Golang-结构体6
http://c.biancheng.net/golang/struct/
Go语言结构体定义
Go语言可以通过自定义的方式形成新的类型,结构体就是这些类型中的一种复合类型,结构体是由零个或多个任意类型的值聚合成的实体,每个值都可以称为结构体的成员。
结构体成员也可以称为“字段”,这些字段有以下特性:
- 字段拥有自己的类型和值;
- 字段名必须唯一;
- 字段的类型也可以是结构体,甚至是字段所在结构体的类型。
使用关键字 type 可以将各种基本类型定义为自定义类型,基本类型包括整型、字符串、布尔等。结构体是一种复合的基本类型,通过 type 定义为自定义类型后,使结构体更便于使用。
结构体的定义格式如下:
type 类型名 struct {
字段1 字段1类型
字段2 字段2类型
…
}
对各个部分的说明:
- 类型名:标识自定义结构体的名称,在同一个包内不能重复。
- struct{}:表示结构体类型,
type 类型名 struct{}可以理解为将 struct{} 结构体定义为类型名的类型。 - 字段1、字段2……:表示结构体字段名,结构体中的字段名必须唯一。
- 字段1类型、字段2类型……:表示结构体各个字段的类型。
使用结构体可以表示一个包含 X 和 Y 整型分量的点结构,代码如下:
- type Point struct {
- X int
- Y int
- }
同类型的变量也可以写在一行,颜色的红、绿、蓝 3 个分量可以使用 byte 类型表示,定义的颜色结构体如下:
- type Color struct {
- R, G, B byte
- }
Go语言实例化结构体——为结构体分配内存并初始化
结构体的定义只是一种内存布局的描述,只有当结构体实例化时,才会真正地分配内存,因此必须在定义结构体并实例化后才能使用结构体的字段。
实例化就是根据结构体定义的格式创建一份与格式一致的内存区域,结构体实例与实例间的内存是完全独立的。
Go语言可以通过多种方式实例化结构体,根据实际需要可以选用不同的写法。
基本的实例化形式
结构体本身是一种类型,可以像整型、字符串等类型一样,以 var 的方式声明结构体即可完成实例化。
基本实例化格式如下:
var ins T
其中,T 为结构体类型,ins 为结构体的实例。
用结构体表示的点结构(Point)的实例化过程请参见下面的代码:
- type Point struct {
- X int
- Y int
- }
- var p Point
- p.X = 10
- p.Y = 20
在例子中,使用.来访问结构体的成员变量,如p.X和p.Y等,结构体成员变量的赋值方法与普通变量一致。
创建指针类型的结构体
Go语言中,还可以使用 new 关键字对类型(包括结构体、整型、浮点数、字符串等)进行实例化,结构体在实例化后会形成指针类型的结构体。
使用 new 的格式如下:
ins := new(T)
其中:
- T 为类型,可以是结构体、整型、字符串等。
- ins:T 类型被实例化后保存到 ins 变量中,ins 的类型为 *T,属于指针。
Go语言让我们可以像访问普通结构体一样使用.来访问结构体指针的成员。
下面的例子定义了一个玩家(Player)的结构,玩家拥有名字、生命值和魔法值,实例化玩家(Player)结构体后,可对成员进行赋值,代码如下:
- type Player struct{
- Name string
- HealthPoint int
- MagicPoint int
- }
- tank := new(Player)
- tank.Name = "Canon"
- tank.HealthPoint = 300
经过 new 实例化的结构体实例在成员赋值上与基本实例化的写法一致。
Go语言和 C/C++
在 C/C++ 语言中,使用 new 实例化类型后,访问其成员变量时必须使用->操作符。
在Go语言中,访问结构体指针的成员变量时可以继续使用.,这是因为Go语言为了方便开发者访问结构体指针的成员变量,使用了语法糖(Syntactic sugar)技术,将 ins.Name 形式转换为 (*ins).Name。
取结构体的地址实例化
在Go语言中,对结构体进行&取地址操作时,视为对该类型进行一次 new 的实例化操作,取地址格式如下:
ins := &T{}
其中:
- T 表示结构体类型。
- ins 为结构体的实例,类型为 *T,是指针类型。
下面使用结构体定义一个命令行指令(Command),指令中包含名称、变量关联和注释等,对 Command 进行指针地址的实例化,并完成赋值过程,代码如下:
- type Command struct {
- Name string // 指令名称
- Var *int // 指令绑定的变量
- Comment string // 指令的注释
- }
- var version int = 1
- cmd := &Command{}
- cmd.Name = "version"
- cmd.Var = &version
- cmd.Comment = "show version"
代码说明如下:
- 第 1 行,定义 Command 结构体,表示命令行指令
- 第 3 行,命令绑定的变量,使用整型指针绑定一个指针,指令的值可以与绑定的值随时保持同步。
- 第 7 行,命令绑定的目标整型变量:版本号。
- 第 9 行,对结构体取地址实例化。
- 第 10~12 行,初始化成员字段。
取地址实例化是最广泛的一种结构体实例化方式,可以使用函数封装上面的初始化过程,代码如下:
- func newCommand(name string, varref *int, comment string) *Command {
- return &Command{
- Name: name,
- Var: varref,
- Comment: comment,
- }
- }
- cmd = newCommand(
- "version",
- &version,
- "show version",
- )
Go语言初始化结构体的成员变量
结构体在实例化时可以直接对成员变量进行初始化,初始化有两种形式分别是以字段“键值对”形式和多个值的列表形式,键值对形式的初始化适合选择性填充字段较多的结构体,多个值的列表形式适合填充字段较少的结构体。
使用“键值对”初始化结构体
结构体可以使用“键值对”(Key value pair)初始化字段,每个“键”(Key)对应结构体中的一个字段,键的“值”(Value)对应字段需要初始化的值。
