HBase-3rowkey的设计
HBase表热点
1 什么是热点
- 检索habse的记录首先要通过row key来定位数据行。
- 当大量的client访问hbase集群的一个或少数几个节点,造成少数region server的读/写请求过多、负载过大,而其他region server负载却很小,就造成了“热点”现象。
2 热点的解决方案
2.1 预分区
- 预分区的目的让表的数据可以均衡的分散在集群中,而不是默认只有一个region分布在集群的一个节点上。
2.2 加盐
- 这里所说的加盐不是密码学中的加盐,而是在rowkey的前面增加随机数,具体就是给rowkey分配一个随机前缀以使得它和之前的rowkey的开头不同
2.3 哈希
- 哈希会使同一行永远用一个前缀加盐。哈希也可以使负载分散到整个集群,但是读却是可以预测的。使用确定的哈希可以让客户端重构完整的rowkey,可以使用get操作准确获取某一个行数据。
rowkey=MD5(username).subString(0,10)+时间戳
2.4 反转
- 反转固定长度或者数字格式的rowkey。这样可以使得rowkey中经常改变的部分(最没有意义的部分)放在前面。
- 这样可以有效的随机rowkey,但是牺牲了rowkey的有序性。
电信公司:
移动-----------> 136xxxx9301 ----->1039xxxx631
136xxxx1234
136xxxx2341
电信
联通
user表
rowkey name age sex address
lisi1 21 m beijing
lisi2 22 m beijing
lisi3 25 m beijing
lisi4 30 m beijing
lisi5 40 f shanghai
lisi6 50 f tianjin
需求:后期想经常按照居住地和年龄进行查询?
rowkey= address+age+随机数
beijing21+随机数
beijing22+随机数
beijing25+随机数
beijing30+随机数
rowkey= address+age+随机数
Rowkey 设计
1 rowkey长度原则
- rowkey是一个二进制码流,可以是任意字符串,最大长度64kb,实际应用中一般为10-100bytes,以byte[]形式保存,一般设计成定长。
- 建议尽可能短;但是也不能太短,否则rowkey前缀重复的概率增大
- 设计过长会降低memstore内存的利用率和HFile存储数据的效率。
2 rowkey散列原则
- 建议将rowkey的高位作为散列字段,这样将提高数据均衡分布在每个RegionServer,以实现负载均衡的几率。
- 如果没有散列字段,首字段直接是时间信息。所有的数据都会集中在一个RegionServer上,这样在数据检索的时候负载会集中在个别的RegionServer上,造成热点问题,会降低查询效率。
3 rowkey唯一原则
- 必须在设计上保证其唯一性,rowkey是按照字典顺序排序存储的
- 因此,设计rowkey的时候,要充分利用这个排序的特点,可以将经常读取的数据存储到一块,将最近可能会被访问的数据放到一块
云数据库HBase的Rowkey设计在数据分区和数据查询中很重要,本节介绍设计Rowkey前需要考虑的一些问题以及设计示例。
问题考虑
- 问题一:Rowkey是唯一的吗?
相同的Rowkey在HBase中认为是同一条数据的多个版本,查询时默认返回最新版本的数据,所以通常Rowkey都需要保证唯一,除非用到多版本特性。
最佳设计示例:Rowkey相当于数据库的主键。Rowkey表示一条记录。Rowkey可以是一个字段也可以是多个字段接起来。Rowkey为[userid]表示每个用户只有一条记录, Rowkey为[userid][orderid]表示每个用户有多条记录。
- 问题二:满足哪种查询场景?
Rowkey的设计限制了数据的查询方式,HBase有两种查询方式。
- 根据完整的Rowkey查询(get方式),例如
SELECT * FROM table WHERE Rowkey = ‘abcde’。说明 get方式需要知道完整的Rowkey,即组成Rowkey所有字段的值都是确定的。 - 根据Rowkey的范围查询(scan方式),例如
SELECT * FROM table WHERE ‘abc’ < Rowkey <’abcx’。说明 scan方式需要知道Rowkey左边的值,例如您使用英文字典查询pre开头的所有单词,也可以查询prefi开头的所有单词,不能查询中间或结尾为prefi的单词。
最佳设计示例:在有限的查询方式下如何实现复杂查询?以下方法可以帮您实现。- 再新建一张表作为索引表。
- 使用Filter在服务端过滤不需要的数据。
- 使用二级索引。
- 使用反向scan方法实现倒序(将新数据排在前面),
scan.setReverse(true)。说明 反向scan的性能比正常scan性能差,如果大部分是倒序场景可以体现在Rowkey设计上,例如[hostname][log-event][timestamp] => [hostname][log-event][Long.MAX_VALUE – timestamp]。
- 根据完整的Rowkey查询(get方式),例如
- 问题三:数据足够分散,会存在堆积的热点现象吗?
