。开启版本控制后,针对数据的覆盖和删除操作将会以历史版本的形式保存下来。您在错误覆盖或者删除文件(Object)后,能够将Bucket中存储的Object恢复至任意时刻的历史版本。有关版本控制的更多信息,请参见版本控制介绍。
- Bucket Policy
Bucket拥有者可通过Bucket Policy授权不同用户以何种权限访问指定的OSS资源。例如您需要进行跨账号或对匿名用户授权访问或管理整个Bucket或Bucket内的部分资源,或者需要对同账号下的不同RAM用户授予访问或管理Bucket资源的不同权限,例如只读、读写或完全控制的权限等。有关配置Bucket Policy的操作步骤,请参见通过Bucket Policy授权用户访问指定资源。
- 跨区域复制
跨区域复制(Cross-Region Replication)是跨不同OSS数据中心(地域)的Bucket自动、异步(近实时)复制Object,它会将Object的创建、更新和删除等操作从源存储空间复制到不同区域的目标存储空间。跨区域复制功能满足Bucket跨区域容灾或用户数据复制的需求。有关跨区域复制的更多信息,请参见跨区域复制。
- 数据加密
服务器端加密:上传文件时,OSS对收到的文件进行加密,再将得到的加密文件持久化保存;下载文件时,OSS自动将加密文件解密后返回给用户,并在返回的HTTP请求Header中,声明该文件进行了服务器端加密。有关服务器端加密的更多信息,请参见服务器端加密。
客户端加密:将文件上传到OSS之前在本地进行加密。有关客户端加密的更多信息,请参见客户端加密。
OSS使用方式
OSS提供多种灵活的上传、下载和管理方式。
- 通过控制台管理OSS
- 通过API或SDK管理OSS
OSS提供RESTful API和各种语言的SDK开发包,方便您快速进行二次开发。更多信息,请参见OSS API参考和OSS SDK参考。
- 通过工具管理OSS
OSS提供图形化管理工具ossbrowser、命令行管理工具ossutil、FTP管理工具ossftp等各种类型的管理工具。更多信息,请参见OSS常用工具。
- 通过云存储网关管理OSS
OSS的存储空间内部是扁平的,没有文件系统的目录等概念,所有的对象都直接隶属于其对应的存储空间。如果您想要像使用本地文件夹和磁盘那样来使用OSS存储服务,可以通过配置云存储网关来实现。更多信息,请参见云存储网关产品详情页面。
OSS定价
传统的存储服务供应商会要求您购买预定量的存储和网络传输容量,如果超出此容量,就会关闭对应的服务或者收取高昂的超容量费用;如果没有超过此容量,又需要您按照全部容量支付费用。
OSS仅按照您的实际使用容量收费,您无需预先购买存储和流量容量,随着您业务的发展,您将享受到更多的基础设施成本优势。
关于OSS的价格,请参见OSS产品定价。关于OSS的计量计费方式,请参见计量项和计费项。
其他相关服务
您把数据存储到OSS以后,就可以使用阿里云提供的其他产品和服务对其进行相关操作。
以下是您会经常使用到的阿里云产品和服务:
- 图片处理:对存储在OSS上的图片进行格式转换、缩放、裁剪、旋转、添加水印等各种操作。更多信息,请参见快速使用OSS图片处理服务。
- 云服务器ECS:提供简单高效、处理能力可弹性伸缩的云端计算服务。更多信息,请参见ECS产品详情页面。
- 内容分发网络CDN:将OSS资源缓存到各区域的边缘节点,利用边缘节点缓存的数据,提升同一个文件,被边缘节点客户大量重复下载的体验。更多信息,请参见CDN产品详情页面。
- E-MapReduce:构建于ECS上的大数据处理的系统解决方案,基于开源的Apache Hadoop和Apache Spark,方便您分析和处理自己的数据。更多信息,请参见E-MapReduce产品详情页面。
- 媒体处理:将存储于OSS的音视频转码成适合在PC、TV以及移动终端上播放的格式。并基于海量数据深度学习,对音视频的内容、文字、语音、场景多模态分析,实现智能审核、内容理解、智能编辑。更多信息,请参见媒体处理产品详情页面。
- 在线迁移服务:您可以使用在线迁移服务将第三方数据源,如亚马逊AWS、谷歌云等数据轻松迁移至OSS。更多信息,请参见在线迁移服务使用教程。
- 离线迁移服务:如果您有TB或PB级别的海量数据需要上传到OSS,但本地的网络带宽不够,扩容成本高,可以使用闪电立方离线数据迁移服务。更多信息,请参见离线迁移(闪电立方)介绍。
其他阿里云存储服务
除了对象存储以外,阿里云还提供文件存储、块存储等类型的存储服务,满足您不同场景下的业务需求。详细信息,请参见阿里云存储服务介绍和阿里云存储产品文档。
什么是文件存储NAS
阿里云文件存储NAS(Apsara File Storage NAS)是面向阿里云ECS实例、E-HPC、容器服务等计算节点的文件存储服务。它是一种可共享访问、弹性扩展、高可靠以及高性能的分布式文件系统。
产品概述
NAS基于POSIX文件接口,天然适配原生操作系统,提供共享访问,同时保证数据一致性和锁互斥。它提供了简单的可扩展文件存储以供与ECS配合使用,多个ECS实例可以同时访问NAS文件系统,并且存储容量会随着您添加和删除文件而自动弹性增长和收缩,为在多个实例或服务器上运行产生的工作负载和应用程序提供通用数据源。
NAS支持丰富的应用场景。更多信息,请参见应用场景。
NAS提供了通用容量型、通用性能型以及极速型存储类型。更多信息,请参见产品规格。
产品优势
NAS在成本、安全、简单、可靠性以及性能上都具有自身的优势。
- 成本
- 一个NAS文件系统可以同时挂载到多个计算节点上,由这些节点共享访问,从而节约大量拷贝与同步成本。
- 单个NAS文件系统的性能能够随存储容量线性扩展,使用户无需购买高端的文件存储设备,大幅降低硬件成本。
- 使用NAS文件存储,您只需为文件系统使用的存储空间付费,不需要提前配置存储,并且不存在最低费用或设置费用。更多信息,请参见产品定价。
- NAS的高可靠性能够降低数据安全风险,从而大幅节约维护成本。
- 简单
一键创建文件系统,无需部署维护文件系统。
- 安全
基于RAM实现的资源访问控制,基于VPC实现的网络访问隔离,结合文件存储NAS的传输加密与存储加密特性,保障数据不被窃取或篡改。
- 高可靠性
文件存储NAS的数据在后端进行多副本存储,每份数据都有多份拷贝在故障域隔离的不同设备上存放,提供99.999999999%的数据可靠性,能够有效降低数据安全风险。
- 高性能
基于分布式架构文件系统,随着容量的增长性能线性扩展,提供远高于传统存储的性能。
- 兼容性
- NAS文件存储提供良好的协议兼容性,支持NFS和SMB协议方案,兼容POSIX文件系统访问语义,提供强大的数据一致性和文件锁定。
- 在NAS中,任何文件修改成功后,用户都能够立刻看到修改结果,便于用户实时修改存储内容。
重要特性
- 生命周期管理
生命周期管理是针对用户存储数据的成本优化。当文件系统中包含每月访问频率低于2次的文件时,可以开启通用型NAS生命周期管理功能,符合生命周期管理策略的文件将自动转储至低频介质,采用低频介质计费方式,从而降低存储成本。更多信息,请参见低频介质。
- ACL
- NAS SMB ACL:基于AD域来实现对阿里云SMB协议文件系统的用户身份和权限管理。支持云账号以及源地址IP权限组的白名单机制为基础的文件系统级别的鉴权和访问控制。更多信息,请参见文件存储NAS SMB ACL特性。
- NAS NFS ACL:通过控制台开启NFS ACL,可以给不同的用户群组设置相应的权限,实现访问隔离。支持设置owner、group、other以外的特定用户和群组设置权限。更多信息,请参见NAS NFS ACL。
- 配额
通过配额管理,您可以轻松管理NAS目录级配额,包括添加配额、编辑配额和删除配额等。更多信息,请参见目录配额。
- 数据加密
- 服务端加密:NAS会对存储在文件系统中的数据进行加密,访问数据时,NAS自动将加密数据解密后返回给用户。更多信息,请参见服务器端加密。
- NFS文件系统传输加密:通过TLS协议保护ECS实例与NAS服务之间网络传输链路上的数据安全,确保数据在传输过程中不被窃取或纂改。更多信息,请参见NFS文件系统传输加密。
- SMB文件系统传输加密:采用认证加密算法(Authenticated Encryption),保证ECS实例与NAS服务之间网络传输链路上的数据安全,确保数据在传输过程中不被窃取或纂改。更多信息,请参见SMB文件系统传输加密。
- 备份
通过灵活的备份策略生成多个备份副本数据,在发生数据丢失或受损时及时恢复文件。更多信息,请参见备份和恢复文件。
- 回收站
开启回收站功能,被删除的文件或目录都将暂存在回收站中。当您误删除文件系统中的文件后,可以通过回收站恢复这些文件及其UID、GID和ACL等元数据信息。更多信息,请参见回收站。
使用方式
- 通过控制台管理NAS
- 通过API或SDK管理NAS
NAS提供RESTful API和各种语言的SDK开发包,方便您快速进行二次开发。更多信息,请参见NAS API参考和阿里云NAS SDK。
其他相关服务
您把数据存储到NAS以后,就可以使用阿里云提供的其他产品和服务对其进行相关操作。
- 云服务器ECS:提供简单高效、处理能力可弹性伸缩的云端计算服务。更多信息,请参见ECS产品详情页。
- 文件存储CPFS:可弹性扩展的POSIX/NFS接口全闪存文件存储系统,提供亚毫秒级的访问延迟和百万级IOPS,供高性能GPU计算使用。更多信息,请详见CPFS产品详情页。
- 在线迁移服务:您可以使用在线迁移服务将OSS数据迁移至NAS,更多信息,请参见在线迁移服务迁移教程。
- 混合云备份:您可以使用混合云备份服务定期备份NAS文件,在数据丢失或受损时及时恢复文件。更多信息,请参见HBR产品详情页。
- 云监控:您可以通过云监控查看NAS的性能监控指标和容量监控指标以及针对指标设置警报。更多信息,请参见云监控产品详情页。
如何选用NAS、OSS和EBS?
本文介绍阿里云文件存储NAS与阿里云对象存储OSS、阿里云块存储EBS的区别,帮助您更好地选用阿里云文件存储NAS。
文件存储NAS提供简单、可伸缩弹性的共享文件存储,配合云服务器ECS弹性计算服务构建业务系统。 当您选择使用文件存储NAS、对象存储OSS或块存储EBS部署应用程序时,需要考虑诸多因素。本文介绍文件存储NAS与对象存储OSS、块存储EBS的区别,帮助您更好地进行选择。
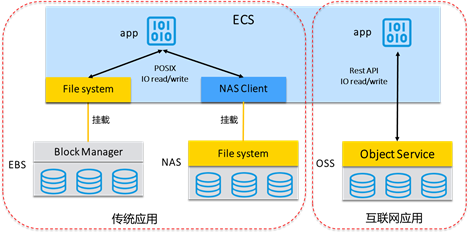
| 存储产品 | 时延 | 吞吐 | 访问模式 |
|---|---|---|---|
| 文件存储NAS | 低时延(毫秒级) | 数百Gbps | 上千个ECS通过POSIX接口并发访问,随机读写。 |
| 对象存储OSS | 较低时延(几十毫秒级) | 数百Gbps | 数百万客户端通过Web并发,追加写。 |
| 块存储EBS | 极低时延(微秒级) | 数十Gbps | 单ECS通过POSIX接口访问,随机读写。 |
文件存储NAS和对象存储OSS有什么不同?
文件存储NAS和对象存储OSS的主要区别:您无需修改应用,即可直接像访问本地文件系统一样访问文件存储NAS。文件存储NAS提供高吞吐和高IOPS的同时支持文件的随机读写和在线修改。
对象存储OSS是比较新的存储类型,相对于文件存储目录树的组织形式,对象存储OSS采用扁平的文件组织形式,采用RESTFul API接口访问,不支持文件随机读写,主要适用于互联网架构的海量数据的上传下载和分发。
文件存储NAS和块存储EBS有什么不同?
文件存储NAS相对于块存储EBS的主要区别:文件存储NAS可以同时支持上千个ECS客户端同时共享访问,提供高吞吐量。
块存储EBS是裸磁盘,挂载到ECS后不能被操作系统应用直接访问,需要格式化成文件系统(ext3、ext4、NTFS等)后才能被访问。块存储EBS的优势是性能高、时延低,适合于OLTP数据库、NoSQL数据库等IO密集型的高性能、低时延应用工作负载。但是块存储EBS无法实现容量弹性扩展,单盘最大容量为32TB,并且对共享访问的支持有限,需要配合类Oracle RAC、WSFC Windows故障转移集群等集群管理软件才能进行共享访问。因此,块存储EBS主要还是针对单ECS的高性能,低时延的存储产品。
什么是文件存储CPFS
文件存储CPFS(Cloud Paralleled File System)是阿里云推出的全托管、可扩展并行文件系统,满足高性能计算场景的需求。CPFS提供了统一的命名空间,支持成百上千的机器同时访问,拥有数十GB的吞吐、数百万的IOPS能力的同时还能保证亚毫秒级的延时。
您在阿里云控制台创建CPFS文件系统,通过标准的POSIX文件协议挂载即可以使用。阿里云CPFS特有的数据流动功能可以实现将对象存储OSS中的数据合并入CPFS,进行统一命名空间的元数据管理。您可以手动或者通过自动Lazy-load能力,将OSS中的数据复制到CPFS中,实现通过POSIX文件接口高速访问OSS中的数据。在保持海量数据在OSS中低成本存储的同时,获得高性能文件访问能力。CPFS文件系统应用于AI训练、自动驾驶、基因计算、影视渲染、石油勘探、气象分析、EDA仿真等场景,适用于高吞吐、高IOPS、海量文件的IO密集型业务。
产品优势
- 高吞吐:IO带宽随容量线性提升,最大支持20 GB/s。如需更大带宽,请提交工单申请。
- 高IOPS:IOPS能力随容量扩展线性提升,最大支持2800000 IOPS。
- 低延时:稳定的亚毫秒级IO时延。
- 海量文件:全对称的元数据服务器架构,100000以上元数据IOPS能力。
存储规格
| 指标 | 100 MB/s/TiB基线 | 200 MB/s/TiB基线 |
|---|---|---|
| IO带宽 | min{100*存储容量(TiB),20000}MBps | min{200*存储容量(TiB),20000}MBps |
| IOPS | min{15000*存储容量(TiB),2800000} | min{30000*存储容量(TiB),2800000} |
| IO时延 | 800 μs | 600 μs |
| 容量规格 |
|
|
支持地域
华东1(杭州)、华东2(上海)、华北1(青岛)、华北2(北京)、华北3(张家口)、华北5(呼和浩特)、华北6(乌兰察布)、华南1(深圳)、华南2(河源)、西南1(成都)。
若其他地域需要使用CPFS文件系统,请您提交工单咨询。
本文主要介绍文件存储CPFS的使用限制、CPFS客户端支持的操作系统及数据流动限制。
文件系统限制
| 限制项 | 阈值 | 说明 |
|---|---|---|
| 单个文件系统可创建的挂载点数量 | 1个 | 单个CPFS文件系统最多支持创建一个挂载点。 |
| 单个客户端挂载文件系统个数 | 1个 | 单个客户端最多可挂载一个CPFS文件系统。 |
| 是否支持子目录挂载 | 不支持 | CPFS文件系统不支持子目录挂载。 |
| 单个文件系统可挂载的计算节点数量 | 2000个 | 如您需要挂载CPFS的计算节点数量超过128个,请您提交工单咨询。 |
| 单个文件系统的最大容量 | 1 PiB | 单个文件系统最大容量1 PiB。 |
| 单个文件系统最大文件或目录数量 | 14亿个 | 文件/目录数量随文件系统容量增长而增加,每1200 GiB容量支持约1500万文件或目录, 单个文件系统上限14亿,如需更高要求,请在创建文件系统前,提交工单申请。 |
| 单个目录下最大文件或目录数量 | 1亿 | 单个目录下最大支持1亿文件或目录数量。 |
| 访问路径最大长度 | 4096字节 | Linux VFS的访问路径(例如:/a/b/c)最大长度为4096字节。 |
| 文件名长度 | 255字节 | 文件名最大支持255字节。 |
| 单个文件的最大容量 | 1 PiB | 单个文件的最大容量为1 PiB。如需更高容量,请在创建文件系统前,提交工单申请。 |
| 单个文件系统可创建的Fileset | 10个 | 仅CPFS 2.2.0及以上版本支持创建Fileset,单个文件系统可创建10个Fileset。如需提高Fileset数量,请提交工单工单申请。 |
| 单个Fileset内的最大文件或目录数量 | 100万个 | 单个Fileset内的最大文件或目录数量为100万个。如需提高文件数量额度,请提交工单工单申请。 |
什么是文件存储HDFS版
文件存储HDFS版(Apsara File Storage for HDFS)是面向阿里云ECS实例及容器服务等计算资源的文件存储服务。
产品概述
文件存储HDFS版就像在Hadoop分布式文件系统(Hadoop Distributed File System)中一样管理和访问数据。您无需对现有大数据分析应用做任何修改,即可使用具备无限容量及性能扩展、单一命名空间、多共享、高可靠和高可用等特性的分布式文件系统。
创建文件存储HDFS版实例后,即可在ECS及容器服务等计算资源内通过标准的HDFS协议接口访问文件系统。此外,多个计算节点可以同时访问同一个文件存储HDFS版实例,共享文件和目录。
支持地域
- 华北3(张家口)
- 华北2(北京)
- 华东2(上海)
- 华东1(杭州)
- 华南2(河源)
使用方式
- HDFS管理控制台:具有交互式操作的Web服务页面。关于管理控制台的操作,请参见快速入门。
- HDFS API:支持GET和POST请求的RPC风格API。关于API说明,请参见API参考。以下为调用文件存储HDFS版 API的常用开发者工具:
OpenAPI开发者门户:提供快速检索接口、在线调用API和动态生成SDK示例代码等服务。
数据迁移
产品定价
文件存储HDFS版计量项包括标准吞吐、预置吞吐,计费方式支持按量付费方式。详细的计费规则,请参见计费项与计费方式。详细的价格信息,请参见云产品定价页。
SDK参考
本文介绍阿里云文件存储HDFS版提供的SDK。
文件存储HDFS版的SDK包含文件系统SDK和管控系统SDK。目前公测期间只提供文件系统SDK,管控操作则通过控制台进行。
文件存储HDFS版SDK实现了Hadoop FileSystem 接口,提供一种Hadoop兼容的文件系统,对外输出为一个单独的JAR文件,即aliyun-sdk-dfs-x.y.z.jar。
借助该SDK,Apache Hadoop的计算分析应用(如MapReduce、Hive、Spark、Flink等)可以无需修改代码和编译,直接使用文件存储HDFS版作为 defaultFS,从而获得超越原始HDFS的功能和性能优势 。
本文档主要介绍文件系统SDK的安装及使用方式。
环境准备
本节以hadoop-mapreduce-examples为例,介绍文件系统SDK的使用方式。其中MapReduce以伪分布式方式运行。有关MapReduce的伪分布方式,请参见Apache Hadoop文档说明。
下载SDK
您可以下载文件存储HDFS版文件系统SDK的JAR文件aliyun-sdk-dfs-x.y.z.jar。
配置Hadoop
- 修改etc/hadoop/core-site.xml文件,core-site.xml文件中需要修改的内容如下所示。
<property> <name>fs.defaultFS</name> <value>dfs://DfsMountpointDomainName:10290</value> </property> <property> <name>fs.dfs.impl</name> <value>com.alibaba.dfs.DistributedFileSystem</value> </property> <property> <name>fs.AbstractFileSystem.dfs.impl</name> <value>com.alibaba.dfs.DFS</value> </property>说明- 请将MountpointDomainName替换为具体文件存储HDFS版实例的挂载地址,如xxx.cn-hangzhou.dfs.aliyuncs.com。
![]()
- core-site.xml的内容需要同步到所有依赖
hadoop-common的节点上。
- 请将MountpointDomainName替换为具体文件存储HDFS版实例的挂载地址,如xxx.cn-hangzhou.dfs.aliyuncs.com。