键值对的填充是可选的,不需要初始化的字段可以不填入初始化列表中。
结构体实例化后字段的默认值是字段类型的默认值,例如 ,数值为 0、字符串为 ""(空字符串)、布尔为 false、指针为 nil 等。
1) 键值对初始化结构体的书写格式
键值对初始化的格式如下:
ins := 结构体类型名{
字段1: 字段1的值,
字段2: 字段2的值,
…
}
下面是对各个部分的说明:
- 结构体类型:定义结构体时的类型名称。
- 字段1、字段2:结构体成员的字段名,结构体类型名的字段初始化列表中,字段名只能出现一次。
- 字段1的值、字段2的值:结构体成员字段的初始值。
键值之间以:分隔,键值对之间以,分隔。
2) 使用键值对填充结构体的例子
下面示例中描述了家里的人物关联,正如儿歌里唱的:“爸爸的爸爸是爷爷”,人物之间可以使用多级的 child 来描述和建立关联,使用键值对形式填充结构体的代码如下:
- type People struct {
- name string
- child *People
- }
- relation := &People{
- name: "爷爷",
- child: &People{
- name: "爸爸",
- child: &People{
- name: "我",
- },
- },
- }
代码说明如下:
- 第 1 行,定义 People 结构体。
- 第 2 行,结构体的字符串字段。
- 第 3 行,结构体的结构体指针字段,类型是 *People。
- 第 6 行,relation 由 People 类型取地址后,形成类型为 *People 的实例。
- 第 8 行,child 在初始化时,需要 *People 类型的值,使用取地址初始化一个 People。
提示:结构体成员中只能包含结构体的指针类型,包含非指针类型会引起编译错误。
使用多个值的列表初始化结构体
Go语言可以在“键值对”初始化的基础上忽略“键”,也就是说,可以使用多个值的列表初始化结构体的字段。
1) 多个值列表初始化结构体的书写格式
多个值使用逗号分隔初始化结构体,例如:
ins := 结构体类型名{
字段1的值,
字段2的值,
…
}
使用这种格式初始化时,需要注意:
- 必须初始化结构体的所有字段。
- 每一个初始值的填充顺序必须与字段在结构体中的声明顺序一致。
- 键值对与值列表的初始化形式不能混用。
2) 多个值列表初始化结构体的例子
下面的例子描述了一段地址结构,地址要求具有一定的顺序,例如:
- type Address struct {
- Province string
- City string
- ZipCode int
- PhoneNumber string
- }
- addr := Address{
- "四川",
- "成都",
- 610000,
- "0",
- }
- fmt.Println(addr)
运行代码,输出如下:
{四川 成都 610000 0}
初始化匿名结构体
匿名结构体没有类型名称,无须通过 type 关键字定义就可以直接使用。
1) 匿名结构体定义格式和初始化写法
匿名结构体的初始化写法由结构体定义和键值对初始化两部分组成,结构体定义时没有结构体类型名,只有字段和类型定义,键值对初始化部分由可选的多个键值对组成,如下格式所示:
ins := struct {
// 匿名结构体字段定义
字段1 字段类型1
字段2 字段类型2
…
}{
// 字段值初始化
初始化字段1: 字段1的值,
初始化字段2: 字段2的值,
…
}
下面是对各个部分的说明:
- 字段1、字段2……:结构体定义的字段名。
- 初始化字段1、初始化字段2……:结构体初始化时的字段名,可选择性地对字段初始化。
- 字段类型1、字段类型2……:结构体定义字段的类型。
- 字段1的值、字段2的值……:结构体初始化字段的初始值。
键值对初始化部分是可选的,不初始化成员时,匿名结构体的格式变为:
ins := struct {
字段1 字段类型1
字段2 字段类型2
…
}
2) 使用匿名结构体的例子
在本示例中,使用匿名结构体的方式定义和初始化一个消息结构,这个消息结构具有消息标示部分(ID)和数据部分(data),打印消息内容的 printMsg() 函数在接收匿名结构体时需要在参数上重新定义匿名结构体,代码如下:
- package main
- import (
- "fmt"
- )
- // 打印消息类型, 传入匿名结构体
- func printMsgType(msg *struct {
- id int
- data string
- }) {
- // 使用动词%T打印msg的类型
- fmt.Printf("%T\n", msg)
- }
- func main() {
- // 实例化一个匿名结构体
- msg := &struct { // 定义部分
- id int
- data string
- }{ // 值初始化部分
- 1024,
- "hello",
- }
- printMsgType(msg)
- }
代码输出如下:
*struct { id int; data string }
代码说明如下:
- 第 8 行,定义 printMsgType() 函数,参数为 msg,类型为
*struct{id int data string},因为类型没有使用 type 定义,所以需要在每次用到的地方进行定义。 - 第 14 行,使用字符串格式化中的
%T动词,将 msg 的类型名打印出来。 - 第 20 行,对匿名结构体进行实例化,同时初始化成员。
- 第 21 和 22 行,定义匿名结构体的字段。
- 第 24 和 25 行,给匿名结构体字段赋予初始值。
- 第 28 行,将 msg 传入 printMsgType() 函数中进行函数调用。
Go语言构造函数
Go语言的类型或结构体没有构造函数的功能,但是我们可以使用结构体初始化的过程来模拟实现构造函数。
其他编程语言构造函数的一些常见功能及特性如下:
- 每个类可以添加构造函数,多个构造函数使用函数重载实现。
- 构造函数一般与类名同名,且没有返回值。
- 构造函数有一个静态构造函数,一般用这个特性来调用父类的构造函数。
- 对于 C++ 来说,还有默认构造函数、拷贝构造函数等。
多种方式创建和初始化结构体——模拟构造函数重载
如果使用结构体描述猫的特性,那么根据猫的颜色和名字可以有不同种类的猫,那么不同的颜色和名字就是结构体的字段,同时可以使用颜色和名字构造不同种类的猫的实例,这个过程可以参考下面的代码:
- type Cat struct {
- Color string
- Name string
- }
- func NewCatByName(name string) *Cat {
- return &Cat{
- Name: name,
- }
- }
- func NewCatByColor(color string) *Cat {
- return &Cat{
- Color: color,
- }
- }
代码说明如下:
- 第 1 行定义 Cat 结构,包含颜色和名字字段。
- 第 6 行定义用名字构造猫结构的函数,返回 Cat 指针。
- 第 7 行取地址实例化猫的结构体。
- 第 8 行初始化猫的名字字段,忽略颜色字段。
- 第 12 行定义用颜色构造猫结构的函数,返回 Cat 指针。
在这个例子中,颜色和名字两个属性的类型都是字符串,由于Go语言中没有函数重载,为了避免函数名字冲突,使用 NewCatByName() 和 NewCatByColor() 两个不同的函数名表示不同的 Cat 构造过程。
带有父子关系的结构体的构造和初始化——模拟父级构造调用
黑猫是一种猫,猫是黑猫的一种泛称,同时描述这两种概念时,就是派生,黑猫派生自猫的种类,使用结构体描述猫和黑猫的关系时,将猫(Cat)的结构体嵌入到黑猫(BlackCat)中,表示黑猫拥有猫的特性,然后再使用两个不同的构造函数分别构造出黑猫和猫两个结构体实例,参考下面的代码:
- type Cat struct {
- Color string
- Name string
- }
- type BlackCat struct {
- Cat // 嵌入Cat, 类似于派生
- }
- // “构造基类”
- func NewCat(name string) *Cat {
- return &Cat{
- Name: name,
- }
- }
- // “构造子类”
- func NewBlackCat(color string) *BlackCat {
- cat := &BlackCat{}
- cat.Color = color
- return cat
- }
代码说明如下:
- 第 6 行,定义 BlackCat 结构,并嵌入了 Cat 结构体,BlackCat 拥有 Cat 的所有成员,实例化后可以自由访问 Cat 的所有成员。
- 第 11 行,NewCat() 函数定义了 Cat 的构造过程,使用名字作为参数,填充 Cat 结构体。
- 第 18 行,NewBlackCat() 使用 color 作为参数,构造返回 BlackCat 指针。
- 第 19 行,实例化 BlackCat 结构,此时 Cat 也同时被实例化。
- 第 20 行,填充 BlackCat 中嵌入的 Cat 颜色属性,BlackCat 没有任何成员,所有的成员都来自于 Cat。
这个例子中,Cat 结构体类似于面向对象中的“基类”,BlackCat 嵌入 Cat 结构体,类似于面向对象中的“派生”,实例化时,BlackCat 中的 Cat 也会一并被实例化。
总之,Go语言中没有提供构造函数相关的特殊机制,用户根据自己的需求,将参数使用函数传递到结构体构造参数中即可完成构造函数的任务。
Go语言初始化内嵌结构体
结构体内嵌初始化时,将结构体内嵌的类型作为字段名像普通结构体一样进行初始化,详细实现过程请参考下面的代码。
车辆结构的组装和初始化:
- package main
- import "fmt"
- // 车轮
- type Wheel struct {
- Size int
- }
- // 引擎
- type Engine struct {
- Power int // 功率
- Type string // 类型
- }
- // 车
- type Car struct {
- Wheel
- Engine
- }
- func main() {
- c := Car{
- // 初始化轮子
- Wheel: Wheel{
- Size: 18,
- },
- // 初始化引擎
- Engine: Engine{
- Type: "1.4T",
- Power: 143,
- },
- }
- fmt.Printf("%+v\n", c)
- }
代码说明如下:
- 第 6 行定义车轮结构。
- 第 11 行定义引擎结构。
- 第 17 行定义车结构,由车轮和引擎结构体嵌入。
- 第 27 行,将 Car 的 Wheel 字段使用 Wheel 结构体进行初始化。
- 第 32 行,将 Car 的 Engine 字段使用 Engine 结构体进行初始化。
初始化内嵌匿名结构体
在前面描述车辆和引擎的例子中,有时考虑编写代码的便利性,会将结构体直接定义在嵌入的结构体中。也就是说,结构体的定义不会被外部引用到。在初始化这个被嵌入的结构体时,就需要再次声明结构才能赋予数据。具体请参考下面的代码。
- package main
- import "fmt"
- // 车轮
- type Wheel struct {
- Size int
- }
- // 车
- type Car struct {
- Wheel
- // 引擎
- Engine struct {
- Power int // 功率
- Type string // 类型
- }
- }
- func main() {
- c := Car{
- // 初始化轮子
- Wheel: Wheel{
- Size: 18,
- },
- // 初始化引擎
- Engine: struct {
- Power int
- Type string
- }{
- Type: "1.4T",
- Power: 143,
- },
- }
- fmt.Printf("%+v\n", c)
- }
代码说明如下:
- 第 14 行中原来的 Engine 结构体被直接定义在 Car 的结构体中。这种嵌入的写法就是将原来的结构体类型转换为 struct{…}。
- 第 30 行,需要对 Car 的 Engine 字段进行初始化,由于 Engine 字段的类型并没有被单独定义,因此在初始化其字段时需要先填写 struct{…} 声明其类型。
- 第 3行开始填充这个匿名结构体的数据,按“键:值”格式填充。
Go语言垃圾回收和SetFinalizer
