w3cschool-Django中文教程
https://www.w3cschool.cn/django/
Django 简介
Django 是用Python开发的一个免费开源的Web框架,可以用于快速搭建高性能,优雅的网站!采用了MVC的框架模式,即模型M,视图V和控制器C,也可以称为MVT模式,模型M,视图V,模板T。
它最初是被开发来用于管理劳伦斯出版集团旗下的一些以新闻内容为主的站点的, 并于2005年7月在BSD许可证下公布.
这套框架是以比利时的吉普赛爵士吉他手Django Reinhardt来命名的.
Django 的主要目标是使得开发复杂的、数据库驱动的网站变得简单。Django 注重组件的重用性和“可插拔性”,敏捷开发和 DRY 法则(Don’t Repeat Yourself)。在 Django 中 Python 被普遍使用,甚至包括配置文件和数据模型。
Django 于 2008 年 6 月 17 日正式成立基金会。
Django 架构分析
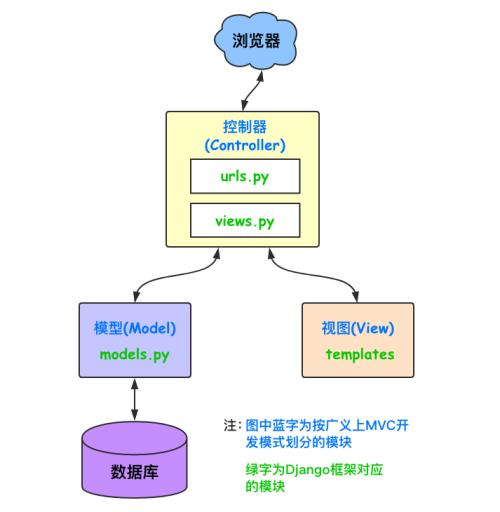
Django 框架的组成部分
Django 框架的核心包括:
- 一个 面向对象 的映射器,用作数据模型(以 Python 类的形式定义)和关系型数据库间的介质;
- 一个基于正则表达式的 URL 分发器;
- 一个视图系统,用于处理请求;
- 一个模板系统。
核心框架中还包括:
- 一个轻量级的、独立的 Web 服务器,用于开发和测试。
- 一个表单序列化及验证系统,用于 HTML 表单和适于数据库存储的数据之间的转换。
- 一个缓存框架,并有几种缓存方式可供选择。
- 中间件支持,允许对请求处理的各个阶段进行干涉。
- 内置的分发系统允许应用程序中的组件采用预定义的信号进行相互间的通信。
- 一个序列化系统,能够生成或读取采用 XML 或 JSON 表示的 Django 模型实例。
- 一个用于扩展模板引擎的能力的系统。
Django 包含了很多应用在它的 contrib 包中,这些包括:
- 一个可扩展的认证系统
- 动态站点管理页面
- 一组产生 RSS 和 Atom 的工具
- 一个灵活的评论系统
- 产生 Google 站点地图(Google Sitemaps)的工具
- 防止跨站请求伪造(cross-site request forgery)的工具
- 一套支持轻量级标记语言(Textile 和 Markdown)的模板库
- 一套协助创建地理信息系统(GIS)的基础框架
Django 的内置应用
- Django 包含了非常多应用在它的"contrib"包中, 这些包含:
- 一个可扩展的认证系统;
- 动态站点管理页面;
- 一组产生RSS和Atom的工具;
- 一个灵活的评论系统;
- 产生Google站点地图(Google Sitemaps)的工具;
- 防止跨站请求伪造(cross-site request forgery)的工具;
- 一套支持轻量级标记语言(Textile和Markdown)的模板库;
- 一套协助创建地理信息系统(GIS)的基础框架;
Django 的优缺点总结
Django 的优点
- 完美的文档,Django近乎完美的官方文档。
- 强大的URL路由配置,Django让你可以设计出非常优雅的URL。
- 自助管理后台,让你几乎不用写一行代码就拥有一个完整的后台管理界面。
- 全套的解决方案(full-stackframework + batteries included),基本要什么有什么(比如:cache、session、feed、orm、geo、auth),而且全部Django自己造,开发网站应手的工具Django基本都给你做好了,因此开发效率是不用说的。
Django 的缺点
- Template功能比较弱,不能插入Python代码,要写复杂一点的逻辑需要另外用Python实现Tag或Filter。
- URL配置虽然强大,但全部要手写,高手和初识Django的人配出来的URL会有很大差异。
- 自带的ORM远不如SQLAlchemy强大,SQLAlchemy是Python世界里事实上的ORM标准,其它框架都支持SQLAlchemy了,唯独Django仍然坚持自己的那一套。
- Django的auth跟其它模块结合紧密,功能也挺强,但做的有点过了,用户的数据库schema都给你定好了,比如很多网站要求email地址唯一,可schema里这个字段的值不是唯一的。
- 系统紧耦合,如果你觉得Django内置的某项功能不是很好,想用喜欢的第三方库来代替是很难的,比如说的ORM、Template。要在Django里用SQLAlchemy或Mako几乎是不可能,即使打了一些补丁用上了也会让你觉得非常非常别扭。
python的WEB框架有Django、Tornado、Flask 等多种,Django是重量级选手中最有代表性的一位,它的优势为:大而全,框架本身集成了ORM、模型绑定、模板引擎、缓存、Session等诸多功能。许多成功的网站和APP都基于Django。
Django是一个开放源代码的Web应用框架,由Python写成。
Django遵守BSD版权,初次发布于2005年7月, 并于2008年9月发布了第一个正式版本1.0 。
Django采用了MVT的软件设计模式,即模型Model,视图View和模板Template。
Django特点
- 完全免费并开源源代码
- 快速高效开发
- 使用MTV架构(熟悉Web开发的应该会说是MVC架构)
- 强大的可扩展性.

用户在浏览器中输入URL后的回车, 浏览器会对URL进行检查, 首先判断协议,如果是http就按照 Web 来处理, 然互调用DNS查询, 将域名转换为IP地址, 然后经过网络传输到达对应Web服务器, 服务器对url进行解析后, 调用View中的逻辑(MTV中的V), 其中又涉及到Model(MTV中的M), 与数据库的进行交互, 将数据发到Template(MTV中的T)进行渲染, 然后发送到浏览器中, 浏览器以合适的方式呈现给用户
框架是什麼?
Django 在新一代的 Web框架 中非常出色,为什么这么说呢?
为回答该问题,让我们考虑一下_不使用_框架设计 Python 网页应用程序的情形。 贯穿整本书,我们多次展示不使用框架实现网站基本功能的方法,让读者认识到框架开发的方便。 (不使用框架,更多情况是没有合适的框架可用。 最重要的是,理解实现的来龙去脉会使你成为一个优秀的web开发者。)
使用Python开发Web,最简单,原始和直接的办法是使用CGI标准,在1998年这种方式很流行。 现在从应用角度解释它是如何工作: 首先做一个Python脚本,输出HTML代码,然后保存成.cgi扩展名的文件,通过浏览器访问此文件。 就是这样。
如下示例,用Python CGI脚本显示数据库中最新出版的10本书: 不用关心语法细节;仅仅感觉一下基本实现的方法:
#!/usr/bin/env python
import MySQLdb
print "Content-Type: text/html\n"
print "<html><head><title>Books</title></head>"
print "<body>"
print "<h1>Books</h1>"
print "<ul>"
connection = MySQLdb.connect(user='me', passwd='letmein', db='my_db')
cursor = connection.cursor()
cursor.execute("SELECT name FROM books ORDER BY pub_date DESC LIMIT 10")
for row in cursor.fetchall():
print "<li>%s</li>" % row[0]
print "</ul>"
print "</body></html>"
connection.close()首先,用户请求CGI,脚本代码打印Content-Type行,后面跟着换行。 再接下 来是一些HTML的起始标签,然后连接数据库并执行一些查询操作,获取最新的十本书。 在遍历这些书的同时,生成一个书名的HTML列表项。 最后,输出HTML的结束标签并且关闭数据库连接。
像这样的一次性的动态页面,从头写起的方法并非一定不好。 其中一点: 这些代码简单易懂,就算是一个初起步的 开发者都能读明白这16行的Python的代码,而且这些代码从头到尾做了什么都能了解得一清二楚。 不需要学习额外 的背景知识,没有额外的代码需要去了解。 同样,也易于部署这16行代码,只需要将它保存为一个latestbooks.cgi 的 文件,上传到网络服务器上,通过浏览器访问即可。
尽管实现很简单,还是暴露了一些问题和不便的地方。 问你自己这几个问题:
- 应用中有多处需要连接数据库会怎样呢? 每个独立的CGI脚本,不应该重复写数据库连接的代码。 比较实用的办法是写一个共享函数,可被多个代码调用。
- 一个开发人员 确实 需要去关注如何输出Content-Type以及完成所有操作后去关闭数据 库么? 此类问题只会降低开发人员的工作效率,增加犯错误的几率。 那些初始化和释放 相关的工作应该交给一些通用的框架来完成。
- 如果这样的代码被重用到一个复合的环境中会发生什么? 每个页面都分别对应独立的数据库和密码吗?
- 如果一个Web设计师,完全没有Python开发经验,但是又需要重新设计页面的话,又将 发生什么呢? 一个字符写错了,可能导致整个应用崩溃。 理想的情况是,页面显示的逻辑与从数据库中读取书本记录分隔开,这样 Web设计师的重新设计不会影响到之前的业务逻辑。
以上正是Web框架致力于解决的问题。 Web框架为应用程序提供了一套程序框架, 这样你可以专注于编写清晰、易维护的代码,而无需从头做起。 简单来说,这就是Django所能做的。
MVC 设计模式
让我们来研究一个简单的例子,通过该实例,你可以分辨出,通过Web框架来实现的功能与之前的方式有何不同。 下面就是通过使用Django来完成以上功能的例子: 首先,我们分成4个Python的文件,(models.py ,views.py , urls.py ) 和html模板文件 (latest_books.html )
# models.py (the database tables)
from django.db import models
class Book(models.Model):
name = models.CharField(max_length=50)
pub_date = models.DateField()
# views.py (the business logic)
from django.shortcuts import render_to_response
from models import Book
def latest_books(request):
book_list = Book.objects.order_by('-pub_date')[:10]
return render_to_response('latest_books.html', {'book_list': book_list})
# urls.py (the URL configuration)
from django.conf.urls.defaults import *
import views
urlpatterns = patterns('',
(r'^latest/$', views.latest_books),
)
# latest_books.html (the template)
<html><head><title>Books</title></head>
<body>
<h1>Books</h1>
<ul>{% for book in book_list %}
<li>{{ book.name }}</li>
{% endfor %}
</ul>
</body></html>然后,不用关心语法细节;只要用心感觉整体的设计。 这里只关注分割后的几个文件:
- models.py 文件主要用一个 Python 类来描述数据表。 称为 模型(model) 。 运用这个类,你可以通过简单的 Python 的代码来创建、检索、更新、删除 数据库中的记录而无需写一条又一条的SQL语句。
- views.py文件包含了页面的业务逻辑。 latest_books()函数叫做视图。
- urls.py 指出了什么样的 URL 调用什么的视图。 在这个例子中 /latest/ URL 将会调用 latest_books()这个函数。 换句话说,如果你的域名是example.com,任何人浏览网址 http://example.com/latest/将会调用latest_books()这个函数。
- latest_books.html 是 html 模板,它描述了这个页面的设计是如何的。 使用带基本逻辑声明的模板语言,如{% for book in book_list %}
结合起来,这些部分松散遵循的模式称为模型-视图-控制器(MVC)。 简单的说, MVC 是一种软件开发的方法,它把代码的定义和数据访问的方法(模型)与请求逻辑 (控制器)还有用户接口(视图)分开来。 我们将在第5章更深入地讨论MVC。
这种设计模式关键的优势在于各种组件都是 松散结合 的。这样,每个由 Django驱动 的Web应用都有着明确的目的,并且可独立更改而不影响到其它的部分。 比如,开发者 更改一个应用程序中的 URL 而不用影响到这个程序底层的实现。 设计师可以改变 HTML 页面 的样式而不用接触 Python 代码。 数据库管理员可以重新命名数据表并且只需更改一个地方,无需从一大堆文件中进行查找和替换。
很重要的两点。
第一,Django最可爱的地方。 Django诞生于新闻网站的环境中,因此它提供很多了特性(如第6章会说到的管理后台),非常适合内容类的网站,如Amazon.com, craigslist.org和washingtonpost.com,这些网站提供动态的,数据库驱动的信息。 (不要看到这就感到沮丧,尽管Django擅长于动态内容管理系统, 但并不表示Django主要的目的就是用来创建动态内容的网站。 某些方面 特别高效 与其他方面 不高效 是有区别的, Django在其他方面也同样高效。)
第二,Django的起源造就了它的开源社区的文化。 因为Django来自于真实世界中的代码,而不是 来自于一个科研项目或者商业产品,她主要集中力量来解决Web开发中遇到的问题,同样 也是Django的开发者经常遇到的问题。 这样,Django每天在现有的基础上进步。 框架的开发者对于让开发人员节省时间,编写更加容易维护的程序,同时保证程序运行的效率具有极大的兴趣。 无他,开发者动力来源于自己的目标:节省时间,快乐工作。 (坦率地讲,他们使用了自己公司的产品。)
所需编程知识
本书读者需要理解基本的面向过程和面向对象编程: 流程控制( if , while 和 for ),数据结构(列表,哈希表/字典),变量,类和对象。
Web开发经验,正如你所想的,也是非常有帮助的,但是对于阅读本书,并不是必须的。 通过本书,我们尽量给缺乏经验的开发人员提供在Web开发中最好的实践。
Python所需知识
本质上来说, Django 只不过是用 Python 编写的一组类库。 用 Django 开发站点就是使用这些类库编写 Python 代码。 因此,学习 Django 的关键就是学习如何进行 Python 编程并理解 Django 类库的运作方式。
如果你有Python开发经验,在学习过程中应该不会有任何问题。 基本上,Django的代码并 没有使用一些黑色魔法(例如代码中的花哨技巧,某个实现解释或者理解起来十分困难)。 对你来说,学习Django就是学习她的命名规则和API。
如果你没有使用 Python 编程的经验,你一定会学到很多东西。 它是非常易学易用的。 虽然这本书没有包括一个完整的 Python 教程, 但也算是一个恰当的介绍了 Python特征和 功能的集锦。 当然,我们推荐你读一下官方的 Python 教程,它可 以从 http://docs.python.org/tut/ 在线获得。 另外我们也推荐 Mark Pilgrims的 书Dive Into Python ( http://www.diveintopython.org/ ) http://www.djangoproject.com/ 上的免费文档
Django版本支持
此书内容对Django 3.0兼容。
学习本教程前你需要了解一些基础的Web知识及Python基础教程。
Django 版本与 Python 环境的对应表:
| Django 版本 | Python 版本 |
| 1.5 | 2.6.5, 2.7, 3.2, 3.3. |
| 1.6 | 2.6, 2.7, 3.2, 3.3 |
| 1.7 | 2.7, 3.2, 3.3, 3.4 (2.6 不支持了) |
| 1.8 LTS | 2.7, 3.2, 3.3, 3.4, 3.5 (长期支持版本 LTS) |
| 1.9 | 2.7, 3.4, 3.5 (3.3 不支持了) |
| 1.10 | 2.7, 3.4, 3.5 |
| 1.11 LTS | 2.7, 3.4, 3.5, 3.6 (最后一个支持 Python 2.7 的版本 ) |
| 2.0 | 3.4, 3.5, 3.6 (注意,不再支持 Python 2) |
| 2.1 | 3.5, 3.6, 3.7 |
| 2.2 LTS | 3.5, 3.6, 3.7 |
| 3.0 | 3.6, 3.7, 3.8 |
获取帮助
Django的最大的益处是,有一群乐于助人的人在Django社区上。 你可以毫无约束的提各种 问题在上面,如:django的安装,app 设计,db 设计,发布。
- Django邮件列表是很多Django用户提出问题、回答问题的地方。 可以通过 http://www.djangoproject.com/r/django-users 来免费注册。
- 如果Django用户遇到棘手的问题,希望得到及时地回复,可以使用Django IRC channel。 在Freenode IRC network加入#django
Django 安装
在安装 Django 前,系统需要已经安装了Python的开发环境。
Window 下安装 Django
如果你还未安装Python环境需要先下载Python安装包。
1、Python 下载地址:https://www.python.org/downloads/
2、Django 下载地址:https://www.djangoproject.com/download/
安装使用python3
python3 --version
brew 安装python3 环境
brew install python3
which python3
sudo pip3 install django==3.1.14
查看版本
django-admin --version
Django 创建第一个项目
Django 创建第一个项目
本章我们将介绍如何使用 Django 来创建项目。
使用 django-admin.py 来创建名为***的项目:
django-admin startproject xxx
创建完成后我们可以查看下项目的目录结构:
[root@solar ~]# cd HelloWorld/ [root@solar HelloWorld]# tree . manage.py 管理器 |--*** | |-- __init__.py 包 | |-- settings.py 设置文件 | |-- urls.py 路由 | `-- wsgi.py 部署
目录说明:
- HelloWorld: 项目的容器。
- manage.py: 一个实用的命令行工具,可让你以各种方式与该 Django 项目进行交互。
- HelloWorld/__init__.py: 一个空文件,告诉 Python 该目录是一个 Python 包。
- HelloWorld/settings.py: 该 Django 项目的设置/配置。
- HelloWorld/urls.py: 该 Django 项目的 URL 声明; 一份由 Django 驱动的网站"目录"。
- HelloWorld/wsgi.py: 一个 WSGI 兼容的 Web 服务器的入口,以便运行你的项目。
创建一个app模块会自动生成app文件夹,该文件夹包括几个文件:
python manage.py startapp app
各个目录的说明:
- init.py 包
- admin.py 管理后台
- apps.py
- migrations
- init.py 迁移
- model.py 模型
- test.py 测试
- view.py 视图
在目录中找到***包里面的setting.py,在INSTALLED_APPS当中注册APP模块:
INSTALLED_APPS = [
'django.contrib.admin',
'django.contrib.auth',
'django.contrib.contenttypes',
'django.contrib.sessions',
'django.contrib.messages',
'django.contrib.staticfiles',
'app',
在包下输入命令,启动项目:
python manage.py runserver
Django 模板
Django模板 简介
在Django框架中,模板是可以帮助开发者快速生成呈现给用户页面的工具。用于编写html代码,还可以嵌入模板代码转换更方便的完成页面开发,再通过在视图中渲染模板,将生成模板的设计实现了业务逻辑视图与显示内容模板的分离,一个视图可以使用任意一个模板,一个模板可以供多个视图使用。
注意:当前显示的页面=模板+数据
模板分为两部分:
- 静态页面:主要包括了CSS,HTML,JS,图片
- 动态填充:主要是通过模板语言去动态的产生一些页面上的内容
模板文件的使用
一般是在视图函数当中通过模板语言去动态产生html页,然后将页面上的内容返回给客户端,进行显示。
- 先加载模板文件loader.get_template,获取模板文件其中的内容,产生一个模板对象
- 定义模板其他RequestContext,给模板文件传递数据
-
模板文件渲染产生的html页面内容渲染,使用传递的数据替换相应的变量,产生一个替换后的表中html内容
from django.shortcuts import render
from django.template import loader,RequestContext
from django.http import HttpResponse
# Create your views here.
def my_render(request,template_path,context={}):
# 1.加载模板文件,获取一个模板对象
temp = loader.get_template(template_path)
# 2.定义模板上下文,给模板传递数据
context = RequestContext(request, context)
# 3.模板渲染,产生一个替换后的html内容
res_html = temp.render(context)
# 4.返回应答
return HttpResponse(res_html)
# /index
def index(request):
# return my_render(request,'booktest/index.html') 这是自己封装的render
# 其实Django已经封装好了,可以直接使用
return render(request,'booktest/index.html')模板文件的加载顺序
- 首先去配置的当前模板的目录下面去找
- 如果配置的目录下面没有,就去已经创建的应用文件中去查找模板文件(这种方式,仅限于应用下面必须有模板文件夹)
模板语言
- 模板语言(Django模板语言)简称DTL。
- 模板变量
>模板变量名是由数字,字母,下划线和点组成
>注意:不能以下划线开头
3.模板标签
{% 代码段 %}
#for循环:
#遍历列表:
{% for i in 列表 %}
#列表不为空时执行
{% empty %}
#列表为空时执行
{% endfor %}
#若加上关键字reversed则倒序遍历:
{% for x in 列表 reversed %}
{% endfor %}
#在for循环中可以通过{{ forloop.counter }}得到for循环遍历到几次
#判断语句:
{% if %}
{% elif %}
{% else %}
{% endif %}
4.关系比较操作符
> <> = <= ==!=
注意:在使用关系比较操作符的时候,比较符两边必须有空格
5.逻辑运算
不和
过滤器
-
https://docs.djangoproject.com/zh-CN/1.11/ref/templates/language/#filters django官方文档
-
https://docs.djangoproject.com/zh-CN/1.11/ref/templates/builtins/#ref-templates-builtins-filters django过滤器官方文档1
- 过滤器用于对模板变量进行操作
- 使用:
>add:将值的值增加2。使用形式为:{{value | add:“ 2”}}
> cut:从给定值中删除所有arg的值。使用形式为:{{value | cut:arg}}
>date:格式化时间格式。使用形式为:{{value| date:“ Ymd H:M:S”}}
>default:如果value是False,那么输出给定的默认值。使用形式:{{value | default:“ nothing”}}。例如,如果值是“”,那么输出将是nothing
> first:返回列表/字符串中的第一个元素。使用形式:{{value | first}}
> length:返回值的长度。使用形式:{{value | length}}
自定义过滤器的步骤:
- 在自己的应用文件下新建一个称为模板标签的python包
- 在python包中新建一个过滤器的py文件
- 配置
from django import template#导入模块
register = template.Library() #标准语句都不能改
#写函数装饰器
@register.filter
def add_xx(value, arg): # 最多有两个
return '{}-{}'.format(value, arg)#返回两个值的拼接
#在html使用方式
{% load my_tags %}#引用模块
{{ 'alex'|add_xx:'dsb' }}#通过函数名使用
@register.filter(name = xxx)#可以直接通过name等于的xxx取引用
def add_xx(value, arg): # 最多有两个
return '{}-{}'.format(value, arg)#返回两个值的拼接
#在html使用方式
{% load my_tags %}#引用模块
{{'alex'|xxx:'dsb'}}#通过赋值的name引用模板注释
- 单行注释:{#注释内容#}
- 多行注释:{%comment%}
- 注释内容
- {%最终评论%}
- 模板注释的内容浏览器看不到,html注释的内容浏览器可以看到html的注释:
模板的继承
模板里编写{%block <demo>%}开头,{%endblock%}结尾处,代表可以被继承
例如如下新建的demo.html:
1.父模板
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Title</title>
<style>
h1{
color: blue;
}
</style>
</head>
<body>
{% block demo %}
<h1>模板1</h1>
{% endblock %}
{% block demo1 %}
<h1>模板2</h1>
{% endblock %}
{% block demo2 %}
<h1>模板3</h1>
{% endblock %}
{% block demo3 %}
<h1 style="color: red">模板4</h1>
{% endblock %}
{% block demo4 %}
<h1>模板5</h1>
{% endblock %}
</body>
</html>2.子模板
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Title</title>
</head>
<body>
{% extends 'demo.html' %} #继承模板
{% block demo %} #对引入的模板块进行从写
<h1>这里是重写</h1>
{% endblock %}
</body>
</html>模块约会完成,可以看到效果如下所示:
Django 模型
简介
模型是有关数据的唯一确定的信息源。它包含要存储数据的基本字段和行为。通常,每个模型都映射到单个数据库表。
- 每一个模型是django.db.models.Model的子类
- 每一个模型属性代表数据表的一个字段。
- Django提供了自动生成的数据库访问API,使用模型操作数据库很方便
快速示例
此示例模型定义了一个Person,其中包含first_name和 last_name:
from django.db import models
class Person(models.Model):
first_name = models.CharField(max_length=30)
last_name = models.CharField(max_length=30)first_name并且last_name是场模型。每个字段都指定为类属性,并且每个属性都映射到数据库列。
上面的Person模型将创建一个数据库表,如下所示:
CREATE TABLE myapp_person (
"id" serial NOT NULL PRIMARY KEY,
"first_name" varchar(30) NOT NULL,
"last_name" varchar(30) NOT NULL
);一些技术说明:
- 表的名称myapp_person是自动从某些模型元数据派生而来的,但是可以被覆盖。
- 一个id字段被自动添加,但这种行为可以被覆盖。
- 在此示例中,SQL是使用PostgreSQL语法格式化的,但是值得注意的是Django使用了针对设置文件中指定的数据库后端定制的SQL 。CREATE TABLE
详情参考官网: https://docs.djangoproject.com/en/3.0/topics/db/models/
定义模型
Django根据属性的类型确定以下信息:
- 当前选择的数据库支持字段的类型
- 渲染管理表单时使用的默认html控件
- 在管理站点最低限度的验证
django会为表创建自动增长的主键列,每个模型只能有一个主键列,如果使用选项设置某属性为主键列后django不会再创建自动增长的主键列。
默认创建的主键列属性为id,可以使用pk代替,pk全拼为primary key。
pk是主键的别名,若主键名为id2,那么pk是id2的别名。
属性命名限制:
- 不能是python的保留关键字。
- 不允许使用连续的下划线,这是由django的查询方式决定的,在第4节会详细讲解查询。
- 定义属性时需要指定字段类型,通过字段类型的参数指定选项。
具体语法如下:
属性=models.字段类型(选项)
模型字段类表
| 字段类 | 默认小组件 | 说明 |
| AutoField | N/A | 根据 ID 自动递增的 IntegerField |
| BigIntegerField | NumberInput | 64 位整数,与 IntegerField 很像,但取值范围是 -9223372036854775808 到 9223372036854775807 。 |
| BinaryField | N/A | 存储原始二进制数据的字段。只支持 bytes 类型。注意,这个字段的功能有限。 |
| BooleanField | CheckboxInput | 真假值字段。如果想接受 null 值,使用 NullBooleanField 。 |
| CharField | TextInput | 字符串字段,针对长度较小的字符串。大量文本应该使用 TextField 。有个额外的必须参数:max_length ,即字段的最大长度(字符个数)。 |
| DateField | DateInput | 日期,在 Python 中使用 datetime.date 实例表示。有两个额外的可选参数: auto_now ,每次保存对象时自动设为当前日期 auto_now_add ,创建对象时自动设为当前日期。 |
| DateTimeField | DateTimeInput | 日期和时间,在 Python 中使用 datetime.datetime 实例表示。与 DateField 具有相同的额外参数。 |
| DecimalField | TextInput | 固定精度的小数,在 Python 中使用 Decimal 实例表示。有两个必须的参数: max_digits 和 decimal_places 。 |
| DurationField | TextInput | 存储时间跨度,在 Python 中使用 timedelta 表示。 |
| EmailField | TextInput | 一种 CharField ,使用 EmailValidator 验证输入。max_length 的默认值为 254 。 |
| FileField | ClearableFileInput | 文件上传字段。详情见下面。 |
| FilePathField | Select | 一种 CharField ,限定只能在文件系统中的特定目录里选择文件。 |
| FloatField | NumberInput | 浮点数,在 Python 中使用 float 实例表示。注意, field.localize 的值为 False 时,默认的小组件是 TextInput 。 |
| ImageField | ClearableFileInput | 所有属性和方法都继承自 FileField ,此外验证上传的对象是不是有效的图像。增加了 height 和 width 两个属性。需要 Pillow 库支持。 |
字段选项
- 通过字段选项,可以实现对字段的约束
- 在字段对象时通过关键字参数指定
- null:如果为True,Django 将空值以NULL 存储到数据库中,默认值是 False
- blank:如果为True,则该字段允许为空白,默认值是 False
- 对比:null是数据库范畴的概念,blank是表单验证证范畴的
- db_column:字段的名称,如果未指定,则使用属性的名称
- db_index:若值为 True, 则在表中会为此字段创建索引
- default:默认值
- primary_key:若为 True, 则该字段会成为模型的主键字段
- unique:如果为 True, 这个字段在表中必须有唯一值
关联关系
多对一 (ForeignKey)
Django提供了定义了几种最常见的数据库关联关系的方法:多对一,多对多,一对一。
多对一关系,需要两个位置参数,一个是关联的模型,另一个是 on_delete 选项,外键要定义在多的一方,如一个汽车厂生产多种汽车,一辆汽车只有一个生产厂家
from django.db import models
class Manufacturer(models.Model):
# ...
pass
class Car(models.Model):
manufacturer = models.ForeignKey(Manufacturer, on_delete=models.CASCADE)
多对多关系的额外字段:throuth
例如:这样一个应用,它记录音乐家所属的音乐小组。 我们可以用一个ManyToManyField 表示小组和成员之间的多对多关系。 但是,有时你可能想知道更多成员关系的细节,比如成员是何时加入小组的。
对于这些情况,Django 允许你指定一个中介模型来定义多对多关系。 你可以将其他字段放在中介模型里面。 源模型的ManyToManyField 字段将使用through 参数指向中介模型。 对于上面的音乐小组的例子,代码如下:
from django.db import models
class Person(models.Model):
name = models.CharField(max_length=128)
def __str__(self): # __unicode__ on Python 2
return self.name
class Group(models.Model):
name = models.CharField(max_length=128)
members = models.ManyToManyField(Person, through='Membership')
def __str__(self): # __unicode__ on Python 2
return self.name
class Membership(models.Model):
person = models.ForeignKey(Person, on_delete=models.CASCADE)
group = models.ForeignKey(Group, on_delete=models.CASCADE)
date_joined = models.DateField()
invite_reason = models.CharField(max_length=64)
您需要在设置中间模型的时候,显式地为多对多关系中涉及的中间模型指定外键。这种显式声明定义了这两个模型之间是如何关联的。
在中间模型当中有一些限制条件:
- 你的模型中间要么有且仅有一个指向源模型(我们例子当中的Group)的外键,你要么必须通过ManyToManyField.through_fields参数在多个外键当中手动选择一个外键,有如果外个多键盘没有用through_fields 参数选择一个的话,会出现验证错误。对于某个目标模型(我们示例当中的Person)的外键也有同样的限制。
- 在一个有用的描述模型当中自己指向自己的多对多关系的中间模型当中,可以有两个指向同一个模型的外健,但这两个外健分表代表多对多关系(不同)的两端。如果外健的个数超过两个,你必须和上面一样的指定through_fields参数,要不然会出现验证错误。
现在你已经通过中间模型完成你的ManyToManyField(示例中的Membership),可以开始创建一些多对多关系了。你通过实例化中间模型来创建关系:
>>> paul = Person.objects.create(name="Paul McCartney")
>>> beatles = Group.objects.create(name="The Beatles")
>>> m1 = Membership(person=ringo, group=beatles,
... date_joined=date(1962, 8, 16),
... invite_reason="Needed a new drummer.")
>>> m1.save()
>>> beatles.members.all()
<QuerySet [<Person: Ringo Starr>]>
>>> ringo.group_set.all()
<QuerySet [<Group: The Beatles>]>
>>> m2 = Membership.objects.create(person=paul, group=beatles,
... date_joined=date(1960, 8, 1),
... invite_reason="Wanted to form a band.")
>>> beatles.members.all()
<QuerySet [<Person: Ringo Starr>, <Person: Paul McCartney>]>你也可以使用add()、、create()或set()创建关系,只要你为任何必需的细分指定 through_defaults:
>>> beatles.members.add(john, through_defaults={'date_joined': date(1960, 8, 1)})
>>> beatles.members.create(name="George Harrison", through_defaults={'date_joined': date(1960, 8, 1)})
>>> beatles.members.set([john, paul, ringo, george], through_defaults={'date_joined': date(1960, 8, 1)})
你可能更潜在直接创造中间模型。
如果自定义中间模型没有强制对的唯一性,调用方法会删除所有中间模型的实例:(model1, model2)remove()
>>> Membership.objects.create(person=ringo, group=beatles, ... date_joined=date(1968, 9, 4), ... invite_reason="You've been gone for a month and we miss you.") >>> beatles.members.all() <QuerySet [<Person: Ringo Starr>, <Person: Paul McCartney>, <Person: Ringo Starr>]> >>> # This deletes both of the intermediate model instances for Ringo Starr >>> beatles.members.remove(ringo) >>> beatles.members.all() <QuerySet [<Person: Paul McCartney>]>
方法clear()用于实例的所有多对多关系:
>>> # Beatles have broken up >>> beatles.members.clear() >>> # Note that this deletes the intermediate model instances >>> Membership.objects.all() <QuerySet []>
一旦你建立了自定义多对多关联关系,就可以执行查询操作。和一般的多对多关联关系一样,你可以使用多对多关联模型的属性来查询:
# Find all the groups with a member whose name starts with 'Paul' >>> Group.objects.filter(members__name__startswith='Paul') <QuerySet [<Group: The Beatles>]>
当你使用中间模型的时候,你也可以查询他的属性:
# Find all the members of the Beatles that joined after 1 Jan 1961 >>> Person.objects.filter( ... group__name='The Beatles', ... membership__date_joined__gt=date(1961,1,1)) <QuerySet [<Person: Ringo Starr]>
如果你想访问一个关系的信息时你可以直接查询Membership模型:
>>> ringos_membership = Membership.objects.get(group=beatles, person=ringo) >>> ringos_membership.date_joined datetime.date(1962, 8, 16) >>> ringos_membership.invite_reason 'Needed a new drummer.'
另一种访问同样信息的方法是通过Person对象来查询多对多递归关系:
>>> ringos_membership = ringo.membership_set.get(group=beatles) >>> ringos_membership.date_joined datetime.date(1962, 8, 16) >>> ringos_membership.invite_reason 'Needed a new drummer.'
