
w3cschool-HBase官方文档-3MapReduce
HBase和MapReduce
HBase和MapReduce
Apache MapReduce 是一个用于分析大量数据的软件框架。它由 Apache Hadoop 提供。MapReduce 本身超出了本文档的范围。开始使用 MapReduce 的好地方是 https://hadoop.apache.org/docs/r2.6.0/hadoop-mapreduce-client/hadoop-mapreduce-client-core/MapReduceTutorial.html。MapReduce 版本2(MR2)现在是 YARN 的一部分。
本章讨论在 HBase 中对数据使用 MapReduce 时需要采取的具体配置步骤。另外,它讨论了 HBase 和 MapReduce 作业之间的其他交互和问题。最后,它讨论了Cascading,MapReduce 的另一种 API。
mapred 和 mapreduce
HBase 中有两个 mapreduce 包,就像 MapReduce 本身一样:org.apache.hadoop.hbase.mapred 和org.apache.hadoop.hbase.mapreduce。前者使用旧式 API,后者使用新模式。后者有更多的设施,尽管你通常可以在旧的包装中找到相同的设备。选择与MapReduce 部署配合使用的软件包。如果有疑问或重新开始,请选择org.apache.hadoop.hbase.mapreduce。在下面的注释中,我们引用了oahhmapreduce,但是如果这是你正在使用的,则用 oahhmapred 替换。
HBase、MapReduce和CLASSPATH
HBase,MapReduce和CLASSPATH
默认情况下,部署到 MapReduce 集群的 MapReduce 作业无权访问 $HBASE_CONF_DIR 类或 HBase 类下的 HBase 配置。
要为 MapReduce 作业提供他们需要的访问权限,可以添加 hbase-site.xml_to _ $ HADOOP_HOME / conf,并将 HBase jar 添加到 $ HADOOP_HOME / lib 目录。然后,您需要在群集中复制这些更改。或者你可以编辑 $ HADOOP_HOME / conf / hadoop-env.sh,并将 hbase 依赖添加到HADOOP_CLASSPATH 变量中。这两种方法都不推荐使用,因为它会使用 HBase 引用污染您的 Hadoop 安装。它还需要您在 Hadoop 可以使用 HBase 数据之前重新启动 Hadoop 集群。
推荐的方法是让 HBase 添加它的依赖 jar 并使用 HADOOP_CLASSPATHor -libjars。
自 HBase 0.90.x 以来,HBase 将其依赖 JAR 添加到作业配置本身。依赖关系只需要在本地 CLASSPATH 可用,从这里它们将被拾取并捆绑到部署到MapReduce 集群的 fat 工作 jar 中。一个基本的技巧就是将完整的 hbase 类路径(所有 hbase 和依赖 jar 以及配置)传递给 mapreduce 作业运行器,让hbase 实用程序从完整类路径中选取需要将其添加到 MapReduce 作业配置中的源代码。
下面的示例针对名为 usertable 的表运行捆绑的 HBase RowCounter MapReduce 作业。它设置为 HADOOP_CLASSPATH 需要在 MapReduce 上下文中运行的 jar 包(包括配置文件,如 hbase-site.xml)。确保为您的系统使用正确版本的 HBase JAR;请在下面的命令行中替换 VERSION 字符串 w/本地 hbase 安装的版本。反引号(`符号)使 shell 执行子命令,设置输入 hbase classpath 为 HADOOP_CLASSPATH。这个例子假设你使用 BASH 兼容的 shell。
$ HADOOP_CLASSPATH=`${HBASE_HOME}/bin/hbase classpath` \
${HADOOP_HOME}/bin/hadoop jar ${HBASE_HOME}/lib/hbase-mapreduce-VERSION.jar \
org.apache.hadoop.hbase.mapreduce.RowCounter usertable上述的命令将针对 hadoop 配置指向的群集上的本地配置指向的 hbase 群集启动行计数 mapreduce 作业。
hbase-mapreduce.jar 的主要内容是一个 Driver(驱动程序),它列出了几个与 hbase 一起使用的基本 mapreduce 任务。例如,假设您的安装是hbase 2.0.0-SNAPSHOT:
$ HADOOP_CLASSPATH=`${HBASE_HOME}/bin/hbase classpath` \
${HADOOP_HOME}/bin/hadoop jar ${HBASE_HOME}/lib/hbase-mapreduce-2.0.0-SNAPSHOT.jar
An example program must be given as the first argument.
