Storm学习笔记
Storm结构概述
主流的三大分布式计算系统:Hadoop,Spark和Storm
由于Google没有开源Google分布式计算模型的技术实现,所以其他互联网公司只能根据Google三篇技术论文中的相关原理,搭建自己的分布式计算系统。
Yahoo的工程师Doug Cutting和Mike Cafarella在2005年合作开发了分布式计算系统Hadoop。后来,Hadoop被贡献给了Apache基金会,成为了Apache基金会的开源项目。Doug Cutting也成为Apache基金会的主席,主持Hadoop的开发工作。
Hadoop采用MapReduce分布式计算框架,并根据GFS开发了HDFS分布式文件系统,根据BigTable开发了HBase数据存储系统。尽管和Google内部使用的分布式计算系统原理相同,但是Hadoop在运算速度上依然达不到Google论文中的标准。
不过,Hadoop的开源特性使其成为分布式计算系统的事实上的国际标准。Yahoo,Facebook,Amazon以及国内的百度,阿里巴巴等众多互联网公司都以Hadoop为基础搭建自己的分布式计算系统。
Spark也是Apache基金会的开源项目,它由加州大学伯克利分校的实验室开发,是另外一种重要的分布式计算系统。它在Hadoop的基础上进行了一些架构上的改良。Spark与Hadoop最大的不同点在于,Hadoop使用硬盘来存储数据,而Spark使用内存来存储数据,因此Spark可以提供超过Hadoop100倍的运算速度。但是,由于内存断电后会丢失数据,Spark不能用于处理需要长期保存的数据。
Storm是Twitter主推的分布式计算系统,它由BackType团队开发,是Apache基金会的孵化项目。它在Hadoop的基础上提供了实时运算的特性,可以实时的处理大数据流。不同于Hadoop和Spark,Storm不进行数据的收集和存储工作,它直接通过网络实时的接受数据并且实时的处理数据,然后直接通过网络实时的传回结果。
Hadoop,Spark和Storm是目前最重要的三大分布式计算系统,Hadoop常用于离线的复杂的大数据处理,Spark常用于离线的快速的大数据处理,而Storm常用于在线的实时的大数据处理。
Storm是什么?
Storm是一个可扩展的、具备数据容错系统的分布式实时计算框架。可以方便的在一个计算机集群中编写可扩展复杂的实时计算,保证每个消息都会得到处理,在一个小集群中,每秒可以处理数以百万计的消息(经测试,每个节点每秒可以处理100万个数据元组)。
实时流计算是什么?
随着信息量个爆发式膨胀,人们对信息时效性的需求也越来越高,数据的价值随着时间的流逝而降低,所以事件出现后,必须尽快对他们进行处理,最好事件发生一个便立刻对其进行处理,而不是将其缓存起来成一批处理。
在数据持久性建模不满足现状的情况下,人们急需对数据流的瞬时建模或者计算处理。例如:商用的搜索引擎(Google、Bing等),通常在用户查询响应中提供结构化的Web查询结果,同时也插入基于流量的点击付费模式的文本广告。为了在页面上的最佳位置展示最相应的广告,可以通过一些算法来动态估算给定上下文中一个广告被点击的可能性(上下文可能包括用户偏好、地理位置、历史查询、历史点击等信息)。一个主搜索引擎可能每秒钟处理成千上万次查询,每个页面都可能会包含多个广告。为了及时处理用户反馈,需要一个低延迟、可扩展、高可靠的处理引擎。对于这种需求,可以采用MapReduce来处理实时数据流,但是尽管MapReduce做了实时性的改进,也很难真正稳定的满足应用需求(这是因为Hadoop MapReduce框架为批处理做了高度优化,典型的是通过调度批量任务来操作静态数据,任务不是常驻服务,数据也不是实时流入)。而数据流计算的典型范式之一是不确定数据速率的时间流流入系统,系统处理能力必须与事件流量匹配。
实时计算处理流程
处理互联网上的海量数据(日志流):
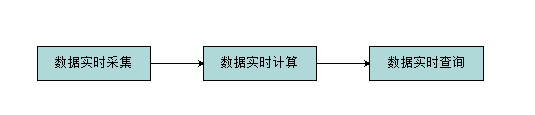
数据实时采集:
完整的收集到所有日志数据,为实时应用提供实时数据;响应时间上药保证实时性、低延迟(满足每秒数百MB的日志数据采集和传输需求);配置简单,部署容易;系统稳定可靠。(数据采集工具有:scribe、kafka、Flume、TimeTunnel、Chukwa等)
数据实时计算:
在流数据不断变化的运动过程中实时地进行分析捕捉到可能对用户有用的信息,并把结果发送出去。在蒸锅过程中数据分析处理系统是主动的,而用户处于被动接收的状态(传统数据操作,首先将数据采集并存储到DBMS中,然后通过查询和DBMS进行交互,得到用户想要的答案,这个过程,用户是主动地,DBMS系统是被动的)。