Go语言自带垃圾回收机制(GC)。GC 通过独立的进程执行,它会搜索不再使用的变量,并将其释放。需要注意的是,GC 在运行时会占用机器资源。
GC 是自动进行的,如果要手动进行 GC,可以使用 runtime.GC() 函数,显式的执行 GC。显式的进行 GC 只在某些特殊的情况下才有用,比如当内存资源不足时调用 runtime.GC() ,这样会立即释放一大片内存,但是会造成程序短时间的性能下降。
finalizer(终止器)是与对象关联的一个函数,通过 runtime.SetFinalizer 来设置,如果某个对象定义了 finalizer,当它被 GC 时候,这个 finalizer 就会被调用,以完成一些特定的任务,例如发信号或者写日志等。
在Go语言中 SetFinalizer 函数是这样定义的:
func SetFinalizer(x, f interface{})
参数说明如下:
- 参数 x 必须是一个指向通过 new 申请的对象的指针,或者通过对复合字面值取址得到的指针。
- 参数 f 必须是一个函数,它接受单个可以直接用 x 类型值赋值的参数,也可以有任意个被忽略的返回值。
SetFinalizer 函数可以将 x 的终止器设置为 f,当垃圾收集器发现 x 不能再直接或间接访问时,它会清理 x 并调用 f(x)。
另外,x 的终止器会在 x 不能直接或间接访问后的任意时间被调用执行,不保证终止器会在程序退出前执行,因此一般终止器只用于在长期运行的程序中释放关联到某对象的非内存资源。例如,当一个程序丢弃一个 os.File 对象时没有调用其 Close 方法,该 os.File 对象可以使用终止器去关闭对应的操作系统文件描述符。
终止器会按依赖顺序执行:如果 A 指向 B,两者都有终止器,且 A 和 B 没有其它关联,那么只有 A 的终止器执行完成,并且 A 被释放后,B 的终止器才可以执行。
如果 *x 的大小为 0 字节,也不保证终止器会执行。
此外,我们也可以使用SetFinalizer(x, nil)来清理绑定到 x 上的终止器。
提示:终止器只有在对象被 GC 时,才会被执行。其他情况下,都不会被执行,即使程序正常结束或者发生错误。
【示例】在函数 entry() 中定义局部变量并设置 finalizer,当函数 entry() 执行完成后,在 main 函数中手动触发 GC,查看 finalizer 的执行情况。
- package main
- import (
- "log"
- "runtime"
- "time"
- )
- type Road int
- func findRoad(r *Road) {
- log.Println("road:", *r)
- }
- func entry() {
- var rd Road = Road(999)
- r := &rd
- runtime.SetFinalizer(r, findRoad)
- }
- func main() {
- entry()
- for i := 0; i < 10; i++ {
- time.Sleep(time.Second)
- runtime.GC()
- }
- }
运行结果如下:
2019/11/28 15:32:16 road: 999
Go语言链表操作
链表是一种物理存储单元上非连续、非顺序的存储结构,数据元素的逻辑顺序是通过链表中的指针链接次序实现的。
链表由一系列结点(链表中每一个元素称为结点)组成,结点可以在运行时动态生成。每个结点包括两个部分:一个是存储数据元素的数据域,另一个是存储下一个结点地址的指针域。
使用链表结构可以避免在使用数组时需要预先知道数据大小的缺点,链表结构可以充分利用计算机内存空间,实现灵活的内存动态管理。但是链表失去了数组随机读取的优点,同时链表由于增加了结点的指针域,空间开销比较大。
链表允许插入和移除表上任意位置上的结点,但是不允许随机存取。链表有三种类型:单向链表、双向链表以及循环链表。
单向链表
单向链表中每个结点包含两部分,分别是数据域和指针域,上一个结点的指针指向下一结点,依次相连,形成链表。
这里介绍三个概念:首元结点、头结点和头指针。
- 首元结点:就是链表中存储第一个元素的结点,如下图中 a1 的位置。
- 头结点:它是在首元结点之前附设的一个结点,其指针域指向首元结点。头结点的数据域可以存储链表的长度或者其它的信息,也可以为空不存储任何信息。
- 头指针:它是指向链表中第一个结点的指针。若链表中有头结点,则头指针指向头结点;若链表中没有头结点,则头指针指向首元结点。
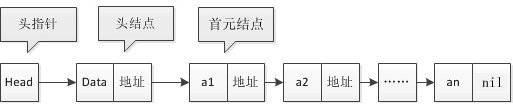
图:单向链表
头结点在链表中不是必须的,但增加头结点有以下几点好处:
- 增加了头结点后,首元结点的地址保存在头结点的指针域中,对链表的第一个数据元素的操作与其他数据元素相同,无需进行特殊处理。
- 增加头结点后,无论链表是否为空,头指针都是指向头结点的非空指针,若链表为空的话,那么头结点的指针域为空。
使用 Struct 定义单链表
利用 Struct 可以包容多种数据类型的特性,使用它作为链表的结点是最合适不过了。一个结构体内可以包含若干成员,这些成员可以是基本类型、自定义类型、数组类型,也可以是指针类型。这里可以使用指针类型成员来存放下一个结点的地址。
【示例 1】使用 Struct 定义一个单向链表。
- type Node struct {
- Data int
- Next *node
- }
其中成员 Data 用来存放结点中的有用数据,Next 是指针类型的成员,它指向 Node struct 类型数据,也就是下一个结点的数据类型。
【示例 2】为链表赋值,并遍历链表中的每个结点。
- package main
- import "fmt"
- type Node struct {
- data int
- next *Node
- }
- func Shownode(p *Node) { //遍历
- for p != nil {
- fmt.Println(*p)
- p = p.next //移动指针
- }
- }
- func main() {
- var head = new(Node)
- head.data = 1
- var node1 = new(Node)
- node1.data = 2
- head.next = node1
- var node2 = new(Node)
- node2.data = 3
- node1.next = node2
- Shownode(head)