部署依赖
将上述步骤中获得的aliyun-sdk-dfs-x.y.z.jar拷贝至Hadoop生态系统组件的CLASSPATH上。推荐将其部署到hadoop-common-x.y.z.jar所在的目录内,并复制到所有Hadoop节点。对于MapReduce组件,该目录为$HADOOP_HOME/share/hadoop/hdfs。
验证安装
请执行以下步骤验证安装。
本文列出了创建目录、删除目录、上传文件、下载文件、显示目录、写入文件,读取文件、测试等操作的SDK示例,您可以参考示例工程开发您的应用。
背景信息
文件存储HDFS版提供对Apache Hadoop FileSystem API的兼容。更多信息,请参见Hadoop FileSystem API。
准备工作
- 已完成文件存储HDFS版的配置。具体操作,请参见快速入门。
- 已安装SDK。具体操作,请参见安装。
- 在计算节点上安装JDK,版本不能低于1.8。
- 在计算节点上安装hadoop,版本建议不低于2.7.2。
- 配置Maven的依赖配置。
<dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-client</artifactId> <version>2.7.2</version> <!--hadoop版本建议不低于 2.7.2 --> </dependency>
创建目录
- 示例
import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.FileSystem; import org.apache.hadoop.fs.Path; import java.io.IOException; public class exampleMkDir { public static void main(String[] args) throws IOException { if (args.length != 1) { System.out.println("本类为创建目录示例类,需要传入一个要创建目录路径的参数。\n" + "例如: hadoop jar hdfs_example-1.0-SNAPSHOT.jar com.alibaba.dfs.examples.exampleMkDir /tmp/hdfs_test"); System.exit(-1); } String fileName = args[0]; //设置操作HDFS文件系统的用户,用户可自行设置 //注意这里设置的用户,最好和在Linux上运行该代码的用户一致 System.setProperty("HADOOP_USER_NAME", "root"); //创建连接配置 Configuration hdfsConf = new Configuration(); //创建文件系统实例对象 FileSystem hadoopFS = FileSystem.get(hdfsConf); //在文件存储HDFS版上创建目录 boolean mkdirsSuccess = hadoopFS.mkdirs(new Path(fileName)); //使用完后,请释放资源,否则可能导致Resource busy错误 hadoopFS.close(); System.out.println("创建是否成功:" + mkdirsSuccess); System.out.println("用户可以使用hadoop命令查看创建的目录,例如:hadoop fs -ls " + fileName); } } - 运行示例
如果创建成功,则执行
hadoop fs -ls /tmp/hdfs_test命令无返回值。否则会报错No such file or directory。![创建目录运行示例]()