散列的目的是将数据分散到不同的分区,不至于产生热点使某一台服务器终止,其他服务器空闲,充分发挥分布式和并发的优势。
最佳设计示例:- 设计md5散列算法:
[userId][orderid] => [md5(userid).subStr(0,4)][userId][orderid]。 - 设计反转:
[userId][orderid] => [reverse(userid)][orderid]。 - 设计取模:
[timestamp][hostname][log-event] => [bucket][timestamp][hostname][log-event]; long bucket = timestamp % numBuckets。 - 增加随机数:
[userId][orderid] => [userId][orderid][random(100)]。
- 设计md5散列算法:
- 问题四:Rowkey可以再短点吗?
短的Rowkey可以减少数据量,提高数据查询和数据写入效率。
最佳设计示例:- 使用Long或Int代替String,例如
'2015122410' => Long(2015122410)。 - 使用编码代替名称,例如
’淘宝‘ => tb。
- 使用Long或Int代替String,例如
- 问题五:使用scan方式会查询出不需要的数据吗?
会的。场景举例:table1的Rowkey为
column1+ column2+ column3,如果您需要查询column1= host1的所有数据,使用scan 'table1',{startkey=> 'host1',endkey=> 'host2'}语句。如果有一条记录为column1=host12,那么此记录也会查询出来。最佳设计示例:- 设计字段定长,
[column1][column2] => [rpad(column1,'x',20)][column2]。 - 添加分隔符,
[column1][column2] => [column1][_][column2]。
- 设计字段定长,
常见设计实例
- 日志类、时间序列数据。列举出三个场景设计Rowkey。
- 查询某台机器某个指标某段时间内的数据,Rowkey设计为
[hostname][log-event][timestamp]。 - 查询某台机器某个指标最新的几条数据,Rowkey设计为
timestamp = Long.MAX_VALUE – timestamp; [hostname][log-event][timestamp]。 - 查询的数据存在只有时间一个维度或某一个维度数据量巨大的情况,Rowkey设计为
long bucket = timestamp % numBuckets; [bucket][timestamp][hostname][log-event]。
- 查询某台机器某个指标某段时间内的数据,Rowkey设计为
- 交易类数据。列举出四个场景设计Rowkey。
- 查询某个卖家某段时间内的交易记录,Rowkey设计为
[seller id][timestmap][order number]。 - 查询某个买家某段时间内的交易记录,Rowkey设计为
[buyer id][timestmap][order number]。 - 根据订单号查询,Rowkey设计为
[order number]。 - 查询中同时满足三张表,一张买家维度表Rowkey设计为
[buyer id][timestmap][order number]。一张卖家维度表Rowkey设计为[seller id][timestmap][order number]。一张订单索引表Rowkey设计为[order number]。
- 查询某个卖家某段时间内的交易记录,Rowkey设计为
Region 分裂
1 region分裂说明
- region中存储的是一张表的数据,当region中的数据条数过多的时候,会直接影响查询效率.
- 当region过大的时候,hbase会将region拆分为两个region , 这也是Hbase的一个优点.
2 Region分裂策略
2.1 ConstantSizeRegionSplitPolicy
- 0.94版本前,HBase region的默认切分策略
- 当region中最大的store大小超过某个阈值(hbase.hregion.max.filesize=10G)之后就会触发切分,一个region等分为2个region。
- 但是在生产线上这种切分策略却有相当大的弊端:
- 切分策略对于大表和小表没有明显的区分。
- 阈值(hbase.hregion.max.filesize)设置较大对大表比较友好,但是小表就有可能不会触发分裂,极端情况下可能就1个,形成热点,这对业务来说并不是什么好事。
- 如果设置较小则对小表友好,但一个大表就会在整个集群产生大量的region,这对于集群的管理、资源使用、failover来说都不是一件好事。
2.2 IncreasingToUpperBoundRegionSplitPolicy
- 0.94版本~2.0版本默认切分策略
- 总体看和ConstantSizeRegionSplitPolicy思路相同
- 一个region中最大的store大小大于设置阈值就会触发切分。
- 但是这个阈值并不像ConstantSizeRegionSplitPolicy是一个固定的值,而是会在一定条件下不断调整,调整规则和region所属表在当前regionserver上的region个数有关系.