- }
运行结果如下:
{1 0xc00004c1e0}
{2 0xc00004c1f0}
{3 <nil>}
插入结点
单链表的结点插入方法一般使用头插法或者尾插法。
1) 头插法
每次插入在链表的头部插入结点,代码如下所示:
- package main
- import "fmt"
- type Node struct {
- data int
- next *Node
- }
- func Shownode(p *Node){ //遍历
- for p != nil{
- fmt.Println(*p)
- p=p.next //移动指针
- }
- }
- func main() {
- var head = new(Node)
- head.data = 0
- var tail *Node
- tail = head //tail用于记录头结点的地址,刚开始tail的的指针指向头结点
- for i :=1 ;i<10;i++{
- var node = Node{data:i}
- node.next = tail //将新插入的node的next指向头结点
- tail = &node //重新赋值头结点
- }
- Shownode(tail) //遍历结果
- }
运行结果如下:
{9 0xc000036270}
{8 0xc000036260}
{7 0xc000036250}
{6 0xc000036240}
{5 0xc000036230}
{4 0xc000036220}
{3 0xc000036210}
{2 0xc000036200}
{1 0xc0000361f0}
{0 <nil>}
2) 尾插法
每次插入结点在尾部,这也是我们较为习惯的方法。
- package main
- import "fmt"
- type Node struct {
- data int
- next *Node
- }
- func Shownode(p *Node){ //遍历
- for p != nil{
- fmt.Println(*p)
- p=p.next //移动指针
- }
- }
- func main() {
- var head = new(Node)
- head.data = 0
- var tail *Node
- tail = head //tail用于记录最末尾的结点的地址,刚开始tail的的指针指向头结点
- for i :=1 ;i<10;i++{
- var node = Node{data:i}
- (*tail).next = &node
- tail = &node
- }
- Shownode(head) //遍历结果
- }
运行结果如下:
{0 0xc0000361f0}
{1 0xc000036200}
{2 0xc000036210}
{3 0xc000036220}
{4 0xc000036230}
{5 0xc000036240}
{6 0xc000036250}
{7 0xc000036260}
{8 0xc000036270}
{9 <nil>}
在进行数组的插入、删除操作时,为了保持内存数据的连续性,需要做大量的数据搬移,所以速度较慢。而在链表中插入或者删除一个数据,我们并不需要为了保持内存的连续性而搬移结点,因为链表的存储空间本身就不是连续的。所以,在链表中插入和删除一个数据是非常快速的。
但是,有利就有弊。链表要想随机访问第 k 个元素,就没有数组那么高效了。因为链表中的数据并非连续存储的,所以无法像数组那样,根据首地址和下标,通过寻址公式就能直接计算出对应的内存地址,而是需要根据指针一个结点一个结点地依次遍历,直到找到相应的结点。
循环链表
循环链表是一种特殊的单链表。
循环链表跟单链表唯一的区别就在尾结点。单向链表的尾结点指针指向空地址,表示这就是最后的结点了,而循环链表的尾结点指针是指向链表的头结点,它像一个环一样首尾相连,所以叫作“循环”链表,如下图所示。
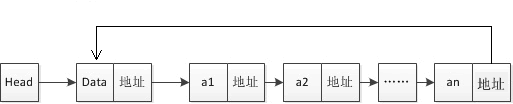
图:循环链表
和单链表相比,循环链表的优点是从链尾到链头比较方便。当要处理的数据具有环型结构特点时,就特别适合采用循环链表。比如著名的约瑟夫问题,尽管用单链表也可以实现,但是用循环链表实现的话,代码就会简洁很多。
双向链表
单向链表只有一个方向,结点只有一个后继指针 next 指向后面的结点。而双向链表,顾名思义它支持两个方向,每个结点不止有一个后继指针 next 指向后面的结点,还有一个前驱指针 prev 指向前面的结点。

图:双向链表
双向链表需要额外的两个空间来存储后继结点和前驱结点的地址。所以,如果存储同样多的数据,双向链表要比单链表占用更多的内存空间。虽然两个指针比较浪费存储空间,但可以支持双向遍历,这样也带来了双向链表操作的灵活性。
Go语言数据I/O对象及操作
在Go语言中,几乎所有的数据结构都围绕接口展开,接口是Go语言中所有数据结构的核心。在实际开发过程中,无论是实现 web 应用程序,还是控制台输入输出,又或者是网络操作,都不可避免的会遇到 I/O 操作。
Go语言标准库的 bufio 包中,实现了对数据 I/O 接口的缓冲功能。这些功能封装于接口 io.ReadWriter、io.Reader 和 io.Writer 中,并对应创建了 ReadWriter、Reader 或 Writer 对象,在提供缓冲的同时实现了一些文本基本 I/O 操作功能。
ReadWriter 对象
ReadWriter 对象可以对数据 I/O 接口 io.ReadWriter 进行输入输出缓冲操作,ReadWriter 结构定义如下:
type ReadWriter struct {
*Reader
*Writer
}
默认情况下,ReadWriter 对象中存放了一对 Reader 和 Writer 指针,它同时提供了对数据 I/O 对象的读写缓冲功能。
可以使用 NewReadWriter() 函数创建 ReadWriter 对象,该函数的功能是根据指定的 Reader 和 Writer 创建一个 ReadWriter 对象,ReadWriter 对象将会向底层 io.ReadWriter 接口写入数据,或者从 io.ReadWriter 接口读取数据。该函数原型声明如下:
func NewReadWriter(r *Reader, w *Writer) *ReadWriter
在函数 NewReadWriter() 中,参数 r 是要读取的来源 Reader 对象,参数 w 是要写入的目的 Writer 对象。