实时计算的需求---适应流式数据、不间断查询、系统稳定可靠、可扩展性好、可维护性好。
数据实时查询:
全内存---直接提供数据读取服务,定期转存到磁盘或数据库进行持久化;
半内存---使用Redis、Memcache、MongoDB、BerkeleyDB等内存数据库提供数据实时查询服务,由这些系统进行持久化操作。
全磁盘---使用HBase等以分布式文件系统(HDFS)为基础的NoSQL数据库,对于Key-Value内存引擎,关键是设计好Key的分布。
Storm设计思想
Storm中有对流(Stream)的抽象,在建立事件流时,Storm把流中的事件抽象为Tuple(元组)——所以在Storm中,流是一个不间断的、无界的连续Tuple。
Storm中认为每个流都有一个Stream源(原始元组的源头)——所以他将这个源头抽象为Spout(Spout可能连接Twitter API并不断发出推文Tweet,也可能从某个队列中不断读取队列元素并装配为Tuple发射)。
将流的中间状态转换抽象为Bolt(Bolt可以消费任意数量的输入流,只要将流方向导向该Blot,同时它也可以发送新的流给其他Blot使用,这样,只要打开特定的Spout,再将Spout中流出的Tuple导向特定的Bolt,由Bolt处理导入的流后在导向其他Bolt或者目的地)。
关系图如下:假设Spout是一个水龙头,并且每个水龙头里流出的水是不同的,想获得哪种水就要打开对应的水龙头,然后把水通过管道
导向一个处理器Bolt,处理后继续使用管道导向另一个处理器,直到处理完成后存入容器。
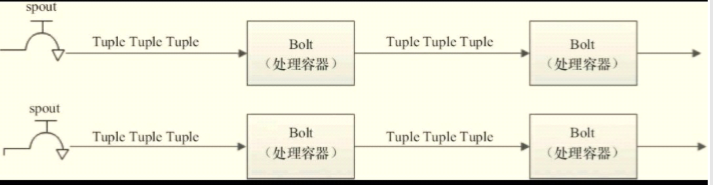
还有其他结构,多对一:

拓扑结构:

Storm将上图抽象为Topology(拓扑),这是Storm中最高层次的一个抽象概念,提交拓扑到Storm集群执行,一个拓扑就是一个流转换图,每个节点是一个Spout或者Blot,边表示Bolt订阅了哪些流。
storm学习笔记(二)——Storm组件详解之Tuple、Spout
Storm的核心概念包括:Stream、Spout、Bolt、Tuple、Task、Worker、Stream Grouping、Topology
Stream是被处理的数据,Spout是数据源,Bolt是处理数据的容器,Tuple是数据单元,Task是运行Spout和Bolt中的线程,Worker是运行这些线程的进程,Stream Grouping规定了Bolt接受何种类型的数据最为输入,Topology是由Stream Grouping连接起来的Spout和Bolt节点网络。
Tuple元组
结构
Tuple是Storm的主要数据结构,是Storm中使用的最基本单元、数据模型和元组。
Tuple就是一个值列表,Tuple中的值可以是任何类型的,动态类型的Tuple的fields可以不用声明。
默认情况下,Storm中的Tuple支持私有类型、字符串、字节数组等作为他的字段值。
Tuple的字段默认类型有:integer、float、double、long、short、string、byte、binary(byte[ ])。
数据结构如下图:可以理解成一个键值对类型的数据结构。
生命周期
下段java代码展示了Spout(消息源)接口发出Tuple(消息)的整个过程,源码如下:
public interface ISpout extends Serializable{
void open(Map conf,TopologyContext context,SpoutOutputCollector collector);
void nextTuple();
void ack(Object msgId);
void fail(Object msgId);
void close();
}
首先,Storm调用Spout(消息源)的nextTuple方法来获取下一个Tuple,Spout通过Open方法的参数提供的SpoutOutputCollector将新Tuple发射到其中一个输出消息流。发射Tuple时,Spout提供一个message-id,通过这个ID来追踪该Tuple。然后,Storm跟踪该Tuple的树形结构是否成功创建,从根据message-id调用Spout中的ack函数,以确认Tuple是否被完全处理。如果Tuple超时,则调用Spout的fail方法。由此看出,同一个Tuple不管是acked还是failed都是由创建它的Spout发出并维护的,所以Storm会利用内部的Acker机制保证每个Tuple被可靠地处理。最后,在任务完成后,Spout调用Close方法结束Tuple的使命。