Valid program names are:
CellCounter: Count cells in HBase table.
WALPlayer: Replay WAL files.
completebulkload: Complete a bulk data load.
copytable: Export a table from local cluster to peer cluster.
export: Write table data to HDFS.
exportsnapshot: Export the specific snapshot to a given FileSystem.
import: Import data written by Export.
importtsv: Import data in TSV format.
rowcounter: Count rows in HBase table.
verifyrep: Compare the data from tables in two different clusters. WARNING: It doesn't work for incrementColumnValues'd cells since the timestamp is changed after being appended to the log.您可以使用上面列出的缩短名称作为 mapreduce 作业,如下面的行计数器作业重新运行(再次假设您的安装为 hbase 2.0.0-SNAPSHOT):
$ HADOOP_CLASSPATH=`${HBASE_HOME}/bin/hbase classpath` \
${HADOOP_HOME}/bin/hadoop jar ${HBASE_HOME}/lib/hbase-mapreduce-2.0.0-SNAPSHOT.jar \
rowcounter usertable您可能会发现更多有选择性的 hbase mapredcp 工具输出;它列出了针对 hbase 安装运行基本 mapreduce 作业所需的最小 jar 集。它不包括配置。如果您希望MapReduce 作业找到目标群集,则可能需要添加这些文件。一旦你开始做任何实质的事情,你可能还必须添加指向额外的 jar 的指针。只需在运行 hbase mapredcp 时通过系统属性 Dtmpjars 来指定附加项。
对于不打包它们的依赖关系或调用 TableMapReduceUtil#addDependencyJars 的作业,以下命令结构是必需的:
$ HADOOP_CLASSPATH=`${HBASE_HOME}/bin/hbase mapredcp`:${HBASE_HOME}/conf hadoop jar MyApp.jar MyJobMainClass -libjars $(${HBASE_HOME}/bin/hbase mapredcp | tr ':' ',') ...注意
如果您从构建目录运行 HBase 而不是安装位置,该示例可能无法运行。您可能会看到类似以下的错误:
java.lang.RuntimeException: java.lang.ClassNotFoundException: org.apache.hadoop.hbase.mapreduce.RowCounter$RowCounterMapper如果发生这种情况,请尝试按如下方式修改该命令,以便在构建环境中使用来自 target/ 目录的 HBase JAR 。
$ HADOOP_CLASSPATH=${HBASE_BUILD_HOME}/hbase-mapreduce/target/hbase-mapreduce-VERSION-SNAPSHOT.jar:`${HBASE_BUILD_HOME}/bin/hbase classpath` ${HADOOP_HOME}/bin/hadoop jar ${HBASE_BUILD_HOME}/hbase-mapreduce/target/hbase-mapreduce-VERSION-SNAPSHOT.jar rowcounter usertableHBase MapReduce 用户在 0.96.1 和 0.98.4 的通知
一些使用 HBase 的 MapReduce 作业无法启动。该症状是类似于以下情况的异常:
Exception in thread "main" java.lang.IllegalAccessError: class
com.google.protobuf.ZeroCopyLiteralByteString cannot access its superclass
com.google.protobuf.LiteralByteString
at java.lang.ClassLoader.defineClass1(Native Method)
at java.lang.ClassLoader.defineClass(ClassLoader.java:792)
at java.security.SecureClassLoader.defineClass(SecureClassLoader.java:142)
at java.net.URLClassLoader.defineClass(URLClassLoader.java:449)
at java.net.URLClassLoader.access$100(URLClassLoader.java:71)
at java.net.URLClassLoader$1.run(URLClassLoader.java:361)