Reader 对象
Reader 对象可以对数据 I/O 接口 io.Reader 进行输入缓冲操作,Reader 结构定义如下:
type Reader struct {
//contains filtered or unexported fields
)
默认情况下 Reader 对象没有定义初始值,输入缓冲区最小值为 16。当超出限制时,另创建一个二倍的存储空间。
创建 Reader 对象
可以创建 Reader 对象的函数一共有两个,分别是 NewReader() 和 NewReaderSize(),下面分别介绍。
1) NewReader() 函数
NewReader() 函数的功能是按照缓冲区默认长度创建 Reader 对象,Reader 对象会从底层 io.Reader 接口读取尽量多的数据进行缓存。该函数原型如下:
func NewReader(rd io.Reader) *Reader
其中,参数 rd 是 io.Reader 接口,Reader 对象将从该接口读取数据。
2) NewReaderSize() 函数
NewReaderSize() 函数的功能是按照指定的缓冲区长度创建 Reader 对象,Reader 对象会从底层 io.Reader 接口读取尽量多的数据进行缓存。该函数原型如下:
func NewReaderSize(rd io.Reader, size int) *Reader
其中,参数 rd 是 io.Reader 接口,参数 size 是指定的缓冲区字节长度。
操作 Reader 对象
操作 Reader 对象的方法共有 11 个,分别是 Read()、ReadByte()、ReadBytes()、ReadLine()、ReadRune ()、ReadSlice()、ReadString()、UnreadByte()、UnreadRune()、Buffered()、Peek(),下面分别介绍。
1) Read() 方法
Read() 方法的功能是读取数据,并存放到字节切片 p 中。Read() 执行结束会返回已读取的字节数,因为最多只调用底层的 io.Reader 一次,所以返回的 n 可能小于 len(p),当字节流结束时,n 为 0,err 为 io. EOF。该方法原型如下:
func (b *Reader) Read(p []byte) (n int, err error)
在方法 Read() 中,参数 p 是用于存放读取数据的字节切片。示例代码如下:
- package main
- import (
- "bufio"
- "bytes"
- "fmt"
- )
- func main() {
- data := []byte("C语言中文网")
- rd := bytes.NewReader(data)
- r := bufio.NewReader(rd)
- var buf [128]byte
- n, err := r.Read(buf[:])
- fmt.Println(string(buf[:n]), n, err)
- }
运行结果如下:
C语言中文网 16 <nil>
2) ReadByte() 方法
ReadByte() 方法的功能是读取并返回一个字节,如果没有字节可读,则返回错误信息。该方法原型如下:
func (b *Reader) ReadByte() (c byte,err error)
示例代码如下:
- package main
- import (
- "bufio"
- "bytes"
- "fmt"
- )
- func main() {
- data := []byte("Go语言入门教程")
- rd := bytes.NewReader(data)
- r := bufio.NewReader(rd)
- c, err := r.ReadByte()
- fmt.Println(string(c), err)
- }
运行结果如下:
G <nil>
3) ReadBytes() 方法
ReadBytes() 方法的功能是读取数据直到遇到第一个分隔符“delim”,并返回读取的字节序列(包括“delim”)。如果 ReadBytes 在读到第一个“delim”之前出错,它返回已读取的数据和那个错误(通常是 io.EOF)。只有当返回的数据不以“delim”结尾时,返回的 err 才不为空值。该方法原型如下:
func (b *Reader) ReadBytes(delim byte) (line []byte, err error)
其中,参数 delim 用于指定分割字节。示例代码如下:
- package main
- import (
- "bufio"
- "bytes"
- "fmt"
- )
- func main() {
- data := []byte("C语言中文网, Go语言入门教程")
- rd := bytes.NewReader(data)
- r := bufio.NewReader(rd)
- var delim byte = ','
- line, err := r.ReadBytes(delim)
- fmt.Println(string(line), err)
- }
运行结果如下:
C语言中文网, <nil>
4) ReadLine() 方法
ReadLine() 是一个低级的用于读取一行数据的方法,大多数调用者应该使用 ReadBytes('\n') 或者 ReadString('\n')。ReadLine 返回一行,不包括结尾的回车字符,如果一行太长(超过缓冲区长度),参数 isPrefix 会设置为 true 并且只返回前面的数据,剩余的数据会在以后的调用中返回。
当返回最后一行数据时,参数 isPrefix 会置为 false。返回的字节切片只在下一次调用 ReadLine 前有效。ReadLine 会返回一个非空的字节切片或一个错误,方法原型如下:
func (b *Reader) ReadLine() (line []byte, isPrefix bool, err error)
示例代码如下:
- package main
- import (
- "bufio"
- "bytes"
- "fmt"
- )
- func main() {
- data := []byte("Golang is a beautiful language. \r\n I like it!")