一对一关联
使用OneToOneField来定义一对一关系。就像使用其他类型的Field一样:在模型属性中包含它。
当一个对象以某种方式“继承”另一个对象时,这那个对象的主键非常有用。
OneToOneField需要一个位置参数:与模型相关的类。
例如,当你要建立一个有关“位置”信息的数据库时,你可能会包含通常的地址,电话等分支。然后,如果你想接着建立一个关于关于餐厅的数据库,除了将位置数据库当中的一部分复制到Restaurant模型,你也可以将一个指向Place OneToOneField放到Restaurant当中(因为餐厅“是一个”地点);事实上,在处理这样的情况时最好使用模型继承,它隐含的包括了一个一对一关系。
和 ForeignKey一样,可以创建自关联关系也可以创建与尚未定义的模型的关系。
OneToOneField初步还接受一个可选的parent_link参数。
OneToOneField类通常自动的成为模型的主键,这条规则现在不再使用了(而你可以手动指定primary_key参数)。因此,现在可以在其中的模型当中指定多个OneToOneField分段。
Django 使用表单模板
简介
除非您打算建立只发布内容的网站和应用程序,并且不接受访问者的输入,否则您将需要理解和使用表格。
Django提供了一系列工具和库,可帮助您构建表单以接受来自站点访问者的输入,然后处理并响应输入。
HTML表单
在HTML中,表单是内部元素的集合<form>...</form>,允许访问者执行诸如输入文本,选择选项,操作对象或控件等操作,然后将该信息发送回服务器。
其中一些表单界面元素(文本输入或复选框)内置于HTML本身。其他则要复杂得多。弹出日期选择器或允许您移动滑块或操纵控件的界面通常将使用JavaScript和CSS以及HTML表单<input>元素来实现这些效果。
<input>表单及其元素还必须指定两件事:
- 其中:应将与用户输入相对应的数据返回到的URL
- 如何:数据应通过的HTTP方法
Django表单处理流程
Django 的表单处理:视图获取请求,执行所需的任何操作,包括从模型中读取数据,然后生成并返回HTML页面(从模板中),我们传递一个包含要显示的数据的上下文。使事情变得更复杂的是,服务器还需要能够处理用户提供的数据,并在出现任何错误时,重新显示页面。
Django表单处理的主要内容:
- 在用户第一次请求时,显示默认表单。表单可能包含空白字段(例如,如果您正在创建新记录),或者可能预先填充了初始值(例如,如果您要更改记录,或者具有有用的默认初始值)。此时表单被称为未绑定,因为它与任何用户输入的数据无关(尽管它可能具有初始值)。
- 从提交请求接收数据,并将其绑定到表单。将数据绑定到表单,意味着当我们需要重新显示表单时,用户输入的数据和任何错误都可取用。
- 清理并验证数据。清理数据会对输入执行清理(例如,删除可能用于向服务器发送恶意内容的无效字符)并将其转换为一致的 Python 类型。验证检查值是否适合该字段(例如,在正确的日期范围内,不是太短或太长等)
- 如果任何数据无效,请重新显示表单,这次使用任何用户填充的值,和问题字段的错误消息。
- 如果所有数据都有效,请执行必要的操作(例如保存数据,发送表单和发送电子邮件,返回搜索结果,上传文件等)
- 完成所有操作后,将用户重定向到另一个页面。
Django表单分为两种使用方法:
- GET
- POST
GET 方法
- 浏览器请求一个页面
- 搜索引擎检索关键字的时候
GET方法是通过键值对的方式显示从用户那边获取的数据,然后通过“&”将其组合形成一个整体的字符串,最后加上“?”,将组合后的字符串拼接到URL内,生成一个url地址。它既不适用于大量数据,也不适合于二进制数据(例如图像)。使用GET 管理表单请求的Web应用程序存在安全风险:攻击者很容易模仿表单的请求来访问系统的敏感部分。GET仅应用于不影响系统状态的请求。诸如Web搜索表单类,它可以轻松对请求到的URL进行共享,提交等操作。
POST 方法
- 浏览器打包数据
- 以编码的形式进行传输
Django在表单中的角色
处理表格是一项复杂的业务。考虑一下Django的管理员,其中可能需要准备好几种不同类型的大量数据,以表格形式显示,呈现为HTML,使用便利的界面进行编辑,返回到服务器,进行验证和清理,然后保存或传递进行进一步处理。
Django的表单功能可以简化和自动化大部分工作,并且比大多数程序员在编写自己的代码中所能做到的更加安全。
Django处理涉及表单的工作的三个不同部分:
- 准备和重组数据以使其准备好呈现
- 为数据创建HTML表单
- 接收并处理客户提交的表格和数据
这是有可能到手动做这一切写代码,但Django的可以照顾这一切为您服务。
Django中的表单
我们已经简要描述了HTML表单,但是HTML <form>只是所需机制的一部分。
在Web应用程序的上下文中,“表单”可能是指该HTML <form>或Form生成它的Django ,或者是提交时返回的结构化数据,或者是这些部分的端到端工作集合。
Django Form类
该组件系统的核心是Django的Form类。类与Django模型描述对象的逻辑结构,其行为以及向我们表示其部分的方式几乎相同,一个 Form类描述一种形式并确定其工作方式和外观。
就像模型类的字段映射到数据库字段一样,表单类的字段映射到HTML表单<input>元素。(A 通过;ModelForm 将模型类的字段映射到HTML表单<input>元素 Form,这是Django管理员所基于的。)
表单的字段本身就是类。他们管理表单数据并在提交表单时执行验证。一个DateField和 FileField手柄非常不同类型的数据,并有做不同的事情吧。
表单字段在浏览器中以HTML“窗口小部件”的形式向用户表示-一种用户界面机制。每个字段类型都有一个适当的默认 Widget类,但是可以根据需要覆盖它们。
实例化,处理和呈现表单
在Django中渲染对象时,通常:
- 在视图中获取它(例如,从数据库中获取它)
- 传递给模板上下文
- 使用模板变量将其扩展为HTML标记
在模板中呈现表单与呈现任何其他类型的对象几乎涉及相同的工作,但是存在一些关键区别。
对于不包含数据的模型实例,在模板中执行任何操作几乎是没有用的。另一方面,呈现未填充的表单非常有意义-当我们希望用户填充它时,这就是我们要做的。
因此,当我们在视图中处理模型实例时,通常会从数据库中检索它。当我们处理表单时,通常在视图中实例化它。
实例化表单时,我们可以选择将其保留为空或预先填充,例如:
- 来自已保存模型实例的数据(例如用于编辑的管理表单)
- 我们从其他来源收集的数据
- 从先前的HTML表单提交中收到的数据
这些情况中的最后一个是最有趣的,因为它使用户不仅可以阅读网站,而且还可以向其发送信息。
构建形式
这方面还需要做需要的工作
假设您想在您的网站上创建一个简单的表单,以获得用户名。您在模板中需要这样的内容:
<form action="/your-name/" method="post">
<label for="your_name">Your name: </label>
<input id="your_name" type="text" name="your_name" value="{{ current_name }}">
<input type="submit" value="OK">
</form>
这告诉浏览器/your-name/使用POST方法将表单数据返回到URL 。它将显示一个文本字段,标记为“您的姓名:”,以及一个标记为“确定”的按钮。如果模板上下文包含一个current_name 变量,它将用于预填充该your_name字段。
您将需要一个视图来呈现包含HTML表单的模板,并且可以提供current_name适当的字段。
提交表单后,POST发送到服务器的请求将包含表单数据。
现在,您还将需要一个与该/your-name/URL 对应的视图,该视图将在请求中找到适当的键/值对,然后对其进行处理。
这是一个非常简单的形式。实际上,一个表单可能包含数十个或数百个字段,其中许多字段可能需要预先填充,并且我们可能希望用户在结束操作之前先完成几次编辑-提交循环。
甚至在提交表单之前,我们可能需要在浏览器中进行一些验证;我们可能想使用更复杂的字段,使用户可以执行诸如从日历中选择日期之类的操作。
在这一点上,让Django为我们完成大部分工作要容易得多。
在Django中建立表单
本Form类
我们已经知道我们想要HTML表单的外观了。我们在Django中的起点是:
的forms.pyfrom django import forms
class NameForm(forms.Form):
your_name = forms.CharField(label='Your name', max_length=100)
这定义了一个Form具有单个字段(your_name)的类。我们在该字段上应用了一个人类友好的标签,该标签将在<label>呈现时显示在标签上(尽管在这种情况下,label 我们指定的标签实际上与省略该标签时会自动生成的标签 相同)。
字段的最大允许长度由定义 max_length。这有两件事。它放在 maxlength="100"HTML上<input>(因此浏览器应首先防止用户输入超过该数量的字符)。这也意味着,当Django从浏览器接收回表单时,它将验证数据的长度。
一个Form实例有一个is_valid()方法,它运行于所有的字段验证程序。调用此方法时,如果所有字段都包含有效数据,它将:
- 返回 True
- 将表单的数据放在其cleaned_data属性中。
首次渲染时,整个表单将如下所示:
<label for="your_name">Your name: </label> <input id="your_name" type="text" name="your_name" maxlength="100" required>
请注意,它不包含<form>标签或提交按钮。我们必须在模板中提供这些信息。
视图
发送回Django网站的表单数据由视图处理,通常与发布表单的视图相同。这使我们可以重用某些相同的逻辑。
要处理表单,我们需要在视图中将其实例化的URL实例化为:
的views.pyfrom django.http import HttpResponseRedirect
from django.shortcuts import render
from .forms import NameForm
def get_name(request):
# if this is a POST request we need to process the form data
if request.method == 'POST':
# create a form instance and populate it with data from the request:
form = NameForm(request.POST)
# check whether it's valid:
if form.is_valid():
# process the data in form.cleaned_data as required
# ...
# redirect to a new URL:
return HttpResponseRedirect('/thanks/')
# if a GET (or any other method) we'll create a blank form
else:
form = NameForm()
return render(request, 'name.html', {'form': form})
如果我们通过GET请求到达此视图,它将创建一个空表单实例并将其放置在要呈现的模板上下文中。这是我们第一次访问URL时可以预期的情况。
如果表单是使用POST请求提交的,则视图将再次创建表单实例,并使用请求中的数据填充该表单实例:这称为“将数据绑定到表单”(现在是绑定表单)。form = NameForm(request.POST)
我们称为表单的is_valid()方法;如果不是True,我们返回带有表单的模板。这次,表单不再是空的(未绑定),因此将使用先前提交的数据填充HTML表单,并可以在其中根据需要对其进行编辑和更正。
如果is_valid()为True,我们现在将能够在其cleaned_data属性中找到所有经过验证的表单数据。我们可以使用此数据来更新数据库或进行其他处理,然后再将HTTP重定向发送到浏览器,告诉浏览器下一步该怎么做。
模板
我们不需要在name.html模板中做很多事情:
<form action="/your-name/" method="post">
{% csrf_token %}
{{ form }}
<input type="submit" value="Submit">
</form>
表单的所有字段及其属性将通过Django的模板语言从中解压缩为HTML标记。{{ form }}
表格和跨站点请求伪造保护
Django随附了易于使用的跨站点请求伪造保护。在POST启用CSRF保护的情况下提交表单时,必须csrf_token像前面的示例一样使用template标记。但是,由于CSRF保护并不直接与模板中的表单相关联,因此在本文档的以下示例中省略了此标签。
HTML5输入类型和浏览器验证
如果表单包括URLField,一个 EmailField或任何整数字段类型,Django会使用的url,email和numberHTML5输入类型。默认情况下,浏览器可以在这些字段上应用自己的验证,这可能比Django的验证更严格。如果您想禁用此行为,请novalidate在form标签上设置属性,或在字段上指定其他小部件,例如TextInput。
现在,我们有了一个工作的Web表单,该表单由Django描述Form,由视图处理并呈现为HTML <form>。
这就是您入门所需的全部内容,但是表单框架为您提供了更多便利。一旦了解了上述过程的基础,就应该准备了解表单系统的其他功能,并准备进一步了解基础机械。
有关Django Form类的更多信息
所有表单类均作为django.forms.Form 或的子类创建django.forms.ModelForm。您可以将其ModelForm视为的子类Form。Form并ModelForm实际上从(私有)BaseForm类继承通用功能,但是这种实现细节很少很重要。
模型和形式
实际上,如果您的表单将用于直接添加或编辑Django模型,那么ModelForm可以节省大量的时间,精力和代码,因为它可以构建表单以及适当的字段及其属性,来自一Model堂课。
绑定表单实例和未绑定表单实例
绑定形式和未绑定形式之间的区别很重要:
- 未绑定的表单没有与之关联的数据。呈现给用户时,它将为空或包含默认值。
- 绑定表单已提交数据,因此可以用来判断该数据是否有效。如果呈现了无效的绑定形式,则它可能包含内联错误消息,告诉用户要纠正哪些数据。
表单的is_bound属性将告诉您表单是否绑定了数据。
更多的字段
考虑一个比上面的最小示例更有用的形式,我们可以使用该形式在个人网站上实现“与我联系”功能:
的forms.pyfrom django import forms
class ContactForm(forms.Form):
subject = forms.CharField(max_length=100)
message = forms.CharField(widget=forms.Textarea)
sender = forms.EmailField()
cc_myself = forms.BooleanField(required=False)
我们之前的形式使用的单场,your_name,一CharField。在这种情况下,我们的表单有四个字段:subject,message,sender和 cc_myself。CharField,EmailField并且 BooleanField只有三个可用的字段类型; 完整列表可以在“ 表单”字段中找到。
Django 处理HTTP请求
URL调度
干净,优雅的URL方案是高质量Web应用程序中的重要细节。Django允许您根据需要设计URL,而无框架限制。
万维网创建者蒂姆·伯纳斯-李(Tim Berners-Lee)的文章“ Cool URIs not not change”中有关为什么URL应该干净和可用的出色论据,请参见。
概述
要设计应用程序的URL,您可以创建一个非正式地称为URLconf(URL配置)的Python模块 。该模块是纯Python代码,并且是URL路径表达式到Python函数(您的视图)之间的映射。
该映射可以根据需要短或长。它可以引用其他映射。而且,由于它是纯Python代码,因此可以动态构建。
Django还提供了一种根据活动语言翻译URL的方法。有关更多信息,请参见国际化文档。
Django是如何处理一个请求
当用户从您的Django支持的网站请求页面时,系统将使用以下算法来确定要执行的Python代码:
- Django确定要使用的根URLconf模块。通常,这是ROOT_URLCONF设置的值,但是如果传入 HttpRequest对象具有urlconf 属性(由中间件设置),则将使用其值代替 ROOT_URLCONF设置。
- Django加载该Python模块并查找变量 urlpatterns。这应该是一个序列的 django.urls.path()和/或django.urls.re_path()实例。
- Django按顺序遍历每个URL模式,并在第一个与请求的URL匹配的URL处停止,与匹配 path_info。
- 一旦其中一个URL模式匹配,Django就会导入并调用给定的视图,该视图是Python函数(或基于类的视图)。该视图将传递以下参数:的实例HttpRequest。如果匹配的URL模式不包含命名组,则来自正则表达式的匹配项将作为位置参数提供。关键字参数由提供的路径表达式匹配的任何命名部分组成,这些名称部分由或 的可选kwargs参数中指定的任何参数覆盖。django.urls.path()django.urls.re_path()在Django 3.0中进行了更改:在旧版本中,带有None值的关键字参数也由未提供的命名部分组成。
- 如果没有URL模式匹配,或者在此过程中的任何时候引发异常,Django都会调用一个适当的错误处理视图。请参阅下面的错误处理。
例子
这是一个示例URLconf:
from django.urls import path
from . import views
urlpatterns = [
path('articles/2003/', views.special_case_2003),
path('articles/<int:year>/', views.year_archive),
path('articles/<int:year>/<int:month>/', views.month_archive),
path('articles/<int:year>/<int:month>/<slug:slug>/', views.article_detail),
]
笔记:
- 要从URL捕获值,请使用尖括号。
- 捕获的值可以选择包括转换器类型。例如,用于 `捕获整数参数。如果不包括转换器/`,则匹配除字符以外的任何字符串。
- 无需添加斜杠,因为每个URL都有该斜杠。例如articles,不是/articles。
请求示例:
- 请求/articles/2005/03/匹配列表中的第三个条目。Django将调用该函数 。views.month_archive(request, year=2005, month=3)
- /articles/2003/会匹配列表中的第一个模式,而不是第二个,因为这些模式是按顺序测试的,而第一个是第一个通过的测试。随意利用命令来插入类似这样的特殊情况。在这里,Django将调用该函数 views.special_case_2003(request)
- /articles/2003 不会与任何这些模式匹配,因为每种模式都要求URL以斜杠结尾。
- /articles/2003/03/building-a-django-site/将匹配最终模式。Django将调用该函数 。views.article_detail(request, year=2003, month=3, slug="building-a-django-site")
路径转换器
默认情况下,以下路径转换器可用:
- str-匹配任何非空字符串,但路径分隔符除外'/'。如果表达式中不包含转换器,则为默认设置。
- int-匹配零或任何正整数。返回int。
- slug-匹配由ASCII字母或数字以及连字符和下划线字符组成的任何条形字符串。例如, building-your-1st-django-site。
- uuid-匹配格式化的UUID。为防止多个URL映射到同一页面,必须包含破折号,并且字母必须小写。例如,075194d3-6885-417e-a8a8-6c931e272f00。返回一个 UUID实例。
- path-匹配任何非空字符串,包括路径分隔符 '/'。这样,您就可以匹配完整的URL路径,而不是像一样匹配URL路径的一部分str。
注册自定义路径转换器
对于更复杂的匹配要求,您可以定义自己的路径转换器。
转换器是包含以下内容的类:
- 一regex类属性,作为一个字符串。
- 一种方法,用于将匹配的字符串转换为应传递给视图函数的类型。如果无法转换给定值,则应加注。A 被解释为不匹配,结果404响应会发送给用户,除非另一个URL模式匹配。to_python(self, value)``ValueError``ValueError
- 一种方法,用于将Python类型转换为要在URL中使用的字符串。to_url(self, value)
例如:
class FourDigitYearConverter:
regex = '[0-9]{4}'
def to_python(self, value):
return int(value)
def to_url(self, value):
return '%04d' % value
使用register_converter()以下命令在URLconf中注册自定义转换器类 :
from django.urls import path, register_converter
from . import converters, views
register_converter(converters.FourDigitYearConverter, 'yyyy')
urlpatterns = [
path('articles/2003/', views.special_case_2003),
path('articles/<yyyy:year>/', views.year_archive),
...