移动或者重命名
- 示例
import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.FileSystem; import org.apache.hadoop.fs.Path; import java.io.IOException; public class exampleRename { public static void main(String[] args) throws IOException { if (args.length != 2) { System.out.println("本类为移动或者重命名示例类,需要传入两个的路径参数。第一个为需要移动或重命名的路径,第二个为移动或重命名后的路径 \n" + "例如:hadoop jar hdfs_example-1.0-SNAPSHOT.jar com.alibaba.dfs.examples.exampleRename /tmp/hdfs_test /tmp/hdfs_test2"); System.exit(-1); } String fileName = args[0]; String fileRename = args[1]; //设置操作HDFS文件系统的用户,用户可自行设置 //注意这里设置的用户,最好和在Linux上运行该代码的用户一致 System.setProperty("HADOOP_USER_NAME", "root"); //创建连接配置 Configuration hdfsConf = new Configuration(); //创建文件系统实例对象 FileSystem hadoopFS = FileSystem.get(hdfsConf); if (hadoopFS.exists(new Path(fileName))) { System.out.println("文件存储HDFS版上不存在" + fileName); } boolean renameSuccess = hadoopFS.rename(new Path(fileName), new Path(fileRename)); System.out.println("改名是否成功" + renameSuccess); System.out.println("用户可以使用hadoop命令查看移动或者重命名后文件,例如:hadoop fs -ls " + fileRename); //使用完后,请释放资源,否则可能导致Resource busy错误 hadoopFS.close(); System.out.println("改名是否成功"+renameSuccess); System.out.println("用户可以使用hadoop命令查看移动或者重命名后文件,例如:hadoop fs -ls " + fileRename); } } - 运行示例
- 重命名
如果重命名成功,则执行
hadoop fs -ls /tmp/hdfs_test2命令无返回值。否则会报错No such file or directory。![重命名运行示例]()
- 移动
如果移动成功,则执行
hadoop fs -ls /tmp/hdfs_test2命令,可以看到/tmp/hdfs_test2目录下有内容。![移动运行示例]()
- 重命名