- rd := bytes.NewReader(data)
- r := bufio.NewReader(rd)
- line, prefix, err := r.ReadLine()
- fmt.Println(string(line), prefix, err)
- }
运行结果如下:
Golang is a beautiful language. false <nil>
5) ReadRune() 方法
ReadRune() 方法的功能是读取一个 UTF-8 编码的字符,并返回其 Unicode 编码和字节数。如果编码错误,ReadRune 只读取一个字节并返回 unicode.ReplacementChar(U+FFFD) 和长度 1。该方法原型如下:
func (b *Reader) ReadRune() (r rune, size int, err error)
示例代码如下:
- package main
- import (
- "bufio"
- "bytes"
- "fmt"
- )
- func main() {
- data := []byte("C语言中文网")
- rd := bytes.NewReader(data)
- r := bufio.NewReader(rd)
- ch, size, err := r.ReadRune()
- fmt.Println(string(ch), size, err)
- }
运行结果如下:
C 1 <nil>
6) ReadSlice() 方法
ReadSlice() 方法的功能是读取数据直到分隔符“delim”处,并返回读取数据的字节切片,下次读取数据时返回的切片会失效。如果 ReadSlice 在查找到“delim”之前遇到错误,它返回读取的所有数据和那个错误(通常是 io.EOF)。
如果缓冲区满时也没有查找到“delim”,则返回 ErrBufferFull 错误。ReadSlice 返回的数据会在下次 I/O 操作时被覆盖,大多数调用者应该使用 ReadBytes 或者 ReadString。只有当 line 不以“delim”结尾时,ReadSlice 才会返回非空 err。该方法原型如下:
func (b *Reader) ReadSlice(delim byte) (line []byte, err error)
其中,参数 delim 用于指定分割字节。示例代码如下:
- package main
- import (
- "bufio"
- "bytes"
- "fmt"
- )
- func main() {
- data := []byte("C语言中文网, Go语言入门教程")
- rd := bytes.NewReader(data)
- r := bufio.NewReader(rd)
- var delim byte = ','
- line, err := r.ReadSlice(delim)
- fmt.Println(string(line), err)
- line, err = r.ReadSlice(delim)
- fmt.Println(string(line), err)
- line, err = r.ReadSlice(delim)
- fmt.Println(string(line), err)
- }
运行结果如下:
C语言中文网, <nil>
Go语言入门教程 EOF
EOF
7) ReadString() 方法
ReadString() 方法的功能是读取数据直到分隔符“delim”第一次出现,并返回一个包含“delim”的字符串。如果 ReadString 在读取到“delim”前遇到错误,它返回已读字符串和那个错误(通常是 io.EOF)。只有当返回的字符串不以“delim”结尾时,ReadString 才返回非空 err。该方法原型如下:
func (b *Reader) ReadString(delim byte) (line string, err error)
其中,参数 delim 用于指定分割字节。示例代码如下:
- package main
- import (
- "bufio"
- "bytes"
- "fmt"
- )
- func main() {
- data := []byte("C语言中文网, Go语言入门教程")
- rd := bytes.NewReader(data)
- r := bufio.NewReader(rd)
- var delim byte = ','
- line, err := r.ReadString(delim)
- fmt.Println(line, err)
- }
运行结果为:
C语言中文网, <nil>
8) UnreadByte() 方法
UnreadByte() 方法的功能是取消已读取的最后一个字节(即把字节重新放回读取缓冲区的前部)。只有最近一次读取的单个字节才能取消读取。该方法原型如下:
func (b *Reader) UnreadByte() error
9) UnreadRune() 方法
UnreadRune() 方法的功能是取消读取最后一次读取的 Unicode 字符。如果最后一次读取操作不是 ReadRune,UnreadRune 会返回一个错误(在这方面它比 UnreadByte 更严格,因为 UnreadByte 会取消上次任意读操作的最后一个字节)。该方法原型如下:
func (b *Reader) UnreadRune() error
10) Buffered() 方法
Buffered() 方法的功能是返回可从缓冲区读出数据的字节数, 示例代码如下:
- package main
- import (
- "bufio"
- "bytes"
- "fmt"
- )
- func main() {
- data := []byte("Go语言入门教程")
- rd := bytes.NewReader(data)
- r := bufio.NewReader(rd)
- var buf [14]byte
- n, err := r.Read(buf[:])
- fmt.Println(string(buf[:n]), n, err)
- rn := r.Buffered()
- fmt.Println(rn)
- n, err = r.Read(buf[:])
- fmt.Println(string(buf[:n]), n, err)
- rn = r.Buffered()
- fmt.Println(rn)
- }
运行结果如下:
Go语言入门 14 <nil>
6
教程 6 <nil>
0
11) Peek() 方法
Peek() 方法的功能是读取指定字节数的数据,这些被读取的数据不会从缓冲区中清除。在下次读取之后,本次返回的字节切片会失效。如果 Peek 返回的字节数不足 n 字节,则会同时返回一个错误说明原因,如果 n 比缓冲区要大,则错误为 ErrBufferFull。该方法原型如下:
func (b *Reader) Peek(n int) ([]byte, error)
在方法 Peek() 中,参数 n 是希望读取的字节数。示例代码如下:
- package main
- import (
- "bufio"
- "bytes"
- "fmt"
- )
- func main() {
- data := []byte("Go语言入门教程")
- rd := bytes.NewReader(data)
- r := bufio.NewReader(rd)
- bl, err := r.Peek(8)
- fmt.Println(string(bl), err)
- bl, err = r.Peek(14)
- fmt.Println(string(bl), err)
- bl, err = r.Peek(20)
- fmt.Println(string(bl), err)
- }
运行结果如下:
Go语言 <nil>
Go语言入门 <nil>
Go语言入门教程 <nil>
Writer 对象
Writer 对象可以对数据 I/O 接口 io.Writer 进行输出缓冲操作,Writer 结构定义如下:
type Writer struct {
//contains filtered or unexported fields
}
默认情况下 Writer 对象没有定义初始值,如果输出缓冲过程中发生错误,则数据写入操作立刻被终止,后续的写操作都会返回写入异常错误。
创建 Writer 对象
创建 Writer 对象的函数共有两个分别是 NewWriter() 和 NewWriterSize(),下面分别介绍一下。