Spout数据源
结构
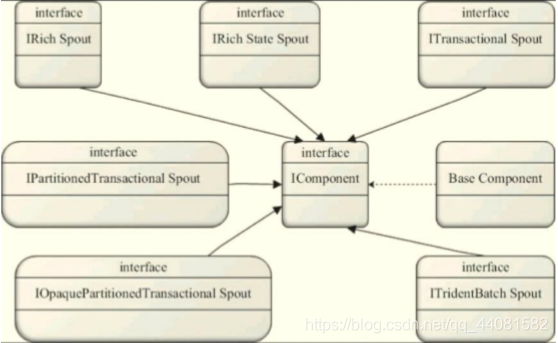
数据源(消息源)Spout是Storm的Topology中的消息生产者(Tuple的创造者),最源头的接口是IComponent,如下图所示,几个Spout接口都继承自IComponent。
Spout从外部获取数据后,向Topology中发出的Tuple可以是可靠的,也可以是不可靠的。一个可靠的消息源可以重新发射一个Tuple(如果该Tuple没有被Storm成功处理),但是一个不可靠的消息源,Spout一旦发出一个Tuple就把它彻底“遗忘”,也就不可能再发了。
Spout可以发射多个流。要达到这样的效果,使用OutputFieldsDeclarer.declareStream来定义多个流(定义多个Stream),然后使用SpoutOutputCollector来发射指定的流。
Spout的最顶层抽象是ISpout接口,在通常情况下(Shell和事务型的除外),实现一个Spout,可以直接实现接口IRichSpout,如果不想写多余代码,可以直接继承BaseRichSpout。
开发spout组件
下段代码是开发Spout组件的一个简单的实例:创建普通Java工程,导入storm依赖包到lib文件夹下,buildpath之后即可。
package storm;
import java.util.Map;
import java.util.Random;
import java.util.stream.Collector;
import backtype.storm.spout.SpoutOutputCollector;
import backtype.storm.task.TopologyContext;
import backtype.storm.topology.OutputFieldsDeclarer;
import backtype.storm.topology.base.BaseRichSpout;
import backtype.storm.tuple.Fields;
import backtype.storm.tuple.Values;
/*
* 用于产生数据源
* 本例中 数据源是不断生成的一个1-100内的随机数
*/
public class NumberSpout extends BaseRichSpout {
private SpoutOutputCollector collector;
/*
* 这是Spout类中最重要的一个方法。用于发射Tuple
*
*/
@Override
public void nextTuple() {
// TODO Auto-generated method stub
while(true){
int randomNum = new Random().nextInt(100);
//Values可以理解为是Tuple的值,是一个集合类型,值可以是一个,也可以是多个
Values value = new Values(randomNum);
//emit方法用于发射元组
collector.emit(value);
try {
Thread.sleep(500);
} catch (InterruptedException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
}
/*
* 当一个Task被初始化时会调用此open方法。
* 一般都会在此方法中初始化发送Tuple的对象SpoutOutputCollector和配置对象TopologyContext。
*
*/
@Override
public void open(Map conf, TopologyContext context, SpoutOutputCollector collector) {
// 对collector进行初始化,因为nextTuple()方法利用collector发射元组
this.collector = collector;
}
/*
* 此方法用于声名当前spout的Tuple发送流,
* 流的定义是通过OutputFieldsDeclare.declareStream方法完成的
