biancheng-Python机器学习算法
http://c.biancheng.net/ml_alg/
Python机器学习
就当下而言,Python 无疑是机器学习领域最火的编程语言,这得益于 Python 对科学计算的强大支持。因此,本套教程中关于机器学习算法的代码均采用 Python 机器学习库 sklearn 编写。
机器学习的最主要的一项工作就是“训练模型”,训练模型的过程就是机器学习算法实现的过程,这里的算法和我们经常提及的算法有些区别,比如插入排序、归并排序等,它们的结果都是“计算出来的”,只要确定输入,就可以给定一个值,而机器学习的算法是“猜”出来的,既然是猜,那么就会有对有错,机器学习会根据猜的“结果”,不断的优化模型,从而得出正确率最高的“结果”。
机器学习的学习形式可以分为两大类:
- 有监督学习
- 无监督学习
每一类学习形式都对应着相应的算法,比如线性回归算法、KNN 分类算法、朴素贝叶斯分类算法、支持向量机算法等等,并且这些算法都有与其相适用的场景,本套教程将对上述算法的原理和应用做详细的介绍。
教程特点
机器学习算法,毫无疑问是比较难学的,它不仅拥有望而生畏的数学公式,还有晦涩难懂的逻辑思路。本教程尽量以通俗易懂的方式讲解所有算法,由于教程中会涉及较多的数学知识,我们在保证知识严谨性的基础上,尽量绕开繁琐、难懂的数学定义,让您更容易理解,从而尽快实现机器学习算法入门。
本套机器学习算法教程推崇“学以致用”,使用机器学习算法解决实际问题才是学习者的最终目的,所以教程中还会涉及如何将机器学习算法应有到实际场景中。除此之外,通过对本教程的学习,您还可以熟练掌握 Python 机器学习算法库 sklearn 的使用。
机器学习&深度学习
人工智能(Artificial Intelligence)是计算机科学技术的一个分支,指的是通过机器和计算机来模拟人类智力活动的过程。人工智能自 1950 年诞生以来,理论和技术日益成熟,应用领域也不断扩大,涉足了领域包括机器人、语言识别、图像识别、自然语言处理等。人工智能并不是人的智能,而是让机器像人一样思考,甚至于超过人类。
如今人工智能已经走进了千家万户,对于普通大众来说,它已经是一个耳熟能详的名字。但还有两个词语您可能没有听说过,它就是机器学习和深度学习。
对于从事计算机领域的工作者或者技术爱好者来说,机器学习与深度学习并不陌生,然而对于初学者而言就可能傻傻分不清楚,那么它们之前到底存在什么关系呢?其实它们之间是包含与被包含关系,下面展示了它们之间的关系图,如下所示: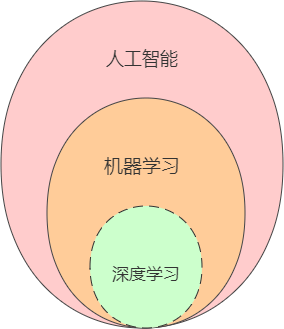
从图中可以看出,机器学习是人工智能的一部分,而深度学习又是机器学习的一部分。人工智能的范围最为广泛,机器学习是人工智能的核心分支,也是当前发展最迅猛的一部分,而关于深度学习,它之前也属于“机器学习”的一个分支,其主要研究对象是神经网络算法,因想要区别于“机器学习”,它重新起了一个高大上的名字。下面以最具有代表性的机器学习来做进一步介绍。
单从定义上来说,机器学习是一种功能、方法,或者更具体的说是一种算法,它能够赋予机器进行学习的能力,从而使机器完成一些通过编程无法直接实现的功能。但从具体的实践意义来说,其实机器学习是利用大量数据训练出一个最优模型,然后再利用此模型预测出其他数据的一种方法。比如要识别猫、狗照片就要拿它们各自的照片提炼出相应的特征(比如耳朵、脸型、鼻子等),从而训练出一个具有预测能力的模型。
学习形式分类
机器学习是人工智能的主要表现形式,其学习形式主要分为:有监督学习、无监督学习、半监督学习等,如果你之前没有接触过机器学习,那么对于“监督”一词会不明就里,其实你可以把这个词理解为习题的“参考答案”,专业术语叫做“标记”。比如有监督学习就是有参考答案的学习,而无监就是无参考答案。
1) 有监督学习
有监督学习(supervised learning),需要你事先需要准备好要输入数据(训练样本)与真实的输出结果(参考答案),然后通过计算机的学习得到一个预测模型,再用已知的模型去预测未知的样本,这种方法被称为有监督学习。这也是是最常见的机器学习方法。简单来说,就像你已经知道了试卷的标准答案,然后再去考试,相比没有答案再去考试准确率会更高,也更容易。
2) 无监督学习
理解了有监督学习,那么无监督学习理解起来也变的容易。所谓无监督学习(unsupervised learning)就是在没有“参考答案”的前提下,计算机仅根据样本的特征或相关性,就能实现从样本数据中训练出相应的预测模型。
除了上述两种学习形式外,还有半监督学习和强化学习,它不在本教程的讨论范畴之内,有兴趣的可以自己研究一下。
预测结果分类
根据预测结果的类型,我们可以对上述学习形式做具体的问题划分,这样就可以具体到实际的应用场景中,比如有监督学习可以划分为:回归问题和分类问题。如果预测结果是离散的,通常为分类问题,而为连续的,则是回归问题。
1) 回归&分类
连续和离散是统计学中的一种概念,全称为“连续变量”和“离散变量”。比如身高,从 1.2m 到 1.78m 这个长高的过程就是连续的,身高只随着年龄的变化一点点的长高。那么什么是“离散变量”呢?比如超市每天的销售额,这类数据就是离散的,因为数据不是固定,可能多也可能少。关于什么是“回归”和“分类”在后续内容中会逐步讲解。
2) 聚类
无监督学习是一种没有“参考答案”的学习形式,它通过在样本之间的比较、计算来实现最终预测输出,比如聚类问题,那什么是“聚类”?其实可以用一个成语表述“物以类聚,人以群分”,将相似的样本聚合在一起后,然后进行分析。关于聚类也会在后续内容中逐步讲解。