]
使用正则表达式
如果路径和转换器语法不足以定义URL模式,则还可以使用正则表达式。为此,请使用 re_path()代替path()。
在Python正则表达式中,命名正则表达式组的语法为(?Ppattern),其中name是组的名称,并且 pattern是匹配的某种模式。
这是前面的示例URLconf,使用正则表达式重写:
from django.urls import path, re_path
from . import views
urlpatterns = [
path('articles/2003/', views.special_case_2003),
re_path(r'^articles/(?P<year>[0-9]{4})/$', views.year_archive),
re_path(r'^articles/(?P<year>[0-9]{4})/(?P<month>[0-9]{2})/$', views.month_archive),
re_path(r'^articles/(?P<year>[0-9]{4})/(?P<month>[0-9]{2})/(?P<slug>[\w-]+)/$', views.article_detail),
]
这可以完成与上一个示例大致相同的操作,除了:
- 将要匹配的确切URL受到更多限制。例如,年份10000将不再匹配,因为年份整数被限制为正好是四位数长。
- 无论正则表达式进行哪种匹配,每个捕获的参数都将作为字符串发送到视图。
当从使用切换为使用path(), re_path()反之亦然时,特别重要的是要注意视图参数的类型可能会更改,因此您可能需要调整视图。
使用未命名的正则表达式组
除了命名组语法(例如)之外(?P[0-9]{4}),您还可以使用较短的未命名组(例如)([0-9]{4})。
不建议特别使用此用法,因为这样可以更轻松地在匹配的预期含义和视图的参数之间意外引入错误。
无论哪种情况,建议在给定的正则表达式中仅使用一种样式。当两种样式混合使用时,任何未命名的组都会被忽略,只有命名的组才会传递给视图函数。
嵌套参数
正则表达式允许嵌套参数,而Django会解析它们并将其传递给视图。反转时,Django将尝试填写所有外部捕获的参数,而忽略任何嵌套的捕获参数。考虑以下URL模式,这些URL模式可以选择采用page参数:
from django.urls import re_path
urlpatterns = [
re_path(r'^blog/(page-(\d+)/)?$', blog_articles), # bad
re_path(r'^comments/(?:page-(?P<page_number>\d+)/)?$', comments), # good
]
两种模式都使用嵌套参数,并将解析:例如, blog/page-2/将导致与匹配blog_articles两个位置参数:page-2/和2。的第二个模式 comments将comments/page-2/与关键字参数 page_number设置为2 匹配。在这种情况下,外部参数是一个非捕获参数(?:...)。
该blog_articles视图需要最外层捕获的参数被反转,page-2/或者在这种情况下不需要参数,而视图 comments可以不带参数也没有值而被反转page_number。
嵌套的捕获参数在视图参数和URL之间建立了牢固的耦合,如下所示blog_articles:视图接收部分URL(page-2/),而不是仅接收视图感兴趣的值。这种反转在反转时更为明显,因为反转视图,我们需要传递该URL而不是页码。
根据经验,当正则表达式需要参数但视图将其忽略时,仅捕获视图需要使用的值,并使用非捕获参数。
URLconf搜索的内容
URLconf按照正常的Python字符串搜索请求的URL。这不包括GET或POST参数或域名。
例如,在对的请求中https://www.example.com/myapp/,URLconf将寻找myapp/。
在请求中https://www.example.com/myapp/?page=3,URLconf将寻找myapp/。
URLconf不会查看请求方法。换句话说,所有的请求方法- ,,POST 等-将被路由到相同的URL相同的功能。GET``HEAD
为视图参数指定默认值
一个方便的技巧是为视图的参数指定默认参数。这是一个示例URLconf和视图:
# URLconf
from django.urls import path
from . import views
urlpatterns = [
path('blog/', views.page),
path('blog/page<int:num>/', views.page),
]
# View (in blog/views.py)
def page(request, num=1):
# Output the appropriate page of blog entries, according to num.
...
在上面的示例中,两个URL模式都指向同一视图– views.page–但是第一个模式未从URL中捕获任何内容。如果第一个模式匹配,该page()函数将使用它的默认参数num,1。如果第二个模式匹配, page()将使用num捕获的任何值。
基于类的视图
视图是可调用的,它接受请求并返回响应。这不仅可以是一个函数,而且Django提供了一些可用作视图的类的示例。这些使您可以利用继承和混合来构造视图并重用代码。对于任务,还有一些通用的视图,我们将在以后进行介绍,但是您可能想要设计自己的可重用视图结构,以适合您的用例。有关完整的详细信息,请参见基于类的视图参考文档。
基本的例子
Django提供了适合各种应用程序的基本视图类。所有视图都从View该类继承,该类负责将视图链接到URL,HTTP方法分派和其他常见功能。RedirectView提供HTTP重定向,并TemplateView扩展基类以使其也呈现模板。
URLconf中的用法
使用通用视图的最直接方法是直接在URLconf中创建它们。如果仅在基于类的视图上更改一些属性,则可以将它们传递给as_view()方法调用本身:
from django.urls import path
from django.views.generic import TemplateView
urlpatterns = [
path('about/', TemplateView.as_view(template_name="about.html")),
]
传递给任何参数as_view()将覆盖在类上设置的属性。在此示例中,我们将设置template_name 为TemplateView。可以对上的url属性使用类似的覆盖模式 RedirectView。
子类化通用视图
使用通用视图的第二种更强大的方法是从现有视图继承并覆盖子类中的属性(例如template_name)或方法(例如get_context_data)以提供新的值或方法。例如,考虑一个仅显示一个模板的视图 about.html。Django有一个通用视图可以执行此操作-- TemplateView因此我们可以将其子类化,并覆盖模板名称:
# some_app/views.py
from django.views.generic import TemplateView
class AboutView(TemplateView):
template_name = "about.html"
然后,我们需要将此新视图添加到我们的URLconf中。 TemplateView是一个类,而不是一个函数,因此我们将URL指向as_view()类方法,该方法为基于类的视图提供类似函数的条目:
# urls.py
from django.urls import path
from some_app.views import AboutView
urlpatterns = [
path('about/', AboutView.as_view()),
]
有关如何使用内置通用视图的更多信息,请参考下一个基于通用类的视图的主题。
支持其他的HTTP方法
假设有人想使用视图作为API通过HTTP访问我们的图书库。API客户端会时不时地进行连接,并下载自上次访问以来发布的图书的图书数据。但是,如果从那以后没有新书出现,那么从数据库中获取书本,呈现完整的响应并将其发送给客户端将浪费CPU时间和带宽。最好向API询问最新书籍的发布时间。
我们将URL映射到URLconf中的书列表视图:
from django.urls import path
from books.views import BookListView
urlpatterns = [
path('books/', BookListView.as_view()),
]
和视图:
from django.http import HttpResponse
from django.views.generic import ListView
from books.models import Book
class BookListView(ListView):
model = Book
def head(self, *args, **kwargs):
last_book = self.get_queryset().latest('publication_date')
response = HttpResponse()
# RFC 1123 date format
response['Last-Modified'] = last_book.publication_date.strftime('%a, %d %b %Y %H:%M:%S GMT')
return response
如果从GET请求访问视图,则在响应中返回对象列表(使用book_list.html模板)。但是,如果客户发出HEAD请求,则响应的主体为空,Last-Modified 标题会指示最新书籍的发布时间。根据此信息,客户端可以下载也可以不下载完整的对象列表。
形成基于类的意见处理
表单处理通常具有3条路径:
- 初始GET(空白或预填充形式)
- POST包含无效数据(通常重新显示带有错误的表单)
- 使用有效数据进行POST(处理数据并通常重定向)
自己实现这一点通常会导致很多重复的样板代码(请参阅在视图中使用表单)。为了避免这种情况,Django提供了一组通用的基于类的视图以进行表单处理。
基本形式
给出联系表:
的forms.py
from django import forms
class ContactForm(forms.Form):
name = forms.CharField()
message = forms.CharField(widget=forms.Textarea)
def send_email(self):
# send email using the self.cleaned_data dictionary
pass
可以使用构造视图FormView:
的views.py
from myapp.forms import ContactForm
from django.views.generic.edit import FormView
class ContactView(FormView):
template_name = 'contact.html'
form_class = ContactForm
success_url = '/thanks/'
def form_valid(self, form):
# This method is called when valid form data has been POSTed.
# It should return an HttpResponse.
form.send_email()
return super().form_valid(form)
笔记:
- FormView是继承的, TemplateResponseMixin因此 template_name 可以在这里使用。
- 的默认实现 form_valid()只是将重定向到success_url。
模型的形式
使用模型时,通用视图确实很出色。这些通用视图将自动创建一个ModelForm,只要它们能够确定要使用的模型类:
- 如果model给定了属性,则将使用该模型类。
- 如果get_object() 返回一个对象,则将使用该对象的类。
- 如果queryset给出a,将使用该查询集的模型。
模型表单视图提供了一种 form_valid()自动保存模型的实现。如果有特殊要求,可以覆盖此设置。请参阅下面的示例。
您甚至不需要提供success_urlfor CreateView或 UpdateView- get_absolute_url()如果可用,它们将 在模型对象上使用。
如果要使用自定义ModelForm(例如添加额外的验证),请form_class在视图上进行设置 。
注意:指定自定义表单类时,即使form_class可能是,您仍必须指定模型ModelForm。
首先,我们需要添加get_absolute_url()到 Author类中:
models.py中
from django.db import models
from django.urls import reverse
class Author(models.Model):
name = models.CharField(max_length=200)
def get_absolute_url(self):
return reverse('author-detail', kwargs={'pk': self.pk})
然后我们可以CreateView和朋友一起做实际的工作。注意这里我们是如何配置通用的基于类的视图的。我们不必自己编写任何逻辑:
的views.py
from django.urls import reverse_lazy
from django.views.generic.edit import CreateView, DeleteView, UpdateView
from myapp.models import Author
class AuthorCreate(CreateView):
model = Author
fields = ['name']
class AuthorUpdate(UpdateView):
model = Author
fields = ['name']
class AuthorDelete(DeleteView):
model = Author
success_url = reverse_lazy('author-list')
注意:我们必须使用reverse_lazy()而不是 reverse(),因为导入文件时不会加载url。
该fields属性的工作方式与fields上内部Meta类的属性相同ModelForm。除非您以其他方式定义表单类,否则该属性是必需的,否则视图将引发ImproperlyConfigured异常。
如果同时指定fields 和form_class属性, ImproperlyConfigured则会引发异常。
最后,我们将这些新视图连接到URLconf中:
的urls.py
from django.urls import path
from myapp.views import AuthorCreate, AuthorDelete, AuthorUpdate
urlpatterns = [
# ...
path('author/add/', AuthorCreate.as_view(), name='author-add'),
path('author/<int:pk>/', AuthorUpdate.as_view(), name='author-update'),
path('author/<int:pk>/delete/', AuthorDelete.as_view(), name='author-delete'),
]
注意:些观点继承 SingleObjectTemplateResponseMixin 它使用 template_name_suffix 了构建 template_name 基于模型。
在此示例中:
- CreateView和UpdateView使用myapp/author_form.html
- DeleteView 用途 myapp/author_confirm_delete.html
如果希望为CreateView和 提供单独的模板UpdateView,则可以 在视图类上设置 template_name或 template_name_suffix。
模型和request.user
要跟踪使用创建对象的用户,CreateView可以使用自定义方法ModelForm来执行此操作。首先,将外键关系添加到模型:
models.py中
from django.contrib.auth.models import User
from django.db import models
class Author(models.Model):
name = models.CharField(max_length=200)
created_by = models.ForeignKey(User, on_delete=models.CASCADE)
# ...
在视图中,确保您不包括created_by要编辑的字段列表,并覆盖 form_valid()以添加用户:
的views.py
from django.contrib.auth.mixins import LoginRequiredMixin
from django.views.generic.edit import CreateView
from myapp.models import Author
class AuthorCreate(LoginRequiredMixin, CreateView):
model = Author
fields = ['name']
def form_valid(self, form):
form.instance.created_by = self.request.user
return super().form_valid(form)
LoginRequiredMixin防止未登录的用户访问表单。如果您忽略了这一点,则需要处理中的未授权用户form_valid()。
AJAX示例
这是一个示例,显示了如何实现适用于AJAX请求以及“普通”表单POST的表单:
from django.http import JsonResponse
from django.views.generic.edit import CreateView
from myapp.models import Author
class AjaxableResponseMixin:
"""
Mixin to add AJAX support to a form.
Must be used with an object-based FormView (e.g. CreateView)
"""
def form_invalid(self, form):
response = super().form_invalid(form)
if self.request.is_ajax():
return JsonResponse(form.errors, status=400)
else:
return response
def form_valid(self, form):
# We make sure to call the parent's form_valid() method because
# it might do some processing (in the case of CreateView, it will
# call form.save() for example).
response = super().form_valid(form)
if self.request.is_ajax():
data = {
'pk': self.object.pk,
}
return JsonResponse(data)
else:
return response
class AuthorCreate(AjaxableResponseMixin, CreateView):
model = Author
fields = ['name']
在基于类的视图中使用mixins
警告: 这是一个高级主题。在探索这些技术之前,建议您对Django基于类的视图有一定的了解。
Django的内置基于类的视图提供了许多功能,但您可能需要单独使用其中的一些功能。例如,您可能想编写一个视图,该视图呈现一个模板以进行HTTP响应,但是您不能使用 TemplateView; 也许您只需要在上渲染模板POST,然后GET完全执行其他操作即可。虽然您可以TemplateResponse直接使用 ,但这可能会导致代码重复。
因此,Django还提供了许多混合器,这些混合器提供了更多离散功能。例如,模板呈现封装在中 TemplateResponseMixin。Django参考文档包含所有mixins的完整文档。
上下文和模板答复
提供了两个中央mixin,它们有助于在使用基于类的视图中的模板时提供一致的界面。
- TemplateResponseMixin每个返回a的内置视图都 TemplateResponse将调用提供的 render_to_response() 方法TemplateResponseMixin。在大多数情况下,都会为您调用此get()方法(例如,由TemplateView和 实现的方法都调用它DetailView);同样,不太可能需要覆盖它,尽管如果您希望响应返回的内容不是通过Django模板呈现的,那么您就需要这样做。有关此示例,请参见JSONResponseMixin示例。render_to_response()本身调用 get_template_names(),默认情况下会 template_name在基于类的视图上查询;其他两个mixin(SingleObjectTemplateResponseMixin 和 MultipleObjectTemplateResponseMixin)覆盖此属性,以便在处理实际对象时提供更灵活的默认值。
- ContextMixin每个需要上下文数据(例如用于渲染模板(包括TemplateResponseMixin上述内容))的内置视图都应调用 get_context_data()传递它们想要确保位于其中的任何数据作为关键字参数。 get_context_data()返回字典;在ContextMixin其中返回其关键字参数,但是通常会覆盖此参数以将更多成员添加到字典中。您也可以使用该 extra_context属性。
建立Django基于类的通用视图
让我们看看Django的两个基于类的通用视图是如何通过提供离散功能的mixin构建的。我们将考虑 DetailView,它呈现一个对象的“详细”视图,而 ListView,它将呈现一个对象列表(通常来自查询集),并可选地对它们进行分页。这将向我们介绍四个mixin,它们在使用单个Django对象或多个对象时提供有用的功能。
也有参与通用编辑观点混入(FormView和特定型号的意见CreateView, UpdateView和 DeleteView),并在基于日期的通用视图。这些已在mixin参考文档中介绍。
DetailView:使用单个Django对象
要显示对象的详细信息,我们基本上需要做两件事:我们需要查找对象,然后需要TemplateResponse使用合适的模板制作一个 ,并将该对象作为上下文。
要获得该对象,需要DetailView 依赖SingleObjectMixin,该get_object() 方法提供了一种方法,该 方法可以根据请求的URL找出对象(它会根据URLConf中的声明查找pk和slug关键字参数,然后从model视图的属性中查找该对象 ,或提供的 queryset 属性)。SingleObjectMixin也会覆盖 get_context_data(),它在所有Django的所有基于类的内置视图中使用,以为模板渲染提供上下文数据。
然后TemplateResponse,要 DetailView使用SingleObjectTemplateResponseMixin,则使用 , 如上所讨论的,它扩展了TemplateResponseMixin,覆盖 get_template_names()。实际上,它提供了一组相当复杂的选项,但是大多数人要使用的主要选项是 /_detail.html。该_detail部分可以通过设置来改变 template_name_suffix 的一个子类别的东西。(例如,通用编辑观点使用_form的创建和更新的意见,并 _confirm_delete进行删除的意见。)
ListView:使用许多Django对象
对象列表遵循大致相同的模式:我们需要一个(可能是分页的)对象列表,通常为 QuerySet,然后我们需要TemplateResponse使用该对象列表使用合适的模板制作一个 。
要获取对象,请ListView使用 MultipleObjectMixin,同时提供 get_queryset() 和 paginate_queryset()。与with不同SingleObjectMixin,不需要关闭URL的一部分来确定要使用的查询集,因此默认值使用 view类上的querysetor model属性。覆盖get_queryset() 此处的常见原因 是动态地改变对象,例如取决于当前用户或排除博客的将来帖子。
MultipleObjectMixin还重写 get_context_data()以包括用于分页的适当上下文变量(如果禁用了分页,则提供虚拟变量)。它依赖object_list于作为关键字参数进行传递的关键字参数ListView。
做一个TemplateResponse, ListView然后使用 MultipleObjectTemplateResponseMixin; 与SingleObjectTemplateResponseMixin 上面的方法一样,此方法将覆盖,get_template_names()以提供,最常用的是 ,而该部分再次从 属性中获取。(基于日期的通用视图使用诸如的后缀, 以此类推,以便为各种专门的基于日期的列表视图使用不同的模板。)a range of options/_list.html``_listtemplate_name_suffix_archive``_archive_year
使用Django的基于类的视图混入
现在,我们已经了解了Django的基于类的通用视图如何使用提供的mixins,让我们看一下将它们组合在一起的其他方法。当然,我们仍将它们与内置的基于类的视图或其他通用的基于类的视图结合起来,但是您可以解决许多比Django开箱即用的罕见问题。
警告:并非所有的mixin都可以一起使用,也不是所有基于通用类的视图都可以与所有其他mixin一起使用。在这里,我们提供了一些可行的示例。如果要合并其他功能,则必须考虑使用的不同类之间重叠的属性和方法之间的交互,以及方法解析顺序将如何影响以何种顺序调用哪些版本的方法。
Django的基于类的视图和基于类的视图mixin的参考文档将帮助您了解哪些属性和方法可能会导致不同的类和mixin之间发生冲突。
如有疑问,通常最好还是放弃并以 View或为基础TemplateView,也许使用 SingleObjectMixin和 MultipleObjectMixin。尽管您可能最终会写出更多的代码,但是以后其他人可能更容易理解它,而更少的交互性让您担心,可以节省一些时间。(当然,您总是可以深入了解Django基于类的通用视图的实现,以获取有关如何解决问题的灵感。)
SingleObjectMixin与View一起使用
如果我们要编写一个仅对做出响应的基于类的视图,则将创建子POST类View并post()在该子类中编写一个方法。但是,如果我们希望我们的处理能够处理从URL识别的特定对象,我们将需要提供的功能 SingleObjectMixin。
我们将通过在基于通用类的视图简介中Author使用的模型来 演示这一点。
的views.py
from django.http import HttpResponseForbidden, HttpResponseRedirect
from django.urls import reverse
from django.views import View
from django.views.generic.detail import SingleObjectMixin
from books.models import Author
class RecordInterest(SingleObjectMixin, View):
"""Records the current user's interest in an author."""