删除目录
- 请求
import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.FileSystem; import org.apache.hadoop.fs.Path; import java.io.IOException; public class exampleDelete { public static void main(String[] args) throws IOException { if (args.length != 1) { System.out.println("本类为删除示例类,需要传入一个要删除的路径。\n" + "例如: hadoop jar hdfs_example-1.0-SNAPSHOT.jar com.alibaba.dfs.examples.exampleDelete /dfs_test2 "); System.exit(-1); } String fileName = args[0]; //设置操作hdfs文件系统的用户,用户可自行设置 //注意这里设置的用户,最好和在Linux上运行该代码的用户一致 System.setProperty("HADOOP_USER_NAME", "root"); //创建连接配置 Configuration hdfsConf = new Configuration(); //创建文件系统实例对象 FileSystem hadoopFS = FileSystem.get(hdfsConf); if (hadoopFS.exists(new Path(fileName))) { boolean deleteSuccess = hadoopFS.delete(new Path(fileName), true); System.out.println("删除是否成功:" + deleteSuccess); System.out.println("用户可以使用hadoop命令查看是否存在删除的目录,例如:hadoop fs -ls " + fileName); } else { System.out.println("HDFS文件系统上不存在文件:" + fileName); } //使用完后,请释放资源,否则可能导致Resource busy错误 hadoopFS.close(); } } - 运行示例
如果删除成功,则执行
hadoop fs -ls /tmp/hdfs_test2命令将返回ls: `/tmp/hdfs_test2': No such file or directory。![删除运行示例]()

上传文件
- 示例
import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.FileSystem; import org.apache.hadoop.fs.Path; import java.io.IOException; public class exampleUp { public static void main(String[] args) throws IOException { if (args.length != 2) { System.out.println("本类为上传文件(将本地文件上传到HDFS上)示例类,需要传入两个的路径。第一个为需要上传的本地文件路径,第二个为上传到HDFS上的文件路径 \n" + "例如: hadoop jar hdfs_example-1.0-SNAPSHOT.jar com.alibaba.dfs.examples.exampleUp /root/test_local.txt /tmp/test_hdfs.txt "); System.exit(-1); } String localFilename = args[0]; String fileName = args[1]; //设置操作HDFS文件系统的用户,用户可自行设置 //注意这里设置的用户,最好和在Linux上运行该代码的用户一致 System.setProperty("HADOOP_USER_NAME", "root"); //创建连接配置 Configuration hdfsConf = new Configuration(); //创建文件系统实例对象 FileSystem hadoopFS = FileSystem.get(hdfsConf); if (!hadoopFS.exists(new Path(fileName))) { hadoopFS.copyFromLocalFile(new Path(localFilename), new Path(fileName)); System.out.println("上传是否成功" + hadoopFS.exists(new Path(fileName))); System.out.println("用户可以使用hadoop命令查看上传的文件,例如 :hadoop fs -ls " + fileName); } else { System.out.println("上传失败,在文件存储HDFS版上已经存在该文件"); } //使用完后,请释放资源,否则可能导致Resource busy错误 hadoopFS.close(); } } - 运行示例
如果上传成功,则执行
hadoop fs -ls /tmp/test_hdfs.txt命令可以在文件存储HDFS版上看到该文件。![上传文件]()

下载文件
- 示例
import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.FileSystem; import org.apache.hadoop.fs.Path; import java.io.File; import java.io.IOException; public class exampleDown { public static void main(String[] args) throws IOException { if (args.length != 2) { System.out.println("本类为下载文件(将HDFS上的文件下载到本地)示例类,需要传入两个的路径。第一个为需要下载的HDFS文件路径,第二个为下载到本地的路径 \n" + "例如: hadoop jar hdfs_example-1.0-SNAPSHOT.jar com.alibaba.dfs.examples.exampleDown /tmp/test_hdfs.txt ./test_hdfs.txt "); System.exit(-1); } String fileName = args[0]; String localFilename = args[1]; //设置操作HDFS文件系统的用户,用户可自行设置 //注意这里设置的用户,最好和在Linux上运行该代码的用户一致 System.setProperty("HADOOP_USER_NAME", "root"); //创建连接配置 Configuration hdfsConf = new Configuration(); //创建文件系统实例对象 FileSystem hadoopFS = FileSystem.get(hdfsConf); if (!new File(localFilename).exists()) { hadoopFS.copyToLocalFile(new Path(fileName), new Path(localFilename)); System.out.println("下载是否成功" + new File(localFilename).exists()); System.out.println("用户可以在本地目录" + localFilename + "下看到下载到的文件。"); } else { System.out.println("下载失败,在本地已经存在该文件"); } //使用完后,请释放资源,否则可能导致Resource busy错误 hadoopFS.close(); } } - 运行示例
如果下载成功,可以在本地看到该文件。
![下载文件]()