* 其中的参数包括了发送的域Fields。
*/
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
// Fields可以理解为时Tuple的键
declarer.declare(new Fields("number"));
}
}
代码说明:从100以内的整数中随机产生一个数作为Tuple的值,然后通过_collector发送到Topology。Spout的最重要方法是nextTuple。nextTuple方法发射一个新的元组到Topology,如果没有新元组发射,则直接返回。
注意:任务Spout的nextTuple方法都不要实现成阻塞的,因为Storm是在相同的线程中调用Spout的方法。
此外,Spout的另外两个重要方法是ack和fail方法,当Spout发射的元组被拓扑成功处理时,调用ack方法;当处理失败时,调用fail方法。ack和fail方法仅可被可靠的Spout调用。
Storm学习笔记(三)——Storm组件详解之Bolt、Topology
Bolt消息处理者
Bolt在Storm中是一个被动的角色,它把元组作为输入,然后产生新的元组作为输出。Bolt可以执行过滤、函数操作、合并、写数据库等操作(还可以简单地传递消息流,复杂的消息流往往需要很多步骤,因此需要很多Bolt来处理)。
生命周期
首先,客户端创建Bolt,然后将其序列化为拓扑,并提交给集群中的主机。
之后,集群启动Worker进程,反序列化Bolt,调用prepare方法开始处理元组。
接下来,Bolt处理Tuple,Bolt处理一个输入Tuple,发射0个或者多个Tuple,然后调用ack通知Storm自己已经处理过这个Tuple了(Storm提供了一个IBasicBolt自动调用ack)。Bolt类接收由Spout或者其他上游Bolt类发来的Tuple,对其进行处理。

在创建Bolt对象时,通过构造方法初始化成员变量,当Bolt被提交到集群时,这些成员变量也会被序列化,所以通过反序列化,可以获取到这些成员变量。
开发Bolt组件
开发Bolt组件的一个简单的例子:
package storm;
import java.util.Map;
import java.util.stream.Collector;
import org.apache.storm.netty.util.internal.SystemPropertyUtil;
import backtype.storm.task.OutputCollector;
import backtype.storm.task.TopologyContext;
import backtype.storm.topology.OutputFieldsDeclarer;
import backtype.storm.topology.base.BaseRichBolt;
import backtype.storm.tuple.Fields;
import backtype.storm.tuple.Tuple;
/*
* 此消息处理者用于接收Spout发来的Tuple,并将Tuple的值做打印输出
*/
public class NumberBolt extends BaseRichBolt{
private OutputCollector collector;
/*
* Bolt的主要方法是execute,它以一个Tuple作为输入
* Bolt使用OutputCollector来发射Tuple
* Bolt必须为它处理的每一个Tuple调用OutputCollector的ack方法
* 以通知Storm该Tuple被处理完成了,从而通知该Tuple的发射者Spout
*/
@Override
public void execute(Tuple input) {
int randomNum = input.getIntegerByField("number");
System.out.println(randomNum);
}
/*
* prepare方法和Spout中的open方法类似,为Bolt提供了OutputCollector,用来从Bolt中发送Tuple。
* OutputCollector是线程安全的,并且随时都可以调用它
* 在Bolt中,Tuple的发送可以再Prepare、execute、cleanup等方法中进行
* 但是一般都是在execute中进行
*/
@Override