model = Author
def post(self, request, *args, **kwargs):
if not request.user.is_authenticated:
return HttpResponseForbidden()
# Look up the author we're interested in.
self.object = self.get_object()
# Actually record interest somehow here!
return HttpResponseRedirect(reverse('author-detail', kwargs={'pk': self.object.pk}))
实际上,您可能希望将兴趣记录在键值存储而不是关系数据库中,因此我们省略了这一点。唯一需要担心使用的视图 SingleObjectMixin就是我们要查找感兴趣的作者的地方,它通过调用来完成 self.get_object()。mixin会为我们处理其他所有事务。
我们可以很容易地将其挂接到我们的URL中:
的urls.py
from django.urls import path
from books.views import RecordInterest
urlpatterns = [
#...
path('author/<int:pk>/interest/', RecordInterest.as_view(), name='author-interest'),
]
请注意pk命名组,该组 get_object()用于查找Author实例。您还可以使用slug或的任何其他功能 SingleObjectMixin。
SingleObjectMixin与 使用ListView
ListView提供内置的分页功能,但是您可能希望对所有通过外键链接到另一个对象的对象列表进行分页。在我们的出版示例中,您可能希望对特定出版商的所有书籍进行分页。
一种实现方法是与结合ListView使用 SingleObjectMixin,以便分页图书清单的查询集可以脱离作为单个对象找到的出版商。为此,我们需要有两个不同的查询集:
- Book 由...使用的查询集 ListView由于我们可以访问Publisher要列出的书,因此我们可以覆盖get_queryset()和使用Publisher的反向外键管理器。
- Publisher queryset用于 get_object()我们将依靠的默认实现get_object()来获取正确的Publisher对象。但是,我们需要显式传递一个queryset参数,因为否则默认的的实现get_object()将调用 get_queryset()我们已重写以返回Book对象而不是对象的对象Publisher。
注意:我们必须仔细考虑get_context_data()。由于SingleObjectMixin和 ListView都会将事物放置在上下文数据中(context_object_name如果已设置)的值之下,因此我们将明确确保事物在 Publisher上下文数据中。ListView 将增加在合适的page_obj和paginator我们提供我们记得打电话super()。
现在我们可以写一个新的PublisherDetail:
from django.views.generic import ListView
from django.views.generic.detail import SingleObjectMixin
from books.models import Publisher
class PublisherDetail(SingleObjectMixin, ListView):
paginate_by = 2
template_name = "books/publisher_detail.html"
def get(self, request, *args, **kwargs):
self.object = self.get_object(queryset=Publisher.objects.all())
return super().get(request, *args, **kwargs)
def get_context_data(self, **kwargs):
context = super().get_context_data(**kwargs)
context['publisher'] = self.object
return context
def get_queryset(self):
return self.object.book_set.all()
请注意我们是如何设置的self.object,get()以便稍后在get_context_data()和中再次使用它get_queryset()。如果您未设置template_name,则模板将默认为正常 ListView选择,在这种情况下,这是 "books/book_list.html"因为它是一本书籍清单; ListView一无所知SingleObjectMixin,因此毫无 头绪Publisher。
该paginate_by所以你不必创建大量的书籍,看到分页的工作是在故意例如小!这是您要使用的模板:
{% extends "base.html" %}
{% block content %}
<h2>Publisher {{ publisher.name }}</h2>
<ol>
{% for book in page_obj %}
<li>{{ book.title }}</li>
{% endfor %}
</ol>
<div class="pagination">
<span class="step-links">
{% if page_obj.has_previous %}
<a href="?page={{ page_obj.previous_page_number }}">previous</a>
{% endif %}
<span class="current">
Page {{ page_obj.number }} of {{ paginator.num_pages }}.
</span>
{% if page_obj.has_next %}
<a href="?page={{ page_obj.next_page_number }}">next</a>
{% endif %}
</span>
</div>
{% endblock %}
避免任何更复杂
一般来说,你可以使用 TemplateResponseMixin和 SingleObjectMixin当你需要它们的功能。如上所示,稍加注意,您甚至可以SingleObjectMixin与结合使用 ListView。但是,随着您尝试这样做,事情变得越来越复杂,一个好的经验法则是:
暗示:您的每个视图都应仅使用mixins或一组基于类的通用视图中的视图:详细信息,列表,编辑和日期。例如,将TemplateView(内置于视图中)与 MultipleObjectMixin(通用列表)结合在一起是很好的选择 ,但是将SingleObjectMixin(通用细节)与MultipleObjectMixin(通用列表)结合起来可能会遇到问题。
为了显示当您尝试变得更复杂时会发生什么,我们展示了一个示例,该示例在存在更简单的解决方案时会牺牲可读性和可维护性。首先,让我们看一下与结合DetailView使用的天真尝试 , FormMixin以使我们能够 POST将Django Form带到与我们使用来显示对象相同的URL DetailView。
FormMixin与 使用DetailView
回想一下我们先前使用View和 SingleObjectMixin在一起的示例。我们正在记录用户对特定作者的兴趣;现在说,我们要让他们留下信息,说明他们为什么喜欢他们。再次,让我们假设我们不会将其存储在关系数据库中,而是存储在我们不再担心的更深奥的东西中。
此时,很自然地可以Form将封装从用户浏览器发送到Django的信息。还要说我们在REST上投入了巨资,因此我们想使用与显示来自用户的消息相同的URL来显示作者。让我们重写我们的代码AuthorDetailView。
尽管必须将a添加到上下文数据中,以便将其呈现在模板中,但我们将保留GET来自的处理。我们还希望从中引入表单处理,并编写一些代码,以便在表单上正确调用。DetailViewFormFormMixinPOST
注意:我们使用FormMixin并实现 post()自己,而不是尝试DetailView与之 混合FormView(这post()已经提供了合适的方法),因为这两个视图都实现get(),并且事情会变得更加混乱。
我们的新AuthorDetail外观如下所示:
# CAUTION: you almost certainly do not want to do this.
# It is provided as part of a discussion of problems you can
# run into when combining different generic class-based view
# functionality that is not designed to be used together.
from django import forms
from django.http import HttpResponseForbidden
from django.urls import reverse
from django.views.generic import DetailView
from django.views.generic.edit import FormMixin
from books.models import Author
class AuthorInterestForm(forms.Form):
message = forms.CharField()
class AuthorDetail(FormMixin, DetailView):
model = Author
form_class = AuthorInterestForm
def get_success_url(self):
return reverse('author-detail', kwargs={'pk': self.object.pk})
def post(self, request, *args, **kwargs):
if not request.user.is_authenticated:
return HttpResponseForbidden()
self.object = self.get_object()
form = self.get_form()
if form.is_valid():
return self.form_valid(form)
else:
return self.form_invalid(form)
def form_valid(self, form):
# Here, we would record the user's interest using the message
# passed in form.cleaned_data['message']
return super().form_valid(form)
get_success_url()提供重定向到的位置,该位置可用于的默认实现form_valid()。post()如前所述,我们必须提供我们自己的。
更好的解决方案
之间微妙的相互作用的数量 FormMixin和DetailView已测试我们的管理事物的能力。您不太可能想自己编写此类。
在这种情况下,尽管编写处理代码涉及很多重复,但是您可以post()自己编写方法,并保持 DetailView唯一的通用功能 Form。
可替代地,它仍然会比上面的方法工作少到具有用于处理的形式,其可以使用一个单独的视图 FormView从不同 DetailView无顾虑。
另一种更好的解决方案
我们实际上在这里试图做的是使用来自同一URL的两个不同的基于类的视图。那么为什么不这样做呢?我们在这里有一个非常清楚的划分:GET请求应获取 DetailView(Form添加到上下文数据中),POST请求应获取FormView。让我们先设置这些视图。
该AuthorDisplay视图与我们首次引入AuthorDetail时几乎相同;我们在写我们自己get_context_data(),使 AuthorInterestForm可用的模板。get_object()为了清楚起见,我们将跳过之前的 替代:
from django import forms
from django.views.generic import DetailView
from books.models import Author
class AuthorInterestForm(forms.Form):
message = forms.CharField()
class AuthorDisplay(DetailView):
model = Author
def get_context_data(self, **kwargs):
context = super().get_context_data(**kwargs)
context['form'] = AuthorInterestForm()
return context
然后AuthorInterest是a FormView,但是我们必须带进来, SingleObjectMixin以便我们可以找到我们正在谈论的作者,并且我们必须记住进行设置template_name以确保表单错误将呈现与AuthorDisplayon 相同的模板GET:
from django.http import HttpResponseForbidden
from django.urls import reverse
from django.views.generic import FormView
from django.views.generic.detail import SingleObjectMixin
class AuthorInterest(SingleObjectMixin, FormView):
template_name = 'books/author_detail.html'
form_class = AuthorInterestForm
model = Author
def post(self, request, *args, **kwargs):
if not request.user.is_authenticated:
return HttpResponseForbidden()
self.object = self.get_object()
return super().post(request, *args, **kwargs)
def get_success_url(self):
return reverse('author-detail', kwargs={'pk': self.object.pk})
最后,我们以一种新的AuthorDetail观点将它们组合在一起。我们已经知道,调用as_view()基于类的视图会使我们的行为与基于函数的视图完全相同,因此我们可以在两个子视图之间进行选择。
当然,您可以通过传递关键字参数as_view()的方式与在URLconf中传递 方式相同,例如,如果您希望该AuthorInterest行为也出现在另一个URL上,但使用不同的模板:
from django.views import View
class AuthorDetail(View):
def get(self, request, *args, **kwargs):
view = AuthorDisplay.as_view()
return view(request, *args, **kwargs)
def post(self, request, *args, **kwargs):
view = AuthorInterest.as_view()
return view(request, *args, **kwargs)
此方法还可以与任何其他直接从View或继承的常规基于类的视图或您自己的基于类的视图一起使用 TemplateView,因为它可以使不同的视图尽可能地分开。
当您想多次执行相同的操作时,基于类的视图就会大放异彩。假设您正在编写一个API,并且每个视图都应返回JSON而不是呈现的HTML。
我们可以创建一个mixin类以在所有视图中使用,一次处理到JSON的转换。
例如,JSON混合可能看起来像这样:
from django.http import JsonResponse
class JSONResponseMixin:
"""
A mixin that can be used to render a JSON response.
"""
def render_to_json_response(self, context, **response_kwargs):
"""
Returns a JSON response, transforming 'context' to make the payload.
"""
return JsonResponse(
self.get_data(context),
**response_kwargs
)
def get_data(self, context):
"""
Returns an object that will be serialized as JSON by json.dumps().
"""
# Note: This is *EXTREMELY* naive; in reality, you'll need
# to do much more complex handling to ensure that arbitrary
# objects -- such as Django model instances or querysets
# -- can be serialized as JSON.
return context
注意:请查看序列化Django对象文档,以获取有关如何正确将Django模型和查询集正确转换为JSON的更多信息。
这个mixin提供了render_to_json_response()一种与签名相同的方法render_to_response()。要使用它,我们需要将其混入一个TemplateView例如,并重写 render_to_response()以render_to_json_response()代替调用:
from django.views.generic import TemplateView
class JSONView(JSONResponseMixin, TemplateView):
def render_to_response(self, context, **response_kwargs):
return self.render_to_json_response(context, **response_kwargs)
同样,我们可以将我们的mixin与通用视图之一一起使用。我们可以DetailView通过JSONResponseMixin与django.views.generic.detail.BaseDetailView– 混合来制作自己的版本(混合 了 DetailView模板渲染之前的行为):
from django.views.generic.detail import BaseDetailView
class JSONDetailView(JSONResponseMixin, BaseDetailView):
def render_to_response(self, context, **response_kwargs):
return self.render_to_json_response(context, **response_kwargs)
然后可以以与其他任何视图相同的方式部署此视图 DetailView,并且行为完全相同-除了响应的格式。
如果你想成为真正的冒险,你甚至可以混合使用一个 DetailView子类,它能够返回两个 HTML和JSON的内容,根据不同的HTTP请求,的某些属性,如查询参数或HTTP标头。混合使用 JSONResponseMixin和和 SingleObjectTemplateResponseMixin,并render_to_response() 根据用户请求的响应类型覆盖的实现, 以采用适当的呈现方法:
from django.views.generic.detail import SingleObjectTemplateResponseMixin
class HybridDetailView(JSONResponseMixin, SingleObjectTemplateResponseMixin, BaseDetailView):
def render_to_response(self, context):
# Look for a 'format=json' GET argument
if self.request.GET.get('format') == 'json':
return self.render_to_json_response(context)
else:
return super().render_to_response(context)
由于Python解决方法重载的方式,对的调用 super().render_to_response(context)最终调用的 render_to_response() 实现TemplateResponseMixin。
详情参考: https://docs.djangoproject.com/en/3.0/
使用WSGI进行部署
简介
Django的主要部署平台是WSGI,这是Web服务器和应用程序的Python标准。
Django的startproject管理命令为您设置了一个最小的默认WSGI配置,您可以根据项目的需要对其进行调整,并指导任何符合WSGI的应用服务器使用。
Django包括以下WSGI服务器的入门文档:
该application对象
使用WSGI进行部署的关键概念是application应用服务器用来与您的代码进行通信的Callable。通常application以在服务器可访问的Python模块中命名的对象的形式提供。
该startproject命令将创建一个/wsgi.py包含此类application可调用文件的文件 。
Django的开发服务器和生产WSGI部署都使用了它。
WSGI服务器application从其配置中获取可调用对象的路径。Django的内置服务器(即runserver 命令)从WSGI_APPLICATION设置中读取它。默认情况下,它设置为.wsgi.application,它指向中的application 可调用对象/wsgi.py。
配置设置模块
当WSGI服务器加载您的应用程序时,Django需要导入settings模块-定义整个应用程序的地方。
Django使用 DJANGO_SETTINGS_MODULE环境变量以找到适当的设置模块。它必须包含指向设置模块的虚线路径。您可以将不同的值用于开发和生产。这完全取决于您如何组织设置。
如果未设置此变量,则默认wsgi.py将其设置为 mysite.settings,其中mysite是项目的名称。这就是 runserver默认情况下发现默认设置文件的方式。
注意:由于环境变量是进程范围的,因此当您在同一进程中运行多个Django站点时,这将无效。这与mod_wsgi一起发生。
为避免此问题,请对每个站点在自己的守护进程中使用mod_wsgi的守护程序模式,或通过在中强制执行来覆盖环境中的值。os.environ["DJANGO_SETTINGS_MODULE"] = "mysite.settings"``wsgi.py
应用WSGI中间件
要应用WSGI中间件,您可以包装应用程序对象。例如,您可以在以下位置添加这些行wsgi.py:
from helloworld.wsgi import HelloWorldApplication
application = HelloWorldApplication(application)
如果您想将Django应用程序与另一个框架的WSGI应用程序结合使用,也可以用自定义WSGI应用程序替换Django WSGI应用程序,该应用程序以后将其委托给Django WSGI应用程序。
Django与Gunicorn 的使用
Gunicorn(“绿色独角兽”)是用于UNIX的纯Python WSGI服务器。它没有依赖性,可以使用安装pip。
安装Gunicorn
通过运行安装gunicorn 。有关更多详细信息,请参见gunicorn文档。
python -m pip install gunicorn
在Gunicorn中将Django作为通用WSGI应用程序运行
安装Gunicorn后,将gunicorn提供一个命令来启动Gunicorn服务器进程。gunicorn的最简单调用是传递包含名为的WSGI应用程序对象的模块的位置application,对于典型的Django项目,该对象应 类似于:
gunicorn myproject.wsgi
这将启动一个进程,该进程运行一个正在侦听的线程127.0.0.1:8000。它要求您的项目位于Python路径上;确保该命令最简单的方法是在与manage.py文件相同的目录中运行此命令。
有关其他提示,请参见Gunicorn的部署文档。
如何使用Django与uWSGI
uWSGI是使用纯C编码的快速,自修复且对开发人员/ sysadmin友好的应用程序容器服务器。
也可以看看
uWSGI文档提供了一个涵盖Django,nginx和uWSGI(许多可能的部署设置)的教程。以下文档重点介绍如何将Django与uWSGI集成。
先决条件:uWSGI
uWSGI Wiki描述了几种安装过程。使用Python软件包管理器pip,您可以通过单个命令安装任何uWSGI版本。例如:
# Install current stable version.
$ python -m pip install uwsgi
# Or install LTS (long term support).
$ python -m pip install https://projects.unbit.it/downloads/uwsgi-lts.tar.gz
uWSGI模型
uWSGI在客户端-服务器模型上运行。您的Web服务器(例如nginx,Apache)与django-uwsgi“工作者”进程进行通信以提供动态内容。
为Django配置和启动uWSGI服务器
uWSGI支持多种配置过程的方式。
这是启动uWSGI服务器的示例命令:
uwsgi --chdir=/path/to/your/project \
--module=mysite.wsgi:application \
--env DJANGO_SETTINGS_MODULE=mysite.settings \
--master --pidfile=/tmp/project-master.pid \
--socket=127.0.0.1:49152 \ # can also be a file
--processes=5 \ # number of worker processes
--uid=1000 --gid=2000 \ # if root, uwsgi can drop privileges
--harakiri=20 \ # respawn processes taking more than 20 seconds
--max-requests=5000 \ # respawn processes after serving 5000 requests
--vacuum \ # clear environment on exit
--home=/path/to/virtual/env \ # optional path to a virtual environment
--daemonize=/var/log/uwsgi/yourproject.log # background the process
假设您有一个名为的顶级项目包mysite,并且mysite/wsgi.py其中包含一个包含WSGI application 对象的模块。如果您使用Django的最新版本(使用您自己的项目名称代替)运行,这将是您的布局。如果该文件不存在,则需要创建它。请参阅“ 如何使用WSGI进行部署”文档,以获取应放在此文件中的默认内容以及可以添加的其他内容。django-admin startproject mysite``mysite
Django特定的选项如下:
- chdir:需要在Python的导入路径上的目录路径-即包含mysite软件包的目录。
- module:要使用的WSGI模块-可能mysite.wsgi是startproject创建的模块。
- env:应该至少包含DJANGO_SETTINGS_MODULE。
- home:项目虚拟环境的可选路径。
示例ini配置文件:
[uwsgi]
chdir=/path/to/your/project
module=mysite.wsgi:application
master=True
pidfile=/tmp/project-master.pid
vacuum=True
max-requests=5000
daemonize=/var/log/uwsgi/yourproject.log
ini配置文件用法示例:
uwsgi --ini uwsgi.ini
修复UnicodeEncodeError文件上传
如果UnicodeEncodeError在上传文件名包含非ASCII字符的文件时看到,请确保将uWSGI配置为接受非ASCII文件名,方法是将其添加到您的uwsgi.ini:
env = LANG=en_US.UTF-8
有关详细信息,请参见Unicode参考指南的“ 文件”部分。
请参阅有关管理uWSGI进程的uWSGI文档,以获取有关启动,停止和重新加载uWSGI工作程序的信息。
在Apache和Django中使用Django和mod_wsgi
使用Apache和mod_wsgi部署Django 是使Django投入生产的一种久经考验的方法。
mod_wsgi是一个Apache模块,可以承载任何Python WSGI应用程序,包括Django。Django可以与任何支持mod_wsgi的Apache版本一起使用。
在官方的mod_wsgi文档是你的所有关于如何使用mod_wsgi的详细信息来源。您可能需要从安装和配置文档开始。
基本配置
安装并激活mod_wsgi后,请编辑Apache服务器的 httpd.conf文件并添加以下内容。
WSGIScriptAlias / /path/to/mysite.com/mysite/wsgi.py
WSGIPythonHome /path/to/venv
WSGIPythonPath /path/to/mysite.com
<Directory /path/to/mysite.com/mysite>
<Files wsgi.py>
Require all granted
</Files>
</Directory>
该WSGIScriptAlias行的第一位是您要在其上为应用程序提供服务的基本URL路径(/表示根URL),第二位是“ WSGI文件”的位置–参见下文–在系统上,通常在项目内部包(mysite在此示例中)。这告诉Apache使用该文件中定义的WSGI应用程序为给定URL下的任何请求提供服务。
如果您将项目的Python依赖项安装在中,请使用添加路径。有关更多详细信息,请参见mod_wsgi虚拟环境指南。virtual environmentWSGIPythonHome
该WSGIPythonPath行确保您的项目包可用于在Python路径上导入;换句话说,那行得通。import mysite
该`部分确保Apache可以访问您的wsgi.py` 文件。
接下来,我们需要确保wsgi.pyWSGI应用程序对象存在。从Django 1.4版开始,startproject将为您创建一个。否则,您将需要创建它。请参阅WSGI概述文档,以获取应放在此文件中的默认内容以及可以添加的其他内容。
警告:如果在单个mod_wsgi进程中运行多个Django站点,则所有站点都将使用碰巧先运行的站点的设置。可以通过以下方法解决:
os.environ.setdefault("DJANGO_SETTINGS_MODULE", "{{ project_name }}.settings")
在中wsgi.py,至:
os.environ["DJANGO_SETTINGS_MODULE"] = "{{ project_name }}.settings"
或通过使用mod_wsgi守护程序模式并确保每个站点都在其自己的守护进程中运行。
修复UnicodeEncodeError文件上传
如果UnicodeEncodeError在上传文件名包含非ASCII字符的文件时看到,请确保Apache配置为接受非ASCII文件名:
export LANG='en_US.UTF-8'
export LC_ALL='en_US.UTF-8'
放置此配置的常见位置是/etc/apache2/envvars。
有关详细信息,请参见Unicode参考指南的“ 文件”部分。
使用mod_wsgi守护程序模式
建议使用“守护程序模式”运行mod_wsgi(在非Windows平台上)。要创建所需的守护进程组并委派Django实例在其中运行,您将需要添加适当的 WSGIDaemonProcess和WSGIProcessGroup指令。如果您使用守护程序模式,则对上述配置的进一步更改是您不能使用WSGIPythonPath;相反,您应该使用的python-path选项 WSGIDaemonProcess,例如:
WSGIDaemonProcess example.com python-home=/path/to/venv python-path=/path/to/mysite.com
WSGIProcessGroup example.com
如果要在子目录中服务项目(https://example.com/mysite在此示例中),则可以添加WSGIScriptAlias 到上面的配置中:
WSGIScriptAlias /mysite /path/to/mysite.com/mysite/wsgi.py process-group=example.com
有关设置守护程序模式的详细信息,请参见mod_wsgi官方文档。
服务文件
Django本身不提供文件;它将工作交给您选择的任何Web服务器。
我们建议使用单独的Web服务器(即未同时运行Django的服务器)来提供媒体服务。这里有一些不错的选择:
- Nginx的
- 精简版的Apache
但是,如果您别无选择,只能在与VirtualHostDjango 相同的Apache上提供媒体文件,则 可以设置Apache以将某些URL用作静态媒体,而将另一些URL使用Django的mod_wsgi接口提供。
这个例子设置的Django在站点根目录,但发球robots.txt, favicon.ico和在什么/static/和/media/URL空间作为静态文件。所有其他URL将使用mod_wsgi提供:
Alias /robots.txt /path/to/mysite.com/static/robots.txt
Alias /favicon.ico /path/to/mysite.com/static/favicon.ico
Alias /media/ /path/to/mysite.com/media/
Alias /static/ /path/to/mysite.com/static/
<Directory /path/to/mysite.com/static>
Require all granted
</Directory>
<Directory /path/to/mysite.com/media>
Require all granted
</Directory>
WSGIScriptAlias / /path/to/mysite.com/mysite/wsgi.py
<Directory /path/to/mysite.com/mysite>
<Files wsgi.py>
Require all granted
</Files>
</Directory>
提供管理文件
在django.contrib.staticfiles中时INSTALLED_APPS,Django开发服务器会自动提供admin应用程序(以及所有其他已安装的应用程序)的静态文件。但是,当您使用任何其他服务器布置时,情况并非如此。您负责设置Apache或您使用的任何Web服务器来提供管理文件。
管理文件位于django/contrib/admin/static/adminDjango发行版的()中。
我们强烈建议您使用django.contrib.staticfiles处理管理文件(如上一节中列出Web服务器一起,使用这种手段collectstatic的管理命令收集的静态文件STATIC_ROOT,然后配置你的Web服务器服务STATIC_ROOT的STATIC_URL),但这里有三个其他方法:
- 从文档根目录创建指向管理静态文件的符号链接(这可能+FollowSymLinks在您的Apache配置中需要)。
- Alias如上所示,使用指令将适当的URL(可能为STATIC_URL+ admin/)别名为管理文件的实际位置。
- 复制管理静态文件,以使它们位于Apache文档根目录中。
从Apache对Django用户数据库进行身份验证
Django提供了一个处理程序,允许Apache直接针对Django的身份验证后端对用户进行身份验证。
由于与多个Apache处理身份验证数据库时保持同步是一个常见问题,因此可以将Apache配置为直接针对Django的身份验证系统进行身份 验证。这需要Apache版本> = 2.2和mod_wsgi> = 2.0。例如:
- 仅将静态/媒体文件直接从Apache提供给经过身份验证的用户。
- 拥有一定的权限,针对Django用户验证对Subversion存储库的访问。
- 允许某些用户连接到使用mod_dav创建的WebDAV共享。
注意:如果您已经安装了自定义用户模型并希望使用此默认身份验证处理程序,则它必须支持一个is_active 属性。如果要使用基于组的授权,则自定义用户必须具有一个名为“组”的关系,该关系引用具有“名称”字段的相关对象。如果您的自定义不符合这些要求,则还可以指定自己的自定义mod_wsgi身份验证处理程序。
使用进行身份验证mod_wsgi
注意:在以下配置中使用时,假设您的Apache实例仅运行一个Django应用程序。如果您正在运行多个Django应用程序,请参阅mod_wsgi文档的“ 定义应用程序组”部分以获取有关此设置的更多信息。WSGIApplicationGroup %{GLOBAL}
确保已安装并激活了mod_wsgi,并且已按照步骤使用mod_wsgi设置Apache。
接下来,编辑您的Apache配置,以添加仅希望经过身份验证的用户才能查看的位置:
WSGIScriptAlias / /path/to/mysite.com/mysite/wsgi.py
WSGIPythonPath /path/to/mysite.com
WSGIProcessGroup %{GLOBAL}
WSGIApplicationGroup %{GLOBAL}
<Location "/secret">
AuthType Basic
AuthName "Top Secret"
Require valid-user
AuthBasicProvider wsgi
WSGIAuthUserScript /path/to/mysite.com/mysite/wsgi.py
</Location>
该WSGIAuthUserScript指令告诉mod_wsgi check_password在指定的wsgi脚本中执行该 功能,并传递从提示符处收到的用户名和密码。在此示例中,与 定义由django-admin startproject创建的应用程序WSGIAuthUserScript的相同。WSGIScriptAlias
结合使用Apache 2.2和身份验证
确保mod_auth_basic和mod_authz_user已加载。
这些可能会静态地编译到Apache中,或者您可能需要使用LoadModule在您的中动态加载它们httpd.conf:
LoadModule auth_basic_module modules/mod_auth_basic.so
LoadModule authz_user_module modules/mod_authz_user.so
最后,mysite.wsgi通过导入以下check_password 功能来编辑WSGI脚本,以将Apache的身份验证与站点的身份验证机制联系起来:
import os
os.environ['DJANGO_SETTINGS_MODULE'] = 'mysite.settings'
from django.contrib.auth.handlers.modwsgi import check_password
from django.core.handlers.wsgi import WSGIHandler
application = WSGIHandler()
/secret/现在开始的请求将要求用户进行身份验证。
mod_wsgi 访问控制机制文档提供了其他详细信息和有关替代身份验证方法的信息。
mod_wsgi和Django组的授权
mod_wsgi还提供了将特定位置限制为组成员的功能。
在这种情况下,Apache配置应如下所示:
WSGIScriptAlias / /path/to/mysite.com/mysite/wsgi.py
WSGIProcessGroup %{GLOBAL}
WSGIApplicationGroup %{GLOBAL}
<Location "/secret">
AuthType Basic
AuthName "Top Secret"
AuthBasicProvider wsgi
WSGIAuthUserScript /path/to/mysite.com/mysite/wsgi.py
WSGIAuthGroupScript /path/to/mysite.com/mysite/wsgi.py
Require group secret-agents
Require valid-user
</Location>
为了支持该WSGIAuthGroupScript指令,相同的WSGI脚本 mysite.wsgi还必须导入该groups_for_user函数,该函数返回给定用户所属的列表组。
from django.contrib.auth.handlers.modwsgi import check_password, groups_for_user
如果有需求/secret/,现在也需要用户是“秘密特工”组的成员。
Django的缓存框架
Django的缓存框架
动态网站的基本权衡是动态的。每次用户请求页面时,Web服务器都会进行各种计算-从数据库查询到模板呈现再到业务逻辑-创建站点访问者可以看到的页面。从处理开销的角度来看,这比标准的从文件中读取文件的服务器系统要贵得多。
对于大多数Web应用程序而言,此开销并不大。大多数Web应用程序不是washingtonpost.com或slashdot.org; 它们是流量中等的中小型网站。但是对于中到高流量的站点,必须尽可能减少开销。
那就是缓存的来源。
缓存某些内容是为了保存昂贵的计算结果,因此您下次不必执行计算。以下是一些伪代码,用于说明如何将其应用于动态生成的网页:
given a URL, try finding that page in the cache
if the page is in the cache:
return the cached page
else:
generate the page
save the generated page in the cache (for next time)
return the generated page
Django带有一个健壮的缓存系统,可让您保存动态页面,因此不必为每个请求都计算它们。为了方便起见,Django提供了不同级别的缓存粒度:您可以缓存特定视图的输出,可以仅缓存难以生成的片段,或者可以缓存整个站点。
Django还可以与“下游”缓存(例如Squid和基于浏览器的缓存)配合使用。这些是您不直接控制的缓存类型,但是您可以向它们提供提示(通过HTTP标头)有关站点的哪些部分以及应该如何缓存的提示。
也可以看看
该缓存框架的设计理念, 解释了一些框架的设计决策。
设置缓存
缓存系统需要少量设置。即,您必须告诉它缓存的数据应该存放在哪里–无论是在数据库中,在文件系统上还是直接在内存中。这是一个影响缓存性能的重要决定。是的,某些缓存类型比其他类型更快。
您的缓存首选项进入CACHES设置文件中的设置。以下是的所有可用值的说明 CACHES。
Memcached
Memcached是Django原生支持的最快,最高效的缓存类型, 是一种完全基于内存的缓存服务器,最初是为处理LiveJournal.com上的高负载而开发的,随后由Danga Interactive开源。Facebook和Wikipedia等网站使用它来减少数据库访问并显着提高网站性能。
Memcached作为守护程序运行,并分配了指定数量的RAM。它所做的只是提供一个用于添加,检索和删除缓存中数据的快速接口。所有数据都直接存储在内存中,因此没有数据库或文件系统使用的开销。
本身安装Memcached后,您需要安装Memcached绑定。有几种可用的Python Memcached绑定。两种最常见的是python-memcached和pylibmc。
要将Memcached与Django结合使用,请执行以下操作:
- 设置BACKEND为 django.core.cache.backends.memcached.MemcachedCache或 django.core.cache.backends.memcached.PyLibMCCache(取决于您选择的内存缓存绑定)
- 设置LOCATION为ip:port值,其中ip是Memcached守护程序的IP地址,port是运行Memcached的端口,或者设置为unix:path值,其中 path是Memcached Unix套接字文件的路径。
在此示例中,Memcached使用python-memcached绑定在本地主机(127.0.0.1)端口11211上运行:
CACHES = {
'default': {
'BACKEND': 'django.core.cache.backends.memcached.MemcachedCache',
'LOCATION': '127.0.0.1:11211',
}
}
在此示例中,可以/tmp/memcached.sock使用python-memcached绑定通过本地Unix套接字文件使用Memcached :
CACHES = {
'default': {
'BACKEND': 'django.core.cache.backends.memcached.MemcachedCache',
'LOCATION': 'unix:/tmp/memcached.sock',
}
}
使用pylibmc绑定时,请勿包括unix:/前缀:
CACHES = {
'default': {
'BACKEND': 'django.core.cache.backends.memcached.PyLibMCCache',
'LOCATION': '/tmp/memcached.sock',
}
}
Memcached的一项出色功能是能够在多个服务器上共享缓存。这意味着您可以在多台计算机上运行Memcached守护程序,并且该程序会将计算机组视为单个 缓存,而无需在每台计算机上重复缓存值。要利用此功能,请将所有服务器地址包含在中 LOCATION,以分号或逗号分隔的字符串或列表的形式。
在此示例中,缓存在IP地址为172.19.26.240和172.19.26.242且均在端口11211上运行的Memcached实例之间共享:
CACHES = {
'default': {
'BACKEND': 'django.core.cache.backends.memcached.MemcachedCache',
'LOCATION': [
'172.19.26.240:11211',
'172.19.26.242:11211',
]
}
}
在以下示例中,缓存在运行在IP地址172.19.26.240(端口11211),172.19.26.42(端口11212)和172.19.26.244(端口11213)上的Memcached实例上共享:
CACHES = {
'default': {
'BACKEND': 'django.core.cache.backends.memcached.MemcachedCache',
'LOCATION': [
'172.19.26.240:11211',
'172.19.26.242:11212',
'172.19.26.244:11213',
]
}
}
关于Memcached的最后一点是基于内存的缓存有一个缺点:由于缓存的数据存储在内存中,因此如果服务器崩溃,数据将丢失。显然,内存不是用于永久性数据存储的,因此不要依赖基于内存的缓存作为唯一的数据存储。毫无疑问,任何 Django缓存后端都不应该用于永久存储-它们都旨在作为缓存而非存储的解决方案-但我们在此指出这一点是因为基于内存的缓存特别临时。