在学习机器学习技术的过程中,我们会遇到很多专业术语或者生僻词汇,这些名词大多数来自于数学或者统计学领域,比如模型、数据集、样本、熵,以及假设函数、损失函数等,这些属词汇于基本的常识,但是如果你第一次接触的话,也会感觉到些许惊慌。在下一节我们将介绍机器学习的常用术语。
机器学习常用术语
机器学习术语
1) 模型
模型这一词语将会贯穿整个教程的始末,它是机器学习中的核心概念。你可以把它看做一个“魔法盒”,你向它许愿(输入数据),它就会帮你实现愿望(输出预测结果)。整个机器学习的过程都将围绕模型展开,训练出一个最优质的“魔法盒”,它可以尽量精准的实现你许的“愿望”,这就是机器学习的目标。
2) 数据集
数据集,从字面意思很容易理解,它表示一个承载数据的集合,如果说“模型”是“魔法盒”的话,那么数据集就是负责给它充能的“能量电池”,简单地说,如果缺少了数据集,那么模型就没有存在的意义了。数据集可划分为“训练集”和“测试集”,它们分别在机器学习的“训练阶段”和“预测输出阶段”起着重要的作用。
3) 样本&特征
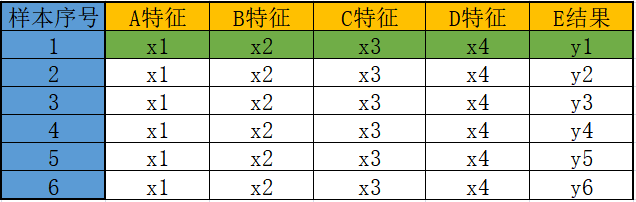
样本指的是数据集中的数据,一条数据被称为“一个样本”,通常情况下,样本会包含多个特征值用来描述数据,比如现在有一组描述人形态的数据“180 70 25”如果单看数据你会非常茫然,但是用“特征”描述后就会变得容易理解,如下所示:
由上图可知数据集的构成是“一行一样本,一列一特征”。特征值也可以理解为数据的相关性,每一列的数据都与这一列的特征值相关。
4) 向量
任何一门算法都会涉及到许多数学上的术语或者公式。在本教程写作的过程中也会涉及到很多数学公式,以及专业的术语,在这里我们先对常用的基本术语做一下简单讲解。
第一个常用术语就是“向量”,向量是机器学习的关键术语。向量在线性代数中有着严格的定义。向量也称欧几里得向量、几何向量、矢量,指具有大小和方向的量。您可以形象地把它的理解为带箭头的线段。箭头所指:代表向量的方向;线段长度:代表向量的大小。与向量对应的量叫做数量(物理学中称标量),数量只有大小,没有方向。
在机器学习中,模型算法的运算均基于线性代数运算法则,比如行列式、矩阵运算、线性方程等等。其实对于这些运算法则学习起来并不难,它们都有着一定运算规则,只需套用即可,因此你也不必彷徨,可参考向量运算法则。向量的计算可采用 NmuPy 来实现,如下所示:
- import numpy as np
- #构建向量数组
- a=np.array([-1,2])
- b=np.array([3,-1])
- #加法
- a_b=a+b
- #数乘
- a2=a*2
- b3=b*(-3)
- #减法
- b_a=a-b
- print(a_b,a2,b3,b_a)
输出结果:
[2 1] [-2 4] [-9 3] [-4 3]
简而言之,数据集中的每一个样本都是一条具有向量形式的数据。
5) 矩阵
矩阵也是一个常用的数学术语,你可以把矩阵看成由向量组成的二维数组,数据集就是以二维矩阵的形式存储数据的,你可以把它形象的理解为电子表格“一行一样本,一列一特征”表现形式如下:
如果用二维矩阵的表示的话,其格式如下所示:

假设函数&损失函数
机器学习在构建模型的过程中会应用大量的数学函数,正因为如此很多初学者对此产生畏惧,那么它们真会有这么可怕吗?其实我认为至少没有你想的那么可怕。从编程角度来看,这些函数就相当于模块中内置好的方法,只需要调用相应的方法就可以达成想要的目的。而要说难点,首先你要理解你的应用场景,然后根据实际的场景去调用相应的方法,这才是你更应该关注的问题。
假设函数和损失函数是机器学习中的两个概念,它并非某个模块下的函数方法,而是我们根据实际应用场景确定的一种函数形式,就像你解决数学的应用题目一样,根据题意写出解决问题的方程组。下面分别来看一下它们的含义。
1) 假设函数
假设函数(Hypothesis Function)可表述为y=f(x)其中 x 表示输入数据,而 y 表示输出的预测结果,而这个结果需要不断的优化才会达到预期的结果,否则会与实际值偏差较大。
2) 损失函数
损失函数(Loss Function)又叫目标函数,简写为 L(x),这里的 x 是假设函数得出的预测结果“y”,如果 L(x) 的返回值越大就表示预测结果与实际偏差越大,越小则证明预测值越来越“逼近”真实值,这才是机器学习最终的目的。因此损失函数就像一个度量尺,让你知道“假设函数”预测结果的优劣,从而做出相应的优化策略。
3) 优化方法
“优化方法”可以理解为假设函数和损失函数之间的沟通桥梁。通过 L(x) 可以得知假设函数输出的预测结果与实际值的偏差值,当该值较大时就需要对其做出相应的调整,这个调整的过程叫做“参数优化”,而如何实现优化呢?这也是机器学习过程中的难点。其实为了解决这一问题,数学家们早就给出了相应的解决方案,比如梯度下降、牛顿方与拟牛顿法、共轭梯度法等等。因此我们要做的就是理解并掌握“科学巨人”留下的理论、方法。
对于优化方法的选择,我们要根据具体的应用场景来选择应用哪一种最合适,因为每一种方法都有自己的优劣势,所以只有合适的才是最好的。
上述函数的关系图如下所示:

拟合&过拟合&欠拟合
拟合是机器学习中的重要概念,也可以说,机器学习的研究对象就是让模型能更好的拟合数据,那到底如何理解“拟合”这个词呢?