public void prepare(Map stormConf, TopologyContext context, OutputCollector collector) {
this.collector = collector;
}
/*
* 用于声名当前Bolt发送的Tuple中包含的字段,和Spout中的类似
* Bolt可以发射多条消息流,使用OutputFieldsDeclarer.declareStream方法来定义流
* 之后使用OutputCollector.emit来选择要发射的流
*/
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declareStream("moreThan", new Fields("It"));
declarer.declareStream("lessThan", new Fields("It"));
}
}
Topology拓扑
Storm的Topology是指类似于网络拓扑图的一种虚拟结构。Storm拓扑类似于MapReduce任务,一个关键的区别是MapReduce任务运行一段时间后最终会完成,而Storm拓扑一直运行(知道杀死它)。
结构
一个拓扑是由Spout和Bolt组成的图,Spout和Bolt之间通过刘分组连接起来,见下图。
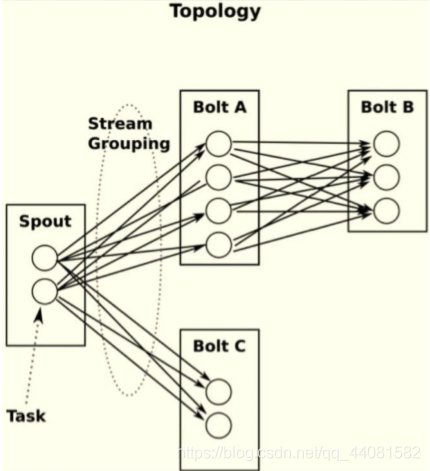
Topology是由Spout、Bolt、数据载体Tuple等构成的一定规则的网络拓扑图。Storm提供了TopologyBuilder类来创建Topology。
运行模式
Topology运行模式有两种:
本地模式,分布式模式
这两种模式的接口区别很大,使用场景不同
示例
package storm;
import backtype.storm.Config;
import backtype.storm.LocalCluster;
import backtype.storm.generated.StormTopology;
import backtype.storm.topology.TopologyBuilder;
public class NumberTopology {
public static void main(String[] args){
//用于设置Topology相关的环境参数
Config config = new Config();
//Storm的运行有两种模式:本地模式和集群模式
//本地模式:LocalCluster
//集群模式:StormSubmitter submitter = new StormSubmitter();
LocalCluster cluster = new LocalCluster();
//实例化Spout、bolt和Topologybuilder
TopologyBuilder builder = new TopologyBuilder();
NumberSpout numberSpout = new NumberSpout();
NumberBolt numberBolt = new NumberBolt();
builder.setSpout("number_spout", numberSpout);
builder.setBolt("number_bolt", numberBolt).shuffleGrouping("number_spout");
StormTopology topology = builder.createTopology();
cluster.submitTopology("topology", config, topology);
}
}
Storm学习笔记(四)——单词统计
Storm实现单词统计的流程:
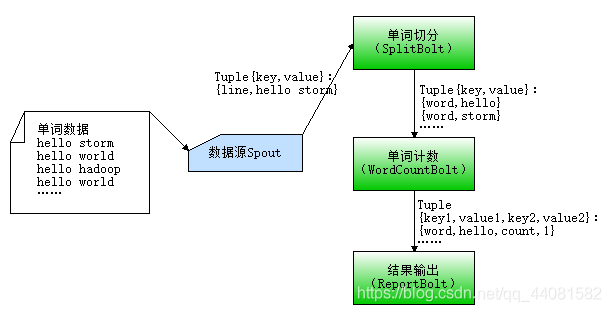
步骤:
1.创建普通java工程
2.将Storm依赖包导入
3.编写各组件代码
WordCountSpout代码:
public class WordCountSpout extends BaseRichSpout{
private String[] data = new String[]{
"hello Storm",
"hello world",
"hello hadoop",
"hello world"
};
private SpoutOutputCollector collector;
private static int i = 0;
@Override