数据库高速缓存
Django可以将其缓存的数据存储在您的数据库中。如果您拥有快速索引良好的数据库服务器,则此方法效果最佳。
要将数据库表用作缓存后端:
- 设置BACKEND于 django.core.cache.backends.db.DatabaseCache
- 设置LOCATION为tablename,数据库表的名称。该名称可以是您想要的任何名称,只要它是数据库中尚未使用的有效表名即可。
在此示例中,缓存表的名称为my_cache_table:
CACHES = {
'default': {
'BACKEND': 'django.core.cache.backends.db.DatabaseCache',
'LOCATION': 'my_cache_table',
}
}
创建缓存表
在使用数据库缓存之前,必须使用以下命令创建缓存表:
python manage.py createcachetable
这会在您的数据库中创建一个表,该表的格式与Django的数据库缓存系统期望的格式相同。该表的名称取自 LOCATION。
如果使用多个数据库缓存,请createcachetable为每个缓存创建一个表。
如果您使用多个数据库,请createcachetable遵循allow_migrate()数据库路由器的 方法(请参见下文)。
像一样migrate,createcachetable不会触摸现有表格。它只会创建丢失的表。
要打印将要运行的SQL,而不是运行它,请使用 选项。createcachetable --dry-run
多个数据库
如果将数据库缓存与多个数据库一起使用,则还需要为数据库缓存表设置路由说明。为了进行路由,数据库高速缓存表CacheEntry在名为的应用程序中显示为名为的模型 django_cache。该模型不会出现在模型缓存中,但是可以将模型详细信息用于路由目的。
例如,以下路由器会将所有缓存读取操作定向到cache_replica,并将所有写入操作定向到 cache_primary。缓存表将仅同步到 cache_primary:
class CacheRouter:
"""A router to control all database cache operations"""
def db_for_read(self, model, **hints):
"All cache read operations go to the replica"
if model._meta.app_label == 'django_cache':
return 'cache_replica'
return None
def db_for_write(self, model, **hints):
"All cache write operations go to primary"
if model._meta.app_label == 'django_cache':
return 'cache_primary'
return None
def allow_migrate(self, db, app_label, model_name=None, **hints):
"Only install the cache model on primary"
if app_label == 'django_cache':
return db == 'cache_primary'
return None
如果您没有为数据库缓存模型指定路由方向,则缓存后端将使用default数据库。
当然,如果您不使用数据库缓存后端,则无需担心为数据库缓存模型提供路由说明。
文件系统缓存
基于文件的后端将每个缓存值序列化并存储为单独的文件。要将此后端设置BACKEND为"django.core.cache.backends.filebased.FileBasedCache"并 设置到 LOCATION合适的目录。例如,要在中存储缓存的数据/var/tmp/django_cache,请使用以下设置:
CACHES = {
'default': {
'BACKEND': 'django.core.cache.backends.filebased.FileBasedCache',
'LOCATION': '/var/tmp/django_cache',
}
}
如果您使用的是Windows,请将驱动器号放在路径的开头,如下所示:
CACHES = {
'default': {
'BACKEND': 'django.core.cache.backends.filebased.FileBasedCache',
'LOCATION': 'c:/foo/bar',
}
}
目录路径应该是绝对的-也就是说,它应该从文件系统的根目录开始。是否在设置的末尾加斜杠都没关系。
确保此设置指向的目录存在,并且Web服务器在其下运行的系统用户可以读写。继续上面的示例,如果您的服务器以用户身份运行apache,请确保该目录/var/tmp/django_cache存在并且可由用户读取和写入apache。
本地内存缓存
如果未在设置文件中指定其他缓存,则这是默认缓存。如果您想要内存中缓存的速度优势,但又不具备运行Memcached的功能,请考虑使用本地内存缓存后端。该缓存是按进程(请参阅下文)并且是线程安全的。要使用它,请设置BACKEND为"django.core.cache.backends.locmem.LocMemCache"。例如:
CACHES = {
'default': {
'BACKEND': 'django.core.cache.backends.locmem.LocMemCache',
'LOCATION': 'unique-snowflake',
}
}
高速缓存LOCATION用于标识各个内存存储。如果只有一个locmem缓存,则可以省略 LOCATION; 但是,如果您有多个本地内存缓存,则需要至少为其分配一个名称,以使它们分开。
缓存使用最近最少使用(LRU)淘汰策略。
请注意,每个进程都有其自己的专用缓存实例,这意味着不可能进行跨进程缓存。这显然也意味着本地内存缓存不是特别有效的内存,因此对于生产环境而言,它可能不是一个好选择。这对开发很好。
虚拟缓存(用于开发)
最后,Django附带了一个“虚拟”缓存,该缓存实际上并没有缓存-它只是实现了缓存接口而无所事事。
如果您的生产站点在各个地方都使用了重型缓存,但是在开发/测试环境中却不想缓存并且不想将代码更改为后者的特殊情况,这将非常有用。要激活虚拟缓存,设置BACKEND如下:
CACHES = {
'default': {
'BACKEND': 'django.core.cache.backends.dummy.DummyCache',
}
}
使用自定义缓存后端
尽管Django开箱即用地支持许多缓存后端,但有时您可能希望使用自定义的缓存后端。要使用Django的外部缓存后端,使用Python导入路径作为 BACKEND该的CACHES设置,如下所示:
CACHES = {
'default': {
'BACKEND': 'path.to.backend',
}
}
如果要构建自己的后端,则可以将标准缓存后端用作参考实现。您将django/core/cache/backends/在Django源代码的目录中找到代码 。
注意:如果没有真正令人信服的理由,例如不支持它们的主机,则应坚持使用Django随附的缓存后端。他们已经过充分的测试并且有据可查。
缓存参数
可以为每个缓存后端提供其他参数来控制缓存行为。这些参数作为设置中的其他键提供 CACHES。有效参数如下:
- TIMEOUT:用于缓存的默认超时(以秒为单位)。此参数默认为300秒(5分钟)。您可以设置TIMEOUT为None默认情况下,缓存键永不过期。值的值0使键立即过期(有效地是“不缓存”)。
- OPTIONS:应传递到缓存后端的所有选项。有效选项的列表将随每个后端而有所不同,并且由第三方库支持的缓存后端会将其选项直接传递给基础缓存库。实现自己的扑杀战略(即缓存后端locmem,filesystem以及database后端)将履行下列选项:MAX_ENTRIES:删除旧值之前,缓存中允许的最大条目数。此参数默认为300。CULL_FREQUENCY:MAX_ENTRIES到达时被剔除的条目分数。实际比例为 ,因此设置为在达到时剔除一半条目。此参数应为整数,默认为。1 / CULL_FREQUENCYCULL_FREQUENCY2MAX_ENTRIES3值0for CULL_FREQUENCY表示MAX_ENTRIES到达时将转储整个缓存。在一些后端(database尤其是)这使得扑杀多 以更高速缓存未命中的代价更快。Memcached后端将OPTIONS as关键字参数的内容传递给客户端构造函数,从而可以更高级地控制客户端行为。有关用法示例,请参见下文。
- KEY_PREFIX:一个字符串,它将自动包含在Django服务器使用的所有缓存键中(默认为前缀)。有关更多信息,请参见缓存文档。
- VERSION:Django服务器生成的缓存键的默认版本号。有关更多信息,请参见缓存文档。
- KEY_FUNCTION 一个字符串,其中包含指向函数的虚线路径,该函数定义了如何将前缀,版本和键组成最终的缓存键。有关 更多信息,请参见缓存文档。
在此示例中,文件系统后端的超时时间为60秒,最大容量为1000:
CACHES = {
'default': {
'BACKEND': 'django.core.cache.backends.filebased.FileBasedCache',
'LOCATION': '/var/tmp/django_cache',
'TIMEOUT': 60,
'OPTIONS': {
'MAX_ENTRIES': 1000
}
}
}
这python-memcached是对象大小限制为2MB 的基于后端的示例配置:
CACHES = {
'default': {
'BACKEND': 'django.core.cache.backends.memcached.MemcachedCache',
'LOCATION': '127.0.0.1:11211',
'OPTIONS': {
'server_max_value_length': 1024 * 1024 * 2,
}
}
}
这是pylibmc基于基础的后端的示例配置,该配置启用了二进制协议,SASL身份验证和ketama行为模式:
CACHES = {
'default': {
'BACKEND': 'django.core.cache.backends.memcached.PyLibMCCache',
'LOCATION': '127.0.0.1:11211',
'OPTIONS': {
'binary': True,
'username': 'user',
'password': 'pass',
'behaviors': {
'ketama': True,
}
}
}
}
每个站点的缓存
一旦设置了缓存,使用缓存的最简单方法就是缓存整个站点。您需要将'django.middleware.cache.UpdateCacheMiddleware'和 添加 'django.middleware.cache.FetchFromCacheMiddleware'到 MIDDLEWARE设置中,如以下示例所示:
MIDDLEWARE = [
'django.middleware.cache.UpdateCacheMiddleware',
'django.middleware.common.CommonMiddleware',
'django.middleware.cache.FetchFromCacheMiddleware',
]
注意
不,这不是输入错误:“更新”中间件必须位于列表的第一位,“获取”中间件必须位于最后。细节有些晦涩,但是如果您想了解完整的故事,请参阅下面的MIDDLEWARE顺序。
然后,将以下必需设置添加到Django设置文件中:
- CACHE_MIDDLEWARE_ALIAS –用于存储的缓存别名。
- CACHE_MIDDLEWARE_SECONDS –每个页面应缓存的秒数。
- CACHE_MIDDLEWARE_KEY_PREFIX–如果使用同一Django安装在多个站点之间共享缓存,请将其设置为站点名称或该Django实例唯一的其他字符串,以防止按键冲突。如果您不在乎,请使用空字符串。
FetchFromCacheMiddleware缓存状态为200的GET和HEAD响应,其中请求和响应标头允许。对具有不同查询参数的相同URL请求的响应被视为唯一页面,并分别进行缓存。该中间件期望用与相应的GET请求相同的响应头来应答HEAD请求。在这种情况下,它可以为HEAD请求返回缓存的GET响应。
此外,会UpdateCacheMiddleware自动在每个标题中设置一些标题 HttpResponse:
- 将Expires标题设置为当前日期/时间加上定义的 CACHE_MIDDLEWARE_SECONDS。
- Cache-Control再次设置,将页眉设置为页面的最长使用期限CACHE_MIDDLEWARE_SECONDS。
有关中间件的更多信息,请参见中间件。
如果视图设置了自己的缓存到期时间(即max-age,其Cache-Control标题中有一个部分),则页面将一直缓存到到期时间,而不是CACHE_MIDDLEWARE_SECONDS。使用装饰器 django.views.decorators.cache可以轻松设置视图的过期时间(使用cache_control()装饰器)或禁用视图的缓存(使用 never_cache()装饰器)。有关这些装饰器的更多信息,请参见“ 使用其他标头”部分。
如果USE_I18N设置为,True则生成的缓存键将包括活动语言的名称-另请参见 Django如何发现语言首选项。这使您可以轻松地缓存多语言站点,而不必自己创建缓存密钥。
缓存键还包括积极的语言时, USE_L10N设置为True与当前时区时USE_TZ被设置为True。
每视图缓存
django.views.decorators.cache.cache_page()
使用缓存框架的更精细的方法是缓存单个视图的输出。django.views.decorators.cache定义一个cache_page 装饰器,该装饰器将自动为您缓存视图的响应:
from django.views.decorators.cache import cache_page
@cache_page(60 * 15)
def my_view(request):
...
cache_page有一个参数:缓存超时(以秒为单位)。在上面的示例中,my_view()视图结果将被缓存15分钟。(请注意,我们出于可读性的目的编写了该代码。它将被评估为– 15分钟乘以每分钟60秒。)60 * 1560 * 15900
与每个站点的缓存一样,每个视图的缓存也是从URL键入的。如果多个URL指向同一视图,则每个URL将被分别缓存。继续该my_view示例,如果您的URLconf如下所示:
urlpatterns = [
path('foo/<int:code>/', my_view),
]
然后,您所期望的/foo/1/和的请求/foo/23/将分别进行缓存。但是,一旦/foo/23/请求了特定的URL(例如),则对该URL的后续请求将使用缓存。
cache_page也可以采用可选的关键字参数,cache该参数指示装饰器CACHES在缓存视图结果时使用特定的缓存(来自您的 设置)。默认情况下, default将使用缓存,但是您可以指定所需的任何缓存:
@cache_page(60 * 15, cache="special_cache")
def my_view(request):
...
您还可以基于每个视图覆盖缓存前缀。cache_page 带有一个可选的关键字参数,key_prefix其工作方式CACHE_MIDDLEWARE_KEY_PREFIX 与中间件的设置相同。可以这样使用:
@cache_page(60 * 15, key_prefix="site1")
def my_view(request):
...
的key_prefix和cache参数可以被同时指定。该 key_prefix参数和KEY_PREFIX 规定下,CACHES将串联。
在URLconf中指定每个视图的缓存
上一节中的示例已经硬编码了缓存视图的事实,因为该视图cache_page改变了my_view功能。这种方法将您的视图耦合到高速缓存系统,由于多种原因,这种方法并不理想。例如,您可能想在另一个无缓存的站点上重用视图功能,或者可能希望将视图分发给可能希望在不被缓存的情况下使用它们的人。这些问题的解决方案是在URLconf中指定每个视图的缓存,而不是在视图函数本身旁边。
您可以通过cache_page在URLconf中引用视图函数时将其包装在一起来实现。这是之前的旧版URLconf:
urlpatterns = [
path('foo/<int:code>/', my_view),
]
这是同一件事,my_view包裹在其中cache_page:
from django.views.decorators.cache import cache_page
urlpatterns = [
path('foo/<int:code>/', cache_page(60 * 15)(my_view)),
]
模板片段缓存
如果您希望获得更多控制权,则还可以使用cachetemplate标签缓存模板片段。要让您的模板访问此标签,请放在 模板顶部附近。{% load cache %}
该模板标签缓存块中的内容给定的时间量。它至少需要两个参数:高速缓存超时(以秒为单位)和提供高速缓存片段的名称。如果超时为,则片段将永远被缓存。名称将按原样使用,请勿使用变量。例如:{% cache %}None
{% load cache %}
{% cache 500 sidebar %}
.. sidebar ..
{% endcache %}
有时,您可能希望根据片段内显示的一些动态数据来缓存片段的多个副本。例如,您可能想要为站点中的每个用户提供上一个示例中使用的侧边栏的单独的缓存副本。为此,请将一个或多个其他参数(可以是带或不带过滤器的变量)传递给模板标记,以唯一地标识缓存片段:{% cache %}
{% load cache %}
{% cache 500 sidebar request.user.username %}
.. sidebar for logged in user ..
{% endcache %}
如果USE_I18N将设置为True每个站点,则中间件缓存将 尊重活动语言。对于cache模板标记,您可以使用模板中可用的特定于 翻译的变量之一来获得相同的结果:
{% load i18n %}
{% load cache %}
{% get_current_language as LANGUAGE_CODE %}
{% cache 600 welcome LANGUAGE_CODE %}
{% trans "Welcome to example.com" %}
{% endcache %}
缓存超时可以是模板变量,只要模板变量解析为整数值即可。例如,如果将模板变量 my_timeout设置为value 600,那么以下两个示例是等效的:
{% cache 600 sidebar %} ... {% endcache %}
{% cache my_timeout sidebar %} ... {% endcache %}
此功能有助于避免模板中的重复。您可以在一个位置的变量中设置超时,然后重用该值。
默认情况下,缓存标签将尝试使用名为“ template_fragments”的缓存。如果不存在这样的缓存,它将退回到使用默认缓存。您可以选择与using关键字参数一起使用的备用缓存后端,该参数必须是标记的最后一个参数。
{% cache 300 local-thing ... using="localcache" %}
指定未配置的缓存名称被视为错误。
django.core.cache.utils.make_template_fragment_key(fragment_name,vary_on =无)
如果要获取用于缓存片段的缓存密钥,可以使用 make_template_fragment_key。fragment_name与cachetemplate标签的第二个参数相同;vary_on是传递给标记的所有其他参数的列表。该功能对于使缓存项无效或覆盖很有用,例如:
>>> from django.core.cache import cache
>>> from django.core.cache.utils import make_template_fragment_key
# cache key for {% cache 500 sidebar username %}
>>> key = make_template_fragment_key('sidebar', [username])
>>> cache.delete(key) # invalidates cached template fragment
低级缓存API
有时,缓存整个渲染的页面并不会带来太多好处,实际上,这会带来不便。
例如,也许您的站点包含一个视图,该视图的结果取决于几个昂贵的查询,这些查询的结果以不同的间隔更改。在这种情况下,使用每个站点或每个视图缓存策略提供的全页缓存并不理想,因为您不想缓存整个结果(因为某些数据经常更改),但您仍想缓存很少更改的结果。
对于此类情况,Django会公开一个低级缓存API。您可以使用此API以所需的任意粒度级别将对象存储在缓存中。您可以缓存可以安全腌制的任何Python对象:字符串,字典,模型对象列表等。(可以对大多数常见的Python对象进行腌制;有关腌制的更多信息,请参考Python文档。)
访问缓存
django.core.cache.caches-
您可以
CACHES通过类似dict的对象访问在设置中配置的缓存:django.core.cache.caches。在同一线程中重复请求相同的别名将返回相同的对象。>>> from django.core.cache import caches >>> cache1 = caches['myalias'] >>> cache2 = caches['myalias'] >>> cache1 is cache2 True
如果指定的键不存在,
InvalidCacheBackendError将引发。为了提供线程安全,将为每个线程返回不同的缓存后端实例。
django.core.cache.cache-
作为一种快捷方式,默认高速缓存可用于
django.core.cache.cache:>>> from django.core.cache import cache
此对象等效于
caches['default']。
基本用法
基本界面是:
cache.set(key,value,timeout = DEFAULT_TIMEOUT,version = None)-
>>> cache.set('my_key', 'hello, world!', 30)
cache.get(key,default = None,version = None)-
>>> cache.get('my_key') 'hello, world!'
key应该是str,并且value可以是任何可挑选的Python对象。
该timeout参数是可选的,并且默认为设置中timeout相应后端的参数CACHES(如上所述)。这是该值应存储在缓存中的秒数。传递 Nonefor timeout将永远缓存该值。一个timeout的0 将不缓存值。
如果对象在缓存中不存在,则cache.get()返回None:
>>> # Wait 30 seconds for 'my_key' to expire...