at java.net.URLClassLoader$1.run(URLClassLoader.java:355)
at java.security.AccessController.doPrivileged(Native Method)
at java.net.URLClassLoader.findClass(URLClassLoader.java:354)
at java.lang.ClassLoader.loadClass(ClassLoader.java:424)
at java.lang.ClassLoader.loadClass(ClassLoader.java:357)
at
org.apache.hadoop.hbase.protobuf.ProtobufUtil.toScan(ProtobufUtil.java:818)
at
org.apache.hadoop.hbase.mapreduce.TableMapReduceUtil.convertScanToString(TableMapReduceUtil.java:433)
at
org.apache.hadoop.hbase.mapreduce.TableMapReduceUtil.initTableMapperJob(TableMapReduceUtil.java:186)
at
org.apache.hadoop.hbase.mapreduce.TableMapReduceUtil.initTableMapperJob(TableMapReduceUtil.java:147)
at
org.apache.hadoop.hbase.mapreduce.TableMapReduceUtil.initTableMapperJob(TableMapReduceUtil.java:270)
at
org.apache.hadoop.hbase.mapreduce.TableMapReduceUtil.initTableMapperJob(TableMapReduceUtil.java:100)
...这是由 HBASE-9867 中引入的优化导致的,它无意中引入了类加载器依赖性。
这会影响两个作业,即使用 libjars 选项和 "fat jar" (在嵌套的 lib 文件夹中打包其运行时依赖项)。
为了满足新的加载器要求,hbase-protocol.jar 必须包含在 Hadoop 的类路径中。以下内容包括用于历史目的。
通过在 Hadoop 的 lib 目录中包括对 hbase-protocol.jar 协议的引用,通过 symlink 或将 jar 复制到新的位置,可以解决整个系统。
这也可以通过 HADOOP_CLASSPATH 在作业提交时将它包含在环境变量中来实现。启动打包依赖关系的作业时,以下所有三个启动命令均满足此要求:
$ HADOOP_CLASSPATH=/path/to/hbase-protocol.jar:/path/to/hbase/conf hadoop jar MyJob.jar MyJobMainClass
$ HADOOP_CLASSPATH=$(hbase mapredcp):/path/to/hbase/conf hadoop jar MyJob.jar MyJobMainClass
$ HADOOP_CLASSPATH=$(hbase classpath) hadoop jar MyJob.jar MyJobMainClass对于不打包它们的依赖关系的 jar,下面的命令结构是必需的:
$ HADOOP_CLASSPATH=$(hbase mapredcp):/etc/hbase/conf hadoop jar MyApp.jar MyJobMainClass -libjars $(hbase mapredcp | tr ':' ',') ...MapReduce扫描缓存
MapReduce扫描缓存
现在,TableMapReduceUtil 恢复了在传入的 Scan 对象中设置扫描程序缓存(在将结果返回给客户端之前缓存的行数)的选项。由于 HBase 0.95(HBASE-11558)中的错误,此功能丢失。这是为 HBase 0.98.5 和0.96.3 而定的。选择扫描仪缓存的优先顺序如下:
- 在扫描对象上设置的缓存设置。
- 通过配置选项 hbase.client.scanner.caching 指定的缓存设置,可以在 hbase-site.xml 中手动设置或通过辅助方法 TableMapReduceUtil.setScannerCaching() 设置。
- 默认值 HConstants.DEFAULT_HBASE_CLIENT_SCANNER_CACHING,设置为 100。
优化缓存设置是客户端等待结果的时间和客户端需要接收的结果集的数量之间的一种平衡。如果缓存设置过大,客户端可能会等待很长时间,否则请求可能会超时。如果设置太小,扫描需要返回几个结果。如果将 scan 视为 shovel,则更大的缓存设置类似于更大的 shovel,而更小的缓存设置相当于更多的 shovel,以填充 bucket。
上面提到的优先级列表允许您设置合理的默认值,并针对特定操作对其进行覆盖。
捆绑HBase MapReduce作业
捆绑HBase MapReduce作业
HBase JAR 也可作为一些捆绑 MapReduce 作业的驱动程序。要了解捆绑的 MapReduce 作业,请运行以下命令:
$ ${HADOOP_HOME}/bin/hadoop jar ${HBASE_HOME}/hbase-mapreduce-VERSION.jar
An example program must be given as the first argument.