public void nextTuple() {
Values line = new Values(data[i]);
collector.emit(line);
//防止越界
if(i == data.length-1){
i = 0;
}else{
i++;
}
}
@Override
public void open(Map conf, TopologyContext context, SpoutOutputCollector collector) {
this.collector = collector;
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("line"));
}
//确认Tuple成功的方法
@Override
public void ack(Object msgId) {
super.ack(msgId);
}
//处理tuple传输失败的方法
//父类中的fail方法,会根据tuple-id,重新发动tuple
@Override
public void fail(Object msgId) {
super.fail(msgId);
}
}
SplitBolt代码:
public class SplitBolt extends BaseRichBolt{
private OutputCollector collector;
@Override
public void execute(Tuple input) {
try {
//获取行数据
String line = input.getStringByField("line");
String[] words = line.split(" ");
for(String word : words){
collector.emit(input,new Values(word));
}
//通过ack确认机制来确保数据传输的可靠性
//若对可靠性要求不高,也可以不写
collector.ack(input);
} catch (Exception e) {
// 通知tuple接收失败
collector.fail(input);
}
}
@Override
public void prepare(Map StormConf, TopologyContext context, OutputCollector collector) {
this.collector = collector;
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("word"));
}
}
WordCountBolt代码:
public class WordCountBolt extends BaseRichBolt{
private OutputCollector collector;
private Map<String,Integer> map = new HashMap<>();
@Override
public void execute(Tuple input) {
String word = input.getStringByField("word");
//单词频率统计
if(map.containsKey(word)){
map.put(word, map.get(word)+1);
}else{
map.put(word, 1);
}
collector.emit(new Values(word,map.get(word)));
collector.ack(input);
}
@Override
public void prepare(Map StormConf, TopologyContext context, OutputCollector collector) {
this.collector = collector;
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("word","count"));
}
}
ReportBolt代码:
public class ReportBolt extends BaseRichBolt{
private OutputCollector collector;
@Override
public void execute(Tuple input) {
String word = input.getStringByField("word");