1)拟合
形象地说,“拟合”就是把平面坐标系中一系列散落的点,用一条光滑的曲线连接起来,因此拟合也被称为“曲线拟合”。拟合的曲线一般用函数进行表示,但是由于拟合曲线会存在许多种连接方式,因此就会出现多种拟合函数。通过研究、比较确定一条最佳的“曲线”也是机器学习中一个重要的任务。如下图所示,展示一条拟合曲线(蓝色曲线):
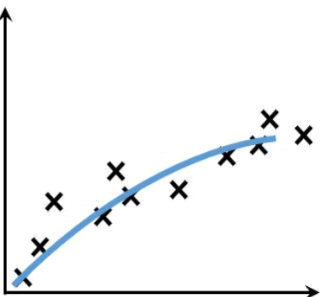
提示:很多和数学相关的编程语言都内置计算拟合曲线的函数,比如 MATLAB 、Python Scipy 等,在后续内容中还会介绍。
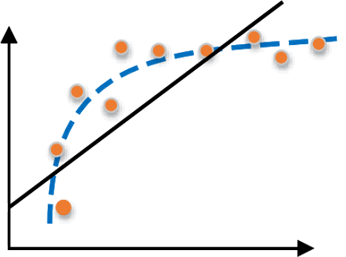
2) 过拟合
过拟合(overfitting)与是机器学习模型训练过程中经常遇到的问题,所谓过拟合,通俗来讲就是模型的泛化能力较差,也就是过拟合的模型在训练样本中表现优越,但是在验证数据以及测试数据集中表现不佳。
举一个简单的例子,比如你训练一个识别狗狗照片的模型,如果你只用金毛犬的照片训练,那么该模型就只吸纳了金毛狗的相关特征,此时让训练好的模型识别一只“泰迪犬”,那么结果可想而知,该模型会认为“泰迪”不是一条狗。如下图所示:
过拟合问题在机器学习中经常原道,主要是因为训练时样本过少,特征值过多导致的,后续还会详细介绍。
3) 欠拟合
欠拟合(underfitting)恰好与过拟合相反,它指的是“曲线”不能很好的“拟合”数据。在训练和测试阶段,欠拟合模型表现均较差,无法输出理想的预测结果。如下图所示: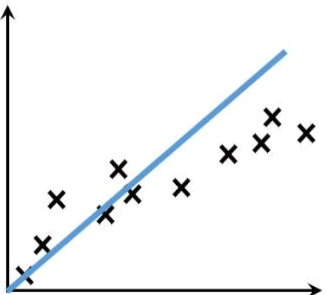
造成欠拟合的主要原因是由于没有选择好合适的特征值,比如使用一次函数(y=kx+b)去拟合具有对数特征的散落点(y=log2x),示例图如下所示:
欠拟合和过拟合是机器学习中会遇到的问题,这两种情况都不是我期望看到的,因此要避免,关于如何处理类似问题,在后续内容中还会陆续讲解,本节只需要大家熟悉并理解常见的机器学习术语和一些概念即可。
Python机器学习环境搭建
Python 官方网站提供了完善的资料文档和版本下载支持(https://www.python.org/)。
NumPy
NumPy(https://numpy.org/)属于 Python 的第三方扩展程序包,它是 Python 科学计算的基础库,提供了多维数组处理、线性代数、傅里叶变换、随机数生成等非常有用的数学工具。
NumPy 的安装方式非常简单,在安装好 Python 的基础上使用包管理器来安装,命令如下所示:
pip install numpy
Pandas 安装非常简单,同样可以使用 pip 包管理器完成安装,如下所示:
pip install pandas
Scikit-Learn
最后介绍机器学习中的重要角色 Scikit-Leran(官网:https://scikit-learn.org/stable/),它是一个基于 Python 语言的机器学习算法库。Scikit-Learn 主要用 Python 语言开发,建立在 NumPy、Scipy 与 Matplotlib 之上,它提供了大量机器学习算法接口(API),因此你可以把它看做一本“百科全书”
线性回归算法详解
线性回归是什么
线性回归主要用来解决回归问题,也就是预测连续值的问题。而能满足这样要求的数学模型被称为“回归模型”。最简单的线性回归模型是我们所熟知的一次函数(即 y=kx+b),这种线性函数描述了两个变量之间的关系,其函数图像是一条连续的直线。如下图蓝色直线: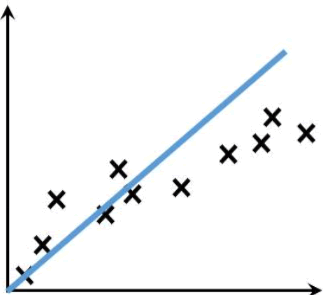
实现预测的流程
下面通过一个具体实例讲解线性回归预测的具体流程。
1) 数据采集
任何模型的训练都离不开数据,因此收集数据构建数据集是必不可少的环节。比如现在要预测一套房子的售价,那么你必须先要收集周围房屋的售价,这样才能确保你预测的价格不会过高,或过低。如下表所示: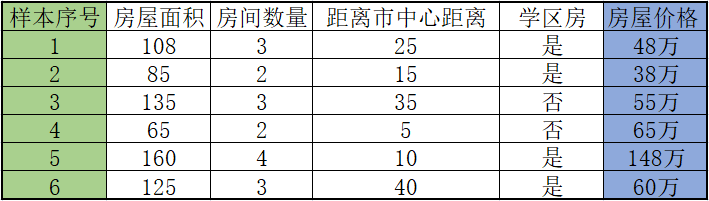
当然上述样本数量远远不足,如果想要更加准确的预测就要收集更多的数据,至少保证 100 条样本。表格中的最后一栏是“房屋售价”,这是“有监督学习”的典型特点,被称为“标签”也就是我们所说的“参考答案”。表格中的面积、数量、距离市中心距离(km),以及是否是学区房,这些都是影响最终预测结果的相关因素,我们称之为“特征”,也叫“属性”。
你可能会认为影响房屋售价的不止这些因素,没错,不过采集数据是一个很繁琐的过程,因此一般情况下,我们只选择与预测结果密切相关的重要“特征”。
2) 构建线性回归模型
有了数据以后,下一步要做的就是构建线性回归模型,这也是最为重要的一步,这个过程会涉及到一些数学知识,至于如何构建模型,下一节会做详细介绍。
构建完模型,我们需要对其进行训练,训练的过程就是将表格中的数据以矩阵的形式输入到模型中,模型则通过数学统计方法计算房屋价格与各个特征之间关联关系,也就是“权值参数”。训练完成之后,您就可以对自己的房屋价格进行预测了。首先将数据按照“特征值”依次填好,并输入到模型中,最后模型会输出一个合理的预测结果。示意图如下所示: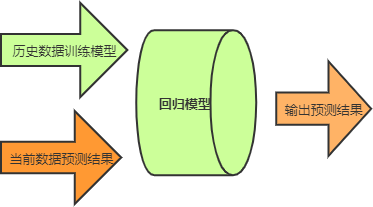
从上图可知,回归模型承担着非常重要的作用,关于如何构建回归模型,在下一节将做详细介绍。
构建线性回归模型
一次函数
一次函数就是最简单的“线性模型”,其直线方程表达式为y = kx + b,其中 k 表示斜率,b 表示截距,x 为自变量,y 表示因变量。下面展示了 y = 2x + 3 的函数图像: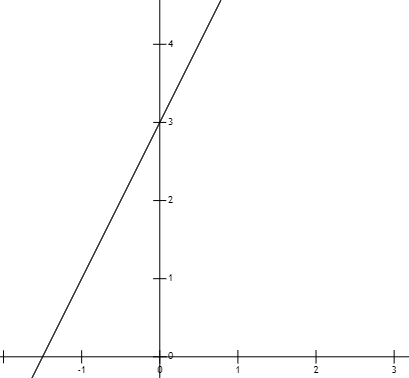
函数中斜率 k 与 截距 b 控制着“直线”的“旋转”与“平移”。如果斜率 k 逐渐减小,则“直线”会向着“顺时针”方向旋转,为 k= 0 的时候与 x 轴平行。截距 b 控制“直接”的上下平移,b 为正数则向上平移,b 为负数则表示向下平移。