- region split阈值的计算公式是:
- 设regioncount:是region所属表在当前regionserver上的region的个数
- 阈值 = regioncount^3 * 128M * 2,当然阈值并不会无限增长,最大不超过MaxRegionFileSize(10G);当region中最大的store的大小达到该阈值的时候进行region split
- 例如:
第一次split阈值 = 1^3 * 256 = 256MB
第二次split阈值 = 2^3 * 256 = 2048MB
第三次split阈值 = 3^3 * 256 = 6912MB
第四次split阈值 = 4^3 * 256 = 16384MB > 10GB,因此取较小的值10GB
后面每次split的size都是10GB了 - 特点
- 相比ConstantSizeRegionSplitPolicy,可以自适应大表、小表;
- 在集群规模比较大的情况下,对大表的表现比较优秀
- 但是,它并不完美,小表可能产生大量的小region,分散在各regionserver上
2.3 SteppingSplitPolicy
- 2.0版本默认切分策略
- 相比 IncreasingToUpperBoundRegionSplitPolicy 简单了一些
- region切分的阈值依然和待分裂region所属表在当前regionserver上的region个数有关系
- 如果region个数等于1,切分阈值为flush size 128M * 2
- 否则为MaxRegionFileSize。
- 这种切分策略对于大集群中的大表、小表会比 IncreasingToUpperBoundRegionSplitPolicy 更加友好,小表不会再产生大量的小region,而是适可而止。
2.4 KeyPrefixRegionSplitPolicy
- 根据rowKey的前缀对数据进行分区,这里是指定rowKey的前多少位作为前缀,比如rowKey都是16位的,指定前5位是前缀,那么前5位相同的rowKey在相同的region中。
2.5 DelimitedKeyPrefixRegionSplitPolicy
- 保证相同前缀的数据在同一个region中,例如rowKey的格式为:userid_eventtype_eventid,指定的delimiter为 _ ,则split的的时候会确保userid相同的数据在同一个region中。
2.6 DisabledRegionSplitPolicy
- 不启用自动拆分, 需要指定手动拆分
Region 合并
1 region合并说明
- Region的合并不是为了性能, 而是出于便于运维的目的 .
- 比如删除了大量的数据 ,这个时候每个Region都变得很小 ,存储多个Region就浪费了 ,这个时候可以把Region合并起来,进而可以减少一些Region服务器节点
2 如何进行region合并
2.1 通过Merge类冷合并Region
-
执行合并前,需要先关闭hbase集群
-
创建一张hbase表:
create 'person','info1',SPLITS => ['1000','2000','3000','4000'] -
查看表region
![]()
-
需求:
需要把person表中的2个region数据进行合并:
person,,1623461265787.b15dce7c3af63faa165e5bade9a29676.
person,1000,1623461265787.785396d84eb17099203fa63c003eb8eb. -
这里通过org.apache.hadoop.hbase.util.Merge类来实现,不需要进入hbase shell,直接执行(需要先关闭hbase集群):
hbase org.apache.hadoop.hbase.util.Merge person person,,1623461265787.b15dce7c3af63faa165e5bade9a29676. person,1000,1623461265787.785396d84eb17099203fa63c003eb8eb. -
成功后界面观察
![]()


2.2 通过online_merge热合并Region
-
不需要关闭hbase集群,在线进行合并
-
与冷合并不同的是,online_merge的传参是Region的hash值,而Region的hash值就是Region名称的最后那段在两个.之间的字符串部分。
-
需求:需要把person表中的2个region数据进行合并:
person,2000,1623461265787.1530224f7edee8855a0cc68af61ba33a.