int count = input.getIntegerByField("count");
//打印输出
System.out.println("单词:"+ word +"的当前的频率为" + count);
collector.ack(input);
}
@Override
public void prepare(Map StormConf, TopologyContext context, OutputCollector collector) {
this.collector = collector;
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
}
}
WordCountTopology代码:
public class WordCountTopology {
public static void main(String[] args) {
Config config = new Config();
TopologyBuilder builder = new TopologyBuilder();
WordCountSpout spout = new WordCountSpout();
SplitBolt splitBolt = new SplitBolt();
WordCountBolt wordCountBolt = new WordCountBolt();
ReportBolt reportBolt = new ReportBolt();
// setSpout(id,bean,线程并发度)
// setNumTasks()如果不设定,默认就是一个线程处理一个task,即task的并发度=线程并发度
builder.setSpout("WordCount_Spout", spout, 2);
builder.setBolt("Split_Bolt", splitBolt).shuffleGrouping("WordCount_Spout");
// fieldsGrouping的作用是保证 让指定field字段的相同的 value值,发往同一个Bolt
// 底层的实现方式是:Value.hashCode % NumBolt
builder.setBolt("WordCount_Bolt", wordCountBolt).fieldsGrouping("Split_Bolt", new Fields("word"));
// globalGrouping相当于是一个数据流汇总
builder.setBolt("Report_Bolt", reportBolt).globalGrouping("WordCount_Bolt");
StormTopology topology = builder.createTopology();
LocalCluster cluster = new LocalCluster();
cluster.submitTopology("wordcount_topology", config, topology);
// 3s后停止Topology
try {
Thread.sleep(3000);
cluster.killTopology("wordcount_topology");
cluster.shutdown();
} catch (InterruptedException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
}
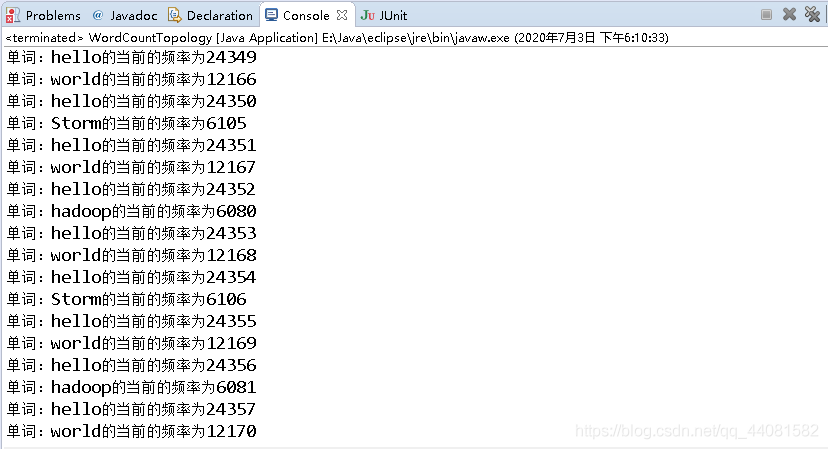
结果如下图:
Storm学习笔记(五)——Storm的并发机制
Storm数据流分组
词频统计的Topology的并发可以如下图所示:
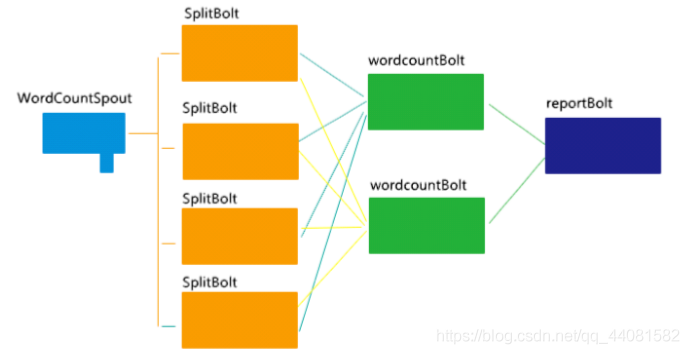
WordCountSpout---->SplitBolt 过程:发送的是一行一行的数据,任何一个SplitBolt都可进行处理。
SplitBolt--->WordCountBolt 过程:发送的是一个一个的单词,同一个单词必须发给同一个WordCountBolt
WordCountBolt--->ReportBolt 过程:发送的是单词和频次,收到后打印输出即可
Stream消息流
Stream是Storm中最关键的抽象,是一个没有边界的Tuple序列,这些Tuple以分布式的方式并行地常见和处理。定义消息流主要是定义消息流中的Tuple。每个消息流在定义时都会分配一个ID,因为单向消息流很普遍,OutputFieldsDeclarer定义了一些方法可以定义一个流而不指定其ID。在这种情况下,该流有一个默认的ID。