线性回归:损失函数和假设函数
假设函数
通过前面知识的学习,我们知道假设函数是用来预测结果的。前面讲述时为了让大家更容易理解“线性回归”,我们以“直线方程”进行了类比讲解,然而线性方程并不等同于“直线方程”,线性方程描绘的是多维空间内的一条“直线”,并且每一个样本都会以向量数组的形式输入到函数中,因此假设函数也会发生一些许变化,函数表达式如下所示:
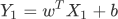
乍一看你可能蒙圈了,记住不用紧张。其实它和 Y=wX + b 是类似的,只不过我们这个标量公式换成了向量的形式。如果你已经学习了 《NumPy 教程》,那么这个公司很好理解,Y1仍然代表预测结果, X1表示数据样本, b表示用来调整预测结果的“偏差度量值”,而wT表示权值系数的转置。矩阵相乘法是一个求两个向量点积的过程,也就是按位相乘,然后求和,如下所示: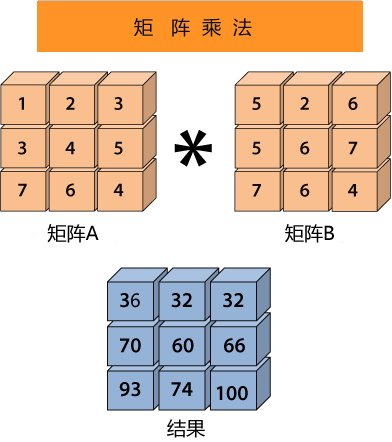
矩阵 A 的每一行分别与矩阵 B 的每一列相乘,比如 1*5+2*5+3*7 =36 、1*2+2*6+3*6=32、1*6+2*7+3*4=32,即可得出结果的第一行数据。
转置操作的目的是为了保证第一个矩阵的列数(column)和第二个矩阵的行数(row)相同,只有这样才能做矩阵乘法运算。
您也可以将假设函数写成关于 x 的函述表达式,如下所示:
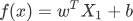
损失函数
我们知道,在线性回归模型中数据样本散落在线性方程的周围,如下图所示: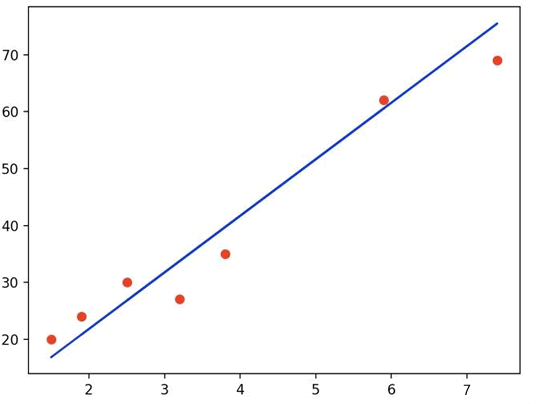
损失函数就像一个衡量尺,这个函数的返回值越大就表示预测结果与真实值偏差越大。其实计算单个样本的误差值非常简单,只需用预测值减去真实值即可:
单样本误差值 = Y1 - Y
但是上述方法只适用于二维平面的直线方程。在线性方程中,要更加复杂、严谨一些,因此我们采用数学中的“均方误差”公式来计算单样本误差: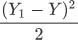
公式是求“距离”因此要使用平方来消除负数,分母 2 代表样本的数量,这样就求得单样本误差值。当我们知道了单样本误差,那么总样本误差就非常好计算了:
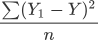
最后,将假设函数带入上述损失函数就会得到一个关于 w 与 b 的损失函数(loss),如下所示:

在机器学习中使用损失函数的目的,是为了使用“优化方法”来求得最小的损失值,这样才能使预测值最逼近真实值。
梯度下降求极值
导数
导数也叫导函数,或者微商,它是微积分中的重要基础概念,从物理学角度来看,导数是研究物体某一时刻的瞬时速度,比如你开车从家 8:00 出发到公司上班,9:00 到到达公司,这一个小时内的平均车速是 80km/h,而途中8:15:30这一时刻的速度,就被称为瞬时速度,此刻的速度可能是 100km/h,也可能是 20km/h。而从几何意义上来讲,你可以把它理解为该函数曲线在一点上的切线斜率。
导数有其严格的数学定义,它巧妙的利用了极限的思想,也就是无限趋近于 0 的思想。设函数 y=f(x) 在点 x0 的某个邻域内有定义,当自变量 x 在 x0 处有增量 Δx,(x0+Δx)也在该邻域内时,相应地函数取得增量 Δy=f(x0+Δx)-f(x0);如果 Δy 与 Δx 之比当 Δx→0 时极限存在,则称函数 y=f(x) 在点 x0 处可导,并称这个极限为函数 y=f(x) 在点 x0 处的导数记做 :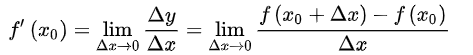
那么什么样的函数具有导数呢?是不是所有的函数都有导数?当然不是,而且函数也不一定在其所有点上都有导数。如果某函数在某一点导数存在,则称其在这一点可导,否则称为不可导。可导的函数一定连续;不连续的函数一定不可导。
导数的发明者是伟大的科学家牛顿与布莱尼茨,它是微积分的一个重要的支柱。在机器学习中,我们只需会用前辈科学家们留下来的知识就行了,比如熟悉常见的导函数公式,以下列举了常用的导数公式:
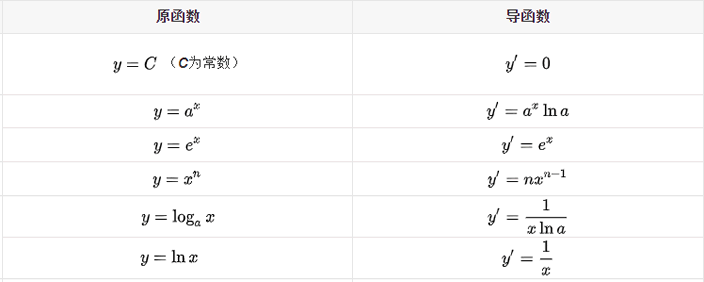
关于导数的的推断过程详细可参见百度百科。
偏导数
偏导数虽然和导数只有一字之差,但是却相差甚多,从它们的定义来看,偏导数是指对含有两个自变量的函数中的一个自变量求导,也就是说偏导数要求函数必须具备两个自变量。比如拿 z=f(x,y) 举例,如果只有自变量x变化,而自变量y固定(即看作常量),这时它就是x的一元函数,这函数对x的导数,就称为二元函数z对于x的偏导数,记做 fx(x,y) 。
有如下函数 z = x2 + 3xy + y2,分别求 z 对于 x 、y 的偏导数。如下所示:
fx(x,y) = 2x + 3y # 关于 x 的偏导数 fy(x,y) = 3x + 2y # 关于 y 的偏导数
当求 x 的偏导时就要把 y 当做常数项来对待,而当求 y 的偏导时就要把 x 当做常数项对待。关于偏导数还会涉及到高阶偏,如果感兴趣的话可以点击了解一下。
梯度下降
梯度下降是机器学习中常用的一种优化方法,主要用来解决求极小值的问题,某个函数在某点的梯度指向该函数取得最大值的方向,那么它的反反向自然就是取得最小值的方向。在解决线性回归和 Logistic(逻辑) 回归问题时,梯度下降方法有着广泛的应用。
梯度是微积分学的术语,它本质上是一个向量,表示函数在某一点处的方向导数上沿着特定的方向取得最大值,即函数在该点处沿着该方向变化最快,变化率最大。梯度下降法的计算过程就是沿梯度方向求解极小值,当然你也可以沿梯度上升的方向求解极大值。