显示目录
- 示例
import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.FileStatus; import org.apache.hadoop.fs.FileSystem; import org.apache.hadoop.fs.Path; import java.io.IOException; public class exampleLs { public static void main(String[] args) throws IOException { if (args.length != 1) { System.out.println("本类为查看文件存储HDFS版上目录信息示例类,需要传入一个要查看的路径。 \n" + "例如: hadoop jar hdfs_example-1.0-SNAPSHOT.jar com.alibaba.dfs.examples.exampleLs / "); System.exit(-1); } String fileName = args[0]; //设置操作HDFS文件系统的用户,用户可自行设置 //注意这里设置的用户,最好和在Linux上运行该代码的用户一致 System.setProperty("HADOOP_USER_NAME", "root"); //创建连接配置 Configuration hdfsConf = new Configuration(); //创建文件系统实例对象 FileSystem hadoopFS = FileSystem.get(hdfsConf); FileStatus[] fileStatuses = hadoopFS.listStatus(new Path(fileName)); for (FileStatus file : fileStatuses) { System.out.print(file.getPermission() + "\t"); System.out.print(file.getOwner() + "\t"); System.out.print(file.getGroup() + "\t"); System.out.print(file.getAccessTime() + "\t"); System.out.print(file.getPath() + "\n"); } //使用完后,请释放资源,否则可能导致Resource busy错误 hadoopFS.close(); System.out.println("\n\n用户可以使用hadoop命令查看文件存储HDFS版 "+ fileName +" 目录下的内容,例如 :hadoop fs -ls " + fileName); } } - 运行示例
如果该方法运行成功,则执行
hadoop fs -ls /命令的返回结果和exampleLs返回结果大致相同。![显示目录]()

写入文件
- 示例
import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.FSDataOutputStream; import org.apache.hadoop.fs.FileSystem; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.IOUtils; import java.io.BufferedInputStream; import java.io.ByteArrayInputStream; import java.io.IOException; import java.io.InputStream; public class exampleWrite { public static void main(String[] args) throws IOException { if (args.length != 2) { System.out.println("本类为写入HDFS文件系统上的文件示例类,需要传入两个的参数。第一个为HDFS文件上一个写入文件的路径,第二个为写入文件中的内容 \n" + "例如: hadoop jar hdfs_example-1.0-SNAPSHOT.jar com.alibaba.dfs.examples.exampleWrite /tmp/test_write.txt 测试输入到HDFS上的文件的内容 "); System.exit(-1); } String filename = args[0]; String msg = args[1] + "\n"; //设置操作HDFS文件系统的用户,用户可自行设置 //注意这里设置的用户,最好和在Linux上运行该代码的用户一致 System.setProperty("HADOOP_USER_NAME", "root"); //创建连接配置 Configuration hdfsConf = new Configuration(); //创建文件系统实例对象 FileSystem hadoopFS = FileSystem.get(hdfsConf); //创建文件流 InputStream in = new BufferedInputStream(new ByteArrayInputStream(msg.getBytes("UTF-8"))); //在HDFS上创建一个测试文件 FSDataOutputStream out = hadoopFS.create(new Path(filename), true); //利用IOUtils.copyBytes进行写入 IOUtils.copyBytes(in, out, 1024 * 8, true); System.out.println("已经写入HDFS文件系统上的" + filename + "文件"); System.out.println("用户可以使用hadoop命令查看写入文件的内容 :hadoop fs -cat " + filename); //使用完后,请释放资源,否则可能导致Resource busy错误 hadoopFS.close(); } } - 运行示例
若该方法运行成功,则执行
hadoop fs -cat /tmp/test_write.txt命令的返回结果和exampleWrite写入该文件的内容相同。![写入文件]()

读取文件
- 示例
import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.FSDataInputStream; import org.apache.hadoop.fs.FileSystem; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.IOUtils; import java.io.IOException; import java.io.OutputStream; public class exampleRead { public static void main(String[] args) throws IOException { if (args.length != 1) { System.out.println("本类为读取HDFS文件系统上的文件示例类,需要传入一个文件存储HDFS版上的文件路径的参数。 \n" + "例如: hadoop jar hdfs_example-1.0-SNAPSHOT.jar com.alibaba.dfs.examples.exampleRead /tmp/test_write.txt"); System.exit(-1); } String filename = args[0]; //设置操作HDFS文件系统的用户,用户可自行设置 //注意这里设置的用户,最好和在Linux上运行该代码的用户一致 System.setProperty("HADOOP_USER_NAME", "root"); //创建连接配置 Configuration hdfsConf = new Configuration(); //创建文件系统实例对象 FileSystem hadoopFS = FileSystem.get(hdfsConf); if (hadoopFS.exists(new Path(filename))) { //创建文件流 FSDataInputStream in = hadoopFS.open(new Path(filename)); OutputStream out = System.out; IOUtils.copyBytes(in, out, 1024 * 8, ); System.out.println("\n 用户可以使用hadoop命令查看文件的内容 ,例如:hadoop fs -cat " + filename); } else { System.out.println("HDFS文件系统上不存在文件:" + filename); } //使用完后,请释放资源,否则可能导致Resource busy错误 hadoopFS.close(); } } - 运行示例
如果该方法运行成功,则执行
hadoop fs -cat /tmp/test_write.txt命令的返回结果和exampleRead打印的内容相同。![读取文件]()