Valid program names are:
copytable: Export a table from local cluster to peer cluster
completebulkload: Complete a bulk data load.
export: Write table data to HDFS.
import: Import data written by Export.
importtsv: Import data in TSV format.
rowcounter: Count rows in HBase table每个有效的程序名都是捆绑的 MapReduce 作业。要运行其中一个作业,请在下面的示例之后为您的命令建模。
$ ${HADOOP_HOME}/bin/hadoop jar ${HBASE_HOME}/hbase-mapreduce-VERSION.jar rowcounter myTableHBase作为MapReduce作业数据源和数据接收器
HBase作为MapReduce作业数据源和数据接收器
对于 MapReduce 作业,HBase 可以用作数据源、TableInputFormat 和数据接收器、TableOutputFormat 或 MultiTableOutputFormat。编写读取或写入HBase 的 MapReduce作业,建议子类化 TableMapper 或 TableReducer。
如果您运行使用 HBase 作为源或接收器的 MapReduce 作业,则需要在配置中指定源和接收器表和列名称。
当您从 HBase 读取时,TableInputFormat 请求 HBase 的区域列表并制作一张映射,可以是一个 map-per-region 或 mapreduce.job.maps mapreduce.job.maps ,映射到大于区域数目的数字。如果您为每个节点运行 TaskTracer/NodeManager 和 RegionServer,则映射将在相邻的 TaskTracker/NodeManager 上运行。在写入 HBase 时,避免使用 Reduce 步骤并从映射中写回 HBase 是有意义的。当您的作业不需要 MapReduce 对映射发出的数据进行排序和排序时,这种方法就可以工作。在插入时,HBase 'sorts',因此除非需要,否则双重排序(并在您的 MapReduce 集群周围混洗数据)没有意义。如果您不需要 Reduce,则映射可能会发出在作业结束时为报告处理的记录计数,或者将 Reduces 的数量设置为零并使用 TableOutputFormat。如果运行 Reduce 步骤在你的情况下是有意义的,则通常应使用多个减速器,以便在 HBase 群集上传播负载。
一个新的 HBase 分区程序 HRegionPartitioner 可以运行与现有区域数量一样多的 reducers。当您的表格很大时,HRegionPartitioner 是合适的,并且您的上传不会在完成时大大改变现有区域的数量。否则使用默认分区程序。
在批量导入时直接写入HFiles
在批量导入时直接写入HFiles
如果您正在导入新表格,则可以绕过 HBase API 并将您的内容直接写入文件系统,格式化为 HBase 数据文件(HFiles)。您的导入将运行得更快,也许快一个数量级。有关此机制如何工作的更多信息,请参阅批量加载。
RowCounter示例
RowCounter示例
包含的 RowCounter MapReduce 作业使用 TableInputFormat,并对指定表中的所有行进行计数。要运行它,请使用以下命令:
$ ./bin/hadoop jar hbase-X.X.X.jar这将调用 HBase MapReduce 驱动程序类。从提供的工作选择中进行选择 rowcounter。这将打印 rowcounter 使用建议到标准输出。指定表名,要计数的列和输出目录。
Map-Task分割
默认的 HBase MapReduce Splitter
当 TableInputFormat 用于在 MapReduce 作业中发送 HBase 表时,其分割器将为表的每个区域创建一个映射任务。因此,如果表格中有 100 个区域,则无论在“扫描(Scan)”中选择多少个列族,该作业都会有 100 个 map-task。
自定义分配器
对于那些有兴趣在实现自定义的分割器的人,请参见 TableInputFormatBase 中 getSplits 的方法。这是 map-task 分配的逻辑所在。
HBase MapReduce 读取示例
HBase MapReduce 读取示例
以下是以只读方式将 HBase 用作 MapReduce 源的示例。具体来说,有一个 Mapper 实例,但没有 Reducer,并且没有任何内容从 Mapper 发出。这项工作将被定义如下:
Configuration config = HBaseConfiguration.create();
Job job = new Job(config, "ExampleRead");
job.setJarByClass(MyReadJob.class); // class that contains mapper
Scan scan = new Scan();
scan.setCaching(500); // 1 is the default in Scan, which will be bad for MapReduce jobs
scan.setCacheBlocks(false); // don't set to true for MR jobs
// set other scan attrs
...
TableMapReduceUtil.initTableMapperJob(
tableName, // input HBase table name
scan, // Scan instance to control CF and attribute selection
MyMapper.class, // mapper
null, // mapper output key
null, // mapper output value
job);
job.setOutputFormatClass(NullOutputFormat.class); // because we aren't emitting anything from mapper
boolean b = job.waitForCompletion(true);
if (!b) {
throw new IOException("error with job!");
}映射器实例将扩展 TableMapper:
public static class MyMapper extends TableMapper<Text, Text> {
public void map(ImmutableBytesWritable row, Result value, Context context) throws InterruptedException, IOException {
// process data for the row from the Result instance.