那么如何能够更好的理解“梯度下降”呢?如果不考虑其他外在因素,其实你可以把它想象成“下山”的场景,如何从一个高山上以最快的时间走到山脚下呢?其实很简单,以你所在的当前位置为基准,寻找该位置最陡峭的地方,然后沿着此方向向下走,并且每走一段距离,都要寻找当前位置“最陡峭的地方”,反复采用上述方法,最终就能以最快的时间抵达山脚下。
在这个下山的过程中,“寻找所处位置最陡峭的地方,并沿此位置向下走”最为关键,如果把这个做法对应到函数中,就是找到“给定点的梯度”而梯度的方向就是函数值变化最快的方向。
从上述描述中,你可能感觉到平淡无奇,其实每一个词语都蕴含着数学知识,比如“以当前所在位置为基准,找到最陡峭的地方”从数学角度来讲就是找到所在点的“切线”方向,也就是对这点“求导”,然后循着切线轨迹点反复使用此方法,就可以到达极小值点。
在《线性回归:损失函数和假设函数》一节,我们讲解了线性回归的损失函数,而梯度下降作为一种优化方法,其目的是要使得损失值最小。因此“梯度下降”就需要控制损失函数的w和b参数来找到最小值。比如控制 w 就会得到如下方法:
w新=w旧 - 学习率 * 损失值
通过梯度下降计算极小值时,需要对损失函数的w求偏导求得,这个偏导也就是“梯度”,通过损失值来调节w,不断缩小损失值直到最小,这也正是梯度下降的得名来由。
sklearn应用线性回归算法
Scikit-learn 简称 sklearn 是基于 Python 语言实现的机器学习算法库,它包含了常用的机器学习算法,比如回归、分类、聚类、支持向量机、随机森林等等。同时,它使用 NumPy 库进行高效的科学计算,比如线性代数、矩阵等等。
Scikit-learn 是 GitHub 上最受欢迎的机器学习库之一,其最新版本是 2020 年12 月发布的 scikit-learn 0.24.1。
提示:Scikit-learn 官方网站:https://scikit-learn.org/stable/
Scikit-learn 涵盖了常用的机器学习算法,而且还在不断的添加完善,对于本教程所涉及的机器学习算法它都做了良好的 API 封装,以供直接调用。你可以根据不同的模型进行针对性的选择。下面介绍 sklearn 中常用的算法库:
- ·linear_model:线性模型算法族库,包含了线性回归算法,以及 Logistic 回归算法,它们都是基于线性模型。
- .naiv_bayes:朴素贝叶斯模型算法库。
- .tree:决策树模型算法库。
- .svm:支持向量机模型算法库。
- .neural_network:神经网络模型算法库。
- .neightbors:最近邻算法模型库。
实现线性回归算法
下面我们是基于 sklearn 实现线性回归算法,大概可以分为三步,首先从 sklearn 库中导入线性模型中的线性回归算法,如下所示:
from sklearn import linear_model
其次训练线性回归模型。使用 fit() 喂入训练数据,如下所示:
model = linear_model.LinearRegression() model.fit(x, y)
最后一步就是对训练好的模型进行预测。调用 predict() 预测输出结果, “x_”为输入测试数据,如下所示:
model.predict(x_)
你可能会感觉 so easy,其实没错,使用 sklearn 算法库实现线性回归就是这么简单,不过上述代码只是一个基本的框架,要想真正的把这台“机器”跑起来,我们就得给它喂入数据,因此准备数据集是必不可少的环节。数据集的整理也是一门专业的知识,会涉及到数据的收集、清洗,也就是预处理的过程,比如均值移除、归一化等操作,如果熟悉 Pandas 的话应该了解, 因此这里不做重点讲解。
1) 准备数据
下面我们手动生成一个数据集,如下所示:
- # 使用numpy准备数据集
- import numpy as np
- # 准备自变量x,-3到3的区间均分间隔30份数
- x = np.linspace(3,6.40)
- #准备因变量y,这一个关于x的假设函数
- y = 3 * x + 2
2) 实现算法
- #使用matplotlib绘制图像,使用numpy准备数据集
- import matplotlib.pyplot as plt
- import numpy as np
- from sklearn import linear_model
- #准备自变量x,生成数据集,3到6的区间均分间隔30份数
- x = np.linspace(3,6.40)
- #准备因变量y,这一个关于x的假设函数
- y = 3 * x + 2
- #由于fit 需要传入二维矩阵数据,因此需要处理x,y的数据格式,将每个样本信息单独作为矩阵的一行
- x=[[i] for i in x]
- y=[[i] for i in y]
- # 构建线性回归模型
- model=linear_model.LinearRegression()
- # 训练模型,"喂入"数据
- model.fit(x,y)
- # 准备测试数据 x_,这里准备了三组,如下:
- x_=[[4],[5],[6]]
- # 打印预测结果
- y_=model.predict(x_)
- print(y_)
- #查看w和b的
- print("w值为:",model.coef_)
- print("b截距值为:",model.intercept_)
- #数据集绘制,散点图,图像满足函假设函数图像
- plt.scatter(x,y)
- plt.show()
通过线性回归得到的线性函数图像,如下所示: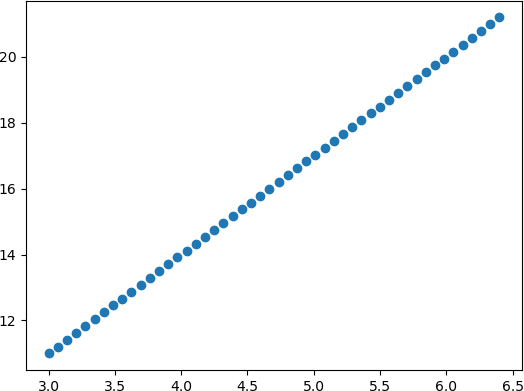
打印输出结果如下所示:
测试集输出结果: [[14.] [17.] [20.]] w值为: [[3.]] b截距值为: [2.]