整体测试
- 示例
import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.*; import org.apache.hadoop.io.IOUtils; import java.io.*; public class exampleAll { public static void main(String[] args) throws Exception { System.out.println("该测试类是包含本测试包中的所有API测试\n\n"); //设置操作HDFS文件系统的用户,用户可自行设置 //注意这里设置的用户,最好和在Linux上运行该代码的用户一致 System.setProperty("HADOOP_USER_NAME", "root"); //创建连接配置 Configuration hdfsConf = new Configuration(); //创建文件系统实例对象 FileSystem hadoopFS = FileSystem.get(hdfsConf); System.out.println("在文件存储HDFS版上创建目录/hdfs_mkdirTest"); System.out.println("创建是否成功:" + hadoopFS.mkdirs(new Path("/hdfs_mkdirTest")) + "\n"); Thread.sleep(2 * 1000); System.out.println("在文件存储HDFS版上修改目录/hdfs_mkdirTest 为 /hdfs_renameTest "); System.out.println("改名是否成功: " + hadoopFS.rename(new Path("/hdfs_mkdirTest"), new Path("/hdfs_renameTest")) + "\n"); Thread.sleep(2 * 1000); System.out.println("在文件存储HDFS版上删除目录 /hdfs_renameTest "); System.out.println("删除是否成功: " + hadoopFS.delete(new Path("/hdfs_renameTest"), true) + "\n"); Thread.sleep(2 * 1000); new File("./hdfs_upTest.txt").delete(); new File("./hdfs_downTest.txt").delete(); new File("./hdfs_upTest.txt").createNewFile(); System.out.println("向文件存储HDFS版的/hdfs_Test中,上传本地文件 ./hdfs_upTest.txt "); hadoopFS.mkdirs(new Path("/hdfs_Test")); hadoopFS.copyFromLocalFile(new Path("./hdfs_upTest.txt"), new Path("/hdfs_Test/hdfs_upTest.txt")); System.out.println("上传是否成功: " + hadoopFS.exists(new Path("/hdfs_Test/hdfs_upTest.txt")) + "\n"); Thread.sleep(2 * 1000); System.out.println("从文件存储HDFS版的/hdfs_Test中,下载文件hdfs_upTest.txt到当前目录 "); hadoopFS.copyToLocalFile(new Path("/hdfs_Test/hdfs_upTest.txt"), new Path("./hdfs_downTest.txt")); System.out.println("下载是否成功: " + new File("./hdfs_downTest.txt").exists() + "\n"); Thread.sleep(2 * 1000); System.out.println("向文件存储HDFS版上的/hdfs_Test/hdfs_writeTest.txt文件中写入测试内容"); InputStream win = new BufferedInputStream(new ByteArrayInputStream(("测试写入文件存储HDFS版 1 \n" + "测试写入文件存储HDFS版 2 \n" + "测试写入文件存储HDFS版 3 \n").getBytes("UTF-8"))); FSDataOutputStream wout = hadoopFS.create(new Path("/hdfs_Test/hdfs_writeTest.txt"), true); IOUtils.copyBytes(win, wout, 1024 * 8, true); System.out.println("已经写入到/hdfs_Test/hdfs_writeTest.txt文件\n"); Thread.sleep(2 * 1000); System.out.println("从文件存储HDFS版上的/hdfs_Test/hdfs_writeTest.txt文件中读取之前写入的内容"); FSDataInputStream rin = hadoopFS.open(new Path("/hdfs_Test/hdfs_writeTest.txt")); OutputStream rout = System.out; System.out.println("/hdfs_Test/hdfs_writeTest.txt文件中的內容为:"); IOUtils.copyBytes(rin, rout, 1024 * 8, false); System.out.println(); System.out.println("查看文件存储HDFS版上 /hdfs_Test 目录 "); FileStatus[] fileStatuses = hadoopFS.listStatus(new Path("/hdfs_Test")); for (FileStatus file : fileStatuses) { System.out.print(file.getPermission() + "\t"); System.out.print(file.getOwner() + "\t"); System.out.print(file.getGroup() + "\t"); System.out.print(file.getPath() + "\n"); } System.out.println(); System.out.println("测试完毕!"); //使用完后,请释放资源,否则可能导致Resource busy错误 hadoopFS.close(); rout.close(); rin.close(); } } - 运行示例
什么是日志服务
日志服务SLS是云原生观测与分析平台,为Log、Metric、Trace等数据提供大规模、低成本、实时的平台化服务。日志服务一站式提供数据采集、加工、查询与分析、可视化、告警、消费与投递等功能,全面提升您在研发、运维、运营、安全等场景的数字化能力。
基本概念
在使用日志服务前,您需要了解以下基本概念。
| 术语 | 说明 |
|---|---|
| 项目(Project) | 项目是日志服务的资源管理单元,是进行多用户隔离与访问控制的主要边界。更多信息,请参见项目(Project)。 |
| 日志库(Logstore) | 日志库是日志服务中日志数据的采集、存储和查询单元。更多信息,请参见日志库(Logstore)。 |
| 时序库(MetricStore) | 时序库是日志服务中时序数据的采集、存储和查询单元。更多信息,请参见时序库(MetricStore)。 |
| 日志(Log) | 日志是系统运行过程中变化的一种抽象数据,其内容为指定对象的操作和其操作结果按时间的有序集合。更多信息,请参见日志(Log)。 |
| 日志组(LogGroup) | 日志组是一组日志的集合,是写入与读取日志的基本单位。一个日志组中的日志包含相同Meta信息(IP地址、Source等信息)。更多信息,请参见日志组(LogGroup)。 |
| 时序数据(Metric) | 时序数据是指时间序列数据。更多信息,请参见时序数据(Metric)。 |
| 链路数据(Trace) | 链路数据代表一个事务或者流程在(分布式)系统中的执行过程。更多信息,请参见链路数据(Trace)。 |
| 分区(Shard) | 分区用于控制Logstore的读写能力,数据必定保存在某一个Shard中。每个Shard均有范围,为MD5左闭右开区间。每个区间范围不会相互覆盖,并且所有的区间的范围是MD5整个取值范围[00000000000000000000000000000000,ffffffffffffffffffffffffffffffff)。更多信息,请参见分区(Shard)。 |
| 日志主题(Topic) | 日志主题是日志服务的基础管理单元。您可在采集日志时指定日志主题,日志服务将通过日志主题划分日志。更多信息,请参见日志主题(Topic)。 |
| 服务入口(Endpoint) | 日志服务的服务入口是访问一个Project及其内部数据的URL。访问不同地域的Project时,所需的服务入口不同。通过内网和外网访问同一地域的Project时,所需的服务入口也是不同的。更多信息,请参见服务入口。 |
| 访问密钥(AccessKey) | 访问密钥指的是访问身份验证中用到的AccessKey ID和AccessKey Secret。日志服务通过使用AccessKey ID和AccessKey Secret对称加密的方法来验证某个请求的发送者身份。AccessKey ID用于标识用户;AccessKey Secret是用户用于加密签名字符串和日志服务用来验证签名字符串的密钥,必须保密。更多信息,请参见访问密钥。 |
| 地域(Region) | 地域是日志服务的数据中心所在物理位置。您可以在创建Project时指定地域,一旦指定之后就不允许更改。更多信息,请参见开服地域。 |
功能概览
日志服务包含以下功能模块,覆盖云原生观测与分析的多种业务场景。
-
数据采集支持Log、Metric、Trace等数据类型,并支持50多种数据源,包括阿里云产品、服务器与应用、物联网设备、移动端、开源软件、标准协议等。
-
数据加工提供200多个内置函数、400多个正则表达式、灵活的自定义函数,实现过滤、分裂、转换、富化、复制等效果,满足数据分派、规整、融合等场景。
-
查询与分析支持PB级数据实时查询与分析,提供10多种查询运算符、10多种机器学习函数、100多个SQL函数,并支持Scheduled SQL和SQL独享版。
-
可视化支持查询与分析结果可视化,提供10多种统计图表,包括表格、线图、柱状图、地图等,并支持基于统计图表自定义仪表盘(支持外嵌与下钻分析)。
-
告警提供一站式告警功能,包括告警监控、告警管理、通知(行动)管理等,适用于开发运维、IT运维、智能运维、安全运维、商务运维等多个场景。
-
消费与投递支持数据实时消费,适用于Storm消费、Flume消费、Flink消费等场景;支持数据实时投递,适用于将数据投递至OSS、TSDB等云产品。
使用方式
您可以通过以下任意一种方式使用日志服务。
| 方式 | 说明 |
|---|---|
| 控制台 | 日志服务提供Web服务页面管理您的日志服务资源。更多信息,请参见日志服务控制台。 |
| SDK | 日志服务提供各种语言的SDK开发包,方便您快速进行二次开发。更多信息,请参见SDK概述。 |
| API | 日志服务提供API管理您的日志服务资源。该方式需要您手动签名验证。更多信息,请参见API概述。
说明 推荐您使用SDK,以免除手动签名验证环节。
|
| CLI | 日志服务提供CLI管理您的日志服务资源。更多信息,请参见CLI概述。 |
产品定价
日志服务支持按量付费,即按照您的实际使用量收费。相较于自建ELK,使用日志服务,总成本预计可以下降50%。关于日志服务的计量项和计费项,请参见计费项。
什么是混合云备份HBR
混合云备份HBR(Hybrid Backup Recovery) 作为阿里云统一灾备平台,是一种简单易用、敏捷高效、安全可靠的公共云数据管理服务,可以为阿里云ECS整机、ECS数据库、文件系统、NAS、OSS以及自建机房内的文件、数据库、虚拟机、大规模NAS等提供备份、容灾保护以及策略化归档管理。
产品架构