>>> cache.get('my_key')
None
我们建议不要将文字值存储None在缓存中,因为您将无法区分存储的None值和返回值为的缓存未命中None。
cache.get()可以default争论。这指定了如果对象在缓存中不存在则返回哪个值:
>>> cache.get('my_key', 'has expired')
'has expired'
cache.add(key,value,timeout = DEFAULT_TIMEOUT,version = None)
若要仅在密钥尚不存在时添加密钥,请使用add()方法。它使用与相同的参数set(),但是如果指定的键已经存在,它将不会尝试更新缓存:
>>> cache.set('add_key', 'Initial value')
>>> cache.add('add_key', 'New value')
>>> cache.get('add_key')
'Initial value'
如果您需要知道是否add()在缓存中存储了值,则可以检查返回值。True如果存储了值,它将返回, False否则返回。
cache.get_or_set(key,default,timeout = DEFAULT_TIMEOUT,version = None)
如果要获取键的值,或者如果键不在缓存中则要设置值,则可以使用该get_or_set()方法。它使用与相同的参数,get() 但默认设置为该键的新缓存值,而不是返回:
>>> cache.get('my_new_key') # returns None
>>> cache.get_or_set('my_new_key', 'my new value', 100)
'my new value'
您还可以将任何callable作为默认值传递:
>>> import datetime
>>> cache.get_or_set('some-timestamp-key', datetime.datetime.now)
datetime.datetime(2014, 12, 11, 0, 15, 49, 457920)
cache.get_many(keys,version = None)
还有一个get_many()接口只命中一次缓存。 get_many()返回一个字典,其中包含您要求的所有键,这些键实际上已存在于缓存中(并且尚未过期):
>>> cache.set('a', 1)
>>> cache.set('b', 2)
>>> cache.set('c', 3)
>>> cache.get_many(['a', 'b', 'c'])
{'a': 1, 'b': 2, 'c': 3}
cache.set_many(dict,超时)
要更有效地设置多个值,请使用set_many()传递键值对字典:
>>> cache.set_many({'a': 1, 'b': 2, 'c': 3})
>>> cache.get_many(['a', 'b', 'c'])
{'a': 1, 'b': 2, 'c': 3}
像一样cache.set(),set_many()带有一个可选timeout参数。
在支持的后端(memcached)上,set_many()返回未能插入的密钥列表。
cache.delete(key,version = None)
您可以显式删除键,delete()以清除特定对象的缓存:
>>> cache.delete('a')
cache.delete_many(keys,version = None)
如果要一次清除一堆键,delete_many()可以列出要清除的键列表:
>>> cache.delete_many(['a', 'b', 'c'])
cache.clear()
最后,如果要删除缓存中的所有键,请使用 cache.clear()。注意这一点。clear()将从 缓存中删除所有内容,而不仅仅是您的应用程序设置的键。
>>> cache.clear()
cache.touch(key,timeout = DEFAULT_TIMEOUT,version = None)
cache.touch()为密钥设置新的到期时间。例如,要将密钥更新为从现在起10秒钟过期:
>>> cache.touch('a', 10)
True
与其他方法一样,该timeout参数是可选的,并且默认为设置中TIMEOUT相应后端的 选项CACHES。
touch()True如果按键被成功触摸,False 则返回;否则返回。
cache.incr(key,delta = 1,version = None)
cache.decr(key,delta = 1,version = None)
您也可以分别使用incr()或decr()方法递增或递减已存在的键 。默认情况下,现有的高速缓存值将递增或递减1。可以通过为递增/递减调用提供参数来指定其他递增/递减值。如果您尝试增加或减少不存在的缓存键,将引发ValueError:
>>> cache.set('num', 1)
>>> cache.incr('num')
2
>>> cache.incr('num', 10)
12
>>> cache.decr('num')
11
>>> cache.decr('num', 5)
6
注意:incr()/ decr()方法不保证是原子的。在那些支持原子增量/减量的后端(最值得注意的是,内存缓存的后端)上,增量和减量操作将是原子的。但是,如果后端本身不提供增量/减量操作,则将使用两步检索/更新来实现。
cache.close()
close()如果由缓存后端实现,则可以关闭与缓存的连接。
>>> cache.close()
注意:对于不实现close方法的缓存,它是无操作的。
缓存键前缀
如果要在服务器之间或生产环境与开发环境之间共享缓存实例,则一台服务器缓存的数据可能会被另一台服务器使用。如果服务器之间的缓存数据格式不同,则可能导致某些很难诊断的问题。
为防止这种情况,Django提供了为服务器使用的所有缓存键添加前缀的功能。保存或检索特定的缓存键后,Django将自动为缓存键添加KEY_PREFIX缓存设置的值 。
通过确保每个Django实例都有一个不同的 KEY_PREFIX,您可以确保缓存值不会发生冲突。
缓存版本
更改使用缓存值的运行代码时,可能需要清除所有现有的缓存值。最简单的方法是刷新整个缓存,但这会导致仍然有效且有用的缓存值丢失。
Django提供了一种更好的方法来定位各个缓存值。Django的缓存框架具有系统范围的版本标识符,该标识符使用VERSION缓存设置指定。此设置的值会自动与缓存前缀和用户提供的缓存键组合在一起,以获取最终的缓存键。
默认情况下,任何密钥请求都将自动包含站点默认的缓存密钥版本。但是,原始缓存功能都包含一个version参数,因此您可以指定要设置或获取的特定缓存键版本。例如:
>>> # Set version 2 of a cache key
>>> cache.set('my_key', 'hello world!', version=2)
>>> # Get the default version (assuming version=1)
>>> cache.get('my_key')
None
>>> # Get version 2 of the same key
>>> cache.get('my_key', version=2)
'hello world!'
可以使用incr_version()和decr_version()方法对特定键的版本进行递增和递减。这样可以使特定的键更改为新版本,而其他键不受影响。继续前面的示例:
>>> # Increment the version of 'my_key'
>>> cache.incr_version('my_key')
>>> # The default version still isn't available
>>> cache.get('my_key')
None
# Version 2 isn't available, either
>>> cache.get('my_key', version=2)
None
>>> # But version 3 *is* available
>>> cache.get('my_key', version=3)
'hello world!'
缓存键转换
如前两节所述,用户不能完全原样使用用户提供的缓存密钥,而是将其与缓存前缀和密钥版本结合使用以提供最终的缓存密钥。默认情况下,这三个部分使用冒号连接起来以生成最终字符串:
def make_key(key, key_prefix, version):
return '%s:%s:%s' % (key_prefix, version, key)
如果要以不同的方式组合各部分,或对最终键进行其他处理(例如,获取键部分的哈希摘要),则可以提供自定义键功能。
的KEY_FUNCTION高速缓存设置指定匹配的原型的功能的虚线路径 make_key()的上方。如果提供,将使用此自定义按键功能代替默认的按键组合功能。
缓存键警告
Memcached是最常用的生产缓存后端,它不允许长度超过250个字符或包含空格或控制字符的缓存键,并且使用此类键会导致异常。为了鼓励缓存可移植的代码并最大程度地减少令人不快的意外,django.core.cache.backends.base.CacheKeyWarning如果使用的键会导致memcached错误,则其他内置的缓存后端会发出警告()。
如果您使用的生产后端可以接受更广泛的键范围(自定义后端或非内存缓存的内置后端之一),并且希望在没有警告的情况下使用更大范围的键,则可以CacheKeyWarning在此代码中保持静音management您之一的模块 INSTALLED_APPS:
import warnings
from django.core.cache import CacheKeyWarning
warnings.simplefilter("ignore", CacheKeyWarning)
如果您想为内置后端之一提供自定义密钥验证逻辑,则可以对其进行子类化,仅覆盖validate_key 方法,并按照说明使用自定义缓存后端。例如,要为locmem后端执行此操作,请将以下代码放在模块中:
from django.core.cache.backends.locmem import LocMemCache
class CustomLocMemCache(LocMemCache):
def validate_key(self, key):
"""Custom validation, raising exceptions or warnings as needed."""
...
…并在设置的BACKEND一部分中使用指向该类的虚线Python路径 CACHES。
下游缓存
到目前为止,本文档的重点是缓存您自己的数据。但是另一种类型的缓存也与Web开发有关:由“下游”缓存执行的缓存。这些系统甚至可以在请求到达您的网站之前为用户缓存页面。
以下是下游缓存的一些示例:
- 您的ISP可能会缓存某些页面,因此,如果您从https://example.com/请求一个页面 ,您的ISP将向您发送该页面,而无需直接访问example.com。example.com的维护者不了解这种缓存。ISP位于example.com和您的Web浏览器之间,透明地处理所有缓存。
- 您的Django网站可能位于代理缓存(例如Squid Web代理缓存(http://www.squid-cache.org/))之后,该缓存可以缓存页面以提高性能。在这种情况下,每个请求首先将由代理处理,并且仅在需要时才将其传递给您的应用程序。
- 您的Web浏览器也缓存页面。如果网页发出适当的标题,您的浏览器将使用本地缓存的副本来对该页面的后续请求,甚至无需再次联系该网页以查看其是否已更改。
下游缓存可以极大地提高效率,但是却存在危险:许多网页的内容基于身份验证和许多其他变量而有所不同,并且仅基于URL盲目保存页面的缓存系统可能会将不正确或敏感的数据暴露给后续这些页面的访问者。
例如,如果您使用Web电子邮件系统,则“收件箱”页面的内容取决于登录的用户。如果ISP盲目缓存了您的站点,则第一个通过该ISP登录的用户将拥有其用户。特定的收件箱页面已缓存,以供该站点的后续访问者使用。那不酷。
幸运的是,HTTP提供了解决此问题的方法。存在许多HTTP标头,以指示下游缓存根据指定的变量来区分其缓存内容,并告知缓存机制不要缓存特定页面。我们将在以下各节中介绍其中的一些标题。
使用Vary标题
的Vary报头定义哪些请求头的高速缓存机制建立其缓存键时应该考虑到。例如,如果网页的内容取决于用户的语言偏好,则称该页面“随语言而异”。
默认情况下,Django的缓存系统使用请求的标准URL(例如,)创建其缓存密钥 "https://www.example.com/stories/2005/?order_by=author"。这意味着对该URL的每个请求都将使用相同的缓存版本,而不管用户代理差异(例如Cookie或语言偏好设置)如何。但是,如果此页面根据请求标头(例如Cookie,语言或用户代理)的不同而产生不同的内容,则需要使用Vary 标头来告诉缓存机制页面输出取决于那些的东西。
要在Django中执行此操作,请使用方便的 django.views.decorators.vary.vary_on_headers()视图装饰器,如下所示:
from django.views.decorators.vary import vary_on_headers
@vary_on_headers('User-Agent')
def my_view(request):
...
在这种情况下,缓存机制(例如Django自己的缓存中间件)将为每个唯一的用户代理缓存页面的单独版本。
使用vary_on_headers装饰器而不是手动设置Vary标头(使用类似的东西 )的好处是,装饰器将添加到 标头(可能已经存在),而不是从头开始设置它并可能覆盖其中的任何内容。response['Vary'] = 'user-agent'Vary
您可以将多个标头传递给vary_on_headers():
@vary_on_headers('User-Agent', 'Cookie')
def my_view(request):
...
这告诉下游缓存在这两者上有所不同,这意味着用户代理和cookie的每种组合都将获得自己的缓存值。例如,具有用户代理Mozilla和cookie值foo=bar的请求将被认为不同于具有用户代理Mozilla和cookie值 的请求foo=ham。
因为在cookie上进行更改非常普遍,所以有一个 django.views.decorators.vary.vary_on_cookie()装饰器。这两个视图是等效的:
@vary_on_cookie
def my_view(request):
...
@vary_on_headers('Cookie')
def my_view(request):
...
您传递给的标头vary_on_headers不区分大小写; "User-Agent"和一样"user-agent"。
您也可以django.utils.cache.patch_vary_headers()直接使用辅助功能。此函数设置或添加到。例如:Vary header
from django.shortcuts import render
from django.utils.cache import patch_vary_headers
def my_view(request):
...
response = render(request, 'template_name', context)
patch_vary_headers(response, ['Cookie'])
return response
patch_vary_headers将HttpResponse实例作为第一个参数,并将不区分大小写的标头名称的列表/元组作为第二个参数。
有关Vary标头的更多信息,请参见 官方Vary规格。
控制缓存:使用其他头文件
缓存的其他问题是数据的私密性以及应在级联缓存中存储数据的位置的问题。
用户通常面临两种缓存:他们自己的浏览器缓存(私有缓存)和提供者的缓存(公共缓存)。公共缓存由多个用户使用,并由其他人控制。这就给敏感数据带来了麻烦,例如,您不希望将银行帐号存储在公共缓存中。因此,Web应用程序需要一种方法来告诉缓存哪些数据是私有数据,哪些是公共数据。
解决方案是指示页面的缓存应为“专用”。要在Django中执行此操作,请使用cache_control()视图装饰器。例:
from django.views.decorators.cache import cache_control
@cache_control(private=True)
def my_view(request):
...
该装饰器负责在后台发送适当的HTTP标头。
请注意,缓存控制设置“专用”和“公用”是互斥的。装饰器确保如果应设置为“ private”,则删除“ public”指令(反之亦然)。这两个伪指令的示例用法是提供私有条目和公共条目的博客网站。公共条目可以缓存在任何共享缓存中。以下代码使用 patch_cache_control()手动方式修改缓存控制标头(由cache_control()装饰器内部调用 ):
from django.views.decorators.cache import patch_cache_control
from django.views.decorators.vary import vary_on_cookie
@vary_on_cookie
def list_blog_entries_view(request):
if request.user.is_anonymous:
response = render_only_public_entries()
patch_cache_control(response, public=True)
else:
response = render_private_and_public_entries(request.user)
patch_cache_control(response, private=True)
return response
您还可以通过其他方式控制下游缓存(请参见 RFC 7234,了解有关HTTP缓存的详细信息)。例如,即使您不使用Django的服务器端缓存框架,您仍然可以使用以下命令告诉客户端将视图缓存一定的时间:最大年龄 指令:
from django.views.decorators.cache import cache_control
@cache_control(max_age=3600)
def my_view(request):
...
(如果你做使用缓存中间件,它已经设置max-age与值CACHE_MIDDLEWARE_SECONDS的设置。在这种情况下,自定义max_age从 cache_control()装饰将优先考虑,并且头部值将被正确地合并。)
任何有效的Cache-Control响应指令在中均有效cache_control()。这里还有更多示例:
- no_transform=True
- must_revalidate=True
- stale_while_revalidate=num_seconds
可以在IANA注册中心中找到已知指令的完整列表 (请注意,并非所有指令都适用于响应)。
如果要使用标头来完全禁用缓存,请 never_cache()使用视图装饰器来添加标头,以确保浏览器或其他缓存不会缓存响应。例:
from django.views.decorators.cache import never_cache
@never_cache
def myview(request):
...
MIDDLEWARE
如果您使用缓存中间件,则将每一半放在MIDDLEWARE设置中的正确位置上很重要。这是因为缓存中间件需要知道通过哪些头来更改缓存存储。中间件总是尽可能在Vary响应头中添加一些内容。
UpdateCacheMiddleware在响应阶段运行,中间件以相反的顺序运行,因此列表顶部的项目在响应阶段最后运行。因此,您需要确保它UpdateCacheMiddleware 出现在任何其他可能向Vary 标头添加内容的中间件之前。以下中间件模块可以这样做:
- SessionMiddleware 添加 Cookie
- GZipMiddleware 添加 Accept-Encoding
- LocaleMiddleware 添加 Accept-Language
FetchFromCacheMiddleware另一方面,在请求阶段运行,其中中间件首先应用,因此列表顶部的项目在请求阶段首先运行。该FetchFromCacheMiddleware还需要经过其他中间件更新运行Vary头,所以 FetchFromCacheMiddleware必须在后的是这样做的任何项目。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号