1) NewWriter() 函数
NewWriter() 函数的功能是按照默认缓冲区长度创建 Writer 对象,Writer 对象会将缓存的数据批量写入底层 io.Writer 接口。该函数原型如下:
func NewWriter(wr io.Writer) *Writer
其中,参数 wr 是 io.Writer 接口,Writer 对象会将数据写入该接口。
2) NewWriterSize() 函数
NewWriterSize() 函数的功能是按照指定的缓冲区长度创建 Writer 对象,Writer 对象会将缓存的数据批量写入底层 io.Writer 接口。该函数原型如下:
func NewWriterSize(wr io.Writer, size int) *Writer
其中,参数 wr 是 io.Writer 接口,参数 size 是指定的缓冲区字节长度。
操作 Writer 对象
操作 Writer 对象的方法共有 7 个,分别是 Available()、Buffered()、Flush()、Write()、WriteByte()、WriteRune() 和 WriteString() 方法,下面分别介绍。
1) Available() 方法
Available() 方法的功能是返回缓冲区中未使用的字节数,该方法原型如下:
func (b *Writer) Available() int
示例代码如下:
- package main
- import (
- "bufio"
- "bytes"
- "fmt"
- )
- func main() {
- wr := bytes.NewBuffer(nil)
- w := bufio.NewWriter(wr)
- p := []byte("C语言中文网")
- fmt.Println("写入前未使用的缓冲区为:", w.Available())
- w.Write(p)
- fmt.Printf("写入%q后,未使用的缓冲区为:%d\n", string(p), w.Available())
- }
运行结果如下:
写入前未使用的缓冲区为: 4096
写入"C语言中文网"后,未使用的缓冲区为:4080
2) Buffered() 方法
Buffered() 方法的功能是返回已写入当前缓冲区中的字节数,该方法原型如下:
func (b *Writer) Buffered() int
示例代码如下:
- package main
- import (
- "bufio"
- "bytes"
- "fmt"
- )
- func main() {
- wr := bytes.NewBuffer(nil)
- w := bufio.NewWriter(wr)
- p := []byte("C语言中文网")
- fmt.Println("写入前未使用的缓冲区为:", w.Buffered())
- w.Write(p)
- fmt.Printf("写入%q后,未使用的缓冲区为:%d\n", string(p), w.Buffered())
- w.Flush()
- fmt.Println("执行 Flush 方法后,写入的字节数为:", w.Buffered())
- }
该例测试结果为:
写入前未使用的缓冲区为: 0
写入"C语言中文网"后,未使用的缓冲区为:16
执行 Flush 方法后,写入的字节数为: 0
3) Flush() 方法
Flush() 方法的功能是把缓冲区中的数据写入底层的 io.Writer,并返回错误信息。如果成功写入,error 返回 nil,否则 error 返回错误原因。该方法原型如下:
func (b *Writer) Flush() error
示例代码如下:
- package main
- import (
- "bufio"
- "bytes"
- "fmt"
- )
- func main() {
- wr := bytes.NewBuffer(nil)
- w := bufio.NewWriter(wr)
- p := []byte("C语言中文网")
- w.Write(p)
- fmt.Printf("未执行 Flush 缓冲区输出 %q\n", string(wr.Bytes()))
- w.Flush()
- fmt.Printf("执行 Flush 后缓冲区输出 %q\n", string(wr.Bytes()))
- }
运行结果如下:
未执行 Flush 缓冲区输出 ""
执行 Flush 后缓冲区输出 "C语言中文网"
4) Write() 方法
Write() 方法的功能是把字节切片 p 写入缓冲区,返回已写入的字节数 nn。如果 nn 小于 len(p),则同时返回一个错误原因。该方法原型如下:
func (b *Writer) Write(p []byte) (nn int, err error)
其中,参数 p 是要写入的字节切片。示例代码如下:
- package main
- import (
- "bufio"
- "bytes"
- "fmt"
- )
- func main() {
- wr := bytes.NewBuffer(nil)
- w := bufio.NewWriter(wr)
- p := []byte("C语言中文网")
- n, err := w.Write(p)
- w.Flush()
- fmt.Println(string(wr.Bytes()), n, err)
- }
运行结果如下:
C语言中文网 16 <nil>
5) WriteByte() 方法
WriteByte() 方法的功能是写入一个字节,如果成功写入,error 返回 nil,否则 error 返回错误原因。该方法原型如下:
func (b *Writer) WriteByte(c byte) error
其中,参数 c 是要写入的字节数据,比如 ASCII 字符。示例代码如下:
- package main
- import (
- "bufio"
- "bytes"
- "fmt"
- )
- func main() {
- wr := bytes.NewBuffer(nil)
- w := bufio.NewWriter(wr)
- var c byte = 'G'
- err := w.WriteByte(c)
- w.Flush()
- fmt.Println(string(wr.Bytes()), err)
- }
运行结果如下:
G <nil>
6) WriteRune() 方法
WriteRune() 方法的功能是以 UTF-8 编码写入一个 Unicode 字符,返回写入的字节数和错误信息。该方法原型如下:
func (b *Writer) WriteRune(r rune) (size int,err error)
其中,参数 r 是要写入的 Unicode 字符。示例代码如下:
- package main
- import (
- "bufio"
- "bytes"
- "fmt"
- )
- func main() {
- wr := bytes.NewBuffer(nil)
- w := bufio.NewWriter(wr)
- var r rune = 'G'
- size, err := w.WriteRune(r)
- w.Flush()
- fmt.Println(string(wr.Bytes()), size, err)
- }
该例测试结果为:
G 1 <nil>
7) WriteString() 方法
WriteString() 方法的功能是写入一个字符串,并返回写入的字节数和错误信息。如果返回的字节数小于 len(s),则同时返回一个错误说明原因。该方法原型如下:
func (b *Writer) WriteString(s string) (int, error)
其中,参数 s 是要写入的字符串。示例代码如下:
- package main
- import (
- "bufio"
- "bytes"
- "fmt"
- )
- func main() {
- wr := bytes.NewBuffer(nil)
- w := bufio.NewWriter(wr)
- s := "C语言中文网"
- n, err := w.WriteString(s)
- w.Flush()
- fmt.Println(string(wr.Bytes()), n, err)
- }
运行结果如下:
C语言中文网 16 <nil>

 浙公网安备 33010602011771号
浙公网安备 33010602011771号