- 云上数据备份
阿里云ECS实例上的文件目录、自建MySQL、Oracle、SQL Server、SAP HANA、NAS、OSS等关键数据可以高效地通过内网备份到备份库,提供MySQL、Oracle数据库近0 RPO实时备份功能。其他云平台的数据也可以备份到阿里云备份库。
- 本地上云备份
将服务器本地文件、NAS文件,VMware虚拟机、数据库等数据直接备份到云备份库,备份策略设置灵活。
- 跨地域备份和ECS跨地域容灾
- 通过镜像备份库功能实现跨地域备份,给数据提供多重保护。
- 提供ECS秒级RPO、分钟级RTO高性能跨地域容灾。
- VMware虚拟机迁云
将本地机房VMware虚拟机无代理迁移上云,提供增量迁移方式,简单、易用、快捷。
- 本地NAS上云归档
将本地海量文件智能归档到HBR归档库,归档策略设置灵活,支持本地存储及归档库中文件内容秒级全文搜索。
基本概念
在使用混合云备份HBR前,您需要了解以下基本概念。
| 名称 | 描述 |
|---|---|
| 备份源 | 需要备份的数据所在的机器,例如服务器、虚拟机或者ECS实例。 |
| 客户端 | 客户端安装在备份源上。您可以通过客户端进行备份和恢复等操作。不同的备份源系统和平台需要安装相应的客户端。
客户端支持定时重试等方式确保备份稳定性,在网络短时抖动情况下依然可以完成备份。 |
| 地域 | 地域是指阿里云物理的数据中心。资源创建成功后不能更换地域。HBR支持的开服地域,请参见开服地域。 |
| 备份仓库 | 备份仓库是HBR的云上备份仓库,用于存储您备份在云上的数据。多个客户端可以备份到同一个仓库,帮助您更高效的管理备份数据,减小管理时间和成本。
备份仓库支持的客户端数和存储容量没有限制,按需订阅,按需扩容,同时备份库提供12个9的数据可靠性。 备份仓库有地域属性,选择合理的备份仓库地域可以帮助您提高备份性能,布局容灾。备份仓库创建成功后不能更换地域。数据的重删压缩都以备份仓库为单位。 |
支持备份哪些数据源
| 数据源 | 系统 | |
|---|---|---|
| 本地数据中心 | 文件目录 | Windows、Windows Server、Linux |
| NAS | Windows、Windows Server、Linux | |
| VMware vSphere中的虚拟机镜像 | Windows、Windows Server、Linux | |
| MySQL、Oracle和SQL Server数据库 | Windows、Windows Server、Linux | |
| 阿里云ECS | ECS中的文件目录 | Windows Server、Linux |
| 部署在ECS上的SAP HANA | Windows Server、Linux | |
| 部署在ECS上的MySQL、Oracle、SQL Server | Windows Server、Linux | |
| 云盘(系统盘、数据盘) | 不涉及 | |
| 云存储网关 | 部署在阿里云上的文件网关 | 不涉及 |
| 阿里云文件存储NAS | 保存在阿里云文件存储NAS的数据 | 不涉及 |
| 阿里云对象存储OSS | 保存在阿里云对象存储OSS的数据 | 不涉及 |
混合云备份定价
HBR支持按量付费和包年包月资源包。关于混合云备份HBR的计量项和计费项,请参见混合云备份计费方式与计费项。
什么是智能媒体管理
阿里云智能媒体管理(Intelligent Media Management,简称IMM),场景化封装数据智能分析管理,为云上文档、图片、视频数据,提供一站式数据处理、分析、检索等管控体验。
产品概述
智能媒体管理针对不同行业的业务场景封装整合完整的处理能力,提供文档的格式转换及预览,图片的内容识别、人脸检测、二维码检测、人脸搜索等功能,适合媒资管理、智能网盘、社交应用、图库图床等开发者使用。智能媒体管理可以结合对象存储(OSS)、表格存储(Tablestore)为文档管理、图片社交分析等领域提供实用的场景化一站式解决方案。
功能特性
- 文档转换和预览
将文档相关的格式转换和预览整合,快速实现文档的智能管理能力。
功能 说明 格式转换 将PPTX、PPT、XLS、DOC、PDF、HTML、HTM等48种文档格式转换为JPG、PNG、PDF、TXT和VECTOR向量格式。更多信息,请参见文档格式转换。 文档预览 根据实际需要选择合适的方式进行文档预览。 - 图片智能检测
将内容识别、人脸检测等AI功能整合,快速实现图片的智能管理能力。
功能 说明 内容识别 识别图片中场景、物体、事件等信息,获取到标签的元数据信息。更多信息,请参见内容识别。 人脸检测 检测图片中的人脸以及人的年龄、性别、心情等,获取到人脸的元数据信息。更多信息,请参见人脸检测。 二维码检测 检测图中的二维码以及二维码中存储的内容,详情请参见二维码识别。 商标检测 检测图片中的户外用品、奢侈品牌、数码 3C、汽车、互联网企业、体育用品等领域企业的商标。更多信息,请参见商标检测。 人体检测 检测图片中的人体区域和置信度。更多信息,请参见人体检测。 人脸搜索 搜索与指定图片最相似的前N张图片,结果按相似度降序排列。更多信息,请参见人脸搜索。 人脸对比 比较两张图片中分别最大的两个人脸的相似度。更多信息,请参见人脸对比。 图片盲水印 为图片添加图片或文字类型的盲水印。盲水印添加后,在图片中不能直接看到该水印,但是可以通过使用智能媒体管理的解析图片盲水印功能恢复图中隐藏的水印。更多信息,请参见图片盲水印。
应用场景
智能媒体管理可应用于文档管理、图片社交分析、家庭设备数据存储等场景。更多信息,请参见应用场景。
使用产品
- 智能媒体管理控制台
使用Web服务页面方便您管理智能媒体管理,您可以登录智能媒体管理控制台操作项目,以及体验不同功能的效果。更多信息,请参见快速入门。
- 智能媒体管理SDK
使用SDK方便您灵活使用智能媒体管理,SDK基于服务API实现,且提供和服务API同样的能力。更多信息,请参见SDK参考和API手册。
- OSS控制台
为OSS Bucket绑定智能媒体管理后,通过OSS控制台可以使用智能媒体管理的功能,例如文档预览、人脸识别等。更多信息,请参见快速开始。
什么是离线迁移(闪电立方)
离线迁移(闪电立方)是阿里云提供的安全、高效、便捷的数据迁移服务。通过定制化的迁移设备(闪电立方),实现TB到PB级别的本地数据迁移上云。致力于解决大规模数据传输效率、安全问题等难题。
当本地机房带宽较小或无公网时,可通过离线迁移服务将数据迁移至阿里云OSS。