Logistic回归算法(分类问题)
下面对上述过程做简单总结:
- 类别标签:“可回收”与“不可回收”。
- 模型训练:以小明为主体,把他所接受的知识、经验做为模型训练的参照。
- 预测:投放垃圾的结果,预测分类是否正确。并输出预测结果。
分类问题是当前机器学习的研究热点,它被广泛应用到各个领域,比图像识别、垃圾邮件处理、预测天气、疾病诊断等等。“分类问题”的预测结果是离散的,它比线性回归要更加复杂,那么我们应该从何处着手处理“分类问题”呢,这就引出了本节要讲的 Logistic 回归分类算法。
Logistic回归算法
也许乍一看算法名字,你会认为它是用来解决“回归问题”的算法,但其实它是针对“分类问题”的算法。
Logistic 回归算法,又叫做逻辑回归算法,或者 LR 算法(Logistic Regression)。分类问题同样也可以基于“线性模型”构建。“线性模型”最大的特点就是“直来直去”不会打弯,而我们知道,分类问题的预测结果是“离散的”,即对输出数据的类别做判断。比如将类别预设条件分为“0”类和“1”类(或者“是”或者“否”)那么图像只会在 “0”和“1”之间上下起伏,如下图所示:
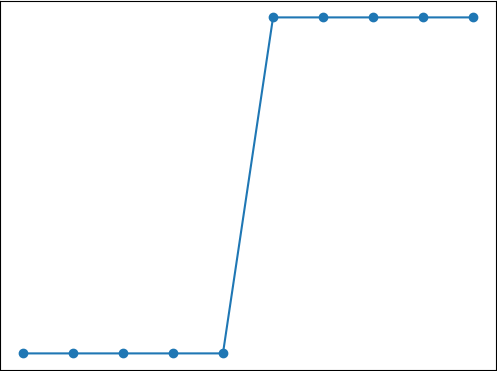
此时你就可能会有很多疑问,线性回归函数不可能“拟合”上述图像。没错,所以接下来我们要学习另一个线性函数 Logistic 函数。
数学解析Logistic回归算法
分类数据表示形式
1) 向量形式
在机器学习中,向量形式是应用最多的形式,使用向量中的元素按顺序代表“类别”。现在有以下三个类别分别是 a/b/c,此时就可以使用 [1,2,3] 来分别代表上述三类,预测结果为哪一类,向量中的元素就对应哪个元素,比如当预测结果为 c 类的时候,则输出以下数据:
[0,0,3]
2) 数字形式
数字形式是一种最简单的分类方式,我们可以用 0 代表“负类”(即 x < 0时的取值),而用“1”代表正类(即 x>0 时的取值),那么当预测结果输出“1”就代表正类,而预测结果输出“0”代表“负类”。当然这里选择的数字只是形式,你可以选择任意其他数字,不过按照约定俗成,我们一般采用 “1”代表正类,而 “-1”或者“0”代表“负类”。 如果用代码的表示数字形式的中心思想,如下所示:
- #以 0 为节将其分开
- if (logistic函数输出的是连续值>0):
- return 1
- else:
- return 0
3) 概率形式
在有些实际场景中,我们无法准确的判断某个“样本”属于哪个类别,此时我们就可以使用“概率”的形式来判断“样本”属于哪个类别的几率大,比如对某个“样本”有如下预测结果:
[0.8,0.1,0.1]
从上述输出结果不难看出,该样本属于 a 类的概率最大,因此我们可以认定该样本从属于 a 类。
Logistic函数数学解析
1) 假设函数
经过上一节的学习得知 Logistic 函数能够很好的拟合“离散数据”,因此可以把它看做“假设函数”,但是还需要稍稍的改变一下形式,如下所示: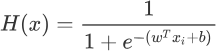
上述公式和 Logistic 函数基本一致,只不过我们它换成了关于x的表达式,并将幂指数x换成了 “线性函数”表达式。H(x) 的函数图像呈现 S 形分布,从而能够预测出离散的输出结果。
2) 损失函数
LogIstic 回归算法的损失函数有点复杂,也许你会感动莫名其妙,损失函数的表达式如下: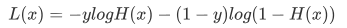
想要理解损失函数,我们需要继续分析假设函数。我们知道假设函数的值域是从 (0,1) 之间的数值,而这个数据区间恰好与概率值区间不谋而合。如果我们把预测结果看做概率,则可以得到另外一种写法的损失函数:
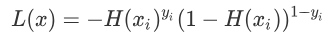
上述函数是根据概率设计出来的,它由 H(xi)yi 和 (1-H(xi))1-yi 两部分组成,由于 y 值的取值只会是 0 或者 1,所以每次只有一个部分输出值,因此可以达到分类的目的。
我们知道 y 输出值概率值只能为 0 或者 1,因此上述函数只会有一部分输出数值。即当 y=1 时候,1-y 就等于 0,因此上述表达式的第二部分,也就是 (1-H(xi))1-yi 的值为 1,相乘后并不会对函数值产生影响。当 y = 0 时,同理。
综上所述:当 y=1 时,如果预测正确,预测值则无限接近 1,也即 H(xi)yi 的值为 1,损失值则为 -1;如果预测错误,H(xi)yi 的值为 0,损失值也为 0。预测错误的损失值确实比预测正确的损失值大(0 > -1),满足要求。
虽然上述函数能够表达预测值和实际值之间的偏差,但它有一个缺点就是不能使用梯度下降等优化方法。因此,在机器学习中要通过取对数的方法来解决此问题,这样就得到了最开始的损失函数。如下所示:
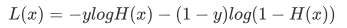
3) 优化方法
如果将 Logistic 函数的输出记做 z 可得如下公式:
z = w0x0+w1x1<+....+wnxn
采用向量的形式可以写为:
z=wTx
它表示将这两个数值向量对应元素相乘然后全部加起来即得到 z 值。其中的 x 是分类器的输入数据,向量 w (最佳参数)会使得分类器尽可能的精确。为了寻找该最佳参数就需要用到优化方法,下面我们简单介绍梯度上升优化方法。
梯度上升优化方法
梯度上升与梯度下降同属于优化方法,它们两者有着异曲同工之妙,梯度下降求的是“最小值”,而梯度上升求的是“最大值”。梯度上升基于的思想是:要找到某函数的最大值,最好的发放是沿着该函数的梯度方向寻找,如果把梯度记为▽,那么关于 f(x,y) 有以下表达式: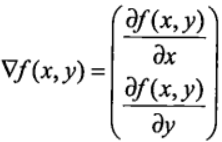
上述公式是其实并不难理解,该函数分别对 x 与 y 求的偏导数,其中关于 x 的偏导数表示沿着 x 的方向移动,而关于 y 的偏导数一个表示沿 y 的方向移。其中,函数f(x,y) 必须要在待计算的点上可导。在梯度上升的过程中,梯度总是指向函数值增长最快的方向,我们可以把每移动一次的“步长”记为α 。用向量来表示的话,其公式如下:
w1= w + α▽wf(w)
在梯度上升的过程中,上述公式将一直被迭代执行,直至达到某个停止条件为止,比如达到某个指定的值或者某个被允许的误差范围之内。
sklearn应用Logistic回归算法
什么是范数?