}
}HBase MapReduce读写示例
HBase MapReduce读写示例
以下是使用 HBase 作为 MapReduce 的源代码和接收器的示例。这个例子将简单地将数据从一个表复制到另一个表。
Configuration config = HBaseConfiguration.create();
Job job = new Job(config,"ExampleReadWrite");
job.setJarByClass(MyReadWriteJob.class); // class that contains mapper
Scan scan = new Scan();
scan.setCaching(500); // 1 is the default in Scan, which will be bad for MapReduce jobs
scan.setCacheBlocks(false); // don't set to true for MR jobs
// set other scan attrs
TableMapReduceUtil.initTableMapperJob(
sourceTable, // input table
scan, // Scan instance to control CF and attribute selection
MyMapper.class, // mapper class
null, // mapper output key
null, // mapper output value
job);
TableMapReduceUtil.initTableReducerJob(
targetTable, // output table
null, // reducer class
job);
job.setNumReduceTasks(0);
boolean b = job.waitForCompletion(true);
if (!b) {
throw new IOException("error with job!");
}需要解释的是 TableMapReduceUtil 正在做什么,特别是对于减速器。TableOutputFormat 被用作 outputFormat 类,并且正在配置几个参数(例如,TableOutputFormat.OUTPUT_TABLE),以及将 reducer 输出键设置为 ImmutableBytesWritable 和 reducer 值为 Writable。这些可以由程序员在作业和 conf 中设置,但 TableMapReduceUtil 试图让事情变得更容易。
以下是示例映射器,它将创建 Put 并匹配输入 Result 并发出它。注意:这是 CopyTable 实用程序的功能。
public static class MyMapper extends TableMapper<ImmutableBytesWritable, Put> {
public void map(ImmutableBytesWritable row, Result value, Context context) throws IOException, InterruptedException {
// this example is just copying the data from the source table...
context.write(row, resultToPut(row,value));
}
private static Put resultToPut(ImmutableBytesWritable key, Result result) throws IOException {
Put put = new Put(key.get());
for (KeyValue kv : result.raw()) {
put.add(kv);
}
return put;
}
}实际上并没有一个简化步骤,所以 TableOutputFormat 负责将 Put 发送到目标表。
这只是一个例子,开发人员可以选择不使用 TableOutputFormat 并连接到目标表本身。
HBase MapReduce摘要到HBase示例
HBase MapReduce摘要到HBase示例
以下的示例使用 HBase 作为 MapReduce 源,并使用一个总结步骤。此示例将计算表中某个值的不同实例的数量,并将这些汇总计数写入另一个表中。
Configuration config = HBaseConfiguration.create();
Job job = new Job(config,"ExampleSummary");
job.setJarByClass(MySummaryJob.class); // class that contains mapper and reducer
Scan scan = new Scan();
scan.setCaching(500); // 1 is the default in Scan, which will be bad for MapReduce jobs
scan.setCacheBlocks(false); // don't set to true for MR jobs
// set other scan attrs
TableMapReduceUtil.initTableMapperJob(
sourceTable, // input table
scan, // Scan instance to control CF and attribute selection
MyMapper.class, // mapper class
Text.class, // mapper output key
IntWritable.class, // mapper output value
job);
TableMapReduceUtil.initTableReducerJob(
targetTable, // output table
MyTableReducer.class, // reducer class
job);
job.setNumReduceTasks(1); // at least one, adjust as required
boolean b = job.waitForCompletion(true);
if (!b) {
throw new IOException("error with job!");
}在此示例映射器中,选择一个带有字符串值的列作为要汇总的值。该值用作从映射器发出的密钥,IntWritable 代表实例计数器。
public static class MyMapper extends TableMapper<Text, IntWritable> {
public static final byte[] CF = "cf".getBytes();
public static final byte[] ATTR1 = "attr1".getBytes();
private final IntWritable ONE = new IntWritable(1);
private Text text = new Text();
public void map(ImmutableBytesWritable row, Result value, Context context) throws IOException, InterruptedException {
String val = new String(value.getValue(CF, ATTR1));
text.set(val); // we can only emit Writables...
