HBase-4MapReduce
集成分析
- HBase表中的数据最终都是存储在HDFS上,HBase天生的支持MR的操作,我们可以通过MR直接处理HBase表中的数据,
并且MR可以将处理后的结果直接存储到HBase表中。 - 参考地址:http://hbase.apache.org/book.html#mapreduce
1 实现方式一
- 读取HBase当中某张表的数据,将数据写入到另外一张表的列族里面去
2 实现方式二
- 读取HDFS上面的数据,写入到HBase表里面去
3 实现方式三
-
通过bulkload的方式批量加载数据到HBase表中
-
加载数据到HBase当中去的方式多种多样,我们可以使用HBase的javaAPI或者使用sqoop将我们的数据写入或者导入到HBase当中去,
但是这些方式不是最佳的,因为在导入的过程中占用Region资源导致效率低下- HBase数据正常写流程回顾
![]()
- HBase数据正常写流程回顾
-
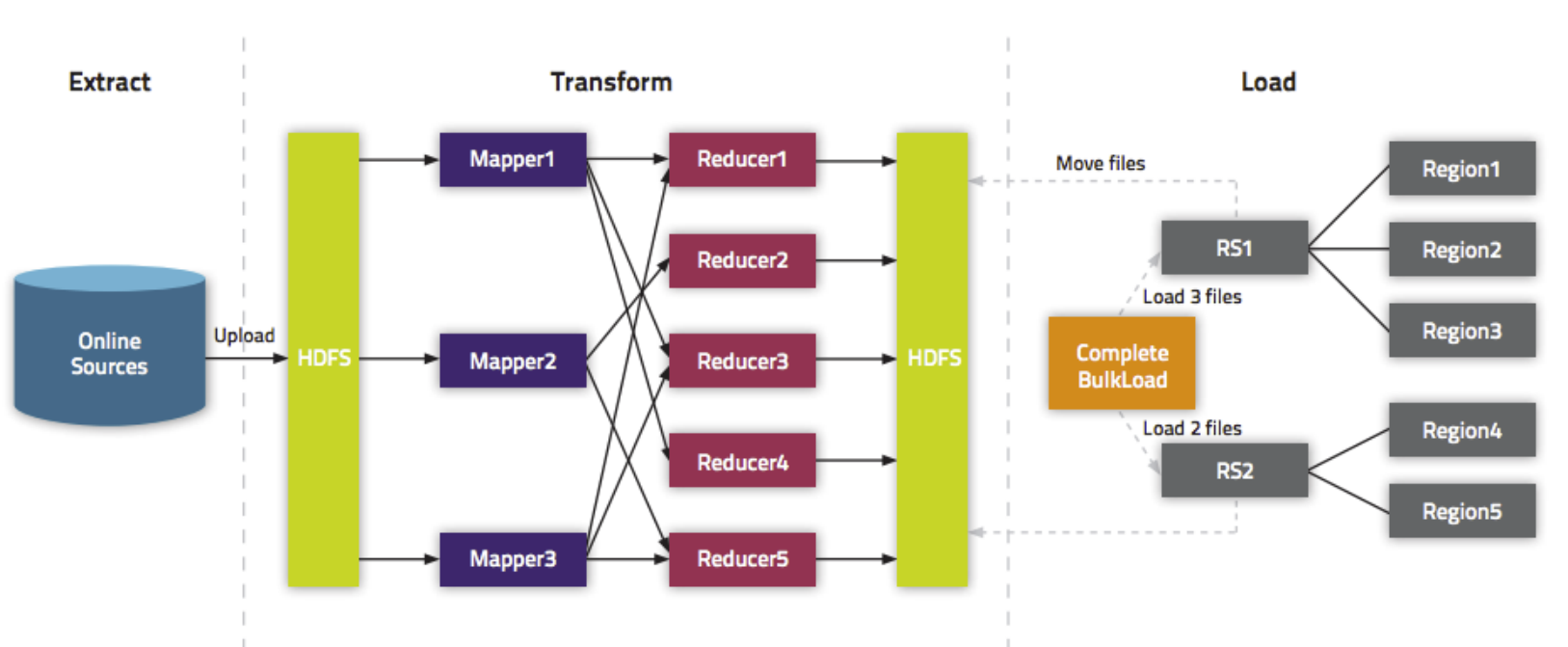
通过MR的程序,将我们的数据直接转换成HBase的最终存储格式HFile,然后直接load数据到HBase当中去即可
- bulkload方式的处理示意图
![]()
- bulkload方式的处理示意图
-
使用bulkload的方式批量加载数据的好处
- 导入过程不占用Region资源
- 能快速导入海量的数据
- 节省内存

实现方式一
- 读取HBase当中person这张表的info1:name、info2:age数据,将数据写入到另外一张person1表的info1列族里面去
- 第一步:创建person1这张hbase表
注意:列族的名字要与person表的列族名字相同
create 'person1','info1'
- 第二步:创建maven工程并导入jar包
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<parent>
<artifactId>tenic</artifactId>
<groupId>org.example</groupId>
<version>1.0-SNAPSHOT</version>
</parent>
<modelVersion>4.0.0</modelVersion>
<artifactId>HbaseMrDdemo</artifactId>
<dependencies>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>3.1.4</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-auth</artifactId>
<version>3.1.4</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.hbase/hbase-client -->
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-client</artifactId>
<version>2.2.2</version>
</dependency>
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-mapreduce</artifactId>
<version>2.2.2</version>
</dependency>
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-server</artifactId>
<version>2.2.2</version>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.12</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.testng</groupId>
<artifactId>testng</artifactId>
<version>6.14.3</version>
<scope>test</scope>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.0</version>
<configuration>
<source>1.8</source>
<target>1.8</target>
<encoding>UTF-8</encoding>
<!-- <verbal>true</verbal>-->
</configuration>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-shade-plugin</artifactId>
<version>2.2</version>
<executions>
<execution>
<phase>package</phase>
<goals>
<goal>shade</goal>
</goals>
<configuration>
<filters>
<filter>
<artifact>*:*</artifact>
<excludes>
<exclude>META-INF/*.SF</exclude>