范数又称为“正则项”,它是机器学习中会经常遇到的术语,它表示了一种运算方式,“范数”的种类有很多,不过常见的范数主要分为两种:L1 和 L2。下面我们来分别认识一下它们。
1) L1范数
L1 范数非常容易理解,它表示向量中每个元素绝对值的和,根据定义,L1 范数的计算分两步,首先逐个求得元素的绝对值,然后相加求和即可。下面给出了 L1 范数正则化定义的数学表达式,如下所示:
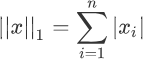
注意:此时两个绝度值符号,是符合范数规定的,两个绝对值符号表示范数。
2) L2范数
L2 范数出现的频率更高,表示向量中每个元素的平方和的平方根。根据定义,L2 范数的计算分三步,首先逐个求得元素的平方,然后相加求和,最后求和的平方根。L2范数正则化定义的数学表达式如下:
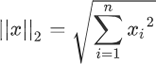
回归类算法
除了“线性回归算法” 也就是“最小二乘法”之外(具体可以参见《线性回归数学解析》一节),还有以下常用算法:
1) Ridge类
Ridge 回归算法,又称“岭回归算法”主要用于预测回归问题,是在线性回归的基础上添加了 L2 正则项,使得权重 w 的分布更加均匀,其损失函数如下:
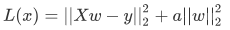
损失函数的左侧与线性回归算法的损失函数一致。只是在最后添加右侧的 L2 正则项,其中 a 只是一个常数,需要根据经验设置。
注意,线性回归函数的 1/n 在优化过程的运算中不会影响结果,它只是一个常量而已,而常量的导数是 0。
2) Lasso类
Lasso 回归算法:我们知道,常用的正则项有 L1 和 L2,而使用了 L1 正则项的线性回归是 Lasso 回归算法,它可以预测回归问题,其损失函数的表达式如下(求最小损失值):
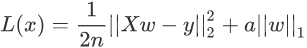
上述表达式的左侧与 Ridge 回归算法的损失函数基本一致,只是将右侧的 L2 范数替换成了 L1 范数,而且左侧式子相比线性回归表达式而言,多了一个1/2,但实际的优化过程中,它并不会对权重 w 产生影响。
实现Logistic回归
下面使用 skleran 库实现 Logistic 回归算法,首先导入一下模块:
from sklearn.linear_model import LogisticRegression
KNN最邻近分类算法
KNN算法原理
为了判断未知样本的类别,以所有已知类别的样本作为参照来计算未知样本与所有已知样本的距离,然后从中选取与未知样本距离最近的 K 个已知样本,并根据少数服从多数的投票法则(majority-voting),将未知样本与 K 个最邻近样本中所属类别占比较多的归为一类。这就是 KNN 算法基本原理。
在 scikit-learn 中 KNN 算法的 K 值是通过 n_neighbors 参数来调节的,默认值是 5。
KNN 算法原理:如果一个样本在特征空间中存在 K 个与其相邻的的样本,其中某一类别的样本数目较多,则待预测样本就属于这一类,并具有这个类别相关特性。该方法在确定分类决策上只依据最邻近的一个或者几个样本的类别来决定待分样本所属的类别。
KNN 算法简单易于理解,无须估计参数,与训练模型,适合于解决多分类问题。但它的不足是,当样本不平衡时,如一个类的样本容量很大,而其他类样本容量很小时,有很能导致当输入一个新样本时,该样本的 K 个邻居中大容量类的样本占多数,而此时只依照数量的多少去预测未知样本的类型,就会可能增加预测错误概率。此时,我们就可以采用对样本取“权值”的方法来改进。
KNN算法流程
下面对 KNN 算法的流程做简单介绍。KNN 分类算法主要包括以下 4 个步骤:
- 准备数据,对数据进行预处理 。
- 计算测试样本点(也就是待分类点)到其他每个样本点的距离(选定度量距离的方法)。
- 对每个距离进行排序,然后选择出距离最小的 K 个点。
- 对 K 个点所属的类别进行比较,按照少数服从多数的原则(多数表决思想),将测试样本点归入到 K 个点中占比最高的一类中。
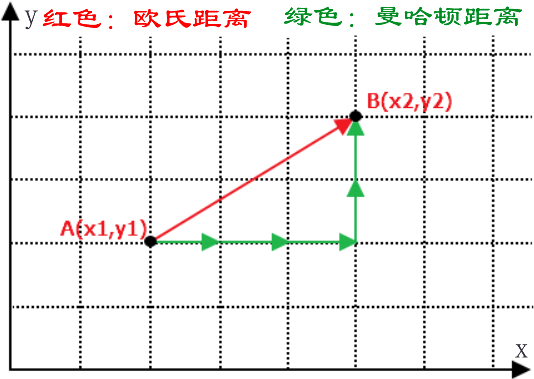
注意:在机器学习中有多种不同的距离公式,下面以计算二维空间 A(x,y),B(x1,y1) 两点间的距离为例进行说明,下图展示了如何计算欧式距离和曼哈顿街区距离。(PS:要理会名字,名字都是纸老虎)如下图所示:
在前面提到过欧氏距离,它表示两点之间最短的距离,其计算公式如下:
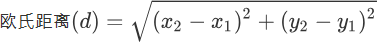
曼哈顿街区距离计算公式如下: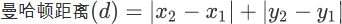
那么你会考虑它们两者的区别是什么呢?其实很容易理解,我们知道两点之前线段最短,A 和 B 之间的最短距离就是“欧式距离”,但是在实际情况中,由于受到实际环境因素的影响,我们有时无法按照既定的最短距离行进,比如你在一个楼宇众多的小区内,你想从 A 栋达到 B 栋,但是中间隔着其他楼房,因此你必须按照街道路线行进(图中红线),这种距离就被称作“曼哈顿街区距离”。
注意:除上述距离外,还有汉明距离、余弦距离、切比雪夫距离、马氏距离等。在 KNN 算法中较为常用的距离公式是“欧氏距离”。
KNN预测分类
通过上述介绍我们理解了 KNN 算法的基本工作流程,它主要利用“多数表决思想”与“距离”来达到分类的目的,那么我们应该如何确定 K 值呢?因为不同的 K 值会影响分类结果,如下所示:
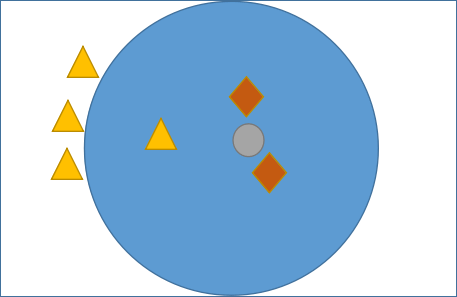
如图 1 所示,有三角形和菱形两个类别,而“灰色圆”是一个未知类别,现在通过 KNN 算法判断“灰色圆”属于哪一类。如果当 K 的取值为 3 时,按照前面讲述的知识,距离最近且少数服从多数,那“灰色圆”属于菱形类,而当 K= 6 时,按照上述规则继续判断,则“灰色圆”属于三角形类。
KNN 分类算法适用于多分类问题、OCR光学模式识别、文本分类等领域。
sklearn实现KNN分类算法
Pyhthon Sklearn 机器学习库提供了 neighbors 模块,该模块下提供了 KNN 算法的常用方法,如下所示:
| 类方法 | 说明 |
|---|---|
| KNeighborsClassifier | KNN 算法解决分类问题 |
| KNeighborsRegressor | KNN 算法解决回归问题 |
| RadiusNeighborsClassifier | 基于半径来查找最近邻的分类算法 |
| NearestNeighbors | 基于无监督学习实现KNN算法 |
| KDTree | 无监督学习下基于 KDTree 来查找最近邻的分类算法 |
| BallTree | 无监督学习下基于 BallTree 来查找最近邻的分类算法 |
本节可以通过调用 KNeighborsClassifier 实现 KNN 分类算法。下面对 Sklearn 自带的“红酒数据集”进行 KNN 算法分类预测。最终实现向训练好的模型喂入数据,输出相应的红酒类别,示例代码如下:
- #加载红酒数据集
- from sklearn.datasets import load_wine
- #KNN分类算法
- from sklearn.neighbors import KNeighborsClassifier
- #分割训练集与测试集
- from sklearn.model_selection import train_test_split
- #导入numpy
- import numpy as np
- #加载数据集
- wine_dataset=load_wine()
- #查看数据集对应的键
- print("红酒数据集的键:\n{}".format(wine_dataset.keys()))
- print("数据集描述:\n{}".format(wine_dataset['data'].shape))
- # data 为数据集数据;target 为样本标签
- #分割数据集,比例为 训练集:测试集 = 8:2
- X_train,X_test,y_train,y_test=train_test_split(wine_dataset['data'],wine_dataset['target'],test_size=0.2,random_state=0)
- #构建knn分类模型,并指定 k 值
- KNN=KNeighborsClassifier(n_neighbors=10)
- #使用训练集训练模型
- KNN.fit(X_train,y_train)
- #评估模型的得分
- score=KNN.score(X_test,y_test)
- print(score)
- #给出一组数据对酒进行分类
- X_wine_test=np.array([[11.8,4.39,2.39,29,82,2.86,3.53,0.21,2.85,2.8,.75,3.78,490]])
- predict_result=KNN.predict(X_wine_test)
- print(predict_result)
- print("分类结果:{}".format(wine_dataset['target_names'][predict_result]))
输出结果:
红酒数据集的键: dict_keys(['data', 'target', 'frame', 'target_names', 'DESCR', 'feature_names']) 数据集描述: (178, 13) 0.75 [1] 分类结果:['class_1']
通俗地理解贝叶斯公式(定理)
贝叶斯定理
贝叶斯定理的发明者 托马斯·贝叶斯 提出了一个很有意思的假设:“如果一个袋子中共有 10 个球,分别是黑球和白球,但是我们不知道它们之间的比例是怎么样的,现在,仅通过摸出的球的颜色,是否能判断出袋子里面黑白球的比例?”