person,3000,1623461265787.0a717dfd631a860dcb6352d8d423fd16. -
需要进入hbase shell:
merge_region '1530224f7edee8855a0cc68af61ba33a','0a717dfd631a860dcb6352d8d423fd16' -
成功后观察界面
![]()

Phoenix介绍
1.什么是Phoenix
Phoenix是一个HBase的开源SQL引擎。你可以使用标准的JDBC API代替HBase客户端API来创建表,插入数据,查询你的HBase数据。
2.Phoenix底层原理
Phoenix框架将命令行上键入的sql语句翻译成hbase指令,然后hbase用翻译好的指令去操作集群,执行完之后给客户端反馈结果。
3.安装部署
- 需要先安装好hbase集群,phoenix只是一个工具,只需要在一台机器上安装就可以了,这里我们选择hadoop02服务器来进行安装一台即可
1、下载安装包
-
从对应的地址下载:
http://www.apache.org/dyn/closer.lua/phoenix/phoenix-5.1.1/phoenix-hbase-2.2-5.1.1-bin.tar.gz -
这里我们使用的是
- phoenix-hbase-2.2-5.1.1-bin.tar.gz
2、上传解压
- 将安装包上传到hadoop02服务器的/bigdata/soft路径下,然后进行解压
cd /bigdata/soft/
tar -zxf phoenix-hbase-2.2-5.1.1-bin.tar.gz -C /bigdata/install/
3、安装
cd /bigdata/install/phoenix-hbase-2.2-5.1.1-bin
cp -a phoenix-server-hbase-2.2-5.1.1.jar ../hbase-2.2.6/lib/
scp -r phoenix-server-hbase-2.2-5.1.1.jar hadoop01:/bigdata/install/hbase-2.2.6/lib/
scp -r phoenix-server-hbase-2.2-5.1.1.jar hadoop03:/bigdata/install/hbase-2.2.6/lib/
mv bin/hbase-site.xml bin/hbase-site.xml.init
cp $HBASE_HOME/conf/hbase-site.xml ./bin
cp $HADOOP_HOME/etc/hadoop/hdfs-site.xml ./bin
4、配置环境变量
sudo vim /etc/profile
#phoenix
export PHOENIX_HOME=/bigdata/install/phoenix-hbase-2.2-5.1.1-bin
export PHOENIX_CLASSPATH=$PHOENIX_HOME
export PATH=$PATH:$PHOENIX_HOME/bin
source /etc/profile
5、重启hbase集群
- 记得要先启动hadoop集群、zookeeper集群
- hadoop01执行以下命令来重启hbase的集群
stop-hbase.sh
start-hbase.sh
6、验证是否成功
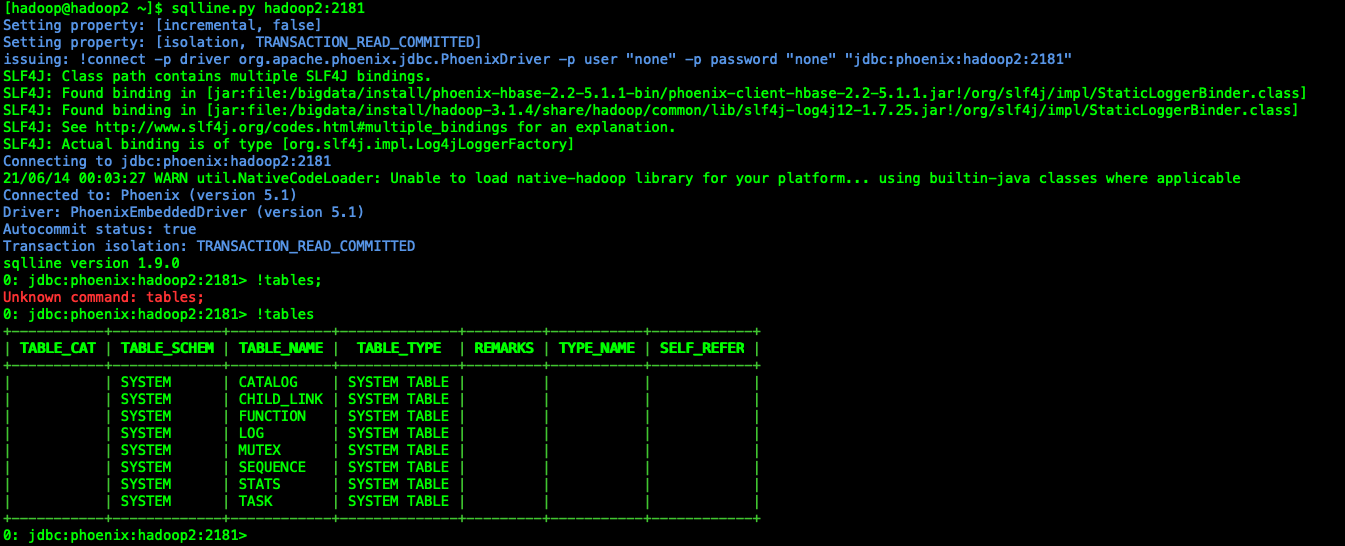
- 1、 hadoop02执行以下命令,进入phoenix客户端
cd /bigdata/install/phoenix-hbase-2.2-5.1.1-bin/ bin/sqlline.py hadoop02:2181 - 2、在命令行模式下输入 !table 查看输出结果
![]()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号