context.write(text, ONE);
}
}在 reducer 中,“ones” 被计数(就像任何其他的 MR 例子一样),然后发出一个 Put。
public static class MyTableReducer extends TableReducer<Text, IntWritable, ImmutableBytesWritable> {
public static final byte[] CF = "cf".getBytes();
public static final byte[] COUNT = "count".getBytes();
public void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
int i = 0;
for (IntWritable val : values) {
i += val.get();
}
Put put = new Put(Bytes.toBytes(key.toString()));
put.add(CF, COUNT, Bytes.toBytes(i));
context.write(null, put);
}
}HBase MapReduce摘要到文件示例
HBase MapReduce摘要到文件示例
这与HBase MapReduce摘要到HBase示例非常相似,不同之处在于,它将 HBase 用作 MapReduce 源,但将 HDFS 用作接收器。差异在于作业设置和减速器中。映射器保持不变。
Configuration config = HBaseConfiguration.create();
Job job = new Job(config,"ExampleSummaryToFile");
job.setJarByClass(MySummaryFileJob.class); // class that contains mapper and reducer
Scan scan = new Scan();
scan.setCaching(500); // 1 is the default in Scan, which will be bad for MapReduce jobs
scan.setCacheBlocks(false); // don't set to true for MR jobs
// set other scan attrs
TableMapReduceUtil.initTableMapperJob(
sourceTable, // input table
scan, // Scan instance to control CF and attribute selection
MyMapper.class, // mapper class
Text.class, // mapper output key
IntWritable.class, // mapper output value
job);
job.setReducerClass(MyReducer.class); // reducer class
job.setNumReduceTasks(1); // at least one, adjust as required
FileOutputFormat.setOutputPath(job, new Path("/tmp/mr/mySummaryFile")); // adjust directories as required
boolean b = job.waitForCompletion(true);
if (!b) {
throw new IOException("error with job!");
}如上所述,前面的Mapper可以与此示例保持不变。至于减速机,它是一种“通用”的减速机,而不是扩展的制表机和发射装置。
public static class MyReducer extends Reducer<Text, IntWritable, Text, IntWritable> {
public void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
int i = 0;
for (IntWritable val : values) {
i += val.get();
}
context.write(key, new IntWritable(i));
}
}HBase MapReduce摘要到没有Reducer的HBase
HBase MapReduce摘要到没有Reducer的HBase
如果您使用 HBase 作为减速器(reducer),也可以在不使用减速器的情况下执行摘要。
工作摘要需要 HBase 目标表。Table 方法 incrementColumnValue 将用于自动增加值。从性能角度来看,对于每个 map-task,保留一个 value 值为 map 的值,并且 在 mapper 的 cleanup 方法期间为每个 key 设置一次更新可能是有意义的。但是,根据要处理的行数和唯一键的不同,您的里程可能会有所不同。
最后,摘要结果在 HBase 中。
HBase MapReduce摘要到RDBMS
HBase MapReduce摘要到RDBMS
有时候给 RDBMS 生成摘要更为合适。对于这些情况,可以通过自定义减速器直接向 RDBMS 生成摘要。该 setup 方法可以连接到 RDBMS(连接信息可以通过上下文中的自定义参数传递),并且清理方法可以关闭连接。
重要的是,要了解工作中的减速器的数量会影响到摘要的实现,您必须将其设计到您的减速器中。具体而言,它是否被设计为以单例(一个减速器)或多个减速器运行。是或不是,这取决于你的用例。认识到分配给作业的减速者越多,同时建立到 RDBMS 的连接就会越多 - 这将会扩展,但仅限于某一点。
public static class MyRdbmsReducer extends Reducer<Text, IntWritable, Text, IntWritable> {
private Connection c = null;
public void setup(Context context) {
// create DB connection...
}
public void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
// do summarization
// in this example the keys are Text, but this is just an example
}
public void cleanup(Context context) {
// close db connection
}
}最后,摘要结果将写入您的 RDBMS 表。
访问MapReduce作业中的其他HBase表
访问MapReduce作业中的其他HBase表
尽管当前框架允许一个 HBase 表作为 MapReduce 作业的输入,其他的HBase表可以作为查找表来访问,等等,在 MapReduce 作业中,通过在 Mapper 的 setup 方法中创建一个 Table 实例。
public class MyMapper extends TableMapper<Text, LongWritable> {
private Table myOtherTable;
public void setup(Context context) {
// In here create a Connection to the cluster and save it or use the Connection
// from the existing table
myOtherTable = connection.getTable("myOtherTable");
}
public void map(ImmutableBytesWritable row, Result value, Context context) throws IOException, InterruptedException {
// process Result...