上述问题可能与我们高中时期所接受的的概率有所冲突,因为你所接触的概率问题可能是这样的:“一个袋子里面有 10 个球,其中 4 个黑球,6 个白球,如果你随机抓取一个球,那么是黑球的概率是多少?”毫无疑问,答案是 0.4。这个问题非常简单,因为我们事先知道了袋子里面黑球和白球的比例,所以很容易算出摸一个球的概率,但是在某些复杂情况下,我们无法得知“比例”,此时就引出了贝叶斯提出的问题。
在统计学中有两个较大的分支:一个是“频率”,另一个便是“贝叶斯”,它们都有各自庞大的知识体系,而“贝叶斯”主要利用了“相关性”一词。下面以通俗易懂的方式描述一下“贝叶斯定理”:通常,事件 A 在事件 B 发生的条件下与事件 B 在事件 A 发生的条件下,它们两者的概率并不相同,但是它们两者之间存在一定的相关性,并具有以下公式(称之为“贝叶斯公式”):
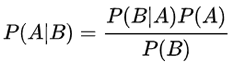
看到上述公式,你可能一头雾水,不过不必慌张,下面我们来了解一下“贝叶斯”公式。
符号意义
首先我们要了解上述公式中符号的意义:
- P(A) 这是概率中最基本的符号,表示 A 出现的概率。比如在投掷骰子时,P(2) 指的是骰子出现数字“2”的概率,这个概率是 六分之一。
- P(B|A) 是条件概率的符号,表示事件 A 发生的条件下,事件 B 发生的概率,条件概率是“贝叶斯公式”的关键所在,它也被称为“似然度”。
- P(A|B) 是条件概率的符号,表示事件 B 发生的条件下,事件 A 发生的概率,这个计算结果也被称为“后验概率”。
有上述描述可知,贝叶斯公式可以预测事件发生的概率,两个本来相互独立的事件,发生了某种“相关性”,此时就可以通过“贝叶斯公式”实现预测。
条件概率
条件概率是“贝叶斯公式”的关键所在,那么如何理解条件概率呢?其实我们可以从“相关性”这一词语出发。举一个简单的例子,比如小明和小红是同班同学,他们各自准时回家的概率是 P(小明回家) = 1/2 和 P(小红回家) =1/2,但是假如小明和小红是好朋友,每天都会一起回家,那么 P(小红回家|小明回家) = 1 (理想状态下)。
上述示例就是条件概率的应用,小红和小明之间产生了某种关联性,本来俩个相互独立的事件,变得不再独立。但是还有一种情况,比如小亮每天准时到家 P(小亮回家) =1/2,但是小亮喜欢独来独往,如果问 P(小亮回家|小红回家) 的概率是多少呢?你会发现这两者之间不存在“相关性”,小红是否到家,不会影响小亮的概率结果,因此小亮准时到家的概率仍然是 1/2。
贝叶斯公式的核心是“条件概率”,譬如 P(B|A),就表示当 A 发生时,B 发生的概率,如果P(B|A)的值越大,说明一旦发生了 A,B 就越可能发生。两者可能存在较高的相关性。
先验概率
在贝叶斯看来,世界并非静止不动的,而是动态和相对的,他希望利用已知经验来进行判断,那么如何用经验进行判断呢?这里就必须要提到“先验”和“后验”这两个词语。我们先讲解“先验”,其实“先验”就相当于“未卜先知”,在事情即将发生之前,做一个概率预判。比如从远处驶来了一辆车,是轿车的概率是 45%,是货车的概率是 35%,是大客车的概率是 20%,在你没有看清之前基本靠猜,此时,我们把这个概率就叫做“先验概率”。
后验概率
在理解了“先验概率”的基础上,我们来研究一下什么是“后验概率?”
我们知道每一个事物都有自己的特征,比如前面所说的轿车、货车、客车,它们都有着各自不同的特征,距离过远的时候,我们无法用肉眼分辨,而当距离达到一定范围内就可以根据各自的特征再次做出概率预判,这就是后验概率。比如轿车的速度相比于另外两者更快可以记做 P(轿车|速度快) = 55%,而客车体型可能更大,可以记做 P(客车|体型大) = 35%。
如果用条件概率来表述 P(体型大|客车)=35%,这种通过“车辆类别”推算出“类别特征”发生的的概率的方法叫作“似然度”。这里的似然就是“可能性”的意思。
朴素+贝叶斯
了解完上述概念,你可能对贝叶斯定理有了一个基本的认识,实际上贝叶斯定理就是求解后验概率的过程,而核心方法是通过似然度预测后验概率,通过不断提高似然度,自然也就达到了提高后验概率的目的。
我们知道“朴素贝叶斯算法”由两个词语组成。朴素(native)是用来修饰“贝叶斯”这个名词的。按照中文的理解“朴素”意味着简单不奢华。朴素的英文是“native”,意味着“单纯天真”。
朴素贝叶斯是一种简单的贝叶斯算法,因为贝叶斯定理涉及到了概率学、统计学,其应用相对复杂,因此我们只能以简单的方式使用它,比如天真的认为,所有事物之间的特征都是相互独立的,彼此互不影响。关于朴素贝爷斯算法在下一节会详细介绍。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号