Stream Grouping消息流组
定义Topology的其中一步是定义每个Bolt接受何种流作为输入。Stream Grouping(消息流组)就是用来定义一个流如何分配Tuple到Bolt。Storm包括6种流分组类型。
随机分组(Shuffle Grouping):随机分发元组到Bolt,并保证每个Bolt获得相等数据量的元组。可以实现一个近似的负载均衡的效果。
字段分组(Fields Grouping):根据指定字段分割数据流并分组。例如,根据“user-id”字段,具有该字段的Tuple被分到相同的Bolt中,不同的“user-id”值则会被分配到不同的Bolt中。(注:之前的单词统计就用到了这种分组,从而能够确保相同单膝被发往一个Bolt去处理。)
全复制分组(All Grouping):对于每个Tuple来说,所有的Bolt都会受到,所有的Tuple被复制到Bolt的所有任务上,需要小心使用该分组。
全局分组(Global Grouping):全部的流都分配到唯一的一个Bolt上,就是分配给ID最小的Task。(注:这种模型,对应的Bolt所设定的并发度没有意义,因为最后一个Bolt在进行处理。)
不分组(None Grouping):不分组的含义是,流不关心到底谁会接收它的Tuple。目前无分组等效于随机分组。
直接分组(Direct Grouping):只是一个特别的分组类型。元组产生者决定元组由哪个元组消费者任务接收。
本地或随机分组(Local or shuffle Grouping):和随机分组类似,但是,会将Tuple分发给同一个Worker内的Bolt Task,其他情况下采用随机分组方式。这种方式可以减少网络传输,从而提高Topology的性能。
Storm并发机制
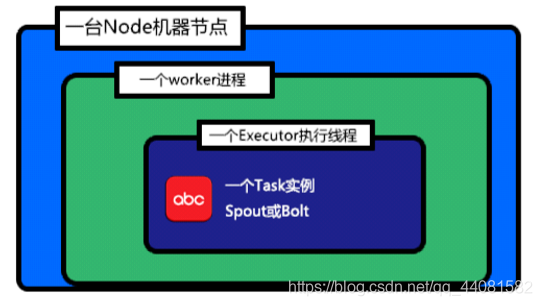
关于Storm集群中的并发度的四个概念:
Node(服务器):指Storm集群中的一个服务器,会执行Topology的一部分运算,一个Storm集群中包含一个或者多个Node。
Worker(JVM进程):指一个Node上相互独立运行的JVM进程,每个Node可以配置运行一个或者多个worker。一个Topology会分配到一个或者多个worker上运行。
Task(bolt/spout实例):指spout和bolt的实例,他们的nextTuple()和execute()方法会被executors线程调用执行。
Executor(执行线程):指一个worker的JVM中运行的java线程。Storm默认会给每个executor分配一个task。此外,多个task也可以指派给同一个executor来执行,但需要明确指示。
Storm的并发度
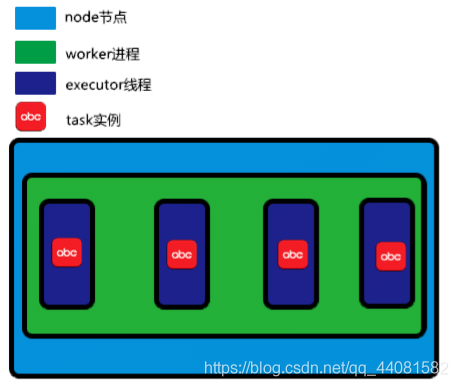
Storm的默认并发度设置值为1。(一台服务器Node---为Topology分配一个worker---每个executor执行一个task)如图。
此时唯一个并发机制出现在线程级。单机模式下增加并发的方式可以体现在分配更多的worker和executor给Topology,增加worker进程如图。
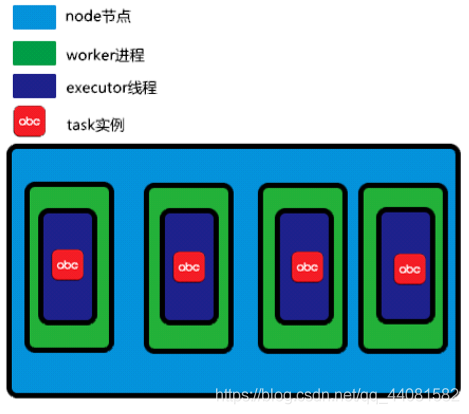
增加executor线程如图:
当然,单机模式下,增加worker的数量并不会有任何提升速度的效果。
增加Storm的并发度的代码
增加worker:可以通过API和修改配置两种方式修改分配给Topology的worker数量
Config config = new Config();
config.setNumWorkers(2);
增加Executor:
builder.setSpout(spout_id,spout,2);//将spout的executor并发度设为2,如果不设置task并发度,则task的并发度也为2,因为默认是一个线程执行一个task
builder.setBolt(bolt_id,bolt,executor_num);
增加Task:
builder.setSpout(...).setNumTasks(2);
builder.setBolt(...).setNumTasks(task_num);

 浙公网安备 33010602011771号
浙公网安备 33010602011771号