// use 'myOtherTable' for lookups
}HBase推测执行
HBase推测执行
通常建议关闭使用 HBase 作为源的 MapReduce 作业的推测执行(speculative execution)功能。这可以通过属性或整个集群来实现。特别是对于长时间运行的作业,推测执行将创建重复的映射任务,将您的数据写入 HBase;这可能不是你想要的。
MapReduce的替代API:Cascading
Cascading
Cascading 是 MapReduce 的替代 API,它实际上使用 MapReduce,但允许您以简化的方式编写 MapReduce 代码。
以下示例显示了 Cascading Flow,它将数据“汇集(sinks)”到 HBase 集群中。同样的 hBaseTap API 也可以用于“源(source)”数据:
// read data from the default filesystem
// emits two fields: "offset" and "line"
Tap source = new Hfs( new TextLine(), inputFileLhs );
// store data in an HBase cluster
// accepts fields "num", "lower", and "upper"
// will automatically scope incoming fields to their proper familyname, "left" or "right"
Fields keyFields = new Fields( "num" );
String[] familyNames = {"left", "right"};
Fields[] valueFields = new Fields[] {new Fields( "lower" ), new Fields( "upper" ) };
Tap hBaseTap = new HBaseTap( "multitable", new HBaseScheme( keyFields, familyNames, valueFields ), SinkMode.REPLACE );
// a simple pipe assembly to parse the input into fields
// a real app would likely chain multiple Pipes together for more complex processing
Pipe parsePipe = new Each( "insert", new Fields( "line" ), new RegexSplitter( new Fields( "num", "lower", "upper" ), " " ) );
// "plan" a cluster executable Flow
// this connects the source Tap and hBaseTap (the sink Tap) to the parsePipe
Flow parseFlow = new FlowConnector( properties ).connect( source, hBaseTap, parsePipe );
// start the flow, and block until complete
parseFlow.complete();
// open an iterator on the HBase table we stuffed data into
TupleEntryIterator iterator = parseFlow.openSink();
while(iterator.hasNext())
{
// print out each tuple from HBase
System.out.println( "iterator.next() = " + iterator.next() );
}
iterator.close();HBase集成MapReduce
集成分析
- HBase表中的数据最终都是存储在HDFS上,HBase天生的支持MR的操作,我们可以通过MR直接处理HBase表中的数据,
并且MR可以将处理后的结果直接存储到HBase表中。 - 参考地址:http://hbase.apache.org/book.html#mapreduce
1 实现方式一
- 读取HBase当中某张表的数据,将数据写入到另外一张表的列族里面去
2 实现方式二
- 读取HDFS上面的数据,写入到HBase表里面去
3 实现方式三
-