使用流程
离线迁移服务使用流程如下图所示。

优势
-
扩展灵活,低成本
-
单台设备可支持36 TB\100 TB\480 TB的迁移数据能力,可多套同时使用,提升迁移效率。
-
相比传统Internet或者专线接入的方式,成本下降60%,迁移速度提升20倍。
-
-
部署方便
-
采用专业的数据迁移设备,标准机架和电源,可多套同时部署提升迁移效率。
-
支持多种的数据源类型:本地文件系统、NAS、HDFS、FastDFS等。
-
-
安全可靠
-
保证数据一致性:采用CRC技术进行读写双向校验。如果数据迁移时CRC校验失败,则闪电立方会自动进行重传。
-
数据加密:提供端到端的加密机制,并通过RAM授权的方式运输并上传数据。
-
数据擦除:数据迁移完毕后,通过阿里云官方数据擦除机制,确保数据不会被第三方获取。
-
什么是混合云存储
阿里云提供针对私有云、容器、数据库、海量数据存储、HPC、AI和大数据等业务场景,基于混合云架构,提供云上弹性空间、软硬件一体集成的混合云存储服务。本文介绍混合云存储的基本信息等,帮助您选择最适合您业务场景和需求的混合云存储服务。
混合云存储包括混合云存储阵列、混合云CPFS存储、混合云分布式存储等多种形态,您可以像使用本地存储一样使用和管理本地和云端的各种存储资源(块、文件和对象)。本地存储可以通过云缓存、云同步、云分层、云备份等方式无缝连通云存储,为不同的数据应用场景提供针对性优化的混合云存储解决方案。
| 产品 | 描述 |
|---|---|
| 混合云存储阵列 | 软硬一体的存储设备,专为对存储有高性能和稳定性要求,并且希望无缝上云的企业客户而设计。集成了阿里云存储服务,融合了公共云存储和传统存储阵列的简单、灵活、高效和可靠的优点。 |
| 混合云CPFS存储 | 高性能计算文件存储,支持标准的POSIX和MPI-IO协议,自带的高性能计算程序无需任何接口适配和性能优化接口即可高效率执行,满足高性能文件存储需求。 |
| 混合云分布式存储 | 弹性灵活,适合业务快速发展的私有云和互联网应用场景,支持海量非结构化数据存储。 |
产品优势
随着云计算技术的普及,越来越多的企业开始选择了部署云计算方案,公共云的灵活性,易用性和可靠性也被大家广泛认可。但也有很多企业对传统存储阵列的依赖度很高,在短期内完全迁移到云端会有诸多的挑战,可能会涉及到系统的重新构建或者应用程序的开发,对客户来说改动量很大,也会面临不小的风险。同时还有很多客户对敏感数据的物理存放地有要求,所以越来越多的企业开始采用混合云来实现面向未来的数字化转型。

阿里云混合云存储阵列作为软硬一体的存储设备,集成了阿里云存储服务,融合了公共云存储和传统存储阵列的优点:
- 简单
客户无需更改原有的IT架构,就可以像使用本地存储设备一样使用阿里云混合云存储阵列,同时使用本地存储空间和云端存储空间,无需关注本地设备存储协议同云存储协议之间的兼容性。
- 灵活
与阿里云存储无缝结合,充分利用公共云存储的易于扩展、快速部署、按需付费的优势,快速响应客户业务需求的变化。
- 高效
自动云分层,热数据存放在本地存储空间,确保了数据的高速访问。冷数据放在云端,充分利用公共云存储的海量空间。云缓存功能确保当数据存放在云端的时候,也能利用本地存储空间的缓存功能,为应用提供快速响应。
- 可靠
阿里云混合云存储阵列采用了全冗余的硬件设计,支持数据加密、集成AD/LDAP、支持ACL,云端分布式存储提供多副本跨区域保护,11个9的数据高可靠性,完备的数据一致性校验,确保用户数据的安全和可靠。
阿里云混合云存储阵列专为对存储有高性能和稳定性要求,并且希望无缝上云的企业客户而设计:
- 数据能按照策略自动同步到云端,实现数据的云端备份容灾。
- 支持自动云分层和云缓存功能,保证数据的高速访问和存储空间的有效利用。
- 数据压缩和去重,提升数据在云端和本地存储无缝流动的效率。
- 支持完备的主机端协议, 包括FC/iSCSI/FCoE、NFS/CIFS、Cinder等。
- 提供多版本快照、复制等丰富的企业数据服务。
- 支持免网关阵列双活容灾,护驾企业关键应用。
- 支持异构虚拟化,提高旧阵列利用率,降低总IT成本。
- 存储阵列多控扩展,全面提升阵列性能和容量。
- 全冗余设计,安全可靠,支持数据中心机架部署。
- 克隆功能:支持卷克隆功能,可创建读写的卷克隆副本。
- 故障恢复:支持故障切换和故障恢复功能。当控制器故障时,支持在线故障切换,业务连续性不受影响。
阿里云混合云存储阵列将云存储的高性价比和可扩展性与本地数据中心架构相结合,帮助客户轻松实现数据在本地数据中心和公共云之间的无缝流动。
产品规格

混合云CPFS存储
混合云CPFS存储提供高性能计算文件存储,支持标准的POSIX和MPI-IO协议,自带的高性能计算程序无需任何接口适配和性能优化即可高效执行,满足高性能文件存储需求。
产品架构
混合云CPFS存储是针对高性能和超大规模存储场景推出的文件存储产品,可结合云上、云下多级存储池,拥有全新的文件存储架构。
该产品单集群最大可扩展至16384个节点,提供高性能、高可扩展性、低时延的分布式文件存储服务。可适用于自动驾驶模型训练、基因组测序数据组装和石油勘探业务分析等场景。

产品优势
| 优势 | 说明 |
|---|---|
| 混合云存储架构 | 集成公共云存储服务,为Cloud Bursting场景下的客户提供优质的体验。 |
| 高可扩展性 |
|
| 高性能 |
|
| 高可用、高可靠性 |
|
| 丰富的接口协议 | 支持POSIX(SMB、NFS)、Object、HDFS等接口协议:
|
适用场景
| 场景 | 场景介绍 |
|---|---|
| 自动驾驶模型训练 | 为自动驾驶场景中车载摄像头、雷达、红外等设备采集的大量的小文件,混合云CPFS存储提供低时延,高IOPS的访问能力,模型训练速度可以提高3倍以上。 |
| 基因组测序数据组装 | 基因序列组装需要海量的并发计算作业,混合云CPFS存储提供高达百GB的访问带宽,可以满足成百上千个节点同时访问的需求,破除文件IO访问瓶颈,任务完成时间缩短到原来的50%。 |
| 石油勘探业务分析 | 大量地质数据需要计算、处理和分析,并且原始地震资料和过程数据需要长期保存。混合云CPFS存储提供PB级单一命名空间,支持空间配额灵活管理,资源划分给不同的计算任务,满足业务随时扩展的需要。 |
混合云分布式存储
混合云分布式存储具备弹性灵活的特性,适用于业务快速发展的私有云和互联网应用场景,支持海量非结构化数据存储。
产品架构
混合云分布式存储是基于分布式架构的存储产品,通过增加节点数可以实现容量和性能的线性增长,产品支持iSCSI、OSS、S3、NFS、CIFS等场景存储协议。
阿里云将领先的分布式存储技术以及长期积累的公共云部署、运维的最佳实践融入到分布式存储产品中,从而打造高性能、高可扩展、高可靠的混合云分布式存储,帮助您降低成本、缩短业务上线时间,轻松构建混合云存储。

产品优势
| 优势 | 说明 |
|---|---|
| 灵活敏捷,弹性扩容 |
|
| 稳定可靠,保证业务持续运行 |
|
| 轻松构建企业存储云 |
|
适用场景
- 专有云存储
数字化转型中的企业,基于虚拟化、容器等技术构建专有云平台,为敏捷部署、快速迭代的互联网应用提供弹性灵活的存储方案,并支持多样化的应用需求。
- 海量非结构化数据存储
在网站、视频监控、在线教育等场景下产生大量视频、音频、图片类的非结构化数据,这些数据是数字化时代增长最快的数据源。混合云分布式存储为这些数据源提供弹性灵活的存储方案。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号