通过bulkload的方式批量加载数据到HBase表中
-
加载数据到HBase当中去的方式多种多样,我们可以使用HBase的javaAPI或者使用sqoop将我们的数据写入或者导入到HBase当中去,
但是这些方式不是最佳的,因为在导入的过程中占用Region资源导致效率低下- HBase数据正常写流程回顾

- HBase数据正常写流程回顾
-
通过MR的程序,将我们的数据直接转换成HBase的最终存储格式HFile,然后直接load数据到HBase当中去即可
- bulkload方式的处理示意图
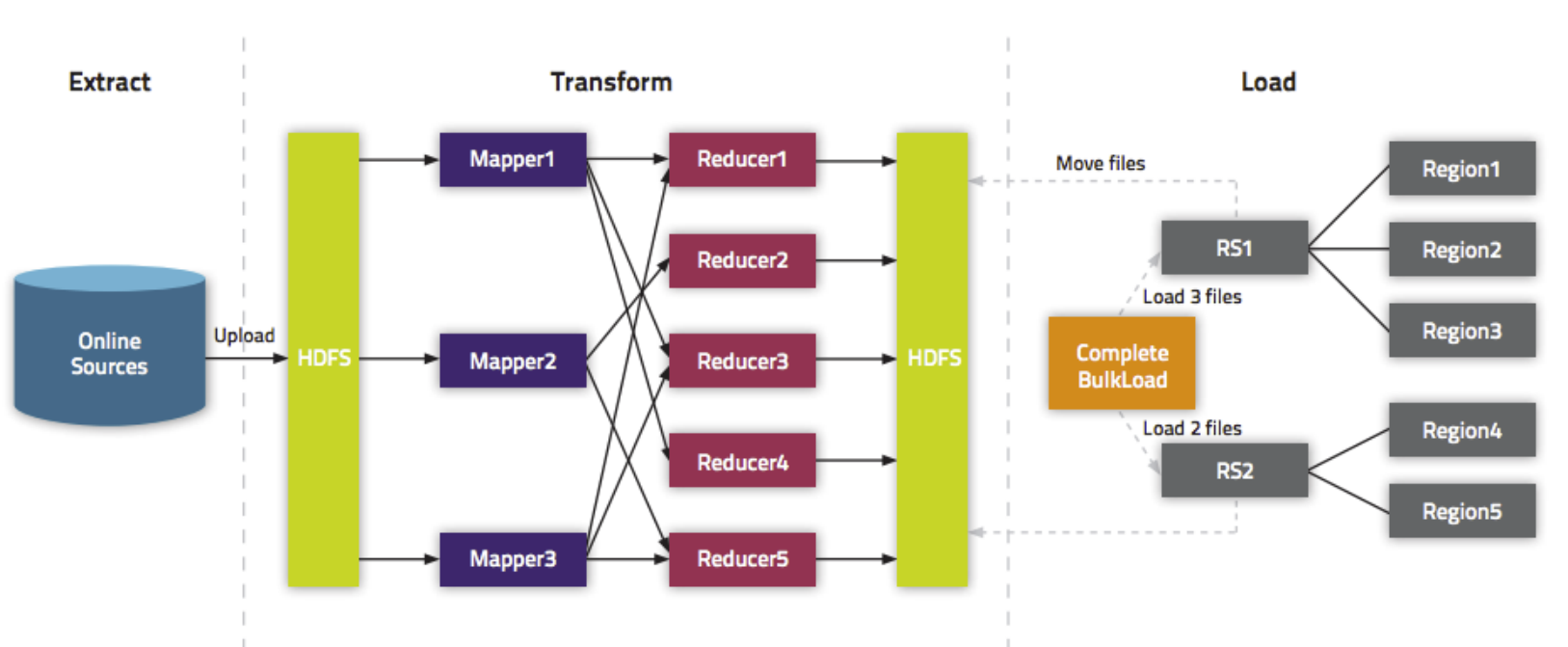
- bulkload方式的处理示意图
-
使用bulkload的方式批量加载数据的好处
- 导入过程不占用Region资源
- 能快速导入海量的数据
- 节省内存
实现方式一
- 读取HBase当中person这张表的info1:name、info2:age数据,将数据写入到另外一张person1表的info1列族里面去
- 第一步:创建person1这张hbase表
注意:列族的名字要与person表的列族名字相同
create 'person1','info1'
- 第二步:创建maven工程并导入jar包
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<parent>
<artifactId>tenic</artifactId>
<groupId>org.example</groupId>
<version>1.0-SNAPSHOT</version>
</parent>
<modelVersion>4.0.0</modelVersion>
<artifactId>HbaseMrDdemo</artifactId>
<dependencies>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>3.1.4</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-auth</artifactId>
<version>3.1.4</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.hbase/hbase-client -->
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-client</artifactId>
<version>2.2.2</version>
</dependency>
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-mapreduce</artifactId>
<version>2.2.2</version>
</dependency>
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-server</artifactId>
<version>2.2.2</version>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.12</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.testng</groupId>
<artifactId>testng</artifactId>
<version>6.14.3</version>
<scope>test</scope>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.0</version>
<configuration>
<source>1.8</source>
<target>1.8</target>
<encoding>UTF-8</encoding>
<!-- <verbal>true</verbal>-->
</configuration>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-shade-plugin</artifactId>
<version>2.2</version>
<executions>
<execution>
<phase>package</phase>
<goals>
<goal>shade</goal>
</goals>
<configuration>
<filters>
<filter>
<artifact>*:*</artifact>
<excludes>
<exclude>META-INF/*.SF